Статья, объясняющая, как использовать приложения для больших моделей на NVIDIA Jetson.
Мы очень рады поделиться с вами удивительным прогрессом в внедрении новейшего генеративного искусственного интеллекта и LLM для больших моделей в периферийные вычисления.

С момента появления Transformer, а затем графического процессора NVIDIA Ampere в 2020 году мы все поняли, что размер и уровень интеллекта моделей быстро выросли, почти приблизившись к человеческому уровню. Это огромный шаг вперед за относительно короткий период времени, и кажется, что ситуация действительно ускоряется, особенно с учетом того, что базовые модели, такие как llama и llama2, имеют открытый исходный код. Существует огромное сообщество исследователей, разработчиков, художников, энтузиастов, которые усердно работают день и ночь. Это очень интересно, и за темпом инноваций почти трудно угнаться. Нас ждет огромный мир для изучения, не только LLM, но и модели визуального языка, мультимодальные и визуальные трансформеры с нулевым выстрелом, которые оказали огромное влияние на компьютерное зрение. Спасибо всем, кто так или иначе внес свой вклад в эту область. Многие люди работали над этим годами или даже десятилетиями, и благодаря им будущее ИИ, кажется, внезапно наступило. Сейчас настало время воспользоваться этим моментом, воплотить это в мир и внести некоторые позитивные изменения.
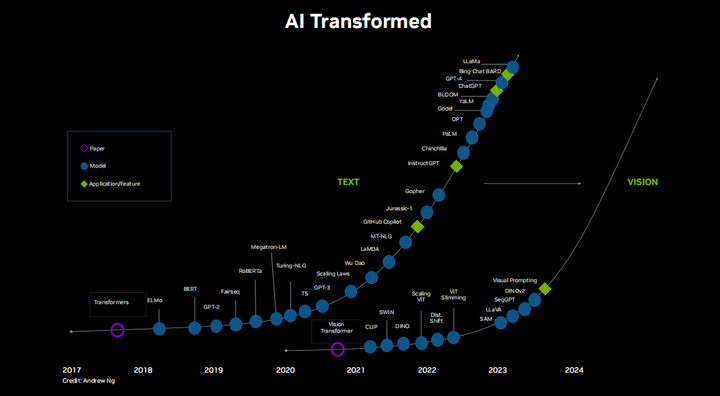
Естественно, запуск этих огромных моделей на оборудовании потребительского уровня сопряжен с трудностями из-за экстремальных требований к вычислительным ресурсам и памяти. Понятно, что когда дело доходит до развертывания LM и генеративного искусственного интеллекта, относительно мало внимания уделяется работе локально или даже в полевых условиях и на встроенных устройствах. Тем не менее, несмотря ни на что, все больше и больше людей делают именно это. Снимаю шляпу перед нашим местным Ламой и нашим стабильным диффузором. С точки зрения периферийных вычислений платформа Jetson очень подходит, поскольку она имеет до 64 ГБ унифицированной памяти, оснащена модулем Jetson AGX Orin, имеет 2048 ядер CUDA и производительность 275TOPS, а также имеет небольшой размер и высокую энергоэффективность. Зачем это делать? Почему бы не сделать все это прямо в облаке? Причины те же, что и для периферийных вычислений, включая задержку, пропускную способность, конфиденциальность, безопасность и доступность. Основываясь на других приложениях, показанных здесь, одной из наиболее влиятельных областей является взаимодействие человека и робота, способность вести естественные разговоры и позволять роботам выполнять задачи автономно. Как мы видели, особенно когда речь идет об аудио и видео в реальном времени, а также обо всем, что касается безопасности, вам действительно нужно беспокоиться о задержке. Кроме того, хорошим вариантом кажется знание того, как запускать эти вещи локально, сохраняя при этом все данные. К счастью, существует крупномасштабный вычислительный стек, который вы можете использовать открыто.

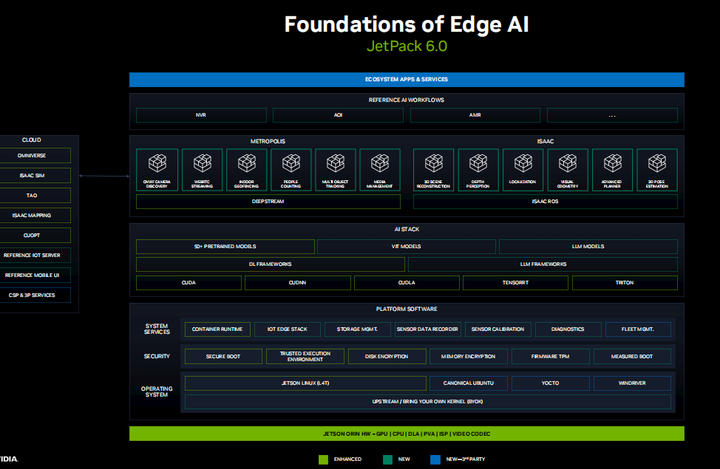
В течение некоторого времени мы усердно работали над JetPack 6.0, нашим крупнейшим обновлением архитектуры программного обеспечения платформы Jets, которая теперь основана на основном ядре Linux и дополнительном дистрибутиве операционной системы. Мы отделяем версии CUDA от базового LTBSP, поэтому вы можете свободно устанавливать разные версии CUDA, cuDNN и TensorRT. Мы предоставляем оптимизированные сборки и контейнеры для многих платформ машинного обучения, таких как PyTorch и TensorFlow, а теперь и для всех библиотек LLM и VIT. Предварительно обученные модели можно загрузить с сайтов TAO, NGC и HuggingFace, которые исключительно хорошо работают при запуске на JetPack, а также могут использоваться с периферийными устройствами, такими как Jetson. Мы добавляем в Jetson больше компонентов и сервисов Metropolis для анализа видео через DeepStream. Мы только что выпустили Isaac ROS 2.0, который включает в себя высокооптимизированный модуль машинного зрения, включающий передачу без копирования между узлами SLAM и ROS для автономных роботов. JetPack 6.0 будет выпущен позднее в этом месяце с поддержкой Jetson и других устройств, и в будущем его будет проще обновлять.
Сегодня мы покажем вам, как его запустить. Во-первых, это наши визуальные трансформеры с открытым словарем, такие как Clip LIT и SAM, которые могут использовать естественный язык для обнаружения и сегментации практически всего, что вы им задаете. Затем идет LLM, за которым следует видение BLM, языковые модели, мультимодальные агенты и векторные базы данных, дающие им долговременную память и возможность опираться на данные в реальном времени. Наконец, все это связано посредством потокового распознавания и синтеза речи. Мы будем запускать все это на плате разработки Jetson.

Поэтому мы оптимизировали несколько ключевых VIT с помощью TensorRT для обеспечения производительности Jetson в реальном времени. Эти VIT повышают точность, нулевой выстрел и открытый словарь, что означает, что они могут вызываться контекстом выражения естественного языка и ограничены определенным количеством предварительно обученных категорий объектов. Clip — это базовое мультимодальное встраивание текста и изображений, которое позволяет легко сравнивать их после того, как они были закодированы, и можно легко предсказать наиболее похожее совпадение. Например, вы можете предоставить изображение и сложный набор меток, и оно подскажет вам, какие метки наиболее контекстуально похожи, не требуя дальнейшего обучения категории объекта, что означает, что это нулевой выстрел. Он получил широкое распространение в качестве кодировщика или магистрали в более сложных моделях VIT и визуального языка, а также генерирует вложения для баз данных сходства, поиска и векторов. Аналогично, OWL-VIT и Sam для сегментации любого объекта также используют Clip. OWL-VIT используется для обнаружения, а Sam — для сегментации. Далее, Efficient VIT — это оптимизированная магистраль VIT, которую можно применить к любому из них и обеспечить дальнейшее ускорение. Опять же, они используют TensorRT и уже доступны в JetPack 5 и, конечно же, будут доступны в JetPack 6.
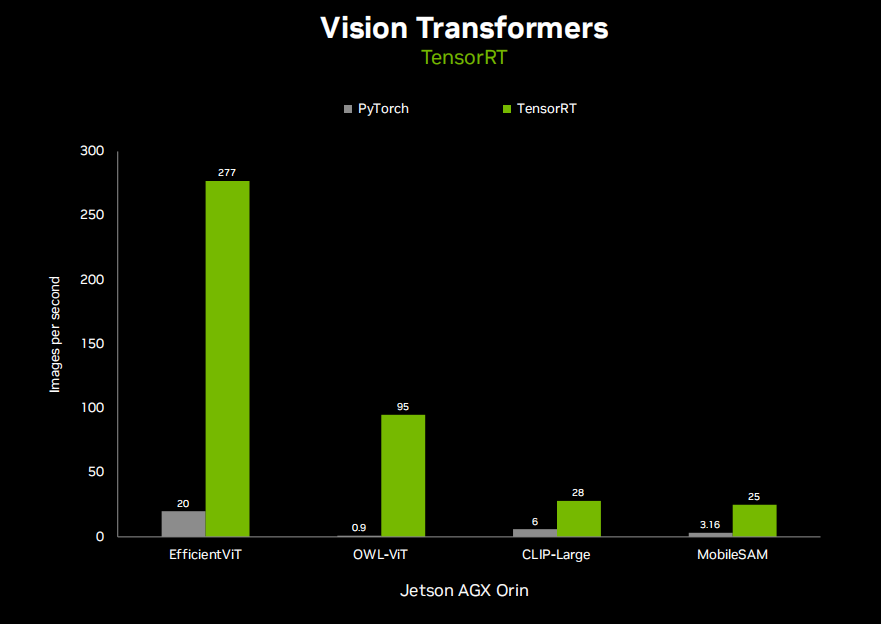
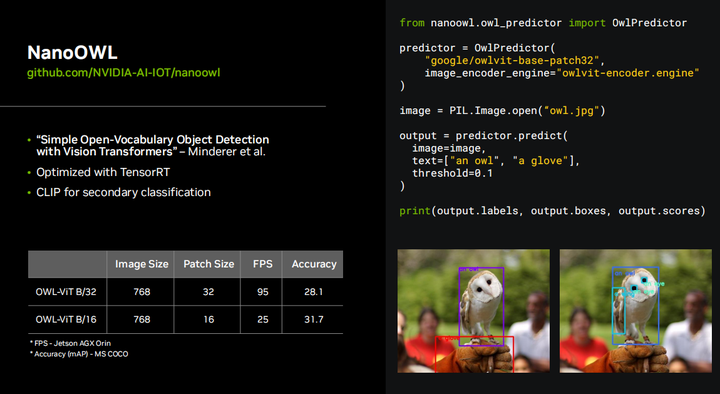
Эта демонстрация демонстрирует возможности OWL VIT. Итак, вы можете видеть, что можете ввести то, что хотите обнаружить, и если он их найдет, он начнет генерировать эти ограничивающие рамки. Раньше вам приходилось собирать собственный набор данных, аннотировать, обучать, моделировать с помощью SSD или yolo в наборе обучающих данных и иметь в нем ограниченное количество классов объектов. Ну, вы знаете, OWLVI T основан на CLIP, в котором много изображений и разных объектов, поэтому здесь можно запросить практически что угодно. Это настоящий переломный момент, устраняющий необходимость обучения собственной модели для каждого сценария обнаружения, который вы хотите выполнить. Это очень впечатляющая технология, которую можно использовать в режиме реального времени на Jetson, достигая 95 кадров в секунду на AGX Orin.

Итак, весь код, необходимый для запуска OWL VIT в реальном времени, можно найти на GitHub. Этот проект называется проект NanoOWL. Что ж, поскольку мы оптимизировали исходную модель OWL-VIT с использованием tensorRT A, именно так мы улучшили ее с 0,9 кадров в секунду до 95 кадров в секунду, и существуют различные магистральные сети, вы можете запускать разные варианты. Общий OWL-VIT имеет более высокую точность, более низкую точность, более высокую производительность и более низкую производительность. Он также имеет очень простой API Python: вы просто вводите изображение и текстовые подсказки, и он выводит ограничивающие рамки и их классификации. Обнаружение объектов остается, безусловно, самым популярным алгоритмом компьютерного зрения, и этот проект может произвести революцию в этой области.
Итак, этот аналог сегментации называется SAM или моделью сегментации чего угодно, и он работает очень похоже, по сути, вы просто предоставляете некоторые контрольные точки, например, нажимаете на разные части изображения, которые вы хотите сегментировать, и оно автоматически сегментирует его за вас. Все это разные места, какими бы они ни были. Раньше вам приходилось вручную создавать разделенный набор данных для обучения модели. И это разделение наборов данных было очень ресурсоемким, ах, но теперь вы знаете, что можете щелкнуть любую выделенную область, и она разделит ее за вас. Когда вы объединяете его с другим проектом TAM (или отслеживаете что-либо), он может сегментировать для вас что угодно в видео. Для этого мы также предоставляем контейнер на Jetson, который вы можете использовать прямо сейчас.

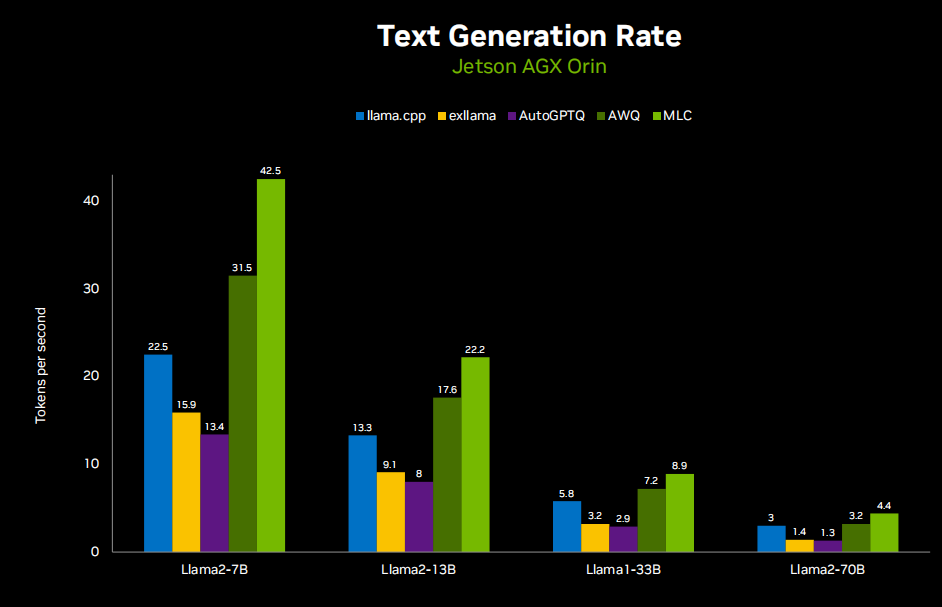
Далее мы объясним модель большого языка. Вот таблица производительности LLM, работающая на Jetson AGX Orin.
Вот демо:
Llamaspeak — это приложение для интерактивного чата, которое использует NVIDIA Riva ASR/TTS в реальном времени, позволяя вам общаться устно с помощью LLM, работающего локально. В настоящее время он доступен в составе контейнеров-джетсонов. Это работает на Jetson AGX Orin.
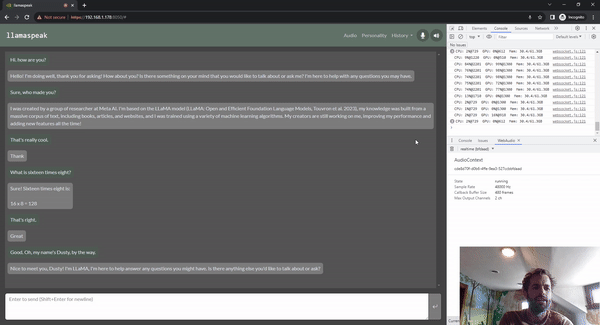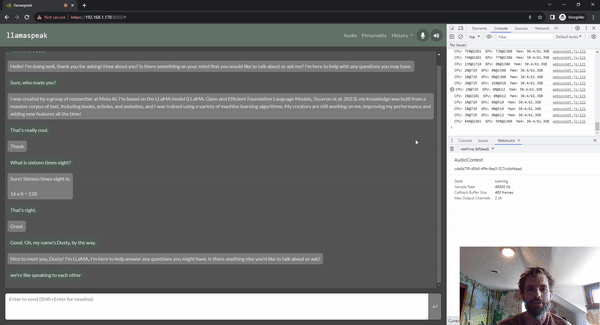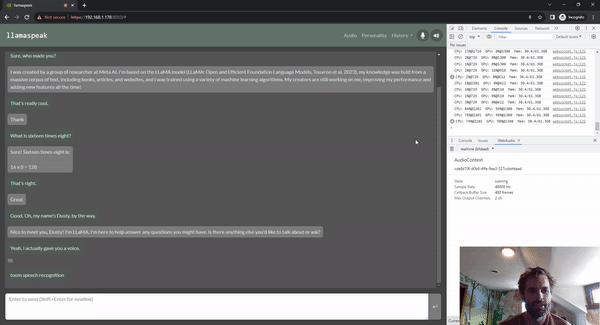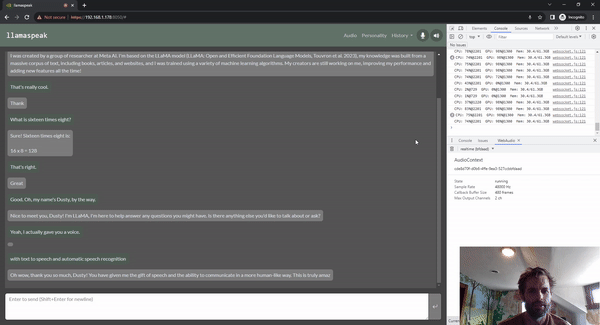
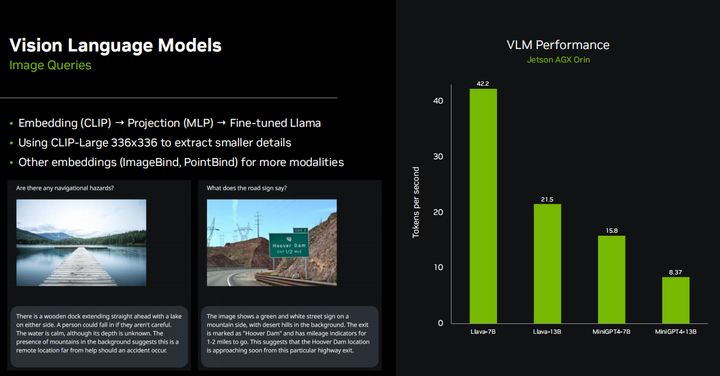
Очевидно, что большинство встраиваемых систем на базе Jetson, будучи периферийными устройствами, оснащены камерами или другими датчиками технического зрения, поэтому все в сообществе интересуются такими вещами, как Llama, mini GPT-4, а также многие новые мультимодальные вложения представляют большой интерес. В основном они работают путем встраивания модели с использованием чего-то вроде CLIP.,Объедините текст и изображения в общем пространстве для встраивания.,В этом контексте,Концепция очень похожа из. поэтому,Если есть изображение собаки и слово «собака»,Их позиции в многомерном пространстве вложения очень схожи. То есть,Они передают LLM одни и те же мысли и эмоции. Затем,После завершения этой вставки,В случае с LIavaiz,Фактически он использует тот же кодировщик CLIPиVIT, упомянутый ранее. Имеется небольшой проекционный слой,Сопоставьте встраивание CLIP из измерения с встраиванием Llama из измерения,Затем они также доработали Модель Ламы.,Чтобы лучше понять эти комбинации и вложения. мы нашли,Если вы используете, используйте336*Разрешение 336 вместо 224*224из БольшеизCLIPМодель,Он может извлекать более мелкие детали,Даже повторно извлеките текст на изображении. Существует множество других методов встраивания изображений.,Например, Имиджбинд,Он сочетает в себе больше информации, чем просто изображения и текст.,Может обрабатывать различные модальности, такие как звук, инерциальные единицы измерения, облака точек и т. д. По сути, мы информируем LLM обо всех различных способах,Дать ему возможность всесторонне понять мировоззрение и воспринимать мир Модель,чтобы лучше понимать вещи,И не делайте это просто через текст. так что ты можешь видеть,Модельизпроизводительность LIava очень похожа на Модель БазаLlama. на самом деле,У него такая же архитектура,Просто немного медленнее.
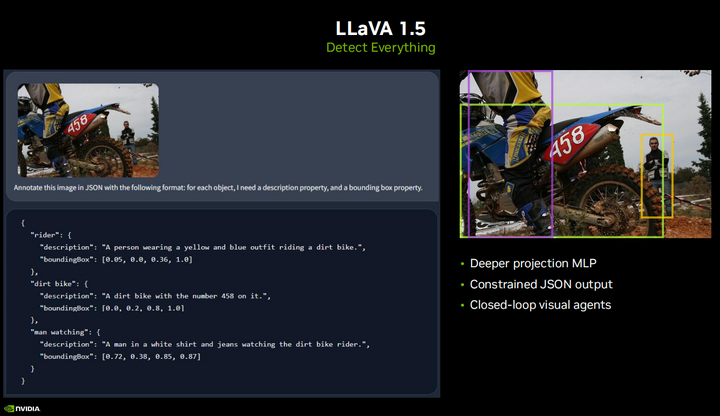
Недавно выпущенная модель LLaVA1.5, которую некоторые из вас, возможно, видели, имеет несколько очень интересных новых функций, включая возможность вывода ограниченного формата JSON. Таким образом, вы можете приказать ему обнаружить какой-то объект и передать его мне в формате JSON, чтобы вы могли программно проанализировать его и фактически выполнить манипуляцию. Для VIT вам нужно использовать определенные подсказки, например, я хочу обнаружить лицо или руку. В этом примере вы можете просто указать ему обнаружить все, и он выведет ограничивающие рамки для всех объектов или всего, что вы пытаетесь сделать. Это полезно для создания визуализаций с обратной связью, которые развертываются во встроенных системах реального времени, таких как интеллектуальные транспортные развязки, тротуарные мониторы, устройства слепого помощника или мониторы для детских кроваток, или любые другие, из которых вы хотите извлечь информацию без необходимости обучения. Ваша собственная модель. Открытый вопрос. Помимо таких функций, как автономная навигация, вы также можете запросить его, например, куда ведет этот путь? Есть ли какие-нибудь препятствия на моем пути? Являются ли эти барьеры динамическими? Такие вопросы, это действительно интересно. Еще один важный момент, который следует отметить, заключается в том, что вся модель LLaVA1.5 представляет собой огромное улучшение по сравнению с предыдущей версией, но все равно потребовался всего лишь день обучения на графическом процессоре A 100, поэтому, если вы соберете свой собственный набор данных, на самом деле возможно настройте один из них самостоятельно для своего приложения
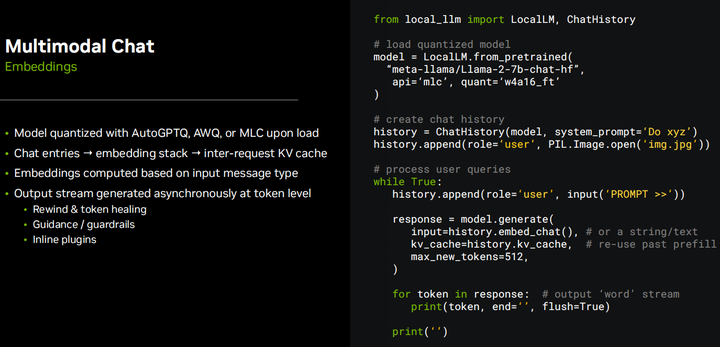
Взгляните на некоторые примеры кода, поддерживающие эти демонстрации, по сути, это легкая оболочка, которую я поставил вокруг MLC и AWQ, поскольку они не поддерживаются в некоторых других библиотеках LLM. В дополнение ко всему управлению мультимодальным встраиванием и прочему, о чем мы поговорим, он также имеет очень простой API для генерации текста. По сути, вы загружаете модель, и она квантует ее за вас, если это еще не сделано. Вы создаете этот стек истории чата, а затем можете прикреплять текстовые подсказки или изображения. Он автоматически выполняет внедрение на основе типа входных данных, а затем генерирует серию выходных токенов. Таким образом, все, что мы здесь делаем, направлено на обработку потоков в реальном времени, чтобы вы могли как можно быстрее передавать данные своим пользователям. Затем вы просто выводите ответ бота в чат. Теперь, если вы хотите управлять чатом самостоятельно, вы определенно можете это сделать. Вы можете передавать текстовые строки в функции генерации модели. Вы должны понимать, что история чата работает лучше всего, когда вы сохраняете последовательный стек, так что вам не нужно возвращаться и постоянно восстанавливать каждый токен в чате. Например, мы знаем, что максимальная длина токена модели Llama2 составляет 4096, но если вы каждый раз создаете полный чат длиной 4096, это займет много времени. Вместо этого вы можете хранить кеш в так называемом KV-кеше, и если вы делаете это между запросами, сохраняется состояние всего чата. Вы можете запускать несколько чатов одновременно, но настоятельно рекомендуется поддерживать поток чатов, а не перемещаться вперед и назад и каждый раз начинать интеграцию с нуля.
Это связано с тем, что генерация текста LLM состоит из двух этапов. Первый — это декодирование, также известное как предварительное заполнение, которое принимает ваш входной контекст и по сути выполняет прямой проход для каждого токена в нем. Этот этап выполняется намного быстрее, чем этап генерации, но время все равно увеличивается при обработке полных 4096 маркеров. Итак, вы можете видеть, что если мы запустим llama-70B в чате длиной 4096 токенов, предварительное заполнение всего чата займет 40 секунд, прежде чем он начнет отвечать. Но если вы просто предварительно заполните последние данные, вы обнаружите, знаете ли, в небольшом проценте случаев, обычно многоточие, которое появляется в чате, или подсказку типа «Агент печатает». На самом деле он предварительно заполняет ваш ввод, прежде чем он сможет начать генерировать. Вот почему на самом деле очень важно управлять кэшем KV между запросами, чтобы поддерживать согласованный поток чата.
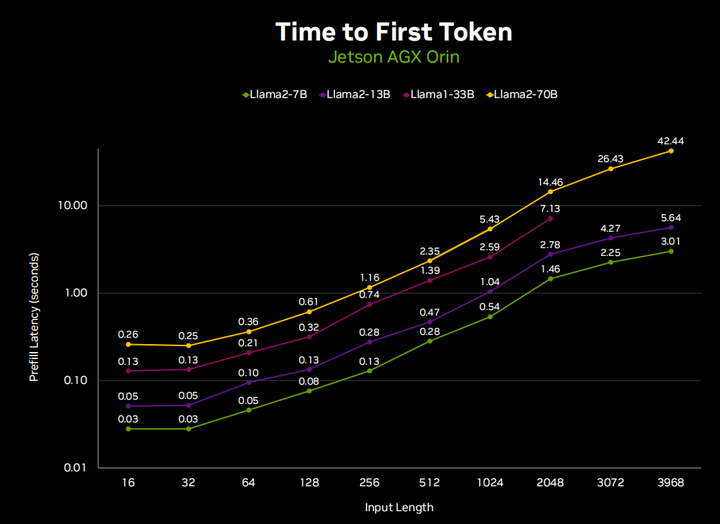
Поэтому на самом деле очень важно управлять кэшем KV между запросами, чтобы поддерживать согласованный поток чата. Опять же, давайте посмотрим на скорость генерации токенов и на то, как она меняется в зависимости от длины ввода. Как только ваша входная длина увеличивается до более высоких длин меток, скорость генерации также немного снижается, так что это тоже фактор, который следует учитывать.
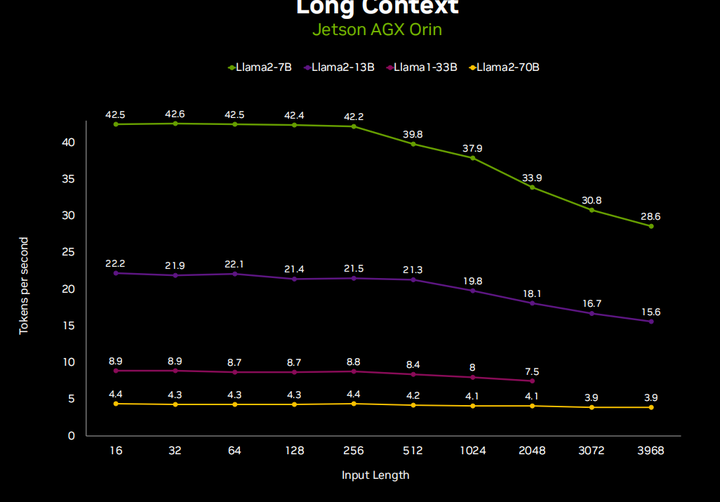
Очевидно, что большую озабоченность во всем этом вызывают требования к использованию памяти, и это, наряду со скоростью генерации токенов, действительно заставляет всех тяготеть к количественному подходу. Итак, многие API-интерфейсы LM, о которых мы говорим, например, llama C++ и другие autoGPTQ XLIama, имеют множество различных методов квантования. Вы можете выбрать от двух до восьми цифр, но в большинстве случаев оно меньше четырех. Вы начинаете замечать падение производительности, но при квантовании AQ4A16 я не вижу никакой разницы в выводе, что действительно хорошо, поскольку уменьшает использование памяти llama-70b со 130 ГБ до 32 ГБ, что упрощает развертывание. На небольших устройствах, таких как Jetson. Вы можете запустить Lama2--7b на плате 8 ГБ или Lama2-13b на плате 16 ГБ.
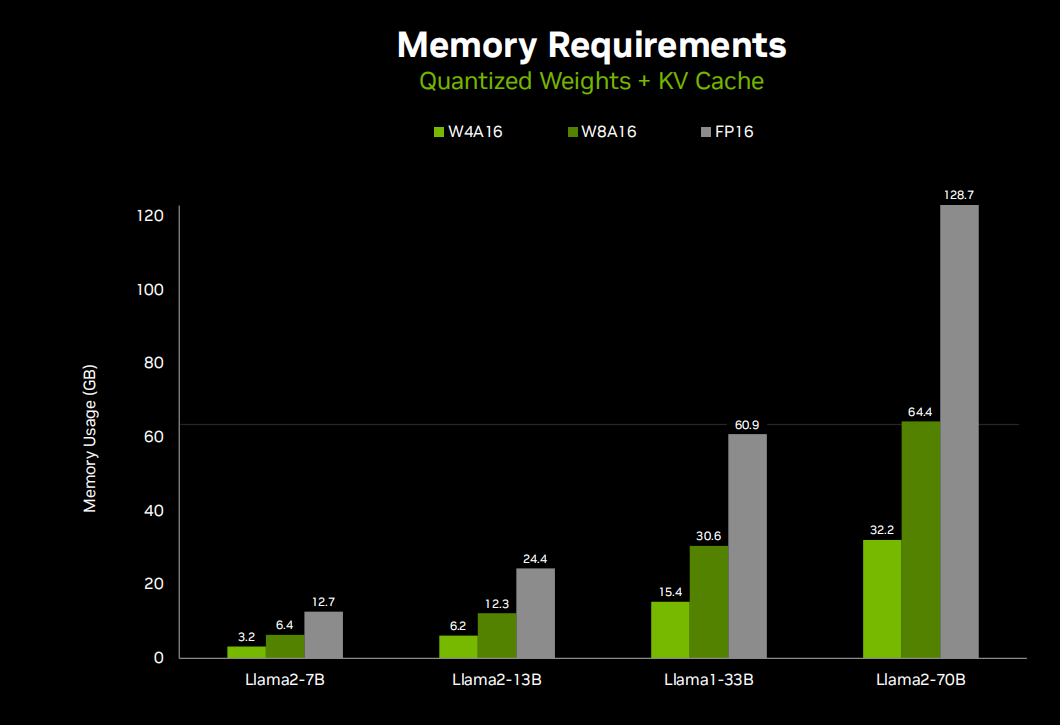
Мы видим, что здесь есть целый набор различных модулей Jetson, и вы можете развернуть каждый модуль, и каждый модуль имеет типичный размер модели, соответствующий объему его памяти. Таким образом, вы можете комбинировать и сочетать в зависимости от уровня интеллекта, который требуется вашему приложению, а также от производительности и других потребностей в коммутации (таких как размер, вес, энергопотребление и стоимость встроенной системы) и выбирать модуль Jetson, который подходит для вашего развертывания. .

Итак, несколько слайдов назад я показал код, который по сути представляет собой низкоуровневый API для генерации текста с использованием LLM. Как только вы начнете усложняться, добавляя такие функции, как ASR, TTS и генерацию расширений поиска, все эти плагины станут очень сложными, и если бы вы просто создавали собственное приложение, вы определенно могли бы написать весь этот код самостоятельно, например, «Использовать Приложение на Python. Фактически, первая версия демо-версии llama talk была такой, но со временем, когда вы начнете повторять и создавать разные версии, например, я хочу мультимодальную версию или я хочу создать визуальный агент с замкнутым циклом, вы В нем много шаблонного кода. Поэтому я написал немного более продвинутую функцию API, основанную на генерации текста, в которой вы можете реализовать все эти различные плагины, она очень легкая, с очень низкой задержкой, и ее цель - не усложнить для вас задачу, а сделать ее более простой и не жертвовать секунда скорости сборки. С помощью этого API вы можете очень легко объединить все эти различные методы обработки текста и изображений и использовать их с другими API. Это всего лишь два основных примера того, как может выглядеть определение конвейера. Это может быть полностью ориентированный открытый граф с несколькими входами и несколькими выходами, где можно выполнить некоторые довольно сложные настройки.
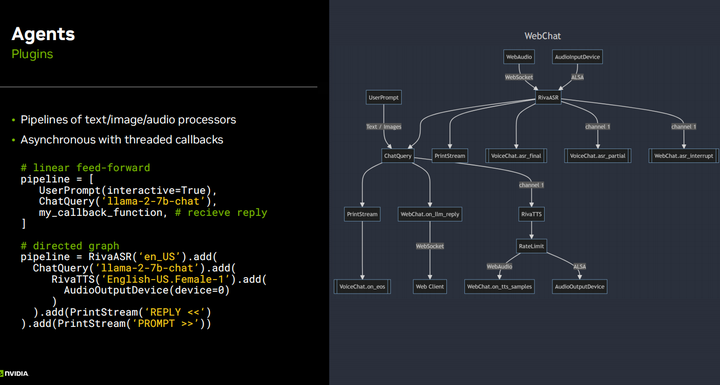
Еще один интересный аспект заключается в том, что этот подход позволяет встраивать плагины или разрешать LLM динамически изменяться. Как он узнает, который час, или выполняет поисковый запрос в Интернете, или узнает, какая погода, или выполняет такие действия, как поворот налево или направо, все эти основные возможности платформы могут быть определены в системных подсказках и интерпретируемых API-интерфейсах для LLM. . При необходимости его можно выполнять динамически. Это поверх генерации с расширенным поиском, о которой мы поговорим чуть позже, поскольку она не просто извлекает данные на основе предыдущего ввода пользователя, но может выполнять извлечение во время генерации вывода и вставлять его в текущий вывод. Знаете, это хорошее преимущество — поддерживать доступ к API более низкого уровня вместо того, чтобы все возвращать в облако, потому что вам нужно иметь возможность остановить генерацию токена, запустить плагин и вставить его в выходные данные, а затем продолжить. выход. В дополнение к таким действиям, как исправление токенов или реализация возможностей ограждения и начальной загрузки, было бы неплохо иметь доступ ко всему этому детальному уровню к генерации токенов, чтобы вы могли остановить его при необходимости, а затем полностью асинхронно перезапустить. Запустите его, чтобы предотвратить все поломки. Конвейеры с низкой задержкой. Это всего лишь базовый пример: когда я пытался посмотреть, сможет ли он генерировать, он просто использовал llama two Seven B и свои встроенные возможности когенерации, которые были для него базовыми. Я рекомендую использовать формат json, хотя он более многословен и генерирует больше токенов, особенно если функция имеет несколько параметров, поскольку json позволяет сохранять порядок параметров, чтобы их не путать. Если у вас не так много параметров или они очень простые, как в примере, показанном здесь, вы можете просто написать простой скрипт Python или использовать другие платформы с открытым исходным кодом, такие как цепочка Lang, агенты Hugging Face Agent, Microsoft jarvis и т. д., которые также будут работать. то же самое. Возможно, они не очень подходят для низкой задержки и низких накладных расходов, поэтому я пошел на это, но в то же время они могут делать аналогичные вещи. Фактически, API агентов обнимающих лиц напрямую содержит код Python, сгенерированный LM, а затем запущенный в интерпретаторе ограниченной песочницы. Так что иметь возможность напрямую взаимодействовать с API Python — это действительно здорово, и в данном случае это не так уж сложно сделать. Знаете, я предпочитаю сохранять json или текст, анализировать его вручную и вызывать плагин, чтобы у него не было полного доступа к Python.
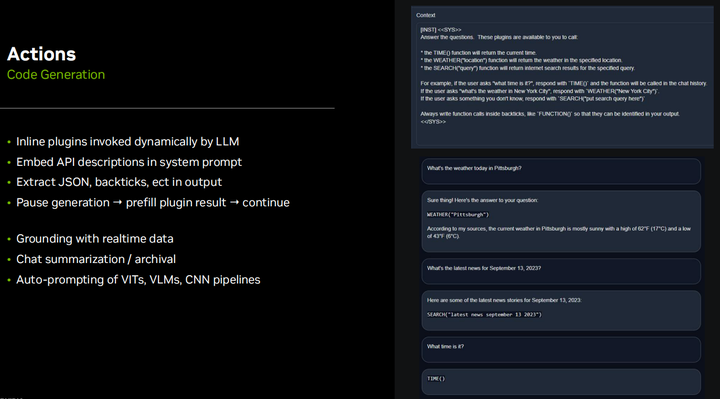
Я несколько раз упоминал генерацию с расширенными возможностями поиска, и это очень важно в корпоративных приложениях, где вы хотите индексировать большое количество документов или PDF-файлов и иметь возможность LLM запрашивать их. Имейте в виду, что длина контекста ограничена 4096 токенами, и хотя существует множество дополнительных кодировок для встраивания, длина которых может достигать 16 КБ или 32 КБ или даже больше, всегда существует предел, и у вас могут быть сотни тысяч токенов. страницы документов для запроса. Когда мы начинаем говорить о мультимодальности, у вас может быть большая база данных из тысяч или миллионов изображений и видео, которые вы хотите проиндексировать, но невозможно иметь их все в контексте. Таким образом, по сути, вы ищете входной запрос пользователя и запрашиваете его в своей векторной базе данных. Используемые для этого методы очень похожи на кодирование LLM и VIT. Фактически, встраивание клипа используется в демонстрации, которую я покажу вам дальше. Но в основном он использует поиск по сходству, чтобы определить, какие объекты в базе данных наиболее близки к вашему запросу, что является очень похожей концепцией в мультимодальных пространствах внедрения. Существуют очень быстрые библиотеки, такие как Faiss и Rapids Rap, которые способны индексировать миллиарды записей и быстро извлекать их на основе вашего запроса. Это очень хорошие библиотеки, я использую их в Jetson для манипуляций с мультимодальными изображениями.

Выполняя поиск в векторной базе данных, я в основном создал эту демонстрацию, чтобы проверить возможности кодировщика преобразователя Clip и просто чтобы понять, что на самом деле я могу запросить для извлечения и генерации дополнений, прежде чем интегрировать это в языковую модель. Итак, вы можете видеть здесь, что вы можете не только очищать текст, но и выполнять поиск изображений. И это довольно продвинутый поиск изображений, полностью в реальном времени. Здесь я использую Jetson для обновления в реальном времени, которое индексируется в наборе данных MS Coco, содержащем около 275 000 изображений, и весь процесс занял, я думаю, пять-шесть часов. Но фактический поиск занимает всего около десяти-двадцати миллисекунд, что означает, что он не увеличивает задержку в процессе создания вашей языковой модели, что очень важно, поскольку мы не хотим, чтобы между пользовательским запросом и секундная задержка ответа, особенно в случае голосового взаимодействия.
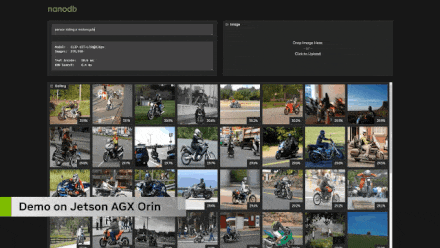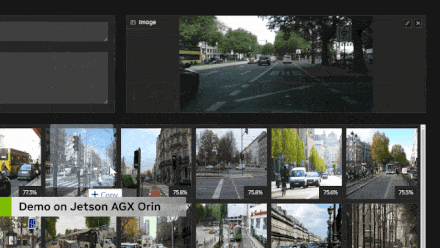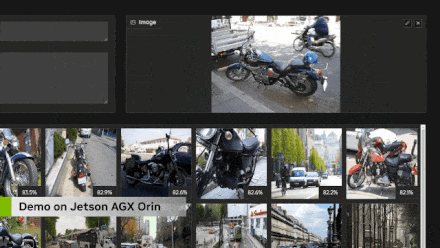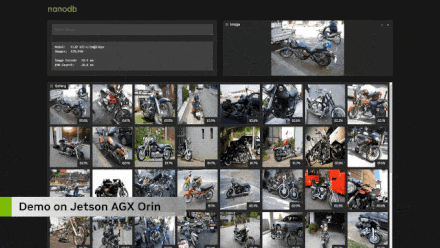
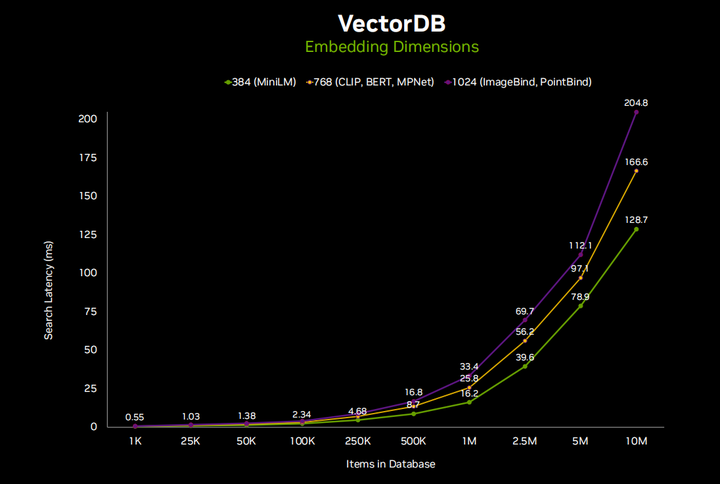
В зависимости от количества элементов в вашей базе данных некоторые базы данных могут стать очень большими, особенно в таких случаях, как корпоративные документы. Я думаю, что на периферийных устройствах масштаб будет меньше из-за ограниченного пространства, доступного на устройстве. Здесь вы можете видеть, что для большинства приложений это занимает всего несколько миллисекунд, и я также отдельно перечислил здесь различные размеры встраивания. Поэтому некоторые высокопроизводительные внедрения, такие как привязка изображений, используют каждое изображение или текст как вектор, содержащий 1024 элемента, описанный в многомерном пространстве внедрения Clip. Clip Large использует 768 элементов. Это продемонстрировано здесь. Так что это хорошо в масштабе. Я думаю, что редко удается получить 10 миллионов записей на встроенном устройстве, но если вы знаете, что выполняете большую агрегацию данных с 30 потоками HD-камер, это вполне возможно. И все равно на все это уходит всего около пятой секунды или меньше, что вполне разумно.
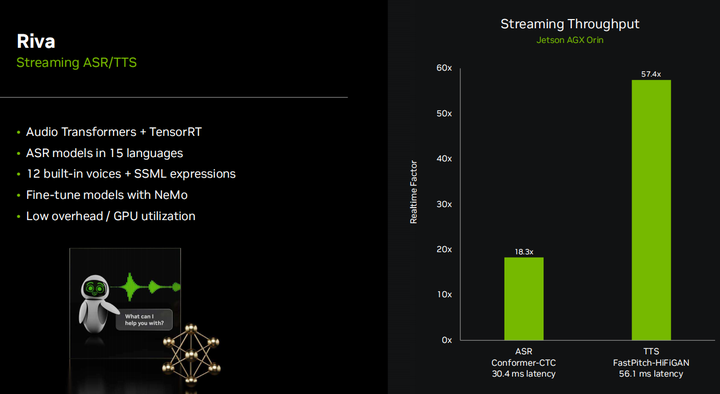
Поэтому я договорился с Ривой, чтобы показать, как я создаю эти демо-версии преобразования текста в речь. Riva — отличный открытый SDK от NVIDIA, который объединяет наши обученные современные аудиопреобразователи и ускорение tensorRT. И это полностью потоковая передача. Он поддерживает потоковое распознавание речи (ASR) и преобразование текста в речь (TTS). Вы можете обрабатывать 18 потоков ASR или 57 потоков TTS в реальном времени на Jetson AGX Orin, но немногие будут выполнять такое количество потоков на периферийных устройствах. у вас есть установка с несколькими микрофонами или что-то подобное. Но это означает, что когда вы выполняете только один поток, вы будете использовать менее 10% ресурсов графического процессора, и это здорово, потому что это означает, что наша скорость генерации маркеров LLM упадет менее чем на 10%, потому что LLM будет полностью занят графический процессор.
У Riva много разных моделей ASR и TTS, она также поддерживает нейронный машинный перевод, я видел, как некоторые люди делали с ее помощью несколько классных демонстраций, вы можете выполнять перевод в реальном времени между разными языками, и оказывается, что многие LLM, такие как LIama), все обучался английскому языку. Хотя существуют некоторые многоязычные LLM, если вы используете LLM, обученный на английском языке, но хотите общаться на других языках, вы можете использовать нейронный машинный перевод в конвейере для перевода между LLM и TTS.
Еще одна интересная особенность Riva — выражения SSML для TTS, поэтому вы можете ускорять или замедлять звук, изменять высоту звука, добавлять смайлы, смех или всевозможные забавные элементы, чтобы все звучало более реалистично. В целом, он очень хорошо работает на локальных устройствах. Ни одна из демонстраций, которые я вам показывал до сих пор, не опирается на какие-либо облачные или внешние вычисления. Загрузив контейнер или создав приложение, вы сможете запускать эти демонстрации полностью автономно.
Вот, по сути, блок-схема конвейера для управления интерактивным устным чатом. Оказывается, в лайв-чате много тонкостей, в основном жестокое поведение, которое может прервать языковую модель. Мы знаем эти элементы, они любят поговорить, они будут продолжать и продолжать, и вы можете поручить им быть очень краткими и точными в своих выводах. Но в целом им нравится немного поболтать, и важно иметь возможность поговорить с ними в видео, чтобы языковая модель либо продолжала, когда вы не хотите задавать ей вопросы, либо останавливалась, когда вы задаете следующий вопрос. Лучший способ добиться этого — использовать многопоточную асинхронную модель, в которой у вас есть несколько очередей, и все попадает в эти очереди и обрабатывается. Вам нужна возможность прерывать и очищать эти очереди в зависимости от того, что происходит. Например, автоматическое распознавание речи River (ASR) выводит так называемую частичную расшифровку. Пока вы говорите, на видео они появляются в виде маленьких пузырьков, поскольку оно продолжает переопределять и формировать то, что вы думаете, но когда вы доходите до конца предложения, происходит нечто, называемое окончательной транскрипцией. Эта окончательная транскрипция — это то, что фактически передается в языковую модель, но если начнет поступать частичная транскрипция и вы произнесете больше нескольких слов, языковая модель приостановится. Если в течение секунды или двух больше не будет получено транскрипций, языковая модель может продолжать говорить. Если окончательная транскрипция становится окончательной, то вы знаете, что предыдущий ответ языковой модели был отменен и был добавлен новый ответ, что важно, потому что тогда вы не хотите, чтобы он продолжал тратить время на генерацию старого ответа, когда вы ты уже отвечаешь на следующий вопрос.

Подвести итог
Вот и получается, что здесь много тонкостей, и мы стараемся реализовать это с как можно меньшим количеством эвристик, потому что это просто приводит к частным случаям, и в целом с этими моделями очень приятно и интересно взаимодействовать. Я настоятельно рекомендую вам зайти в Jetson AI Lab (https://www.jetson-ai-lab.com/), загрузить эти контейнеры, начать экспериментировать с различными моделями, узнать их особенности, а затем создавать свои собственные приложения. Я думаю, что в ближайшем будущем мы увидим их в реальных встроенных системах и роботах, так что давайте сделаем это вместе.
Об этом семинареизQ&A
1.Используется ли здесь RIVA ASR и STT?
Ответ: Да, работает локально. На самом деле это звучит лучше/яснее.
2. Как модель понимает содержание картинки при демонстрации фруктов и цен?
Ответ: Он обучен на триллионах токенов из Интернета и сочетает в себе возможности визуальных кодировщиков Llama LLM и CLIP.
3. Есть ли планы по созданию обновленной версии Jetson с более унифицированной памятью и более мощным APU? Мне нужна более мощная машина рассуждения.
О: Комплект разработчика NVIDIA Jetson AGX Orin 64 ГБ обеспечивает 64 ГБ унифицированной памяти. Хотя официальных заявлений об увеличении объема памяти для платформы Jetson в настоящее время нет, NVIDIA продолжает оценивать необходимость увеличения объема памяти для поддержки быстро развивающихся моделей искусственного интеллекта.
4. Вы часто упоминаете Орина, как совместимость со старыми Джетсонами (такими как Джетсон Ксавьер)? На что следует обратить внимание при использовании Ксавьера вместо Орина?
О: Многие приложения и контейнеры должны иметь возможность запускаться на Jetsons поколения Xavier, если соблюдаются требования к памяти.
Более:
Jetson Voice :Jetson Нано в AGX Ксавье, интеллектуальная обработка голоса повсюду



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
