Статическое квантование модели PyTorch, сохранение, загрузка модели квантования int8
1. Что такое количественная оценка модели?
Чтобы обеспечить более высокую точность, большинство научных операций вычисляются с использованием типов с плавающей запятой. Наиболее распространенными являются 32-битный тип с плавающей запятой и 64-битный тип с плавающей запятой, а именно float32 и double64. Однако вывод без обратного распространения ошибки, в сети много неважных параметров, или для их представления не требуется слишком высокая точность.
Следовательно, квантование модели — это процесс преобразования весов, значений активации и т. д. обученной глубокой нейронной сети из высокой точности в низкую точность. Например, преобразование 32-битного числа с плавающей запятой в 8-битное целое число int8 и мы ожидаем, что после преобразования точность модели аналогична точности до преобразования.
2. Каковы преимущества количественной оценки модели?
- Уменьшите объем памяти и хранилища. Можно сказать, что эффект «похудения» от количественной оценки на модели является немедленным. Преимущества, которые она дает, двояки: во-первых, она уменьшает объем памяти. Мы знаем, что во многих случаях узкое место производительности рассуждений заключается не в вычислениях, а в доступе к памяти. В этом случае увеличение плотности вычислений окажет существенное оптимизационное влияние на затраты времени, во-вторых, экономит место на диске, уменьшает размер приложения; и облегчает обновление обновлений программного обеспечения.
- Уменьшите энергопотребление. Мы знаем, что энергопотребление в основном состоит из двух частей: вычислений и доступа к памяти. С одной стороны, если взять в качестве примера операции умножения и сложения, существует разница в энергопотреблении между 8-битным целым числом и 32-битным числом с плавающей запятой на порядок. С другой стороны, доступ к памяти является большим потребителем энергии. Если предположить, что модели, которые можно разместить только в DRAM, можно будет после квантования поместить в SRAM, это не только улучшит производительность, но и снизит энергопотребление, что просто идеально.
- Улучшите скорость вычислений. Многие инструкции процессора по целочисленным вычислениям более эффективны, чем соответствующие вычисления с плавающей запятой. Если взять в качестве примера ЦП, то задержка инструкций операций с плавающей запятой в среднем больше, чем задержка соответствующих инструкций целочисленных операций.
Таким образом, в отрасли существует очень большой спрос на количественную оценку моделей.
3. Что является объектом количественного определения?
Вообще говоря, какие данные модели будут иметь количественную оценку. В основном это следующие три. На практике возможно количественное определение многих или даже всех из них.
- Вес: Количественное определение веса является наиболее традиционным и распространенным. Квантование веса может уменьшить размер модели, объем памяти и пространство.
- Активация (выходные данные функции активации). На практике на активацию часто приходится большая часть использования памяти, поэтому количественная оценка активации может не только значительно сократить использование памяти. Что еще более важно, в сочетании с весовым квантованием целочисленные вычисления могут быть полностью использованы для повышения производительности.
- Градиент немного менее популярен, чем два предыдущих, поскольку в основном используется для обучения. Его основная функция — уменьшить накладные расходы на связь при распределенных вычислениях. Он также может уменьшить обратные накладные расходы во время автономного обучения.
4. Количество цифр для количественной оценки
Большинство научных операций вычисляются с использованием типов с плавающей запятой. Наиболее распространенными являются 32-битный тип с плавающей запятой и 64-битный тип с плавающей запятой, а именно float32 и double64.
Существует множество вариантов количества битов квантования. Условно его можно разделить на несколько категорий:
- 16 бит
- 8-битная версия является наиболее распространенной и относительно зрелой. Поддерживаются различные основные платформы и оборудование.
- В настоящее время в академическом сообществе относительно больше развлечений для детей младше 8 лет, и существует небольшая поддержка со стороны отрасли, но она еще не слишком зрелая. Ниже 8 битов в основном находятся 4, 2 и 1 бит (поскольку производительность выше и ее легче реализовать, когда количество бит равно степени 2). Если точность составляет всего 1 цифру, то есть бинаризация, ее можно вычислить с помощью битовых операций. Это очень удобно для процессора.
5. Количественная классификация
Квантование в основном делится на автономное квантование: (квантование после обучения, PTQ) и обучение с учетом квантования (QAT). В статье 2019 года компания Qualcomm определила четыре уровня для моделей количественной оценки производства: как правило, мы чаще всего используем уровень 2 и уровень 3.
- Уровень 1: Нет данных в автономном режиме, нет данных, нет обратного распространения ошибки, один вызов API для завершения создания количественной модели.
- Уровень 2: Есть данные для автономной количественной оценки. Требуются данные, и обратное распространение ошибки не требуется. Данные используются для калибровки BN, или для уменьшения количества речи используется статистическое распределение значений активации. ошибка
- Уровень 3: Обучение с учетом количественных показателей требует данных и обратного распространения ошибки. Достижение приемлемой точности квантованной модели посредством обучения и тонкой настройки обычно требует полного процесса обучения и настройки гиперпараметров.
- Уровень 4: Обучение с учетом количественных показателей, которое изменяет структуру сети, требует данных, обратного распространения ошибки и корректировки сетевой структуры. Требуется значительно больше времени на обучение и тщательная настройка гиперпараметров.
6. Каковы формы количественной оценки модели?
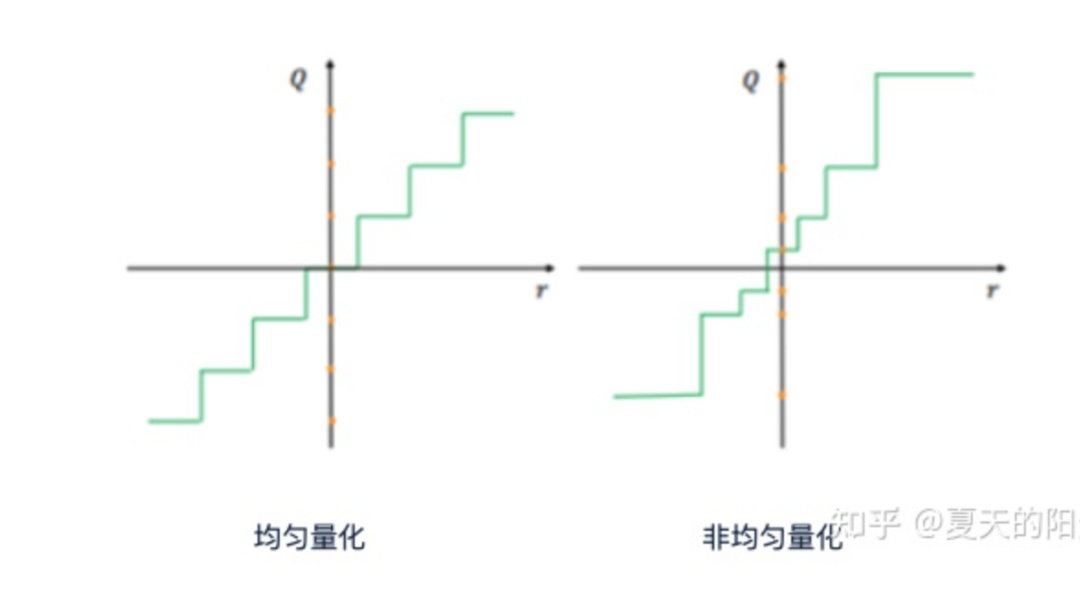
Как показано на рисунке ниже, квантование можно разделить на равномерное и неравномерное квантование.
- равномерное квантование:
- Бинаризация использует 1 бит для квантования.
- Линейное квантование (симметричное, асимметричное, Ристретто)
- 非равномерное квантование
- Количественная оценка журнала
- другой
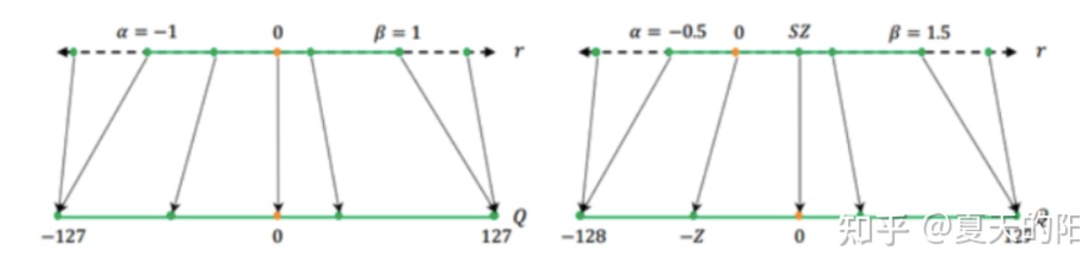
Как показано на рисунке ниже, квантование также можно разделить на симметричное квантование и асимметричное квантование. Если значение нулевой точки остается неизменным до и после квантования, это называется симметричным квантованием. Однако в реальном процессе квантованные объекты распределены неравномерно и не обязательно симметричны по обе стороны от значения нулевой точки. Как показано в правой части рисунка ниже, значение нулевой точки до и после квантования различно. , которое называется асимметричным квантованием.
7. Процесс количественной оценки модели
Как видно из приведенного выше введения, квантование на самом деле представляет собой процесс преобразования весов, значений активации и т. д. обученной глубокой нейронной сети из высокой точности в низкую точность и обеспечения того, чтобы точность не уменьшалась. Как переключиться с высокой точности на низкую? Установите взаимосвязь сопоставления данных между данными с фиксированной и плавающей запятой, аппроксимируйте непрерывное значение сигнала до конечного числа дискретных значений и добейтесь лучших преимуществ с меньшей потерей точности. Этот процесс отображения обычно выражается следующей формулой:
Q = round(scale factor * clip(x,α,β))+ zero point
В этой формуле: x представляет число, которое необходимо определить количественно, то есть объект квантования, который представляет собой данные с плавающей запятой. Q представляет собой квантованное число, которое представляет собой целочисленные данные. Формула включает в себя три операции: операцию округления, операцию обрезки и выбор масштабного коэффициента. А значения α и β, которые необходимо определить, являются верхней и нижней границей операции отсечения, называемой значением отсечения.
Нулевая точка представляет собой квантованное значение 0 в исходном диапазоне значений. В весе или активации будет много нулей (например, при заполнении или через ReLU), поэтому при квантовании нам нужно обеспечить точное представление действительного числа 0 после квантования.
Операция округления: на самом деле это отношение отображения, которое определяет, как сопоставить исходное значение с плавающей запятой с целочисленным значением в соответствии с определенными правилами. Например, мы можем выбрать принцип округления «при условии, что 5,4 имеет значение 5, а 5,5 — значение 6», или мы можем выбрать ближайшую левую вершину «5,4 и 5,5 имеют значение 5» или ближайшую правую вершину. принцип и т. д.
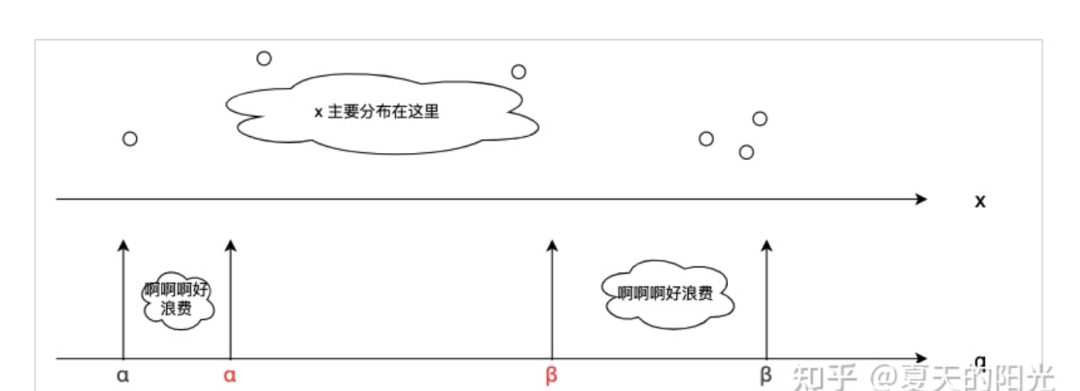
Операция обрезки: на самом деле это операция разрезания. Как выбрать диапазон этого количественного объекта. Почему нам следует выбирать этот диапазон? Потому что после квантования до n цифр квантованное целое значение, которое можно использовать для выражения, является фиксированным. Как нам лучше сопоставить исходную плавающую точку с такими ограниченными данными? распределение стоимости? Этот диапазон слишком велик (выбирайте по исходным максимальным и минимальным значениям, как показано на рисунке ниже. В этот раз, если в начале и в хвосте всего несколько значений с плавающей запятой, и они очень далеки). вдали от других значений (если в это время происходит равномерное квантование). Тогда дискретные значения α-α, β-β на рисунке могут быть потрачены впустую, поэтому ошибка, вызванная отображением значений с плавающей запятой к целочисленным значениямможет быть очень большим. Это значение — искусство. Если оно слишком велико, оно тратит биты. Если оно слишком мало, оно «вырежет» слишком много полезной информации.
Следовательно, различные текущие алгоритмы квантования и стратегии оптимизации часто ищут подходящее [α, β], чтобы уменьшить ошибки, вызванные операциями обрезки и округления.
Масштабный коэффициент: выражает пропорциональную связь между числами с плавающей запятой и целыми числами [разные формы квантования принимают разные значения]. Если это линейное равномерное квантование, то тогда

Подводя итог, можно сказать, что процесс квантования заключается в выборе соответствующих параметров квантования (таких как коэффициент масштабирования, нулевая точка, значение ограничения) и методов отображения данных, чтобы после того, как исходное значение с плавающей запятой преобразуется в целочисленное значение, попытайтесь сохранить точность от снижения (или, когда это возможно, дальность контроля).
8. Количественная детализация модели
В соответствии с различными диапазонами выбора параметров квантования модели степень детализации количественного анализа модели можно разделить на:
- Канальное квантование (по оси/на канал): существуют отдельные параметры квантования для одной оси тензора. Например, поканальное означает, что каждый канал веса использует отдельные параметры квантования. Обычно точность квантования для каждого канала часто лучше, чем для каждого тензора, из-за более тонкой детализации квантования и более высокой степени свободы в параметрах квантования.
- Квантование слоев (по тензору/по слоям): каждый тензор имеет отдельные параметры квантования. Для сверточных или полностью связанных слоев это означает независимые параметры квантования для каждого слоя.
- Глобальный: то есть вся сеть использует одни и те же параметры квантования. Вообще говоря, для 8-битного квантования влияние глобальных параметров квантования не очевидно, но при более низкой точности оно будет иметь большее влияние на точность.
8. Каковы проблемы количественной оценки?
1. Трудности с несколькими бэкэндами
Реализация алгоритмов квантования на разных процессорах имеет разные характеристики. Для разного оборудования пользователям необходимо изучить разные схемы квантования оборудования. Это также приводит к ограниченному аппаратному обобщению схемы квантования. Так называемая аппаратная генерализация в основном относится к возможности миграции количественных моделей на общеаппаратные платформы.
2. Трудности аппаратного черного ящика
Количественное развертывание моделей часто сопровождается сложными работами по восстановлению точности модели, особенно при использовании стороннего оборудования, что требует решения проблемы его согласования со сторонним оборудованием. Однако в реальном процессе обслуживания решение по аппаратному выравниванию на битовом уровне является высшим приоритетом для развертывания услуг. Предоставляя среду моделирования для алгоритма квантования, алгоритм точного восстановления можно воспроизвести на аппаратном уровне. Общие аппаратные различия в основном возникают из-за обработки квантования невычислительных операторов (Concat, Eltwise), методов повторной выборки и округления аккумулятора.
3. Трудности количественного анализа ошибок
Квантование приведет к ошибкам в процессе вычислений, в результате чего точность развертывания сети потеряет некоторое выражение по сравнению с FP32. В реальном бизнесе основная проблема при развертывании заключается в том, как обеспечить точность количественной модели и обеспечить баланс между скоростью и точностью модели за счет уменьшения ошибок.
9. Введение в методы количественной оценки моделей.
1. Как найти лучший метод сопоставления данных
Самый простой и грубый способ количественной оценки — округление. Методы округления для преобразования плавающей запятой в фиксированную: один — «Округление до ближайшего», то есть округление до ближайшего целого числа, другой — стохастическое округление, то есть с определенной вероятностью (пропорциональной расстоянию от точки округления вниз); ), чтобы определить, следует ли округлять вверх или вниз.
Обычно используемый алгоритм таков:
2. Учитывая обученную модель квантования, как найти оптимальные гиперпараметры квантования
Решение проблемы следующее: учитывая тензор, найдите подходящее [α,β], чтобы ошибки, вызванные операциями обрезки и округления, были меньше.
После обучения модели PyTorch статическое квантование, сохранение и загрузка модели квантования int8.
1. Метод количественной оценки модели PyTorch
Существует множество ссылок по внедрению методов количественной оценки модели Pytorch. Вот две рекомендуемые статьи, которые очень подробны и могут дать вам общую информацию.
Количественная оценка в Pytorch
https://zhuanlan.zhihu.com/p/299108528
Официальный количественный документ
https://pytorch.org/docs/stable/quantization.html#common-errors
Количественная оценка в Pytorch условно делится на три типа: динамическое квантование после обучения модели, статическое квантование после обучения модели и квантование, включенное во время обучения модели. Эта статья начинается с инженерного проекта (Pose. Estimation) представляет процесс статического квантования после обучения модели.
Конкретные количественные знания можно получить из двух рекомендуемых статей.
2. Подготовка к количественному процессу.
Среда выполнения кода: PyTorch1.9.0, Python3.6.4.
1. Загрузите набор данных (при выполнении статического количественного анализа вам необходимо вывести набор данных для получения характеристик распределения и калибровки данных), используйте набор проверки MSCOCO и выберите около 100 MSCOCO_val2017.
http://images.cocodataset.org/zips/val2017.zip
2. Файл модели Pytorch можно скачать здесь. Пароль для извлечения Pose_Model: s7qh.
https://pan.baidu.com/s/1nvml9pB
3. Загрузка кода квантования Pytorch_Model_Quantization
https://github.com/Laicheng0830/Pytorch_Model_Quantization
После загрузки кода, как показано выше, выберите 100 изображений из загруженного набора данных MSCOC и поместите их в каталог данных, а загруженный файл модели coco_pose_iter_440000.pth.tar поместите в каталог моделей.
pth_to_int.py преобразует модель float32 Pytorch в модель int8.
Загрузите модель int8 в Assessment_model.py для вывода.
3. Статическая количественная оценка модели
Основной код статической количественной оценки модели выглядит следующим образом. Прочтите модель float32, затем преобразуйте ее в модель int8 и сохраните как openpose_vgg_quant.pth. Полный код можно увидеть в файле pth_to_int.py. Что делает каждый шаг, подробно объясняется в комментариях.

4. Количественная загрузка модели для вывода
Примечание. Прямой код квантованной модели был немного изменен, и квантование и деквантование необходимо вставлять до и после ввода модели. Пример:

Квантование и деквантование можно увидеть в строках 34–86 файлаpose_estimation.py.
Загрузка модели int8 не может быть такой же, как предыдущая загрузка модели float32. Модель необходимо преобразовать в количественную модель с помощью операций подготовки() и преобразования(), а затем в модель загружается load_state_dict.

5. Производительность
На рисунке ниже показаны результаты после количественного определения.,общий损失不大。где размер модели200M->50M,Время работы модели5.7s->3.4s。общий,Размер модели сжат до 1/4 от исходного размера., Время работы модели сокращается примерно на 20%




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
