Старшие эксперты крупнейших интернет-компаний знакомят с основами распределенного обучения
Автор этой статьи, г-н Муму, является старшим экспертом по исследованиям и разработкам в Meituan. Он опубликовал ее в Internet Things.
Ссылка на босса: https://www.zhihu.com/people/mu-mu-67-87-35
1 Обзор
Основная архитектура, используемая в архитектуре кластеров распределенных обучающих серверов, в настоящее время разделена на две основные распределенные архитектуры:
- Сервер параметров (ParameterServer), называемый PS
- Децентрализованная сеть
Распределенное обучение обычно выполняется в вычислительном кластере, где каждый узел кластера выполняет часть вычислений. Конечно, разные узлы будут иметь совместное использование данных и зависимости, и данные необходимо передавать на разные узлы. Это приводит к возникновению концепции распределенной связи.
- Коллективное общение: общение внутри группы узлов.
- Метод связи «точка-точка» (Point to point comunication, P2P): связь между двумя узлами
Поскольку процесс обучения глубокому обучению включает в себя большое количество весовых параметров сетевой модели и временных переменных, генерируемых в процессе обучения, в основном используется коллективное общение, поэтому мы можем понять, что в основном используется режим коллективного общения в архитектуре PS; распределенное обучение больших моделей, поскольку меньше необходимости в унифицированных обновлениях с одноточечными серверами параметров, более непосредственно используется чистый режим коллективной связи.
В рамках глубокого обучения примитивы связи и методы реализации связи распределенного обучения играют очень важную роль в распределенном обучении среды искусственного интеллекта. Если вы хотите обучить большую модель (базовую модель), общение определенно необходимо.
2 примитива связи
Установленная связь содержит несколько отправителей и несколько получателей. Общие примитивы связи включают широковещательную рассылку, сбор, сбор всех, разброс, сокращение, сокращение всех, сокращение-рассеяние, все-ко-всем и другие операции связи для передачи данных.
Предположим, у нас теперь есть сервер, интегрированный с 4 тренировочными картами:
2.1 Broadcast
При коллективной связи, если узел хочет отправить свои собственные данные другим узлам кластера, он может использовать операцию широковещания.
Как показано на рисунке, кружки представляют собой независимые узлы в распределенной системе. Всего имеется 4 узла. Маленькие квадраты представляют собой одни и те же данные. Broadcast представляет собой поведение широковещательной рассылки. При выполнении Broadcast данные передаются от главного узла 0 к каждому другому указанному узлу (0 ~ 3).
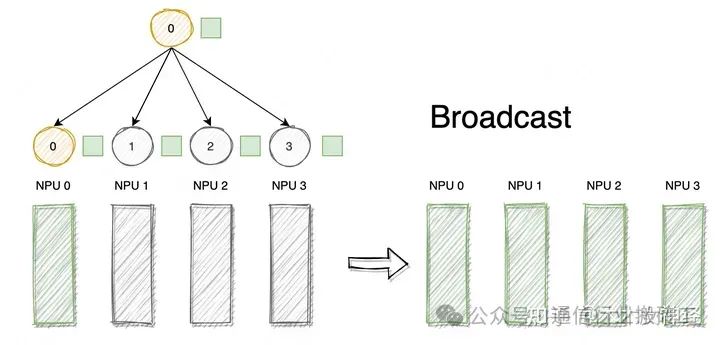
Широковещательная передача — это синхронизация данных «один ко многим». Она синхронизирует данные на одной карте XPU со всеми другими картами XPU. Сценарии ее применения включают:
1) Инициализация параметров параллельного обмена данными, чтобы гарантировать согласованность исходных параметров на каждой карте;
2) Операция трансляции в комбинации «трансляция + сокращение» в allReduce;
3) Сервер параметров распределенного обучения. Главный узел в структуре сервера параметров передает данные рабочему узлу, а затем преобразует данные из рабочего узла обратно в операцию широковещательной передачи в главном узле;
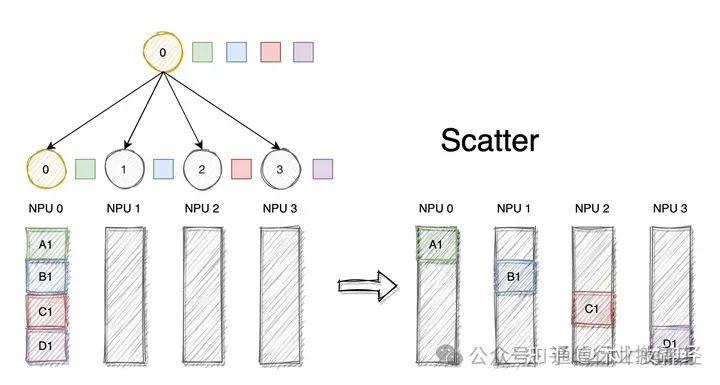
2.2 Scatter
Как и Broadcast, Scatter также является примитивом связи «один ко многим». Он также является отправителем данных и несколькими получателями данных. Он может распространять данные одного узла на другие узлы кластера. Отличие от Broadcast заключается в том, что Broadcast отправляет данные главного узла 0 на все узлы, а Scatter разрезает данные и затем распределяет их по всем узлам кластера, как показано на рисунке ниже, маленькие квадраты разных цветов представляют разные данные. Главный узел 0 делит данные на четыре части и распределяет их по узлам 0-3.
2.3 Reduce
Сокращение называется операцией сокращения, что является общим термином для ряда простых операций. Его подразделение может включать в себя: SUM, MIN, MAX, PROD, LOR и другие типы операций сокращения. Уменьшить означает сокращение/упрощение, поскольку его операция получает массив входных элементов на каждом узле, и после выполнения операции он будет уменьшен до меньшего количества элементов. Ниже в качестве примера используется функция «Уменьшить сумму».
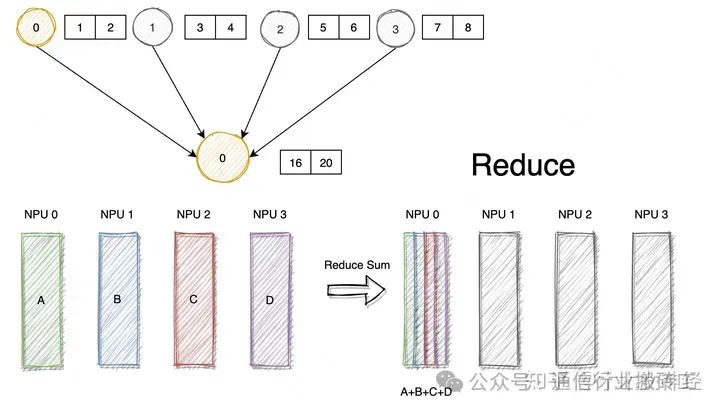
Уменьшение в NCCL получает данные от нескольких отправителей и, наконец, объединяет их в один узел.
2.4 All Reduce
Уменьшение — это собирательное название для серии простых операций, а вариант «Все сокращение» применяет одну и ту же операцию «Уменьшение» на всех узлах. В качестве примера возьмем все сокращения суммы.
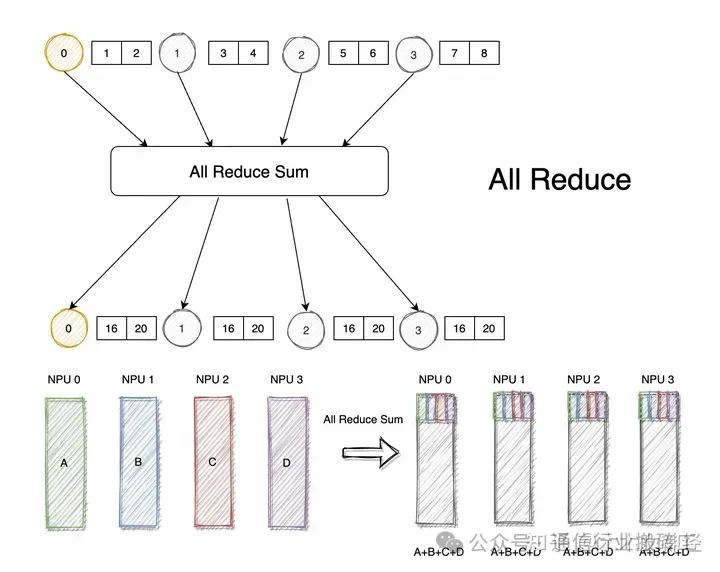
Все операции сокращения можно выполнить с помощью операций сокращения + широковещания на одном узле. В All Discount в NCCL данные принимаются от нескольких отправителей и, наконец, объединяются и распределяются по каждому узлу.
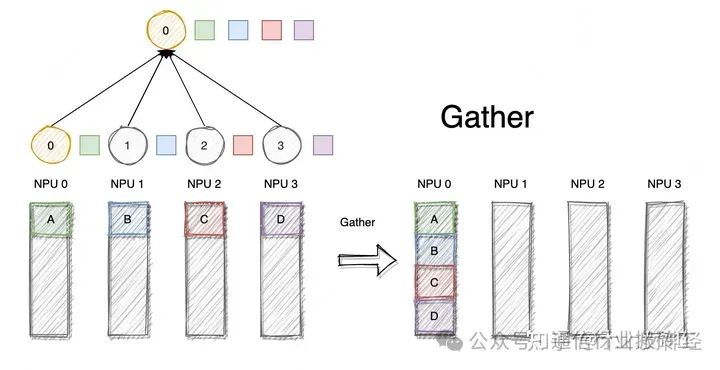
2.5 Gather
Все операции сокращения можно выполнить с помощью операций сокращения + широковещания на одном узле. В All Discount в NCCL данные принимаются от нескольких отправителей и, наконец, объединяются и распределяются по каждому узлу.
2.6 All Gather
Во многих случаях также полезно отправлять несколько элементов на несколько узлов, то есть в сценариях режима связи «многие ко многим». В это время требуется операция All Gather.
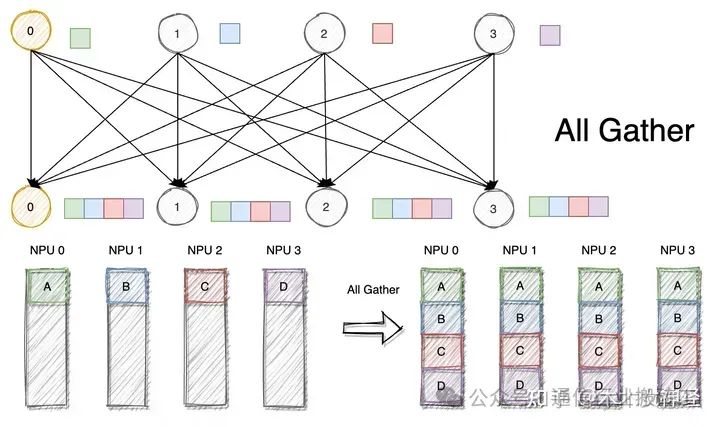
Для набора данных, распределенных по всем узлам, All Gather собирает все данные по всем узлам. С самой базовой точки зрения All Gather эквивалентен операции Gather, за которой следует операция Broadcast.
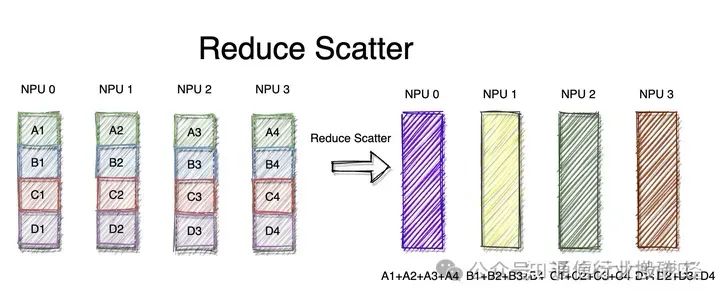
2.7 Reduce Scatter
Операция уменьшения разброса сначала суммирует входные данные каждого узла, затем разделяет их в соответствии с количеством карт в 0-м измерении и распределяет данные по соответствующим картам. Например, как показано на рисунке выше, входные данные каждой карты представляют собой тензор 4x1. Функция уменьшения разброса сначала суммирует входные данные, чтобы получить тензор [0, 4, 8, 12], а затем распределяет их, получая тензор размера 1x1 для каждой карты. Например, выходной результат, соответствующий карте 0, — [[0.0]], а выходной результат, соответствующий карте 1, — [[4.0]].
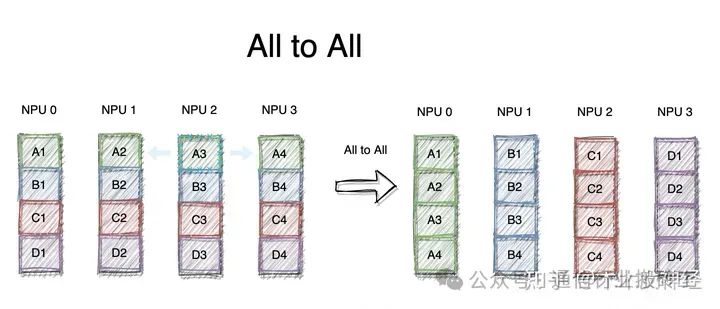
2.8 All to All
«Все ко всем» — это операция полного обмена. Благодаря связи «Все ко всем» каждый узел может получить ценность других узлов.
При использовании «Все ко всем» каждый узел отправит сообщение любому узлу, и каждый узел также получит сообщение от любого узла. Буфер приема и буфер отправки каждого узла представляют собой массив, разделенный на несколько блоков данных. Конкретная операция «Все ко всем» заключается в следующем: отправка j-го блока данных в буфере отправки узла i узлу j, а узел j помещает полученный блок данных из узла i в позицию i-го блока своего собственного приема. буфер.
При сравнении «Все ко всем» с «Всем сбором» разница состоит в том, что при операции «Всего сбора» данные, собранные разными узлами из определенного узла, совершенно одинаковы, тогда как в операции «Все ко всем» данные, собранные разными узлами из определенного узла, другой. В буфере отправки каждого узла для каждого узла подготавливается отдельный фрагмент данных.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
