Сравнение методов количественной оценки больших языковых моделей: GPTQ, GGUF, AWQ.
в прошлом году,Модель большого языка (llm) быстро развивалась.,в этой статье,Мы рассмотрим несколько способов,Помимо этого,Также будут представлены шардинг и различные стратегии сбережений и сжатия.
Примечание. После каждой загрузки примеров LLM рекомендуется очищать кеш, чтобы предотвратить ошибки OutOfMemory.
del model, tokenizer, pipe
import torch
torch.cuda.empty_cache()Если видеопамять не может быть освобождена в Jupyter, перезагрузите ноутбук Jupyter.
Загрузка модели
Самый прямой и распространенный способ загрузки LLM — через 🤗Трансформеры. HuggingFace создал комплект, который мы можем использовать напрямую
pip install git+https://github.com/huggingface/transformers.git
pip install accelerate bitsandbytes xformersПосле установки мы можем легко загрузить LLM, используя следующий конвейер:
from torch import bfloat16
from transformers import pipeline
# Load in your LLM without any compression tricks
pipe = pipeline(
"text-generation",
model="HuggingFaceH4/zephyr-7b-beta",
torch_dtype=bfloat16,
device_map="auto"
)В качестве примера мы используем зефир-7b-бета.
Этот метод загрузки LLM обычно не выполняет никаких трюков со сжатием. Давайте приведем пример использования
messages = [
{
"role": "system",
"content": "You are a friendly chatbot.",
},
{
"role": "user",
"content": "Tell me a funny joke about Large Language Models."
},
]
prompt = pipe.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)Подсказки, созданные с использованием внутреннего шаблона подсказок, строятся следующим образом:
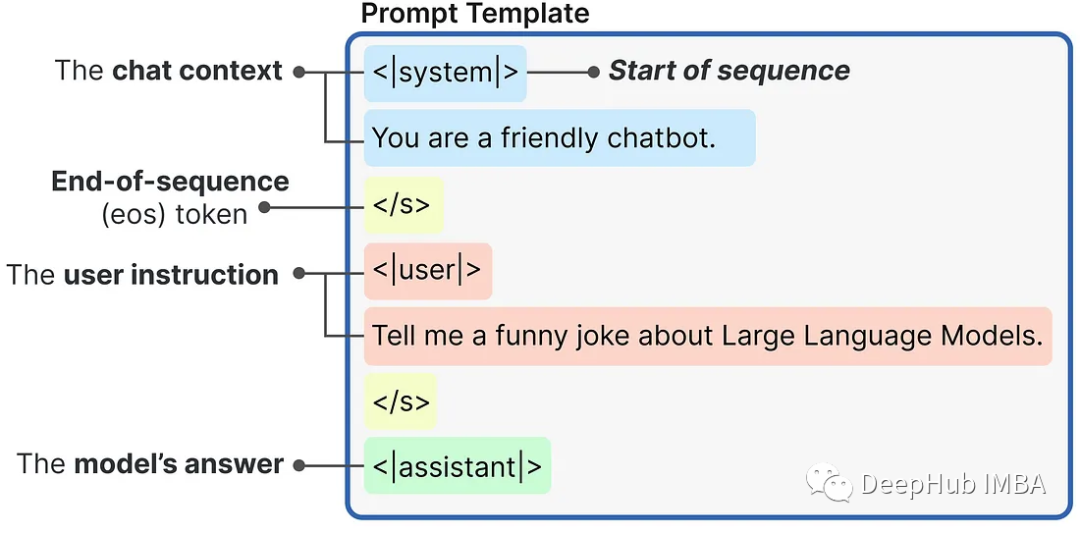
Затем мы можем передать запрос в LLM для генерации ответа:
outputs = pipe(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.1,
top_p=0.95
)
print(outputs[0]["generated_text"])Это самый прямой процесс использования,Но из чистого рассуждения,Этот метод наименее эффективен,Потому что нет никакого сжатия или Количественной Случай стратегии оценки загружает всю модель.
Шардинг
Прежде чем мы войдем в Количественную До стратегии оценки,Давайте сначала представим внешний метод: Шардинг. Модель можно разделить на небольшие части по Шардингу.,Каждый Шардинг содержит меньшие части Модели.,Обойдите ограничения Памяти графического процессора, распределив вес модели между разными устройствами.
Хотя он не имеет каких-либо сжимающих и количественных свойств, этот метод считается самым простым решением для загрузки больших моделей.
Например, Zephyr-7B-β на самом деле является Шардингом! Если ввести Модель и нажать «Файлы и Версии», то можно увидеть, что модель разделена на 8 частей.
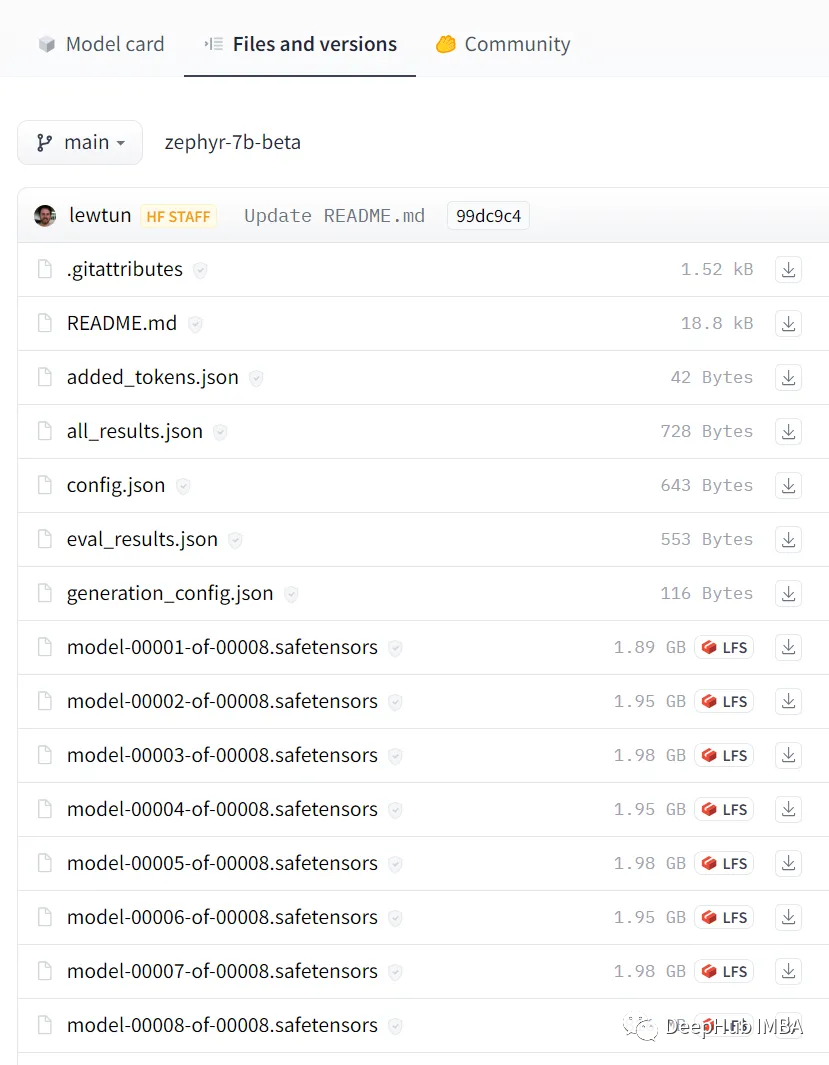
Шардинг модели очень прост и может быть использован непосредственно в Accelerate Сумка:
from accelerate import Accelerator
# Shard our model into pieces of 1GB
accelerator = Accelerator()
accelerator.save_model(
model=pipe.model,
save_directory="/content/model",
max_shard_size="4GB"
)Таким образом Модель делится на 4ГБ Шардинга.

Количественная оценка
Большие языковые модели представлены набором весов и активаций. Эти значения обычно представлены обычным 32-битным типом данных с плавающей запятой (float32).
Количество битов говорит вам, сколько значений оно может представлять. Float32 может представлять значения между 1.18e-38 и 3.4e38, а это довольно много значений! Чем меньше количество битов, тем меньше значений он может представлять.
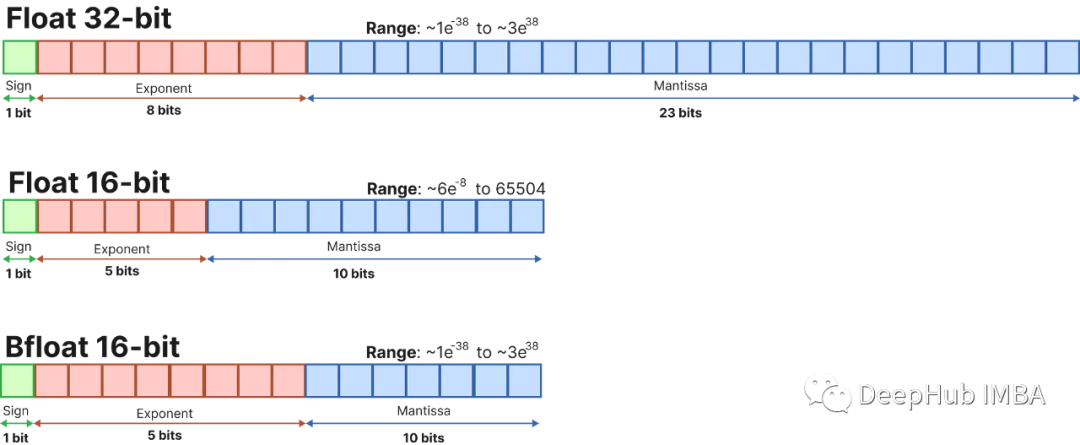
Если мы выберем меньший размер бит, модель станет менее точной, но она будет представлять меньше значений, что уменьшит ее размер и требования к памяти.

Количественная оценка означает преобразование LLM из исходного представления Float32 в меньшее представление. Вместо того, чтобы просто использовать вариант меньшего бита, мы хотим сопоставить представление большего бита с меньшим битом, не теряя при этом слишком много информации.
Обычно для этого мы часто используем новый формат под названием 4bit-NormalFloat (NF4). Этот тип данных выполняет некоторые специальные приемы для эффективного представления типов данных большего размера. Он состоит из трех шагов:
Нормализация: нормализуйте веса модели так, чтобы мы ожидали, что веса попадут в определенный диапазон. Это позволяет более эффективно представлять более общие значения.
Количественная оценка:масса Количественная Кредитный код состоит из 4 цифр. В НФ4,Уровни количественной оценки равномерно распределены относительно нормализованных весов.,Таким образом, эффективно представляют исходные 32-битные веса.
идти Количественная Оценка: Хотя веса хранятся в 4 битах, они удаляются во время вычислений. точность, тем самым повышая производительность рассуждений.
Мы можем напрямую использовать библиотеку Bitsandbytes для операций Количественной оценки:
from transformers import BitsAndBytesConfig
from torch import bfloat16
# Our 4-bit configuration to load the LLM with less GPU memory
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 4-bit quantization
bnb_4bit_quant_type='nf4', # Normalized float 4
bnb_4bit_use_double_quant=True, # Second quantization after the first
bnb_4bit_compute_dtype=bfloat16 # Computation type
)Приведенная выше конфигурация определяет используемый уровень Количественной оплаты. Например, 4-битная Количественная оценка представляет вес, а 16-битная используется для вывода.
Тогда загрузка модели в конвейер проста:
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
# Zephyr with BitsAndBytes Configuration
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
model = AutoModelForCausalLM.from_pretrained(
"HuggingFaceH4/zephyr-7b-alpha",
quantization_config=bnb_config,
device_map='auto',
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')Далее используйте те же советы, что и раньше:
outputs = pipe(
prompt,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_p=0.95
)
print(outputs[0]["generated_text"])Количественная оценка — мощный метод,Может снизить спрос на Память из Модели.,Сохраняя производительность на том же уровне. Это позволяет быстрее загружать, использовать и настраивать llm.,Даже с меньшим графическим процессором.
предварительно Количественная оценка(GPTQ、AWQ、GGUF)
Мы исследовали Шардинг и Количественную оценкатехнология。но Количественная Оценка выполняется каждый раз при загрузке модели. Это очень трудоемкая операция. Есть ли способ сохранить Количественную напрямую? Модель после загрузки и загружаете ее непосредственно при использовании?
TheBloke — пользователь HuggingFace.,Он выполняет для нас ряд операций Количественной оценки.,Я думаю, что люди, которые использовали Модель, должны быть с ней хорошо знакомы.
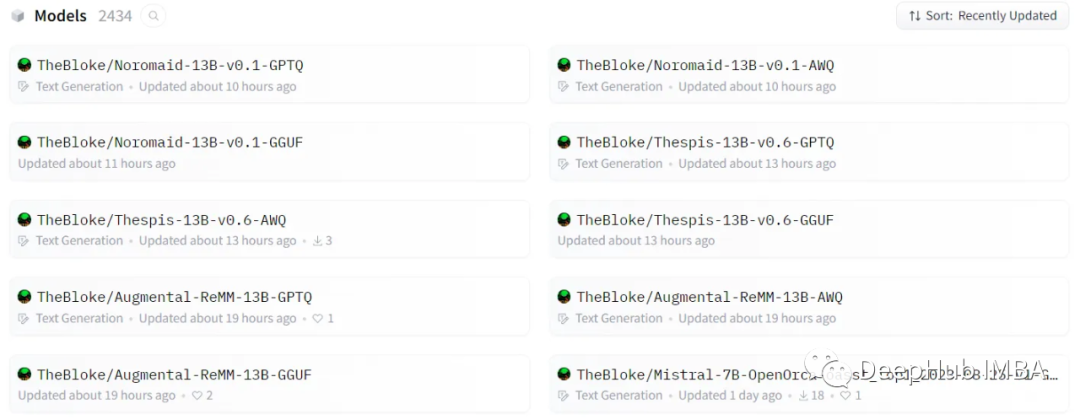
Эти Количественные модели оценок содержат множество форматов GPTQ, GGUF и AWQ, давайте их представим.
1、GPTQ: Post-Training Quantization for GPT Models
GPTQэто своего рода4Кусочек Количественная оценкапосле тренировки Количественная оценка(PTQ)метод,основнойсосредоточиться наGPUсумма рассужденийпроизводительность。
Идея этого подхода заключается в,Попробуйте уменьшить все веса до 4 бит, минимизировав среднеквадратическую ошибку этого веса. в процессе рассуждения,Он будет динамически менять свой вес на float16.,улучшитьпроизводительность,Также держите Память на низком уровне.
Нам нужно загрузить модель класса gptq в HuggingFace Transformers:
pip install optimum
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/Затем найдите модель, которую необходимо загрузить, например «TheBloke/zephyr-7B-beta-GPTQ», и загрузите ее.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# Load LLM and Tokenizer
model_id = "TheBloke/zephyr-7B-beta-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
trust_remote_code=False,
revision="main"
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')Хотя мы установили некоторые дополнительные зависимости, мы можем использовать тот же конвейер, что и раньше, а это значит, что никаких модификаций кода не требуется, что является большим преимуществом использования GPTQ.
GPTQ — наиболее часто используемый метод сжатия, поскольку он оптимизирован для использования графического процессора. Но если ваш графический процессор не может справиться с такой большой моделью, определенно стоит переключиться на подход, ориентированный на ЦП, такой как GGUF, начиная с GPTQ.
2、GPT-Generated Unified Format
Хотя GPTQ отлично справляется со сжатием, если у вас нет оборудования для его запуска, вам придется использовать другие методы.
GGUF (ранее GGML) — Количественная оценкаметод,Позволяет пользователям использовать ЦП для запуска LLM.,Но некоторые из его слоев также можно загрузить в графический процессор для увеличения скорости.
Хотя использование ЦП для вывода обычно медленнее, чем использование графического процессора, это очень хороший формат для тех, кто запускает модели на ЦП или устройстве Apple.
Использовать GGUF очень просто, сначала нам нужно установить ctransformersСумка:
pip install ctransformers[cuda]Затем загрузите модель "TheBloke/zephyr-7B-beta-GGUF",
from ctransformers import AutoModelForCausalLM
from transformers import AutoTokenizer, pipeline
# Load LLM and Tokenizer
# Use `gpu_layers` to specify how many layers will be offloaded to the GPU.
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/zephyr-7B-beta-GGUF",
model_file="zephyr-7b-beta.Q4_K_M.gguf",
model_type="mistral", gpu_layers=50, hf=True
)
tokenizer = AutoTokenizer.from_pretrained(
"HuggingFaceH4/zephyr-7b-beta", use_fast=True
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')После загрузки модели мы можем запустить следующую подсказку:
outputs = pipe(prompt, max_new_tokens=256)
print(outputs[0]["generated_text"])GGUF — очень хороший формат, если вы хотите использовать преимущества как процессора, так и графического процессора.
3、AWQ: Activation-aware Weight Quantization
В дополнение к двум вышеперечисленным, новый формат — AWQ (вес активации с учетом Количественной Оценка), которая является Количественной, аналогичной GPTQ. метод оценки. Существует несколько различий между AWQ и GPTQ как методами, но наиболее важным из них является то, что AWQ предполагает, что не все веса одинаково важны для производительности LLM.
То есть в Количественной Небольшая часть весов пропускается в процессе оценки, что помогает упростить Количественную оценку. потеря рейтинга. В их статье упоминается, что по сравнению с GPTQ его можно значительно ускорить за счет,сохраняя при этом аналогичные,Иногда даже лучшая производительность.
Этот метод все еще относительно нов и еще не принят в масштабах GPTQ и GGUF.
Для AWQ мы будем использовать vLLMСумку:
pip install vllmМодели можно загружать напрямую с помощью vLLM:
from vllm import LLM, SamplingParams
# Load the LLM
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=256)
llm = LLM(
model="TheBloke/zephyr-7B-beta-AWQ",
quantization='awq',
dtype='half',
gpu_memory_utilization=.95,
max_model_len=4096
)Затем используйте .generate для запуска модели:
output = llm.generate(prompt, sampling_params)
print(output[0].outputs[0].text)Вот и все
Место:Мартен Гроотендорст
Если вам это нравится, пожалуйста, подпишитесь на него:
Нажмите заглянуть Ты самый красивый!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
