Сравнение LangChain и LlamaIndex через 4 задачи
Нажмите «Deephub» выше. «Имба», подписывайтесь на паблик-аккаунт и не пропустите хорошие статьи. !
Когда мы используем большие модели локально, особенно при создании приложений RAG, обычно можно использовать две зрелые платформы.
- LangChain: Универсальный инструмент для разработки LLM.
- LlamaIndex: рамка, специально используемая для создания систем RAG.

Выбор фреймворка очень важен для последующей разработки проекта, потому что потом очень сложно изменить фреймворк, поэтому мы проведем здесь простое сравнение двух фреймворков, чтобы иметь предварительное впечатление о выборе.
Во-первых, давайте посмотрим на их производительность на Github и некоторую общедоступную информацию:
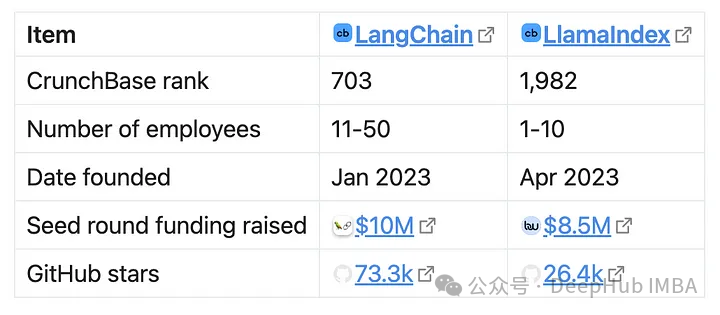
Если посмотреть на финансовую ситуацию, то масштаб финансирования LlamaIndex близок к LangChain, хотя их целевой рынок намного меньше. Это может указывать на то, что у LlamaIndex больше шансов на выживание, поскольку средств относительно много. Но LangChain предлагает более ориентированные на предприятие и приносящие доход продукты (LangServe, LangSmith), поэтому, возможно, доход LangChain выше, поэтому кажется, что LangChain будет лучше. .
Вышеуказанное представляет собой наш случайный анализ корпоративных фондов только для справки. Перейдем к делу. В этой статье я буду использовать два фреймворка для параллельного выполнения некоторых основных задач. Я надеюсь, что демонстрация этих фрагментов кода рядом друг с другом поможет вам сделать выбор.
1. Создайте чат-бота, используя локальный LLM.
Первая задача — сделать чат-бота и использовать локальный LLM.
Несмотря на то, что он является локальным, мы позволяем LLM работать на независимом сервере вывода, чтобы избежать повторного использования. Две платформы могут напрямую использовать один и тот же сервис. Хотя API вывода LLM имеет несколько режимов, здесь мы выбираем режим, совместимый с OpenAI, чтобы при переключении на модель OpenAI вам не нужно было изменять код.
Ниже приведен метод LlamaIndex:
from llama_index.llms import ChatMessage, OpenAILike
llm = OpenAILike(
api_base="http://localhost:1234/v1",
timeout=600, # secs
api_key="loremIpsum",
is_chat_model=True,
context_window=32768,
)
chat_history = [
ChatMessage(role="system", content="You are a bartender."),
ChatMessage(role="user", content="What do I enjoy drinking?"),
]
output = llm.chat(chat_history)
print(output)Это Лангчейн:
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="http://localhost:1234/v1",
request_timeout=600, # secs, I guess.
openai_api_key="loremIpsum",
max_tokens=32768,
)
chat_history = [
SystemMessage(content="You are a bartender."),
HumanMessage(content="What do I enjoy drinking?"),
]
print(llm(chat_history))Вы можете видеть, что код очень похож:
LangChain различает чат llm (ChatOpenAI) и llm (OpenAI), а LlamaIndex использует для различения параметр is_chat_model в конструкторе.
LlamaIndex различает официальные конечные точки OpenAI и конечные точки, подобные openail, а LangChain определяет, куда отправлять запросы через параметр openai_api_base.
LlamaIndex помечает сообщения чата параметром роли, а LangChain использует отдельный класс.
По сути, между этими двумя фреймворками нет никакой разницы, продолжим.
2. Создайте систему RAG для локальных файлов.
Мы строим простую систему RAG: читаем текст из локальной папки с текстовыми файлами.
Вот код, использующий документ LlamaIndex:
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex
service_context = ServiceContext.from_defaults(
embed_model="local",
llm=llm, # This should be the LLM initialized in the task above.
)
documents = SimpleDirectoryReader(
input_dir="mock_notebook/",
).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
service_context=service_context,
)
engine = index.as_query_engine(
service_context=service_context,
)
output = engine.query("What do I like to drink?")
print(output)С LangChain код становится очень длинным:
from langchain_community.document_loaders import DirectoryLoader
# pip install "unstructured[md]"
loader = DirectoryLoader("mock_notebook/", glob="*.md")
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=FastEmbedEmbeddings())
retriever = vectorstore.as_retriever()
from langchain import hub
# pip install langchainhub
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm # This should be the LLM initialized in the task above.
)
print(rag_chain.invoke("What do I like to drink?"))Эти фрагменты кода ясно иллюстрируют разные уровни абстракции этих двух платформ. LlamaIndex инкапсулирует конвейер RAG с помощью метода, называемого «механизмами запросов», в то время как LangChain требует большего количества внутренних компонентов: включая коннекторы для получения документов, шаблоны подсказок «На основе X, пожалуйста, ответьте Y» и другие. Так называемая «цепочка». (показано в LCEL выше).
Создавая с помощью LangChain, вы должны точно знать, чего хотите. Например, расположение вызова from_documents делает его очень проблематичным для новичков и требует дополнительного обучения.
LlamaIndex можно использовать напрямую, без явного выбора бэкенда векторного хранилища, тогда как LangChain необходимо указывать явно. Это также требует дополнительной информации, поскольку мы не уверены, приняли ли мы осознанное решение при выборе базы данных.
Хотя и LangChain, и LlamaIndex предоставляют облачные сервисы, аналогичные Hugging Face (т. е. LangSmith Hub и LlamaHub), LangChain интегрирует их практически во все функции. Мы используем pull только для загрузки короткого текстового шаблона со следующим содержимым:
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don’t know the answer, just say that you don’t know. Use three sentences maximum and keep the answer concise.Question: {question}Context: {context}Answer:**
Это определенно перебор. Хотя это и поощряет обмен советами внутри сообщества, необходимо ли это?
3. Чат-бот, поддерживающий RAG
Мы объединили две вышеупомянутые простые функции, чтобы получить по-настоящему полезное простое приложение, которое может работать с локальными файлами.
Использовать LlamaIndex так же просто, как заменить as_query_engine на as_chat_engine:
engine = index.as_chat_engine()
output = engine.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = engine.chat("How do I brew it?")
print(output) # "You brew coffee with a Aeropress."При использовании LangChain, согласно официальному руководству, давайте сначала определим память (отвечающую за управление записями чата):
# Everything above this line is the same as that of the last task.
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.messages import get_buffer_string
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import format_document
from langchain_core.prompts import ChatPromptTemplate
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)В начале LLM нам необходимо загрузить историю чата из памяти.
load_history_from_memory = RunnableLambda(memory.load_memory_variables) | itemgetter(
"history"
)
load_history_from_memory_and_carry_along = RunnablePassthrough.assign(
chat_history=load_history_from_memory
)Затем попросите LLM дополнить наши вопросы контекстом.
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)Но мы не можем просто связать их, потому что тема могла измениться во время разговора, в результате чего большая часть семантической информации в стенограмме чата не имеет значения.
Затем просто запустите RAG.
retrieve_documents = {
"docs": itemgetter("standalone_question") | retriever,
"question": itemgetter("standalone_question"),
}Ответьте на вопрос:
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)Когда вы получите окончательный ответ, добавьте его в историю чата.
final_chain = (
load_history_from_memory_and_carry_along
| {"standalone_question": rephrase_the_question}
| retrieve_documents
| compose_the_final_answer
)
# Demo.
inputs = {"question": "What do I like to drink?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You enjoy drinking coffee."
inputs = {"question": "How do I brew it?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You brew coffee with a Aeropress."Это очень сложный процесс,Благодаря этому процессу мы можем многое узнать о том, как создаются приложения на основе llm. В частности, несколько раз вызывали LLM.,Пусть он возьмет на себя разные роли: создатель запросов, человек, который извлекает документы.,Участники беседы. Это очень полезно для обучения,Но разве это немного сложно для приложения?
4、Agent
Конвейер RAG можно рассматривать как инструмент. LLM может получить доступ к нескольким инструментам, таким как поиск, запросы к энциклопедии, прогноз погоды и т. д. Таким образом, чат-бот может отвечать на вопросы о вещах, находящихся за пределами его непосредственного знания.
Инструменты также не обязательно предоставляют информацию, они также могут выполнять другие действия, такие как размещение заказов на покупки, ответы на электронные письма и т. д.
LLM С помощью этих инструментов вам нужно решить, какие инструменты использовать и в каком порядке. Роль LLM, использующая эти инструменты, называется «агентом».
Есть несколько способов обеспечить представительство для LLM. Наиболее универсальным подходом к модели является парадигма ReAct.
Метод использования в LlamaIndex следующий:
from llama_index.tools import ToolMetadata
from llama_index.tools.query_engine import QueryEngineTool
notes_query_engine_tool = QueryEngineTool(
query_engine=notes_query_engine,
metadata=ToolMetadata(
name="look_up_notes",
description="Gives information about the user.",
),
)
from llama_index.agent import ReActAgent
agent = ReActAgent.from_tools(
tools=[notes_query_engine_tool],
llm=llm,
service_context=service_context,
)
output = agent.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = agent.chat("How do I brew it?")
print(output) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."На наш дополнительный вопрос «как мне заварить кофе» агент ответил иначе, чем если бы это был просто механизм запросов. Это связано с тем, что агенты могут сами решать, просматривать ли наши местные заметки. Если они достаточно уверены в себе, чтобы ответить на этот вопрос, агенты могут отказаться от использования каких-либо инструментов. Если LLM обнаружит, что не может ответить на вопрос, он выполнит поиск в наших локальных файлах с помощью RAG (задача нашей системы запросов — найти документы из индекса, поэтому он обязательно выберет это).
Прокси — это API высокого уровня LangChain:
from langchain.agents import AgentExecutor, Tool, create_react_agent
tools = [
Tool(
name="look_up_notes",
func=rag_chain.invoke,
description="Gives information about the user.",
),
]
react_prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, react_prompt)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools)
result = agent_executor.invoke(
{"input": "What do I like to drink?", "chat_history": ""}
)
print(result) # "You enjoy drinking coffee."
result = agent_executor.invoke(
{
"input": "How do I brew it?",
"chat_history": "Human: What do I like to drink?\nAI: You enjoy drinking coffee.",
}
)
print(result) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."Хотя нам по-прежнему необходимо вручную управлять историей чатов, создать прокси гораздо проще, чем создать RAG. create_react_agent и AgentExecutor объединяют большую часть основной работы.
Подвести итог
LlamaIndex и LangChain — это две платформы для создания приложений LLM. LlamaIndex фокусируется на вариантах использования RAG, а LangChain используется более широко. Мы видим, что если это вариант использования, связанный с RAG, LlamaIndex будет намного удобнее и, можно сказать, будет лучшим выбором.
Но если вашему приложению требуются некоторые функции, отличные от RAG, LangChain может быть лучшим выбором.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
