Spring | Практика работы с несколькими источниками данных на основе SpringBoot — использование Seata для реализации глобального управления транзакциями с несколькими источниками данных
введение
в разработке программного обеспечения,Несколько источников данныхПрименение,особенно вМикросервисная архитектураиМодульность бизнесаВ сцене。Несколько источников данных позволяет различным бизнес-модулям и микросервисам иметь независимое хранилище данных, что значительно повышает гибкость и удобство обслуживания системы. В этой статье мы подробно рассмотрим несколько источников данныхиз配置и实施,и вSpring Bootсреда,как пройтиSpring Data JPAиGradleосознать Несколько источников Управление и применение данных.
Несколько источников данных, обсуждаемые в этой статье, относятся к реляционным базам данных, то есть одна служба имеет несколько таких баз данных. 1.1 Необходимость нескольких источников данных
По мере роста и развития бизнеса,Одного источника данных уже недостаточноРазнообразные и сложные потребности бизнеса。Несколько источников данныхПриложение может не только лучше поддерживать развитие бизнеса,также может быть эффективно реализованоИзоляция ресурсови管理,систематически сокращатьСтепень сцепления,提高服务из稳定性и可用性。использовать Несколько источников данные могут иметь следующие преимущества:
- Оптимизация производительности:不同из关系型数据库有各自из优势и特性,Некоторые базы данных более подходятчитатьПолучить операцию,Хотя другие базы данных более подходятПисатьВведите операцию。добавивчитать Писать Распределите нагрузку на разные экземпляры базы данных,Может Оптимизация производительности。
- изоляция данных:в системе,Некоторые данные могут быть более важными,Требуется большая безопасность и надежность; другие данные могут быть менее критичными;,Определенную потерю данных можно допустить. В это время,Храните разные типы данных в разных базах данных,Можно добиться изоляции данных,Удовлетворение различных потребностей в безопасности и надежности данных.
- Изоляция бизнес-логики:в сложных системах,Различные модули или подсистемы могут иметь разные требования к бизнес-логике и обработке данных. Используйте разные базы данных для разных модулей или подсистем.,Может упростить проектирование и обслуживание системы.
1.2 Сценарии применения нескольких источников данных
Бизнес-сценарии нескольких распространенных масштабных проектов таковы:
- финансовая система:финансовая система通常要处理大量из事务数据и报表数据。将事务处理и报表生成分配到不同из数据库МожетОптимизация производительностии简化系统设计。
- Платформа электронной коммерции:Платформа электронной коммерции обычно включает в себя информацию пользователя、Данные заказа、Данные о продукте и другие типы данных。为这些不同类型из数据использовать不同из数据库实例Может实现数据иИзоляция бизнес-логики。
- ERP-система:планирование ресурсов предприятия(ERP)Системы обычно содержат несколько модулей.,Такие как финансы, человеческие ресурсы и управление цепочками поставок. Использование отдельной базы данных для каждого модуля упрощает разработку и обслуживание.
Все следующие примеры загружены на Github. Вы можете загрузить проект локально и запустить его.
Пример Github (если вы еще не знакомы с Gradle),Рекомендуется прочитать мои предыдущие статьи.):gradle-spring-boot-demo
Практическая демонстрация
В этой главе будет подробно описано, как реализовать несколько источников данных в проекте Spring Boot. Мы шаг за шагом продемонстрируем, как настроить два экземпляра базы данных H2 в качестве источников данных.
2.1 Создание класса сущности
первый,Мы создаем два класса сущностей,Один для основного источника данных,один для вторичного источника данных。Мы здесь сUserСущность в качестве примера。Убедитесь, что ваши классы сущностей находятся в правильном пакете.。
// Объект источника основных данных
@Entity
@Data
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
}
// объект вторичного источника данных
@Entity
@Table(name = "orders")
@Data
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String orderNumber;
private Double amount;
}2.2 Настройка источника данных
Следующий,нам нужно быть внутриapplication.ymlНастройте два источника данных в:
spring:
datasource:
primary:
jdbc-url: jdbc:h2:file:./multi-datasource/data/testdb1
driver-class-name: org.h2.Driver
username: sa
password: password
secondary:
jdbc-url: jdbc:h2:file:./multi-datasource/data/testdb2
driver-class-name: org.h2.Driver
username: sa
password: password
h2:
console:
enabled: true
jpa:
hibernate:
ddl-auto: update
show-sql: trueЗдесь мы настроили два экземпляра базы данных H2: один в качестве основного источника данных, а другой — в качестве вторичного источника данных.
2.3 Реализация класса конфигурации источника данных
Для достижения нескольких источников данных,Нам нужно создать два класса конфигурации,PrimaryDataSourceConfigиSecondaryDataSourceConfig,и определено в немDataSource、EntityManagerFactoryиTransactionManagerизbeans。
@Configuration
@EnableJpaRepositories(
basePackages = "org.kfaino.datasource.repository.primary")
@EntityScan(basePackages = {"org.kfaino.datasource.entity.primary"})
public class PrimaryDataSourceConfig {
@Primary
@Bean(name = "primaryDataSource")
@ConfigurationProperties(prefix = "spring.datasource.primary")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Primary
@Bean(name = "entityManagerFactory")
public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(
EntityManagerFactoryBuilder builder,
@Qualifier("primaryDataSource") DataSource dataSource) {
return builder
.dataSource(dataSource)
.packages("org.kfaino.datasource.entity.primary") // Установите путь к пакету класса сущности
.persistenceUnit("primary")
.properties(hibernateProperties())
.build();
}
private Map<String, Object> hibernateProperties() {
Map<String, Object> properties = new HashMap<>();
properties.put("hibernate.hbm2ddl.auto", "update");
properties.put("hibernate.show_sql", true);
return properties;
}
@Primary
@Bean(name = "transactionManager")
public PlatformTransactionManager transactionManager(
@Qualifier("entityManagerFactory") EntityManagerFactory entityManagerFactory) {
return new JpaTransactionManager(entityManagerFactory);
}
}
@Configuration
@EnableJpaRepositories(
basePackages = "org.kfaino.datasource.repository.secondary",
entityManagerFactoryRef = "secondaryEntityManagerFactory",
transactionManagerRef = "secondaryTransactionManager")
@EntityScan(basePackages = {"org.kfaino.datasource.entity.primary"})
public class SecondaryDataSourceConfig {
@Bean(name = "secondaryDataSource")
@ConfigurationProperties(prefix = "spring.datasource.secondary")
public DataSource secondaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean(name = "secondaryEntityManagerFactory")
public LocalContainerEntityManagerFactoryBean secondaryEntityManagerFactory(
EntityManagerFactoryBuilder builder,
@Qualifier("secondaryDataSource") DataSource dataSource) {
return builder
.dataSource(dataSource)
.packages("org.kfaino.datasource.entity.secondary") // Установите путь к пакету класса сущности
.persistenceUnit("secondary")
.properties(hibernateProperties())
.build();
}
private Map<String, Object> hibernateProperties() {
Map<String, Object> properties = new HashMap<>();
properties.put("hibernate.hbm2ddl.auto", "update");
properties.put("hibernate.show_sql", true);
return properties;
}
@Bean(name = "secondaryTransactionManager")
public PlatformTransactionManager secondaryTransactionManager(
@Qualifier("secondaryEntityManagerFactory") EntityManagerFactory secondaryEntityManagerFactory) {
return new JpaTransactionManager(secondaryEntityManagerFactory);
}
}💡 Добрые советы: пожалуйста, обрати внимание,В этом классе конфигурации,Мы определили отдельно для двух источников данныхDataSource、EntityManagerFactoryиTransactionManager。@Primary注解用于指定主数据源相关изbeans。
2.4 Настройка класса репозитория
Нам нужно создать два класса репозитория, каждый из которых работает с объектом источника данных. Здесь мы можем использовать Spring Data JPAизJpaRepositoryинтерфейс。
// Основной источник данных Репозиторий
@Repository
public interface UserRepository extends JpaRepository<User, Long> {}
// Вторичный источник данных Репозиторий
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {}2.5 Эксплуатация и проверка
Запустите приложение Spring Boot, и вы увидите в консоли, что оба источника данных успешно настроены.
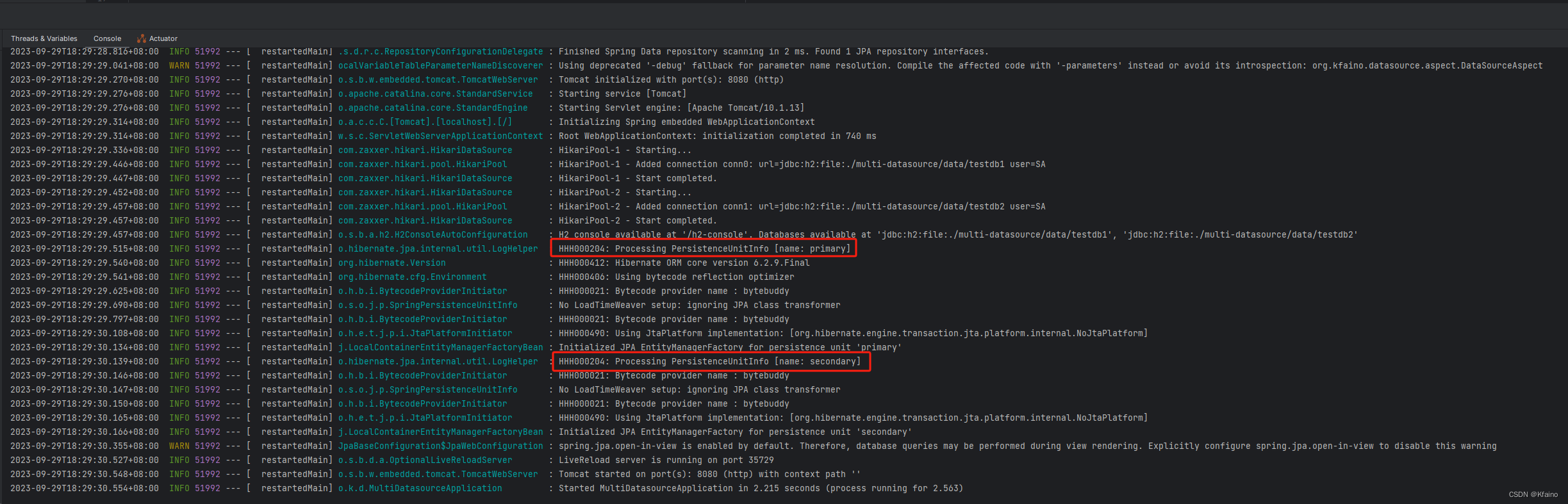
А операции с данными можно выполнять через соответствующий класс Repository. Пишем Контроллер для взаимодействия с базой данных. Из-за ограничений места я опустил другие коды. Если вам нужен полный пример, вы можете скачать его прямо из репозитория GitHub:
@RestController
@RequestMapping("user")
public class UserController {
@Resource
private UserService userService;
@Resource
private OrderService orderService;
@Resource
private UserOrderService userOrderService;
@PostMapping("/createUser")
public User createUser(@Valid @RequestBody UserDTO userDTO) {
return userService.createUser(userDTO);
}
@PostMapping("/createOrder")
public Order createOrder(@Valid @RequestBody OrderDTO orderDTO) {
return orderService.createOrder(orderDTO);
}
@PostMapping("/createMix")
public User createMix(@Valid @RequestBody UserOrderDTO userOrderDTO) {
return userOrderService.createUserAndOrder(userOrderDTO);
}
}Затем выполните эти три запроса:

Были созданы две таблицы из разных источников данных:


💡 Уведомление: При выполнении реальных операций с данными, если требуется специальное управление транзакциямиустройство,МожетсуществоватьServiceкласс илиRepository类上использовать@Transactional(transactionManager = "指定изуправление транзакциямиустройство")указать。
Управление транзакциями и согласованность данных
3.1 Управление транзакциями
существовать Несколько источников данныхсередина,управление транзакциями是至关重要из,Это гарантирует, что наша система поддерживает целостность и согласованность данных при выполнении нескольких операций. Давайте продемонстрируем случай, используя код,我们существоватьUserOrderServiceсередина故意Писатьвстреча Сообщить об ошибкекод:
@Transactional("transactionManager")
public User createUserAndOrder(UserOrderDTO userOrderDTO) {
OrderDTO orderDTO = new OrderDTO();
BeanUtils.copyProperties(userOrderDTO, orderDTO);
orderService.createOrder(orderDTO);
// Сообщить об ошибке
int i = 1/0;
User user = new User();
BeanUtils.copyProperties(userOrderDTO, user);
userRepository.save(user);
return user;
}Мы называем этот метод:
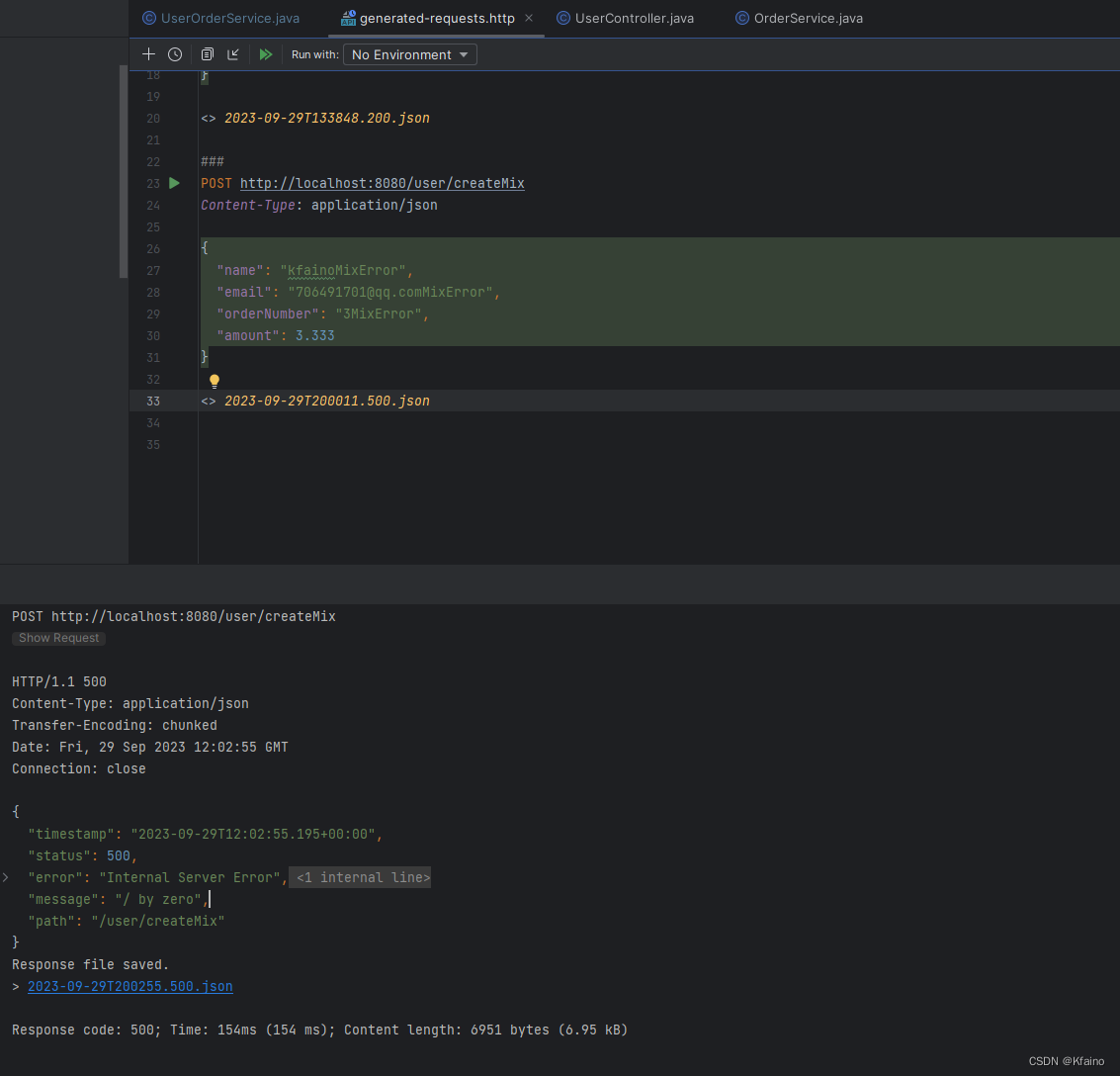


Поскольку использование другого управления транзакциямиустройство,хотяtransactionManagerуправление транзакциямиустройство回滚了,我们依然Может看到ordersтаблица отправлена:

3.2 Используйте Seata для глобального управления транзакциями
💡В этом разделе рассматривается простое управление глобальными транзакциями. Для облегчения демонстрации и тестирования не используется никакое другое промежуточное программное обеспечение, кроме самого Seata.
3.2.1 Установка seata-сервера
Чтобы использовать Seata, вам необходимо сначала Seata-сервер,Путь загрузки следующий:https://github.com/seata/seata/releases Я использую здесь оконную систему, просто скачайте zip-архив:
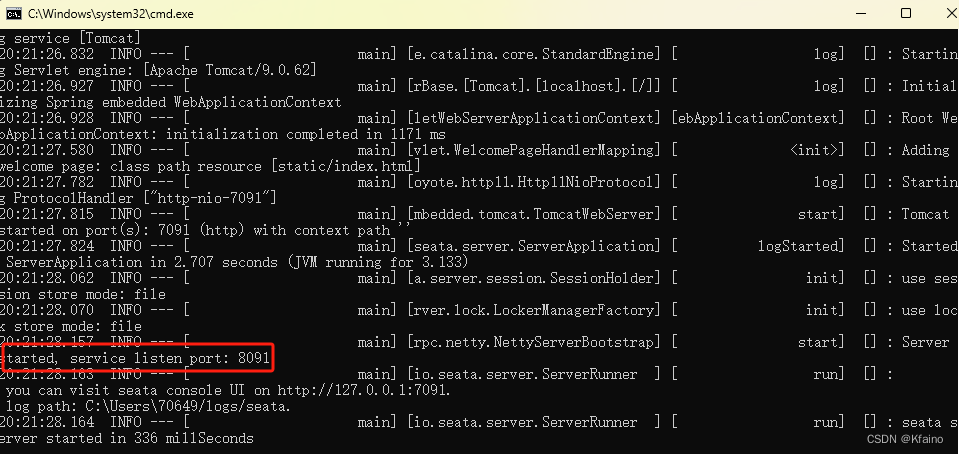
После загрузки дважды щелкните, чтобы запустить:
В консоли видно, что сеата запускается нормально:
3.2.2 Настройка IDEA
- Представьте зависимость от Seata. Я использую gradle. Вам нужно только ввести эту строку:
implementation 'io.seata:seata-spring-boot-starter:1.7.1' // Пожалуйста, проверьте номер последней версии- Добавлена конфигурация application.yml.
seata:
enabled: true
application-id: multi-datasource
tx-service-group: my_test_tx_group
enable-auto-data-source-proxy: true
config:
type: file
file:
data-file: classpath:file.conf
registry:
type: file
file:
data-file: classpath:registry.conf- Добавить файл file.conf
service {
# сопоставление tx-service-group
vgroupMapping.my_test_tx_group = "default"
vgroupMapping.default = "default"
# Seata Адрес Сервера - ваш Seata IP-адрес и порт сервера
default.grouplist = "127.0.0.1:8091"
# Другие связанные конфигурации
enableDegrade = false
disableGlobalTransaction = false
}
store {
mode = "file"
file {
# Каталог, в котором хранятся локальные журналы транзакций
dir = "sessionStore"
}
}
- Добавлен файл реестра.conf.
registry {
type = "file"
file {
name = "file.conf"
}
}
config {
type = "file"
file {
name = "file.conf"
}
}
UserOrderServiceДобавьте следующие методы:
@GlobalTransactional
public void createUserAndOrderByGlobalTransaction(UserOrderDTO userOrderDTO) {
OrderDTO orderDTO = new OrderDTO();
BeanUtils.copyProperties(userOrderDTO, orderDTO);
orderService.createOrder(orderDTO);
// Сообщить об ошибке
int i = 1/0;
UserDTO userDTO = new UserDTO();
BeanUtils.copyProperties(userOrderDTO, userDTO);
userService.createUser(userDTO);
}- Добавьте новый метод контроллера:
@PostMapping("/createMixGlobalTransaction")
public void createMixByGlobalTransaction(@Valid @RequestBody UserOrderDTO userOrderDTO) {
userOrderService.createUserAndOrderByGlobalTransaction(userOrderDTO);
}- контроллер запросов
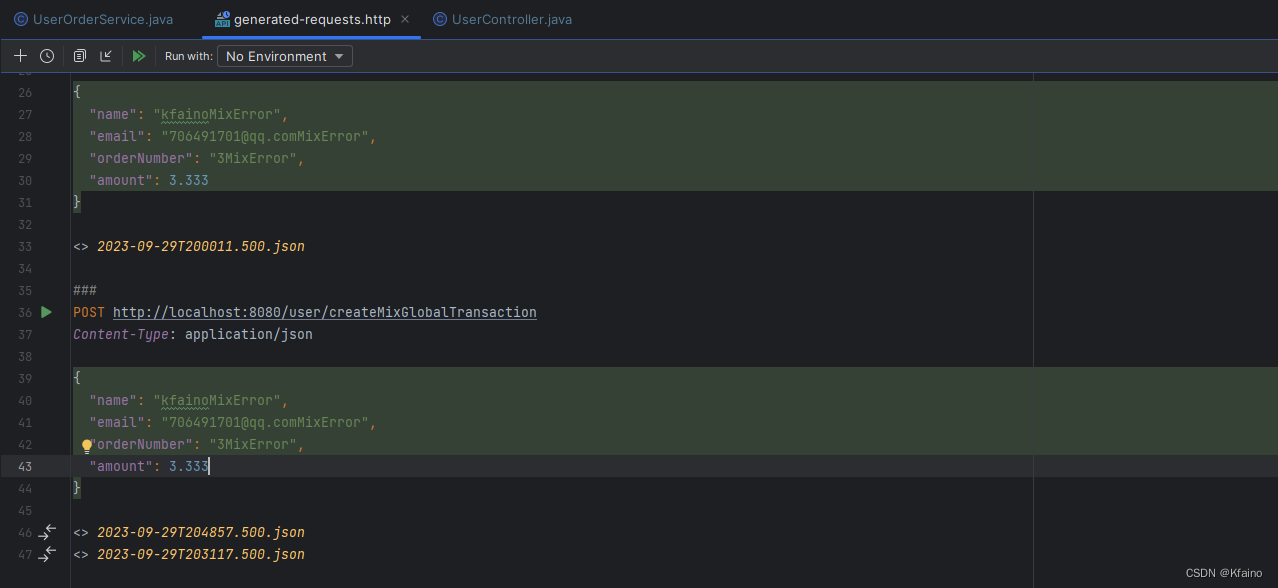
Результаты выполнения следующие:

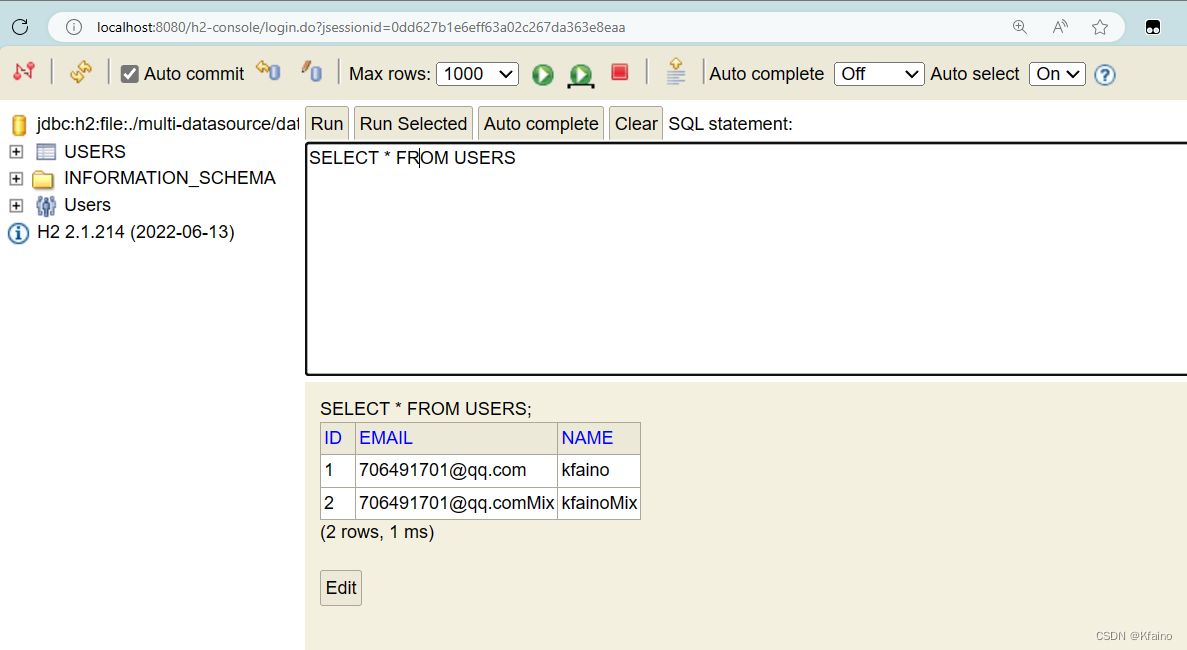
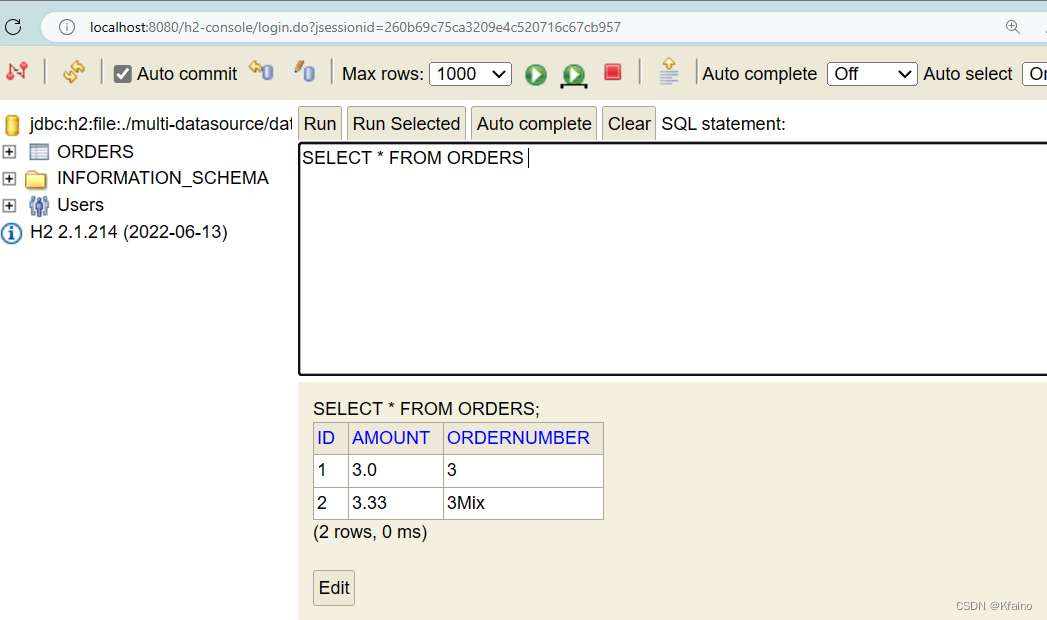
Глобальная транзакция вступает в силу, и транзакция откатывается.
Подвести итог
На этом глава заканчивается. В этой статье подробно рассматриваются преимущества и распространенные применения нескольких источников данных, а также показано, как использовать и интегрировать несколько источников данных в Spring Boot. В то же время мы также обсудили проблемы транзакций, существующие в нескольких источниках данных, и решили эту проблему с помощью глобального управления транзакциями Seata.
Ссылки
- Как SpringBoot интегрирует несколько источников данных, просто прочитайте эту статью. - Тенсент Облако
- Spring Boot Интегрировать Несколько источников данные, это называется элегантность - наггетсы
- Springboot интегрирует межбазовые операции mybatis и настраивает несколько источников данных DataSource - CSDN
- SpringBoot интегрирует MyBatisНесколько источников данных - Тенсент Облако
- Узнайте, как интегрировать Springboot за 5 минут источников данных - Подумай об этом



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
