Spark+Celeborn: быстрее, стабильнее и гибче
краткое содержание:Содержание этой статьи в основном разделено на трииндивидуальныйчасть:
- 1. Проблемы с традиционным Shuffle
- 2.Apache Celeborn (инкубация) Введение
- 3.Celeborn существоватьпроизводительность、стабильность、эластичностьначальствоиздизайн
1. Проблемы с традиционным Shuffle
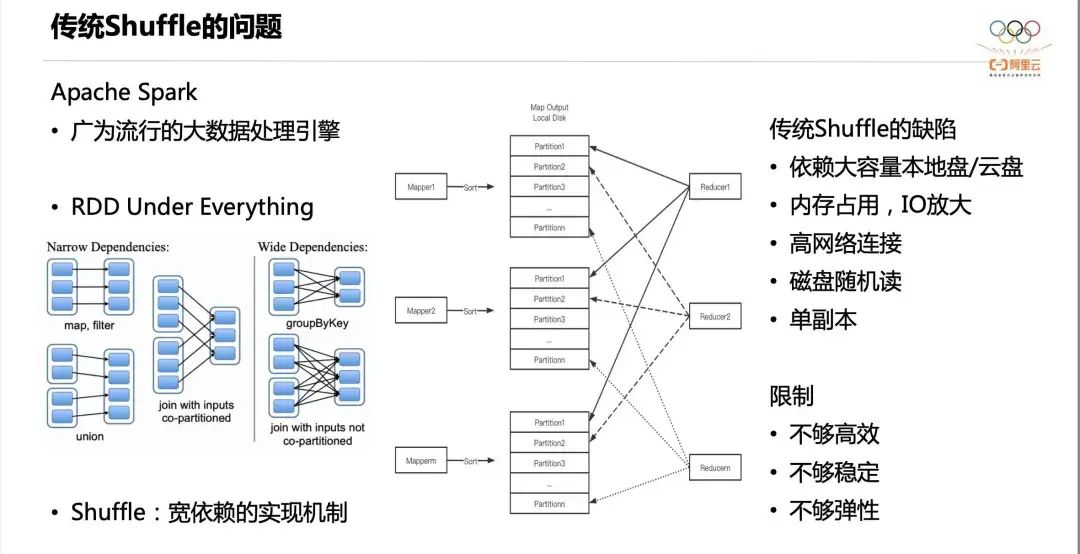
Apache Spark — широко популярный механизм обработки больших данных. Он имеет множество сценариев использования: Spark SQL, пакетная обработка, потоковая обработка, MLLIB, GraphX и т. д. В основе всех компонентов лежит единая абстракция RDD, а происхождение RDD описывается двумя типами зависимостей: узкими зависимостями и широкими зависимостями. Среди них широкая зависимость является ключом к поддержке сложных операторов (Join, Agg и т. д.), а механизм реализации широкой зависимости — Shuffle.
Традиционная реализация Shuffle показана в средней части рисунка выше. Каждый Mapper сортирует выходные данные Shuffle в соответствии с идентификатором раздела, а затем записывает отсортированные данные и индекс на локальный диск. На этапе чтения в случайном порядке Редуктор считывает свои собственные данные раздела из файлов в случайном порядке всех картографов. Однако эта реализация имеет следующие недостатки:
- Первый,Положитесь на большую емкость локального диска или хранилища облачных дисков. Перетасуйте данные., данные должны оставаться до тех пор, пока потребление не будет завершено. Это ограничивает разделение хранилища и вычислений, поскольку при разделении архитектуры хранения и вычислений вычислительным узлам обычно не нужны локальные диски большой емкости и надеются, что узлы можно будет освободить после завершения вычислений.
- Во-вторых, картограф Сортировка займет много места и может даже вызвать сортировку вне кучи и использование дополнительных дисков. IO。
- В-третьих, Shuffle Read имеет большое количество сетевых подключений, а количество логических подключений составляет m×n.
- В-четвертых, существует большое количество случайных чтений. Предположим, Mapper из Shuffle данныеда 128M,Reducer из начальствоволосыда 2000, тогда каждый файл будет прочитан 2000 раз, каждый раз читается случайно 64к, который легко доходит до диска IOPS из «Узкого места».
- В-пятых, данные имеют единственную копию и имеют низкую отказоустойчивость.
Вышеуказанные пять недостатков в конечном итоге приводят к недостаточной эффективности, недостаточной стабильности и недостаточной гибкости.
2. Апач Celeborn (Инкубация)

Apache Celeborn (Incubating) — это служба удаленного перемешивания, разработанная нашей командой на заре для решения вышеуказанных проблем. В октябре 2022 года она была передана в дар Apache Foundation. Celeborn позиционируется как единый сервис промежуточных данных для движков больших данных. Он не зависит от движка и помимо поддержки Shuffle в будущем также будет поддерживать Spilled data, чтобы вычислительные узлы могли действительно устранить свою зависимость от большой емкости. локальные диски.
Прежде чем перейти к официальному представлению дизайна Celeborn, немного истории. Celeborn родился в 2020 году. В то время он назывался Remote Shuffle Service, главным образом для удовлетворения потребностей клиентов. В декабре 2021 года его исходный код был официально открыт. После открытия исходного кода мы привлекли к его созданию разработчиков из Xiaomi, Shopee, NetEase и т. д., многие из которых стали основными участниками.
Мы официально войдем в инкубатор Apache в октябре 2022 года. На данный момент мы накопили более 600 коммитов, 32 участника и более 330 звезд. Мы также надеемся, что в совместном создании примут участие больше заинтересованных разработчиков.
3. Производительность, стабильность и гибкость Celeborn
Проект Celeborn по повышению производительности в основном включает в себя дизайн ядра, способы взаимодействия со Spark AQE, столбчатое перемешивание и многоуровневое хранилище.
1. Производительность
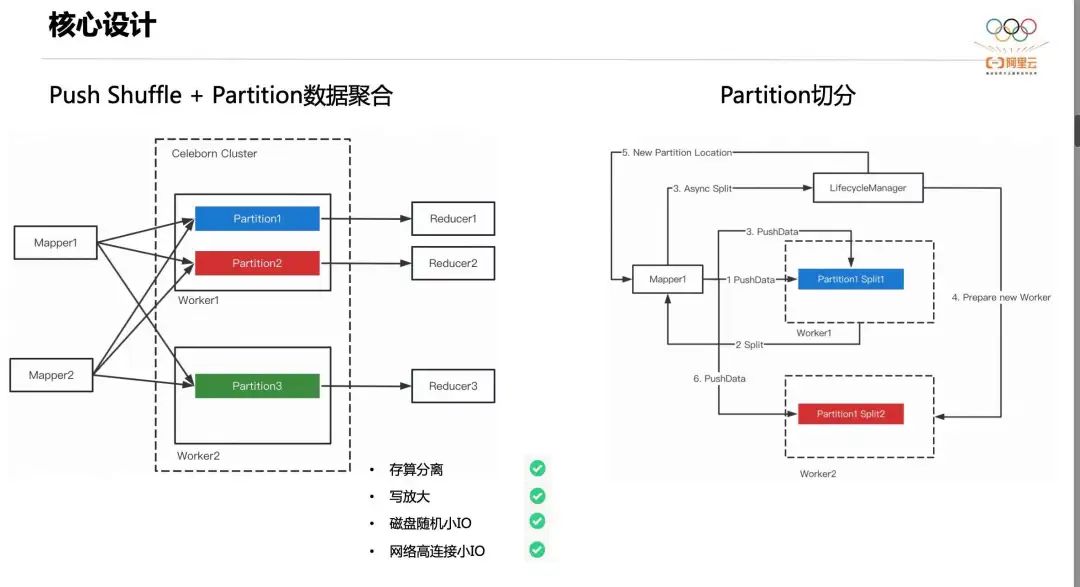
Celeborn использует базовую конструкцию агрегации данных Push Shuffle + Partition. Проще говоря, каждый Mapper поддерживает внутренний буфер для кэширования данных Shuffle. Когда буфер превышает пороговое значение, Mapper отправляет данные, принадлежащие одному и тому же разделу, в предварительно выделенный Worker.
Как показано на рисунке выше, данные Partition1 и Partition2 передаются в Worker1, а данные Partition3 — в Worker2. Каждый раздел в конечном итоге генерирует файл. На этапе случайного чтения Редюсеру нужно только прочитать свои собственные данные от Воркера. При такой конструкции данные Shuffle не попадают на диск и их не нужно сортировать. При этом Shuffle Read преобразуется из случайного чтения в последовательное, а количество сетевых подключений также меняется с мультипликативной зависимости на линейную. Это решает главный недостаток традиционного Shuffle.
Смысл проектирования нарезки раздела заключается в том, что для больших заданий или данных с неравномерностью данных файл раздела становится очень большим. Когда мы сталкиваемся с ситуацией, когда размер одного раздела превышает 100 ГБ, легко разрушить диск и вызвать дисбаланс нагрузки на диск.
Чтобы решить эту ситуацию, Celeborn реализует Partition. В частности, Worker будет динамически отслеживать размер каждого файла раздела, и когда он превысит пороговое значение, он вернет клиенту метку разделения. После того, как Клиент получит метку разделения, он асинхронно подаст заявку на нового работника. После того, как новый работник будет готов, клиент отправит данные новому работнику. Это гарантирует, что файл разделения одного раздела не будет слишком большим, и два файла разделения будут считываться во время произвольного чтения.
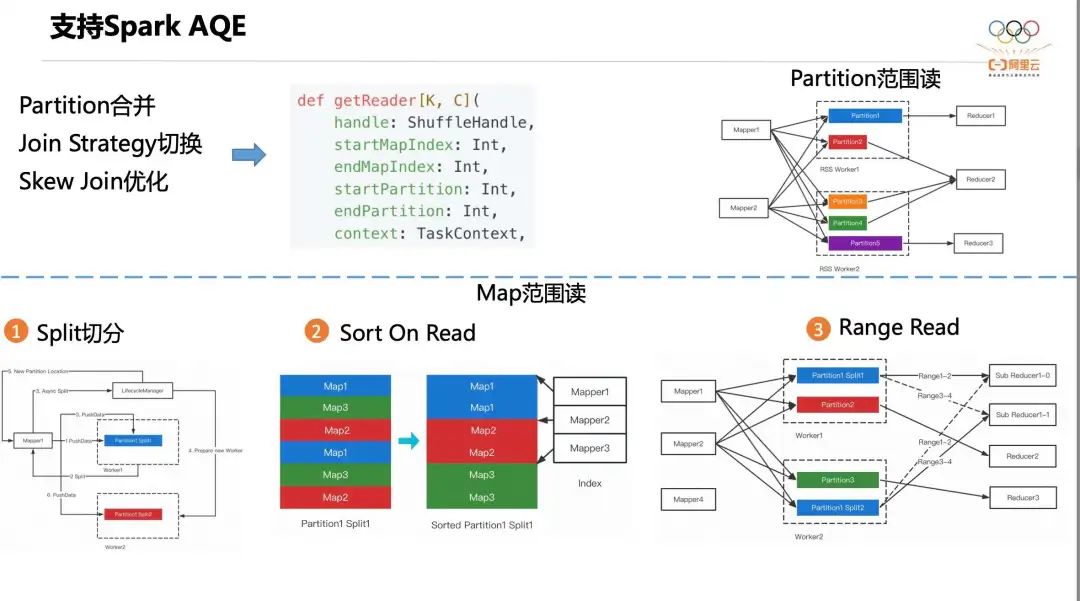
Далее мы расскажем, как Celeborn поддерживает Spark AQE. AQE — самая важная оптимизация Apache Spark за последние годы. В основном она включает три сценария: слияние разделов, переключение стратегии объединения и оптимизацию Skew Join. Требование AQE к модулю Shuffle — иметь возможность чтения в соответствии с диапазоном раздела и диапазоном Mapper. Более естественно читать в соответствии с диапазоном раздела, как показано в правом верхнем углу рисунка. выше, Редюсер1 напрямую считывает данные из Разделов 2, 3 и 4.
Согласно показаниям Mapper, реализация немного сложна и может быть разделена на следующие три этапа:
- Первый шаг, Сплит Нарезка. Перекос Join Это означает, что данныеиметь наклонена и, скорее всего, сработает. Partition Сегментация, например. Partition1 разделен на Split1 и Split2。
- Второй шаг, сортировка On Читать. впервые Read кто-то Partition Split Когда файл будет удален, он будет запущен. Sort On Read,Worker будет основано на Partition ID Отсортируйте этот файл. После сортировки Mapper Чтение диапазона изменится со случайного чтения перед сортировкой на последовательное чтение. Например, я хочу прочитать Mapper1 приезжать Mapper2 изданные, если да отсортировано перед из файлов, мне действительно нужен этот индивидуальный файл seek четыре раза, но если это после сортировки, мне просто нужно seek один раз.
- Третий шаг, Диапазон Read。Sub Reducer из этих двух Partition Последовательность чтения принадлежит вам из Mapper Диапазон изданные. Тем временем Сплит Файл запишет себя из Mapper список, чтобы можно было удалить ненужные элементы Split документ.
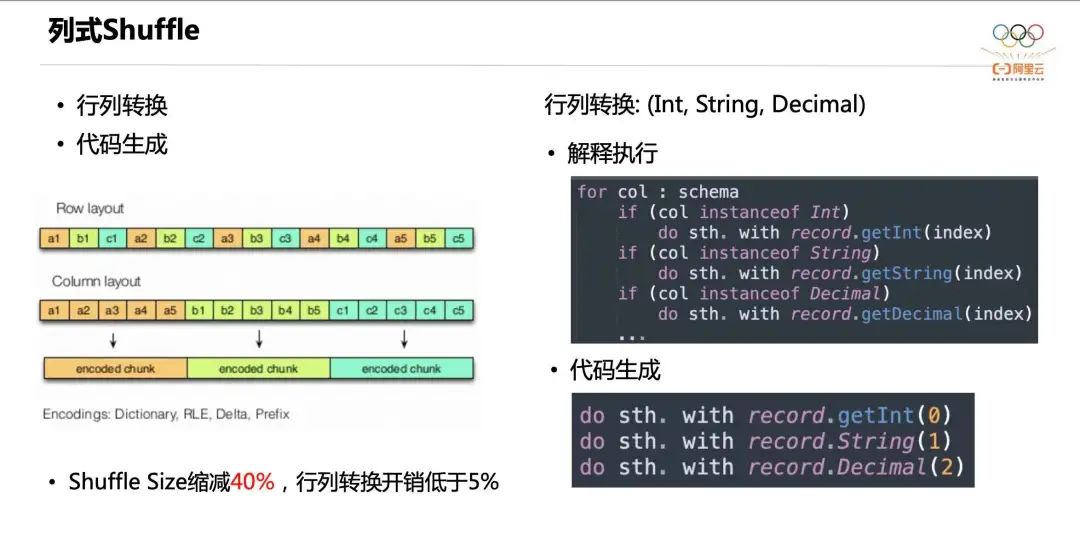
Далее мы представляем столбчатый Shuffle от Celeborn. Как мы все знаем, хранилище строк и хранилище столбцов — это два распространенных метода размещения данных. Преимущество хранения столбцов заключается в том, что данные одного типа объединяются и их легко кодировать, например, словарное кодирование, кодирование серий, дельта-кодирование, префиксное кодирование и т. д., что может значительно уменьшить объем данных. Раньше хранилище столбцов в основном использовалось для хранения данных исходной таблицы, а хранилище строк в основном использовалось для промежуточных данных в операторах механизма вычислений, поскольку реализация предыдущих операторов в основном основывалась на данных хранения строк.
Однако в последние годы все более популярными становятся механизмы векторизации, включая Velox, ClickHouse, DuckDB и т. д. Все они используют реализации векторизованных операторов, поэтому промежуточные данные операторов также используют хранилище столбцов. Хотя фотонный движок Databricks использует технологию векторизации, Apache Spark по-прежнему является движком на основе строк.
Чтобы реализовать перемешивание по столбцам в Apache Spark, Celeborn представляет преобразование строк в столбцы и генерацию кода, преобразование данных, хранящихся в строках, в данные, хранящиеся в столбцах, во время записи в случайном порядке и преобразование столбцов в данные, хранящиеся в строках, во время чтения в случайном порядке. В то же время, чтобы повысить эффективность преобразования строк в столбцы, Celeborn представляет технологию генерации кода, позволяющую устранить накладные расходы на интерпретацию и выполнение. После включения перемешивания столбцов в тесте 3T TPCDS общий размер перемешивания можно уменьшить на 40 %, а затраты на преобразование строк в столбцы составляют менее 5 %.

Далее мы представляем многоуровневое хранилище Celeborn. Цель разработки многоуровневого хранилища — позволить Celeborn гибко адаптироваться к различным аппаратным средам и хранить данные на более быстрых уровнях хранения, насколько это возможно. Celeborn определяет три носителя данных: память, локальный диск и распределенное хранилище (OSS/HDFS). Пользователи могут выбирать 1-3 типа хранилища по своему желанию. Например, они могут использовать только локальные диски или использовать только память и OSS.
На рисунке выше показан механизм хранения с одновременным выбором трех носителей. Во-первых, память будет разделена на две логические области: область push-данных и область кэша. Данные, отправленные с карты, сначала попадают в область push-данных. Когда данные раздела превышают заданный порог, в это время срабатывает Flush, Celeborn определяет целевой уровень хранения раздела. локальный диск (P3), эта часть данных будет сброшена в локальную область; если это кэш памяти (p4), эта часть данных будет логически разделена на области кэша (реальной копии в памяти не будет); ).
Когда область кэша заполнена, Celeborn вытеснит самый большой раздел на следующий уровень хранилища. Например, P4 будет сброшен на локальный диск. После очистки данных раздела последующие данные не будут перемещены в область кэша.
Когда локальный диск заполнен, у нас есть две стратегии. Первая — выселить локальные файлы в OSS. Второму типу не нужно трогать локальные файлы, и данные сбрасываются напрямую из памяти в OSS.
Многоуровневое хранилище может не только повысить производительность небольших перемешиваний в памяти, но также использовать огромное пространство хранения OSS для поддержки очень больших перемешиваний. Например, если вы только выберете, Celeborn будет независимым. памяти и OSS, то у Celeborn не будет локальных дисков, это позволит повысить гибкость самого сервиса Celeborn.
2. Стабильность
Проект Celeborn по обеспечению стабильности самого сервиса в основном включает в себя обновления на месте, контроль перегрузки и балансировку нагрузки.
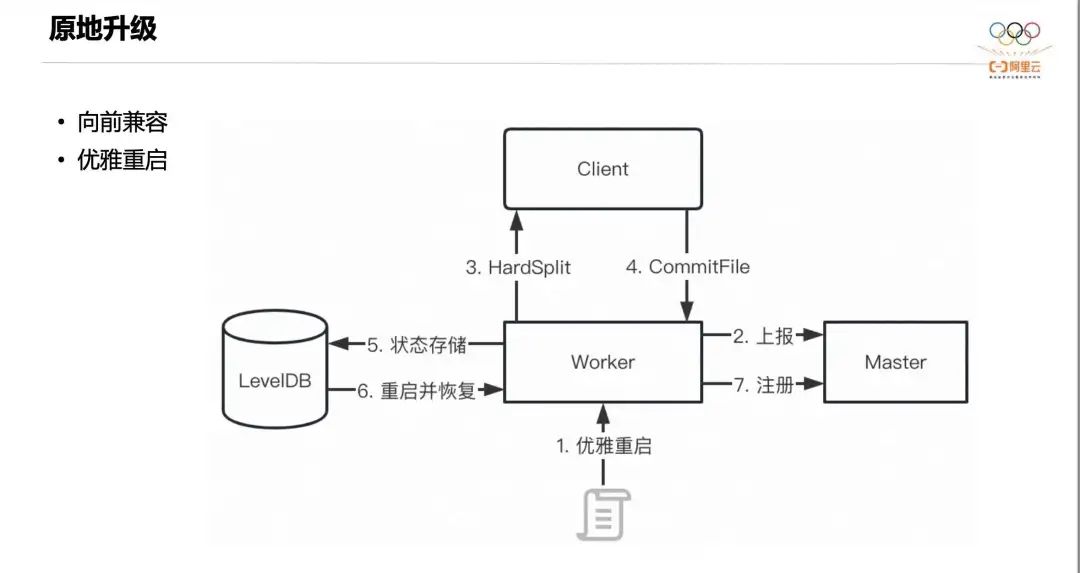
Сначала представьте обновление на месте. Доступность — это требование, которому должны соответствовать службы. Хотя метод переключения «синий-зеленый» может соответствовать большинству сценариев, он требует большего количества ручного вмешательства и временного расширения ресурсов. Celeborn обеспечивает обновление на месте без приложений благодаря совместимости протоколов и плавному перезапуску. Прямая совместимость достигается за счет PBизации протокола, а для плавного перезапуска мы используем функцию активного разделения раздела. На рисунке выше показан процесс плавного перезапуска.
Во-первых, внешняя система запускает плавный перезапуск. После того, как работник получает сигнал, он отмечает себя как состояние постепенного отключения и сообщает об этом мастеру. После этого мастер не будет выделять новые слоты работнику. Затем Worker отмечает возврат PushData меткой HardSplit. После получения этой отметки Клиент не будет продолжать отправлять данные Worker. В то же время он инициирует сообщение CommitFile для Worker, когда все данные раздела кэшируются. в памяти на Worker завершает CommitFile. Наконец, Worker выполнит сериализацию и сохранит состояние памяти в локальной базе данных LevelDB, а затем перезапустится. Затем прочитайте и восстановите статус из LevelDB и, наконец, перерегистрируйтесь на Мастере.
Из этого процесса мы видим, что благодаря активному механизму разделения плавный перезапуск Celeborn более эффективен, чем в других системах. По сути, его можно завершить на втором уровне, вообще не влияя на выполнение задания.
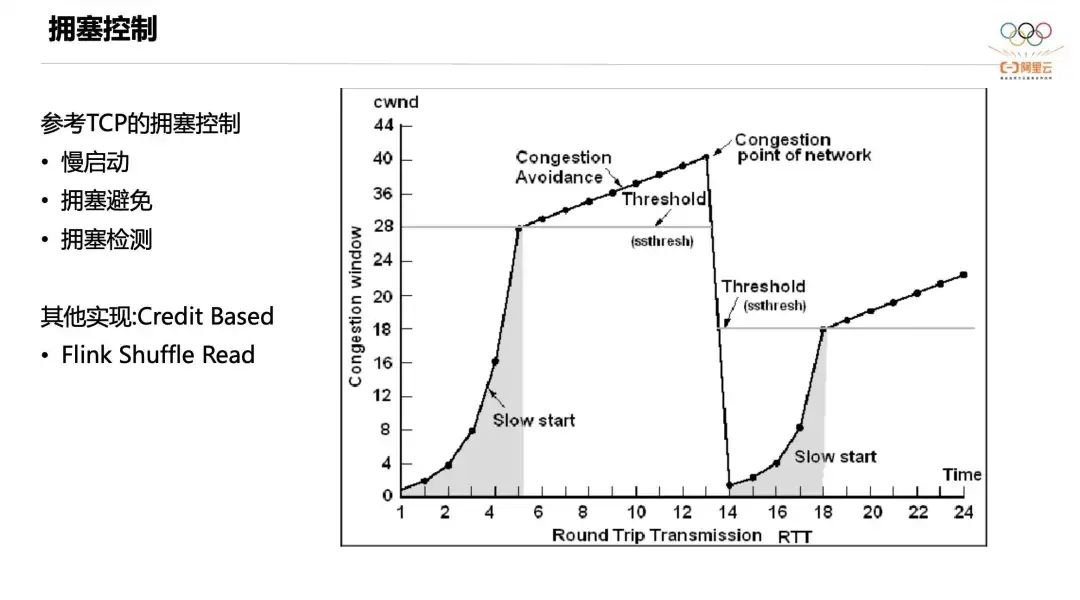
Далее мы представляем контроль перегрузки Celeborn на этапе произвольной записи. Чтобы предотвратить перегрузку рабочей памяти большими мгновенными заданиями, Келеборн обращается к механизму контроля перегрузки TCP, который включает в себя три канала: медленный запуск, предотвращение перегрузки и контроль перегрузки.
Изначально Pusher находится в состоянии медленного запуска, и скорость передачи данных очень низкая, но эта скорость будет увеличиваться в геометрической прогрессии. Когда он достигнет определенного порога, он перейдет в стадию предотвращения перегрузки. В это время скорость толчка будет медленно увеличиваться и станет фиксированным наклоном. В это время, если память Worker достигнет уровня предупреждения, сработает контроль перегрузки и каждому Клиенту будет отправлена отметка. После его получения Клиент вернется в исходное состояние медленного старта, а скорость Пушера соответственно упадет до очень низкого уровня.
Другой распространенный способ управления потоком — управление потоком на основе кредитов. Проще говоря, каждый раз, когда я отправляю данные, я должен получить определенное количество кредитов от работника. Это означает, что работник зарезервирует для меня часть памяти. только мне нужно, чтобы я мог передать данные размером не больше, чем кредит в моей руке. Этот механизм может обеспечить точное управление памятью, но его компромисс увеличивает поток управления и оказывает определенное влияние на производительность.
Celeborn использует TCP-подобный контроль перегрузки на этапе произвольной записи, который может учитывать как мгновенные пики трафика, так и стабильную производительность. В то же время Celeborn использует дизайн на основе кредитов для поддержки этапа произвольного чтения Flink.
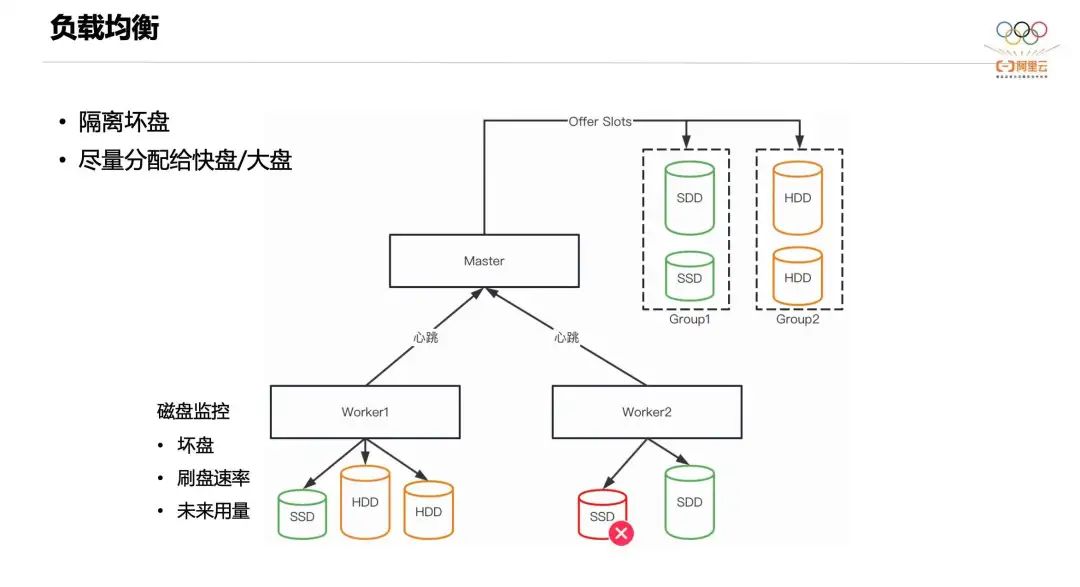
Далее мы представляем дизайн балансировки нагрузки Celeborn. Текущая балансировка нагрузки, на которой фокусируется Celeborn, в основном сосредоточена на дисках. Цель разработки — изолировать плохие диски и попытаться распределить нагрузку на более быстрые диски с большим пространством. В частности, Worker будет отслеживать состояние каждого доступного локального диска, включая работоспособность, скорость очистки диска и прогнозируемое будущее использование. Эта информация о состоянии будет мгновенно отправлена Master. Мастер хранит информацию о состоянии всех доступных дисков во всем кластере и группирует диски в соответствии с моделью алгоритма. Группы с более высокими уровнями будут распределять больше рабочих нагрузок. Если они принадлежат к одной группе, они будут выделены дискам с большей доступной емкостью. Конструкция балансировки нагрузки Celeborn обеспечивает более стабильную работу в гетерогенных средах.
3. Гибкость
Celeborn разработан с учетом гибкости, в основном включая решение Spark на K8s + Celeborn.

В сценарии Yarn внешняя служба Shuffle является необходимым условием для Spark, чтобы обеспечить динамическое масштабирование ресурсов. После размещения данных Shuffle в ESS можно выпустить Executor.
Однако ESS не существует в сценарии Spark на K8s. Для обслуживания последующего произвольного чтения модуль не может быть освобожден, даже если он простаивает. Чтобы оптимизировать этот сценарий, решение с открытым исходным кодом добавляет параметр spark.dynamicAllocation.shuffleTracking.enabled, который определяет, следует ли его освободить, отслеживая, читается ли файл Shuffle. Но, согласно нашим тестам, этот параметр имеет ограниченный эффект. После интеграции Celeborn данные Shuffle размещаются в кластере Celeborn, а поды могут быть освобождены сразу после простоя, что обеспечивает истинную эластичность.
4. Типичные сценарии
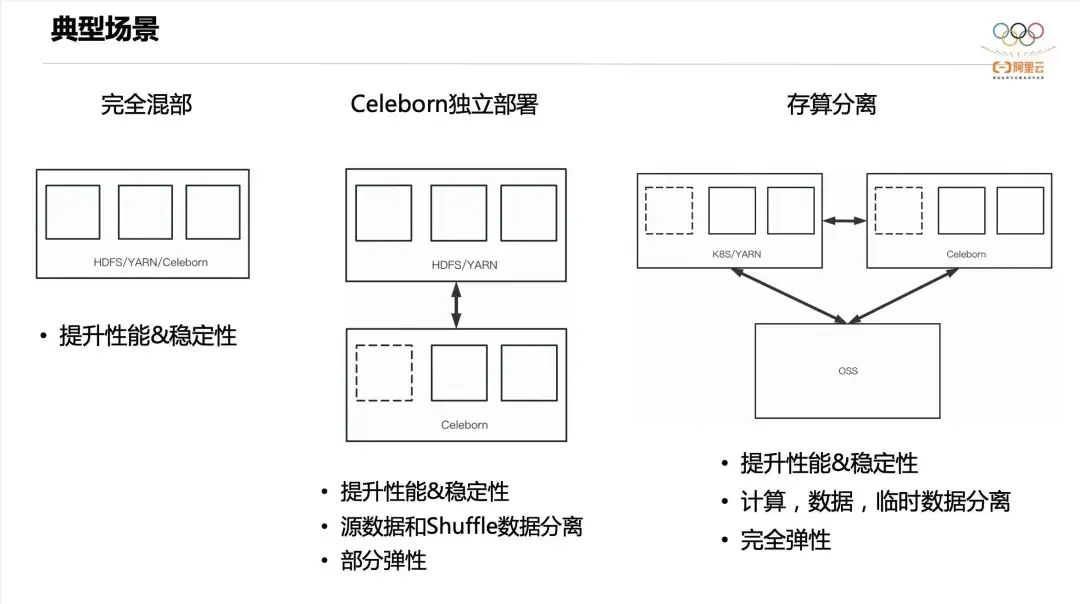
У Келеборна есть следующие три типичных сценария.
- Первый полностью смешанный. То есть HDFS、Yarn、Celeborn распределенныйсуществоватьтакой жеиндивидуальныйкластер,Это основное преимущество – повышение производительности и стабильности.
- Второй Celeborn Автономное развертывание, HDFS и Yarn Смешанное отделение. Помимо повышения производительности и стабильности, он также может изолировать данные исходной таблицы. IO и Shuffle данныеиз IO верно Вытеснение диска, которое обеспечивает определенную изоляцию ресурсов, а также Celeborn кластеризчастьэластичность。
- Третий тип разделения хранения и расчета. Исходная таблица сохраняет существующее хранилище образов, а вычислительный узел запускается существующим. K8s или Yarn Кластер, Келеборн Кластер также развертывается независимо. В этом сценарии вычислительный кластери. Celeborn Кластеры могут обладать полной изэластичностью.
5. Evaluation
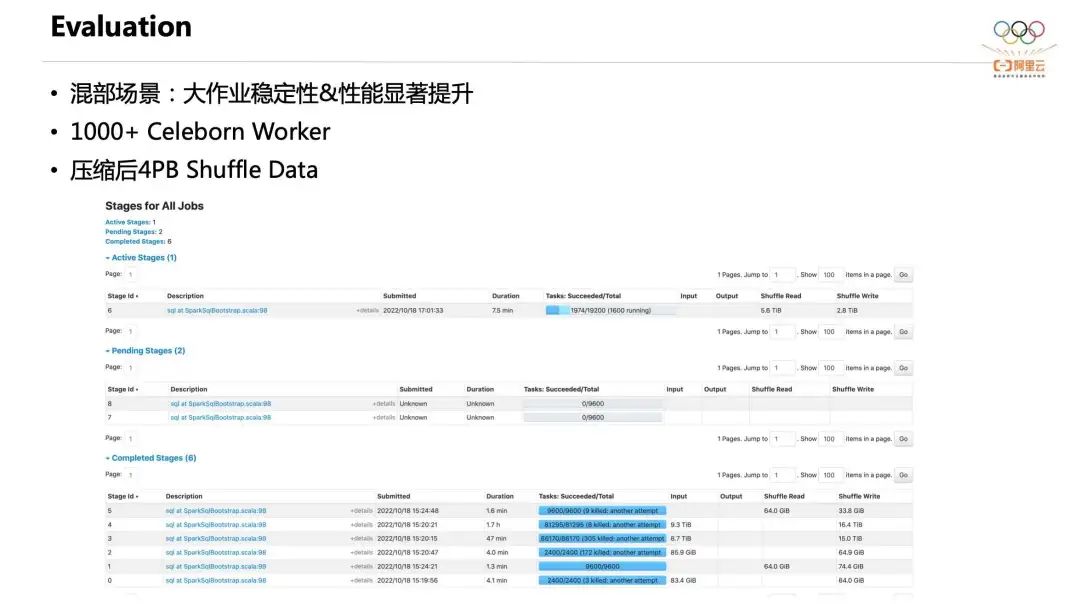
Далее я расскажу о двух случаях. Первый — это случай совместного размещения. Пользователь смешал Celeborn в вычислительный кластер. Общий масштаб развертывания Celeborn достиг более 1000 единиц, но ресурсы, предоставляемые каждому Worker, были относительно ограничены.
Ежедневный объем данных Shuffle этого пользователя может достигать 4 ПБ после сжатия, а улучшение стабильности больших данных также очень очевидно. Как видно на рисунке выше, существует более 80 000 одновременных операций. Одно задание Shuffle имеет масштаб 16T и может стабильно работать в среде жесткого диска. Это задание нельзя было запустить до установки Celeborn.
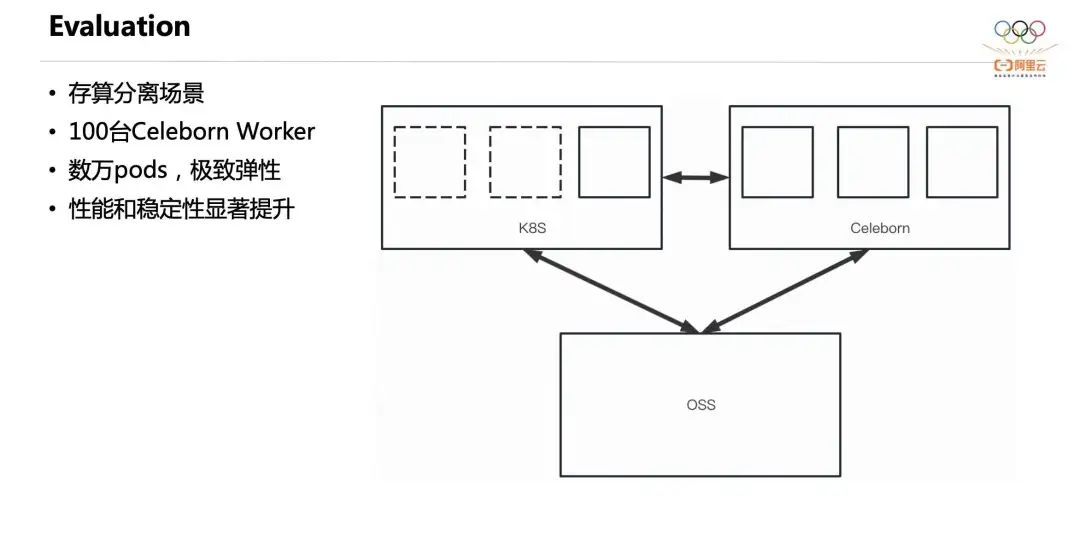
Второй — случай разделения хранения и вычислений. Один пользователь использует полностью разделенную архитектуру хранения и вычислений. Его вычислительные узлы работают на K8, данные исходной таблицы хранятся в OSS, а кластер Celeborn развертывается независимо. Их вычислительные узлы ежедневно содержат десятки тысяч модулей. Функция динамического масштабирования ресурсов Spark включена по умолчанию, что обеспечивает очень хорошую гибкость. Кроме того, значительно улучшены производительность и стабильность.

На рисунке выше — результат нашего теста в смешанной среде стандартного тестового набора TPCDS 3T. Без потребления дополнительных машинных ресурсов одна копия Celeborn повышает производительность на 20% по сравнению с Службой внешнего перемешивания, а двойные копии дают улучшение на 13%.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
