Spark: расчет индикатора мониторинга в реальном времени в течение 30 секунд от 0
Предисловие
Говоря о Spark, каждый, естественно, вспомнит о Flink и неосознанно сравнит эти две основные технологии обработки больших данных в реальном времени. Затем мы наконец пришли к выводу: производительность Flink в реальном времени выше, чем у Spark.
действительно,Расчет данных в Flink управляется событиями.,Таким образом, часть данных вызовет расчет,Spark рассчитывает на основе набора данных RDD.,Минимальный интервал генерации RDD составляет 50 миллисекунд.,такSparkопределяется какВычисления в субреальном времени。
Окно
СДР здесь является «естественным окном». Мы устанавливаем временной интервал для генерации СДР равным 1 минуте, тогда это СДР можно понимать как «1минутное окно». Так что, если вам нужен расчет окна, я все равно предпочитаю Spark.
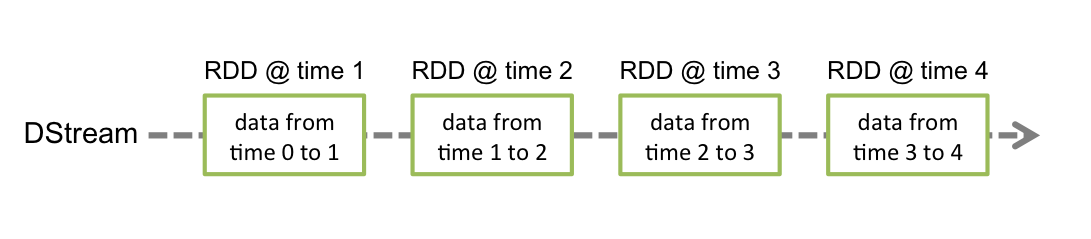
Но когда нам нужно вычислить непосредственное временное окно,Необходимо использоватьраздвижное окнооператор для реализации。что скоро?
Например, описание временного диапазона — «в течение 3 минут». Расчет этого временного диапазона требует расчета исторических данных. Например, 1~3 - это 3 минуты, 2~4 - тоже 3 минуты, здесь повторно используются данные 2 и 3 и так далее, 3~5 - тоже 3 минуты, а 3 и 4 тоже используются повторно.
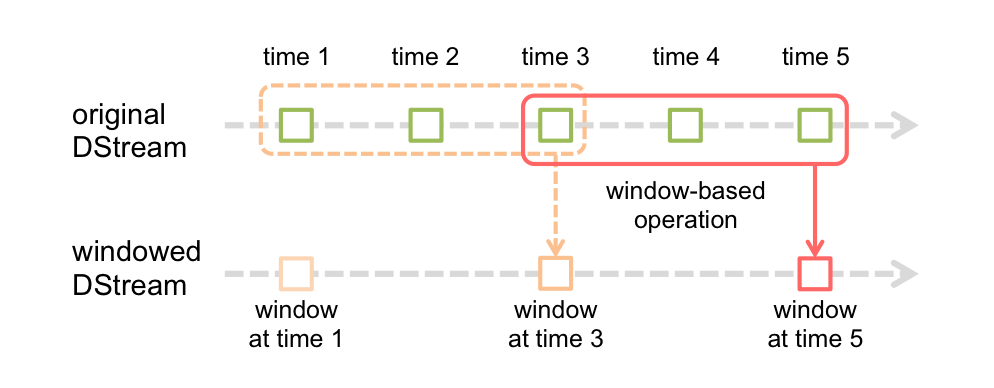
Если вы используете обычное окно, вы не можете соблюдать концепцию времени «в течение последних 3 минут».
Как показано на рисунке ниже, многие окна потеряли время близости. Например, время близости третьего СДР на самом деле является вторым СДР, но их нельзя рассчитать вместе. Вот почему обычные окна не используются.
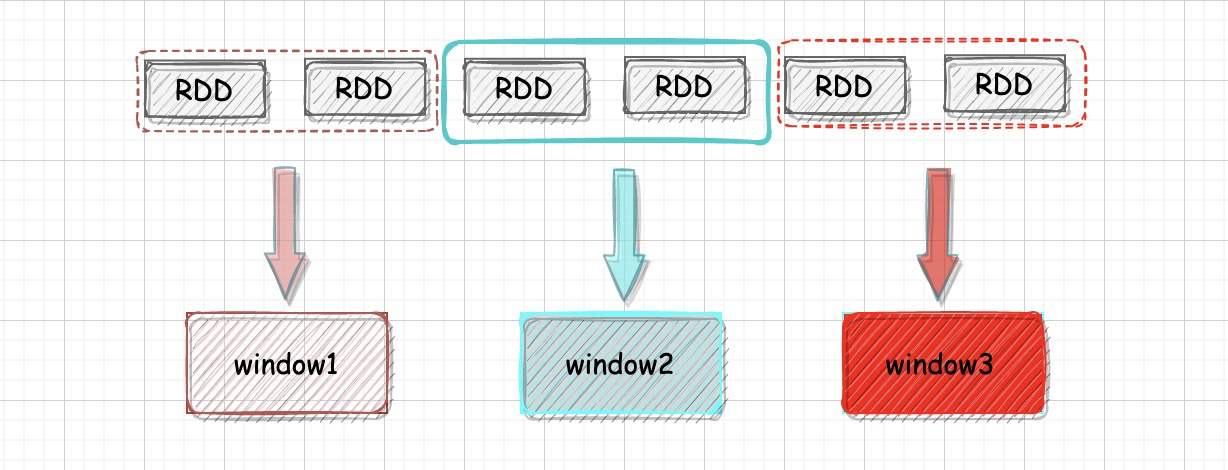
раздвижное окно
раздвижное окно Три элемента: время генерации RDD、длина окна、Размер скользящего шага.
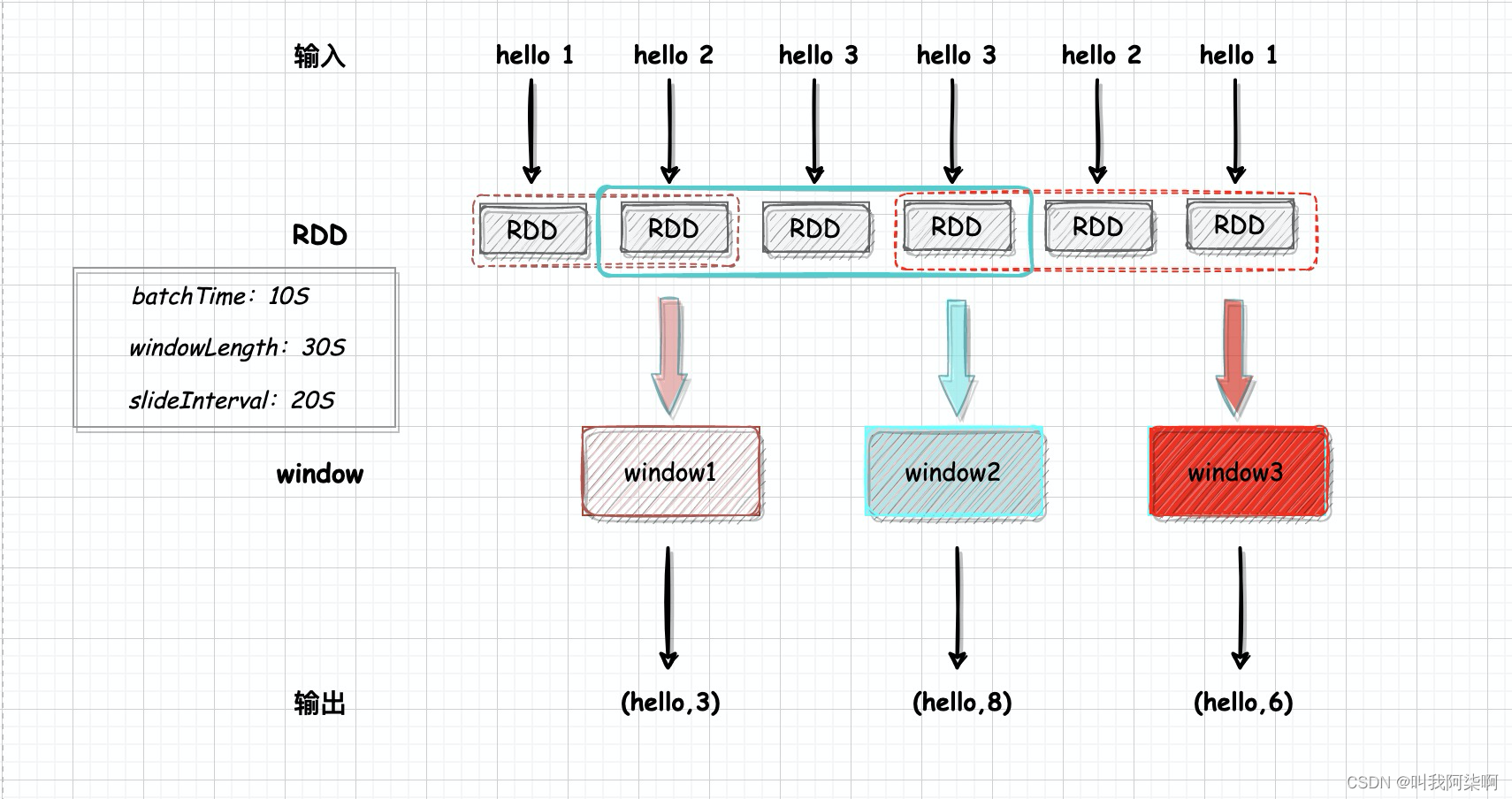
В этой практике я установил временной интервал RDD на 10 с, длину окна на 30 с и шаг скольжения на 10 с. То есть каждые 10 секунд будет генерироваться окно для расчета данных за последние 30 секунд. Каждое окно состоит из 3 RDD.
Создание источника данных
1. Спецификация данных
Предположим, что мы собираем индикаторную информацию об устройстве. Здесь мы фокусируемся только на пропускной способности и времени ответа. Перед сбором мы определяем поля данных и спецификации [пропускная способность, время ответа], которые определяются как тип int. определяется как миллисекунды мс.
В реальных ситуациях мы не можем собрать только одно устройство. Если мы хотим получить мониторинг индикаторов каждого устройства или каждого типа устройства, мы должны добавить уникальный идентификатор или TypeID к каждому устройству при сборе данных.
Моя идея здесь состоит в том, чтобы проанализировать показатели каждого устройства, поэтому я добавил уникальный идентификатор для каждого устройства, а конечные поля — [id, пропускная способность, время ответа], поэтому мы следуем этому формату данных и строим данные в части чтения источника SparkStreaming.
2. Читайте Кафку
val conf = new SparkConf().setAppName("aqi").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds(10))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "121.91.168.193:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "aqi",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("evt_monitor")
val stream: DStream[String] = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
).map(_.value)Здесь мы устанавливаем временной интервал RDD равным 10 с.,Потому что я работаю на ноутбуке,так Здесь нам нужноMasterустановлен наlocal,Указывает локальный режим работы,1 означает использование 1 потока.
Мы используем Kafka в качестве источника данных,При чтении необходимо построить конфиг Потребителя.,картинаbootstrap.serversОб этих базовых конфигурациях особо нечего сказать.,Ключauto.offset.resetиenable.auto.commit,
Эти два параметра управляют чтением политик потребления тем и отправкой смещений. Самый ранний здесь начнет использовать самые ранние существующие данные в теме, а самый последний начнет использовать самую последнюю позицию.
При перезапуске программы эти два режима потребления контролируются параметром Enable.auto.commit. Если установлено значение true для отправки смещения, самый ранний и последний режимы больше не действуют и используются из смещения, записанного группой потребителей. Установите значение false, и смещение не будет отправлено. Самые ранние данные по-прежнему будут использоваться из самых ранних существующих данных в теме, а самые последние будут использоваться из самых последних данных.
Последний шаг — задать тему для чтения и создать поток данных DStream Kafka. На этом чтение всего источника данных завершено. Далее идет разработка логики обработки данных.
3. Расчет агрегирования показателей
stream.map(x => {
val s = x.split(",")
(s(0), (s(2).toInt, 1))
}).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.reduceByKeyAndWindow((x: (Int, Int), y: (Int, Int)) => (x._1 + y._1, x._2 + y._2), Seconds(30), Seconds(10))
.foreachRDD(rdd => {
rdd.foreach(x => {
val id = x._1
val responseTimes = x._2._1
val num = x._2._2
val responseTime_avg = responseTimes / num
println(id, responseTime_avg)
})
})Мы исходим из собственных потребностей,задумать разработку логики программы. С точки зрения спроса,Ключевые слова – это не что иное, какЗа последний период в среднем。Хотите получить данные за определенный период времени,Просто используйте раздвижное окно,На основе текущего времени,Обведите временные рамки вперед.
И средний,Это не что иное, как размещение временного диапазона,То есть сумма всех времен отклика окна,Затем разделите на количество элементов данных. Хотите суммировать все время ответа,используется здесьreduceByKey() Добавьте время устройства с тем же идентификатором в окно и добавьте количество элементов данных.
Поэтому, когда я разделяю данные на первом этапе, я разделяю данные на кортежи KV. У V есть два поля: первое — это время ответа, а второе — 1, представляющее фрагмент данных. Функция «reduceByKey» разделена на два этапа. Первый — это «reducByKey» в RDD, который также рассматривается как предварительная обработка данных. Данные RDD будут рассчитываться только один раз. Когда этот RDD используется несколькими окнами, он не будет рассчитываться повторно. Вторым шагом является агрегирование данных всех RDD в окне на основе значения «reducByKey» окна и, наконец, получение выходных данных в foreachRDD.
4. Результаты проверки
Мы желаемkafkaизevt_monitorэтотtopicзаписать данные в。

Примечание. (Последние 11 идентификаторов — это проблема с отображением терминала, на самом деле это 1), а затем можно вывести среднее значение.
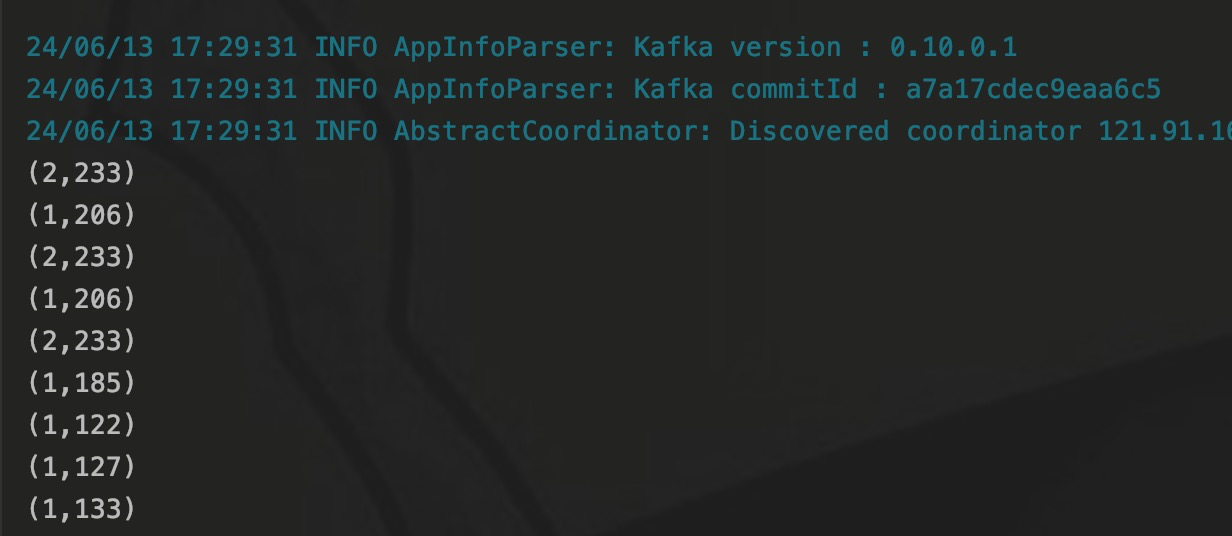
С результатами проверки проблем нет. С другой стороны, мы также можем посмотреть на это со стороны DAG.
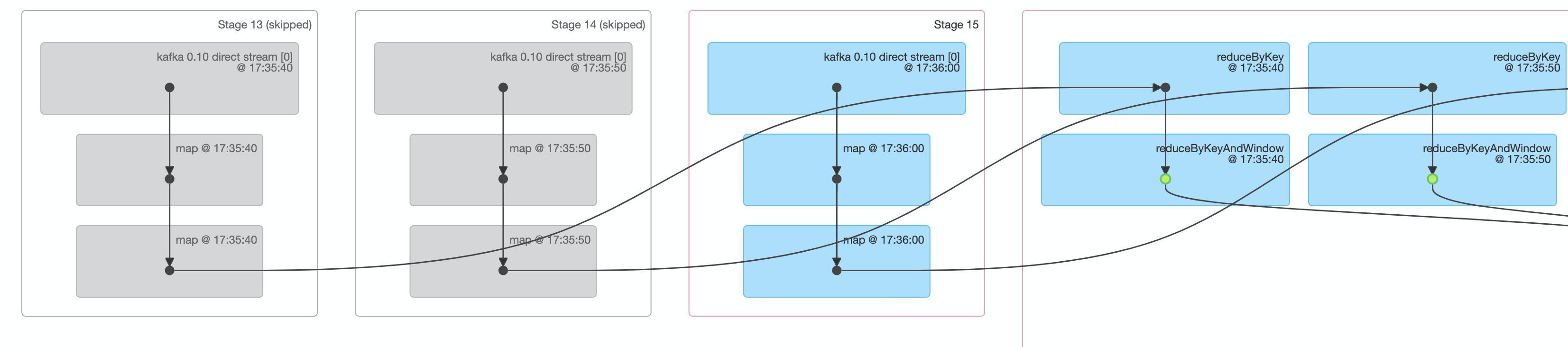
В этом окне рассчитано всего 3 СДР. Два слева имеют серый цвет с пропущенными логотипами, что означает, что два СДР были рассчитаны в предыдущем окне. В этом окне необходимо рассчитать только текущий СДР. а затем вместе выполните расчет окна для данных результатов RDD.
Заключение
В этой статье в основном используется раздвижное приложение Spark. окно, сделал сценарий приложения для расчета среднего времени ответа, используя Kafka в качестве источника данных, через раздвижное окноиreduceByKeyоператор реализован。в то же время,При разработке Spark настоятельно рекомендуется использовать Scala.,Вся программа не выглядит лишней.
Наконец, есть мое личное мнение по поводу выбора Spark и Flink. Spark действительно хуже Flink с точки зрения производительности в реальном времени, но у Spark все же есть преимущества для оконных вычислений. Поэтому по каждой технологии вам не нужно следовать тому, что говорят другие, лучше всего подходит та, которая вам подходит.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
