Создание распределенной системы сканирования на Python [комбинация Scrapy и распределенной очереди задач]
С постоянным развитием Интернета,Сетевые рептилии играют важную роль в сборе данных и интеллектуальном анализе информации. Однако,Одна машина часто не может справиться с потребностью в больших объемах данных.,поэтому,Создание распределенной системы рептилий стало неизбежным выбором. В этой статье рассказывается, как использовать Python в Scrapy Рамка и Распределенная очередь Задача построить эффективную распределенную систему рептилия.
Введение в Scrapy
Scrapy является мощным Python Фреймворк рептилии, который предоставляет мощные возможности ползти и гибкие функции извлечения данных. проходить Scrapy,Мы можем легко определить процесс, правила и методы обработки данных рептилий.,Таким образом, можно быстро построить эффективную автономную систему рептилий.
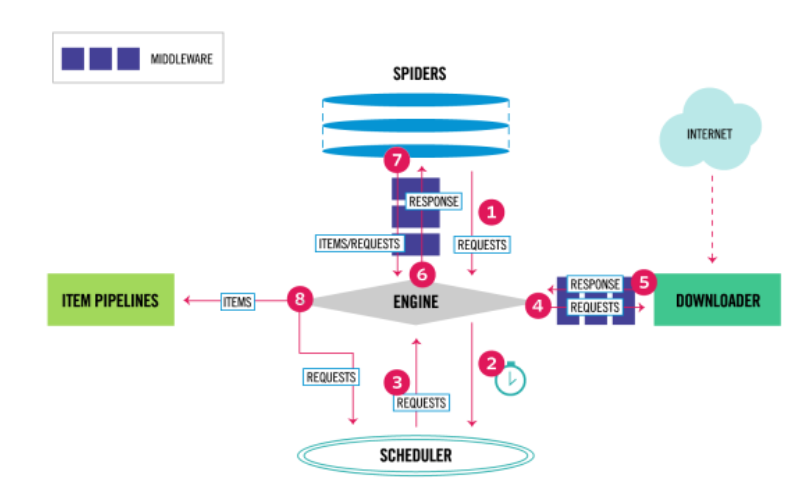
Введение в распределенные очереди задач
Распределенная очередь задач — это система распределения задач и координации работы между несколькими узлами. Обычно он состоит из производителей задач, очередей задач и нескольких потребителей задач. Производители задач отвечают за создание задач и помещение их в очередь, тогда как потребители задач получают задачи из очереди и выполняют их.
Объединение Scrapy и распределенных очередей задач
Чтобы построить распределеннуюрептилиясистема,мы можем Scrapy Будучи потребителем задач, распределенная очередь задач отвечает за распределение задач по нескольким Scrapy узел. Сельдерей является популярным Python Структура распределенной очереди задач, мы будем использовать Celery как наша очередь задач.
Вот основные шаги по построению распределенной системы рептилий:
Шаг 1. Установите необходимые библиотеки
pip install scrapy celeryШаг 2. Определите сканер Scrapy
# myspider/spiders/example_spider.py
import scrapy
class ExampleSpider(scrapy.Spider):
name = "example"
start_urls = [
'http://example.com',
]
def parse(self, response):
# Определите здесь логику извлечения данных
passШаг 3: Настройте сельдерей
# celeryconfig.py
CELERY_BROKER_URL = 'redis://localhost:6379/0'Шаг 4. Напишите задачи Celery
# tasks.py
from celery import Celery
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
app = Celery('tasks', broker='redis://localhost:6379/0')
@app.task
def run_spider():
process = CrawlerProcess(get_project_settings())
process.crawl('example')
process.start()Шаг 5: Запустите Celery Worker
celery -A tasks worker --loglevel=infoШаг 6. Запустите задачу
# trigger.py
from tasks import run_spider
run_spider.delay()Выполнив вышеуказанные шаги, мы успешно создали эксплойт. Scrapy и Celery Реализована распределенная система рептилий. С производителями задач можно связаться по телефону run_spider.delay() Чтобы запустить задачу, Celery Worker тогда начнется с Очереди задач Залезай Задачаи выполнитьрептилия。
Реализуйте дедупликацию задач
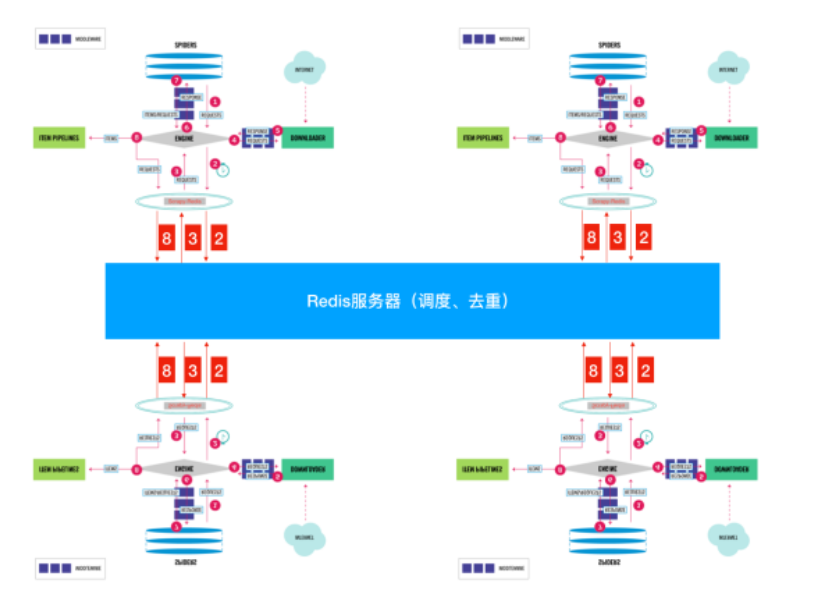
При построении распределенной системы рептилий важным вопросом является дедупликация задач. Поскольку несколько узлов рептилий могут одновременно использовать один и тот же узел. Если URL-адрес не дедуплицирован, это приведет к дублированию и пустой трате ресурсов. Для решения этой проблемы мы можем воспользоваться Распределенной. очередь задач Характеристики Реализуйте дедупликацию задач。
Шаг 1. Используйте Redis в качестве контейнера дедупликации Scrapy
# settings.py
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://localhost:6379/1'
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = TrueШаг 2. Настройте Celery для использования Redis в качестве промежуточного программного обеспечения для сообщений.
# celeryconfig.py
CELERY_BROKER_URL = 'redis://localhost:6379/0'В приведенной выше конфигурации мы используем Redis Реализована функция дедупликации задач распределенной системы рептилий, гарантирующая, что несколько узлов рептилий не будут дублировать одни и те же ползти. URL。
Контролируйте и управляйте
в практическом применении,Нам также необходимо провести Модерируйте и управляйте распределенной системой рептилии., чтобы обеспечить его стабильную работу. Сельдерей Обеспечивает мощную Контролируйте и инструмент управления, который мы можем использовать Flower контролировать Celery Worker статус работы и управлять очередью задач.
Шаг 1: Установите цветок
pip install flowerШаг 2: Запустите цветок
flower -A tasks --port=5555путем доступа http://localhost:5555,Мы можем просмотреть его в браузере Celery Worker Интерфейс мониторинга и выполнение связанных операций управления, таких как просмотр очереди задач, просмотр состояния выполнения задач и т. д.
Оптимизация производительности
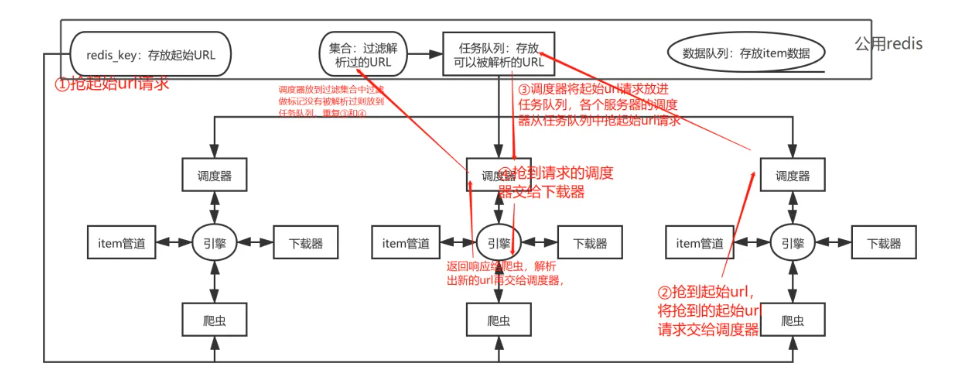
В сценарии крупномасштабного использования данных ключевым вопросом является оптимизация производительности. Мы можем улучшить производительность распределенной системы рептилий за счет следующих моментов:
- Управление параллелизмом: В зависимости от состояния нагрузки целевого веб-сайта и производительности сервера.,Разумно установите количество одновременных запросов,Опасность создает чрезмерную нагрузку на целевой сервер.
- Использовать пул прокси: избегать IP Блокировка целевым веб-сайтом может быть достигнута с помощью пула прокси. IP Вращение повышает стабильность и удобство использования рептилий.
- Оптимизация хранения данных: Используйте высокопроизводительную базу данных или NoSQL Система хранилища собирает данные из хранилищаползти и повышает эффективность чтения и записи данных.
Благодаря вышеуказанным мерам оптимизации,Мы можем еще больше улучшить производительность и стабильность распределенной системы рептилий.,Убедитесь, что он может эффективно обрабатывать крупномасштабные данные ползти Задача.
Пример: использование Redis в качестве распределенной очереди задач
В этом примере мы покажем, как использовать Redis В качестве распределенной очереди задач взаимодействуйте с Scrapy Создайте простую распределенную систему рептилий. Мы создадим простую рептилию для ползти. Quotes to Scrape котировки веб-сайта и сохраняйте результаты в MongoDB середина.
Шаг 1. Установите необходимые библиотеки
Сначала убедитесь, что он у вас установлен Scrapy、Redis и pymongo:
pip install scrapy redis pymongoШаг 2. Определите сканер Scrapy
# quotes_spider.py
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)Шаг 3. Настройте Scrapy для использования Redis
# settings.py
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://localhost:6379/0'Шаг 4. Создайте подключение к базе данных MongoDB.
# db.py
import pymongo
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["quotes_database"]
collection = db["quotes"]Шаг 5. Определите конвейер хранения данных
# pipelines.py
from .db import collection
class MongoDBPipeline(object):
def process_item(self, item, spider):
collection.insert_one(item)
return itemШаг 6: Запустите рептилию
scrapy crawl quotesПройдите вышеуказанные шаги,Мы реализовали простую распределенную систему рептилий.,использовать Scrapy ползти Quotes to Scrape котировки веб-сайта и сохраняйте результаты в MongoDB середина.Redis как Распределенная очередь задача, обеспечивает распределение и совместную работу задачи между несколькими узлами рептилии, MongoDB Он используется для данных, полученных хранилищем ползти.
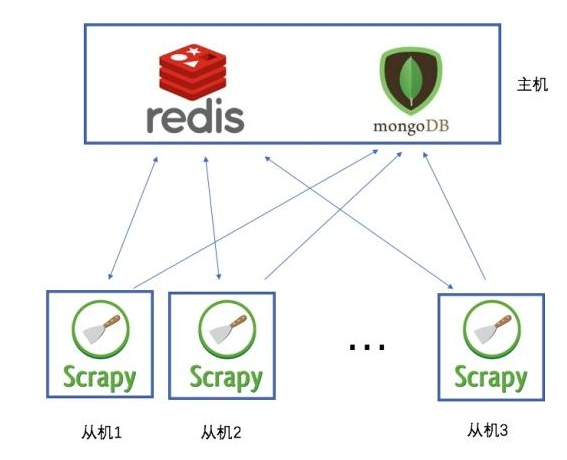
Дополнительные расширения
Помимо использования Scrapy и Celery Это классическое сочетание,Есть и другие варианты построения распределенной системы рептилий.,Для удовлетворения потребностей различных сценариев.
1. Используйте распределенную очередь сообщений
Кроме Celery и другие распределенные очереди сообщений, такие как Kafka、RabbitMQ ждать,Их также можно поставить в очередь. Эти очереди сообщений имеют характеристики высокой пропускной способности, низкой задержки и т. д.,Подходит для обработки больших объемов данных. ползти Задача.
2. Используйте распределенное хранилище
В распределенной системе рептилий,Хранение данных также является важным вопросом. Традиционные реляционные базы данных могут оказаться не в состоянии удовлетворить потребности хранилища данных с высоким уровнем параллелизма и большой емкости.,Можно считатьиспользоватьраспределенныйхранилищесистеманравиться Hadoop、Cassandra Ждем поступления данных.
3. Используйте технологию контейнеризации
Docker и Kubernetes могут упростить развертывание и управление распределенными системами рептилий.,Повысьте гибкость и масштабируемость системы. через контейнеризацию,Узлы рептилий, очереди задач, хранилище данных и другие компоненты можно упаковать в контейнеры.,И унифицированное управление с помощью инструментов оркестрации контейнеров.
4. Используйте инструменты автоматического развертывания.
Анзибль, Шеф-повар, Марионетка Он может реализовать автоматизированное развертывание и управление конфигурацией распределенной системы рептилий, а также улучшить ремонтопригодность и стабильность системы.
Выбрав правильное решение и технологию,Мы можем построить эффективную и стабильную распределенную систему рептилий в соответствии с конкретными потребностями и сценариями.,Для того, чтобы лучше достичь цели крупномасштабного сбора данных и интеллектуального анализа данных.
Подвести итог
В этой статье объясняется, как использовать Python в Scrapy Рамка и Распределенная очередь задач Redis создает простую, но эффективную распределенную систему рептилий. Пример показывает, как определить Scrapy рептилия,Конфигурация Redis как Задача поставить в очередь и передать данные из ползтихранилище в MongoDB середина. Ниже приведены основные положения этой статьи. итог:
- Scrapy рептилиярамка:Scrapy Он предоставляет мощные возможности ползти и гибкие функции извлечения данных, что делает его идеальным выбором для создания эффективной системы рептилий.
- Распределенная очередь задач Redis:использовать Redis Распределенная может быть легко достигнута очередь задачи, обеспечивающие распределение и совместную работу задачи среди множества узлов рептилия.
- Хранилище данных MongoDB:MongoDB является высокопроизводительным NoSQL База данных, подходящая для хранения большого количества полезных данных.
- Задача Планирование и Выполнение:проходить Конфигурация Scrapy использовать Redis как Задача очередь может реализовать распределение и выполнение задач. Сельдерей èДругие распределенные очереди сообщений также являются опциями.
- Обработка данных:определенный MongoDB хранилище Конвейер, передающий данные из ползтихранилище в MongoDB за настойчивость.
через этот пример,Читатели могут узнать, как построить простую, но полнофункциональную распределенную систему рептилий.,И может быть расширен и оптимизирован в соответствии с реальными потребностями. Построение распределенной системы рептилий предполагает совместную работу нескольких компонентов.,Необходимо выбрать подходящую технологию и решение в соответствии с конкретным сценарием и потребностями. Я надеюсь, что эта статья поможет читателям лучше понять, как использовать Python для создания эффективной распределенной системы рептилий.,и добиться успеха в практическом применении.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
