Совершенно новая «ядерная бомба»! Выпущена NVIDIA B200: 208 миллиардов транзисторов, вычислительная мощность FP4 до 40PFlops!

18 марта по местному времени компания Nvidia, ведущий производитель чипов искусственного интеллекта (ИИ), провела конференцию GTC 2024 в Сан-Хосе, штат Калифорния, и официально представила «ядерную бомбу» для центров обработки данных следующего поколения и приложений искусственного интеллекта — Графический процессор B200 на базе архитектуры Blackwell обеспечит огромный скачок в вычислительной мощности и, как ожидается, официально поступит в продажу позднее в этом году. В то же время Nvidia также представила суперчип Grace Blackwell GB200 и так далее.

По словам основателя и генерального директора NVIDIA Дженсена Хуанга, NVIDIA в настоящее время обновляет свою архитектуру графического процессора каждые два года, чтобы еще больше повысить производительность чипов искусственного интеллекта. Хотя графический процессор с архитектурой Hopper, выпущенный два года назад, уже очень хорош, нам нужен более мощный графический процессор.

B200: 208 миллиардов транзисторов, вычислительная мощность FP4 до 40 петафлопс
После того, как Nvidia выпустила графический процессор H100 с использованием архитектуры Hopper в 2022 году, она стала лидировать на мировом рынке искусственного интеллекта. B200, выпущенный на этот раз с использованием архитектуры Blackwell, будет более мощным и лучше справляется с задачами, связанными с искусственным интеллектом. Архитектура Блэквелла названа в честь математика Дэвида Гарольда Блэквелла.
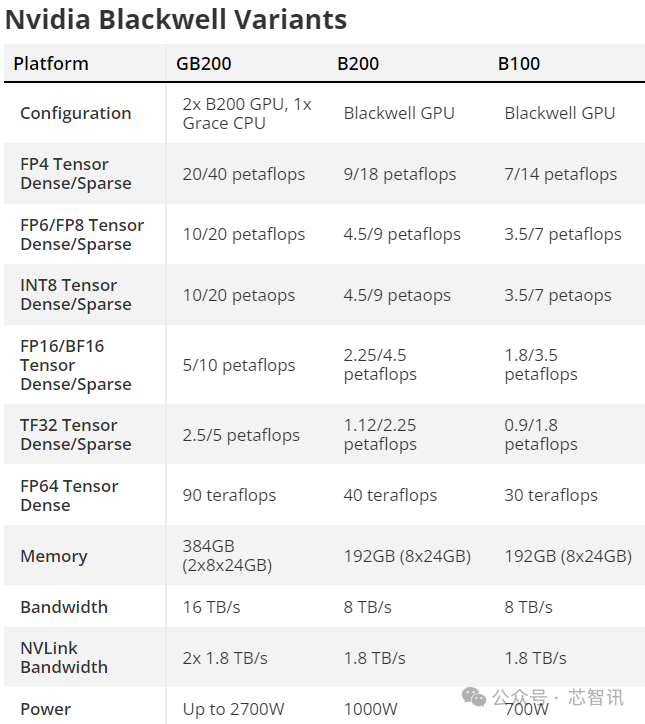
По имеющимся данным, графический процессор B200 основан на техпроцессе TSMC N4P (который представляет собой улучшенную версию техпроцесса N4, используемого предыдущим поколением графических процессоров Hopper H100 и архитектуры Ada Lovelace. Число транзисторов достигло 208 миллиардов, что составляет 208 миллиардов). вдвое больше 80 миллиардов транзисторов H100/H200. Это также позволяет производительности искусственного интеллекта B200 достигать 20 петафлопс.
Хуан Ренсюнь заявил, что производительность вычислений на базе искусственного интеллекта графического процессора Blackwell с архитектурой B200 может достигать 20 петафлопс как на FP8, так и на новом FP6, что в 2,5 раза превышает 8 петафлопс вычислительной производительности H100 с архитектурой Hopper предыдущего поколения. В новом формате FP4 она может достигать 40 петафлопс, что в пять раз превышает 8 петафлопс вычислительной производительности графического процессора предыдущего поколения с архитектурой Hopper. В зависимости от объема памяти и конфигурации пропускной способности различных графических процессоров с архитектурой Blackwell фактическая производительность выполнения рабочей нагрузки может быть выше. Хуан Жэньсюнь подчеркнул, что благодаря этой дополнительной вычислительной мощности компании, занимающиеся искусственным интеллектом, смогут обучать более крупные и сложные модели.
Однако следует отметить, что B200 — это не один графический процессор в традиционном понимании. Вместо этого он состоит из двух тесно связанных чипов графического процессора. Хотя, по словам Nvidia, они функционируют как единый графический процессор CUDA. Два чипа соединены через соединение NV-HBI (интерфейс высокой пропускной способности Nvidia) со скоростью 10 ТБ/с, чтобы гарантировать их работу как полностью согласованный чип.


В то же время мощность HBM также чрезвычайно важна для вычислений с использованием искусственного интеллекта. Причина, по которой AMD MI300X привлекла широкое внимание, заключается в том, что помимо значительного улучшения производительности, его емкость до 192 ГБ HBM (памяти с высокой пропускной способностью) также очень важна, что более чем вдвое превышает 80 ГБ чипа Nvidia H100 SXM. Чтобы компенсировать недостаток емкости HBM, NVIDIA также выпустила H200 с HBM емкостью 141 ГБ, но она все еще отстает от AMD MI300X. B200, выпущенный на этот раз Nvidia, оснащен той же памятью HBM3e емкостью 192 ГБ, которая может обеспечить пропускную способность 8 ТБ/с, что компенсирует это слабое звено.
Хотя Nvidia еще не предоставила точные размеры чипа для B200, судя по опубликованным фотографиям, в B200 будут использоваться два чипа размером с полную маску с четырьмя стеками HMB3e вокруг каждого кристалла, каждый стек имеет емкость 24 ГБ и пропускную способность каждого стека 1 ТБ/с. пропускная способность на 1024-битном интерфейсе.
Следует отметить, что H100 использует шесть стеков HBM3 по 16 ГБ каждый (H200 увеличивает это число до шести по 24 ГБ), а это означает, что значительная часть кристалла H100 отведена под шесть контроллеров памяти HBM. Уменьшив количество интерфейсов контроллера памяти HBM внутри каждого чипа до четырех и соединив два чипа вместе, B200 может соответственно уменьшить площадь кристалла, необходимую для интерфейса контроллера памяти HBM, и может интегрировать больше транзисторов, используемых в вычислениях.
Поддержка нового формата FP4/FP6.
B200, основанный на архитектуре Blackwell, достигает этого показателя благодаря новому цифровому формату FP4, который имеет вдвое большую пропускную способность, чем формат FP8 в Hopper H100. Следовательно, если мы сравним B200 с H100, настаивающим на использовании вычислительной мощности FP8, B200 обеспечивает только в 2,5 раза больше теоретических вычислений FP8 (с разреженностью), чем H100. Большая часть причины связана с тем, что B200 имеет два вычислительных чипа. Для большинства цифровых форматов, поддерживаемых как H100, так и B200, B200 теоретически увеличивает вычислительную мощность на чип в 1,25 раза.
Опять же, речь идет об отсутствии масштабных улучшений плотности на технологическом узле 4NP. Удаление двух интерфейсов HBM3 и создание чипа немного большего размера может означать, что B200 даже не станет значительно более плотным в вычислениях на уровне чипа. Конечно, интерфейс NV-HBI между двумя чипами также будет занимать некоторую площадь кристалла.
Nvidia также предоставляет необработанные расчеты B200 в других числовых форматах с применением обычных коэффициентов масштабирования. Таким образом, FP8 имеет половину пропускной способности FP4 (уровень 10 петафлопс), FP16/BF16 имеет половину пропускной способности уровня 5 петафлопс, TF32 поддерживает половину FP16 (уровень 2,5 петафлопс) - все со свойствами разреженности, поэтому скорость для интенсивных операций вдвое меньше. из этих ставок. Аналогично, во всех случаях вычислительная мощность может в 2,5 раза превышать мощность одного H100.
А как насчет вычислительной мощности FP64? H100 рассчитан на производительность 60 терафлопс интенсивных вычислений FP64 на каждый графический процессор. Если бы B200 имел такое же масштабирование, как и другие форматы, каждый двухчиповый графический процессор имел бы производительность 150 терафлопс. В действительности, однако, производительность FP64 у B200 ниже и составляет около 45 терафлопс на графический процессор. Но это также требует некоторых пояснений, поскольку суперчип GB200 станет одним из ключевых строительных блоков. Он оснащен двумя графическими процессорами B200, которые могут выполнять 90 терафлопс интенсивных вычислений FP64, а другие факторы могут увеличить производительность классического моделирования по сравнению с H100.
Кроме того, что касается использования FP4, у Nvidia есть новый Transformer Engine второго поколения, который поможет пользователям автоматически конвертировать модели в соответствующий формат для максимальной производительности. Помимо поддержки FP4, Blackwell также будет поддерживать новый формат FP6 — промежуточное решение для ситуаций, когда FP4 не хватает необходимой точности, но не требует и FP8. Независимо от точности результатов, Nvidia классифицирует этот тип использования как модель «смесь экспертов» (MoE).
Самый мощный AI-чип GB200
Nvidia также выпустила суперчип GB200, который основан на двух графических процессорах B200 плюс процессоре Grace. То есть теоретическая вычислительная мощность суперчипа GB200 достигнет 40 петафлопс, а настраиваемый TDP всего суперчипа будет таким же. высокая мощность 2700 Вт.


Хуан Ренсюнь также отметил, что B200, который содержит два графических процессора Blackwell и процессор Grace с использованием архитектуры Arm, имеет производительность модели вывода, которая в 30 раз выше, чем у H100, а стоимость и энергопотребление снижены до 1/1. 25 оригинальных.
В дополнение к суперчипу GB200 Nvidia также предлагает серверное решение HGX B200, основанное на использовании восьми графических процессоров B200 и процессора x86 (возможно, двух процессоров) в одном серверном узле. Эти конфигурации TDP составляют 1000 Вт на графический процессор B200, а графический процессор обеспечивает пропускную способность FP4 до 18 петафлопс, поэтому на бумаге он на 10% медленнее, чем графический процессор в GB200.
Кроме того, существует HGX B100, который имеет ту же базовую архитектуру, что и HGX B200, с процессором x86 и восемью графическими процессорами B100, за исключением того, что он разработан для совместимости с существующей инфраструктурой HGX H100 и обеспечивает максимально быстрое развертывание графических процессоров Blackwell. В результате TDP на графический процессор ограничен 700 Вт, как и у H100, а пропускная способность падает до FP4 при 14 петафлопс на графический процессор.
Стоит отметить, что среди трех чипов пропускная способность каждого графического процессора HBM3e составляет 8 ТБ/с. Таким образом, будут отличаться только мощность, частота ядра графического процессора и, возможно, количество ядер. Однако Nvidia не раскрыла никаких подробностей о том, сколько ядер CUDA или потоковых мультипроцессоров имеется в графических процессорах Blackwell.
NVLink пятого поколения и коммутатор NVLink 7.2T
Одним из ограничивающих факторов для рабочих нагрузок искусственного интеллекта и высокопроизводительных вычислений является пропускная способность межузлового соединения, необходимая для связи между различными узлами. По мере увеличения количества графических процессоров,Коммуникация становится серьезным узким местом,Вероятно, использовано 60% ресурсов и времени. Одновременно с запуском B200,Nvidia также выпустила NVLink NVLink 7.2T.
Новый чип NVLink имеет двунаправленную пропускную способность 1,8 ТБ/с и поддерживает 576 доменов NVLink графического процессора. Он также производится на узле N4P TSMC и имеет 50 миллиардов транзисторов. Чип также поддерживает 3,6 терафлопс Sharp v4 во внутрикристальных сетевых вычислениях, что помогает эффективно обрабатывать более крупные модели.


Предыдущее поколение NVSwitch поддерживало пропускную способность HDR InfiniBand до 100 ГБ/с, что было огромным шагом вперед. По сравнению с многоузловым соединением H100 новый NVSwitch обеспечивает ускорение в 18 раз. Это значительно улучшит масштабируемость сетей искусственного интеллекта с моделями в триллион параметров.
Кроме того, каждый графический процессор Blackwell оснащен 18 соединениями NVLink пятого поколения. Это в 18 раз больше ссылок H100. Обеспечивает двунаправленную пропускную способность 50 ГБ/с на канал или 100 ГБ/с на канал.
Сервер GB200 NVL72
NVIDIA также предоставляет готовые продукты для компаний с крупномасштабными потребностями.,Предоставляем комплексные серверные решения,Например Сервер GB200 НВЛ72, обеспечивает 36 ЦП и 72 Графический процессор с архитектурой Блэквелл и комплексное решение для интегрированного водяного охлаждения, которое может достичь в общей сложности 720 Производительность обучения ИИ в петафлопсах или 1440 петафлопс производительности вывода. Общая длина кабеля, используемого в нем, составляет почти 2 мили, в общей сложности 5000 отдельных кабелей.



В частности, GB200 NVL72 представляет собой комплексное стоечное решение с 18 серверами высотой 1U, каждый из которых оснащен двумя суперчипами GB200. Однако есть некоторые отличия от предыдущего поколения с точки зрения состава суперчипа GB200.
Просочившиеся изображения и характеристики показывают, что два графических процессора B200 соединены с процессором Grace, в то время как GH100 использует меньшее решение, сочетающее процессор Grace с графическим процессором H100. Конечным результатом является то, что вычислительный блок суперчипа GB200 будет оснащен двумя процессорами Grace и четырьмя графическими процессорами B200 с производительностью 80 петафлопс для вывода искусственного интеллекта FP4 и 40 петабайт для обучения искусственного интеллекта FP8. Это серверы высотой 1U с жидкостным охлаждением, которые занимают значительную часть обычного места в стойке из 42 модулей.
В дополнение к вычислительному лотку GB200 Super Chip, GB200 NVL72 также будет оснащен лотком для переключателей NVLink. Это также лотки жидкостного охлаждения высотой 1U, с двумя коммутаторами NVLink на лоток и девятью таких лотков на стойку. Каждый лоток обеспечивает общую пропускную способность 14,4 ТБ/с, а также вышеупомянутые вычисления Sharp v4.
GB200 NVL72 имеет в общей сложности 36 процессоров Grace и 72 графических процессора Blackwell с вычислительной мощностью FP8 720 ПБ и вычислительной мощностью FP4 1440 ПБ. NVIDIA заявляет, что благодаря многоузловой пропускной способности 130 ТБ/с NVL72 может обрабатывать до 27 триллионов моделей параметров AI LLM.

В настоящее время AWS Amazon планирует приобрести кластер серверов, состоящий из 20 000 чипов GB200, который сможет развертывать модели с 27 триллионами параметров. Помимо AWS от Amazon, среди пользователей серии Blackwell стали DELL, Alphabet, Meta, Microsoft, OpenAI, Oracle и TESLA.
Редактор: Core Intelligence — Меч Руруни



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
