Соревнование по производительности серверной части LLM, глубокая оценка от команды BentoML!
Эта статья переведена командой инженеров BentoML. Исходная ссылка: https://www.bentoml.com/blog/benchmarking-llm-inference-backends.
Выбор правильного механизма вывода для обслуживания больших языковых моделей (LLM) имеет решающее значение. Это не только гарантирует, что пользователи получат наилучшие впечатления за счет высокой скорости генерации, но также снижает затраты и повышает эффективность за счет высокой скорости генерации токенов и использования ресурсов. Сегодня разработчики могут выбирать из множества механизмов вывода, созданных известными исследовательскими и отраслевыми группами. Однако выбор лучшего бэкэнда для конкретного варианта использования может оказаться непростой задачей.
Чтобы помочь разработчикам принимать обоснованные решения, команда инженеров BentoML создала службы вывода Llama 3 на BentoCloud с использованием vLLM, LMDeploy, MLC-LLM, TensorRT-LLM и Hugging Face TGI, а также провела комплексное тестирование производительности вывода.
Эти механизмы вывода оцениваются с использованием следующих двух ключевых показателей:
- Time to First Token (TTFT):голова token Задержка, измеряемая от отправки запроса до создания первого token Затраченное время в миллисекундах. Для приложений, требующих мгновенной обратной связи (например, интерактивных чат-ботов), TTFT Очень важно. Снижение задержки может повысить воспринимаемую производительность и удовлетворенность пользователей.
- Token Generation Rate:token Скорость генерации, оценка Модель в decoding Этапы генерируются каждую секунду token количество, в token Единица измерения — в секунду. жетон Скорость генерации да измеряет способность Модели выдерживать высокие нагрузки по показателю. Высокая скорость генерации указывает на то, что Модель может эффективно обрабатывать несколько индивидуальных запросов и быстро генерировать ответы, что подходит для сред с высоким уровнем параллелизма.
1. Сравните основные идеи
Мы протестировали 4-битные квантованные модели Llama 3 8B и 70B в BentoCloud с использованием экземпляра графического процессора A100 емкостью 80 ГБ (gpu.a100.1x80), охватывая три различные рабочие нагрузки вывода (10, 50 и 100 одновременных пользователей). Вот некоторые из наших ключевых выводов:
Llama 3 8B
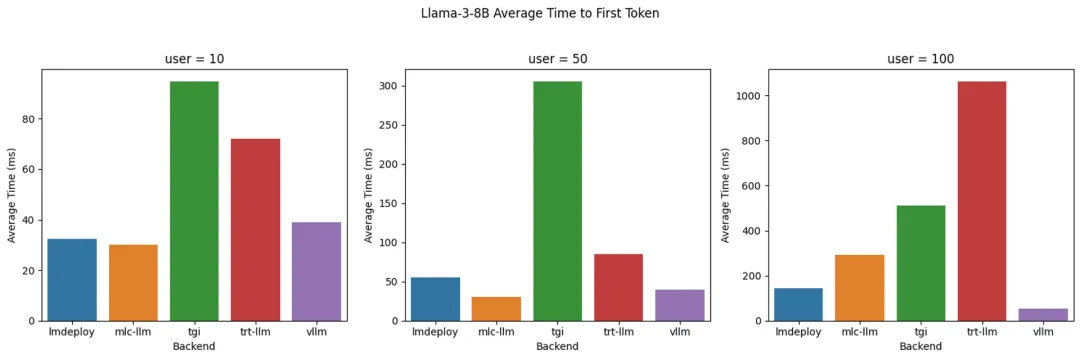
Llama 3 8B: токен времени до первого (TTFT) с разными серверными модулями
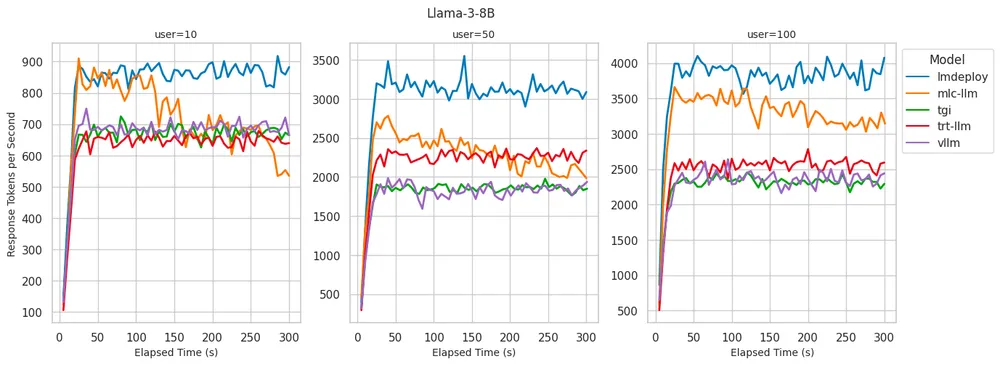
Llama 3 8B: Скорость генерации токенов для разных серверов
- LMDeploy:существовать token Лучшая производительность с точки зрения скорости генерации. для 100 одновременных пользователей, генерирующих до 4000 индивидуальный жетон. подарок 10 Достигайте лучших в своем классе результатов для всех пользователей ТТФТ. Хотя по мере увеличения количества пользователей TTFT будет постепенно увеличиваться,Но он всегда держится на низком уровне и в пределах допустимого.
- MLC-LLM:Достигнуто немного нижеиз decoding производительность,для 100 отдельные пользователи могут обработать ок. 3500 индивидуальный жетон. Однако при запуске теста 5 Через несколько минут производительность несколько упала, примерно до 3100 индивидуальный жетон. Когда количество пользователей достигнет 100 Когда,ТТФТ производительностьзначительно уменьшится。
- vLLM:существовать Лучший в своем классе результат на всех уровнях одновременного использованияиз TTFT производительность。нода,Что decoding производительностьи LMDeploy и MLC-LLM Немного уступает decoding 2300-2500 индивидуальный жетон, данный TGI и TRT-LLM похожий.
LLama3 70B 4-битное квантование
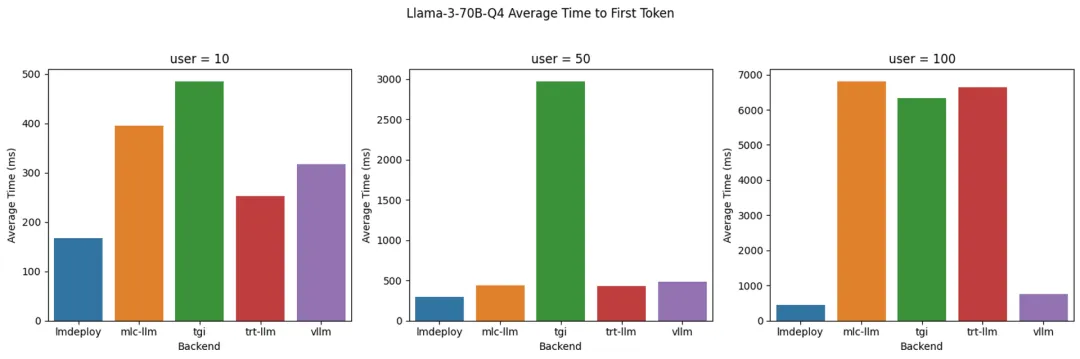
Llama 3 70B Q4: время до первого токена (TTFT) с разными серверными модулями
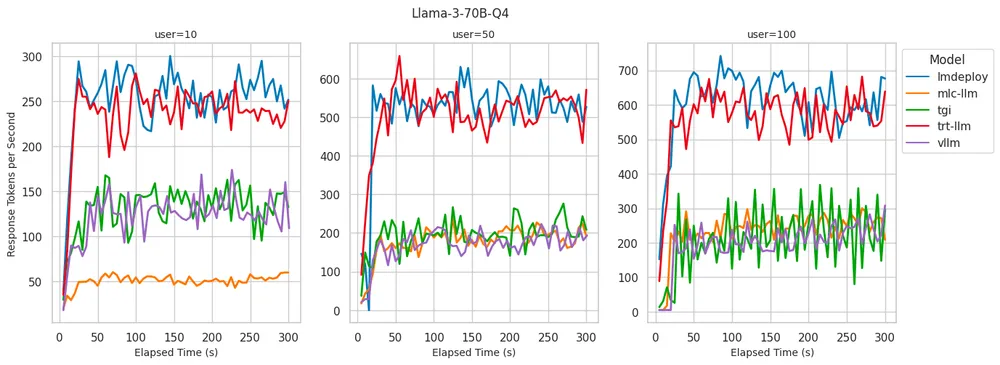
Llama 3 70B Q4: Скорость генерации токенов на разных бэкендах
- LMDeploy:существовать Служить 100 индивидуальный обеспечивает лучшее, когда пользователи token Скорость генерации, в секунду 700 токена, сохраняя при этом минимум на всех одновременных уровнях пользователя. TTFT。
- TensorRT-LLM:существовать token Скорость генерации показывает то же, что и LMDeploy Подобно изпроизводительности, она остается низкой, когда количество одновременных пользователей невелико. ТТФТ. Однако, когда количество одновременных пользователей достигает 100 Когда, ТТФТ значительно увеличился до 6 Более секунды.
- vLLM:существовать Стабильная производительность на всех одновременных уровнях пользователейиз Низкий TTFT, это то, что мы делаем в 8B См. Модель из ситуации похожа.По сравнению с LMDeploy и TensorRT-LLM, который генерирует token из скорости ниже, это может да Зависит из-за отсутствия таргетинга Количественная Оценка Моделизация происходит за счет оптимизации рассуждений.
Мы обнаружили сильную корреляцию между скоростью генерации токенов и использованием графического процессора при реализации серверной части вывода. Серверные системы, способные поддерживать высокую скорость генерации токенов, также демонстрируют почти 100% загрузку графического процессора. Напротив, серверная часть с низкой загрузкой графического процессора, по-видимому, ограничена процессом Python.
2. Помимо производительности
Помимо производительности, при выборе серверной части для служб LLM необходимо учитывать и другие важные факторы. Вот что, по нашему мнению, является ключевыми аспектами, которые следует учитывать при выборе идеального механизма вывода:
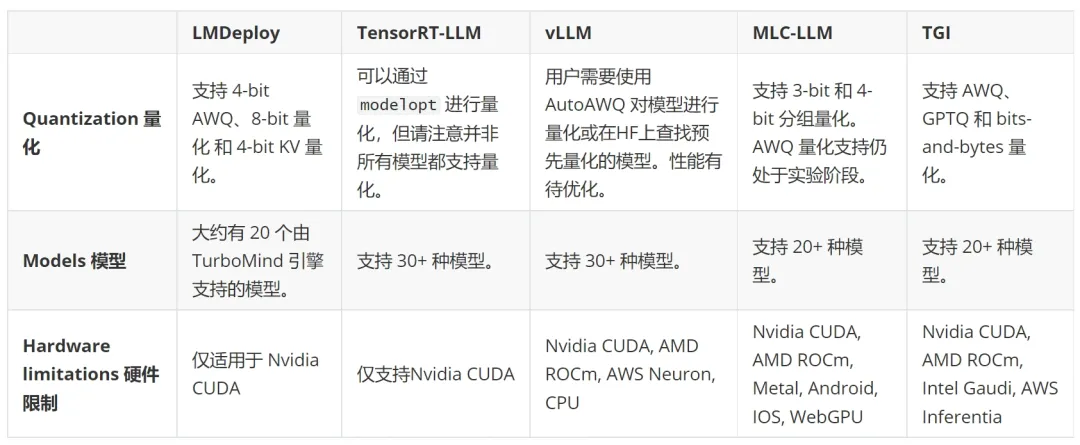
3. Опыт разработчика
Удобный для пользователя сервер вывода должен обеспечивать возможности быстрой разработки и высокую удобство сопровождения кода для приложений ИИ, работающих на LLM.
стабильная версия:LMDeploy、TensorRT-LLM、vLLM и TGI Оба предоставляют стабильные версии. MLC-LLM В настоящее время не существует стабильных выпусков с тегами, есть только ночные сборки. Одним из возможных решений является сборка из исходного кода.
Составлено Моделью:TensorRT-LLM и MLC-LLM Требуется явный этап компиляции модели, который может привести к дополнительным задержкам при холодном запуске во время развертывания.
документ:
- Полный документ по LMDeploy, vLLM и TGI включает примеры.,Легко учиться.
- MLC-LLM из Умеренная кривая обучения,Это главным образом потому, что нужно понимать Составлено Модельюшаг。
- В нашем тесте TensorRT-LLM из настроек самые сложные. Зависит от Поскольку хороших примеров мало,приходится читать TensorRT-LLM、tensorrtllm_backend и Triton Inference Server издокумент, конвертировать Модель, построить TRT двигатель и напишу много настроек.
4. Концепция
Llama 3
Llama 3 — это последняя версия серии Llama LLM, доступная в различных конфигурациях. В наших тестах мы использовали следующие размеры моделей.
- 8B:Должен Модельиметь 80 100 миллионов параметров, которые одновременно эффективны и просты в управлении вычислительными ресурсами. использовать FP16 , это занимает примерно 16GB из Память (не входит в комплект) KV Кэширование и другие накладные расходы), могут быть адаптированы для отдельных пользователей. A100-80G GPU Пример.
- 70B 4Кусочек Количественная оценка:Воляэтотиндивидуальныйиметь 70 100 миллионовиндивидуальныйпараметриз Модель Количественная оценкадля 4 Кусочек, который может значительно уменьшить объем памяти. Количественная Оценка сжимает модель за счет уменьшения количества параметров на одного человека, обеспечивая более высокую скорость вывода и меньшее использование памяти, сохраняя при этом минимальную производительность. использовать 4 Кусочек AWQ Количественная оценканазад,существоватьодининдивидуальный A100-80G Загрузка весовой модели на экземпляр занимает ок. 37 GB из RAM。существоватьодининдивидуальный GPU Услуги на устройстве Количественная Оценка задней части веса обычно обеспечивает лучшую пропускную способность для Моделииз, в то время как Воля Модель не очень хорошо подходит для обслуживания нескольких отдельных устройств.
BentoML и BentoCloud
- BentoML: унифицированная сервисная платформа из Модель, которая позволяет разработчикам использовать любой открытый или собственный код. AI Модель конструирует Модель рассуждения API Системы обслуживания нескольких моделей. Разработчики могут упаковать все зависимости, конфигурацию среды выполнения и конфигурацию среды выполнения в автономный модуль, называемый Bento。
- BentoCloud: для предприятий AI Команда из AI Платформа вывода, предоставляющая полностью управляемую инфраструктуру, настроенную для вывода моделей. Разработчики могут использовать его с BentoML Используется вместе для масштабируемого и безопасного развертывания. AI Модель и имеет расширенные функции, такие как автоматическое масштабирование, встроенная наблюдаемость и оркестровка нескольких моделей.
Мы обязательно используем BentoML Предоставление бэкэнда вывода и использования Python Изначально обеспечивает вывод назад По сравнению с частью, это лишь добавляет минимальные накладные расходы. Накладные расходы да Зависит от Обеспечивает расширение, наблюдаемость IO Функция сериализации. использовать BentoML и BentoCloud дает нам последовательный RESTful API, тем самым упрощая настройку производительностиидействовать。
Серверы вывода
Различные серверные части предоставляют разные способы обслуживания LLM, каждый метод имеет уникальные особенности и технологию оптимизации. Проверяем все рассуждениязадняя часть следовать Apache 2.0 лицензия.
- LMDeploy:рассуждениезадняя часть ориентирована на обеспечение высокого decoding Скорость и эффективная обработка одновременных запросов. Он поддерживает различные Количественные Технология повышения качества, подходящая для развертывания больших моделей с меньшими требованиями к памяти.
- vLLM:Служить LLM И оптимизированный механизм вывода производительности. он эффективно использует GPU Ресурсы и быстрота decoding Известен своими способностями.
- TensorRT-LLM:рассуждениезадняя часть воспользовалась NVIDIA из TensorRT (высокотехнологичная библиотека вывода глубокого обучения). Он направлен на NVIDIA GPU Оптимизирован для работы с большими моделями, обеспечивает быстрый вывод и поддерживает Количественную. оптимизация и другая расширенная оптимизация.
- Hugging Face Text Generation Inference (TGI):для развертыванияи Служить LLM из инструментария. это в Hugging Face из используется в производстве для Hugging Болтать, рассуждать API Конечная точка вывода обеспечивает поддержку.
- MLC-LLM:Применимо к LLM из ML Компилятор и высокопроизводительный механизм развертывания. он построен на Apache TVM Перед предоставлением модели необходимо выполнить компиляцию и преобразование веса.
BentoML легко интегрировать с различными серверными модулями вывода в самостоятельный хостинг LLM. Сообщество BentoML предоставляет следующие примеры проектов на GitHub, чтобы помочь вам в этом процессе.
BentoVLLM:
https://github.com/bentoml/BentoVLLM
BentoMLCLLM:
https://github.com/bentoml/BentoMLCLLM
BentoLMDeploy:
https://github.com/bentoml/BentoLMDeploy
BentoTRTLLM:
https://github.com/bentoml/BentoTRTLLM
BentoTGI:
https://github.com/bentoml/BentoTGI
5. Настройка бенчмарка
Мы настроили тестовую среду следующим образом.
Модель
мы тестировали Meta-Llama-3-8B-Instruct и Meta-Llama-3-70B-Instruct 4-bit Количественная оценка Модель。для 70B Модель, которую мы выполнили 4-bit квантовано так, что его можно измерить за один A100-80G GPU беги дальше. Если механизм вывода поддерживает собственное квантование, мы будем использовать метод квантования, предоставляемый механизмом вывода. Например, для MLC-LLM, мы используем q4f16_1 Количественная схема. В противном случае мы используем Hugging Face из AWQ Количественная оценка casperhansen/llama-3-70b-instruct-awqМодель。
Обратите внимание, что в дополнение к использованию общих методов оптимизации вывода (например, непрерывной пакетной обработки, флэш-памяти) attention и префиксный кеш), мы не нацелены на каждую индивидуальную заднюю часть Тонкая настройка конфигурации вывода (GPU Использование памяти, максимальное количество последовательностей, подкачка KV размер блока кэша и т. д.). Это потому, что с нашим сервисом LLM По мере роста числа этот подход не масштабируется. Обеспечить оптимальный набор параметров вывода дазадняя частьпроизводительности простота использования является неявной мерой.
Тестовый клиент
Мы создали собственный сценарий тестирования. Скрипт имитирует реальный сценарий, варьируя пользовательскую нагрузку и отправляя запросы на сборку на разных уровнях параллелизма.
Наш тестовый клиент доступен по адресу 20 Создайте целевое количество пользователей в течение нескольких секунд, после чего он ответит, отправив случайно выбранное слово-подсказку и сгенерировав запрос. LLM задняя часть провести стресс-тест. мы тестировали 10、50 и 100 отдельные одновременные пользователи для оценки производительности системы при различных нагрузках.
Каждый стресс-тест длился 5 минут.,в этот период,Мы собираем метрики вывода каждые 5 секунд. Этой продолжительности достаточно, чтобы наблюдать потенциальную деградацию, узкие места в использовании ресурсов или другие проблемы, которые могут не проявляться в более коротких тестах.
Для получения дополнительной информации ознакомьтесь с исходным кодом нашего Тестового клиента: https://github.com/bentoml/llm-bench.
Набор данных подсказки слова
Мы из тестового слова да из databricks-dolly-15k Извлечение набора данных из. для каждого индивидуального сеанса тестирования мы случайным образом выбираем слова-подсказки из этого набора данных. Мы также протестировали генерацию текста с системными подсказками и без системных подсказок. какой-то задний часть может оптимизировать общие сценарии системных подсказок, включив кэширование префиксов.
Версии библиотеки
- BentoML: 1.2.16
- vLLM: 0.4.2
- MLC-LLM: mlc-llm-nightly-cu121 0.1.dev1251 (No stable release yet)
- LMDeploy: 0.4.0
- TensorRT-LLM: 0.9.0 (with Triton v24.04)
- TGI: 2.0.4
6. Предложения
LLM Область оптимизации вывода быстро развивается и получила обширные исследования. Лучшие сегодняшние рассуждения назад часть вскоре может быть потеснена новичками. На основе сравнительного анализа и исследований юзабилити, проведенных на момент написания этой статьи, мы протестировали Llama 3 Модель Выберите наиболее подходящую иззаднюю частьпредложил следующеепредположение。
Llama 3 8B
для Llama 3 8B Модель,LMDeploy Всегда обеспечивайте более низкую нагрузку при всех пользовательских нагрузках. TTFT и Самый высокийиз token Скорость генерации. Это простота использования — еще одно важное преимущество отдельного человека, поскольку оно может динамически конвертировать Воля Модель в TurboMind движок, тем самым упрощая процесс развертывания. На момент написания LMDeploy Механизм внимания для использования скользящего окна из Модели (например. Mistral и Qwen 1.5) Предоставляется ограниченная поддержка.
Даже при увеличении пользовательской нагрузки vLLM Его также всегда можно поддерживать на низком уровне. TTFT, что делает его подходящим для сценариев, где важно поддерживать низкую задержку. vLLM Предлагает простую интеграцию, обширную поддержку и широкую совместимость с оборудованием, и все это с легкостью. Мощный и поддерживается сообществом открытого исходного кода.
MLC-LLM Обеспечивает самую низкую производительность при меньшей пользовательской нагрузке TTFT и первоначально остается высоким decoding скорость. После длительного периода стресс-тестирования decoding Скорость значительно упала. Несмотря на эти проблемы, MLC-LLM По-прежнему демонстрирует большой потенциал. Решите эти проблемы производительности и внедрите стабильную версия может значительно повысить ее эффективность.
Llama 3 70B 4-bit Количественная оценка
дляLlama 3 70B 4 bit Количественная оценка,LMDeploy Впечатляющая производительность при любых пользовательских нагрузках, TTFT самый низкий. Он также поддерживает более высокий token Скорость генерации делает его идеальным для приложений, требующих низкой задержки и высокой пропускной способности. ЛМДеплой еще и потому, что Что Выделитесь простотой использования,он можетсуществовать Не требуется обширная настройка или компиляция.издело быстро Преобразовать модель,Это делает его идеальным для сценариев быстрого развертывания.
TensorRT-LLM По пропускной способности это то же самое, что и LMDeploy Сопоставимо, но производительность задержки не так хороша в сценариях с высокой пользовательской нагрузкой. LMDeploy. потому что TensorRT-LLM Зависит от Nvidia Поддержка, мы ожидаем, что эти пробелы будут устранены в ближайшее время. Однако у него есть неотъемлемые требования к компиляции Модели и к Nvidia CUDA GPU Это зависит от намеренного выбора дизайна, который может привести к ограничениям при развертывании.
vLLM Возможность оставаться на низком уровне при увеличении пользовательской нагрузки TTFT, простота использования является существенным преимуществом для многих пользователей. Однако на момент написания этой статьи задняя часть частьдля AWQ Количественная Оценка качества не оптимизирована в достаточной степени, что приводит к Количественной оценка Модельиз decoding Производительность далека от идеала.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
