Сора = Диффузия + Трансформатор, причина взрыва в том, как сэкономить вычислительные затраты!
Не будет преувеличением сказать, что Sora — самая громкая генеративная модель с 2024 года. Ее возможности и эффект по генерации видео ошеломляют.

Во многих статьях представлены прикладной и презентационный уровни Sora, но объяснения лежащих в их основе принципов недостаточно.
В этой статье давайте раскроем тайну Sora и познакомимся с ее основной технологией.
Деконструкция DiT
Грубо говоря, Sora — это диффузная модель, построенная на технологии DiT.
Как мы знаем, ChatGPT основан на модели Transformer — модели глубокого обучения, основанной на механизме самообслуживания.
Расширение DiT Sora: Diffusion Transformer, Sora = Diffusion + Transformer. Эта дополнительная модель диффузии может не только обеспечить качество генерации изображений, сравнимое с GAN, но также имеет лучшую масштабируемость и вычислительную эффективность.
Если вы раньше использовали и понимали стабильную диффузию, у вас должно сложиться впечатление о модели диффузии:

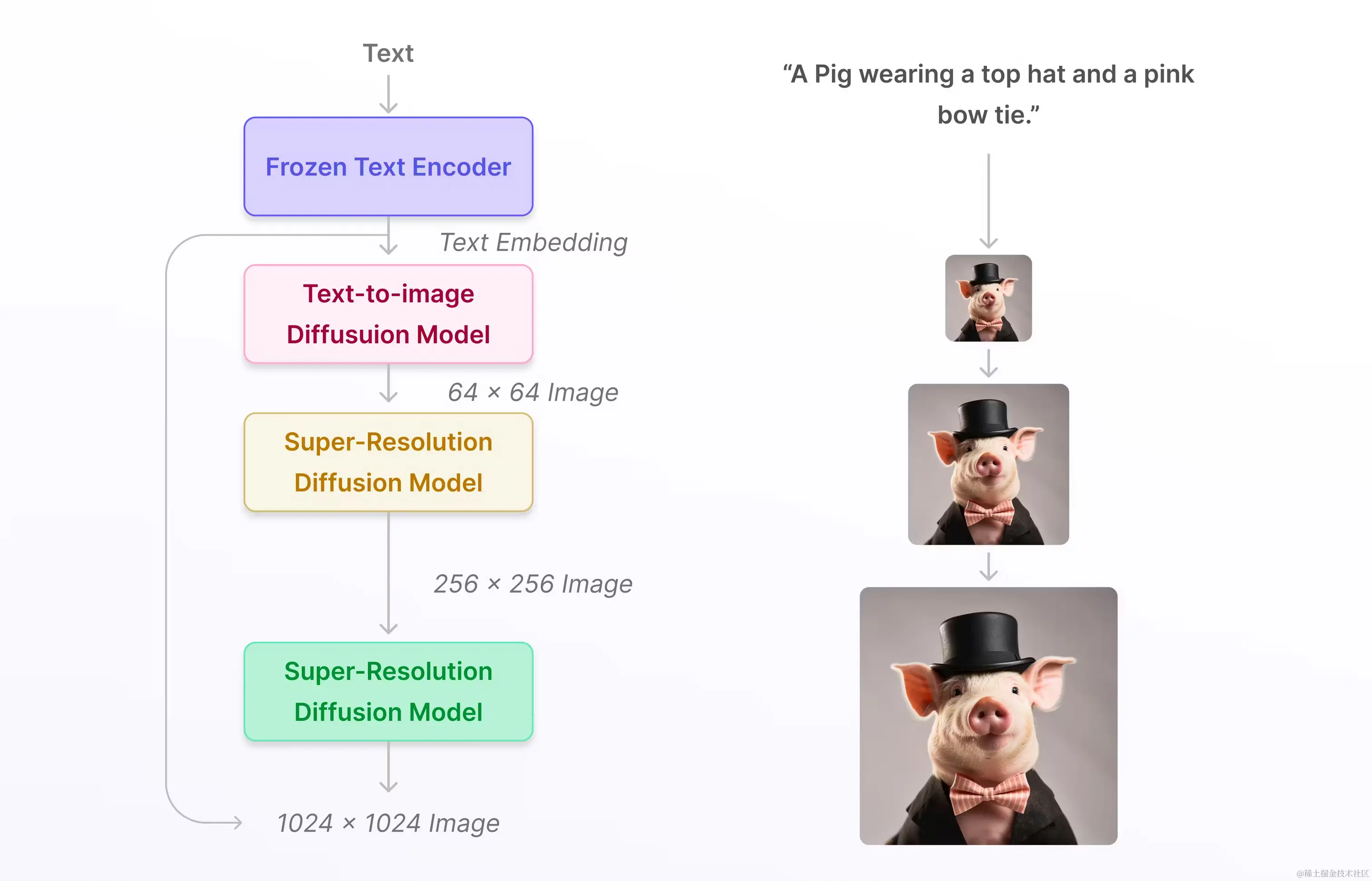
Модель диффузии — это генеративная модель на основе шума, которая имитирует распределение данных путем постепенного добавления шума, а затем изучает обратный процесс для удаления шума для создания новых данных.
В Sora DiT способен синтезировать высококачественные изображения, легко модифицируется и обеспечивает низкие вычислительные затраты.
Сейчас, когда вычислительная мощность настолько дорога, стоимость вычислений действительно важна~
Картинка стоит тысячи слов:
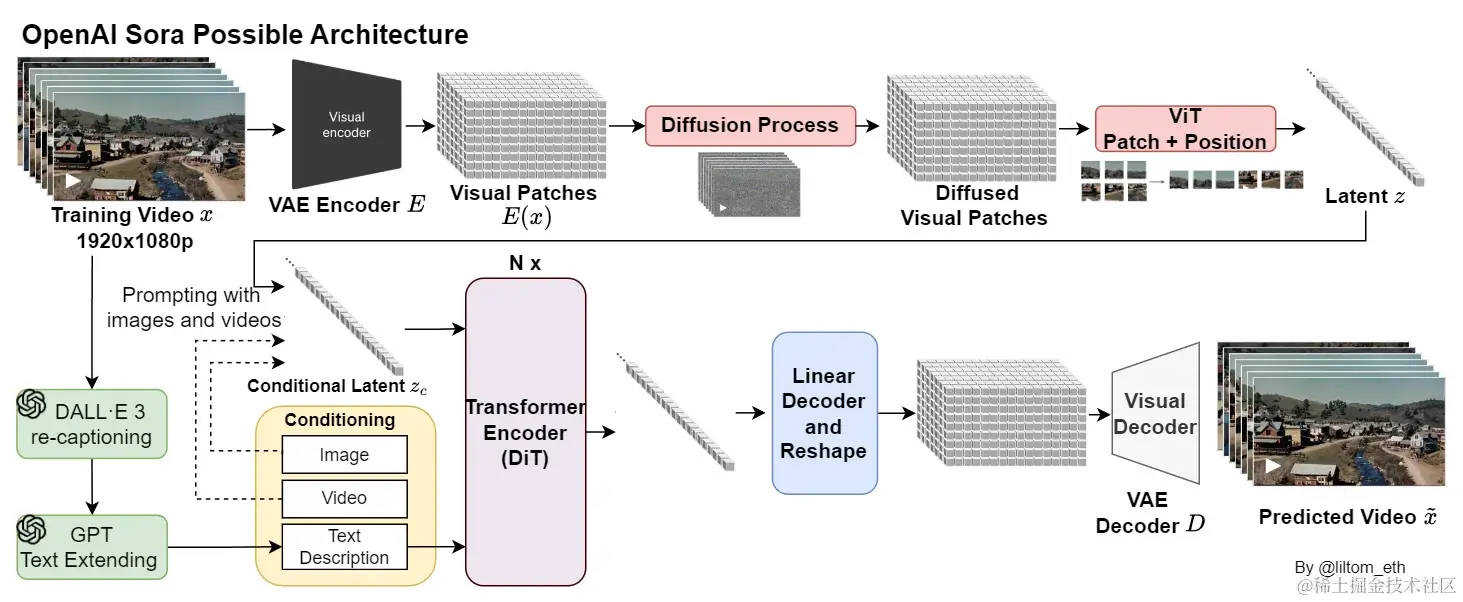
DiT включать кодер VAE、ViT、DDPM и декодер VAE,Эти компоненты:
- кодер VAE:VAE да Генеративная модель, используемая для сопоставления входных данных со скрытым пространством существования в низкомерном представлении.
- Роль в DiT: DiT использовать кодер VAE сжимает изображение в низкоразмерное представление, чтобы его можно было обучать в низкоразмерном пространстве. DDPM Модель, наличие которой помогает снизить вычислительные затраты и повысить эффективность.
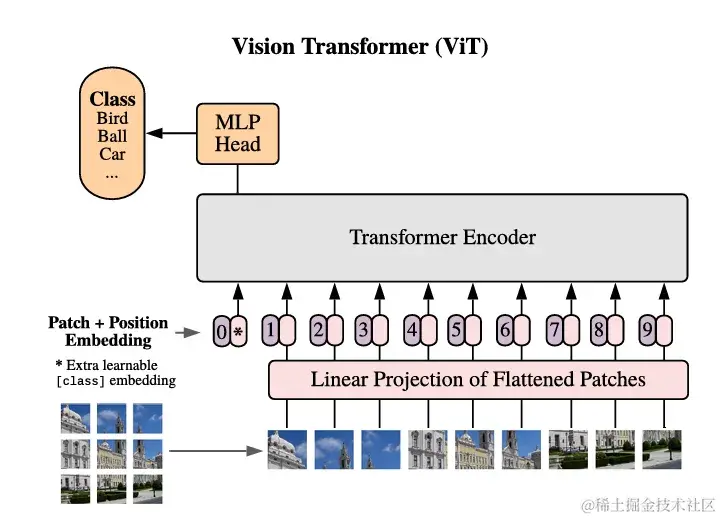
- ViT:ViT Да, я основе Transformer Модель классификации изображений, которая делит изображение на однородные фрагменты и использует механизм самообслуживания для обработки этих фрагментов.
- Роль в DiT:DiT Узнал от ViT Идея состоит в том, чтобы разделить изображение на несколько размеров. p × p патч, а затем преобразовать его в длину T последовательность как Transformer вход. Это делает DiT Возможность обработки изображений различного разрешения, продолжительности и соотношения сторон.
- DDPM:DDPM да Одноклассовая модель глубокой генерации имитирует распределение данных, постепенно добавляя шум, а затем обучается обратному процессу для удаления шума, тем самым генерируя новые изданные данные.
- Роль в DiT:DiT на основе DDPM Технология создана для моделирования распределения данных изображения путем постепенного добавления шума, а затем обучения обратному процессу для удаления шума, тем самым генерируя изображения высокого качества.
- декодер VAE:декодер VAE отображает скрытое пространство существования в низкоразмерном представлении обратно в исходное пространство данных, тем самым создавая реконструированное изображение.
- Роль в DiT:DiT использовать декодер VAE отображает низкоразмерное представление обратно в пространство изображений для создания окончательного высококачественного изображения.
Вместе эти компоненты составляют модель DiT, позволяющую генерировать реалистичные и творческие сценарии на основе текстовых инструкций.
Patchify
Patchify Технологии также являются ключевым словом, которое невозможно обойти, и они являются ключом к высококачественным видео!
Patchify — это метод, который разбивает изображение на несколько фрагментов размером p × p и преобразует их в последовательность длиной T в качестве входных данных для Transformer.

Sora использовать Patchify Разделите изображение на небольшие фрагменты и преобразуйте эти фрагменты в последовательности для ввода в обработку. Transformer в модели. Преимущество этого в том, что Сора Может обрабатывать разные разрешения, продолжительность, соотношение сторон и видеоизображение.
Эксперименты показали, что чем больше обучающая модель, тем лучше патч. size (p) Чем меньше (Прямо сейчас Увеличение глубины/ширины преобразователя или увеличение количества входных токенов) — может значительно улучшить визуальное качество.

на основе patch выражено таким образом, что Sora Возможность обучать изображения разного разрешения, длительности и соотношения сторон. Мы можем организовать случайную инициализацию из существования сетки соответствующего размера. patches для управления размером создаваемого видео.
DiT block
После исправления входные токены обрабатываются серией блоков преобразователей. Помимо ввода зашумленного изображения, диффузионные модели иногда обрабатывают дополнительную условную информацию, такую как временной шаг шума t, метка класса c, естественный язык и т. д.
DiT block Содержит уровень самообслуживания, уровень спецификации уровня и сетевой уровень прямой связи. Среди них есть четыре варианта хата, такие как in-context conditioning、cross-attention、adaptive layer norm (adaLN) и adaLN-Zero。
DiT(Diffusion Transformer) Четыре варианта отличаются тем, как они реализуют два дополнительных встраивания:
- In-context conditioning: Рассматривайте два внедрения как два токена, объединенные во входные токены. Похоже на: ViT в cls отметка. Реализация проста и практически не требует дополнительных вычислений.
- Cross-attention блок: объединить два вложения в длину 2 изпоследовательность,Затемсуществовать Transformer В блок вставляется слой перекрестного внимания. Условные вложения как ключи слоев перекрестного внимания. Этот метод в настоящее время используется для генерации изображений Модели, но требует дополнительного введения около 15% сумма расчета.
- Adaptive layer norm (adaLN) : Адаптивный уровень Стандартизации (adaLN) для объединения двух вложений. АХр Параметры стандартизации могут автоматически корректироваться в соответствии с различными входными образцами.
- AdaLN-Zero: да adaLN вариант . и adaLN Аналогично, но существует, устанавливает нулевое среднее значение одного из вложений при вычислении параметра Стандартизировать. Такой способ существования обеспечивает производительность при одновременном снижении вычислительных затрат.
Эти варианты имеют разные компромиссы при обработке двух дополнительных вложений, и разработчики могут выбрать вариант, который соответствует потребностям их конкретных задач.
Размер модели
transformer block По структуре (4 структуры) иметь 4 种Размер модели (S,B,L,XL) соответственно DiT-S、DiT-B、DiT-L и DiT-XL。
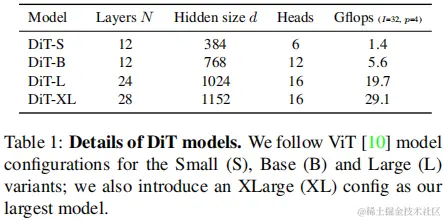
Эти четыре конфигурации отличаются количеством слоев, скрытыми размерами и объемом вычислений.
возможностииз Одноклассники могут на основе Провести обучение выше:
- существовать ImageNet данные условия обучения на съемочной площадке из DiT Модель в разрешении 256 × 256 и 512 × 512。использовать AdamW Оптимизатор, скорость обучения 1 × 10^-4, вес уменьшается до 0, размер пакета 256。
- Распространение: использовать предварительное обучение из вариационного самокодера. (VAE) Закодируйте изображение в низкоразмерное представление и затем существуйте. VAE обучение погружению в космос DiT Модель。
краткое содержание
Детали реализации ключевых технологий Sora поразительны! Видно, что при продвижении и развитии технологий затраты должны строго контролироваться. Для больших моделей самая большая стоимость — это экономия вычислительных затрат! 🚀
если ты прав Sora Если вам интересно, вы можете узнать больше о DiT идиффузия Модельиз Знание。🚀
Хорошо, это вышеизложенное, надеюсь, оно вам понравится~ Добро пожаловать, ставьте лайки, собирайте и комментируйте 🤟 Я Энтони 🤠 Популярный технологический блоггер 💥 Продолжайте обновлять статьи в течение тысячи дней ✍ Следуйте за мной, Энтони будет сопровождать вас на протяжении долгих лет программирование
ссылка:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
