Слишком сильно! Топ-10 моделей глубокого обучения!
Прошло почти 20 лет с тех пор, как в 2006 году была предложена концепция глубокого обучения. Будучи революцией в области искусственного интеллекта, глубокое обучение породило множество влиятельных алгоритмов или моделей. Итак, какие модели глубокого обучения вы считаете лучшими? Добро пожаловать, чтобы оставить сообщение в области комментариев для обсуждения ~
Ниже приведены 10 лучших моделей глубокого обучения, на мой взгляд. Все они занимают важное место с точки зрения инноваций, ценности приложений и влияния.
1. Глубокая нейронная сеть (DNN)
фон:глубинанейронная сеть (DNN), также называемая многослойным персептроном, является наиболее распространенной глубокой сетью. обучениеалгоритм,В начале своего изобретения оно было поставлено под сомнение из-за узкого места в вычислительной мощности.,Прорывы были достигнуты только после резкого роста вычислительных мощностей и данных в последние годы.
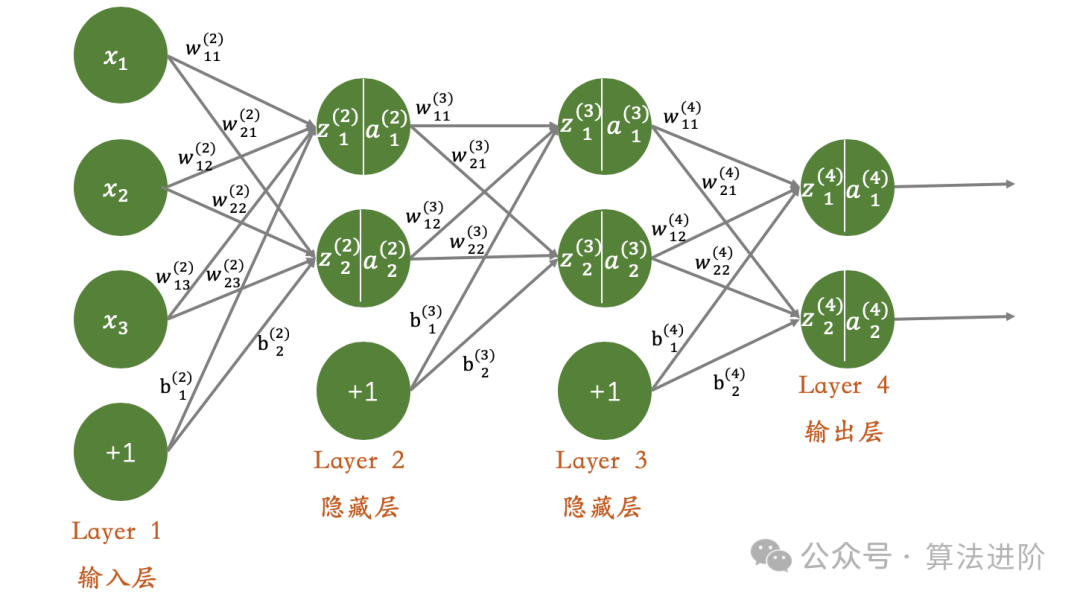
Принцип модели:глубинанейронная Сеть (DNN) — это нейронная сеть, построенная на нескольких скрытых слоях. сеть。Каждый уровень играет роль передатчика и процессора информации.,Преобразуйте входные данные в более выразительное представление объекта с помощью функции нелинейной активации. Именно эти непрерывные нелинейные преобразования,Это позволяет DNN улавливать глубокие и сложные особенности входных данных.
Модельное Обучение: Обновление веса DNN в основном основано на алгоритме обратного распространения ошибки и алгоритме оптимизации градиентного спуска. В спортивном процесссередина,проходить Рассчитать потерифункция О градиенте весов,Повторное использование градиентного спуска или другие стратегии оптимизации.,Постепенно корректируйте значения веса.,Для достижения цели минимизации потерь функция.
Преимущества: благодаря своим мощным возможностям обучения и представления функций DNN может эффективно изучать сложные функции входных данных и точно фиксировать нелинейные взаимосвязи, что обеспечивает хорошие результаты в различных задачах.
Недостатки: Однако по мере увеличения количества сетевых слоев постепенно становится очевидной проблема исчезновения градиента, что может привести к нестабильности процесса обучения. Кроме того, DNN склонны застревать в локальных минимумах, что ограничивает их производительность, и для решения этих проблем обычно требуются сложные стратегии инициализации и методы регуляризации.
Сценарии использования: DNN широко используется во многих областях, включая классификацию изображений, распознавание речи, обработку естественного языка и системы рекомендаций.
Пример кода Python:
import tensorflow as tf
from tensorflow.keras.datasets import iris
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Загрузка набора данных о цветке ириса
(x_train, y_train), (x_test, y_test) = iris.load_data()
# Предварительная обработка данных
y_train = tf.keras.utils.to_categorical(y_train) # Преобразование тегов в горячее кодирование
y_test = tf.keras.utils.to_categorical(y_test)
# создаватьнейронная сеть Модель
model = Sequential([
Dense(64, activation='relu', input_shape=(4,)), # Входной слой, имеет 4 входных узла
Dense(32, activation='relu'), # Скрытый слой, имеет 32 узла.
Dense(3, activation='softmax') # Выходной слой имеет 3 узла (соответствующие 3 типам цветов ириса).
])
# Скомпилировать модель
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Модель обучения
model.fit(x_train, y_train, epochs=10, batch_size=32)
# Тестовая модель
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print('Test accuracy:', test_acc)2. Сверточная нейронная сеть (CNN).
Принцип модели:свертканейронная (CNN) — нейронная сеть, специально предназначенная для обработки изображений и данных. сеть,Ленет, разработанный г-ном Лечуном, является новаторской работой CNN. CNN фиксирует локальные объекты, используя сверточные слои.,И уменьшите размерность данных с помощью уровня объединения. Сверточный слой выполняет локальную операцию свертки над входными данными.,И используйте механизм совместного использования параметров, чтобы уменьшить количество параметров в модели. Слой объединения снижает дискретизацию выходных данных сверточного слоя.,Уменьшить размерность и вычислительную сложность данных. Эта структура особенно подходит для обработки данных изображений.
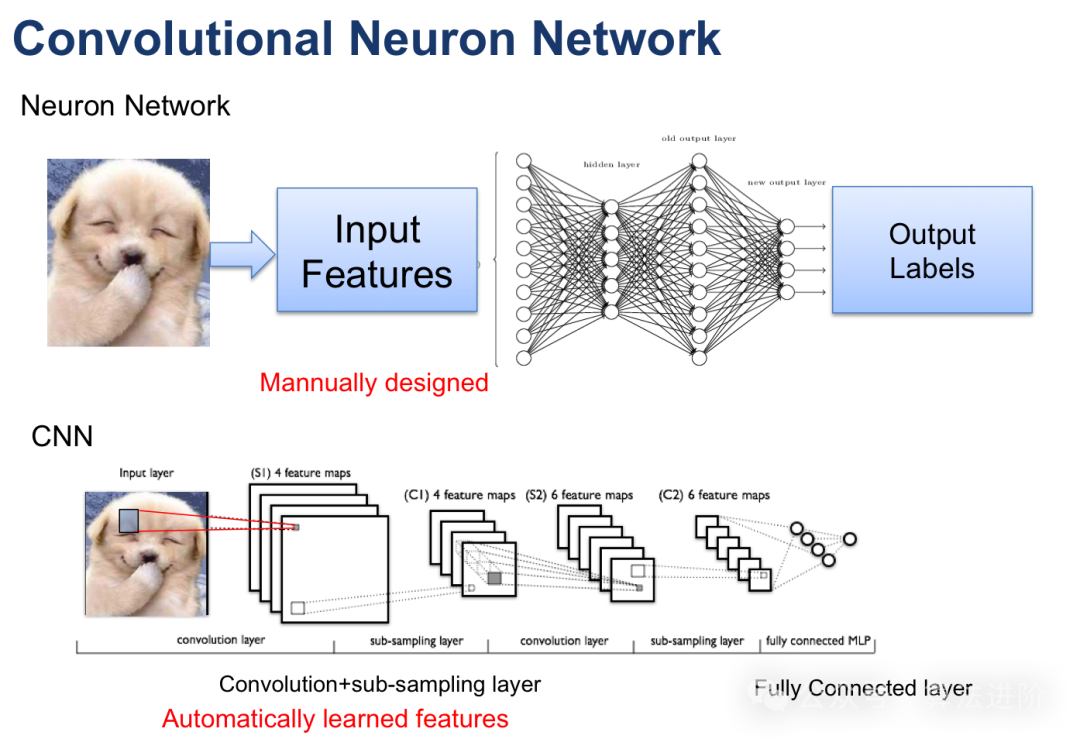
Модельное Обучение: Используйте алгоритм обратного распространения ошибки и стратегию оптимизации градиентного спуска для непрерывной корректировки весов. В спортивном процесссередина,Точный Рассчитать потерифункция О градиенте весов,С помощью градиентного спуска или других продвинутых алгоритмов оптимизации.,Точно отрегулируйте вес,Разработан для минимизации потерьфункция,Улучшена точность модели.
Преимущества: эта модель хорошо справляется с обработкой данных изображений и особенно хороша при улавливании локальных тонких особенностей. Благодаря оптимизированному дизайну параметров риск переобучения эффективно снижается и улучшается способность модели к обобщению.
Ограничения: Эта модель может не подходить для данных последовательности или задач, требующих зависимостей на больших расстояниях. Кроме того, чтобы гарантировать входное качество модели, может потребоваться утомительная работа по предварительной обработке исходных данных.
Применимые сценарии: эта модель хорошо работает в задачах обработки изображений, таких как классификация изображений, обнаружение целей и семантическая сегментация, и может обеспечить надежную поддержку связанных приложений.
Пример кода Python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Установить гиперпараметры
input_shape = (28, 28, 1) # Предположим, что входное изображение представляет собой изображение в оттенках серого размером 28x28 пикселей.
num_classes = 10 # Предположим, есть 10 категорий.
# Создать CNNМодель
model = Sequential()
# Добавьте слой свертки, 32 ядра свертки 3x3, используйте функцию активации ReLU.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=input_shape))
# Добавьте слой свертки, 64 ядра свертки 3x3, используйте функцию активации ReLU.
model.add(Conv2D(64, (3, 3), activation='relu'))
# Добавьте максимальный слой пула с окном пула 2x2.
model.add(MaxPooling2D(pool_size=(2, 2)))
# Сведение многомерных входных данных в одно измерение для ввода в полностью связный слой.
model.add(Flatten())
# Добавьте полносвязный слой, 128 нейронов и используйте функцию активации ReLU.
model.add(Dense(128, activation='relu'))
# Добавьте выходной слой, 10 нейронов, используйте функцию активации softmax для мультиклассификации
model.add(Dense(num_classes, activation='softmax'))
# Скомпилировать модель,Использование перекрестной энтропии в качестве функции потерь,использоватьAdamоптимизацияустройство
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Распечатать структуру модели
model.summary()3. Остаточная сеть (ResNet)
Благодаря быстрому развитию глубокого обучения глубокие нейронные сети добились замечательных успехов во многих областях. Однако обучение глубоких нейронных сетей сталкивается с такими проблемами, как исчезновение градиента и деградация модели, что ограничивает глубину и производительность сети. Для решения этих проблем была предложена остаточная сеть (ResNet).
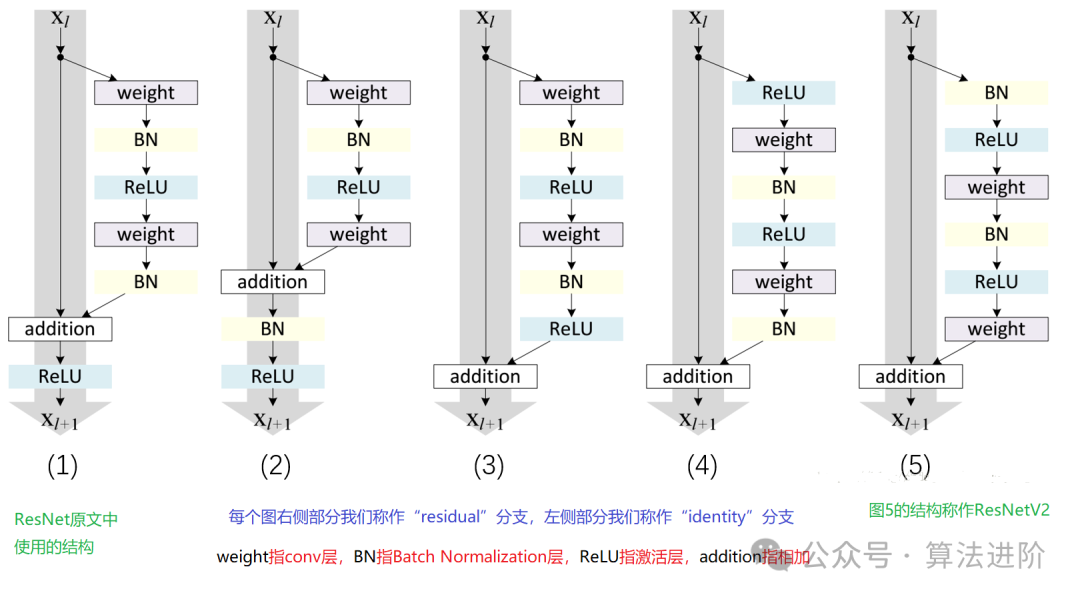
Принцип модели:
ResNet благодаря своему уникально разработанному «остаточному блоку» преодолевает две основные проблемы исчезновения градиента и деградации модели, с которыми сталкиваются глубокие нейронные сети. Остаточный блок умело сочетает «пропуск соединений» с несколькими нелинейными слоями, позволяя плавно переносить градиенты обратно из глубоких слоев в мелкие, что значительно улучшает эффект обучения глубоких сетей. Именно это нововведение позволяет ResNet строить чрезвычайно глубокие сетевые структуры и демонстрировать отличную производительность во многих задачах.
Модельное обучение:
При обучении ResNet обычно используются алгоритм обратного распространения ошибки и алгоритмы оптимизации, такие как стохастический градиентный спуск. В процессе обучения рассчитывается градиент функции потерь по отношению к весам, а веса корректируются с помощью алгоритма оптимизации для минимизации функции потерь. Чтобы еще больше повысить скорость обучения и способность модели к обобщению, мы также будем использовать такие стратегии, как технология регуляризации и ансамблевое обучение.
преимущество:
- Прорыв исчезновения градиента и деградации модели: с введением остаточных блоков и пропусков связей,ResNet успешно решает задачу обучения глубоких сетей,Эффективно избегайте исчезновения градиента и явлений деградации модели.
- Построение глубокой сетевой структуры: за счет преодоления исчезающего градиента и проблем деградации модели,ResNet может построить более глубокую сетевую структуру,Значительно улучшена производительность Модели.
- Отличная производительность в многозадачном режиме: благодаря мощным возможностям обучения и представления функций ResNet продемонстрировала отличную производительность в различных задачах, таких как классификация изображений и обнаружение целей.
недостаток:
- Высокие требования к вычислительным ресурсам: поскольку ResNet обычно необходимо построить глубокую сетевую структуру, объем вычислений огромен, и к нему предъявляются высокие требования к вычислительным ресурсам и времени обучения.
- Настройка параметров сложна: ResNet имеет большое количество параметров, что требует много времени и энергии для настройки параметров и выбора гиперпараметров.
- Чувствителен к весам инициализации: ResNet очень чувствителен к выбору весов инициализации. Неправильная инициализация может привести к таким проблемам, как нестабильное обучение или переобучение.
Сценарии применения:
ResNet имеет обширную прикладную ценность в области компьютерного зрения, например, для классификации изображений, обнаружения целей, распознавания лиц и т. д. Кроме того, он также имеет определенный потенциал применения в таких областях, как обработка естественного языка и распознавание речи.
Пример кода Python(Упрощенная версия):
from keras.models import Sequential
from keras.layers import Conv2D, Add, Activation, BatchNormalization, Shortcut
def residual_block(input, filters):
x = Conv2D(filters=filters, kernel_size=(3, 3), padding='same')(input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=filters, kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return Add()([x, input]) # Add shortcut connection
# Создание модели ResNet
model = Sequential()
# Добавьте входной слой и другие необходимые слои.
# ...
# Добавить остаточный блок
model.add(residual_block(previous_layer, filters=64))
# Продолжайте добавлять остаточные блоки и другие слои.
# ...
# Добавить выходной слой
# ...
# Составление и модель обучения
# model.compile(...)
# model.fit(...)4. LSTM (сеть с длинной краткосрочной памятью)
При обработке данных последовательности традиционные рекуррентные нейронные сети (RNN) сталкиваются с такими проблемами, как исчезновение градиента и деградация модели, которые ограничивают глубину и производительность сети. Для решения этих проблем был предложен LSTM.
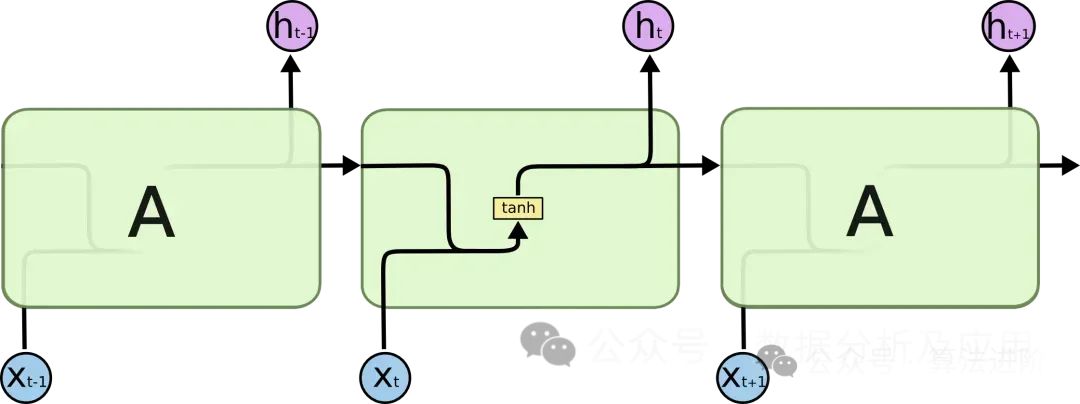
Принцип модели:
LSTM использует инновационный механизм «ворот» для умелого регулирования потока информации, тем самым преодолевая две основные проблемы: исчезновение градиента и деградацию модели. В частности, LSTM имеет три основных механизма вентилирования: входной вентиль, вентиль забывания и выходной вентиль. Входной вентиль отвечает за фильтрацию и прием новой информации, вентиль забывания определяет, какая старая информация должна быть отброшена, а выходной вентиль управляет конечным выходным информационным потоком. Именно эти изысканные механизмы шлюзования позволяют LSTM демонстрировать отличную производительность при решении проблем долгосрочных зависимостей.
Модельное обучение:
В процессе обучения LSTM обычно используется комбинация алгоритма обратного распространения ошибки и алгоритма оптимизации (например, стохастического градиентного спуска). В процессе обучения алгоритм точно рассчитает градиент функции потерь по отношению к весу и использует алгоритм оптимизации для непрерывной корректировки веса, чтобы минимизировать функцию потерь. Чтобы еще больше повысить эффективность обучения и способность к обобщению модели, вы также можете рассмотреть возможность использования передовых стратегий, таких как технология регуляризации и ансамблевое обучение.
преимущество:
- Преодоление исчезновения градиента и деградации модели: путем введения вентильного механизма,LSTM хорошо справляется с решением долгосрочных проблем зависимостей.,Это эффективно позволяет избежать проблем исчезновения градиента и деградации модели.
- Постройте глубокую сетевую структуру: получите выгоду от обработки исчезновения градиента и деградации модели.,LSTM может создавать глубокие и огромные сетевые структуры.,Чтобы полностью изучить внутренние законы данных,Улучшите производительность модели.
- Отличная производительность в многозадачном режиме: LSTM продемонстрировал отличную производительность в ряде задач, таких как генерация текста, распознавание речи и машинный перевод, доказывая свои мощные возможности обучения и представления функций.
недостаток:
- Настройка параметров — большая проблема: LSTM включает в себя большое количество параметров, а процесс настройки громоздкий, требующий много времени и энергии для выбора и настройки гиперпараметров.
- Чувствителен к инициализации: LSTM чрезвычайно чувствителен к инициализации весов. Неправильная инициализация может привести к нестабильному обучению или проблемам с перенастройкой.
- Большой объем вычислений. Поскольку LSTM обычно создает глубокую сетевую структуру, объем вычислений огромен и требует больших вычислительных ресурсов и времени на обучение.
Сценарии использования:
В области обработки естественного языка LSTM опирается на свои уникальные преимущества и широко используется в таких задачах, как генерация текста, машинный перевод и распознавание речи. Кроме того, LSTM также продемонстрировал большой потенциал в таких областях, как анализ временных рядов и системы рекомендаций.
Пример кода Python(Упрощенная версия):
Pythonfrom keras.models import Sequential
from keras.layers import LSTM, Dense
def lstm_model(input_shape, num_classes):
model = Sequential()
model.add(LSTM(units=128, input_shape=input_shape)) # Добавьте слой LSTM
model.add(Dense(units=num_classes, activation='softmax')) # Добавьте полностью связанный слой
return model5、Word2Vec
Модель Word2Vec — это новаторская работа в области обучения представлениям. (Поверхностная) модель нейронной сети для обработки естественного языка, разработанная учеными Google. Цель модели Word2Vec — векторизовать каждое слово в вектор фиксированного размера, чтобы похожие слова можно было сопоставить с похожими векторными пространствами.
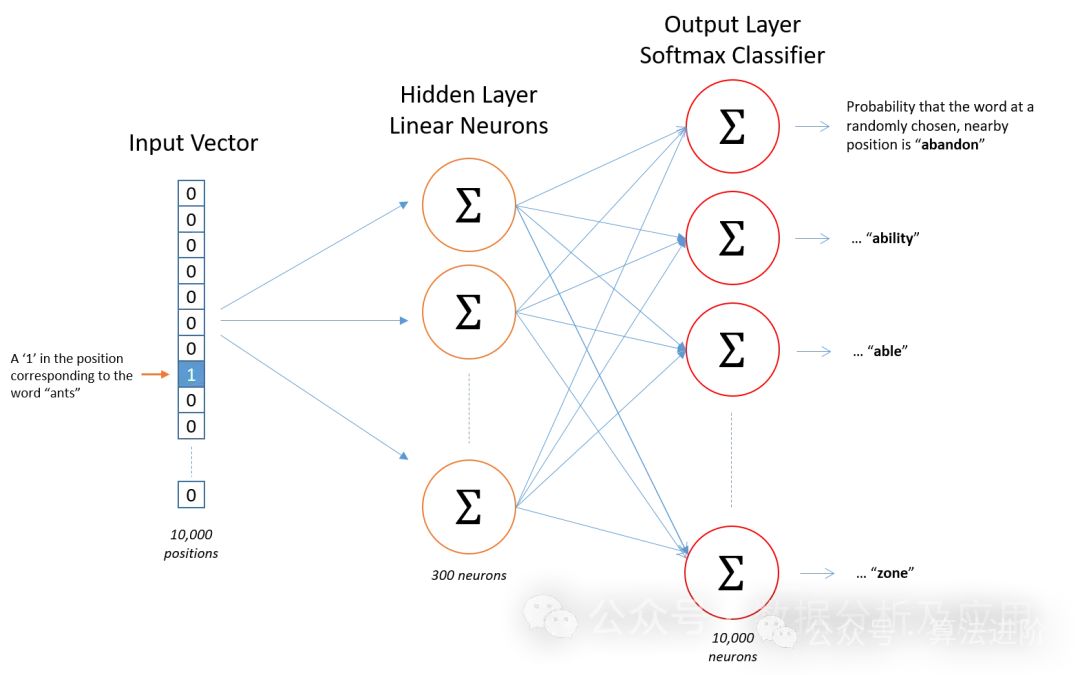
Принцип модели
Модель Word2Vec основана на нейронной сети и использует входное слово для прогнозирования его контекстных слов. В процессе обучения модель пытается изучить векторное представление каждого слова, чтобы слово, появляющееся в данном контексте, было как можно ближе к векторному представлению целевого слова. Этот метод обучения называется «Скип-грамма» или «Непрерывный мешок слов» (CBOW).
Модельное обучение
Обучение модели Word2Vec неотделимо от ресурсов расширенных текстовых данных. Сначала мы предварительно обработаем эти данные в последовательности слов или n-грамм. Затем нейронная сеть используется для глубокого обучения контексту этих слов или n-грамм. В процессе обучения модель постоянно корректирует векторное представление слов, чтобы минимизировать ошибки прогнозирования и, таким образом, точно улавливать семантические коннотации.
Обзор преимуществ
- Семантическое сходство: Word2Vec может точно уловить семантическую связь между словами, сближая слова со схожим значением в векторном пространстве.
- Эффективность обучения: тренировочный процесс Word2Vec эффективен и может легко справиться с потребностями обработки крупномасштабных текстовых данных.
- Интерпретируемость: векторы слов, созданные Word2Vec, имеют практическую прикладную ценность и могут использоваться для различных задач, таких как кластеризация, классификация и расчет семантического сходства.
Потенциальные недостатки
- разреженность данных: для слов, которые не встречались в обучающих данных,Word2Vec может не генерировать точное векторное представление.
- Ограничение контекстного окна: контекстное окно Word2Vec фиксировано и может игнорировать зависимости между удаленными словами.
- Требования к вычислительным ресурсам. Процесс обучения и вывода Word2Vec предъявляет определенные требования к вычислительным ресурсам.
- Проблема настройки параметров: производительность Word2Vec во многом зависит от тщательной настройки гиперпараметров (таких как размеры вектора, размер окна, скорость обучения и т. д.).
Области применения
Word2Vec широко используется в области обработки естественного языка, такой как классификация текста, анализ настроений, извлечение информации и т. д. Например, его можно использовать для определения эмоциональной направленности (положительной или отрицательной) новостного сообщения или для извлечения ключевых сущностей или концепций из больших объемов текста.
Пример кода Python
Pythonfrom gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
import nltk
# Скачать точечное причастие Модель
nltk.download('punkt')
# Предположим, у нас есть текстовые данные.
sentences = [
«Я люблю есть яблоки»,
«Яблоко — мое любимое»,
«Я не люблю есть бананы»,
«Банан слишком сладкий»,
"Я люблю читать",
«Чтение делает меня счастливым»
]
# Выполнить обработку сегментации слов на текстовых данных.
sentences = [word_tokenize(sentence) for sentence in sentences]
# создавать Word2Vec Модель
# Параметры здесь можно настроить по мере необходимости.
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# Модель обучения
model.train(sentences, total_examples=model.corpus_count, epochs=10)
# Получить вектор слов
vector = model.wv['Яблоко']
# Найдите слово, наиболее похожее на слово «яблоко».
similar_words = model.wv.most_similar('Apple')
print("Вектор слов Apple:", vector)
print("Слово, наиболее похожее на яблоко:", similar_words)6、Transformer
фон:
существоватьглубокое Ранние стадии обучения, нейронная свертка сеть (CNN) добилась замечательных успехов в области распознавания изображений и обработки естественного языка. Однако по мере увеличения сложности задачи модель «последовательность-последовательность» (Seq2Seq) и нейронная петля сеть(RNN)стать последовательностью обработкиданныеобщие методы。хотяRNNи его вариантысуществовать Хорошо справляться с определенными задачами,Однако они склонны к проблемам исчезновения градиента и деградации модели при обработке длинных последовательностей. Чтобы решить эти проблемы,TransformerМодельбыло предложено。Более поздние крупные модели, такие как GPT и Bert, были основаны на Transformer для достижения превосходной производительности!
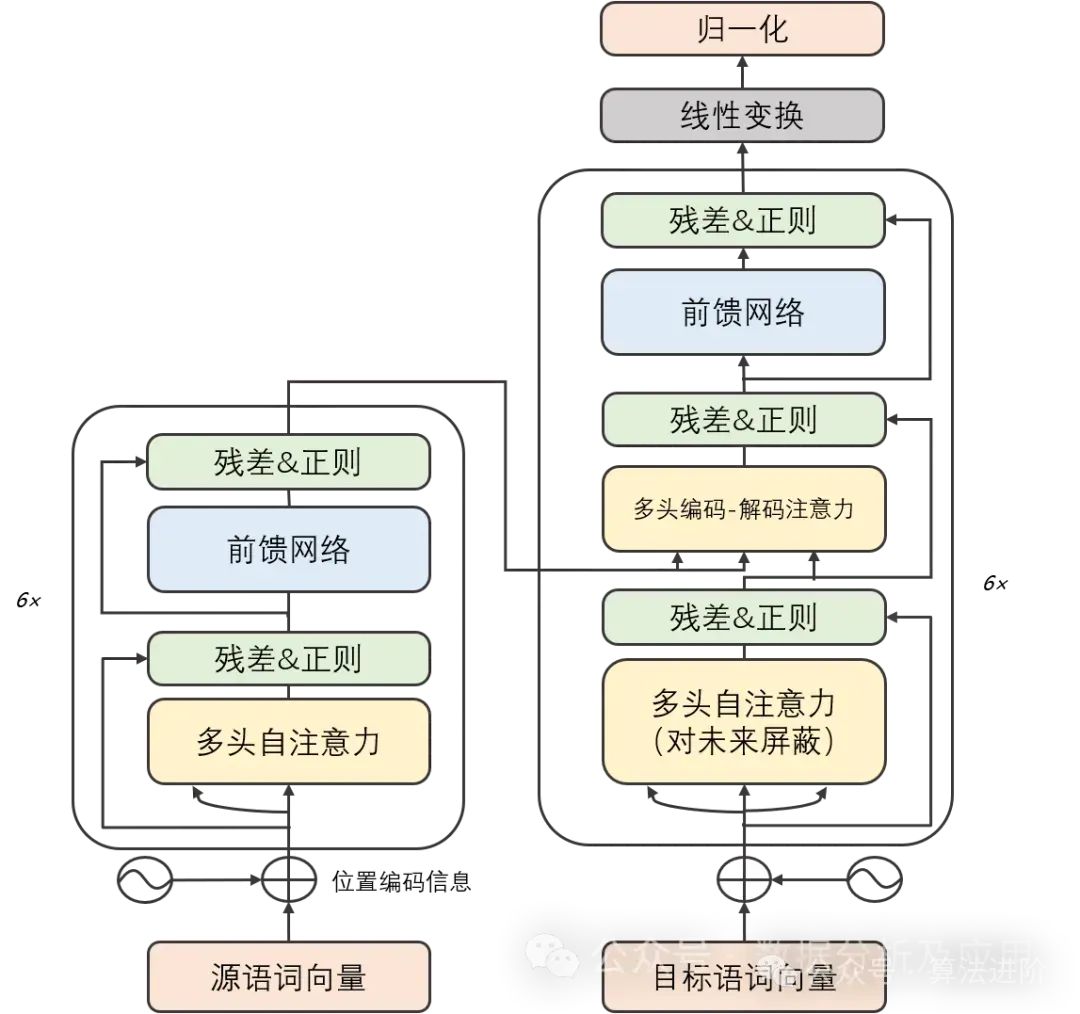
Принцип модели:
Модель Трансформера умело объединяет две части: кодировщик и декодер. Каждая часть состоит из нескольких «слоев» одной и той же структуры. Эти слои умело сочетают подуровни самообслуживания с подуровнями нейронной сети с линейной прямой связью. Подуровень самовнимания умело использует механизм внимания скалярного произведения для создания уникального представления входной последовательности в каждой позиции, в то время как подуровень нейронной сети с линейной прямой связью использует мудрость слоя самовнимания для создания насыщенный информацией экспресс. Стоит отметить, что и кодер, и декодер оснащены уровнем кодирования позиции, предназначенным специально для захвата контекста позиции во входной последовательности.
Модельное обучение:
Метод обучения модели Transformer основан на алгоритме обратного распространения ошибки и алгоритме оптимизации, таком как стохастический градиентный спуск. В процессе обучения он тщательно вычисляет градиент функции потерь по отношению к весам и использует алгоритмы оптимизации для точной настройки этих весов для минимизации функции потерь. Чтобы ускорить прогресс практики и улучшить общие возможности модели, практики часто применяют такие стратегии, как технология регуляризации и интегрированное обучение.
преимущество:
- Проблема исчезновения градиента и вырождения модели решена: модель-трансформер опирается на свой уникальный механизм самообслуживания.,Легко фиксируйте долгосрочные зависимости в последовательностях,Тем самым избавляясь от оков исчезновения градиента и деградации Модели.
- Отличные возможности параллельных вычислений: вычислительная архитектура модели Transformer естественно параллельна, что позволяет быстро обучать и делать выводы на графическом процессоре.
- Отличная производительность в многозадачном режиме: мощные возможности обучения и представления функций.,TransformerМодельсуществоватьмашинаустройствопереводить、Классификация текста、Продемонстрировал отличную производительность в ряде задач, таких как распознавание речи.
недостаток:
- Огромная потребность в вычислительных ресурсах: из-за распараллеливаемости TransformerModel,Процессы обучения и вывода требуют огромных вычислительных ресурсов.
- Чувствителен к весам инициализации. Трансформатор чрезвычайно требователен к выбору весов инициализации. Неправильная инициализация может привести к нестабильности или проблемам с перенастройкой.
- Ограниченная долгосрочная обработка зависимостей: хотя модель Transformer эффективно решила проблемы исчезновения градиента и деградации модели.,Но при работе с очень длинными последовательностями все еще возникают проблемы.
Сценарии применения:
Модели трансформаторов широко используются в области обработки естественного языка, охватывая многие аспекты, такие как машинный перевод, классификация текста и генерация текста. Кроме того, модель Transformer также хороша в таких областях, как распознавание изображений и речи.
Пример кода Python(Упрощенная версия):
import torch
import torch.nn as nn
import torch.optim as optim
#Этот пример используется только для иллюстрации базовой структуры и принципа Transformer. Фактические преобразователи (такие как GPT или BERT) намного сложнее и требуют большего количества этапов предварительной обработки, таких как токенизация, заполнение, маскирование и т. д.
class Transformer(nn.Module):
def __init__(self, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward=2048):
super(Transformer, self).__init__()
self.model_type = 'Transformer'
# encoder layers
self.src_mask = None
self.pos_encoder = PositionalEncoding(d_model, max_len=5000)
encoder_layers = nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_encoder_layers)
# decoder layers
decoder_layers = nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward)
self.transformer_decoder = nn.TransformerDecoder(decoder_layers, num_decoder_layers)
# decoder
self.decoder = nn.Linear(d_model, d_model)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src, tgt, teacher_forcing_ratio=0.5):
batch_size = tgt.size(0)
tgt_len = tgt.size(1)
tgt_vocab_size = self.decoder.out_features
# forward pass through encoder
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
# prepare decoder input with teacher forcing
target_input = tgt[:, :-1].contiguous()
target_input = target_input.view(batch_size * tgt_len, -1)
target_input = torch.autograd.Variable(target_input)
# forward pass through decoder
output2 = self.transformer_decoder(target_input, output)
output2 = output2.view(batch_size, tgt_len, -1)
# generate predictions
prediction = self.decoder(output2)
prediction = prediction.view(batch_size * tgt_len, tgt_vocab_size)
return prediction[:, -1], prediction
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
# гиперпараметры
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
# Создать экземпляр модели
model = Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward)
# Случайно сгенерированные данные
src = torch.randn(10, 32, 512)
tgt = torch.randn(10, 32, 512)
# прямое распространение
prediction, predictions = model(src, tgt)
print(prediction)7. Генеративно-состязательная сеть (GAN).
Идея GAN берет свое начало из игры с нулевой суммой в теории игр, в которой один игрок пытается сгенерировать максимально реалистичные фейковые данные, в то время как другой игрок пытается отличить настоящие данные от фейковых. GAN возникла из проблемы Монти Холла (проблемы объединения генеративной модели и дискриминантной модели), но в отличие от проблемы Монти Холла, GAN не делает упор на аппроксимацию определенных распределений вероятностей или генерацию определенных выборок, а напрямую использует генеративные модели, а не дискриминационные модели.
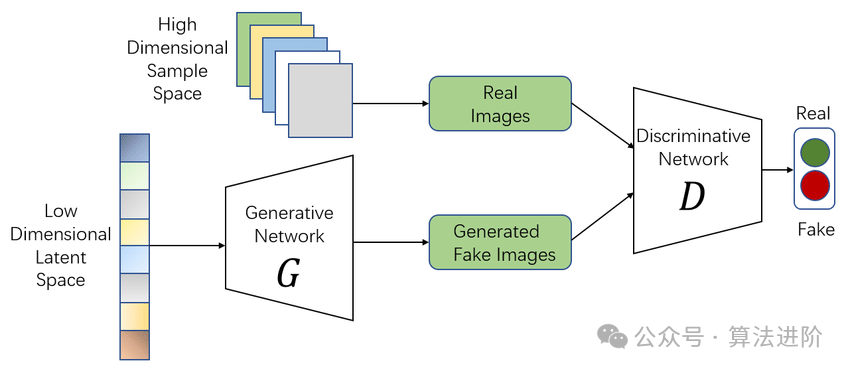
Принцип модели:
GAN состоит из двух частей: генератора и дискриминатора. Генератор предназначен для создания реалистичных поддельных данных, а дискриминатор предназначен для определения подлинности входных данных. В продолжающейся игре эти двое постоянно корректируют параметры, пока не будет достигнут динамический баланс. В это время фальшивые данные, генерируемые генератором, настолько реалистичны, что дискриминатору сложно отличить их подлинность.
Модельное обучение:
Процесс обучения GAN — это тонкий процесс оптимизации. На каждом этапе обучения генератор сначала генерирует поддельные данные, используя текущие параметры, а затем дискриминатор оценивает подлинность этих данных. На основании результатов дискриминации обновляются параметры дискриминатора. В то же время, чтобы дискриминатор не был слишком точным, мы также обучим генератор так, чтобы он мог создавать поддельные данные, которые могут обмануть дискриминатор. Этот процесс повторяется до тех пор, пока обе стороны не достигнут хрупкого баланса.
преимущество:
- Мощные возможности генерации: GAN может глубоко исследовать внутреннюю структуру и правила распределения данных.,Создавайте чрезвычайно реалистичные поддельные данные.
- Не требуется явного контроля: тренировочный в GAN. процесссередина,Нам не нужно предоставлять явную информацию на этикетке.,Просто предоставьте реальные данные.
- Высокая гибкость: GAN можно легко комбинировать с другими моделями.,В сочетании с автоэнкодером для формирования AutoGAN,Или в сочетании со сверточной нейронной сетью, чтобы сформировать DCGAN и т. д.,Тем самым расширяя сферу применения.
недостаток:
- Тренировочная нестабильность: спортивный GAN процесс может быть сложным и иногда происходит сбой режима (режим коллапс), то есть генератор фокусируется только на генерации определенного типа выборки, что затрудняет точную оценку дискриминатора.
- Сложность отладки. Взаимодействия между генератором и дискриминатором сложны, что делает отладку GAN довольно сложной задачей.
- Сложность оценки: учитывая отличные возможности генерации GAN,Нелегко точно оценить подлинность и разнообразие фальшивых данных, которые он генерирует.
Сценарии использования:
- Генерация изображений: GAN отлично справляется с созданием изображений и может создавать изображения различных стилей, например генерировать изображения на основе текстовых описаний или конвертировать изображение в другой стиль.
- Улучшение данных: GAN может генерировать поддельные данные, которые очень похожи на реальные данные, которые можно использовать для расширения набора данных или улучшения способности модели к обобщению.
- Восстановление изображения: с помощью GAN мы можем исправить дефекты изображения или устранить шум в изображении, значительно улучшив качество изображения.
- Генерация видео: генерация видео на основе GAN стала одной из актуальных тем исследований и позволяет создавать различные уникальные стили видеоконтента.
Простой пример кода Python:
Ниже приведен простой пример кода GAN, реализованный с использованием PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# Определите сетевые структуры генератора и дискриминатора
class Generator(nn.Module):
def __init__(self, input_dim, output_dim):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.model(x)
# Создание экземпляров объектов генератора и дискриминатора
input_dim = 100 # Входные размеры могут быть скорректированы в соответствии с фактическими потребностями.
output_dim = 784 # Для набора данных MNIST выходной размер равен 28*28=784.
gen = Generator(input_dim, output_dim)
disc = Discriminator(output_dim)
# Определить функцию потерь и оптимизацию
criterion = nn.BCELoss() # Двоичная перекрестная энтропийная потеря подходит для дискриминационной части GAN и логистической части генератора. Однако часто более распространенным вариантом является использование функции потери двоичной перекрестной энтропии (двоичная функция cross
8. Диффузионно-диффузионная модель.
Нижним слоем популярной модели Sora является модель Diffusion, которая представляет собой генеративную модель, основанную на глубоком обучении. Она в основном используется для генерации непрерывных данных, таких как изображения, аудио и т. д. Основная идея модели Diffusion состоит в том, чтобы преобразовать сложное распределение данных в простое распределение Гаусса путем постепенного добавления шума, а затем генерировать данные из простого распределения путем постепенного удаления шума.
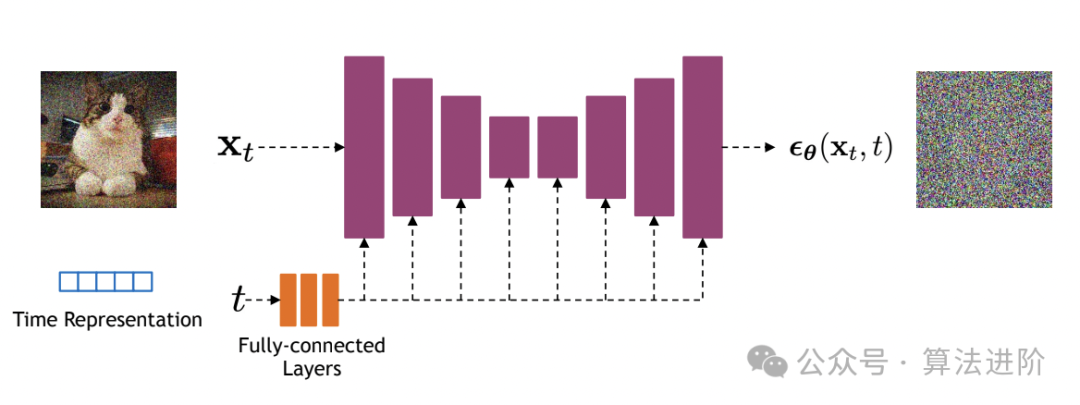
Принцип алгоритма:
Основная идея модели диффузии — рассматривать процесс генерации данных как цепь Маркова. Начиная с целевых данных, каждый шаг приближается к случайному шуму, пока не достигнет состояния чистого шума. Затем посредством обратного процесса целевые данные постепенно восстанавливаются из чистого шума. Этот процесс обычно описывается серией условных распределений вероятностей.
тренировочный процесс:
- Прямой процесс:Начните с реальных данных,постепеннодобавить шум,пока не будет достигнуто состояние чистого шума. В этом процессе,Необходимо рассчитать уровень шума на каждом этапе,и сохраните его.
- Обратный процесс:Начните с чистого шума,Убираем шум шаг за шагом,Пока целевые данные не будут восстановлены. в этом процессе,Используйте нейронную сеть (обычно структуру U-Net) для прогнозирования уровня шума на каждом этапе.,И соответственно генерировать данные.
- оптимизация:проходитьминимизировать реальностьданныеи генерироватьданныеразница между Модель обучения。Часто используемые потерифункциявключатьMSE(среднеквадратическая ошибка)иBCE(Двоичная перекрестная энтропия)。
преимущество:
- Высокое качество сборки: благодаря Diffusion Model применяется процесс постепенной диффузии и восстановления.,Таким образом, можно генерировать данные высокого качества.
- Сильная интерпретируемость: процесс создания модели диффузии имеет очевидный физический смысл, его легко понять и объяснить.
- Хорошая гибкость: диффузия Модель может обрабатывать различные типы контента, включая изображения, текст и аудио.
недостаток:
- Длительное время обучения. Поскольку модель диффузии требует многоэтапного процесса распространения и восстановления, время обучения длительное.
- Требования к большим вычислительным ресурсам: для обеспечения качества генерации диффузионная модель обычно требует больших вычислительных ресурсов, включая память и вычислительную мощность.
Применимые сценарии:
Модель диффузии подходит для сценариев, в которых необходимо генерировать высококачественные данные, таких как генерация изображений, генерация текста и генерация звука. В то же время, благодаря своей высокой интерпретируемости и гибкости, модель диффузии также может применяться к другим областям, требующим глубоких генеративных моделей.
Пример кода Python:
import torch
import torch.nn as nn
import torch.optim as optim
# ОпределениеU-NetМодель
class UNet(nn.Module):
# ...опустить определение модели...
# Определение Диффузия Model
class DiffusionModel(nn.Module):
def __init__(self, unet):
super(DiffusionModel, self).__init__()
self.unet = unet
def forward(self, x_t, t):
# x_t — данные на текущий момент, t — уровень шума
# Прогнозирование уровня шума с помощью U-Net
noise_pred = self.unet(x_t, t)
# Генерация данных на основе уровня шума
x_t_minus_1 = x_t - noise_pred * torch.sqrt(1 - torch.exp(-2 * t))
return x_t_minus_1
# Инициализация модели и оптимизация
unet = UNet()
model = DiffusionModel(unet)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# тренировочный процесс
for epoch in range(num_epochs):
for x_real in dataloader: # Получите реальные данные из загрузчика данных
# прямой процесс
x_t = x_real # Начните с реальных данных
for t in torch.linspace(0, 1, num_steps):
# добавить шум
noise = torch.randn_like(x_t) * torch.sqrt(1 - torch.exp(-2 * t))
x_t = x_t + noise * torch.sqrt(torch.exp(-2 * t))
# Вычислить шум прогнозирования
noise_pred = model(x_t, t)
# Рассчитать потери
loss = nn.MSELoss()(noise_pred, noise)
# Обратное распространение ошибки и оптимизация
optimizer.zero_grad()
loss.backward()
optimizer.step()
9. Графовая нейронная сеть (GNN).
Графовые нейронные сети (сокращенно GNN) — это модель глубокого обучения, предназначенная для данных, структурированных на графах. В реальном мире графовые структуры широко используются для описания различных сложных систем, таких как социальные сети, молекулярные структуры и транспортные сети. Однако традиционные модели машинного обучения часто сталкиваются с узкими местами при обработке этих графовых данных, а графовые нейронные сети предоставляют новые решения этих проблем.
Основная идея нейронной сети графа состоит в том, чтобы изучить представление признаков узлов в графе с помощью нейронной сети и одновременно учитывать корреляцию между узлами. Он использует итеративную передачу информации о соседях для обновления представлений узлов, чтобы аналогичные сообщества или соседние узлы имели схожие представления. На каждом уровне узел обновляет свое представление на основе информации о соседних узлах, что позволяет ему фиксировать сложные закономерности в графе.
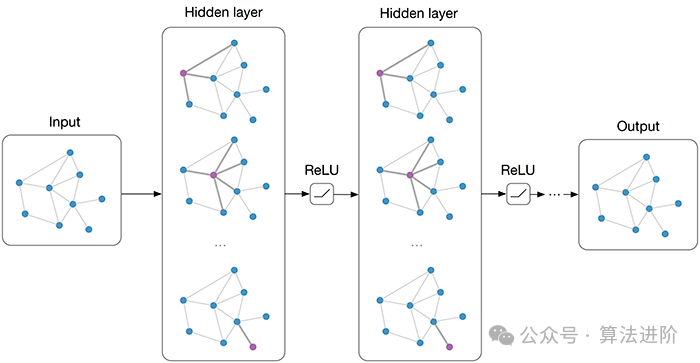
При обучении нейронных сетей графов обычно используются алгоритмы оптимизации на основе градиента, такие как стохастический градиентный спуск (SGD). Градиент функции потерь рассчитывается с помощью алгоритма обратного распространения ошибки, и веса нейронной сети обновляются на основе этих градиентов. Обычно используемые функции потерь включают перекрестную энтропию для классификации узлов и двоичную перекрестную энтропию для прогнозирования ссылок.
картинанейронная имеет следующие важные особенности: во-первых, он обладает мощными возможностями представления и может эффективно фиксировать сложные закономерности в графовых структурах, тем самым демонстрируя отличную производительность при выполнении таких задач, как классификация узлов и прогнозирование связей в сети. Во-вторых, он может естественным образом обрабатывать структуры графов без преобразования графа в матричную форму, что позволяет избежать накладных расходов на вычисления и хранение, вызванных крупномасштабными разреженными матрицами. Наконец, картинка нейронная Сеть обладает высокой масштабируемостью, и более сложные шаблоны можно фиксировать, накладывая больше слоев.
Однако графовые нейронные сети также имеют некоторые ограничения. Во-первых, по мере увеличения количества узлов и ребер в графе его вычислительная сложность будет быстро возрастать, что может привести к увеличению времени обучения. Во-вторых, графовые нейронные сети имеют множество гиперпараметров, таких как размер окрестности, количество слоев и скорость обучения. Настройка этих параметров требует глубокого понимания требований задачи. Кроме того, нейронные сети на графах изначально были разработаны для неориентированных графов и могут быть менее адаптируемы к ориентированным графам.
В практических приложениях графовые нейронные сети показали широкие перспективы применения во многих областях. Например, при анализе социальных сетей его можно использовать для анализа таких проблем, как сходство между пользователями, обнаружение сообщества и распространение влияния. В химии графовые нейронные сети можно использовать для прогнозирования свойств молекул и химических реакций. Кроме того, графовые нейронные сети также играют важную роль в таких сценариях, как системы рекомендаций и графы знаний, которые могут помочь нам глубоко понять внутреннюю структуру и корреляцию данных.
Пример кода GNN:
Pythonimport torch
from torch_geometric.nn import GCNConv
from torch_geometric.data import Data
# Определить простую структуру графа
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
# Определите простую сверточную сеть с двухслойным графом
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = GCNConv(dataset.num_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = torch.relu(x)
x = torch.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return torch.log_softmax(x, dim=1)
# Создать экземпляр модели、потеряфункцияиоптимизацияустройство
model = Net()
criterion = torch.nn.NLLLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
# Модель обучения
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
# Оцените модель на тестовом наборе
model.eval()
_, pred = model(data).max(dim=1)
correct = int((pred == data.y).sum().item())
acc = correct / int(data.y.sum().item())
print('Accuracy: {:.4f}'.format(acc))10. Глубокое обучение с подкреплением (DQN):
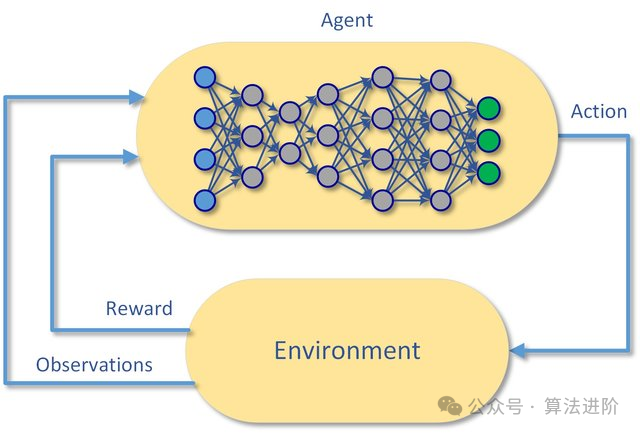
Принцип модели:
Deep Q-Networks (DQN) — это алгоритм обучения с подкреплением, который объединяет глубокое обучение и Q-обучение. Основная идея состоит в том, чтобы использовать нейронные сети для аппроксимации функции Q, которая представляет собой функцию значения состояния-действия, тем самым обеспечивая надежную поддержку агенту в выборе оптимального действия в конкретном состоянии.
Модельное обучение:
Процесс обучения DQN разделен на два ключевых этапа: офлайн-этап и онлайн-этап. На автономном этапе агент собирает данные посредством взаимодействия с окружающей средой, а затем обучает нейронную сеть. Выходя на онлайн-этап, агент начинает полагаться на нейронную сеть для выбора и обновления действий. Чтобы предотвратить риск переоценки, DQN инновационно вводит концепцию целевой сети, которая поддерживает стабильность целевой сети в течение определенного периода времени, тем самым значительно улучшая стабильность алгоритма.
преимущество:
Благодаря своей превосходной производительности DQN успешно преодолел проблемы многомерного пространства состояний и действий, особенно при решении проблем пространства непрерывных действий. Он не только обладает высокой стабильностью, но также обладает сильной способностью к обобщению, демонстрируя большую практическую ценность.
недостаток:
DQN также имеет некоторые ограничения. Например, иногда он может попасть в локальное оптимальное решение и не сможет выбраться из него. Кроме того, для его поддержки требуются огромные данные и вычислительные ресурсы, а также он очень чувствителен к выбору параметров, что увеличивает сложность его практического применения.
Сценарии использования:
DQN по-прежнему проявляет себя во многих областях, таких как игры и управление роботами, полностью демонстрируя свою уникальную ценность и широкие перспективы применения.
Пример кода:
import tensorflow as tf
import numpy as np
import random
import gym
from collections import deque
# Установить гиперпараметры
BUFFER_SIZE = int(1e5) # Оцените размер хранилища повторов
BATCH_SIZE = 64 # Количество образцов, взятых из каждого повтора опыта
GAMMA = 0.99 # коэффициент дисконтирования
TAU = 1e-3 # Размер шага обновления целевой сети
LR = 1e-3 # скорость обучения
UPDATE_RATE = 10 # Сколько шагов должна обновляться целевая сеть каждый раз?
# Определить хранилище повторов опыта
class ReplayBuffer:
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
return random.sample(self.buffer, batch_size)
# Определение DQNМодель
class DQN:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.model = self._build_model()
def _build_model(self):
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(24, input_dim=self.state_size, activation='relu'))
model.add(tf.keras.layers.Dense(24, activation='relu'))
model.add(tf.keras.layers.Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=tf.keras.optimizers.Adam(lr=LR))
return model
def remember(self, state, action, reward, next_state, done):
self.replay_buffer.push((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= 0.01:
return random.randrange(self.action_size)
act_values = self.model.predict(state)
return np.argmax(act_values[0])
def replay(self, batch_size):
minibatch = self.replay_buffer.sample(batch_size)
for state, action, reward, next_state, done in minibatch:
target = self.model.predict(state)
if done:
target[0][action] = reward
else:
Q_future = max(self.target_model.predict(next_state)[0])
target[0][action] = reward + GAMMA * Q_future
self.model.fit(state, target, epochs=1, verbose=0)
if self.step % UPDATE_RATE == 0:
self.target_model.set_weights(self.model.get_weights())
def load(self, name):
self.model.load_weights(name)
def save(self, name):
self.model.save_weights(name)
# создаватьсреда
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# Инициализируйте DQN и хранилище повторов.
dqn = DQN(state_size, action_size)
replay_buffer = ReplayBuffer(BUFFER_SIZE)
# тренировочный процесс
total_steps = 10000
for step in range(total_steps):
state = env.reset()
state = np.reshape(state, [1, state_size])
for episode in range(100):
action = dqn.act(state)
next_state, reward, done, _ = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
replay_buffer.remember(state, action, reward, next_state, done)
state = next_state
if done:
break
if replay_buffer.buffer.__Какая модель、Какой алгоритм вам кажется лучшим?↓



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
