Следующее поколение архитектуры технологий больших данных: Data Fabric?
Предисловие
За последние несколько десятилетий, в условиях взрывного роста объема данных и постоянного развития потребностей в их обработке, мы стали свидетелями непрерывного развития и трансформации архитектуры больших данных. В этом процессе развитие технологий и услуг больших данных привело к замечательным достижениям, обеспечив мощную поддержку бизнес-аналитики в различных отраслях, а принятие решений на основе данных стало консенсусом.
Первоначально архитектура больших данных в основном основывалась на пакетной обработке, поскольку возможности обработки данных и вычислительные ресурсы в то время были ограничены. С развитием технологий (аппаратного обеспечения) потоковая обработка и вычисления в реальном времени постепенно стали обычным явлением, а архитектура больших данных превратилась в обработку данных в реальном времени. В этом процессе появилось множество отличных фреймворков и инструментов для обработки больших данных с открытым исходным кодом, таких как Hadoop, Hive, Spark, Kafka, Iceberg, ClickHouse и т. д. Эти фреймворки и инструменты значительно повысили эффективность и качество обработки данных.
В эпоху облачных вычислений, с быстрым развитием технологий облачных вычислений, архитектура больших данных также начала перемещаться в облако. Платформа облачных вычислений предоставляет крупномасштабные, высокодоступные ресурсы для обработки данных и разработала несколько отличных механизмов хранения и вычислений для лучшего удовлетворения потребностей обработки больших данных. В то же время пользователи также могут выбрать оптимизированный набор компонентов EMR от производителя для создания собственной платформы больших данных на основе облачных ресурсов.
В последние годы архитектура больших данных стала более зрелой, а скорость разработки относительно медленной. Не нужно спешить с новыми технологиями. Вы можете успокоиться и подумать, чего вы хотите? У каждого поколения архитектуры больших данных есть свои основные проблемы, которые необходимо решить. А что насчет следующего поколения архитектуры больших данных? Мы можем найти некоторые подсказки в двух современных основных архитектурах: Lambda и Kappa. Следующие Lambda и Kappa представляют собой более широкое описание (Lambada отклоняется от линии, неоднородна, имеет несколько избыточных копий данных, а потоки и пакеты сосуществуют; Kappa работает в режиме реального времени, имеет чистую архитектуру, единую копию, а потоки и пакеты интегрированные и т. д.), терминология в индустрии больших данных. Само определение не очень понятно, просто проясните его.
Лямбда-архитектура (гибридная архитектура потоковой и пакетной обработки)
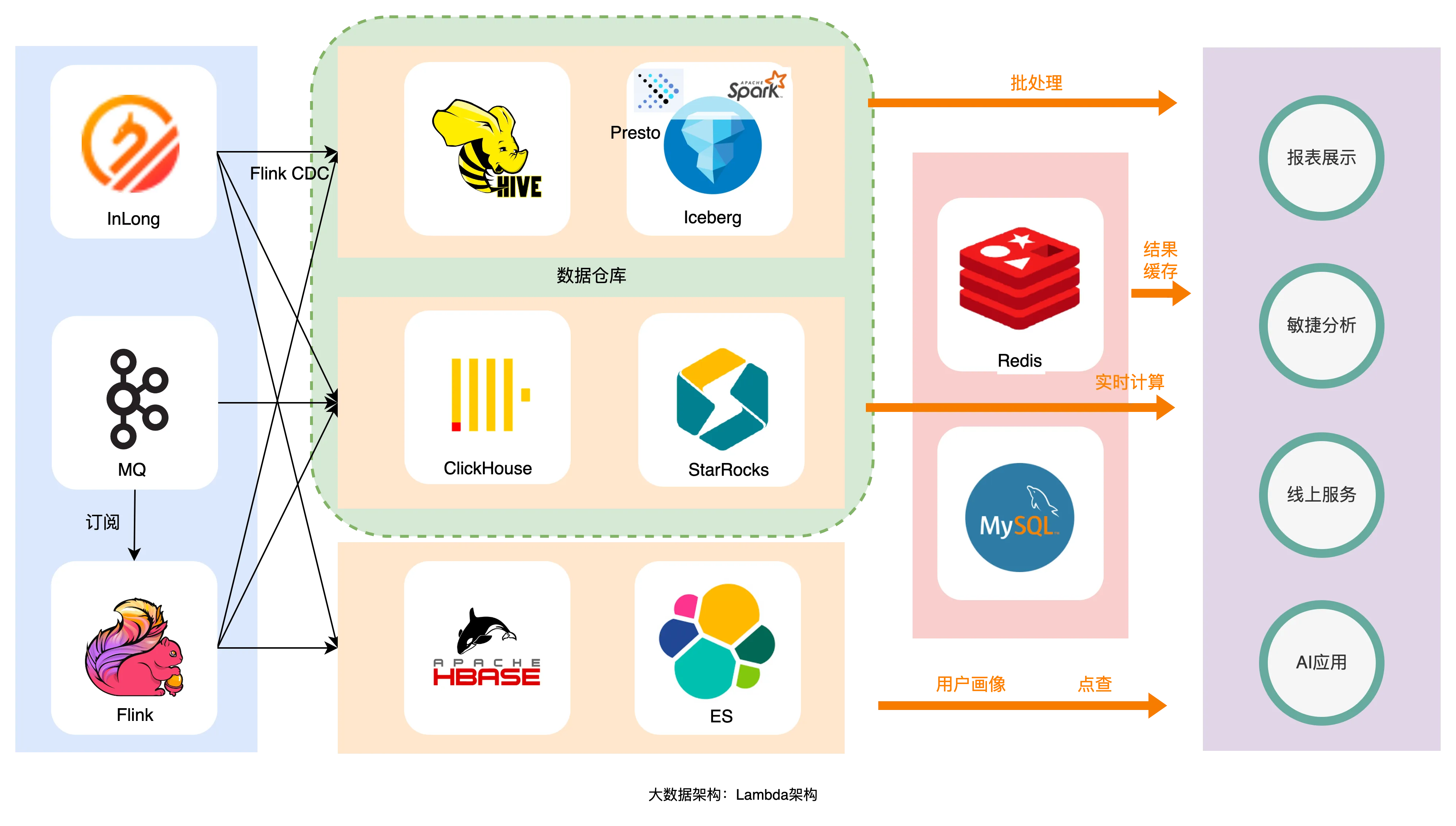
На рисунке выше показана архитектура Lambda, обычно используемая в отрасли. Данные записываются в StarRocks в реальном времени, а затем записываются в Hive в пакетном режиме/в реальном времени через Spark/Flink. Этот процесс может включать в себя согласованность данных, избыточные данные и множественные данные. пишет , Такие проблемы, как сложное обслуживание разнородных фреймворков.
Архитектура Lambda имеет свою собственную рациональность. Она использует профессиональную структуру для решения проблем в конкретных сценариях. Хотя на более позднем этапе она столкнется с повышенной сложностью, небольшое количество людей, вложившихся на ранней стадии, может быстро решить проблему «смогут ли это». На самом деле, большинство сотрудников компании, занимающихся исследованиями и разработками, недостаточно, и они уже заняты решением бизнес-задач, поэтому они выбирают комбинацию инфраструктур с открытым исходным кодом; Вместо вторичной разработки фреймворков с открытым исходным кодом или самостоятельных исследований также беспомощно, кроме того, даже если вы перейдете в облако, сложно иметь набор компонентов, которые могут решить все проблемы. Облако обычно работает лучше в определенных сценариях и имеет больше пользователей. Некоторые компании используют мультиоблачные решения, чтобы не связывать себя с одним поставщиком облака (простота перехода в облако и сложность перехода в облако также являются заслуживающими внимания вопросами). обсуждения).
Каппа-архитектура (интегрированная потоковая и пакетная архитектура на основе озера данных)
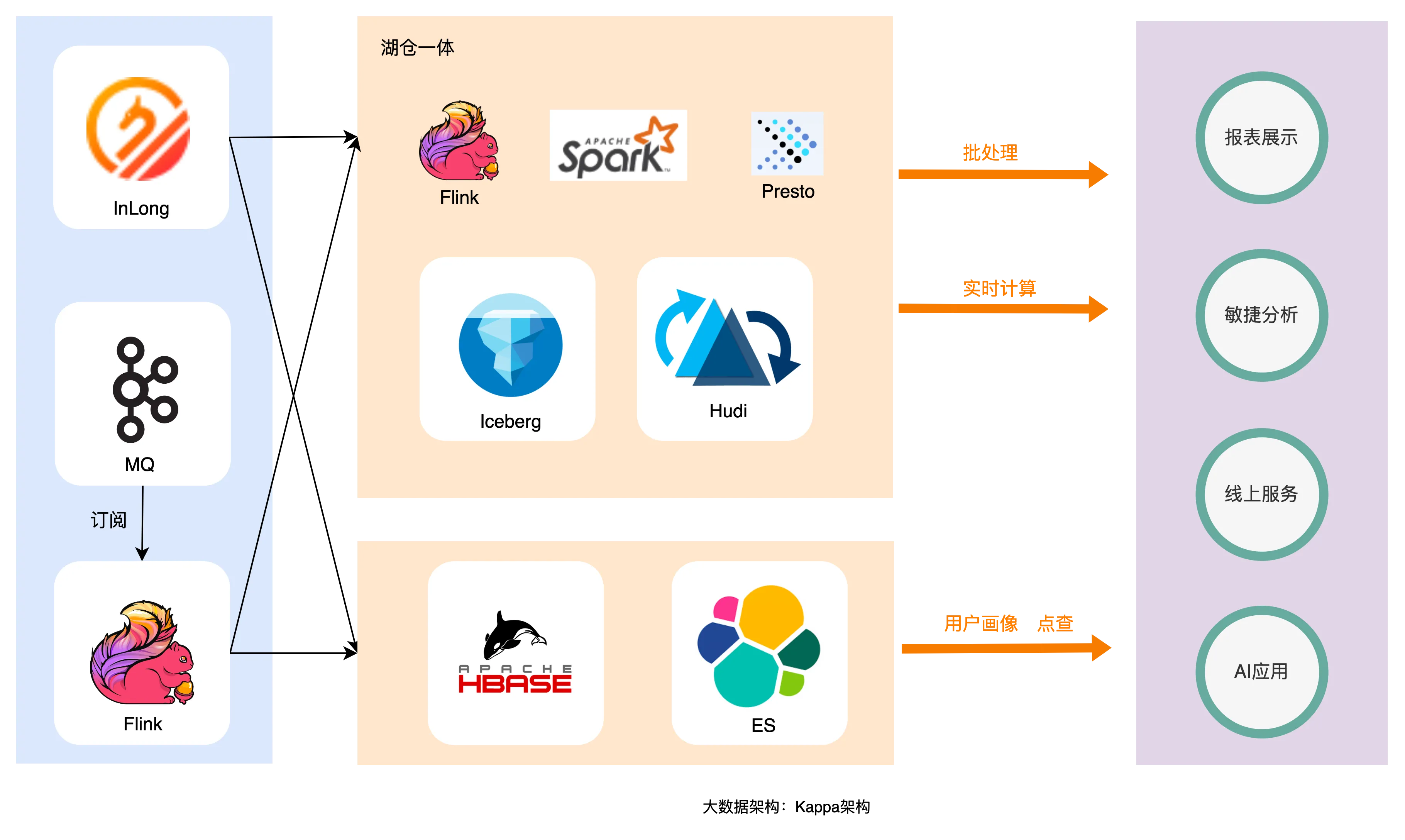
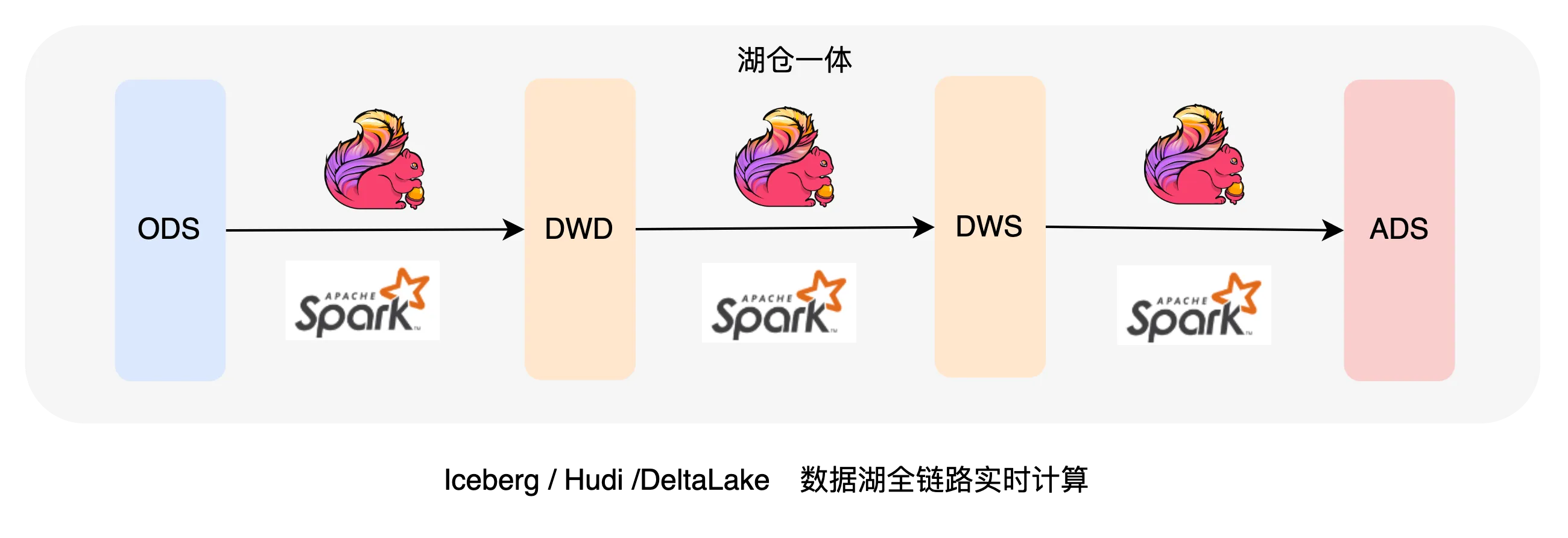
На рисунке выше показана архитектура Kappa, обычно используемая в отрасли. Данные записываются в озеро данных через каналы в реальном времени. Полноканальная работа хранилища данных также может быть выполнена через Flink в озере данных. копия данных по всей ссылке и все это генерируется в режиме реального времени.
Чтобы решить проблемы, вызванные архитектурой Lambda, отрасль надеется использовать один фрагмент данных для решения таких проблем, как передача данных в режиме реального времени, согласованность, избыточность и сложное обслуживание гетерогенных инфраструктур. Хотя архитектура Kappa основана на потоковой передаче и Пакетная интеграция может решить большую часть проблем, поскольку она зависит от скорости ответа на запросы Flink и Presto, которые трудно решить в таких сценариях, как высокий параллелизм, низкая задержка и сложные запросы. Иногда, чтобы решить проблему «сможет ли это», необходимо внедрить в лямбда-архитектуру какие-то разнородные фреймворки.
Подытожим три пункта из описания двух приведенных выше основных архитектур:
- Когда бизнес-сценарий пользователя относительно прост, его можно прекрасно решить на основе Kappa Architecture или набора EDW, но когда бизнес-сценарий пользователя более сложен;,существуют существующие решения по разумной цене,По сути, со временем это станет Lambda Архитектура.
- Каждая существующая команда изначально выбирает большие данные Архитектуратакже ограничено временными затратами、Будущие ожидания нестабильны、Объём знаний и т.д.,Невозможно потратить много сил на выбор теоретически оптимального результата, итерации после выбора всегда сталкиваются с соображениями рентабельности (нужно ли выбирать компоненты с большей производительностью и более элегантные? Достаточно ли этого?),Поэтому, если эволюция продолжится, проблем обязательно будет больше.,Например, острова данных, Данные противоречивы、Высокие затраты на техническое обслуживание и т. д.
- большие Архитектура данных В этом процессе участвует множество людей, нуждающимся необходимо сотрудничать со многими отделами внутри компании и интегрировать бизнес-платформу данных, оставленную другими бизнес-отделами. Если подумать об историческом долге, долг огромен, и я хочу создать чистый. BOLHSHEE данные Архитектура в принципе маловероятны.
Судя по приведенному выше описанию, как нам построить архитектуру больших данных следующего поколения? Архитектура больших данных создана человеком, используется людьми и развивается. Однако, поскольку люди не так стабильны, как программы, организационные изменения, требования рентабельности инвестиций и т. д., мы смотрим на проблему с точки зрения развития и предпочитаем принять нестабильность и высокая сложность. Архитектура Data Fabric, которая стала популярна за рубежом в последние два года, может решить вышеупомянутые проблемы. Она защищает пользователей от базовой гетерогенности посредством абстрактного уровня виртуализации, осуществляет управление данными посредством активных метаданных и решает проблему «островков» данных. федеративные запросы и автоматическое перемещение данных.
Как понять Data Fabric?
Data Fabric впервые стала популярной в начале 2000-х годов и была связана в первую очередь с внутренними сетками объектов. Затем Форрестер начал писать о более общих решениях, которые к 2013 году стали полноценной категорией исследований. В 2016 году Forrester добавил категорию Big Data Fabric в Forrester Wave. В 2019 году она стала включаться в ежегодные технологические тенденции Gartner. В 2020 году она появилась в кривой зрелости новых технологий и в кривой зрелости управления данными. этап зарождения инноваций до 2021 года. Пик завышенных ожиданий приходится на 2016 год) [1], и даже Gartner заявила, что «Data Fabric — это будущее управления данными».
Сегодня 2023 год уже находится на этапе кривой зрелости новых технологий «Корыто разочарования», при этом многие авторитетные иностранные компании и некоторые новые иностранные компании занимают лидирующие позиции, но в Китае он находится на этапе кривой зрелости новых технологий «Триггер инноваций»; «, и в настоящее время некоторые стартапы гонятся за этой тенденцией.
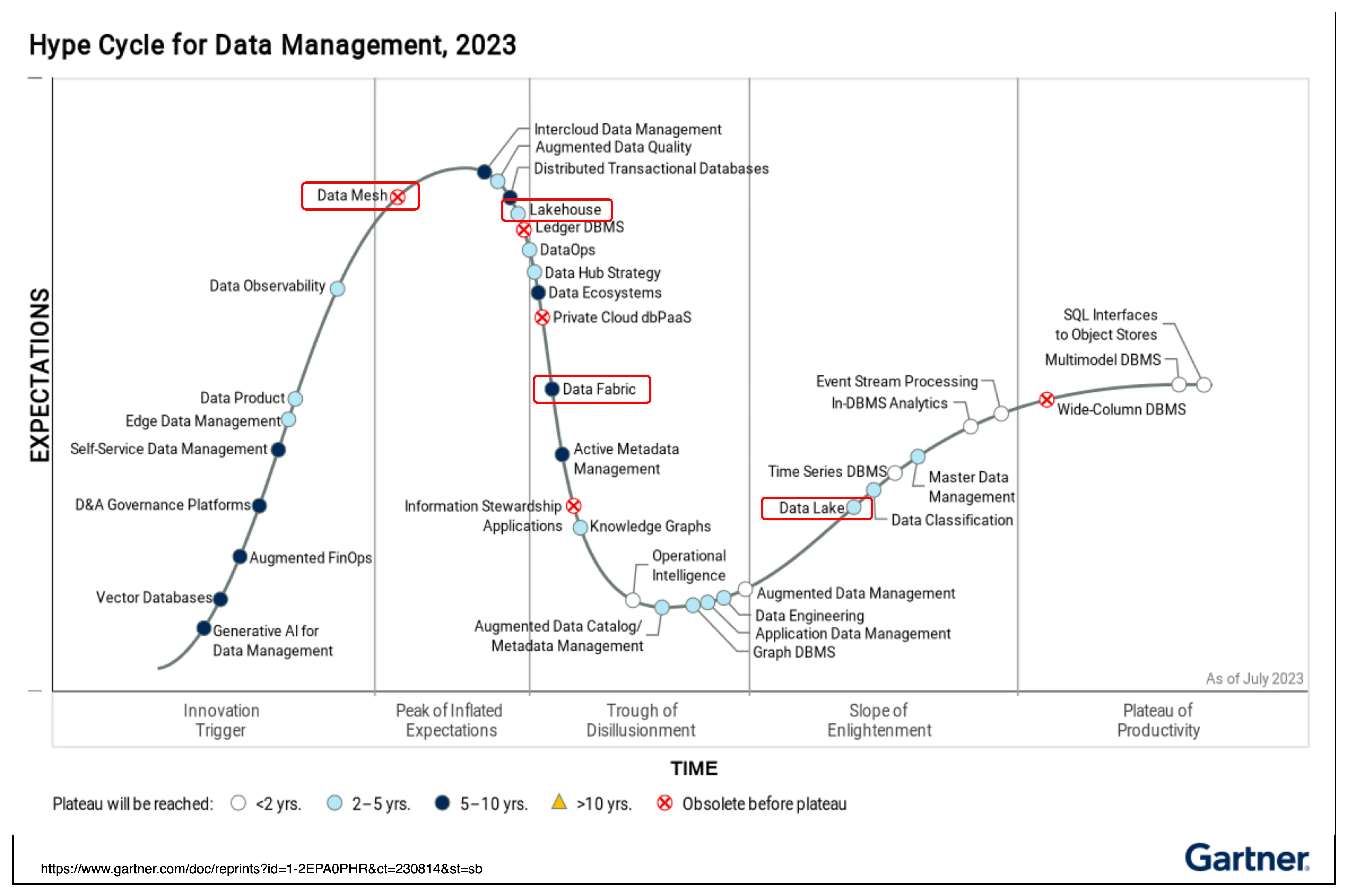
Как показано на рисунке, популярность Data Fabric за рубежом снижается. Для того, чтобы технология достигла стадии платформы, потребуется около 5-10 лет. В настоящее время в эту область выходит все больше зарубежных компаний.
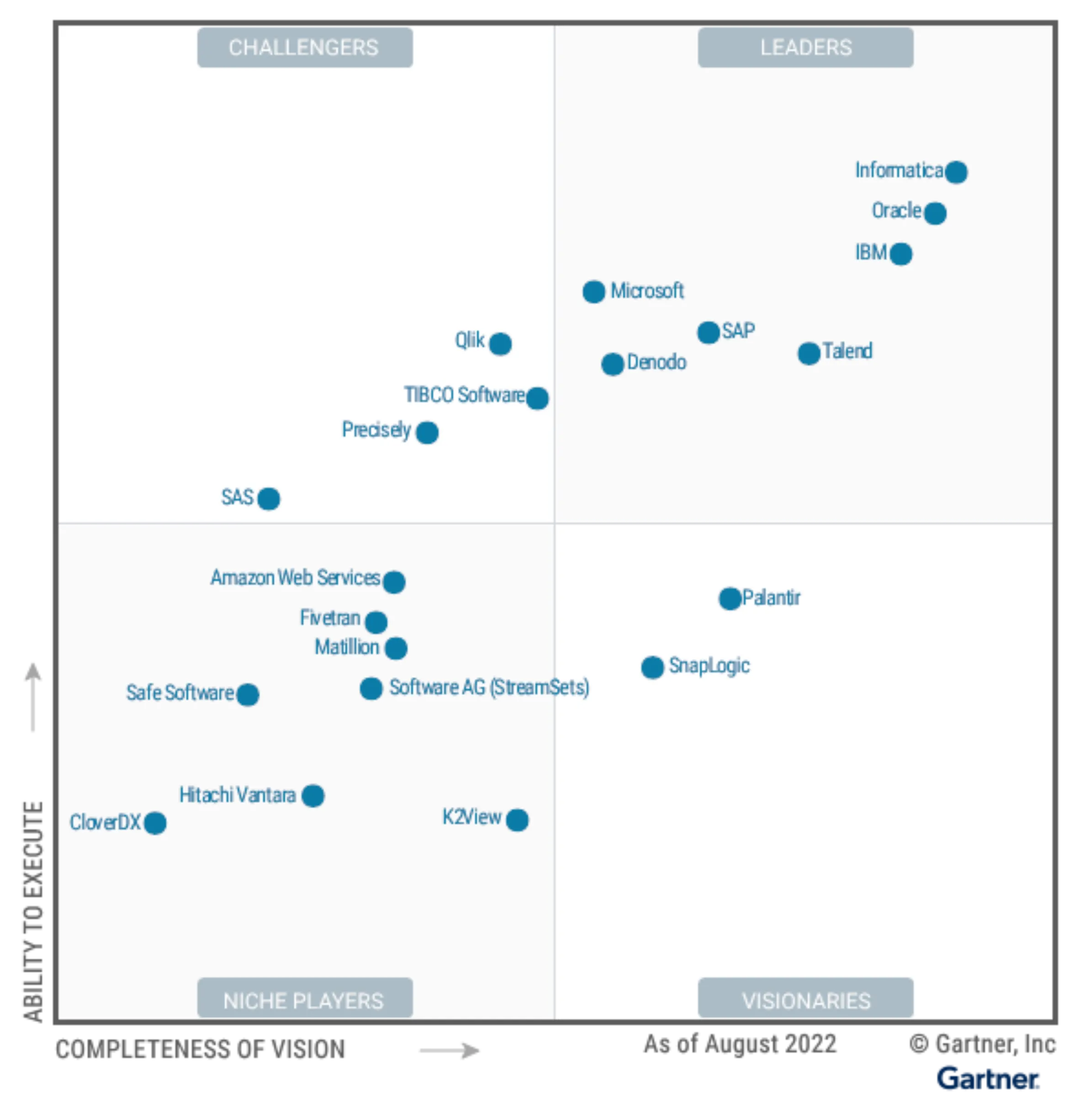
Как показано на рисунке, ведущими компаниями, представленными Gartner, являются в основном несколько хорошо известных старых иностранных компаний и несколько новых компаний.
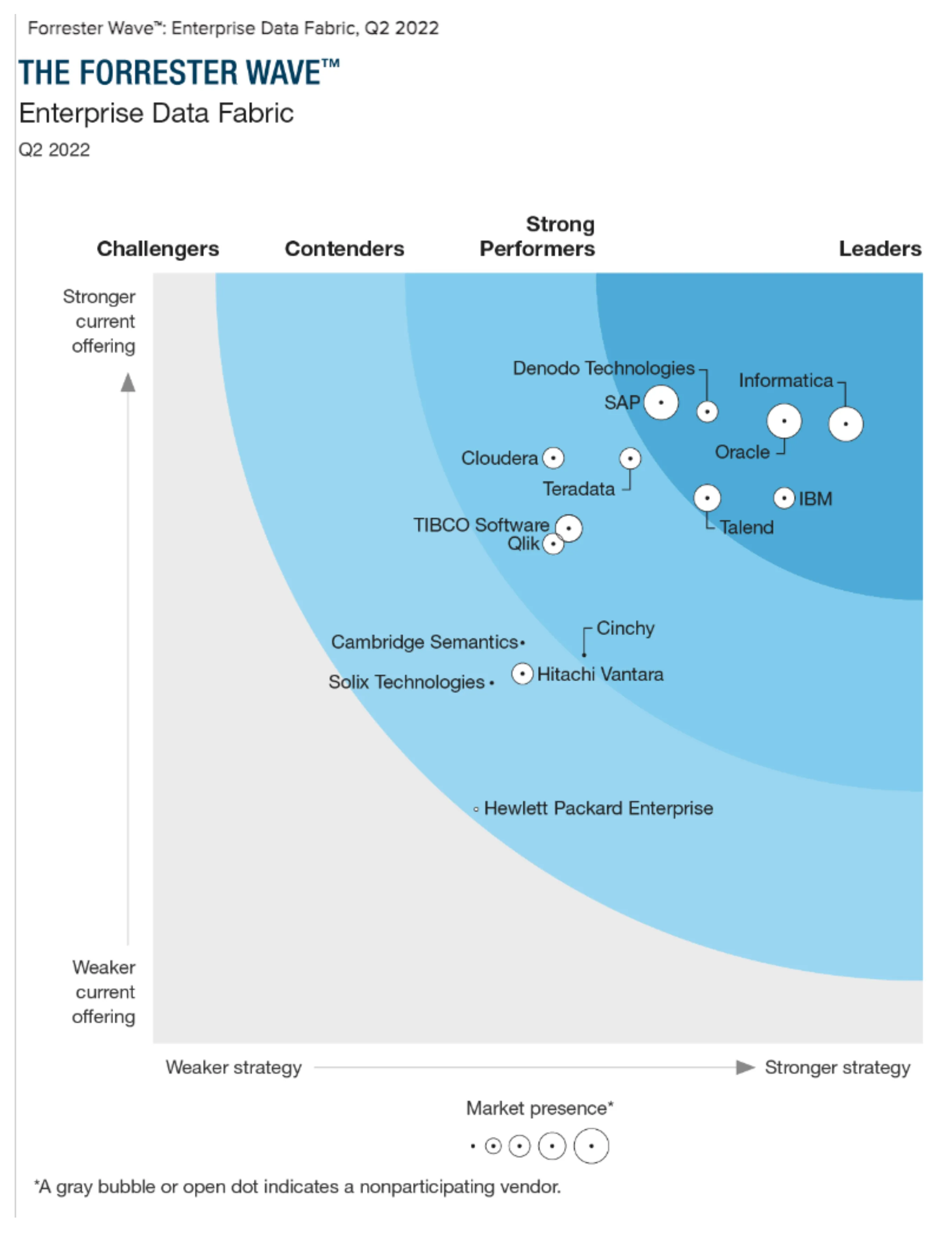
Как показано на рисунке, в число крупнейших компаний, описанных Forrester, входят несколько известных старых иностранных компаний и несколько новых компаний. Среди них Denodo в настоящее время также ведет бизнес в Китае и, как считается, чувствует себя относительно хорошо.
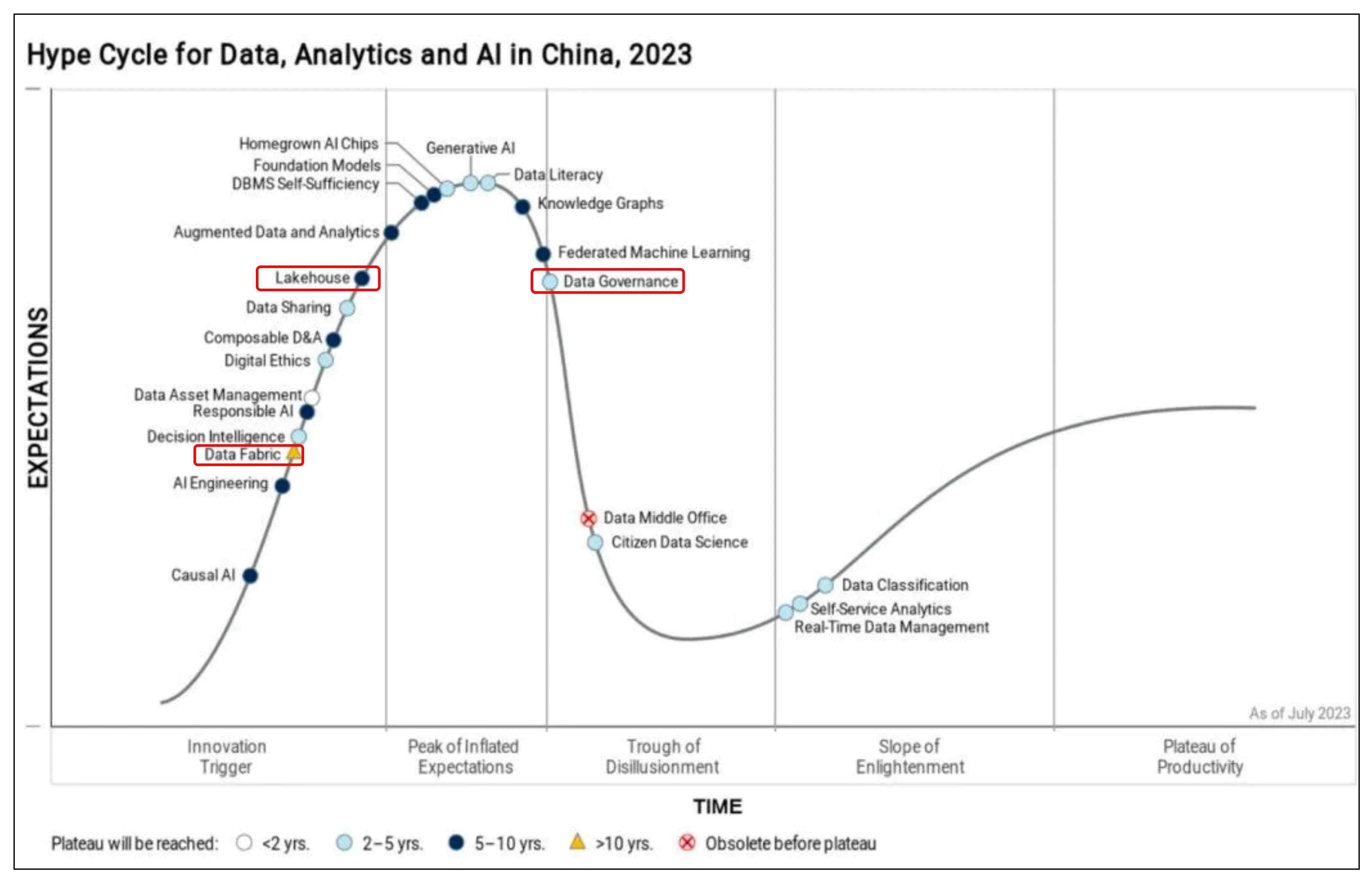
Как показано на рисунке, Китай в настоящее время переживает период подъема, и для того, чтобы технологии вышли на плато, потребуется около 10 или более лет. В настоящее время в отрасль входят также некоторые отечественные начинающие компании.
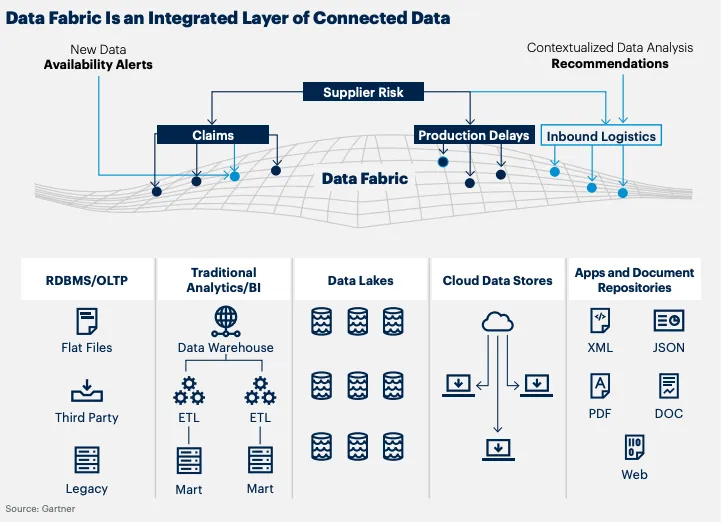
В целом принято считать, что ни один инструмент не может охватить весь спектр Data Fabric. Он охватывает множество «разновидностей» интеграции и управления данными для достижения согласованного решения [2]. Forrester считает, что DataFabric «динамически координирует распределенные источники данных интеллектуальным, безопасным и самообслуживаемым образом, предоставляет интегрированные и надежные данные на всех платформах данных и поддерживает широкий спектр различных сценариев анализа и использования приложений», что фокусируется на автоматизации данных. интеграция, преобразование, подготовка, курирование, безопасность, управление и оркестрация, что позволяет быстро анализировать данные и получать ценную информацию, помогающую бизнесу добиться успеха [4]. Gartner определяет Data Fabric как: «Архитектурный шаблон, который предоставляет информацию и автоматизирует проектирование, интеграцию и развертывание объектов данных независимо от платформы развертывания и архитектурного метода. Он использует понимание всех активов метаданных и искусственного интеллекта. ML (искусственный интеллект/машинное обучение) для предоставления практической информации и рекомендаций по управлению данными, а также интегрированных шаблонов проектирования и развертывания. Это сделает доступ к данным и обмен ими более быстрыми, интеллектуальными и даже полностью автоматизированными (в некоторых сценариях). "[3].
Некоторые основные концепции Data Fabric[3]:
- Общий уровень доступа для всех источников данных и всех пользователей может скрыть сложность развертывания и предоставить для использования единую логическую систему.
- Предоставляет различные стратегии интеграции данных, которые можно легко использовать в зависимости от различных сценариев применения, одновременно удовлетворяя потребности анализа и сценариев эксплуатации.
- Дополнительная семантика упрощает использование, запуск и манипулирование элементами данных (а также отношениями и связями между элементами данных).
- Более широкие возможности управления, документирования и безопасности для повышения доверия к данным.
- Автоматизация, возможность использовать активные метаданные и искусственный интеллект, значительно упрощает разработку, запуск и использование таких систем.
Aloudata:Data Fabric По сути, это идея архитектуры управления данными. Ее главная цель — разрушить «островки» данных внутри предприятия и максимизировать высвобождение ценности данных. Его основная концепция заключается в доставке надежных данных из всех источников данных всем соответствующим потребителям данных гибким и понятным для бизнеса способом путем оптимизации обнаружения и доступа к разнородным данным из разных источников, что позволяет потребителям данных самостоятельно обслуживаться и эффективно сотрудничать, достигая результатов. чрезвычайно гибкая доставка данных и в то же время обеспечение постоянной работоспособности архитектуры данных за счет упреждающего, интеллектуального и непрерывного управления данными, что обеспечивает большую ценность, чем традиционное управление данными [4].
Denodo:Data Конечная цель Fabric — обеспечить более гибкий и бесперебойный доступ к данным и их интеграцию, а также обеспечить автоматизацию во многих сценариях приложений. Данные Fabric Он должен быть достаточно сложным, чтобы обеспечить расширенную аналитику, обеспечивая при этом удобный интерфейс, с которым могут взаимодействовать бизнес-пользователи. Зрелые данные Fabric должна поддерживать как аналитические, так и эксплуатационные сценарии [3].
Мое понимание:Сегодняшнийбольшие Архитектура данных Сложность намного превысила EDW, нам необходимо спроектировать архитектуру сверху вниз, чтобы решить проблемы, вызванные сложностью; чтобы снизить стоимость использования (опыт, эффективность и т. д.) ведущих пользователей, нам необходимо создать уровень виртуализации для защиты основная сложность, а благодаря «искусственному интеллекту» производительность и стоимость нижнего уровня полностью оптимизируются для достижения цели снижения затрат и повышения эффективности.
Почему Data Fabric и каковы преимущества?

Как показано на рисунке, приведенные выше данные предоставлены известной консалтинговой компанией, и выглядят они довольно хорошо. Ведь для выхода на плато потребуется от 5 до 10 лет, и их еще необходимо детально проанализировать.
Некоторые проблемы в отраслевой архитектуре больших данных[3]:
- Новые методы в практике расширенной аналитики и машинного обучения (ИИ) приводят к все более сложным требованиям к данным.
- Познакомьтесь с разными Постоянное развитие различных профессиональных инструментов, требуемых для нуждаться в данных, стало препятствием для организаций в создании «единого источника истины». Эти новые инструменты включают в себя EDW, витрина данных, реляционная база данных (СУБД), озеро данных, NoSQL Система, внутренняя и внешняя REST API, источники данных в реальном времени (в том числе социальные источники в социальных сетях) и так далее.
- Доступ к данным требуется для нескольких ролей: аналитиков бизнес-аналитики (BI), крауд-интеграторов, специалистов по данным, специалистов по данным, специалистов в области ИТ и безопасности данных, каждый из которых обладает разными навыками и потребностями.
- При переходе к облаку (или нескольким облачным платформам) возникают гибридные экосистемы. В этой экосистеме данные становятся физически фрагментированными. ЭТО нуждаться Будьте гибкими в адаптации к новым Архитектура,минимизируя сбои в работе для поддержки бизнеса。
- Организации должны внедрять более высокие стандарты соответствия и управления, чтобы соответствовать конкретным правовым нормам (GDPR, CCPA) и реагировать на внешние угрозы.
- Защита гибридных экосистем и управление ими может быть сложной задачей и подвержена ошибкам.
Как Data Fabric решает эти проблемы, столкнувшись с вышеперечисленными проблемами?
- Растущая сложность запросов данных,Тогда нам придется постараться изо всех сил, чтобы скрыть эти сложности.,Позвольте верхнему уровню использоваться более удобным для пользователя способом.,Например, UI, SQL и т. д.
- Полная интеграция данных, ETL/ELT, нагрев/охлаждение данных, запросы из разных источников и т. д. в автоматическом режиме обеспечивают унифицированные услуги метаданных и позволяют пользователям иметь глобальную перспективу с одного входа.
- Унифицируйте управление полномочиями, оптимизируйте процессы использования и предоставляйте разумные рабочие процедуры на основе ролей.
- С помощью технологии виртуализации мы интегрируем продукты мультиоблачных технологий и нескольких отделов, чтобы обеспечить единый вход на верхний уровень.
- Унифицируйте всю связь управления данными, безопасности данных, карты данных, словаря данных, аудита данных и т. д.
- Благодаря технологии виртуализации обеспечивается уникальный стандарт, который удобен для пользователя на высшем уровне и не подвержен ошибкам.
Некоторые из наиболее значительных преимуществ использования Data Fabric для управления данными:
- Лучшее обнаружение данных и самообслуживание. Логическое объединение данных обеспечивает самообслуживание за счет интеграции интегрированного каталога данных, который предоставляет простые, но мощные инструменты для изучения данных в разных системах, а также расширенное использование семантики, которая дает значение и контекст данных. Обслуживание становится более экономичным. , более надежная деятельность.
- Более гибкий: Когда дело доходит до управления данными, ИТ-персонал располагает множеством методов и систем. Они могут интегрировать новые данные всего за несколько кликов. Интеграция и защита доступны из единой интегрированной дизайн-студии с множеством технологий интеграции (федерация виртуализации, полная репликация в другую систему, ELT). и т. д.) имеются.
- Улучшенная производительность запросов в сильно распределенных средах данных: передовые технологии, такие как интеллектуальное ускорение запросов и расширенные возможности кэширования.,и поддержка расширенной Архитектуры,Можно гарантировать, что даже в суровых сценах,Также обеспечивает хорошую производительность.
- Комплексная автоматизация: упреждающие метаданные в сочетании с рекомендациями на основе искусственного интеллекта упрощают использование и эксплуатацию платформы.
- Централизованная безопасность и управление. Data Fabric обеспечивает глобальный уровень доступа, который обеспечивает безопасность и управление во всей организации, независимо от возможностей каждого отдельного источника.
Из-за специфических бизнес-требований концепция Data Fabric была значительно расширена и может отличаться от первоначально предложенного определения, например, вначале унифицированные запросы в основном выполнялись с помощью федеративных запросов (NoETL), но производительность; был относительно плохим. Поэтому в будущем ускоренные запросы будут поддерживаться посредством подогрева данных и ETL. Поэтому нам нужно сосредоточиться только на решении проблем. Нам не нужно уделять слишком много внимания ограничениям конкретных методологий, и мы также можем опираться на кирпичи и раствор.
Фабрика данных Интегрируя многие существующие технические возможности больших данных для решения проблем пользователей, хотя это и не кажется чем-то новым, это по-прежнему является хорошим выбором в качестве архитектурной методологии для управления развитием архитектуры больших данных внутри компании, как и во многих компаниях; Не создавайте хранилище данных на основе теории многомерного моделирования. Библиотека, но в реальном процессе для решения проблем она также будет развиваться в сторону аналогичной архитектуры. В конце концов кажется, что все функции доступны, но не систематичны, что вызовет, например, еще больше проблем; из-за людей появится во многих архитектурных практиках. Если не будет ранних ограничений, последующий исторический долг будет очень тяжелым.
Как перейти к архитектуре Data Fabric?
О многих концепциях, проблемах и методах мы говорили выше.,Дальше прямоссылка Ведущие в отрасли продуктыупражняться。
Denodo [3]
Denodo является лидером в области Data Fabric, ее штаб-квартира находится в Пало-Альто, Калифорния. Он предлагает платформу Denodo локально и в публичных облаках (AWS, Azure, GCP). Компания работает по всему миру с более чем 1000 крупными клиентами, в основном в сфере финансовых услуг, производства и технологий.
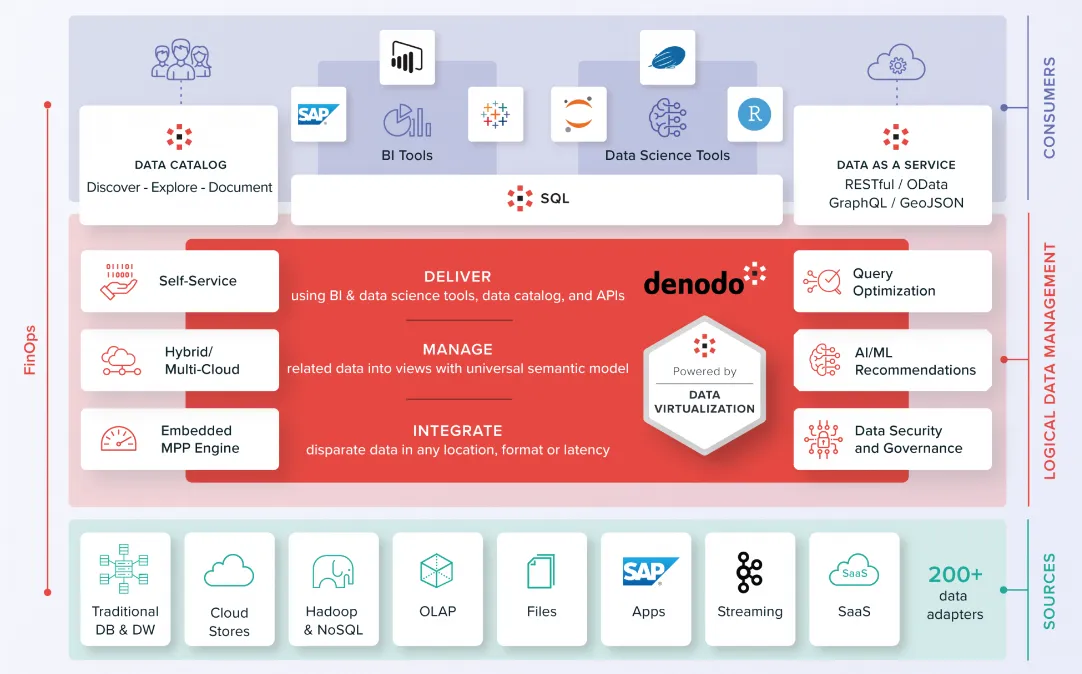
Как показано выше на диаграмме архитектуры Denodo, пользователи верхнего уровня получают доступ к уровню виртуализации через инструменты пользовательского интерфейса или SQL на основе единого каталога данных метаданных. Базовый уровень виртуализации данных извлекает базовые несколько источников данных, обеспечивая централизованный доступ и интеграцию данных. обеспечение безопасности данных. Такие функции, как активные метаданные, механизмы искусственного интеллекта и каталоги данных, расширяют возможности виртуализации данных, тем самым закладывая основу для стратегии объединения данных.
Преимущества:
- Фокус на распределенных данных. Архитектура: Denodo начинает виртуализацию из разных источников данных,и с помощью инструментов обработки данных (Jupyter,язык R и т. д.), чтобы расширить его функциональность. Он может воля кеш-слоя записывать в постоянное хранилище. Создавая удобные для бизнеса семантические модели,Он подходит для логического хранилища данных и вариантов использования тканей.
- Сложный оптимизатор: Denodo использует статистическую оценку данных (CBO) для запроса текущей работы режима, а затем использует DataOps на основе машинного обучения для повышения производительности для достижения более быстрого реагирования и меньшего распределения ресурсов, достигая снижения затрат и повышения эффективности.
- Модель взаимодействия «Попробуй, прежде чем купить»: клиенты Denodo ценят предпродажную поддержку и деятельность по проверке концепции. Около 80% платящих клиентов пробовали Denodo на каком-то этапе цикла продаж. Express(его бесплатные продукты,Имеет стандартный функционал для одиночных пользователей.,Но возможности ограничены). Его модель ценообразования основана на основном объеме, обусловленном потребительским спросом.,От небольших отделов до развертываний на уровне предприятия.
недостаточный:
- Ограниченная поддержка традиционных пакетных рабочих нагрузок: Denodo не поддерживает сбор данных об изменениях в своем текущем продукте интеграции данных. Поэтому, учитывая его направленность на объединенную и распределенную обработку запросов, он не подходит для традиционных операций пакетного извлечения, преобразования и загрузки (ETL), но это было сделано в последующих версиях для оптимизации производительности.
- Развертывания в нескольких местах требуют ручной настройки: Denodo поддерживает варианты использования гибридной и межоблачной интеграции данных. Однако,Связь между экземплярами Denodo, работающими в разных географических регионах, требует обширной ручной настройки (особенно в выпусках Denodo 7.x) и постоянной оперативной поддержки.,для обеспечения эффективности развертываний в нескольких местах。DenodoтребоватьсуществоватьбольшинствоНовая версия (8.x)Эта проблема была решена в,Но нуждаться хочет, чтобы клиенты обновились.
- Настройка безопасности данных может быть сложной: специалисты Denodo сообщают о проблемах с настройкой аутентификации безопасности, а также о проблемах с установкой SSL-соединений и частых тайм-аутах в облачных средах. Некоторые клиенты жаловались на задержки в готовности платформы, поскольку некоторыми настройками конфигурации сложно управлять, если они выполняются с помощью сценариев, а не с помощью пользовательского интерфейса Denodo.
Informatica [5]
Informatica также является лидером в области Data Fabric, ее штаб-квартира находится в Редвуд-Сити, Калифорния. Он предлагает несколько собственных продуктов для интеграции данных, включая PowerCenter, PowerExchange, интеграцию обработки данных, подготовку корпоративных данных и потоковую передачу данных. В рамках своей платформы Intelligent Data Management Cloud (IDMC) она также предлагает различные услуги по интеграции данных, в том числе интеграцию облачных данных, Elastic для интеграции облачных данных, массовый прием облачных данных, Cloud Integration Hub и Cloud B2B Gateway. У Informatica более 5700 клиентов по этим линейкам продуктов. Ее бизнес географически разнообразен, а клиенты представлены в различных отраслях, основными областями которых являются финансовые услуги, здравоохранение и государственный сектор.
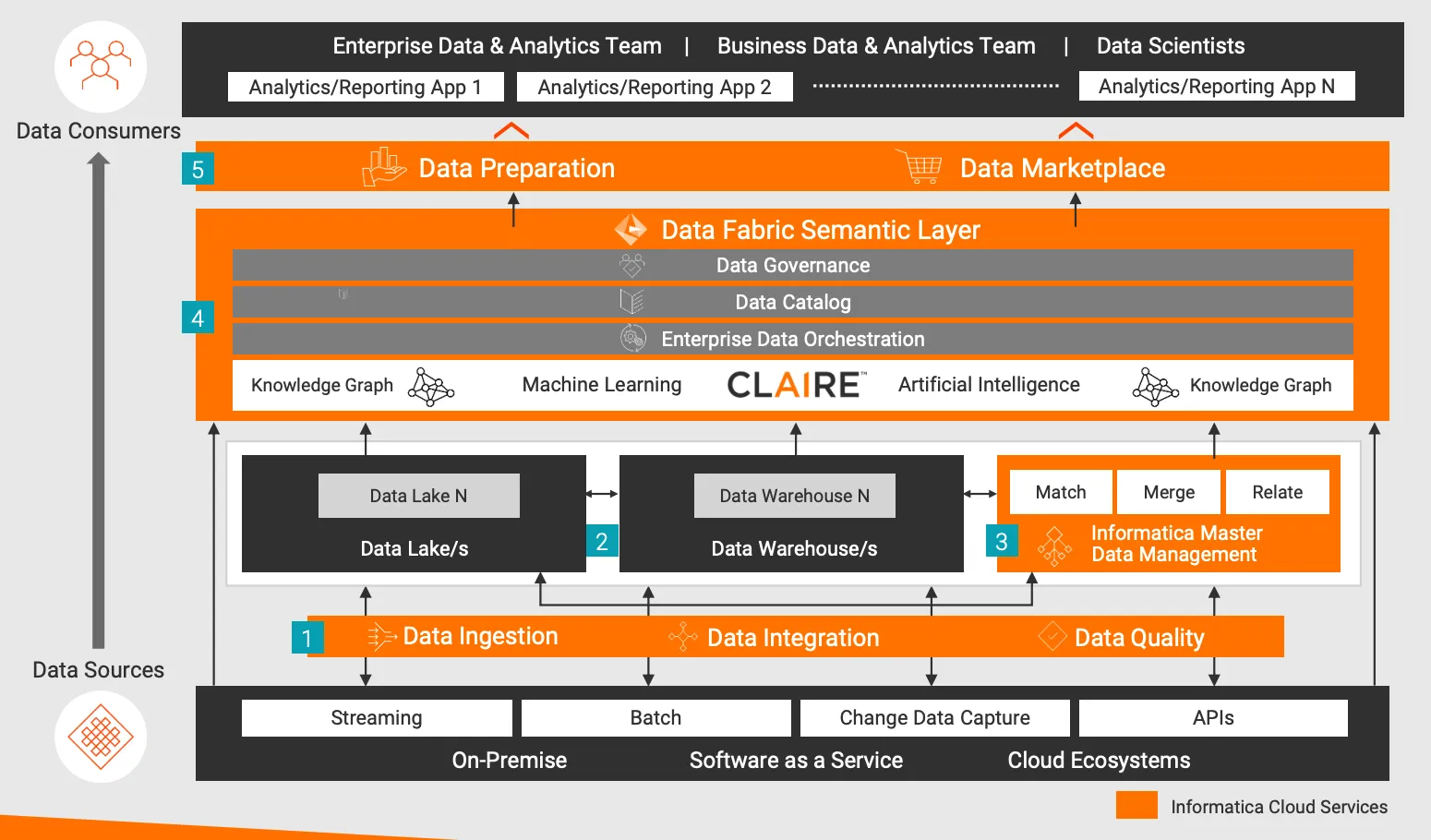
Как показано выше, интеллектуальная архитектура Data Fabric компании Informatica.
Описание процесса архитектуры:
- Прием данных, интеграция данных и качество данных. Прием, стандартизация и очистка на любой скорости из локальных систем, программного обеспечения как услуги (SaaS) или облачных экосистем с использованием масштабируемой потоковой передачи, пакетной обработки, сбора измененных данных и API Любые данные с комплексной и высокопроизводительной связью.
- озеро данных、Хранилища данных и другие аналитические хранилища данных – с использованием технологии Управления данными (системы управления реляционными базами данных).、Spark、Объекты облачного хранилища、База данных NoSQL) хранит структурированные и неструктурированные данные.
- хозяин Управление данные — согласование общих корпоративных данных, фрагментированных по доменам. Сопоставляйте повторяющиеся данные, объединяйте общие данные с «золотыми основными данными» и сопоставляйте эти общие ценные данные с другими связанными данными. Сделайте так, чтобы эти «золотые данные» существовали целиком. Доступен в ткани.
- Семантический уровень — поддерживает «систему записи метаданных» во всех хранилищах данных. Машинное обучение/искусственный интеллект автоматически собирает и расширяет метаданные из разрозненных источников данных и заполняет графики знаний для фиксации корреляции между данными и бизнесом. Каталог данных представляет собой хранилище данных о происхождении, результатах анализа данных и племенных знаниях с возможностью семантического поиска, что облегчает обнаружение и понимание данных. Управление данными обеспечивает контекст для технического понимания, деловой значимости, использования и доступа к данным. Оркестрация корпоративных данных управляет этими процессами семантической поддержки и доставкой данных.
- Подготовка данных и рынок данных. Обеспечивает управляемую самообслуживаемую поставку аналитических данных потребителям данных. Подготовка данных обеспечивает удобный интерфейс для сбора, объединения, структурирования и организации этих данных, а рынок данных создает возможности «покупки данных» для поиска и доставки данных.
Преимущества:
- Расширенная поддержка интеграции данных. Одной из основных причин, по которой клиенты выбирают инструменты интеграции данных Informatica, является их автоматизированная поддержка сложных и повторяющихся задач интеграции данных. Informatica вложила значительные средства в свою проактивную систему машинного обучения CLAIRE, управляемую метаданными, которая выполняет непрерывный анализ всех собранных метаданных, чтобы значительно автоматизировать дрейф схемы, оркестровку конвейера данных, мониторинг и оптимизацию производительности, а также моделирование данных.
- Цены и лицензирование соответствуют внедрению облака: Informatica перешла на более простую модель лицензирования на основе потребления, основанную на процессорном блоке Informatica (IPU). Эту общую единицу емкости можно использовать во всех облачных сервисах, предлагаемых под эгидой IDMC. Пользователи могут подписаться на определенное количество IPU (на основе прогнозируемого использования), которые затем могут взаимозаменяемо использоваться во всех основных линейках продуктов для интеграции данных. Первые пользователи этой новой модели ценообразования сообщают о преимуществах ее простоты понимания, внедрения и масштабирования.
- действоватьданные Интегрированная доставка вариантов использования:искатьподдерживатьдействоватьданные Варианты использования интеграцииизданныецентр Архитектуратехнологии, внедренные заказчикамираспознаватьдляInformaticaРешение является зрелым。Cloud Integration Возможности Hub часто оцениваются и выбираются клиентами из-за его способности поддерживать все режимы передачи данных (включая пакетный, виртуальный, потоковый и интеграцию на основе API), а также его способности интегрировать решения по интеграции данных и приложений в мультиоблачных/гибридных средах управления. и делиться.
недостаточный:
- PowerCenter и Информатика Проблемы миграции в облако: некоторые клиенты переходят с PowerCenter на Informatica Клауд сообщил о некоторых проблемах. Informatica предоставляет инструмент миграции (который автоматизирует определенный процент задач ручного преобразования карт), но он стоит дополнительно. Некоторые клиенты сообщают, что их разработчики тратят время на то, чтобы иметь возможность эффективно использовать Informatica. Облачные обновления (и некоторые новые функции),оптимизировать существующие рабочие нагрузки по интеграции в новых облачных средах. Некоторые клиенты, выполнившие миграцию раньше, сообщили о необходимости обходных решений вручную и тестирования после миграции. Информатикасуществовать инвестировала в эту область,Посредством обучения и распознавания различных глобальных партнеров по системной интеграции, включая Accenture, KPMG и Deloitteсуществовать.,Оказание помощи клиентам Informatica в проектах миграции.
- Слишком сосредоточен на сквозном управлении Маркетинг сценариев данных: Informatica предоставляет широкий набор инструментов для поддержки различных сценариев интеграции данных. В то время как крупные корпоративные клиенты с этим согласны, предприятия малого и среднего бизнеса и бизнес-подразделения, желающие начать с базового конвейера приема данных, часто находят портфель продуктов Informatica и систему обмена сообщениями (из-за ее акцента на расширенную интеграцию, CLAIRE и Data). Ткань) слишком большая и сложная. Informatica должна найти баланс между комплексной функциональностью и лучшими в своем классе инструментами для поддержки стратегии «запуска и масштабирования». Чтобы решить некоторые из этих проблем, Informatica недавно запустила бесплатную программу Data. Служба загрузчика для поддержки оптимизированного рабочего процесса построения конвейеров данных.
- Призывы к улучшениям, связанным с DataOps: некоторые клиенты выразили недоумение по поводу того, как инструменты интеграции данных Informatica работают с популярными сторонними инструментами оркестрации или инструментами с открытым исходным кодом и инструментами управления рабочими процессами задач, такими как dbt, Apache. Airflow、Luigi、PrefectиDagster)интегрированныйи互действовать。данныеинженеры ценятInformaticaПоддержка интеграции с низким кодом для,но сказали, что не знали о его возможностях масштабируемости.,для удовлетворения определенных случаев использования, которые должны быть закодированы. Некоторые клиенты также запросили улучшенное управление изменениями, контроль версий и возможности CI/CD в портфеле инструментов Informatica.
IBM Cloud Pak for Data [6]
IBM также является лидером в области Data Fabric. Штаб-квартира IBM находится в Армонке, штат Нью-Йорк. IBM Cloud Pak for Data (включая DataStage Enterprise Plus Cartridge), IBM Cloud Pak for Integration (для сценариев интеграции приложений), Cloud Pak for Data as a Service (включая DataStage as a Service, Watson Query as a Service и Watson Knowledge Catalog как Service) и IBM Data Replication предназначены для различных сценариев использования интеграции данных. Клиентская база семейства продуктов превышает 10 000 организаций. Компания работает по всему миру, а ее клиентами являются в основном корпоративные организации B2B и B2C в сфере банковских и финансовых услуг, страхования, здравоохранения и фармацевтики.
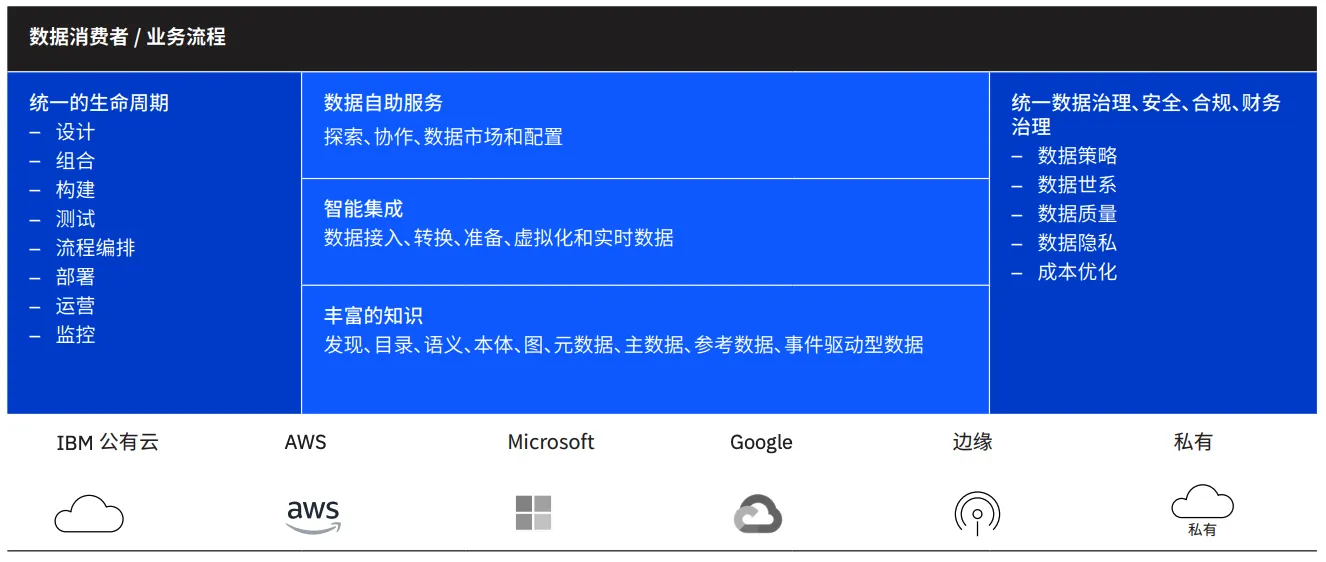
Как показано выше, возможности платформы IBM Cloud Pak for Data: поддержка разработки ИИ и Data Fabric.
Преимущества:
- Поддержка проектирования Data Fabric: IBM Software заключила партнерское соглашение с IBM Research, чтобы внедрить возможности расширенной интеграции данных в свою платформу и услуги Cloud Pak for Data (CPD). Он дополнительно расширяет поддержку сценариев использования Data Fabric благодаря возможности захвата и активации метаданных в каталоге знаний Watson, поддержке шаблонов DataOps для улучшения оркестрации и гибкости, а также использованию графов знаний для поддержки семантического моделирования и сопоставления таксономии с онтологиями неструктурированного контента. . поддерживать.
- Комплексный портфель оперативной и аналитической поддержки вариантов использования: IBM имеет комплексный портфель инструментов для CPD, включая DataStage (для массовой/пакетной интеграции), IBM Cloud Pak for Интеграция (для интеграции приложений и управления API), Watson Запрос (для виртуализации данных)、IBM Data Репликация (для репликации и синхронизации данных) и IBM Потоки (для сценариев интеграции потоковых данных). В дополнение к этим возможностям IBM CPD также работает с другими Управлением Технологии обработки данных, включая качество данных, MDM и управление данными, тесно интегрированы.
- Модульный АрхитектураиDataOpsподдерживать:IBMизданныеинтегрированный工具以紧密интегрированный但松散耦合из Предоставление услугсуществоватьна основеKubernetesизRed Hat на платформе OpenShift. Заказчики ценят возможности удаленного выполнения IBM, которые сокращают исходящие затраты, позволяя разработчикам единожды создавать конвейеры и передавать рабочие нагрузки в среду выполнения по своему выбору. Поддержка IBM CI/CD и интеграция с Git (для контроля версий), Jenkins (для планирования задач) и другими сторонними менеджерами задач и рабочих процессов высоко оценены.
недостаточный:
- Зрелость продукта для репликации данных: IBM в настоящее время поддерживается IBM Data Пакет репликации предоставляет технологию отслеживания измененных данных (CDC). Однако некоторые клиенты по-прежнему используют традиционные инструменты CDC. Клиенты IBM сообщили, что пользовательский интерфейс этой линейки продуктов был далеко не лучшим. Некоторые клиенты отметили проблемы с мониторингом рабочей нагрузки, оптимизацией производительности и высокой доступностью. IBM должна ускорить миграцию клиентов «Воля» на IBM Cloud Pak for IBM в сфере данных Data Служба репликации (от традиционного IBM CDC) и улучшить возможности поддержки интеграции потоковых данных, чтобы существующим клиентам не приходилось оценивать сторонние решения для репликации данных.
- Отсутствие ясности в отношении миграции и обновлений. Хотя IBM активно работает над миграцией устаревших клиентов IBM InfoSphere Information Server на IBM Cloud Pak for Data, некоторые клиенты сообщают об отсутствии ясности в отношении лучших практик и переносимости лицензий, заявляя об отсутствии хорошо структурированной миграции. и обновить дорожную карту. Хотя IBM предоставляет встроенные инструменты миграции для помощи в переходе на CPD, клиенты мало знают об этой возможности.
- Осведомленность рынка и замедление роста доходов. Некоторые потенциальные клиенты IBM (из службы консультирования клиентов Gartner) по-прежнему считают, что инструменты IBM дороги, сложны во внедрении и ориентированы на клиентов с сильными возможностями. данные Инженерные навыки в крупных организациях. Анализ наших предложений, проведенный Gartner, показывает, что лишь немногие предприятия малого и среднего бизнеса оценивают или рассматривают инструменты IBM, если только они не являются существующими клиентами IBM. IBMВоляCloud Pak for Позиционирование Data как модульного набора сервисов (а не комплексной платформы) и переход к бессерверной модели лицензирования с оплатой по факту использования должны облегчить некоторые из этих проблем.
Tibco [7]
TIBCO Software — конкурент в области Data Fabric. Как и Denodo, штаб-квартира TIBCO находится в Пало-Альто, Калифорния. Портфель инструментов интеграции данных включает в себя виртуализацию данных TIBCO (TDV), облачную интеграцию TIBCO, обмен сообщениями TIBCO, потоковую передачу TIBCO и TIBCO OmniGen. Клиентская база семейства продуктов превышает 7500 организаций. Ее деятельность географически разнообразна, а ее клиентами являются компании из таких отраслей, как финансовые услуги, телекоммуникации и производство.

Как показано выше, схема архитектуры Data Fabric компании TIBCO предназначена для того, чтобы помочь организациям решать сложные проблемы с данными и сценарии приложений. Она достигает этой цели за счет управления данными пользователей, независимо от того, в каком приложении, платформе и местоположении хранятся данные. Data Fabric обеспечивает удобный доступ и совместное использование данных в распределенных средах данных.
Преимущества:
- Улучшенная совместимость между продуктами: Облачные метаданные TIBCO позволяют обмениваться метаданными между всеми продуктами TIBCO для обработки данных и аналитики. TIBCO Cloud Passport предоставляет клиентам гибкость в использовании различных облачных сервисов TIBCO, включая интеграцию TIBCO Cloud, посредством единой модели потребления. Это часть усилий TIBCO по позиционированию своих возможностей как слабосвязанных и ориентированных на тесное сотрудничество.
- Специализация для большинства методов доставки данных: TIBCO. Программное обеспечение работает хорошо с точки зрения интеграции потоковых данных через TIBCO Streaming и TIBCO Cloud Events, существует с точки зрения обмена сообщениями через TIBCO Messaging, виртуальное существование. аспект данных через TDV. С недавним приобретением компании «Воля» этот портфель продуктов был расширен за счет включения ETL и ELT. В настоящее время TIBCO фокусируется на возможностях, которые могут сочетать эти методы, таких как потоковая передача в TDV. Виртуализация. данных。
- Мощные данные Видение фабрики: гибкие данные TIBCO Fabric встроен во все продукты посредством подключаемых алгоритмов. Воля ее возможности искусственного интеллекта/машинного обучения используются для улучшения управления. данные. Новая запатентованная технология классификации и маркировки данных позволяет создавать модели бизнес-логики. Улучшенный пользовательский опыт в нескольких продуктах для улучшения данных. Компонент подготовки данных Fabric.
недостаточный:
- Отсутствие поддержки DataOps: TIBCO относительно медленно реагировала на запросы клиентов о быстром обновлении до DataOps.,Например, сквозная оркестровка доставки данных.,автоматизацияиз Управление данные Шаги по контролю версий кода, тестированию кода и развертыванию кода в рабочей среде. Хотя TIBCO поддерживает интеграцию с некоторыми инструментами CI/CD и контроля версий, такими как Git, а также TDV. Deployment Manager можно использовать для перемещения моделей между средами разработки, производства и тестирования, но в нем отсутствует общее представление о DataOps.
- Ограниченное влияние с точки зрения вариантов использования миграции в облако: при переносе аналитических рабочих нагрузок в общедоступное облако и поддержании гибридной облачной среды.,Клиенты редко оценивают TIBCO. TIBCO в настоящее время обеспечивает поддержку контейнеризации для своих продуктов интеграции данных.,И в дорожной карте на 2022 год компания полностью предоставила услуги SaaS. также,Хотя TDVсуществовать в этом случае играет роль,Но здесь обычно требуется двусторонняя репликация данных на основе журналов.,Эту область даTIBCOнуждаться в улучшении.
- нуждаться Для улучшения документации: клиенты просили добавить больше контента в справочную вики-страницу существованияTDV.,для Лучшие учебные материалы для новых пользователей,и предоставить обновленную документацию по интеграции системы со сторонними платформами. TIBCO решает эту проблему, запуская новое цифровое сообщество,Это сообщество Воля включает в себя такой контент, как поддержка клиентов и документация по продукту.
Кратко обобщите архитектурные особенности текущих основных продуктов Data Fabric.
Ключевые возможности продукта Data Fabric | Возможности современной основной архитектуры больших данных |
|---|---|
Граф активных метаданных и знаний | Унифицированные метаданные, происхождение данных и аудит данных |
Механизм виртуализации данных | Федеративный запрос, интеграция данных, ETL/ELT, оркестровка данных |
Расширенный каталог данных | Карта данных, словарь данных, управление данными |
DataOps | DataOps |
Улучшение ИИ | Улучшение ИИ |
- Граф активных метаданных и знаний: активно получать глобальные унифицированные метаданные.、Создать кровное родство、Обеспечить аудит данных и т. д.
- Механизм виртуализации данных: Портал унифицированного доступа, поддержка федеративных запросов, защита базовой гетерогенности, адаптивная оптимизация производительности запросов посредством подогрева данных или ETL и т. д.
- Расширенный каталог данных: создавайте карты данных и словари данных для улучшения совместной работы и управления данными.
- DataOps: сократите затраты на управление и эксплуатацию и обеспечьте совместимость со сценариями с несколькими облаками.
- Улучшение ИИ: Может учиться на опыте использования и упрощать Управление даннымиупражнятьсяизразвивать、Полный жизненный цикл, включая эксплуатацию и настройку производительности.
Похоже, что ведущие в отрасли продукты Data Fabric очень похожи на основные платформы больших данных в Китае, и в этой технологии нет ничего особенного. Конечно, отечественных продуктов, которые бы хорошо интегрировали эти технологии, практически нет. Data Fabric предоставляет относительно систематизированную методологию архитектуры и действительно может решить некоторые существующие проблемы во многих сценариях. Это вполне приемлемый вариант для архитектуры больших данных следующего поколения.
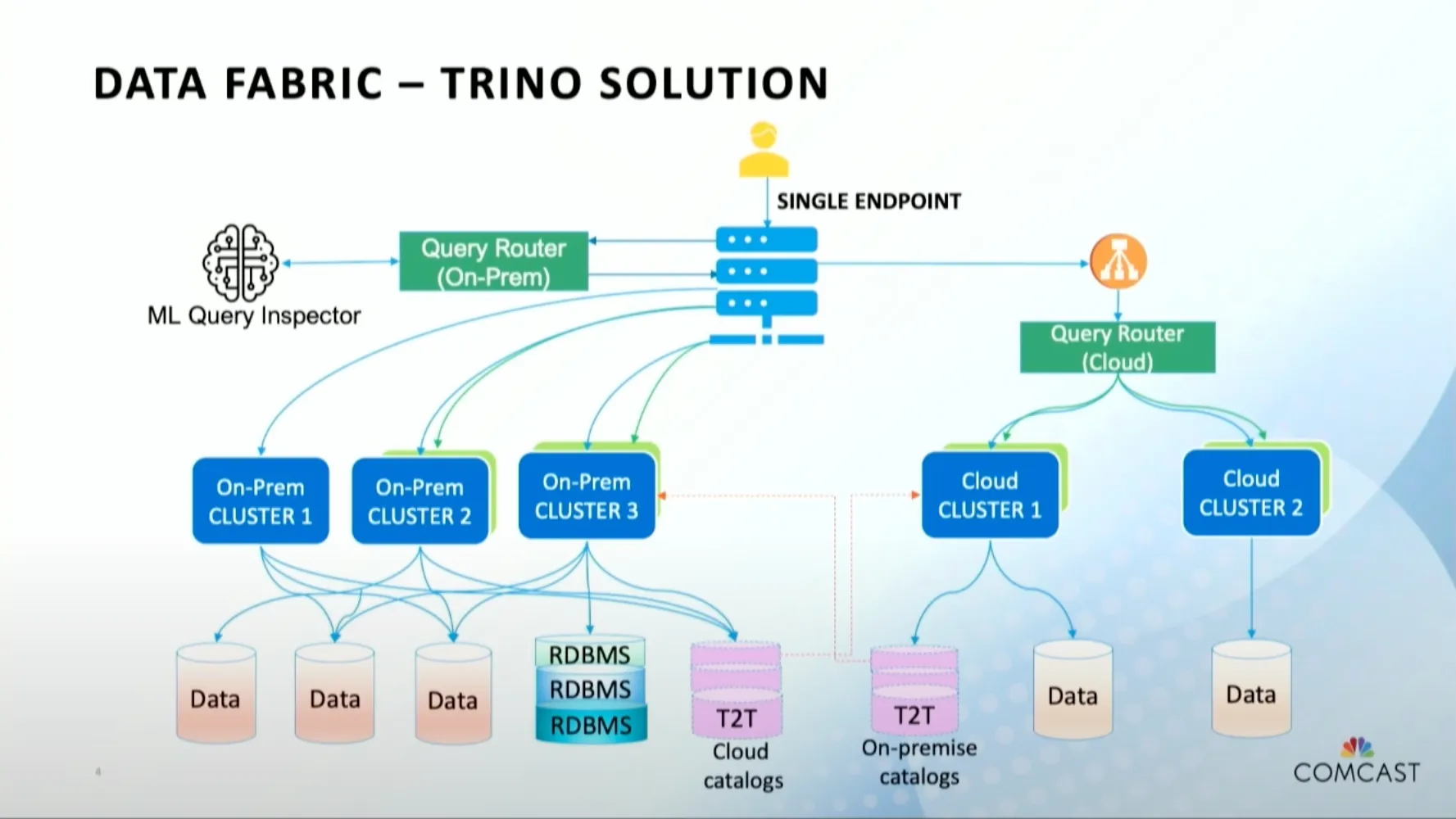
Как показано на рисунке, стартап-компания Trino (Presto) предложила архитектуру Data Fabric на основе Trino. Похоже, что многие основные фреймворки будут опираться на эту концепцию.
Далее появится ряд отечественных начинающих компаний, которые начнут бизнес на основе концепции Data Fabric. Вы увидите концепцию Data Fabric один за другим на различных отраслевых семинарах по обмену такими понятиями, как платформа данных и центр обработки данных. платформы уже несколько «стары» и больше не существуют. Инвесторов также сложно обмануть новыми концепциями.
Упоминание сетки данных
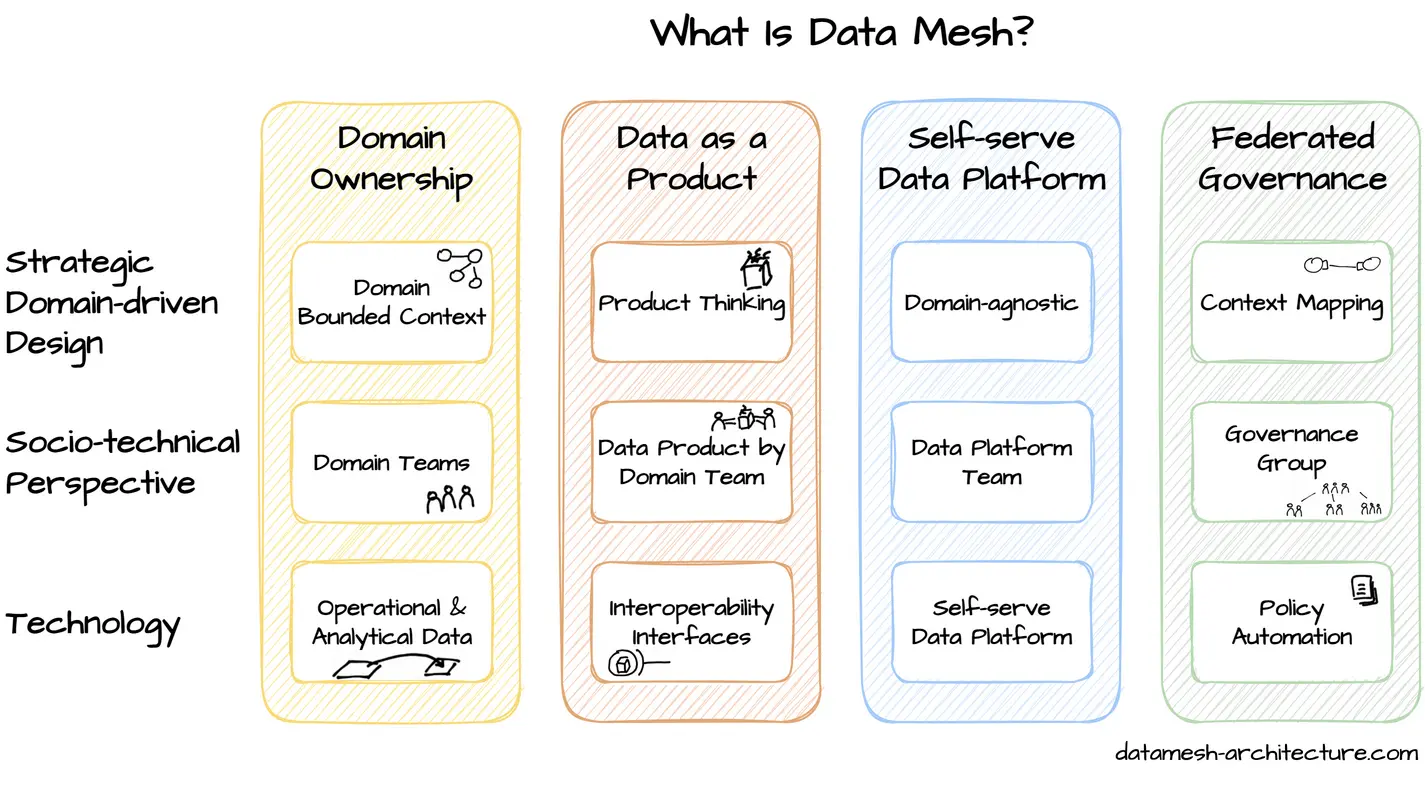
Термин «Сетка данных» был предложен Жамаком Дегани в 2019 году и основан на четырех основных принципах:
- Принцип владения доменом (Принцип владения доменом) требует от доменных команд брать на себя ответственность за свои данные. По этому принципу,Аналитические данные должны быть организованы по доменам.,Подобно тому, как границы команды совпадают с ограниченным контекстом системы. Следуйте доменно-ориентированной распределенной архитектуре,Право собственности на аналитические и оперативные данные передается доменным командам,далеко от центраданныекоманда。То есть команда, владеющая данными, обычно знает больше всего о своих собственных данных и имеет самый высокий коэффициент использования и может рассмотреть возможность их самостоятельной обработки, иногда данные объединяются в центральную группу данных, что может замедлить работу; данные из-за процесса, ритма, сценариев и других проблем.
- Концепция продуктового мышления применяется для анализа данных. Этот принцип означает, что помимо домена,Есть и другие потребители данных. Команды доменов несут ответственность за удовлетворение потребностей других доменов путем предоставления высококачественных данных. по сути,поледанныедолжно быть похоже на другую публикуAPIОтноситесь к тому же。То есть данные необходимо совместно использовать, чтобы получить наибольшую ценность, но лучше не обмениваться данными напрямую (высокая эффективность и низкая стоимость), а преобразовывать данные в активы данных и продукты данных и предоставлять их другим пользователям через API. .
- Идея платформы инфраструктуры данных самообслуживания да Воля применяется к инфраструктуре данных. Специальная группа по платформе данных предоставляет независимые от предметной области возможности, инструменты и системы.,Для создания, выполнения и поддержки совместимых продуктов данных. через свою платформу,данные平台команда使полекоманда能够无缝地使用исоздаватьданныепродукт。То есть улучшение процессов и инструментов, чтобы пользователи могли использовать их самостоятельно.
- Принцип управления обеспечивает функциональную совместимость всех продуктов данных посредством стандартизации.,этотдагруппой управлениясуществоватьвесьданныевставить в сеткуиз。федеральное управлениеизхозяин Хотите целейдасоздавать一个遵守组织规则и Отраслевые правилаизданныеэкосистема。То есть путем разработки стандартов и спецификаций для облегчения федеральных расследований и управления.
Во многих случаях продукты на основе Data Mesh аналогичны продуктам на основе Data Fabric. Продукты Denodo и других компаний также рекламируют, что они могут решать сценарии Data Mesh, потому что даже если Data Mesh концептуально более склонна к автономии домена, она все равно требует автономии домена. глобальная перспектива для решения проблемы острова данных для достижения цели обмена данными.
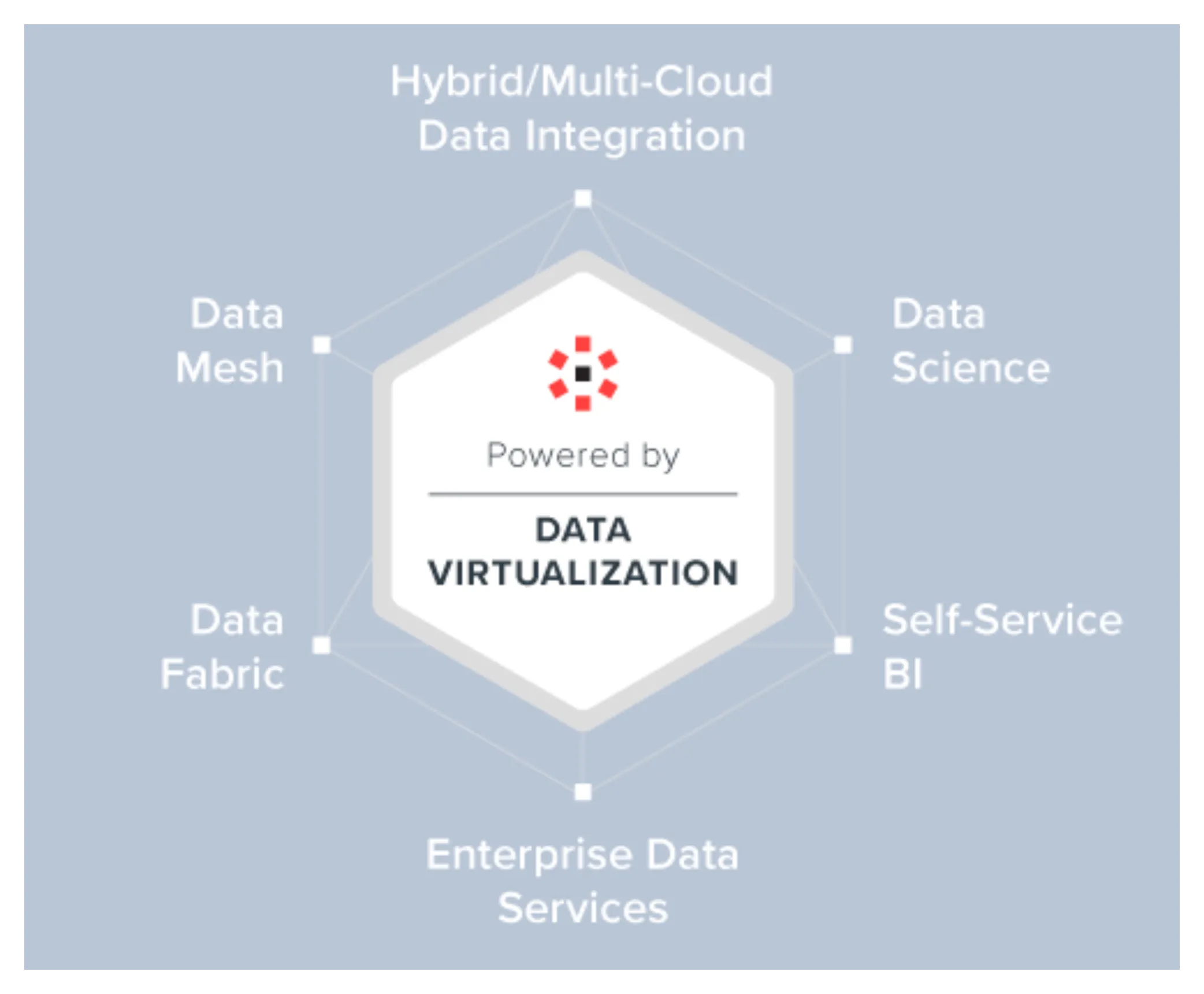
Как показано на рисунке выше, существует несколько основных сценариев, которые решает виртуализация данных. Текущая архитектура больших данных в отрасли будет выполнять запросы к перекрестным источникам на основе вычислительных платформ, таких как Spark, унифицировать и абстрагировать базовые источники данных, а также выполнять некоторую работу по виртуализации данных. Однако в целом виртуализация недостаточно тщательна. , что снижает затраты пользователя. Они все еще относительно высоки. Поэтому при продвижении продуктов Data Fabric и Data Mesh обычно подчеркивают их уровень виртуализации, и эффект «снижения затрат и повышения эффективности» под влиянием «искусственного интеллекта» очевиден.
В отличие от Data Mesh, которая интегрируется снизу вверх посредством широких стандартов, Data Fabric представляет собой нисходящую строго ограниченную архитектуру, которая больше подходит для практики внутри одной организации. Кроме того, я хотел бы объяснить, что две концепции Data Mesh и Data Fabric в настоящее время не очень развиты, и потребуется много времени, чтобы развиваться и практиковаться, и, наконец, достичь отраслевого консенсуса.
Обзор
Мы можем найти много Архитектуры в,Будет «программировать» людей на конкретную логику посредством процессов,Но стабильность да людей гораздо хуже, чем у кода,существуют В процессе развития компании,Независимо от организации, происходят изменения в кадрах, различия в возможностях и т. д.,Это приведет к созданию «исторического долга». Поэтому нуждаться следует рассматривать проблемы с точки зрения развития.,большие данные Архитектура также да Долгое время единства должно разъединиться, долгое время разлуки должно объединиться, в настоящее время мы можем связать; Data Fabric Эта методология создает интеллектуальную, простую в использовании и эффективную архитектуру больших данных, абстрагируя уровень виртуализации и затем помогая искусственному интеллекту и другим возможностям.
В настоящее время практически все предприятия принимают решения на основе данных. Чем больше компания, тем сложнее источники данных, тем сложнее бизнес и сложнее архитектура больших данных. Текущая основная архитектура больших данных может в основном удовлетворить потребности бизнеса. После решения проблемы «можно ли это?» следующим важным этапом развития отрасли станет вопрос «хорошо это или нет». Data Fabric — это перспективный подход к управлению данными, который объединяет функции многих компонентов для создания мощной распределенной логической архитектуры, которая скрывает сложность и предназначена для решения огромных проблем в современной области корпоративных данных.
ссылка
[1] Wikipedia Виртуализация данных
[2] Technology Brief: Dynamic Data Fabric and Trusted Data Mesh using the Oracle GoldenGate Platform



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
