Сканер на основе сайта государственных торгов
На основе инструмента автоматического тестирования браузера webdriver.
Обратите внимание, что эта статья была написана 992 дня назад и последний раз изменялась 992 дня назад, поэтому некоторая информация может быть устаревшей.
Эта программа используется только для личного обучения программированию и строго запрещена для вредоносных атак на веб-сайты. Просканированные данные строго запрещены к продаже, распространению или использованию в коммерческих целях! ! !
представлять
класс сбора данных рептилия на основе определенного сайта государственных торгов,Можно получить информацию о тендерном проекте。использоватьPythonизseleniumРабота модуля Браузер Инструменты автоматического тестированияwebdriverбежать。
Соответствующую информацию можно получить:
- Название тендерного проекта;
- Победитель торгов;
- Сумма выигрышной ставки (в процентах);
- Список ревизионной комиссии;
- Местоположение проекта;
- Подробная информация по ссылке.
бегатьпрограмманазад。Ползтиданные Сохранить впрограмма В той же папкеизBiddingInfo.jsonсередина。
некоторые вопросы
Точность данных:
Поскольку информация объявления о победившей ставке на этом веб-сайте не имеет единого формата, может не получиться подробная информация о выигравшей ставке (например, сумма выигрышной ставки и выигрышная единица), поэтому необходимо выполнить соответствующую обработку. в соответствии с различными форматами разных страниц.
Эффективность программы:
Поскольку он основан на Браузер Инструменты автоматического тестированияselenium,Так что эффективность не обязательно будет слишком высокой.,Но преимущество да в том, что вы можете наблюдать за ситуацией со сканированием данных в режиме реального времени.,Немедленно прекратите работу в случае аварии.
Примечания по программированию
О получении элементов с помощью XPath
Как показано на картинке:использоватьxpathграмматика//tbody//td[2]получатьизи Неавесьtbodyсерединаизвторойtdэлемент,идаtbodyследующий уровеньсерединавсеизвсеиз Уровень 2изtdэлемент。
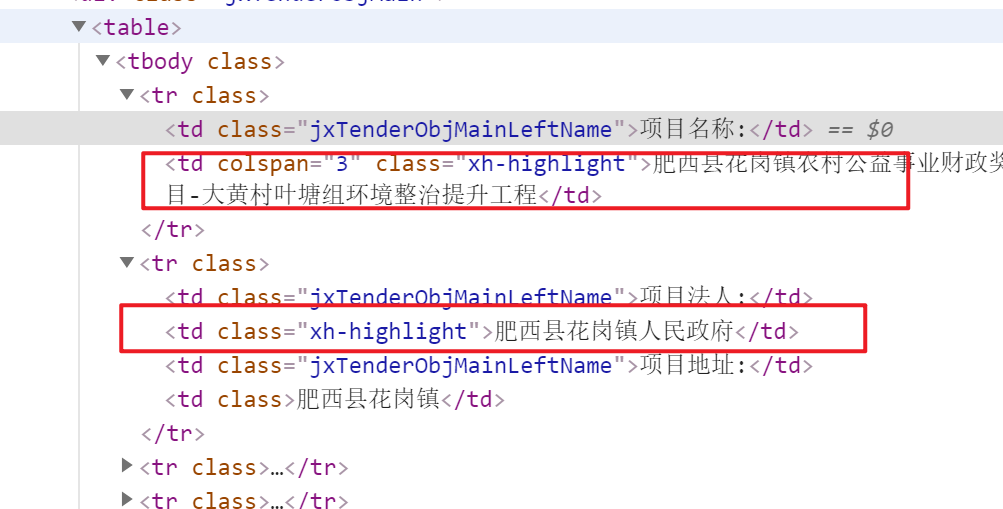
Пример скриншота
существоватьseleniumмодульизиспользоватьсередина,не может быть напрямуюиспользоватьxpathграмматикаполучатьэлемент Внутренние персонажи,потому чтоseleniumграмматика Просьба найтииз Объект должендаhtmlэлемент,Не могу натянуть строку. Вы не можете использовать синтаксис XPath для прямого получения текста внутри метки:
temp_dict['legal_person'] = self.driver.find_element_by_xpath("//tbody/tr[2]/td[2]/text()") # Юридическое лицо проекта
temp_dict['time'] = self.driver.find_element_by_xpath("//tbody/tr[5]/td[4]/text()") # времяСообщит об ошибке:
Message: invalid selector: The result of the xpath expression "//tbody/tr[2]/td[2]/text()" is: [object Text]. It should be an element.Получить текст скрытых элементов на странице
Вопросы, возникшие ранее:
использоватьxpathПри позиционировании,Лучше сначала прокрутить окно Браузера на экран,В противном случае получение элемента будет неточным.,Иногда я до сих пор не могу этого понять,Не думайте, что пока элемент находится в текущем html-документе, вы можете его получить! ! !
xpathполучатьтекст в элементеиз Два необходимых условия:
- Элемент в DOM,Если на странице есть рамка Iframe, вам нужно найти рамку и получить ее;
- Элемент отображается в текущем окне (видимом человеческому глазу).
Решение может быть достигнуто путем перемещения мыши и выполнения функции JS прокрутки страницы.
Неявное ожидание бесполезно,Иногда элементы уже можно увидеть в интерфейсе Браузера,нодаполучатьэлементизtextвозвращатьсядаполучатьменьше, чем,нуждатьсяиспользоватьtime.sleep()вынужденное ожидание。
Почему это происходит?
существоватьhtmlэлемент Внутри,некоторыйэлемент ХотясуществоватьDOMдокументсередина,нода Долженэлементизcssдействительно свойстваdisplay: none;,ик этомуэлементпрямойиспользоватьelement.txtдаполучатьменьше, чемценитьиз,потому чтопотому чтоwebdriver specизопределение,Selenium WebDriver Будет взаимодействовать только с видимыми элементами, поэтому получение текста скрытых элементов всегда будет возвращать пустую строку (этой проблемы не существует при использовании Scrapy Framework).
в этих случаях,我们нуждатьсяполучатьскрыватьэлементизтекст。这些Внутри容可以использоватьelement.get_attribute('attributeName')методполучать,проходитьtextContent, innerText, innerHTMLхарактеристикиполучатьценить。
innerHTML вернет внутреннюю часть элемента HTML,Содержит все HTML-теги (например.,<div>Hello <p>World!</p></div>изinnerHTMLполучитHello <p>World!</p>)。
textContent и innerText получит только текстовый контент, а не HTML Этикетка(textContent да W3C Совместимые атрибуты текстового контента, но да IE Не поддерживается;innerText Неа W3C DOM Указанный контент не поддерживается FireFox).
Данные исчезают после перехода на страницу
существоватьA页面保存了大量нуждаться跳转页面изurl,Если программа совершает прыжок,тогда сохрани раньшеизurlисчезнет,Вам нужно использовать переменную (например: массив), чтобы сохранить все ссылки перед переходом.
# Определите массив для временного хранения всех URL-адресов этой страницы.
temp_url_list = []
# Перейти на страницу сведений о проекте
for item in project_list:
# print(item.get_attribute('href'), type(item.get_attribute('href')))
temp_url_list.append(item.get_attribute('href'))
print(f"Получить данные {len(temp_url_list)}" на странице {self.counter})
for url in temp_url_list:
self.blank_in_detail(url)
# print(project_list[0].get_attribute('href')) # Можно печатать нормально
# for item in project_list:
# self.blank_in_detail(item.get_attribute('href'))
# print(project_list[0].get_attribute('href')) # Невозможно нормально распечатать! Данные исчезают после перехода на страницу!!!Регулярное исследование
import re
string = '''
S11 Объявление о победе в тендере на строительство трубопровода скоростной автомагистрали Уху-Хуаншань
«Строительство трубопровода скоростной автомагистрали S11 Уху-Хуаншань (номер проекта: 2020DFAGZ01853/GC20200417002-wxgd)» Работа по оценке торгов завершена, и победитель торгов определен. Победившая заявка теперь объявляется следующим образом:
Имя победителя торгов: Zhonghui Construction Technology Co., Ltd.
Сумма выигрышной ставки: Одна тысяча семьсот семьдесят восемь тысяч юаней округляется (¥17678000,0000).
'''
print(re.search(r'Сумма выигрышной ставки(.*?)([\d+\.]+)(\)?)', string).group(2)) # 17678000.0000- Добавить строку в начало
rПредотвратить экранирование строки; *?Указывает нежадный режимполучать,проходитьсуществовать *、+ или ? размещен после квалификации ?,Выражение преобразуется из «жадного» выражения в «нежадное» выражение или минимальное совпадение.
исходный код
from selenium import webdriver
import time
import random
import re
import openpyxl
import json
# Создать класс рептилий
class BiddingInfo(object):
def __init__(self):
'''
Инициализация объекта
'''
self.start_url = ''
self.file = open('BiddingInfo.json', 'w',
encoding='utf-8') # Установите начальный формат, чтобы предотвратить искажение символов после сохранения.
self.counter = 0 # Счетчик перелистывания страниц
def run(self):
'''
Определить функцию ввода объекта
'''
self.get_web_gage()
while True:
return_mark = self.get_list()
if return_mark:
self.jump_into_iframe() # Поскольку вы входите на страницу сведений о проекте, вам необходимо повторно ввести рамку после того, как окно вернется обратно.
self.click_next_page()
def get_web_gage(self):
'''
Построить Браузер для мониторинга и отправки запросов
'''
self.driver = webdriver.Chrome()
self.driver.get(self.start_url)
self.driver.implicitly_wait(10) # Неявное ожидание, до 20 секунд
self.move_search_btn() # При первом открытии окна необходимо нажать кнопку поиска
self.jump_into_iframe()
def jump_into_iframe(self):
'''
Наведите драйвер страницы на переход во фреймрамку.
'''
frame = self.driver.find_element_by_id('infoframe') # Позиция по идентификатору элемент рамы
self.driver.switch_to.frame(frame) # Перейти к этому кадру
def move_search_btn(self):
'''
Наведите курсор мыши на список объявлений о тендерах
'''
search_btn = self.driver.find_elements_by_class_name(
"ewb-right-tab")[3]
# Разверните текущую страницу, чтобы переместить указатель мыши на этот элемент.
self.driver.maximize_window()
webdriver.common.action_chains.ActionChains(
self.driver).move_to_element(search_btn).perform()
time.sleep(3) # После нажатия кнопки поиска нужно дождаться обновления рамкаданных кадров.
# Прокрутите страницу до конца, чтобы избежать исключений при извлечении элементов.
self.driver.execute_script('scrollTo(0,1000)')
def get_list(self):
'''
Получите каждую часть информации на странице списка проектов одну за другой.
'''
project_list = self.driver.find_elements_by_xpath(
"//ul[contains(@class,'ewb-right-item')]//a")
# Определите массив для временного хранения всех URL-адресов этой страницы.
temp_url_list = []
# Перейти на страницу сведений о проекте
for item in project_list:
name = item.get_attribute("textContent")
if (name.find("Дизайн") > 0) and (name.find("Дорога") > 0): # Фильтр по названию проекта
temp_url_list.append(item.get_attribute('href'))
print(f"Получить {len(temp_url_list)} действительных элементов на странице {self.counter+1}.")
if len(temp_url_list) > 0: # Прыжок будет выполнен только тогда, когда список получит действительные данные.
for url in temp_url_list:
self.blank_in_detail(url)
return True # После получения действительных данных на этой странице вам необходимо перейти на страницу сведений. Если вы вернетесь назад, вам необходимо повторно войти в Iframeramka.
else:
return False
def blank_in_detail(self, url):
'''
Открыть новое подробное окно для элемента в списке проектов.
'''
# Откройте новую вкладку, выполнив js
js = "window.open('"+url+"');"
self.driver.execute_script(js)
windows = self.driver.window_handles # 1. Получить все текущие окна
self.driver.switch_to.window(windows[1]) # 2. Переключение на основе индекса окна
self.get_detail_info(url)
self.driver.close()
self.driver.switch_to.window(windows[0]) # Хотя окно можно закрыть, да все равно придется прыгать вручную
def get_detail_info(self, url):
'''
Получите информацию на странице сведений о проекте.
'''
temp_dict = {} # Интегрируйте словарь для этого проекта
temp_dict['url'] = url # URL веб-страницы проекта
temp_dict['name'] = self.driver.find_element_by_id(
'showtitle').text # Название проекта
temp_dict['legal_person'] = self.driver.find_element_by_xpath(
"//*[@id='container']//tbody/tr[2]/td[2]").get_attribute("innerHTML") # Юридическое лицо проекта
temp_dict['time'] = self.driver.find_element_by_xpath(
"//tbody/tr[5]/td[4]").get_attribute("innerHTML") # время
print(temp_dict['legal_person'], temp_dict['time'])
main_text = self.driver.find_elements_by_xpath(
"//div[contains(@class, 'ewb-info-bd')]")[3]
item_info = self.handle_string(
main_text.get_attribute('textContent')) # Получить информацию о торгах
# Улучшить информацию о проекте
temp_dict['bid_price'] = item_info[0]
temp_dict['bidder'] = item_info[1]
temp_dict['committee'] = item_info[2]
temp_dict['abandon'] = item_info[3]
print(temp_dict)
# писатьданные json_data = json.dumps(temp_dict, ensure_ascii=False)+',\n' # форматирование json
self.file.write(json_data) # Напишите jsonданные
@staticmethod
def handle_string(string):
'''
Отфильтруйте информацию о победившей ставке на странице сведений о проекте.
'''
string = re.sub(' ', '', string) # Удалить все пробелы (переносы строк не удаляются и могут использоваться как разделители)
string = re.sub(':', ':', string) # Заменить китайские символы
string = "".join(
[s for s in string.splitlines(True) if s.strip()]) # Удалить все пустые строки
# print(string)
if (string.find('метка потока') > 0) or (string.find('Информации пока нет') > 0) or (string.find('сдаваться') > 0):
# Расход по проекту или нет информации
return '', '', '', True
else:
bid_price = bidder = committee = ''
try:
# Проект имеет информацию о победивших торгах
if re.search(r'(:?)([\d+\.]+)(\)?)Юань', string): # Найти сумму выигрышной ставки
bid_price = re.search(
r'(:?)([\d+\.]+)(\)?)Юань', string).group(2)
elif re.search(r'Сумма выигрышной ставки(.*?)([\d+\.]+)(\)?)', string): # Найти сумму выигрышной ставки
bid_price = re.search(
r'Сумма выигрышной ставки(.*?)([\d+\.]+)(\)?)', string).group(2)
elif re.search('Выигрышная цена за единицу: (.+)\n', string):
bid_price = re.search('Выигрышная цена за единицу: (.+)\n', string).group(1)
elif re.search("Доля выигрышных ставок: (.+)\n", string):
bid_price = re.search('Выигрышная цена за единицу: (.+)\n', string).group(1)
else:
pass
if re.search('Имя объекта:(.+)\n', string): # Найдите победителя торгов
bidder = re.search('Имя объекта:(.+)\n', string).group(1)
if re.search('Список участников:(.+)\n', string): # Найдите победителя торгов
committee = re.search('Список участников:(.+)\n', string).group(1)
except:
print("Не удалось получить информацию о проекте!")
finally:
# Возврат к цене торгов, победитель торгов, комиссия по оценке заявок
return bid_price, bidder, committee, False
def click_next_page(self):
'''
Нажмите, чтобы перейти на следующую страницу
'''
try:
next_page_url = self.driver.find_elements_by_class_name(
"wb-page-next")[1]
except:
print("Не удалось получить следующую страницу! (или просканированы все данные.)")
else:
self.counter += 1
print(f"Сканирование страницы {self.counter} завершено, выполняется переход к следующей странице...")
next_page_url.click()
time.sleep(3) # Ожидание реконструкции страницы Iframeрамка
def __del__(self):
'''
Сохраните файл при уничтожении объекта (чтобы предотвратить аварийное завершение программы)
'''
self.file.close() # сохранить файл
self.driver.quit() # Выход Браузер
if __name__ == "__main__":
# программа Вход my_spider = BiddingInfo()
my_spider.run()----- END -----



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
