Система самообслуживания на основе улучшенной версии YOLOv10!

На фоне стремительного развития технологий глубокого обучения компьютерное зрение показало большой потенциал в сфере автоматизации розничной торговли. В этой статье предлагается новая розничная система самообслуживания на основе улучшенной сети YOLOv10, призванная повысить эффективность касс и снизить затраты на рабочую силу. Автор специально оптимизировал модель YOLOv10 и значительно повысил точность идентификации продукта за счет интеграции структуры головки обнаружения YOLOv8. Кроме того, автор также разработал алгоритм постобработки специально для сценариев самообслуживания для дальнейшей оптимизации применения системы. Результаты экспериментов показывают, что авторская система превосходит существующие методы по точности идентификации товаров и скорости оформления заказа. Это исследование не только предлагает новое техническое решение для автоматизации розничной торговли, но также дает ценную информацию об оптимизации моделей глубокого обучения для реальных приложений.
1 Introduction
Research Background
Под влиянием цифровой революции традиционные розничные магазины сталкиваются с многочисленными проблемами и возможностями трансформации. С диверсификацией потребностей потребителей и быстрым развитием покупательского поведения неэффективность традиционных процессов оформления покупок в розничных магазинах становится все более заметной, что часто приводит к ухудшению качества обслуживания клиентов. Особенно в часы пик покупателям, возможно, придется ждать оплаты в течение длительного периода времени, что отрицательно влияет на их впечатления от покупок и ограничивает возможности магазинов и потенциал роста продаж.
С быстрым развитием технологий волна искусственного интеллекта (ИИ) глубоко трансформирует многие отрасли, включая розничную торговлю [1, 2]. Двузначные и трехзначные модели зрения широко используются в различных сценариях [3, 4], а технология отслеживания и обнаружения в реальном времени может применяться как к занятым, так и к непроходимым человеческим телам [5, 6]. В сфере искусственного интеллекта машинное обучение стало мощным инструментом решения сложных задач и повышения эффективности. Глубокое обучение и компьютерное зрение, как два важных подвида машинного обучения, в последние годы привлекли внимание благодаря своей точности обработки и анализа визуальных данных даже в сложных и удаленных средах [7, 8]. Сверточные нейронные сети (CNN), как знаковая архитектура глубокого обучения, хорошо справляются с задачами компьютерного зрения и широко используются для классификации изображений, обнаружения целей и сегментации. В сфере розничной торговли CNN могут значительно повысить точность идентификации продуктов и управление запасами, а также поднять качество обслуживания клиентов и анализ рынка на новую высоту.
До появления глубокого обучения область обнаружения объектов в основном полагалась на традиционные методы ручного проектирования объектов. А достижения в области глубокого обучения принесли преимущества обнаружения объектов в сферу розничной торговли и потребительских товаров [9, 10]. Решения на этом этапе обычно представляют собой двухэтапный процесс: извлечение признаков и классификация. Помимо совершенствования алгоритмов исследования выборок данных [11, 12], методы обработки изображений и компьютерного зрения также используются для ручного построения и извлечения существенных признаков в изображениях, таких как наборы признаков Хаара и масштабно-инвариантные преобразования признаков (SIFT). ). [13]. Эти спроектированные функции затем передаются в классификатор для идентификации объектов на изображениях. Однако эффективность этого метода во многом зависит от качества проектирования объектов, которого часто не хватает в сложных и меняющихся фоновых изображениях и сценах. С развитием глубокого обучения, особенно с широким распространением CNN, обнаружение объектов сделало значительный скачок. Благодаря своим мощным возможностям автоматического обучения функциям CNN устраняют необходимость в утомительном ручном проектировании функций [14, 15]. Они могут изучать иерархическое богатство и представление функций непосредственно на основе необработанных данных изображения, что значительно повышает точность и эффективность обнаружения целей. На этом этапе появилось несколько знаковых алгоритмов обнаружения целей, таких как Faster R-CNN, You Only Look Once (YOLO) и Single Shot MultiBox Detector (SSD). Каждый алгоритм имеет свою уникальную концепцию конструкции и отличную производительность, становясь символом цели. обнаружение в эпоху глубокого обучения.
Current Study
Обеспечение точности продукта и общей цены в процессе мерчандайзинга имеет решающее значение. Традиционные торговые процессы часто основаны на ручных операциях, которые подвержены субъективным суждениям, человеческим ошибкам и высоким затратам на рабочую силу. Хотя автоматизированные контрольно-кассовые машины повышают эффективность за счет сканирования штрих-кодов продуктов, эти системы по-прежнему требуют от клиентов сканировать товары индивидуально и по-прежнему подвержены ошибкам. Для дальнейшего снижения трудозатрат и повышения точности и эффективности идентификации продукта технология обнаружения целей обеспечивает эффективное решение. Объединив технологию обнаружения объектов с автоматизированными контрольно-кассовыми машинами и создав среду, способствующую идентификации, эти новые системы могут идентифицировать и подсчитывать несколько предметов одновременно [16]. После последующей обработки эти машины могут предоставить точную общую стоимость.
В последние годы серия YOLO быстро развивалась, достигая эффективного баланса между вычислительными затратами и производительностью обнаружения. В большом количестве исследований обсуждались архитектурный проект YOLO, цели оптимизации, стратегии улучшения данных и т. д. 23 мая 2024 года в серию была запущена новая итеративная версия YOLOv10. В этом исследовании автор фокусируется на целевой оптимизации YOLOv10 для набора данных розничных продуктов (RPC). Структура данного исследования следующая: Сначала автор создал сеть MidState-YOLO, используя YOLOv8 и YOLOv10. Затем авторы модифицировали традиционную модель C2f, используя для разработки ядро двойной свертки (DualConv), которое заменяет модуль C2f перед уровнем объединения пространственной пирамиды (SPPF). Кроме того, авторы также интегрировали эффективный многомасштабный модуль внимания, чтобы повысить способность сети точно находить и идентифицировать розничные продукты. Последней разработанной моделью стала сеть MidState-YOLO-ED.
Чтобы проверить эффективность улучшенной стратегии, автор провел комплексную экспериментальную проверку и подтвердил эффективность улучшенного алгоритма, исследуя влияние различных стратегий улучшения на производительность распознавания моделей. Результаты экспериментов показывают, что предложенная стратегия улучшения может значительно повысить точность распознавания модели, сохраняя при этом параметры и вычислительную нагрузку в управляемом диапазоне.
2 Related Work
Traditional Object Detection Algorithms
В области компьютерного зрения обнаружение объектов по-прежнему остается основной технологией, которая постоянно привлекает внимание исследователей. Традиционные методы глубокого обучения в основном основаны на CNN. Среди них Faster R-CNN, YOLO и SSD — три важных достижения в этой области, каждое из которых уникальным образом способствует развитию технологий.
Более быстрый R-CNN представляет собой важное улучшение в семействе R-CNN. Он не только сохраняет преимущества серии в обнаружении целей, но и значительно повышает точность и скорость за счет ряда инноваций [17]. Внедряя сеть предложений регионов (RPN), она автоматически извлекает потенциальные целевые регионы, эффективно сокращая избыточные вычисления, вызванные традиционным методом скользящего окна. Сеть RPN эффективно использует небольшие партии выборок для обучения и сочетает в себе стратегии сопоставления якорной рамки и реальной ограничивающей рамки для быстрого создания регионов-кандидатов, полностью устраняя трудоемкий и сложный процесс выборочного поиска. Кроме того, Faster R-CNN реализует идею совместного использования функций, позволяя совместно использовать сверточные слои в задачах извлечения признаков и предложения регионов, что может значительно повысить эффективность и точность обнаружения.
YOLO — это метод обнаружения объектов на основе регрессии, который упрощает процесс обнаружения объектов. С помощью одного прямого прохода сети он напрямую прогнозирует местоположение и категорию объектов на изображении, рассматривая обнаружение как проблему регрессии. YOLO обеспечивает быстрое обнаружение путем построения изображения по сетке и прогнозирования достоверности объекта в каждой сетке.
SSD сочетает в себе эффективность Faster R-CNN и простоту YOLO, стремясь добиться эффективного и точного обнаружения целей. Он использует единый механизм многокадрового обнаружения для прямого вывода информации о положении и категории объекта за один прямой проход, что эффективно устраняет избыточность вычислений, вызванную скользящим окном, и значительно повышает скорость обнаружения. Еще одной особенностью SSD является его многомасштабная стратегия объединения функций, которая гибко обрабатывает цели различных размеров и повышает надежность и точность обнаружения. В процессе внедрения SSD заранее определил несколько групп возможных блоков с разными масштабами и соотношениями сторон, которые были тщательно настроены на этапе обучения, чтобы охватить потенциальные целевые области изображения. Совместно используя CNN для параллельного извлечения объектов и обнаружения объектов на нескольких картах объектов, SSD в полной мере использует различные уровни информации об объектах. Такая конструкция не только ускоряет обнаружение, но и повышает чувствительность модели к целям различного масштаба. Кроме того, SSD использует концепцию блоков по умолчанию с целью дальнейшей оптимизации обнаружения потенциальных целевых областей, которые явно не охвачены блоками-кандидатами. Обучая блоки по умолчанию и соответствующие им классификаторы, SSD может более полно охватить цели на изображениях, что еще больше повышает полноту и точность обнаружения.
Development of the YOLO Series
С тех пор как серия YOLO была впервые представлена Джозефом Редмоном и его сотрудниками в 2016 году, она добилась значительного прогресса в области обнаружения объектов в реальном времени, превратив задачу обнаружения объектов в задачу регрессии. Благодаря быстрому развитию технологий компьютерного зрения серия YOLO продолжает развиваться, внедряя новые технологии и методы для решения многих проблем в исходной версии и постепенно улучшая производительность обнаружения.
YOLOv1 является революционным преобразованием задачи обнаружения объектов в единую задачу регрессии. Он делит входное изображение на несколько сеток и прогнозирует ограничивающие рамки и информацию о категориях внутри каждой сетки, обеспечивая быстрое и точное обнаружение объектов. Однако YOLOv1 имеет ограничения при обнаружении небольших целей и перекрывающихся целей. В YOLOv2 внесено несколько улучшений для устранения этих недостатков. Он представляет механизм привязки для повышения точности прогнозирования ограничивающего прямоугольника и использует новую базовую сеть Darknet-53 для улучшения возможностей извлечения признаков. Кроме того, он также использует многомасштабную стратегию обучения для повышения способности модели к обобщению. Эти улучшения улучшают скорость и точность обнаружения YOLOv2.
YOLOv3 еще больше расширяет возможности серии YOLO, представляет многомасштабную стратегию объединения функций и использует дизайн сети пирамиды функций (FPN). Это усовершенствование позволяет YOLOv3 лучше захватывать контекстную информацию в изображениях, тем самым улучшая способность обнаруживать цели различных размеров.
YOLOv4 и YOLOv5 были дополнительно оптимизированы и улучшены на основе предыдущего поколения со значительными улучшениями в архитектуре модели, функциях извлечения признаков и потерь, что значительно повышает точность и скорость обнаружения целей [18, 19, 20].
YOLOv8 — это серия YOLO следующего поколения, разработанная Ultralytics после YOLOv5 на основе успешного опыта модели предыдущего поколения [21]. Он имеет более эффективную базовую конструкцию сети и головки обнаружения, включающую новые блоки свертки и функции активации для повышения точности извлечения признаков и прогнозирования ограничительной рамки. Кроме того, YOLOv8 обеспечивает более удобный метод установки и эксплуатации, упрощая пользователям развертывание и использование на различных аппаратных платформах.
Будучи новейшим членом серии YOLO, YOLOv10 добился эпохального прогресса в сквозной производительности и производительности в реальном времени. Он представляет стратегию обучения, которая не требует немаксимального подавления (NMS) и использует механизм распределения двойной метки для устранения задержки вывода, вызванной традиционным NMS.
YOLOv8 and YOLOv10 Network Structures and Their Differences
Сетевая архитектура YOLOv8 в основном состоит из трех основных частей: Backbone (Магистральная сеть), Neck (Шея) и Head (Голова). YOLOv8 использует расширенный CSPDarknet в качестве магистральной сети, которая оптимизирована на основе конструкции CSP, чтобы лучше сбалансировать вычислительную сложность и выразительность функций. В частности, CSPDarknet делит карту объектов на две части на каждом этапе: одна часть глубоко обрабатывается посредством Dense Block (плотный блок), а другая часть напрямую склеивается с выходными данными Dense Block. Такая конструкция не только снижает вычислительные затраты, но также улучшает градиентный поток и повторное использование функций, тем самым улучшая общую производительность модели. YOLOv8 также представляет расширенную функцию активации SiLU (Swish), которая заменяет традиционную Leaky ReLU. SiLU обеспечивает лучший градиентный поток, сохраняя при этом нелинейные характеристики, помогая модели быстрее сходиться и повышать точность во время обучения.
Часть сети «Шейка» использует сеть агрегации путей (PANet), которая добавляет дополнительные восходящие пути на основе сети пирамиды функций (FPN) для дальнейшего улучшения потока информации и объединения между слоями объектов. Структура PANet включает восходящий путь извлечения признаков, нисходящий путь распространения семантических признаков и дополнительный восходящий путь улучшения признаков. На каждом уровне объекты из разных путей объединяются путем поэлементного добавления или конкатенации, тем самым улучшая способность сети обнаруживать цели в разных масштабах.
В отличие от традиционной модели YOLO, YOLOv8 использует головку обнаружения точек без привязки, что упрощает архитектуру модели и снижает накладные расходы на вычисления. Метод точки без привязки напрямую прогнозирует центральную точку объекта и его атрибуты (такие как размер, направление и т. д.), избегая ограничений и сложности предопределенных полей привязки. Это изменение не только ускоряет вывод, но и улучшает способность модели обнаруживать небольшие и плотные объекты, что делает ее особенно подходящей для сценариев периферийных вычислений.
YOLOv8 также включает в себя строительный блок C2f (перекрестная частичная свертка с двумя типами слияния), который еще больше повышает точность обнаружения модели за счет расширения возможностей извлечения признаков и объединения [22]. Строительный блок C2f сочетает в себе преимущества конструкции CSP и инновации в объединении функций, что позволяет модели лучше улавливать мелкие детали и сложные узоры.
Сетевая структура YOLOv10 в целом аналогична YOLOv8, но была улучшена с точки зрения магистральной сети, структуры шеи, конструкции головы и инновационной стратегии обучения без максимального подавления (NMS). YOLOv10 применяет стратегию распределения двойной метки в процессе обучения, сочетая распределение «один ко многим» и «один к одному». Назначение «один ко многим» улучшает запоминание, а назначение «один ко многим» обеспечивает точность. Эта комбинация поддерживает согласованность между обучением и выводом, устраняя необходимость в NMS во время вывода. Удаление этапа NMS значительно сокращает время вывода и упрощает процесс вывода, что критически важно для приложений реального времени и периферийных устройств.
YOLOv10 оптимизирует различные компоненты архитектуры модели, чтобы минимизировать вычислительные затраты и одновременно повысить производительность. Чтобы повысить эффективность, YOLOv10 использует свертку с разделением по глубине, чтобы снизить вычислительные затраты на классификацию Head, и предлагает понижающую дискретизацию с развязкой по пространственным каналам для достижения более эффективной понижающей дискретизации. YOLOv10 также использует глубокие свертки с большим ядром в более глубоких компактных инвертированных блоках (CIB) для расширения восприимчивого поля и улучшения возможностей извлечения признаков, а также включает модуль частичного самообслуживания (PSA) для улучшения обучения глобальному представлению с минимальными накладными расходами, тем самым улучшая обнаружение. точность. Эти улучшения дают YOLOv10 преимущества в производительности и точности в реальном времени.
Loss Functions
В YOLOv8 головка развязки используется для разделения головок классификации и обнаружения. Ветвь классификации использует потерю двоичной перекрестной энтропии (BCE), формула которой выглядит следующим образом:
Где «w» представляет вес; «y» представляет метку, а «x» представляет прогнозируемое значение, сгенерированное моделью [21]. Для ветви регрессии она сочетает в себе использование распределенной фокусной потери (DFL) и потери CIoU. Функция DFL предназначена для подчеркивания расширения значений вероятности вокруг цели «y». Его уравнение выглядит следующим образом:
Потери CIoU вносят фактор влияния в потери DIoU, учитывая соотношение сторон между прогнозируемыми и фактическими ограничивающими рамками. Соответствующее уравнение имеет следующий вид:
где IoU измеряет перекрытие между прогнозируемой ограничивающей рамкой и истинной ограничивающей рамкой; «d» — евклидово расстояние между центром прогнозируемой ограничивающей рамки и центром истинной ограничивающей рамки, а «c» — минимальная ограничивающая рамка, которая содержит прогнозируемую ограничивающую рамку и истинную ограничивающую рамку. Длина диагонали рамки. Кроме того, «v» представляет собой параметр, который количественно определяет согласованность соотношения сторон, определяемую следующим уравнением:
Где «w» представляет ширину ограничивающей рамки; «h» представляет высоту ограничивающей рамки; «gt» указывает значение GT, а «p» представляет прогнозируемое значение [23].
3 The Improved MidState-YOLO-ED Network
Автор предлагает улучшенную сеть MidState-YOLO-ED, призванную устранить ограничения существующих алгоритмов обнаружения целей при работе с небольшими и плотными целями. Благодаря углубленному анализу исходной архитектуры MidState-YOLO-ED авторы реализовали несколько ключевых структурных улучшений для повышения точности и эффективности обнаружения.
Эти улучшения включают, помимо прочего, настройку возможности извлечения признаков промежуточного состояния сети и оптимизацию механизма прогнозирования целевой ограничивающей рамки. Кроме того, автор также представляет новую улучшенную технологию предварительной обработки данных, чтобы еще больше улучшить способность модели понимать сложные сцены.
Подробно развивая эти улучшения, в этом разделе будет показано, как метод авторов значительно повышает производительность обнаружения небольших и плотных объектов, сохраняя при этом производительность в реальном времени.
Integration of YOLOv8 and YOLOv10
Одной из наиболее примечательных особенностей YOLOv10 по сравнению с его предшественником является устранение немаксимального подавления (NMS), достигнутое за счет внедрения последовательной стратегии двойного распределения. Эта стратегия предполагает двойной вызов метода расчета функции потерь YOLOv8, сложение результатов и их возврат. Этот метод направлен на решение проблемы избыточности прогнозирования при постобработке и ближе к сквозному направлению модели RT-DETR. К сожалению, это изменение привело к снижению точности многих наборов данных в реальных приложениях. Чтобы избежать потери точности, голова прогнозирования YOLOv10 возвращается к конструкции в YOLOv8 [24].
Чтобы значительно снизить избыточность вычислений и добиться более эффективной архитектуры, YOLOv10 использует облегченную головку классификации, понижающую дискретизацию с развязкой по пространственным каналам (SCDown) и конструкцию блоков на основе сортировки (C2fUIB). SCDown сначала настраивает размеры канала посредством точечной свертки, а затем использует свертку глубины для пространственной понижающей дискретизации, чтобы уменьшить количество параметров. Однако некоторая информация будет потеряна в процессе понижающей дискретизации в эксперименте, и хотя это уменьшает задержку, это не гарантирует улучшения производительности.
Поскольку в этом исследовании модификации двух основных компонентов YOLOv10 были восстановлены до состояния YOLOv8 и обе версии были интегрированы, текущая модель получила название MidState-YOLO. Кроме того, модель умело объединяет внимание EMA и дизайн свертки C2f-Dual, и, наконец, окончательная модель получила название сети MidState-YOLO-ED.
Integration of EMA Attention
Чтобы еще больше улучшить репрезентативную способность сети MidState-YOLO и установить долгосрочные и краткосрочные зависимости, автор интегрировал эффективный механизм многомасштабного внимания (EMA) в сеть Neck. EMA — это механизм параллельного внимания, используемый в задачах компьютерного зрения с целью повышения производительности модели и скорости обработки. В отличие от традиционных сверточных нейронных сетей (CNN), EMA использует параллельную структуру для обработки входных данных. Эта параллельная свертка обеспечивает более быстрое обучение модели при работе с крупномасштабными данными и повышает точность за счет параллельной обработки функций в разных масштабах. На рисунке x группировка представлена буквой «g», «X Avg Pool» представляет собой одномерную горизонтальную глобальную группировку, а «Y Avg Pool» представляет собой одномерную вертикальную глобальную группировку. Формула операции среднего объединения выглядит следующим образом, где Xc(i,j) представляет элемент в позиции (i,j):
Входные данные для EMA сначала группируются и изменяются, перераспределяя части измерения канала в измерение пакета. Впоследствии измерение канала дополнительно подразделяется на несколько подфункций, чтобы сохранить ключевую информацию в каждом канале и оптимизировать распределение пространственных семантических признаков [25].
Эта структура содержит две основные параллельные ветви: одна ветвь выполняет одномерную глобальную операцию объединения в пул для кодирования глобальной информации, а другая ветвь выполняет извлечение признаков посредством свертки 3x3. Выходные характеристики этих двух ветвей модулируются сигмовидной функцией и процессом нормализации, а затем объединяются модулем межпространственного взаимодействия для фиксации парных отношений на уровне пикселей. Наконец, карта выходных признаков с сигмовидной модуляцией используется для усиления или ослабления исходных входных признаков, тем самым достигая более точного и эффективного представления признаков. Таким образом, EMA не только кодирует межканальную информацию для регулировки важности отдельных каналов, но также сохраняет точные детали пространственной структуры в этих каналах.
Lightweight Dual Convolution C2f-Dual Design
В YOLOv8 и YOLOv10 модуль C2f объединяет карты объектов низкого и высокого уровня, чтобы помочь зафиксировать поток информации о градиенте. Однако по мере увеличения количества слоев сверточной нейронной сети семантическая информация в картах признаков часто постепенно извлекается и агрегируется, что приводит к избыточности в картах глубоких признаков. Кроме того, из-за механизма распределения веса сверточного слоя параметры ядра свертки распределяются между зависимыми объектами в разных местах, что еще больше усугубляет избыточность карт глубоких объектов. «Узкие горлышки», состоящие из множества сложных витков, значительно увеличивают размер параметров и сложность вычислений.
Чтобы решить эту проблему, улучшенная конструкция свертки C2f-Dual с использованием DualConv значительно снижает вычислительные затраты и количество параметров, одновременно повышая точность. Это улучшение включает замену модуля C2f перед пространственным пирамидальным объединением (SPPF) на модуль C2f-Dual, как показано на рисунке 1. Эта адаптация не только упрощает структуру сети, но и оптимизирует производительность, гарантируя эффективную обработку и интеграцию ключевых пространственных и семантических характеристик.
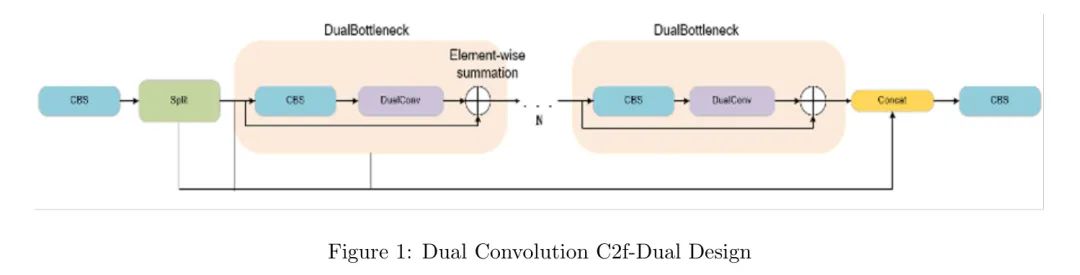
DualConv стремится создать легкую глубокую нейронную сеть и оптимизировать обработку информации и извлечение признаков путем объединения ядер свертки 3×3 и 1×1 для обработки одного и того же канала входной карты объектов. В DualConv ядро свертки 3×3 используется для извлечения пространственных признаков из карты объектов и сбора дополнительной пространственной информации, в то время как ядро свертки 1×1 интегрирует эти признаки и уменьшает параметры модели. Каждый набор ядер свертки независимо обрабатывает часть входного канала, а затем объединяет выходные данные, чтобы облегчить эффективный поток и интеграцию информации между различными каналами карты объектов.
Кроме того, DualConv также использует технологию групповой свертки для эффективной организации фильтров свертки. При групповой свертке входные и выходные карты объектов делятся на несколько групп, и сверточные фильтры каждой группы обрабатывают только часть соответствующей входной карты объектов. Такое расположение позволяет различным ядрам свертки внутри группы параллельно обрабатывать один и тот же набор входных каналов, оптимизируя поток информации и эффективность извлечения признаков, сохраняя при этом возможности представления сети.
Таким образом, замена структуры узкого места в C2f на DualBottleneck обогащает представление градиентного потока, расширяет возможности извлечения признаков и уменьшает разнообразие ложных срабатываний и ложных обнаружений при обучении сети. Это делает его более подходящим для сценариев обнаружения целевых продуктов розничной торговли.
4 Experimental Results and Analysis
В этом разделе авторы представляют результаты экспериментов и анализируют эти результаты. Целью авторов является проверка эффективности предложенного авторами метода посредством данных экспериментов и сравнение его с другими существующими методиками. Ниже приведены основные выводы и наблюдения экспериментов авторов.
Experimental Setup and Parameters

Dataset
В этом исследовании для обучения и проверки использовалась часть набора данных RPC. Набор данных RPC был разработан Нанкинским научно-исследовательским институтом Megvii Technology и в настоящее время является крупнейшим набором данных для идентификации продукта. Он содержит до 200 различных категорий продуктов и в общей сложности 83 000 изображений, реалистично имитирует среду розничной торговли и превосходит существующие наборы данных с точки зрения реализма. Более того, он эффективно отражает детальные характеристики, присущие проблеме автоматизированной кассы (ACO).
Концептуальный подход этого исследования может отличаться от подхода исследователей [26], собиравших наборы данных RPC. Когда покупатели входят в магазин и размещают товары, которые они хотят приобрести, на кассе, идеальная система ACO должна иметь возможность автоматически идентифицировать каждый продукт и точно составить список покупок за один раз, как показано на рисунке 2. Таким образом, ACO — это, по сути, система, предназначенная для идентификации и подсчета каждого товара в любой комбинации продуктов. Из-за постоянного обновления большого количества категорий продуктов, чтобы не исчерпать все возможные комбинации, набор данных RPC принимает реальное решение: собирать изображения одного типа продуктов в конкретной среде и повторно использовать их в реальных расчетах.
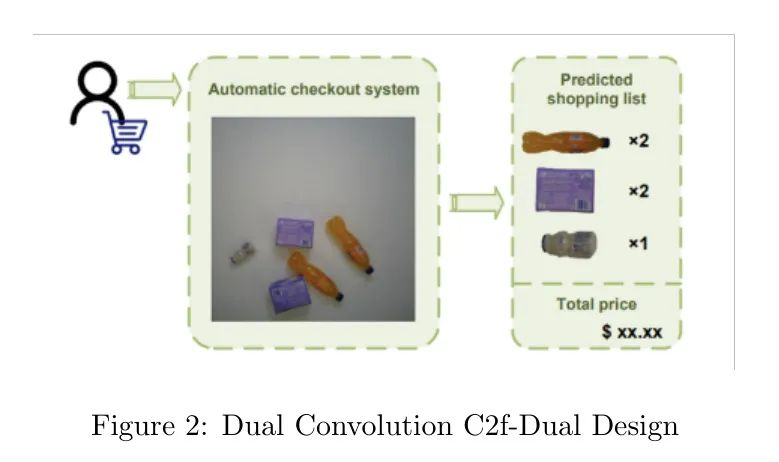
В этом исследовании предполагается, что существует несколько важных показателей оценки эффективности задачи автоматической проверки (ACO). Чтобы обеспечить точность и производительность, изображения, используемые для обучения системы распознавания ACO, должны отражать реальную среду розничных касс, что действительно может ее упростить и стабилизировать. Более того, исходная модель не требует исчерпания всех комбинаций продуктов для выполнения задачи ACO, вместо этого достаточно создать случайные комбинации продуктов;
Поэтому в этом исследовании использовались только конфигурации проверки из изображений набора данных RPC. Автор случайным образом разделил 30 000 изображений конфигурации оформления заказа на обучающий набор, набор проверки и тестовый набор с соотношением 8:1:1 соответственно. Этот подход направлен на предоставление набора данных, который был бы одновременно реалистичным и управляемым, отражающим работу реальных систем ACO, сохраняя при этом управляемую сложность и разнообразие в сценариях обучения.
Evaluation Metrics
В этой статье в качестве индикаторов оценки используются точность (P), полнота (R), средняя средняя точность (mAP), количество параметров (Params) и операций с плавающей запятой (FLOP), а также устанавливается порог IoU, равный 0,5. mAP@0,5 относится к средней средней точности, когда IoU установлен на 0,5, а mAP@0,5:0,95 представляет собой среднюю среднюю точность, когда IoU изменяется от 0,5 до 0,95 с размером шага 0,05. Операнды с плавающей запятой отражают сложность алгоритма.
Точность относится к вероятности того, что образец, предсказанный моделью как положительный, на самом деле является положительным образцом, а полнота относится к вероятности того, что образец, который на самом деле является положительным, будет предсказан моделью как положительный. Эти два показателя являются двумя важными показателями для оценки эффективности модели.
В приведенной выше формуле TP (истинный пример) относится к положительному образцу, который модель правильно распознает как положительный; FP (ложно-положительный пример) относится к отрицательному образцу, который ошибочно определен как положительный; образец, который ошибочно определен как положительный, является отрицательным положительным образцом.
mAP представляет собой среднее значение средней точности всех категорий обнаружения объектов. AP — это среднее значение точности на разных уровнях полноты. ### Сравните эксперименты и результаты
Результаты эксперимента в основном организуют параметры производительности алгоритма обучения, объясняют преимущества и недостатки каждого алгоритма на основе этих результатов, а также анализируют экспериментальные данные и фактические результаты обнаружения. Все эксперименты проводились с одинаковыми настройками конфигурации, и после обучения были протестированы файлы весов, сгенерированные каждым алгоритмом. Алгоритмы, использованные в сравнительных экспериментах, включают SSD (одиночный многокадровый детектор), Faster-RCNN (быстрое обнаружение областей с функциями CNN), YOLOv8-n и YOLOv10-n. Результаты эксперимента представлены в таблице 2.
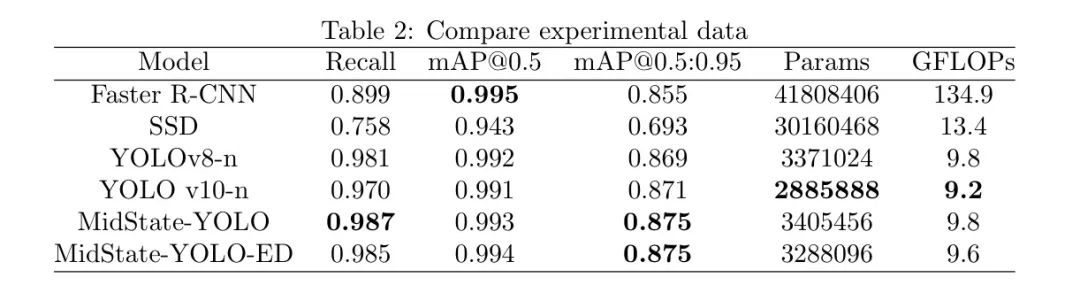
Результаты экспериментов показывают, что по сравнению с алгоритмами SSD и Faster-RCNN алгоритмы серии YOLO и усовершенствования, представленные в этом исследовании, обеспечивают лучшую производительность обнаружения. Кроме того, поскольку Faster-RCNN представляет собой двухэтапный алгоритм, его применимость ограничена его сложностью и увеличенным временем, необходимым для обнаружения, что делает его общую производительность хуже, чем у серии YOLO.
Результаты сравнения различных алгоритмов показывают, что алгоритм MidState-YOLO-ED работает превосходно с точки зрения количества параметров и операций с плавающей запятой: всего 3 288 096 параметров и 9,6 GFLOP. Это в полной мере доказывает отличную работу улучшенного алгоритма в облегченном исполнении. Этот алгоритм позволяет быстро и точно обрабатывать данные изображения и подходит для сценариев, требующих быстрого реагирования. Он также более подходит для работы в средах с ограниченными ресурсами, таких как мобильные устройства и встроенные системы, для удовлетворения требований реального времени [27].
Кроме того, ключевые показатели алгоритма MidState-YOLO-ED, такие как скорость отзыва и mAP, выше, чем у базового алгоритма, что обеспечивает новый выбор для эффективного и быстрого обнаружения целей.
Ablation Study
Чтобы изучить эффекты трех схем улучшения, автор провел исследование абляции, используя YOLOv8-n и YOLOv10-n в качестве базовых сетей без изменения программной и аппаратной среды. Эти эксперименты проводились на экспериментальном наборе данных, и единственным измененным параметром было сокращение эпох обучения до 25 эпох. Как показано в таблице 3, сеть MidState-YOLO, объединяющая модули YOLOv8 и YOLOv10, улучшила mAP на 23,2 процентных пункта по сравнению с исходной базовой сетью YOLOv10-n. Это показывает, что объединение двух моделей позволяет в полной мере использовать их соответствующие преимущества, избегая при этом некоторых недостатков, тем самым улучшая производительность модели. Использование облегченного модуля двойной свертки C2f_Dual в сети MidState-YOLO значительно сокращает количество параметров и улучшает все показатели производительности. Причина в том, чтобы уменьшить количество избыточной информации в картах глубоких признаков и уменьшить количество ложноположительных и ложноотрицательных результатов во время обучения сети. Включение модуля EMA увеличивает mAP@0,5 до 84,4%, увеличение на 4,2%. Это показывает, что модуль EMA эффективно собирает глобальную информацию, изучает более широкие семантические функции и позволяет сетевой модели уделять больше внимания общему контексту целевого розничного продукта, тем самым повышая производительность модели.
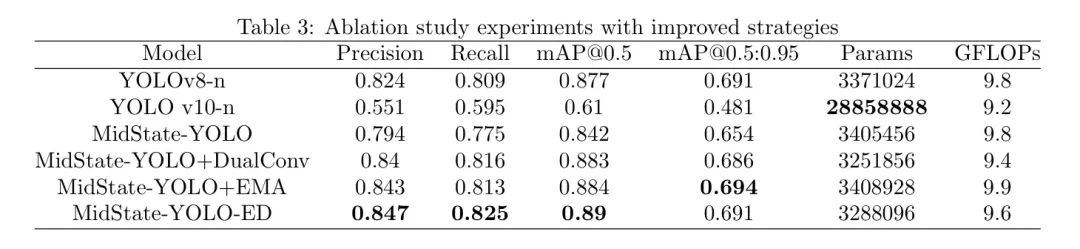
Итоговая улучшенная модель MidState-YOLO-ED улучшилась по сравнению с YOLOv8-n по всем показателям оценки. Точность и полнота увеличились на 2,3 и 1,6 процентных пункта соответственно, а mAP достиг 89%. Кроме того, значительно сокращается количество параметров и операций с плавающей запятой.
Visualization of Results
После обучения окончательной улучшенной модели MidState-YOLO-ED в течение 30 циклов результаты прогнозирования показаны на рисунке 3. Результаты показывают, что алгоритм, предложенный в этой статье, обеспечивает отличную производительность обнаружения, сохраняя при этом легкую структуру.

5 Conclusion
В этой статье авторы демонстрируют усовершенствованную систему самообслуживания с использованием улучшенной сети YOLOv10. Система вносит значительный вклад в развитие автоматизации розничной торговли за счет повышения эффективности касс и снижения затрат на рабочую силу.
Авторская настройка модели YOLOv10 сочетает в себе возможности YOLOv8 и новый алгоритм постобработки, что существенно повышает точность идентификации продукта. Результаты экспериментов показывают, что система имеет очевидные преимущества перед производительностью существующих систем.
Это исследование будет иметь положительные последствия для более широкого применения в таких областях, как контроль запасов и обслуживание клиентов. Исследование автора показывает, что технология искусственного интеллекта будет играть жизненно важную роль в улучшении потребительского опыта и операционной эффективности.
ссылка
[1].Enhanced Self-Checkout System for Retail Based on Improved YOLOv10.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
