Система распознавания голосовых отпечатков на базе Pytorch
Предисловие
В этом проекте используются EcapaTdnn, ResNetSE, ERes2Net, CAM++ и другие расширенные возможности Распознавания. голосового отпечатка Модель, не исключено, что в будущем будет поддерживаться больше Модель. В то же время этот проект также поддерживает MelSpectrogram, Spectrogram, MFCC, Fbank и другие данные Метод. предварительной обработки,Использованная потеря ArcFace,ArcFace loss:Additive Angular Margin Loss (аддитивная функция потерь углового интервала), соответствующая AAMLoss в проекте, нормализует вектор признаков и вес, добавляет угловой интервал m к θ, угловой интервал оказывает более прямое влияние на угол, чем косинусный интервал, кроме того , также поддерживает несколько функций потерь, таких как AMLoss, ARMLoss, CELoss и т. д.
Адрес исходного кода:VoiceprintRecognition-Pytorch
Среда использования:
- Anaconda 3
- Python 3.8
- Pytorch 1.13.1
- Windows 10 or Ubuntu 18.04
Характеристики проекта
- поддерживать Модель:EcapaTdnn、TDNN、Res2Net、ResNetSE、ERes2Net、CAM++
- Доступные варианты: AttentiveStatsPool (ASP), SelfAttentivePooling (SAP), TemporalStatisticsPooling (TSP), TemporalAveragePooling (TAP), TemporalStatsPool (TSTP).
- Поддерживаемые функции потерь: AAMLoss, AMLoss, ARMLoss, CELoss.
- поддерживать Метод предварительной обработки:MelSpectrogram、Spectrogram、MFCC、Fbank
Модельная бумага:
- EcapaTdnn:ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
- PANNS:PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition
- TDNN:Prediction of speech intelligibility with DNN-based performance measures
- Res2Net:Res2Net: A New Multi-scale Backbone Architecture
- ResNetSE:Squeeze-and-Excitation Networks
- CAMPPlus:CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking
- ERes2Net:An Enhanced Res2Net with Local and Global Feature Fusion for Speaker Verification
Загрузка модели
Модель | Params(M) | Метод предварительной обработки | Набор данных | train speakers | threshold | EER | MinDCF |
|---|---|---|---|---|---|---|---|
CAM++ | 7.5 | Fbank | CN-Celeb | 2796 | 0.26 | 0.09557 | 0.53516 |
ERes2Net | 8.2 | Fbank | CN-Celeb | 2796 | |||
ResNetSE | 9.4 | Fbank | CN-Celeb | 2796 | 0.20 | 0.10149 | 0.55185 |
EcapaTdnn | 6.7 | Fbank | CN-Celeb | 2796 | 0.24 | 0.10163 | 0.56543 |
TDNN | 3.2 | Fbank | CN-Celeb | 2796 | 0.23 | 0.12182 | 0.62141 |
Res2Net | 6.6 | Fbank | CN-Celeb | 2796 | 0.22 | 0.14390 | 0.67961 |
ERes2Net | 8.2 | Fbank | другой Набор данных | 20W | 0.36 | 0.02936 | 0.18355 |
CAM++ | 7.5 | Fbank | другой Набор данных | 20W | 0.29 | 0.04765 | 0.31436 |
проиллюстрировать:
- Оцениваемый тестовый наборТестовый набор CN-Celeb,Содержит 196 динамиков.
Среда установки
- Первое, что нужно установить, — это версия Pytorch для графического процессора. Если вы уже установили ее, пропустите ее.
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia- Установите библиотеку ppvector.
Используйте pip для установки, команда выглядит следующим образом:
python -m pip install mvector -U -i https://pypi.tuna.tsinghua.edu.cn/simpleРекомендуемая установка исходного кода,Установка исходного кода гарантирует использование последней версии кода.
git clone https://github.com/yeyupiaoling/VoiceprintRecognition-Pytorch.git
cd VoiceprintRecognition-Pytorch/
python setup.py installСоздать данные
В этом уроке автор используетCN-Celeb,этот Набор В данных около 3000 голосданных, а голосовых 65W+. После скачивания нужно разархивировать Набор. данныхприезжатьdatasetОглавление,Кроме того, если вы хотите оценить,Еще нужно скачатьТестовый набор CN-Celeb。如果读者有другой更好из Набор данных,Можно смешивать и использовать,Но для обработки звука лучше всего использовать модуль инструмента Python aukit.,Снижение шумаи Включить звук。
Первое, что нужно сделать, это создать список данных.,данные Формат списка:<голоспуть к файлу\tголос Классификационные теги>,Этот список в основном создан для облегчения последующего чтения.,也是方便读取использоватьдругойизголос Набор данные, тег классификации голоса относится к уникальному идентификатору говорящего, разные голоса Набор данных, вы можете преобразовать эти Наборы, написав соответствующую функцию, которая генерирует список данных все данные записываются в один и тот же список данных.
осуществлятьcreate_data.pyПрограмма завершенаданные Подготовить。
python create_data.pyПосле выполнения вышеуказанной программы,Будет сгенерирован следующий формат данных,Если вы хотите настроить данные,См. следующий список данных.,Спереди — относительный путь аудио,Далее следует метка динамика, соответствующего звуку.,Так же, как классификация。Примечания по настройке Набора данных,Идентификатор списка тестов не обязательно должен совпадать с идентификатором обучения.,Другими словами, носитель данных в тесте не обязательно должен присутствовать в обучающем наборе.,Просто убедитесь, что вы проверили тот же идентификатор одного и того же человека в списке данных.
dataset/CN-Celeb2_flac/data/id11999/recitation-03-019.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-023.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-025.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-014.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-030.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-032.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-06-028.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-031.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-003.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-04-017.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-10-016.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-09-001.flac 2795
dataset/CN-Celeb2_flac/data/id11999/recitation-05-010.flac 2795Изменить метод предварительной обработки
В файле конфигурации по умолчанию используется FbankMetod. предварительной обработки, если вы хотите использовать другой метод предварительной обработки,Вы можете изменить установку в файле конфигурации следующим образом:,Конкретное значение может быть изменено в соответствии с вашей ситуацией. Если вы не знаете, как установить параметры,Вы можете удалить эту часть напрямую,Просто используйте значение по умолчанию.
# параметры предварительной обработки данных
preprocess_conf:
# Аудио метод предварительной обработки,поддерживать:MelSpectrogram、Spectrogram、MFCC、Fbank feature_method: 'Fbank'
# Установите параметры API, измените параметры и просмотрите соответствующий API. Если вы не уверены, вы можете напрямую удалить эту часть и напрямую использовать значение по умолчанию.
method_args:
sample_frequency: 16000
num_mel_bins: 80Модель обучения
использоватьtrain.pyМодель обучения,Этот проект поддерживает несколько методов предварительной обработки звука.,проходитьconfigs/ecapa_tdnn.ymlПараметры файла конфигурацииpreprocess_conf.feature_methodМожно указать,MelSpectrogramэто мел-спектр,Spectrogramдля спектрограммы,MFCCкепстральные коэффициенты мел-спектра и т. д.。проходить参数augment_conf_pathМожно указатьданные Метод улучшения。Во время тренировки,Будет использовать VisualDL для сохранения журналов тренировок.,Результаты обучения можно просмотреть в любой момент, запустив VisualDL.,Команда запускаvisualdl --logdir=log --host 0.0.0.0
# Обучение одной карте
CUDA_VISIBLE_DEVICES=0 python train.py
# Обучение Дока
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyЖурнал результатов обучения:
[2023-08-05 09:52:06.497988 INFO ] utils:print_arguments:13 - ----------- Дополнительные параметры конфигурации -----------
[2023-08-05 09:52:06.498094 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-08-05 09:52:06.498149 INFO ] utils:print_arguments:15 - do_eval: True
[2023-08-05 09:52:06.498191 INFO ] utils:print_arguments:15 - local_rank: 0
[2023-08-05 09:52:06.498230 INFO ] utils:print_arguments:15 - pretrained_model: None
[2023-08-05 09:52:06.498269 INFO ] utils:print_arguments:15 - resume_model: None
[2023-08-05 09:52:06.498306 INFO ] utils:print_arguments:15 - save_model_path: models/
[2023-08-05 09:52:06.498342 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-08-05 09:52:06.498378 INFO ] utils:print_arguments:16 - ------------------------------------------------
[2023-08-05 09:52:06.513761 INFO ] utils:print_arguments:18 - ----------- Параметры файла конфигурации -----------
[2023-08-05 09:52:06.513906 INFO ] utils:print_arguments:21 - dataset_conf:
[2023-08-05 09:52:06.513957 INFO ] utils:print_arguments:24 - dataLoader:
[2023-08-05 09:52:06.513995 INFO ] utils:print_arguments:26 - batch_size: 64
[2023-08-05 09:52:06.514031 INFO ] utils:print_arguments:26 - num_workers: 4
[2023-08-05 09:52:06.514066 INFO ] utils:print_arguments:28 - do_vad: False
[2023-08-05 09:52:06.514101 INFO ] utils:print_arguments:28 - enroll_list: dataset/enroll_list.txt
[2023-08-05 09:52:06.514135 INFO ] utils:print_arguments:24 - eval_conf:
[2023-08-05 09:52:06.514169 INFO ] utils:print_arguments:26 - batch_size: 1
[2023-08-05 09:52:06.514203 INFO ] utils:print_arguments:26 - max_duration: 20
[2023-08-05 09:52:06.514237 INFO ] utils:print_arguments:28 - max_duration: 3
[2023-08-05 09:52:06.514274 INFO ] utils:print_arguments:28 - min_duration: 0.5
[2023-08-05 09:52:06.514308 INFO ] utils:print_arguments:28 - noise_aug_prob: 0.2
[2023-08-05 09:52:06.514342 INFO ] utils:print_arguments:28 - noise_dir: dataset/noise
[2023-08-05 09:52:06.514374 INFO ] utils:print_arguments:28 - num_speakers: 3242
[2023-08-05 09:52:06.514408 INFO ] utils:print_arguments:28 - sample_rate: 16000
[2023-08-05 09:52:06.514441 INFO ] utils:print_arguments:28 - speed_perturb: True
[2023-08-05 09:52:06.514475 INFO ] utils:print_arguments:28 - target_dB: -20
[2023-08-05 09:52:06.514508 INFO ] utils:print_arguments:28 - train_list: dataset/train_list.txt
[2023-08-05 09:52:06.514542 INFO ] utils:print_arguments:28 - trials_list: dataset/trials_list.txt
[2023-08-05 09:52:06.514575 INFO ] utils:print_arguments:28 - use_dB_normalization: True
[2023-08-05 09:52:06.514609 INFO ] utils:print_arguments:21 - loss_conf:
[2023-08-05 09:52:06.514643 INFO ] utils:print_arguments:24 - args:
[2023-08-05 09:52:06.514678 INFO ] utils:print_arguments:26 - easy_margin: False
[2023-08-05 09:52:06.514713 INFO ] utils:print_arguments:26 - margin: 0.2
[2023-08-05 09:52:06.514746 INFO ] utils:print_arguments:26 - scale: 32
[2023-08-05 09:52:06.514779 INFO ] utils:print_arguments:24 - margin_scheduler_args:
[2023-08-05 09:52:06.514814 INFO ] utils:print_arguments:26 - final_margin: 0.3
[2023-08-05 09:52:06.514848 INFO ] utils:print_arguments:28 - use_loss: AAMLoss
[2023-08-05 09:52:06.514882 INFO ] utils:print_arguments:28 - use_margin_scheduler: True
[2023-08-05 09:52:06.514915 INFO ] utils:print_arguments:21 - model_conf:
[2023-08-05 09:52:06.514950 INFO ] utils:print_arguments:24 - backbone:
[2023-08-05 09:52:06.514984 INFO ] utils:print_arguments:26 - embd_dim: 192
[2023-08-05 09:52:06.515017 INFO ] utils:print_arguments:26 - pooling_type: ASP
[2023-08-05 09:52:06.515050 INFO ] utils:print_arguments:24 - classifier:
[2023-08-05 09:52:06.515084 INFO ] utils:print_arguments:26 - num_blocks: 0
[2023-08-05 09:52:06.515118 INFO ] utils:print_arguments:21 - optimizer_conf:
[2023-08-05 09:52:06.515154 INFO ] utils:print_arguments:28 - learning_rate: 0.001
[2023-08-05 09:52:06.515188 INFO ] utils:print_arguments:28 - optimizer: Adam
[2023-08-05 09:52:06.515221 INFO ] utils:print_arguments:28 - scheduler: CosineAnnealingLR
[2023-08-05 09:52:06.515254 INFO ] utils:print_arguments:28 - scheduler_args: None
[2023-08-05 09:52:06.515289 INFO ] utils:print_arguments:28 - weight_decay: 1e-06
[2023-08-05 09:52:06.515323 INFO ] utils:print_arguments:21 - preprocess_conf:
[2023-08-05 09:52:06.515357 INFO ] utils:print_arguments:28 - feature_method: MelSpectrogram
[2023-08-05 09:52:06.515390 INFO ] utils:print_arguments:24 - method_args:
[2023-08-05 09:52:06.515426 INFO ] utils:print_arguments:26 - f_max: 14000.0
[2023-08-05 09:52:06.515460 INFO ] utils:print_arguments:26 - f_min: 50.0
[2023-08-05 09:52:06.515493 INFO ] utils:print_arguments:26 - hop_length: 320
[2023-08-05 09:52:06.515527 INFO ] utils:print_arguments:26 - n_fft: 1024
[2023-08-05 09:52:06.515560 INFO ] utils:print_arguments:26 - n_mels: 64
[2023-08-05 09:52:06.515593 INFO ] utils:print_arguments:26 - sample_rate: 16000
[2023-08-05 09:52:06.515626 INFO ] utils:print_arguments:26 - win_length: 1024
[2023-08-05 09:52:06.515660 INFO ] utils:print_arguments:21 - train_conf:
[2023-08-05 09:52:06.515694 INFO ] utils:print_arguments:28 - log_interval: 100
[2023-08-05 09:52:06.515728 INFO ] utils:print_arguments:28 - max_epoch: 30
[2023-08-05 09:52:06.515761 INFO ] utils:print_arguments:30 - use_model: EcapaTdnn
[2023-08-05 09:52:06.515794 INFO ] utils:print_arguments:31 - ------------------------------------------------
······
===============================================================================================
Layer (type:depth-idx) Output Shape Param #
===============================================================================================
Sequential [1, 9726] --
├─EcapaTdnn: 1-1 [1, 192] --
│ └─Conv1dReluBn: 2-1 [1, 512, 98] --
│ │ └─Conv1d: 3-1 [1, 512, 98] 163,840
│ │ └─BatchNorm1d: 3-2 [1, 512, 98] 1,024
│ └─Sequential: 2-2 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-3 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-4 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-5 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-6 [1, 512, 98] 262,912
│ └─Sequential: 2-3 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-7 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-8 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-9 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-10 [1, 512, 98] 262,912
│ └─Sequential: 2-4 [1, 512, 98] --
│ │ └─Conv1dReluBn: 3-11 [1, 512, 98] 263,168
│ │ └─Res2Conv1dReluBn: 3-12 [1, 512, 98] 86,912
│ │ └─Conv1dReluBn: 3-13 [1, 512, 98] 263,168
│ │ └─SE_Connect: 3-14 [1, 512, 98] 262,912
│ └─Conv1d: 2-5 [1, 1536, 98] 2,360,832
│ └─AttentiveStatsPool: 2-6 [1, 3072] --
│ │ └─Conv1d: 3-15 [1, 128, 98] 196,736
│ │ └─Conv1d: 3-16 [1, 1536, 98] 198,144
│ └─BatchNorm1d: 2-7 [1, 3072] 6,144
│ └─Linear: 2-8 [1, 192] 590,016
│ └─BatchNorm1d: 2-9 [1, 192] 384
├─SpeakerIdentification: 1-2 [1, 9726] 1,867,392
===============================================================================================
Total params: 8,012,992
Trainable params: 8,012,992
Необучаемые параметры: 0
Всего мультиаддов (M): 468,81
=============================================== ============================================
Размер ввода (МБ): 0,03
Размер прямого/обратного прохода (МБ): 10,36
Размер параметров (МБ): 32,05
Предполагаемый общий размер (МБ): 42,44
=============================================== ============================================
[2023-08-05 09:52:08.084231 ИНФОРМАЦИЯ ] тренер:поезд:388 - тренироватьсяданные:874175
[2023-08-05 09:52:09.186542 ИНФОРМАЦИЯ] тренер:__train_epoch:334 - Эпоха поезда: [1/30], batch: [0/13659], loss: 11.95824, accuracy: 0.00000, learning rate: 0.00100000, speed: 58.09 data/sec, eta: 5 days, 5:24:08
[2023-08-05 09:52:22.477905 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [100/13659], loss: 10.35675, accuracy: 0.00278, learning rate: 0.00100000, speed: 481.65 data/sec, eta: 15:07:15
[2023-08-05 09:52:35.948581 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [200/13659], loss: 10.22089, accuracy: 0.00505, learning rate: 0.00100000, speed: 475.27 data/sec, eta: 15:19:12
[2023-08-05 09:52:49.249098 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [300/13659], loss: 10.00268, accuracy: 0.00706, learning rate: 0.00100000, speed: 481.45 data/sec, eta: 15:07:11
[2023-08-05 09:53:03.716015 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [400/13659], loss: 9.76052, accuracy: 0.00830, learning rate: 0.00100000, speed: 442.74 data/sec, eta: 16:26:16
[2023-08-05 09:53:18.258807 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [500/13659], loss: 9.50189, accuracy: 0.01060, learning rate: 0.00100000, speed: 440.46 data/sec, eta: 16:31:08
[2023-08-05 09:53:31.618354 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [600/13659], loss: 9.26083, accuracy: 0.01256, learning rate: 0.00100000, speed: 479.50 data/sec, eta: 15:10:12
[2023-08-05 09:53:45.439642 INFO ] trainer:__train_epoch:334 - Train epoch: [1/30], batch: [700/13659], loss: 9.03548, accuracy: 0.01449, learning rate: 0.00099999, speed: 463.63 data/sec, eta: 15:41:08Страница VisualDL:
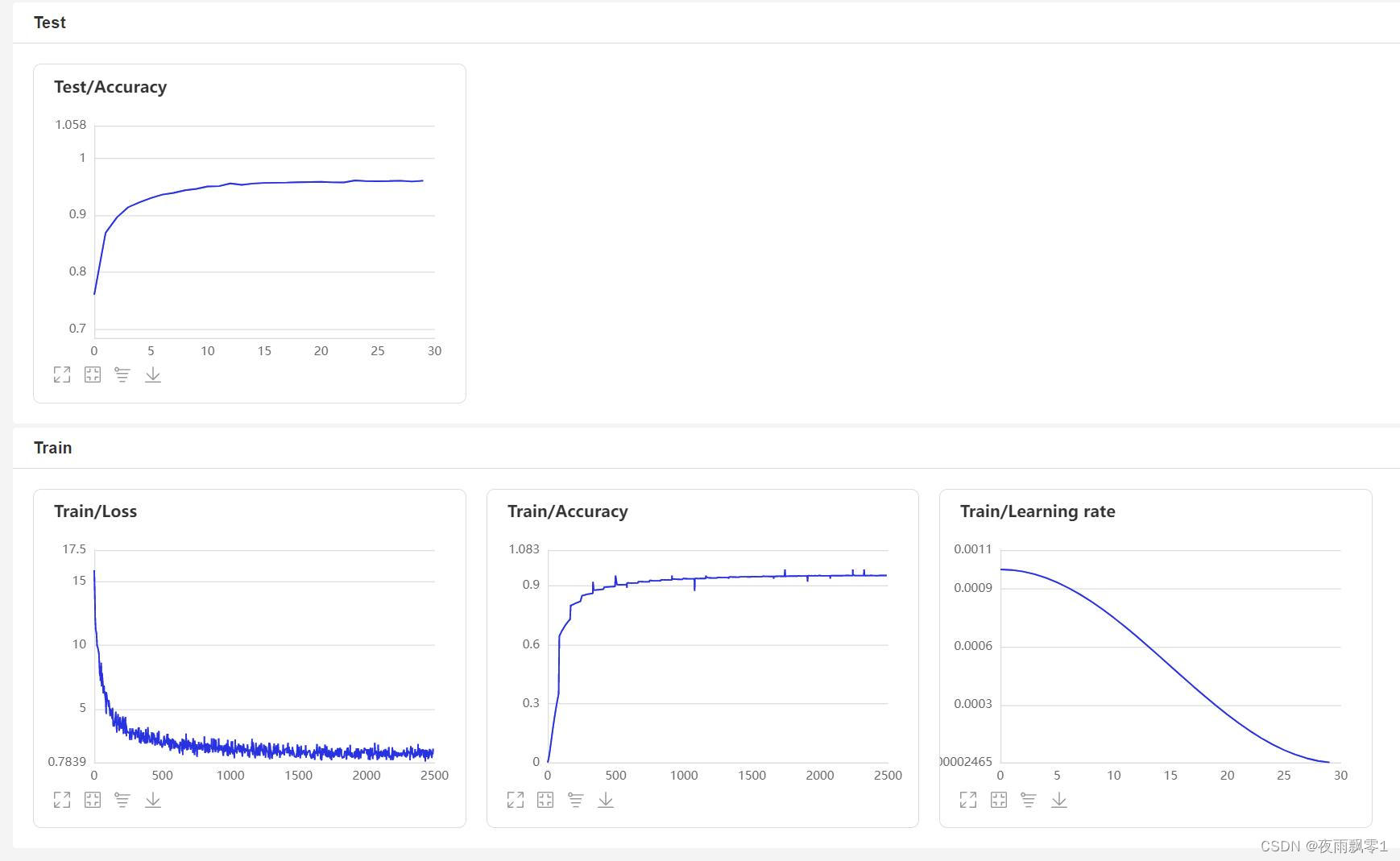
Модель оценки
После обучения Модель прогноза будет сохранена.,Мы используем модель прогнозирования для прогнозирования характеристик звука в тестовом наборе.,Затем используйте аудиофункции для выполнения попарных сравнений.,вычислитьEERиMinDCF。
python eval.pyВывод аналогичен следующему:
······
------------------------------------------------
W0425 08:27:32.057426 17654 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:27:32.065165 17654 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2023-03-16 20:20:47.195908 INFO ] trainer:evaluate:341 - Модель успешно загружена: models/EcapaTdnn_Fbank/best_model/model.pth
100%|███████████████████████████| 84/84 [00:28<00:00, 2.95it/s]
Начните сравнивать аудиофункции попарно...
100%|███████████████████████████| 5332/5332 [00:05<00:00, 1027.83it/s]
Время оценки: 65 с, порог: 0,26, EER: 0.14739, MinDCF: 0.41999Сравнение голосового отпечатка
Приступим к реализации Сравнения голосового отпечатка,создаватьinfer_contrast.pyпрограмма,писатьinfer()функция,Пока пишу Модель,Модель имеет два выхода,Первый — это результат классификации Модели.,Второй — выход аудио. Итак, здесь выводится характеристическое значение звука.,Используя собственные значения аудио, можно выполнить Распознание голосовой отпечатки. Вводим два голоса,Получите их характеристики через функцию прогнозирования.,Используя эту функцию, данные могут найти свои диагональные косинусы.,得приезжатьиз结果可以作为他们相识度。对于этот相识度из阈值threshold,Читатели могут изменить его в соответствии с требованиями точности своих собственных проектов.
python infer_contrast.py --audio_path1=audio/a_1.wav --audio_path2=audio/b_2.wavВывод аналогичен следующему:
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:13 - ----------- Дополнительные параметры конфигурации -----------
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path1: dataset/a_1.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - audio_path2: dataset/b_2.wav
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:30:48.009149 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:29:10.006249 21121 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:29:10.008555 21121 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Параметры модели и параметры метода оптимизации успешно загружены: models/EcapaTdnn_Fbank/best_model/model.pth
audio/a_1.wav и audio/b_2.wav Не тот же человек, сходство: -0,09565544128417969Распознавание голосового отпечатка
Сравнение сверху голосового На основе отпечатки,我们создаватьinfer_recognition.pyвыполнить Распознавание голосового отпечатка. Также используйте приведенное выше сравнение голосового отпечаткаизinfer()预测функция,проходить这两个同样获取голос Характеристикиданные。 不同из是笔者增加了load_audio_db()иregister(),а такжеrecognition(),Первая функция — загрузка озвученных из библиотеки voiceprint.,Эти аудио эквивалентны зарегистрированным пользователям.,Их зарегистрированные голоса будут храниться здесь.,Если пользователю необходимо войти в систему через voiceprint,就需要拿приезжать用户изголосиголос库中изголосруководить Сравнение голосового отпечатка,Если сравнение прошло успешно,那就相当于登录成功并且获取用户注册时из信息данные。第二个функцияregister()Фактически запись сохраняется в библиотеке voiceprint.,同时获取该音频Характеристики添加приезжать待对比изданные Рекомендуемые。наконецrecognition()функция中,этотфункция就是将输入изголосиголос库中изголос Сравните один за другим。
При вышеуказанном Распознавании голосового функция отпечатки, читатели могут завершить Распознание в соответствии с потребностями своих проектов. голосового Способ отпечатки, например, который предлагает автор ниже, заключается в полном Распознавании через запись. голосового отпечатка。Сначала вам необходимо загрузитьголос库中изголос,голос Папка библиотеки находитсяaudio_db,Затем пользователь нажимает Enter и записывает 3 секунды.,Затем программа автоматически запишет,И используйте записанный звук для выполнения распознавания голосов отпечатка., чтобы сопоставить голос в библиотеке голосов для получения информации о пользователе. Таким образом, читатели также могут изменить его для завершения Распознавания посредством запросов на обслуживание. голосового отпечатка, например, предоставить API для вызова приложения. Когда пользователь входит в систему через голосовую отпечатку в приложении, записанный голос отправляется на серверную часть для завершения Распознавания. голосового отпечатка,Затем верните результаты в приложение.,Предполагается, что пользователь зарегистрировался с помощью голоса.,и успешно поставилголосданныехранится вaudio_dbв папке。
python infer_recognition.pyВывод аналогичен следующему:
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:13 - ----------- Дополнительные параметры конфигурации -----------
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - audio_db_path: audio_db/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - configs: configs/ecapa_tdnn.yml
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - model_path: models/EcapaTdnn_Fbank/best_model/
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - record_seconds: 3
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - threshold: 0.6
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:15 - use_gpu: True
[2023-04-02 18:31:20.521040 INFO ] utils:print_arguments:16 - ------------------------------------------------
······································································
W0425 08:30:13.257884 23889 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.6, Runtime API Version: 10.2
W0425 08:30:13.260191 23889 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Успешно загружены параметры модели и параметры метода оптимизации: models/ecapa_tdnn/model.pth.
Loaded Ша Жуйджин audio.
Loaded Ли Дакан audio.
Пожалуйста, выберите функцию: 0 — зарегистрировать звук в библиотеке голосовой печати, 1 — выполнить Распознание. голосового отпечатка:0
Нажмите клавишу Enter, чтобы начать запись, запись в течение 3 секунд:
Начать запись...
Запись закончилась!
Пожалуйста, введите имя пользователя аудио: Дождь идет ночью
Пожалуйста, выберите функцию: 0 — зарегистрировать звук в библиотеке голосовой печати, 1 — выполнить Распознание. голосового отпечатка:1
Нажмите клавишу Enter, чтобы начать запись, запись в течение 3 секунд:
Начать запись...
Запись закончилась!
Узнайте в говорящем: Дождь идет ночью, сходство: 0.920434Другие версии
- Tensorflow:VoiceprintRecognition-Tensorflow
- PaddlePaddle:VoiceprintRecognition-PaddlePaddle
- Keras:VoiceprintRecognition-Keras
Ссылки



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
