[Система искусственного интеллекта] Тензорный параллелизм
При обучении больших моделей одно устройство часто не может удовлетворить требования к вычислительным ресурсам и хранению данных, поэтому необходима технология распределенного обучения. Среди них модель параллельная (Модель Parallelism, МП) является важным методом. Основная идея модели параллельнойиз состоит в том, чтобы разделить модель вычислить задачи на приезжать и выполнить их на разных устройствах. , для повышения эффективности обучения и работы с более масштабными моделями. Следующее внимание будет сосредоточено на модели параллельной и зтензорной. параллелизм。
Наивный тензорный параллелизм
тензорный параллелизм широко используется в технологии распределенного обучения. В предыдущем разделе объяснялось, как использовать данные параллельной реализации для обучения нейронной сети на нескольких отдельных устройствах; этот метод, как правило, один и тот же из модели Копировать. в Все устройства,Каждое отдельное устройство потребляет различную часть входных данных. Хотя это может существенно ускорить тренировочный процесс.,Но существуют в некоторых случаях модель слишком велика, чтобы уместиться в одном устройстве.,Этот подход не работает.
В этой статье показано, какпроходитьиспользоватьНаивный тензорный параллелизмрешить этоиндивидуальныйвопрос。иданныепараллельный Напротив,тензорный параллелизм расколет единую индивидуальную модель, которая будет жить на разных устройствах вместо того, чтобы существовать каждая в дивидуальное устройство копировать индивидуальную полную модель (в частности, при условии индивидуальной модели) m Включать 6 Слои: при использовании параллелизма данных каждое устройство будет иметь этот уровень. 6 Слой из копии при использовании тензорного режима параллелизм существует два отдельных устройства, каждое индивидуальное устройство имеет только 3 слой).
Приходите и посмотритеиндивидуальный Простойизтензорный параллелизмизпример:
from torchvision.models.resnet import ResNet, Bottleneck
num_classes = 1000
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1, self.bn1, self.relu,
self.maxpool, self.layer1,self.layer2
).to('npu:0')
self.seq2 = nn.Sequential(
self.layer3, self.layer4, self.avgpool,
).to('npu:1')
self.fc.to('npu:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('npu:1'))
return self.fc(x.view(x.size(0), -1))Код выше показывает, как torchvision.models.resnet50() Разбейте его на два устройства, поместите каждый блок на отдельное устройство и переместите входы и промежуточные выходы в соответствии с устройством слоя. Идея состоит в том, чтобы наследовать существующий ResNet модуль и назначьте слои обоим устройствам во время построения. Затем перепишите forward метод соединяет две подсети путем перемещения промежуточных выходов.
Наивный тензорный параллелизмвыполнить решает проблему, заключающуюся в том, что модель слишком велика, чтобы поместиться в одно индивидуальное устройство. Однако вы могли заметить, что приезжать, если модель способна поместиться в одно индивидуальное устройство, Наивный тензорный параллелизм будет работать медленнее, чем существование на одном индивидуальном устройстве. Это связано с тем, что в любой момент времени работает только одно индивидуальное устройство, а другое индивидуальное устройство простаивает. Когда необходимо получить промежуточный результат npu:0 Копировать в npu:1 , производительность еще больше ухудшится.
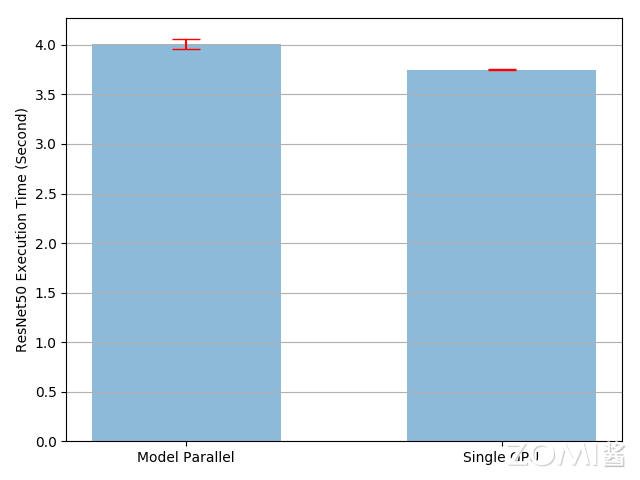
на самом деле Наивный тензорный параллелизмвыполнитьвремя выполнения медленнее, чем существующее из одного устройства. 7%。поэтому,можно сделать вывод,Тензор межплатформенных копирований из накладных расходов составляет прибл. 7%. Есть еще возможности для улучшения, учитывая, что одно устройство простаивает во время выполнения. Один из вариантов — дальнейшее разделение каждого пакета на конвейерные сегменты, чтобы, когда один сегмент прибудет во вторую подсеть, следующий сегмент мог перейти в первую подсеть. Таким образом, два последовательных сегмента могут работать параллельно на обоих устройствах.
простой Наивный тензорный параллелизмизпреимуществосуществовать Ввыполнить相对Простой,Никаких сложных механизмов связи и синхронизации не требуется. Однако,этот методиз Недостатки также очевидны:Если вычислительная нагрузка каждой части модели несбалансирована, это может привести к низкой загрузке некоторого оборудования, что повлияет на общую эффективность обучения.также,Верно. В зависимости от сильной структуры модели простой из Наивный тензорный параллелизм также может быть трудным для выбора.
тензорный параллелизм
тензорный параллелизм(Tensor Параллелизм (TP) — это более детальный метод распараллеливания моделей, который разделяет параметры и задачи вычислений в пределах одного уровня на разные устройства для выполнения. Этот метод особенно подходит для крупномасштабных моделей с большим количеством параметров. изначально это было в Megatron-LM предложенная в статье, это эффективная технология распараллеливания моделей, которую можно использовать для обучения крупномасштабных Transformer Модель.
проходитьтензорный Благодаря параллелизму, вы можете разделить матрицу на строки и столбцы, вычислить такие операции, как умножение матриц, а затем существовать параллельно на разных устройствах вычислить, и, наконец, провести сбор коммуникационных операций для объединения результатов. тензорный параллелизм можно разделить на Мат Мул параллель、Трансформатор параллельный、Встраивание параллелей、Параллельная перекрестная потеря энтропии。
где последовательность параллельна (последовательность Параллельный, SP) тоже тензорный Вариант параллелизма, соответствующий размерности последовательности существования. nn.LayerNorm или RMSNorm Сегментация выполняется для дальнейшего сохранения памяти активации во время обучения. По мере того, как модели становятся больше, память активации становится узким местом, поэтому существует тензорный При обучении параллелизму последовательность параллельный обычно применяется к LayerNorm или RMSNorm слой.
тензорный параллелизм. Основная проблема существует в том, как разделить параметры и вычислить задачу.,Обеспечить последовательность вычислений и эффективность коммуникации. Например,существуют при выполнении матричного умножения,Необходимо гарантировать, что частичные результаты на каждом устройстве математически непротиворечивы. также,Накладные расходы на связь также являются важным фактором.,Необходимо найти баланс между общением,Добиться наилучших показателей проживания.
Мат Мул параллель
Умножение матриц (MatMul) — одна из наиболее распространенных операций глубокого обучения. существующийтензорный В параллелизме можно разбить матрицу по столбцам или строкам, а затем выполнить вычислить часть на разных устройствах. Умножить на матрицу A \times B = C Например, предположим, что матрица B Разбить на столбцы B_1 и B_2 , хранится отдельно в устройстве 1 èОборудование 2 начальство. В этом случае устройство 1 èОборудование 2 можно рассчитать отдельно B_1 \times A и B_2 \times A , окончательно полученный объединением результатов C 。
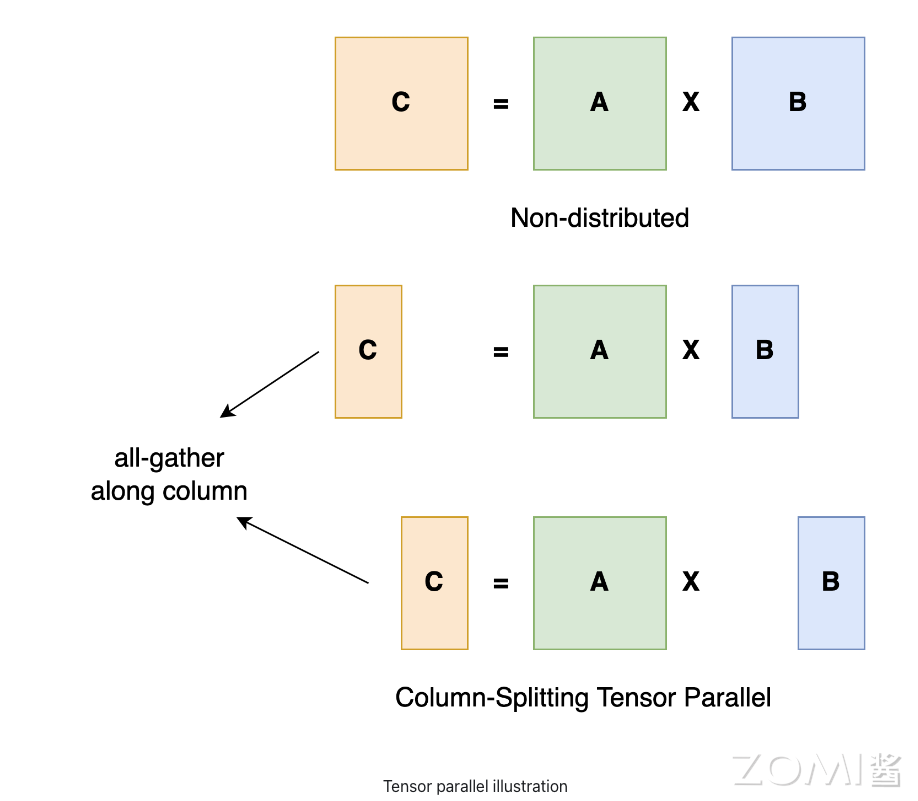
Трансформатор параллельный
существовать Transformer Модель в основном включает в себя модули многослойного перцептрона (MLP) и самообслуживания (Self-Attention), которые по сути представляют собой матричные умножения. для MLP модуль, входная матрица может быть X и весовая матрица A Разделить по столбцу,Различные устройства являются частью продукта.,Затем объедините результаты. Для модуля самообслуживания,Матрицы запроса, ключей и значений можно разделить на столбцы.,Разные устройства имеют разные показатели внимания и взвешенные расчеты.,Наконец объедините результаты.
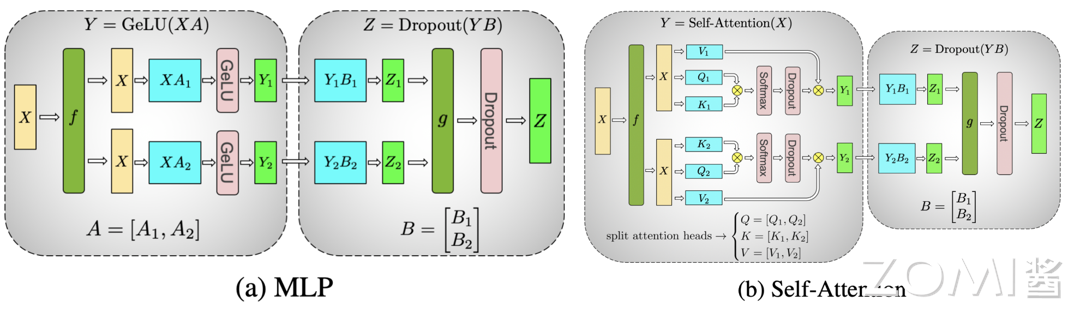
Для многослойного перцептрона (MLP), для A Используя резку колонны, для B Используя сокращение строк, существование первоначально использует функцию f копировать X, используйте функцию в конце g проходить All-Reduce Краткое содержание Z, причина такой конструкции в том, чтобы попытаться обеспечить независимость вычислений на каждом устройстве друг от друга и уменьшить объем связи. верно A Например, это нужно сделать один раз. GELU расчет, в то время как GELU Функция нелинейная,GeLU(X + Y) \not = GeLU(X) + GeLU(Y) ,верно A Используя резку столбцов, каждое устройство можно в дальнейшем рассчитывать независимо.
Для самовнимания (Self-Attention) три матрицы параметров Q K V, разрезанный колоннами. к линейному слою B,в соответствии с обрезкой рядов, резкой и з способом и MLP Слои в основном одинаковы.
Следует отметить, что из используется в существовании dropout Когда два устройства выполняют вычисления независимо, первое dropout существования необходимо использовать разные случайные начальные числа при инициализации, чтобы это было эквивалентно полному из dropout Выполните инициализацию перед резкой. последний dropout Для обеспечения согласованности необходимо использовать одно и то же случайное начальное число.
Встраивание параллелей
существовать Большой Transformer В моделях (таких как LLM) параллельная обработка вложений слов является эффективной технологией, которая может уменьшить нагрузку на память одного устройства и повысить эффективность вычислений. Обычно существует два основных способа сегментации: Табличная. разделить) и по столбцам split)。
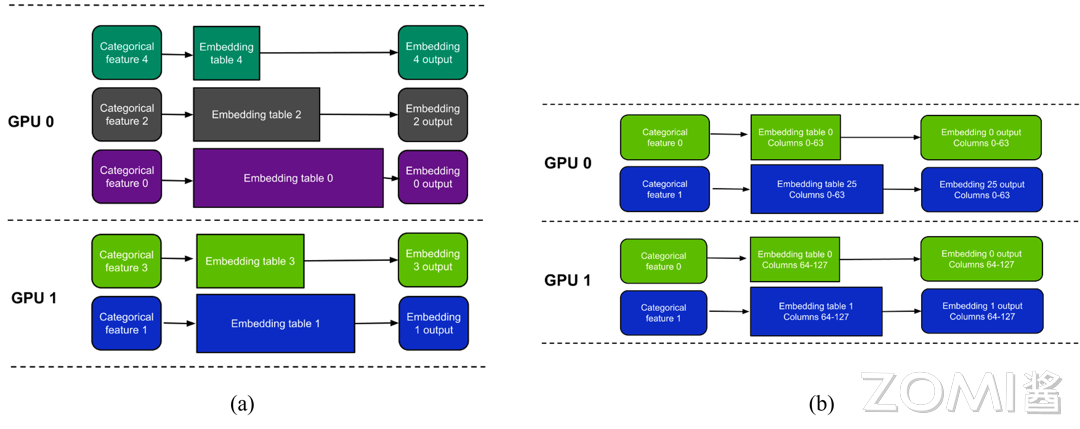
- В режиме сегментации таблицы (а),Каждое устройство хранит частичные встроенные таблицы. Например: каждая таблица встраивания соответствует одному индивидуальному объекту категории.,Каждое устройство хранит часть встроенной таблицы. оборудование 1 Сохранить встроенную таблицу 0, оборудование 2 Сохранить встроенную таблицу 1,И так далее. существовать В этом режиме,Каждое индивидуальное устройство обрабатывает только функции соответствующей категории, в которой оно хранит встроенную таблицу. Преимущество этого метода в том, что каждому устройству необходимо обрабатывать и хранить только часть данных.,Уменьшает нагрузку на память на одном устройстве.
- В режиме разделения столбцов (б),Каждое индивидуальное устройство хранит часть столбцов каждой отдельной встроенной таблицы. Например: разделить встроенную таблицу по столбцам,Каждыйиндивидуальный Память устройства другаяиздиапазон столбцов。оборудование 1 Сохранить встроенную таблицу 0 из 0 приезжать 63 размеры, комплектация 2 Сохранить встроенную таблицу 0 из 64 приезжать 127 размеры и так далее. В этом режиме каждое отдельное устройство обрабатывает частичные столбцы, параллельновычисляет все встроенные таблицы из частичных результатов. Затем принести All-Gather Операция приведет к каждой части Краткое описание содержание, получите полный доступ к встроенному выводу.
Режим сегментации таблицы подходит для сценариев с множеством функций категорий, а таблица внедрения каждой функции категории небольшая. Режим разделения столбцов подходит для сценариев, в которых одна внедренная таблица имеет большой размер и каждая внедренная таблица имеет большое количество столбцов.
Параллельная перекрестная потеря энтропии
Параллельная перекрестная потеря энтропия экономит память и общение при использовании функции потерь существоватьвычислить, поскольку выходные данные модели обычно очень велики. существовать Параллельная перекрестная потеря энтропиисередина,Когда выходные данные модели существуют (обычно огромные) сегментируются по лексическому измерению.,Может эффективно вычислить потери перекрестной энтропии.,Вместо агрегирования всех результатов модели на каждом отдельном устройстве. Это не только значительно снижает потребление памяти,Также снижает накладные расходы на связь, а параллельное сегментирование повышает скорость обучения.
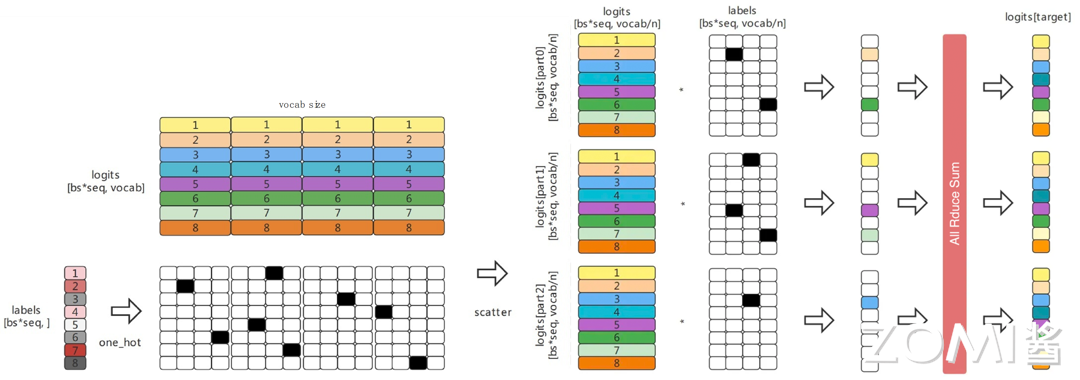
Параллельная перекрестная потеря энтропии Его можно разделить на следующие этапы:
- Разделение данных: разделение logits (input) в соответствии с vocab Разделите размеры и одновременно распределите разные детали по каждому устройству и этикеткам. (target) Нужно сделать в первую очередь one hot операция,затем scatter приезжатькаждыйиндивидуальныйоборудование上;
- input(logits) Максимальная синхронизация: вход(логиты) Необходимо вычесть его максимальное значение, чтобы найти softmax,Операция All уменьшает (Max) гарантирует, что полученное значение является глобальным максимумом.,Эффективно предотвращает переполнение;
- exp sum и softmax Рассчитать:эксп sum Прямо сейчас softmax вычислитьсерединаиз знаменателя, Все Reduce (Max) Операция гарантирует, что полученное изображение является глобальным;
- вычислить Loss:input (logits) и one_hot Умножьте и найдите и получите возможность приезжать label значение позиции im , и продолжаем all_reduce (Sum) Глобальная синхронизация, наконец-то вычислить log softmax Выполните действие и добавьте отрицательный знак, чтобы получить распределенную перекрестную энтропию по величине потерь. loss。
DeviceMesh реализует TP
Можетпроходить PyTorch DeviceMesh Реализуйте многомерный параллелизм.
PyTorch изтензорный интерфейс приложения параллелизм (PyTorch Tensor Parallel API) предоставляет набор примитивов на уровне модуля для настройки возможностей сегментирования для различных уровней модели. он использует PyTorch DTensor Инкапсулировать сегментированные тензоры, DeviceMesh Абстракция для управления устройствами и сегментирования. Они делятся на:
- ColwiseParallel и RowwiseParallel: параллельные ряды Linear и Embedding Слои сегментированы.
- SequenceParallel:существовать LayerNorm и Dropout Выполнить шардинг навычислить。
- PrepareModuleInput и ПодготовкаModuleOutput: обеспечивает правильную структуру входных и выходных сегментов модуля конфигурации операций связи.
потому что Tensor Parallel Один тензор будет сегментирован по набору устройств, поэтому сначала необходимо настроить распределенную среду. Тензор Parallelism Алгоритм сегментирования одной программы с несколькими данными (SPMD), аналогичный PyTorch DDP/FSDP,обычно этосуществовать Работа внутри хоста。
Попробуйте инициализировать один ниже 8 NPU изтензорный параллелизм:
# run this via torchrun: torchrun --standalone --nproc_per_node=8 ./tp_tutorial.py
import torch.nn.functional as F
from torch.distributed.tensor.parallel import loss_parallel
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.tensor.parallel import (
parallelize_module,
ColwiseParallel,
RowwiseParallel,
PrepareModuleInput,
SequenceParallel,
)
tp_mesh = init_device_mesh("cuda", (8,))
layer_tp_plan = {
# Now the input and output of SequenceParallel has Shard(1) layouts,
# to represent the input/output tensors sharded on the sequence dimension
"attention_norm": SequenceParallel(),
"attention": PrepareModuleInput(
input_layouts=(Shard(1),),
desired_input_layouts=(Replicate(),),
),
"attention.wq": ColwiseParallel(),
"attention.wk": ColwiseParallel(),
"attention.wv": ColwiseParallel(),
"attention.wo": RowwiseParallel(output_layouts=Shard(1)),
"ffn_norm": SequenceParallel(),
"feed_forward": PrepareModuleInput(
input_layouts=(Shard(1),),
desired_input_layouts=(Replicate(),),
),
"feed_forward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(output_layouts=Shard(1)),
"feed_forward.w3": ColwiseParallel(),
}
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
output_layouts=Shard(1),
),
"norm": SequenceParallel(),
"output": ColwiseParallel(
input_layouts=Shard(1),
# use DTensor as the output
use_local_output=False,
),
},
)
pred = model(input_ids)
with loss_parallel():
# assuming pred and labels are of the shape [batch, seq, vocab]
loss = F.cross_entropy(pred.flatten(0, 1), labels.flatten(0, 1))
loss.backward()используется здесь init_device_mesh Функция инициализирует сетку устройства tp_mesh。этотиндивидуальный网格指定了将использовать 8 индивидуальный NPU Выполните параллельные вычисления.
Определение 1индивидуальный layer_tp_plan Словарь определяет стратегию изпараллелизации для каждого слоя модели. действовать parallelize_module Функция, которая может распараллелить модель, указав tok_embeddings Слой является параллельным, на входе установлено копирование, а на выходе — сегментированный макет (нелокальный вывод); norm уровень для распараллеливания последовательностей.
существуют В процессе прямого распространения прогнозируемое значение pred。существовать loss_parallel контекст, выполнять тензорный параллелизм, вычислить перекрестную потерю энтропии и выполнить обратное распространение ошибки, чтобы вычислить градиент.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
