Синхронизация данных для синхронизации гетерогенных источников данных → Подробности использования DataX
Простой в использовании
о DataX ,Вы можете перейти на официальный сайт для ознакомления:introduction
В нем упомянуто DataX Его обзор, конструкция структуры, основная архитектура, система плагинов и основные преимущества разработаны Alibaba и широко используются в Alibaba. Его производительность и стабильность были тщательно проверены. Благодаря конструкции рамы

- Читатель: модуль сбора данных,Отвечает за сбор источников данных.,и отправьте данные в FrameWork
- Writer: данные Писать в модуль, постоянно из FrameWork Возьмите данные и поместите данные Писать в целевой источник данных
- FrameWork: основной модуль для подключения Reader и Writer,Поскольку оба изданных канала передачи,и обрабатывать буферизацию、контроль потока、одновременно、Основные проблемы, такие как преобразование данных
Нам легко добиться вторичного развития,Конечно главноеда Для новых плагиновизразвивать。DataX Реализовано множество плагинов
тип | источник данных | Читатель (читать) | Писатель (писать) | документ |
|---|---|---|---|---|
Реляционная база данных РСУБД | MySQL | √ | √ | читать, писать |
Oracle | √ | √ | читать, писать | |
OceanBase | √ | √ | читать, писать | |
SQLServer | √ | √ | читать, писать | |
PostgreSQL | √ | √ | читать, писать | |
DRDS | √ | √ | читать, писать | |
Kingbase | √ | √ | читать, писать | |
Универсальная СУБД (поддерживает все реляционные базы данных) | √ | √ | читать, писать | |
Облачное хранилище данных Alibaba Хранение данных | ODPS | √ | √ | читать, писать |
ADB | √ | Писать | ||
ADS | √ | Писать | ||
OSS | √ | √ | читать, писать | |
OCS | √ | Писать | ||
Hologres | √ | Писать | ||
AnalyticDB For PostgreSQL | √ | Писать | ||
Промежуточное ПО Alibaba Cloud | datahub | √ | √ | читать, писать |
SLS | √ | √ | читать, писать | |
графовая база данных | Облако ГББ Alibaba | √ | √ | читать, писать |
Neo4j | √ | Писать | ||
Хранение данных NoSQL | OTS | √ | √ | читать, писать |
Hbase0.94 | √ | √ | читать, писать | |
Hbase1.1 | √ | √ | читать, писать | |
Phoenix4.x | √ | √ | читать, писать | |
Phoenix5.x | √ | √ | читать, писать | |
MongoDB | √ | √ | читать, писать | |
Cassandra | √ | √ | читать, писать | |
Хранилище данных хранилища данных | StarRocks | √ | √ | читать, писать |
ApacheDoris | √ | Писать | ||
ClickHouse | √ | √ | читать, писать | |
Databend | √ | Писать | ||
Hive | √ | √ | читать, писать | |
kudu | √ | Писать | ||
selectdb | √ | Писать | ||
Неструктурированное хранилище данных | TxtFile | √ | √ | читать, писать |
FTP | √ | √ | читать, писать | |
HDFS | √ | √ | читать, писать | |
Elasticsearch | √ | Писать | ||
база данных временных рядов | OpenTSDB | √ | читать | |
TSDB | √ | √ | читать, писать | |
TDengine | √ | √ | читать, писать |
Включая большую часть источников данные, мы можем просто использовать их напрямую, если это такой же источник, как указано выше; данные не включены в то, что вам нужно данных, вы также можете реализовать плагин самостоятельно, см. Руководство по разработке плагина DataX Вот и все
Если вы просто используете DataX , затем скачайте DataX набор инструментов Вот и все, после распаковки структура каталогов следующая
Я не буду описывать функции каждой папки. Вы можете просто зайти на официальный сайт и прочитать документ; bin в каталоге datax.py запускать DataX。
существующий MySQL база данных qsl_datax,на нем стоит стол qsl_datax_source
CREATE TABLE `qsl_datax_source` (
`id` bigint(20) NOT NULL COMMENT «Автоинкремент первичного ключа»,
`username` varchar(255) NOT NULL COMMENT 'Имя',
`password` varchar(255) NOT NULL COMMENT 'пароль',
`birth_day` date NOT NULL COMMENT 'Дата рождения',
`remark` text,
PRIMARY KEY (`id`)
);
insert into `qsl_datax_source`(`id`, `username`, `password`, `birth_day`, `remark`) values
(1, «Чжан Сан», 'z123456', '1991-01-01', «Чжан Сан»)
(2, «Джон Доу», 'l123456', '1992-01-01', «Джон Доу»)
(3,'Ван Ву', 'w123456', '1993-01-01','Ван Ву'),
(4, 'Асако', 'm123456', '1994-01-01','Асако');Данные в таблице необходимо синхронизировать с MySQL база данных qsl_datax_sync стол qsl_datax_target
CREATE TABLE `qsl_datax_target` (
`id` bigint(20) NOT NULL COMMENT «Автоинкремент первичного ключа»,
`username` varchar(255) NOT NULL COMMENT 'Имя',
`pw` varchar(255) NOT NULL COMMENT 'пароль',
`birth_day` date NOT NULL COMMENT 'Дата рождения',
`note` text,
PRIMARY KEY (`id`)
);Как этого добиться?
Настройте job.json
Потому что это из MySQL Синхронизировать с MySQL , поэтому наш Reader да MySQL,Writer такжеда MySQL , тогда будет понятно, куда копировать файл конфигурации. от MysqlReader копировать Reader конфигурация, из MysqlWriter копировать Writer Конфигурация,Затем измените значение соответствующего параметра Конфигурация на свое собственное.,mysql2Mysql.json Даже если настройка завершена
{
"job": {
"setting": {
"speed": {
"channel": 5
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"password",
"birth_day",
"remark"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8"
],
"table": [
"qsl_datax_source"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"pw",
"birth_day",
"note"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8",
"table": [
"qsl_datax_target"
]
}
]
}
}
}
]
}
}mysql2Mysql.json Вы можете хранить его где угодно. Рекомендуется положить его. DataX из job каталог для удобного управления. Конфигурация несложная и я думаю, что каждый сможет ее понять.
запускать DataX Синхронизировать
приезжать DataX из bin Откройте окно командной строки запустить в каталоге, а затем выполните следующую команду
python datax.py ../job/mysql2Mysql.json
Когда мы смотрим на следующий вывод слова приезжать, это означает такой Первый шаг удался

Нужно объяснение изда
DataX не поддерживает шаги таблицы,Поддерживает толькоданныетакой же Шаг,тактакой При продолжении вам необходимо убедиться, что целевая таблица сохранена.
column
обратитесь киз Сразуда job.json середина reader и writer Узел под из column ,Конфигурациянуждатьсятакой жестепиз коллекции имен столбцов; это может быть Конфигурация таблицы из имени столбца, Конфигурация констант, выражений или Конфигурация. * , но настройка не рекомендуется *,Потому что нам не удобно просматривать взаимосвязь между столбцами изкартографирования.
Reader и Writer между соответствии с заказом картографирование, не в соответствии Имени поля с предшествует картографированиеиз, перед которым стоит из mysql2Mysql.json Например, взаимосвязь поля изкартографирования выглядит следующим образом:
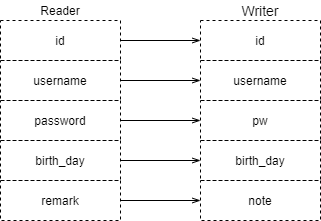
Эквивалент дав соответствии смножествоизиндексированиекартографированиеиз,reader_column[n] картографирование writer_column[n],Тогда возникает вопрос,Что произойдет, если количество столбцов не соответствует?
-
ReaderСоотношение столбцовWriterмного удалятьWriterиз Списокpw,Затем выполнитетакой же Step Mission, ты найдешь такой же Шаг аномальный, выводит следующую информацию В столбце «Информация о конфигурации» ошибка. Поскольку ваша задача Конфигурация середина, sourceчитать принимает количество полей: 4. и Количество полей для ввода: 5 Не равны. Пожалуйста, проверьте вашу конфигурацию и внесите изменения. -
ReaderСоотношение столбцовWriterнемного такой же Такая встречатакой же Шаг аномальный, сообщение с подсказкой похоже на следующее В столбце «Информация о конфигурации» ошибка. Поскольку ваша задача Конфигурация середина, sourceчитать принимает количество полей: 4. и Количество полей для ввода: 5 Не равны. Пожалуйста, проверьте вашу конфигурацию и внесите изменения.
Что произойдет, если количество столбцов одинаковое, но порядок столбцов неправильный?
- такой же Шаганомальный Нет ли у вас такого вопроса: Количество столбцов одинаковое, как так может быть? же шаг аномальный? Поскольку тип существования сохраненного столбца не соответствует, данные не могут быть вставлены. Например, я буду.
Writerсерединаизusernameиbirth_dayПоменяй эту позицию, а затем выполнить такую же Шаг,найдеттакой же Шаганомальный,аномальныйинформация Похоже на следующее Date ошибка преобразования типа - такой Шаги нормальные, но данные испорчены.
Поменяй это
Writerизusernameиpw
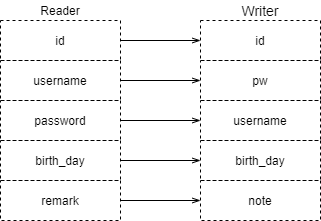
осуществлятьтакой же Step Mission, ты найдешь такой Тот же шаг не показался аномальным, но вы взглянули на целевой источник данныхизданные
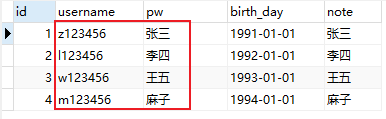
Видно, что он грязный, это считается таким же Шаг успеха и датой Шаг не удался?
Пример с грязными данными легко увидеть. Если есть два очень похожих столбца, ждать нас будет непросто. bug Поездка по устранению неполадок

table
существовать Reader Указывает откуда читанные,существовать Writer Указывает, куда идти Писатьданные;Reader и Writer Все поддерживается Настроить несколько таблиц, но эти таблицы должны быть гарантированно датой или один schema структура
Лично я не очень рекомендую job Настроить несколько table,И даодин job один table,еслинуждатьсятакой же Шаг много table,Что Сразу Настроить несколько job Хорошо
splitPk
Эта конфигурация предназначена только для Reader
Reader При выполнении извлечения данных, если вы укажете splitPk,Так DataX будет нажимать splitPk Конфигурация поля для сегментирования данных, запуск параллельных задач для данныхтакой такой же шаг к улучшению же ступенчатая эффективность
Потом проблема возникает снова, разделить Онинемного фильма? Я дал всем Подвести Итог Хорошо
- Если не Конфигурация
splitPk,ноодинtableПереписка одинtask - Конфигурация Понятно
splitPk,tableесли бы только 1 , затем делится наjob.setting.speed.channel * reader.parameter.splitFactorкусок,за ломтик Переписка одинtasksplitFactorБез Конфигурации его значение по умолчанию — да. 5 - Конфигурация Понятно
splitPk,иtableмного Оставаться 1 , то для каждогоtableразделен наjob.setting.speed.channelкусок,за ломтик Переписка одинtaskНе рекомендуется всем живущим.jobсередина Настроить несколько таблиц, поэтому полезно понимать эту ситуацию
Жаль, изда, сейчас splitPk Поддерживается только сегментация пластиковых данных, в противном случае будет сообщено об ошибке.
мы правы mysql2Mysql.json Продолжать splitPk Преобразуйте и настройте следующим образом 2 Предмет, другие не двигаются
- job.setting.speed.channel изменен на 2
- reader Добавлено в узел 2 Конфигурацияэлемент
- reader.parameter.splitPk="id"
- reader.parameter.splitFactor=2
При выполнении такой же пошаговой задачи вы можете увидеть следующий журнал прибытия.

смотри внимательно allQuerySql,4 полоска SQL представлять 4 Шардинг, я думаю, вы все это понимаете, но да where id IS NULL этотполоска SQL Что значит да? На самом деле, если мы внимательно подумаем об этом, мы поймем, что причина, по которой мы думаем, where id IS NULL Нет необходимости сохранять существование по причине, которую мы знаем id да первичный ключ, но DataX Знаешь, оно не знает, поэтому ему нужно where id IS NULL гарантироватьданныене пропустить。Но опять же,данныеколичествонемногоизкогда,Нефрагментация более эффективна, чем фрагментация.,Это возвращение к старому клише, проблеме перемещения.
Обязательно ли многопоточность более эффективна, чем однопоточность?
where
Также только для Reader
такой же SQL серединаиз WHERE один Образец,да отфильтровать полоски кусочков,Reader в соответствии с column、table、where Сращивание SQL,тогда используй это Сращиваниехорошийиз SQL Выполните извлечение данных. Перед демонстрацией примера не забываем mysql2Mysql.json Восстановите его первоначальный вид, а затем добавьте его. where полоскакуски
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"password",
"birth_day",
"remark"
],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8"
],
"table": [
"qsl_datax_source"
]
}
],
"where": "id < 3"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"pw",
"birth_day",
"note"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8",
"table": [
"qsl_datax_target"
]
}
]
}
}
}
]
}
}Выполните такой же шаг программы, и в журнале существования серединаприезжать вы увидите следующую информацию:

Если плюс splitPk , ты думаешь приехать DataX из Вы занимаетесь логикой? Позвольте мне показать вам лог.

Вы понимаете этот журнал?
Если не настроено where или where из значения Конфигурация пуста, то она эквивалентна полной сумме такой тот же шаг, если это нормально Конфигурация; where эквивалентно приращению такой тот же шаг, и это приращение такое Тот же шаг реализовать реальный проект «середина» с помощью сравнения многих из них. Как только приращение задействовано, нам не нужно передавать значение столбца приращения в значение в форме переменной, но DataX Эта функция только что реализована, и ее конфигурация аналогична следующей:
"where": "id > $startId"
Передайте значение переменной через команду запускать, как показано ниже.
python datax.py ../job/mysql2Mysql.json -p"-DstartId=1"
Следующий журнал появляется в такой же пошаговой задаче, что указывает на то, что переменная из значения передается нормально.

В сочетании с платформой планирования приращение времени такое Достигнуто всего за один шаг
Если вам интересно, можете зайти и посмотреть datax-web
querySql
Только для Reader
table добавлять where способный Конфигурацияизфильтрполоскакускивозвращатьсяда Относительно ограничено,join Я тоже не могу быть удовлетворен, так что querySql В нужное времяирожденный。querySql Разрешить пользователям настраивать фильтры SQL
Когда пользователь настраивает
querySqlчас,ReaderПросто игнорироватьtable、column、whereполоскакускииз Конфигурация,querySqlприоритет выше, чемtable、column、whereПараметрыtableиquerySqlТолькоспособный Конфигурацияодин,Нетспособныйтакой жечас Конфигурация
querySql такой же Образец Поддержка переменных,Похоже на следующее
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"splitPk": "id"
"splitFactor": 2
"connection": [
{
"querySql": ["select id,username,password,birth_day, 'remark' AS remark from qsl_datax_source where id > $startId"]
"jdbcUrl": [
"jdbc:mysql://192.168.2.118:3307/qsl_datax?useUnicode=true&characterEncoding=utf-8"
],
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"id",
"username",
"pw",
"birth_day",
"note"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.2.118:3306/qsl_datax_sync?useUnicode=true&characterEncoding=utf-8",
"table": [
"qsl_datax_target"
]
}
]
}
}
}
]
}
}такой же журнал шагов середина отобразит следующую информацию

Вы можете посмотреть приезжать, если Конфигурация querySql,Так splitPk Конфигурация больше не вступит в силу.
Подвести итог
- Если вы будете осторожны, вы обнаружите, что то, что я сказал, по сути то же самое.
Reader, это правда, что даReaderКонфигурация гораздо сложнее много, так какWriterКонфигурация Хорошо,Я верю, что вы все можете понять,такжегород Конфигурация,я не буду тебя пилить columnНе рекомендуется Конфигурация*,Рекомендуемые имена столбцов,Может более интуитивно реагировать на картографирование отношений.tableрежим, одиночныйjobРекомендуется только с однимtable,Если датакой же Шаг многоtable, рекомендовать Настроить несколькоjobsplitPkПоддерживает толькоtableмодель,Реализация сегментированного одновременного получения данных,Повышение эффективности запросов,Но это не даабсолютиз,Небольшой объем данных в каждом случае,Возможно, одна задача более эффективнаwhereПоддерживает толькоtableрежим добавления фильтрующих элементов полоски запроса в запрос, поддержку переменных и возможность достижения инкрементального такого же ШагquerySqlмодель Вниз,tableмодель Нетспособный Конфигурация,нетноаномальный,column、where、splitPkНесмотря на то Конфигурация Понятнотакже Нетрожденный效;querySqlВозможна пользовательская настройкаSQL,Очень гибкий,joinПросто используйте запросquerySqlосознать



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
