Сингапур & Нью-Йоркский университет & байт предлагать PLLaVA | Простой и эффективный метод адаптации модели языка видео, превосходящий GPT4V и преодолевающий ограничения ресурсов. !

На видео изображена женщина, идущая по ночной улице. На ней была черная кожаная куртка, солнцезащитные очки и черная сумочка. Улицы были мокрыми, что указывало на то, что только что прошел дождь. На заднем плане есть еще люди, но они не в центре внимания видео. Женщина кажется главным героем, идущим целеустремленно. Общая атмосфера видео мрачная и мрачная. Предварительное обучение визуальному языку значительно улучшило производительность в широком спектре приложений языка изображений. Однако процесс предварительного обучения для задач, связанных с видео, требует особенно больших вычислительных ресурсов и ресурсов данных, что затрудняет разработку моделей языка видео. В этой статье исследуется простой, эффективный и экономичный метод адаптации существующих предварительно обученных моделей языка изображений для понимания плотного видео. Предварительные эксперименты авторов показывают, что точная настройка предварительно обученной модели языка изображений непосредственно на наборе видеоданных с использованием нескольких кадров в качестве входных данных может привести к насыщению или даже снижению производительности. Дальнейшие исследования авторов показали, что это в основном связано с предвзятостью выученных зрительных функций, отвечающих высоким нормам. Вдохновленный этим открытием, автор предложил разработать простую и эффективную стратегию объединения, позволяющую сгладить распределение признаков во временном измерении, тем самым уменьшая влияние экстремальных признаков. Новая модель называется Pooled LLaVA, или сокращенно PLLaVA. PLLaVA обеспечивает высочайшую производительность на современных эталонных наборах данных для решения задач видеоответов на вопросы и субтитров. Стоит отметить, что в популярном в последнее время Видео В эталонном тесте ChatGPT PLLaVA получила средний балл 3,48/5 по пяти параметрам оценки, превысив предыдущий результат SOTA GPT4V (IG-VLM) на 9%. В последнем тесте вопросов с несколькими вариантами ответов MVBench PLLaVA достигла средней точности 58,1% в 20 подзадачах, что на 14,5% выше, чем GPT4V (IG-VLM). Код доступен по адресу https://github.com/magic-research/PLLaVA.
1 Introduction
Мультимодальные модели большого языка (MLLM) продемонстрировали превосходные возможности в понимании изображений при обучении крупномасштабных пар изображение-текст. Подобно области изображений, последние модели понимания видео также исследовали аналогичные процессы, настраивая LLM на крупномасштабных видеотекстовых данных. Однако этот метод требует больших вычислительных ресурсов и затрат на аннотирование видеоданных. Более практичный подход заключается в адаптации предварительно обученных MLLM доменов изображений к видеоданным.
Интуитивный подход к адаптации изображений MLLM заключается в кодировании нескольких видеокадров в последовательности функций и передаче их непосредственно в MLLM, поскольку модели большого языка (LLM) по своей сути подходят для обработки последовательных функций и, как было показано, понимают временную информацию.
Однако авторы эмпирически обнаружили две технические проблемы при расширении MLLM изображений на видеоданные таким способом. Во-первых, обучение MLLM изображений на видеоданных не всегда повышает производительность по сравнению с приложениями с нулевым кадром, вместо этого производительность становится чувствительной к изменениям в подсказках запросов.
Во-вторых, увеличение размера компонента языковой модели не улучшает производительность понимания видео. Эти два наблюдения противоречат здравому смыслу, поскольку увеличение размера модели и предоставление модели большего количества последующих данных обычно считаются полезными для повышения производительности модели.
Затем авторы провели серию исследований, чтобы выяснить основные причины этих двух наблюдений. Что касается первой проблемы, авторы обнаружили, что это связано главным образом с ограниченностью информации, кодируемой кодером изображения. При проведении экспериментов на LLaVA с 4 кадрами ввода автор экспериментально обнаружил, что, как показано на рисунке 3, в процессе тонкой настройки нормы некоторых Токенов визуальных особенностей были значительно больше, чем у других Токенов. Эти токены приводят к снижению качества коротких текстовых описаний.
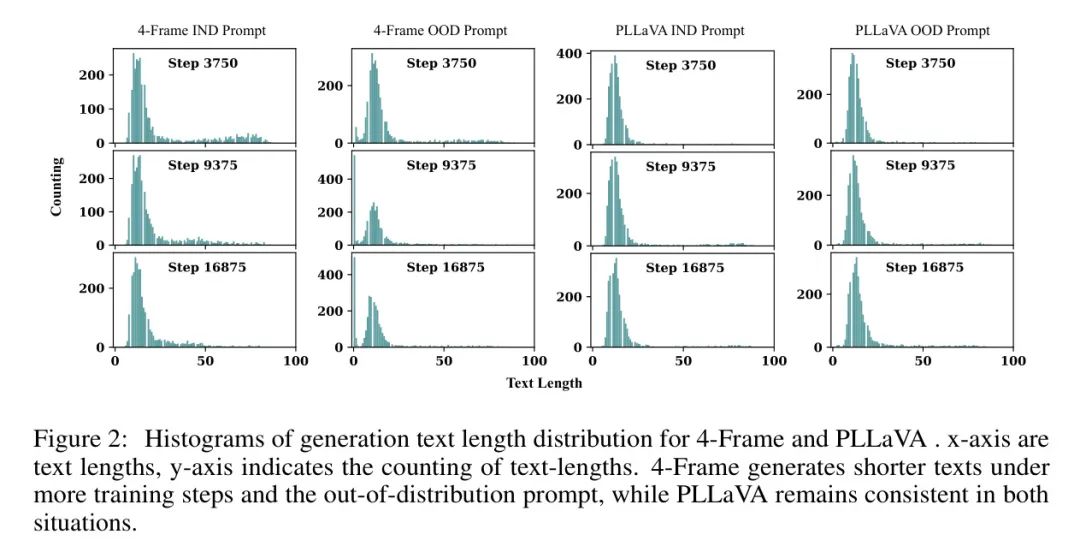
Как показано на рисунке 2, 4-кадровая модель имеет тенденцию генерировать более короткий текст по мере обучения большего количества образцов. Автор предполагает, что из-за расчета softmax в процессе самообслуживания функции с большими нормами получают глобальную видеоинформацию, тем самым подавляя нормы других токенов. Это приводит к более коротким генерируемым описаниям. Хуже того, если шаблон подсказки изменится, изученные MLLM полностью сломаются, что приведет к очень коротким описаниям или даже к отсутствию ответов. Авторы заметили, что добавление большего количества видеокадров смягчило блокировку большинства токенов. Однако это приведет к значительному увеличению потребления памяти.

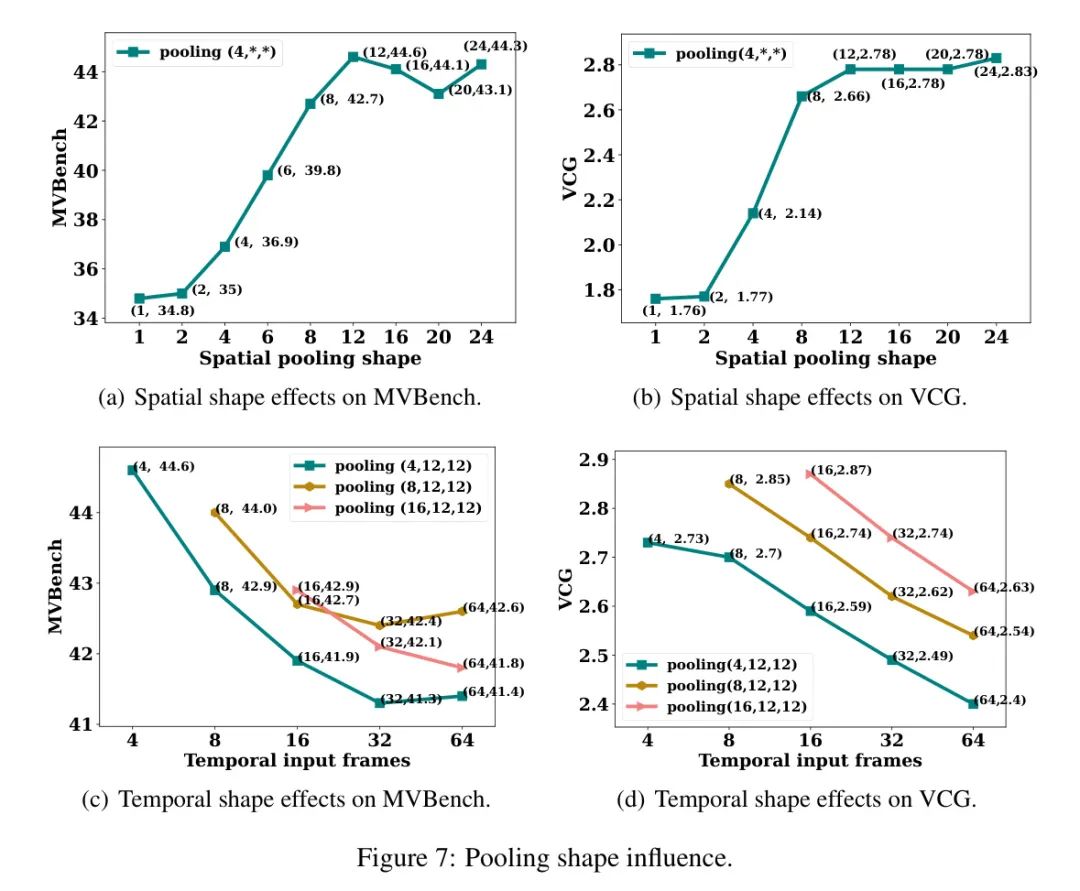
Следовательно, существует компромисс между количеством кадров и вычислительными затратами. Интуитивный подход заключается в понижении разрешения видеокадров. Однако прямое усреднение пространственных и временных измерений, как это делается в VideoChatGPT [30], приводит к потере слишком большого количества пространственной информации и не обеспечивает оптимальной производительности при масштабировании набора обучающих данных. Следовательно, цель состоит в том, чтобы найти минимальное пространственное разрешение каждого кадра, чтобы оно не ухудшало производительность кривой масштабирования. Чтобы достичь этого, авторы используют операцию объединения [15] для изучения оптимальных настроек, которые не уменьшают выгоду от увеличения временного рецептивного поля. Влияние операции объединения показано на рисунке 7.
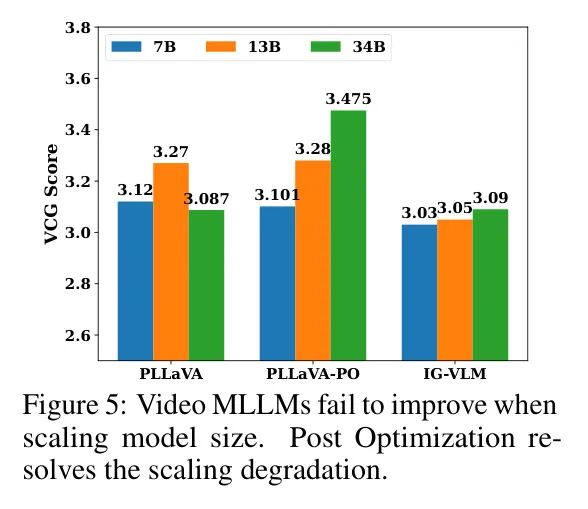
Что касается второго наблюдаемого явления, авторы полагают, что основной причиной является низкое качество наборов видеоданных по сравнению с наборами данных изображений. В частности, многие наборы видеоданных имеют формат вопросов и ответов, а описания видео могут быть короткими. Поэтому, когда модель изучает временные описания из наборов видеоданных, описания других показателей, таких как объекты и пространственные отношения, ухудшаются. Чем мощнее модель, тем быстрее ухудшается производительность. Вместо создания высококачественного набора видеоданных авторы решили изучить архитектуру и оптимизировать алгоритмы, чтобы лучше сохранять информацию, полученную в наборах данных изображений, при изучении временной информации из наборов видеоданных. Для этого авторы используют технику слияния весов. Автор устанавливает два набора весов: один из предварительной тренировки изображения и один из точной настройки набора видеоданных. После обучения авторы ищут наилучшую комбинацию весов модели на основе изображений и весов модели на основе видео, надеясь, что комбинированная модель выиграет от обоих наборов данных. В этой статье этот процесс называется оптимизацией после обучения, и его влияние показано на рисунке 5.
Авторы провели тщательное предварительное исследование по прямому применению крупномасштабной мультимодальной модели изображения к видео задаче.,И было обнаружено несколько режимов отказа. Затем автор представляет простую и элегантную, но очень эффективную стратегию объединения ресурсов.,Он систематически достигает оптимального баланса между эффективностью обучения и точностью субтитров. Автор предложения предложил метод слияния моделей после обучения.,Это может эффективно уменьшить явление забывания в процессе мультимодальной тонкой настройки больших языков. с помощью этого метода,Автору удалось получить большую мультимодальную видеомодель с языком 34B.,Нет необходимости дополнительно создавать качественные наборы данных. Автор провел обширные эксперименты, чтобы убедиться в превосходстве предлагаемой Модели.,И добились новых современных результатов по различным тестам понимания видео.,Особенно на существующих видео субтитрах с плотными субтитрами. По бассейну-LLaVA,Автор перезаписал первые 1 миллион видеоданных с Панды-70М.,Создаются плотные и точные двуязычные субтитры.
2 Related Works
Рисунок 2: Гистограмма распределения длины текста, созданная с помощью 4-Frame и PLLaVA. Ось X — это длина текста, а ось Y — отсчет длины текста. Благодаря большему количеству этапов обучения и нераспределенным сигналам 4-Frame генерировал более короткий текст, в то время как PLLaVA оставался неизменным в обоих случаях.
Мультимодальная видеомодель на большом языке Мультимодальная модель видео обрабатывает входной видеосигнал и генерирует ответы на основе команд пользователя. Обычно они используют обучаемый интерфейс, включающий проекционные сети [30; 22; 19], кроссмодальное внимание [17; 18] или модальный перцептрон [45; 32; 12]. Эти интерфейсы играют ключевую роль в объединении пространственно-временной динамики видео с вычислительной мощностью больших языковых моделей (LLM) путем преобразования видеоконтента во что-то, что LLM могут профессионально анализировать. token последовательность. БЛИП [16] Благодаря интеграции замороженного визуального кодера с BLIP для повышения эффективности обработки видео можно изучить только недавно добавленный Q-Former, что знаменует собой важную веху. Он продемонстрировал превосходные возможности видеоответа на вопросы (VQA) с нулевой выборкой, превосходя существующие в то время технологии. Video-ChatGPT расширяет инновации своих предшественников. [30] Представлен новаторский подход к адаптации видеоинструкций и создан высококачественный набор обучающих данных. Эта инициатива устанавливает новый стандарт для сравнительной оценки моделей посредством генерации текста на основе видео. Видеочат [17] Используйте механизм перекрестного внимания, чтобы умело сжимать видеотокены и привлекать пользователей Query Согласуйте ее с контекстом разговора, чтобы повысить объяснительную силу модели. Основываясь на этих достижениях, VideoChat2 [18] Применяется подход к многоэтапному совершенствованию технологии наведения, в котором особое внимание уделяется согласованию модальности и корректировке команд, а также накапливается мощная коллекция высококачественных видеоданных для задач, управляемых командами. ВИЛА [23] предложение разработало более продвинутые методы обучения. Дальнейшая интеграция модальностей, Video-LLaVA [22] Использует предварительно настроенный кодер, который адаптируется как к изображениям, так и к видео, облегчая совместное проецирование и обеспечивая совместное обучение задачам, связанным с изображениями и видео. КОТ [41] Видео и аудио представлены для дальнейшего улучшения понимания.
Длинные видео создают серьезные проблемы из-за высокой вычислительной сложности и больших требований к памяти. Использование тегов видео для обработки всего диапазона длинных видеороликов создает трудности в эффективном совместном захвате пространственных деталей и временной динамики. С этой целью модели языка видео (Video MLLM) используют сложные методы временного моделирования для более эффективного решения этих проблем. «MovieChat» [32] реализует в Transformer новый механизм на основе памяти, позволяющий стратегически объединять похожие кадры для уменьшения вычислительной нагрузки и объема памяти. «Чат-Уни Ви» [12] впервые использует метод скоординированной обработки изображений и видео, инновационно сжимает пространственные и временные маркеры посредством динамического слияния маркеров и использует алгоритм k-NN для повышения эффективности. «LLaMA-VID» [19] инновационно использует метод двойной маркировки для эффективного сжатия представления видео путем разделения тегов контекста и контента, тем самым достигая более эффективного сжатия. «VTimeLLM» [10] подчеркивает границы видео, вводя новый набор данных вопросов и ответов. «Виста-ЛЛАМА» [29] запустила на этой основе ЭДВТ-Внимание и последовательные зрительные проекторы, тщательно планируя зрительные маркеры и сжимая временные маркеры, а затем постепенно интегрируя их через механизм Q-формера. Для дальнейшей оптимизации обработки длинных видео некоторые модели делают упор на выборочную обработку ключевых кадров, тем самым уменьшая количество необходимых видеокадров и упрощая общие вычислительные требования.
Понимание конвейерного видео Использование видеомультимодальной языковой модели (Видео MLLM) появился новый подход, который объединяет ранее существовавшие видеомодели с большими языковыми моделями (LLM) посредством многоэтапного процесса преобразования модальности видео. Этот подход включает преобразование видеоконтента в текстовые повествования, как правило, с использованием предварительно обученных моделей языка видео (VideoLM), интегрированных с LLM на заключительном этапе. Инкапсулируя видео в виде текстовых тегов, он использует опыт LLM в обработке текстовых данных, позволяя интерпретировать временные ряды с помощью этих тщательно созданных описаний. Видеочат-текст [17] Он может эффективно конвертировать видеопотоки в подробные текстовые описания, включая различные видеоэлементы. В то же время ЛЛови [44] Представлена эффективная, ориентированная на LLM структура, предназначенная для решения проблем, связанных с длительным видео. Здесь агент субтитров видео расшифровывает видео в подробные текстовые описания, которые затем уточняются LLM для улучшения понимания длинных видеороликов. Хотя вышеупомянутые методы в основном преобразуют видео в текст для обработки LLM, LLM также изучает свою способность помогать в анализе видео посредством процедурной генерации. ViperGPT [34] это новаторский пример, в котором используются LLM, генерирующие код, включая GPT-3. Codex [4]. Он эффективно использует текстово-ориентированный Query API модуля Vision и программная проверка изображения или видеоконтента для этих Query Дайте образованный ответ. Аналогично, ProViQ [5] Используйте LLM для написания сценариев Python в видеороликах с нулевой выборкой. Query Выполнять многоэтапные программные рассуждения в контексте,Обработайте эти сценарии, чтобы определитьпредлагатьрешение проблемы。
3 Method & Analysis
существоватьв этом разделе,Сначала автор расскажет о некоторых проблемах, с которыми приходится сталкиваться при распространении имиджевого MLLM на сферу существования.,Эти проблемы возникают в результате всесторонних экспериментов автора. затем,Автор предлагает соответствующие решения этих проблем.,Формирование общей структуры PLLaVA.
Failure Cases Analysis for Applying Image MLLMs
Авторы сначала исследовали метод непосредственной адаптации MLLM изображений (моделей многоязычного обучения) к видеообласти: отдельно кодировать выбранные видеокадры с помощью кодировщиков изображений и объединять эти функции кадров в качестве входных данных для MLLM изображений. Это сделано для того, чтобы воспользоваться способностью LLM (моделей большого языка) интерпретировать временную информацию в закодированных видеокадрах.
Авторы называют этот подход _n-frame_. В частности, для заданного набора последовательностей видеокадров.
, автор получает характеристики каждого кадра через визуальный кодер, предварительно обученный в модели CLIP-ViT [31], а характеристики закодированного кадра выражаются как
. Формула метода _n-frame_ выглядит следующим образом:
в
— это текстовый ввод, а r — выходной текст. Однако, пытаясь обучить MLLM таким образом, мы столкнулись с двумя проблемами, которые помешали нашим усилиям по созданию наиболее эффективной модели.
Первое наблюдение заключается в том, что модели, обученные с помощью n-кадров, могут быть очень чувствительны к шаблонам сигналов при выполнении задач генерации. Рисунок 3 иллюстрирует это явление. Авторы делят чаевые на две категории: распределяемые (IND) и внераспределенные (OOD). В левой части рисунка, когда модель сгенерирована в режиме подсказки (IND), используемом для обучения, по-прежнему генерирует достойное описание видео, хотя она имеет тенденцию генерировать более короткий текст при обучении на большем количестве образцов данных. Однако если автор подсказывает модель с подсказками ООД, то есть автор меняет метки только двух персонажей в разговоре, качество генерируемых ответов резко падает. В модели, обученной на 3750 шагов, длина сгенерированного контента является нормальной. А вот у модели, обученной на 7500 шагов, генерация становится короче, а на 11250 шагах она даже не реагирует. Этот пример демонстрирует хрупкость n-кадрового подхода.
ведущий Token . Ввиду упомянутой выше хрупкости n-кадровой модели автор продолжает анализировать изменения модели на раннем этапе обучения и после полного обучения. Визуализация в моделях, обученных на разных этапах обучения Token норме, автор заметил, что по мере увеличения количества обучающих выборок ведущий Token (с высокой нормой), как показано на гистограмме на рисунке 3. Кроме того, распределение башен-близнецов становится намного шире при обучении с использованием большего количества данных. Таким образом, автор предполагает, что эти ведущие Token Существует разумная корреляция между существованием и возможностью возникновения деградации под влиянием существованияOOD. Эта гипотеза будет дополнительно проверена в разделе 4.4 путем сравнения распределения PLLaVA _n-frame_ипредлагать.
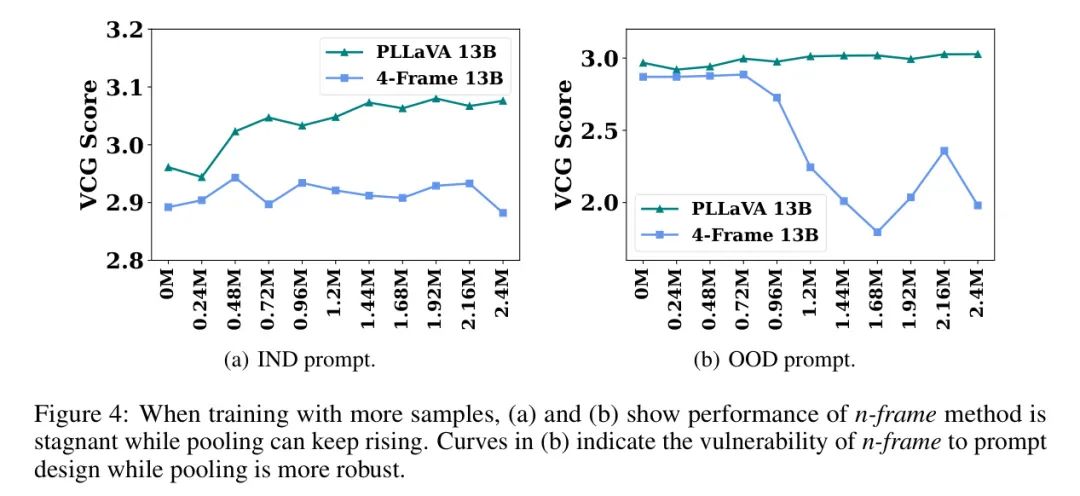
Основываясь на вышеупомянутых явлениях, можно сделать вывод, что использование MMLM изображений для видео и стремление получить выгоду от расширения выборок видеоданных может представлять собой сложную проблему. На рисунке 4 автор показывает кривую производительности метода n-кадров при различных обучающих выборках. Синяя кривая, представляющая тенденцию производительности _n-frame_, остается неизменной под приглашением IND, и после того, как обучающие выборки превысят 0,48M, производительность значительно падает под приглашением OOD. Аналогичная картина наблюдалась и в экспериментальных результатах Video-ChatGPT [30], как показано в таблице 1. Video-ChatGPT [30] представляет уникальную стратегию объединения, которая включает в себя усреднение визуальных характеристик во временном и пространственном измерениях и получение визуальных характеристик после сращивания.
. Затем эта функция передается в LLM для генерации соответствующих ответов. Первые два столбца таблицы 1 показывают репликацию авторов Video-ChatGPT с использованием их набора видеотекстовых данных из 100 000, а третий столбец показывает улучшение производительности модели после введения дополнительных образцов обучающих видеоданных VideoChat2 [18]. Значительное ухудшение. Поэтому определение стратегий для моделей, позволяющих эффективно использовать растущие объемы данных, остается критической проблемой.
Model Scaling Degradation
Таблица 1. Video-ChatGPT [30] не удается расширить данные.
Обзор современных видеомоделей, проведенный авторами, показал, что увеличение размера модели обычно не приводит к значительному улучшению производительности большинства моделей. Авторы отображают результаты недавней работы IG-VLM [14] и попытки авторов на рисунке 5. Разницы в IG-VLM при применении моделей LLaVA-Next 7B, 13B и 34B практически нет [25]. В случае, когда авторы пытались использовать объединенные функции (первый столбец на рисунке 5), LLaVA-Next 34B показала себя даже хуже, чем модель 13B LLaVA-Next. Для IG-VLM входные видеокадры объединяются в изображение сетки с ограниченным разрешением, что приводит к неоптимальным возможностям масштабирования. Что касается попыток авторов, они обнаружили, что по мере увеличения размера LLM в модели MLLM генерация имеет тенденцию быть короче. Таким образом, авторы связывают ухудшение с качеством пар данных видео-текст, что подрывает генеративную способность LLM в моделях MLLM.
PLLaVA
Мотивация: первоначальные попытки авторов использовать n-frame и VideoChatGPT [30] выявили сложность адаптации ориентированных на изображения моделей многоязычного обучения (MLLM) к видеообласти и столкнулись с проблемами масштабирования данных. Первый вводит небольшое количество кадров из-за ограничений памяти, а второй сжимает информацию более 100 кадров с помощью стратегии объединения. Однако оба случая дали схожие результаты.
Учитывая необходимость временной информации и непомерно высокую стоимость обработки очень длинных видеовходов для MLLM, объединение в пул является интуитивно понятным и простым способом удовлетворения обоих требований. Две вышеупомянутые проблемы могут возникать из-за недостаточной информации о кадре и неправильной обработки характеристик кадра. Поэтому в этой статье авторы углубляются в стратегии объединения видеофункций в MLLM.
Определение: Автор формализует процесс объединения функций видео следующим образом, а структура модели показана на рисунке 6. При конвертации видеокадров
После ввода данных в модель CLIP-ViT и мультимодальный проектор авторы получили функцию кодированного видео.
для видеовхода. Затем эта функция была передана через модуль адаптивного пула структур без параметров и уменьшена до меньшего размера. Учитывая желаемые размеры объекта
, процесс формулируется как:
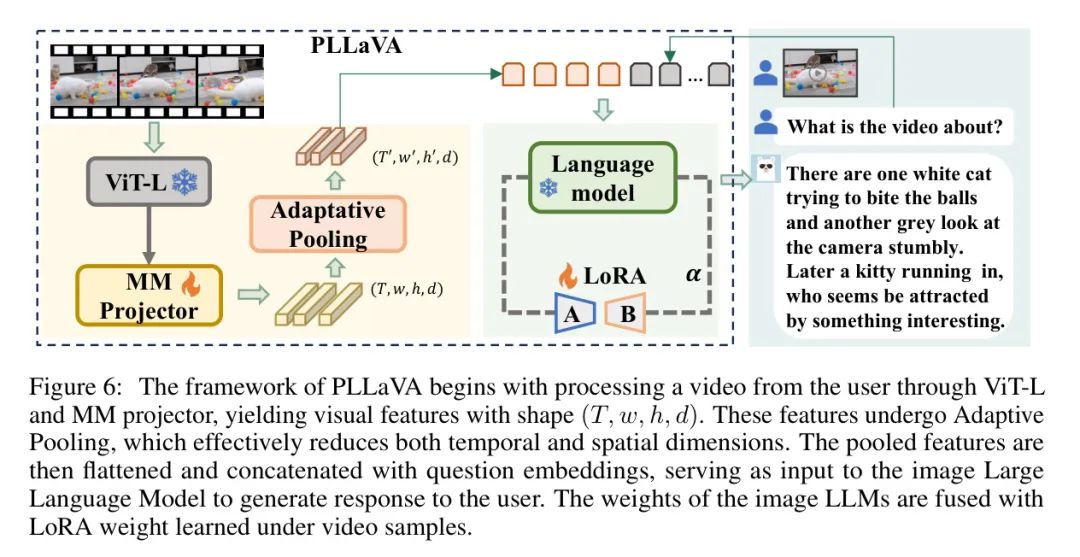
Эти функции затем встраиваются в ConCat с помощью текстового ввода и передаются в LLM для генерации ответов. Авторы также включают модуль LoRA [9] для адаптации LLM к задачам генерации видео. Таким образом, веса, которые будут обновлены, — это мультимодальный проектор и LLM LoRA.
существовать в этих рамках,Авторы изучили влияние объединения с помощью анализа поиска по сетке. Выводы авторов указывают на,Объединение в пространственном измерении может дать благоприятные результаты.,Объединение во временном измерении связано со снижением производительности. Тщательно изучить процесс поиска авторов и обоснование этого вывода.,Пожалуйста, дайте ссылку на раздел 4.2.
Post Optimization
О падении производительности, связанном с расширением Модели,Эта деградация может быть связана с потерей владения языком, вызванной обучением на образцах видеотекстовых данных низкого качества. Чтобы облегчить эту проблему,Автор предлагает метод оптимизации параметров видеоMLLM после обучения. Метод включает в себя объединение языка Модели (LLM), обученного на существующих видеоданных, с исходным LLM базового изображения MLLM. За наличие параметров LLM
Предварительно обученный MLLM и заданные входные данные
, выходное скрытое состояние LLM, настроенное LoRA, можно получить следующим образом:
в
используется для адаптации
Обучаемые низкоранговые параметры
Используется для масштабирования изученных весов низкого ранга.
В процессе оптимизации после обучения автор меняет
Значение для корректировки соотношения смешивания между исходным LLM и обученным LLM (включая веса LoRA). Опыты автора показывают, что ниже
значение может значительно улучшить производительность сборки.
4 Experiments
Часть 4. Эксперимент начинается
Experiment Setting
Данные и оценка. Авторы используют обучающий набор данных для преобразования видео в текст, чтобы расширить возможности MLM изображений для обработки видеовхода. Данные для обучения поступают из набора данных VideoChat2 [18], который содержит данные для различных задач по распознаванию видео, включая 27 тысяч данных для диалога, комбинацию VideoChat [17] и Video-ChatGPT [30], а также 80 000 классификационных данных из Kinetics[ 13] и ShthSthV2[6], приходят данные о 450 000 заголовках. Начиная с Webvid [2], YouCook2 [47], TextVR [37] и VideoChat, 11,7 тыс. данных вывода от NextQA [38] и CLEVRER [42] и 109 тыс. данных вопросов и ответов от Webvid, TGIF [20] и Ego4D [7]. ], в общей сложности 783 000 данных обучающей настройки.
Для оценки нашей обученной модели мы используем следующий тест преобразования видео в текст. Во-первых, открытый ответ на видеовопрос (Video QA) включает MSVD-QA[39], MSRVTT-QA[39], ActivityQA[43] и TGIF QA[20]. Ответы в этих тестах «вопрос-ответ» обычно состоят из отдельных слов. Авторы использовали GPT-3.5 для оценки точности (точность, ответ «верно/неверно») и качества (оценка от 0 до 5) ответов модели. Кроме того, авторы также используют тест производительности генерации видео (так называемый показатель VCG), представленный VideoChatGPT [30].
Эти тесты обычно включают более длинные ответы и охватывают пять аспектов понимания видео: правильность информации (CI), ориентацию на детали (DO), контекстное понимание (CU), временное понимание (TU) и последовательность (CO). Часть генерации также оценивается с использованием модели GPT-3.5. Кроме того, авторы использовали тест ответов на вопросы с множественным выбором MVBench [18], который включает 20 задач, требующих детального временного понимания видео. Этот тест не обязательно должен оцениваться с помощью модели GPT-3.5.
Детали модели и реализации PLLaVA основан на образах MLLM, LLaVA Next [26, 25] модели 7B, 13B и 34B. Авторы используют предварительно обученные веса, которые они предоставляют в библиотеке Hugging Face1, и интегрируют модуль адаптивного пула, чтобы уменьшить размерность признаков перед передачей входных визуальных признаков в компонент генерации LLM. Для слоя объединения автор равномерно выбирает 16 кадров в качестве входных данных и устанавливает целевую форму объединения на
,в
Соответствует входному размеру LLM. Во время обучения авторы использовали размер пакета 128 и скорость обучения 2e-5, используя косинусный планировщик и коэффициент прогрева 0,03. Все сообщаемые результаты относятся к моделям, оцененным после обучения на 6250 шагов. Для оценки авторы используют модель GPT-3.5-turbo-0125 на всех тестах. ### Влияние проектирования операций объединения
Учитывая низкую производительность полного объединения во временных и пространственных измерениях, принятого в Video-ChatGPT, а также ограниченность информации в прямом подходе с n-кадрами, мы дополнительно исследуем влияние стратегии объединения здесь.
Объединение дизайнов слоев Объединение может выполняться как во времени, так и в пространстве. В этом разделе авторы стремятся найти ответы на два вопроса:
- Какое измерение больше подходит для объединения, чтобы сэкономить вычислительные затраты;
- Какова максимальная степень сжатия по этому измерению? Для этого автор использует LLaVA-1.5, управляемый операциями объединения на основе различных временных и пространственных измерений. 7BМодель рисует модельную кривую.
В частности, для пространственного измерения авторы выбирают измерение с формой (4, 24, 24,
) функции ввода видео,в4 — количество кадров (временное измерение),24×24 — исходный пространственный размер объекта кадра.,
— это измерение внедрения каждого визуального токена. Целевые пространственные формы выбираются через равные интервалы от 1 до 24, в результате чего получается набор пространственных форм.
{
}. Показатели MVBench и VCG Score для этих форм пространственного пула показаны на рисунках 7(a) и 7(b) соответственно. Было замечено, что уменьшение пространственной размерности на 50% не снижает производительность модели. Дальнейшее уменьшение пространственных размеров приводит к значительному снижению производительности. Учитывая компромисс между вычислительными затратами и производительностью, в качестве целевого размера пространства можно использовать 12 × 12.
Далее автор проводит эксперименты во временном измерении. При фиксированном пространственном измерении, равном 12, выбираются несколько форм целевого пула, включая (4,12,12), (8,12,12) и (16,12,12). Авторы изучают тенденции производительности пулинга при изменении количества входных видеокадров, что демонстрирует скорость субдискретизации пула. Например, объединение от (64,24,24) до (4,12,12) означает объединение каждых 16 кадров, тогда уровень понижающей дискретизации должен составлять 6,25%. Все сгенерированные модельные кривые показаны на рисунках 7(c) и 7(d). В отличие от пространственного объединения, производительность модели чувствительна к временному объединению. Как показано на рисунках 7(c) и 7(d), все линии работают лучше при более низких скоростях понижающей дискретизации. Другими словами, объединение по временному измерению всегда будет ухудшать производительность модели.
Авторы обнаружили, что объединение большего количества видеокадров не только повысило эффективность модели, но и сделало ее более удобной для пользователя. Query более надежный。существовать В авторском эксперименте,Авторы оценивали существование при различных итерациях обучения, используя два набора сигналов. Например,существуют в процессе оценки,Автор изменил ярлык персонажа с «ПОЛЬЗОВАТЕЛЬ» на «Человек».,Результаты показаны на рисунке 3. На рисунке показано,По сравнению с 4-кадровым методом отображения ведущего токена,Спецификации визуальных функций, полученные с помощью операций объединения, демонстрируют последовательное распределение по различным итерациям обучения. Это также отражено в ответе существующей Модели.,Метод объединения дает стабильно хороший текстовый ответ,По мере обучения метод 4 кадров,Текстовые ответы становятся все короче и короче,Даже существуют не реагирует при использовании подсказок вне дистрибутива. Этот вывод можно дополнительно подтвердить с помощью рисунка 2. После введения пула,Независимо от того, какие советы вы используете,Или сколько обучающих выборок было изучено,Длина генерации текста методом объединения является постоянной. Стабильность генерации автор связывает со сглаживающей способностью пула.,Это устраняет влияние токенов высокого стандарта. Более строгий анализ с точки зрения математического доказательства.,Авторы оставляют это на будущее.
Qualitative Results
В таблице 2 показаны результаты выполнения задачи с ответами на видеовопросы. PLLaVA 34B значительно превосходит все существующие методы по точности и показателям оценки MSVD, MSRVTT, ActivityNet и TGIF. По сравнению с GPT-4V, PLLaVA 34B демонстрирует улучшение на 3,6, 4,9, 3,9 и 15,3 балла по этим четырем тестам соответственно. PLLaVA с размерами моделей 7B и 13B также превосходит все базовые показатели по показателям оценки. Эти результаты не только демонстрируют способность нашей модели отвечать на видеовопросы, но также подчеркивают преимущества нашей стратегии объединения при масштабировании модели.
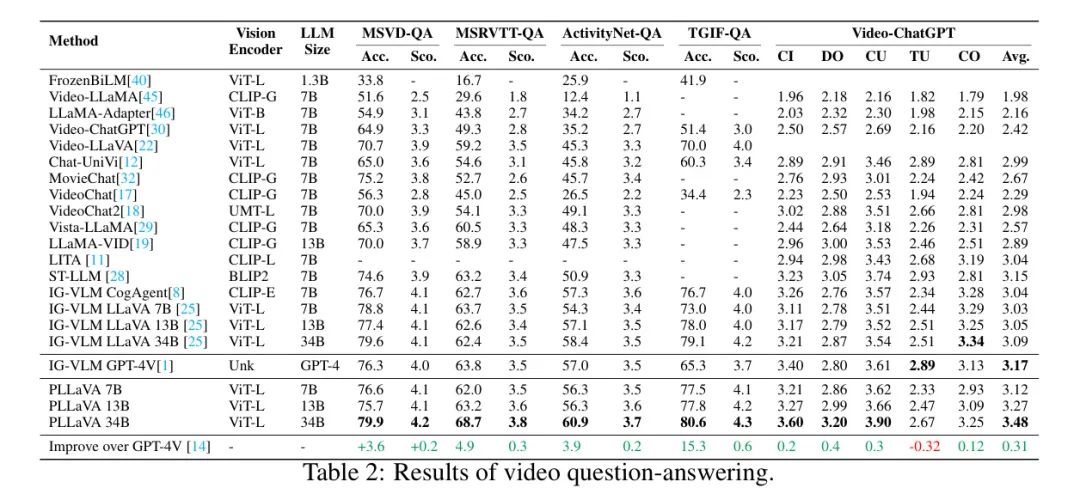
PLLaVA также демонстрирует самые современные показатели по среднему баллу VCG. Версии 7B, 13B и 34B показали хорошие результаты против лучших противников того же размера LLM, улучшившись на 2,9%, 7,1% и 12,6% соответственно. Стоит отметить, что по сравнению с предыдущим SOTA, PLLaVA показал лучшие результаты в CI (правильность информации), DO (ориентация деталей) и CU (понимание контекста), при этом версия 34B превысила 5,8%, 6,7% и CU 9,2% соответственно. . Эти результаты показывают, что PLLaVA имеет большой потенциал для создания подробных субтитров к видео. Что касается TU (временного понимания), PLLaVA 34B на 6% лучше, чем его честный конкурент IG-VLM LLaVA 34B. По сравнению с теми моделями, которые используют специализированный видеокодер VideoChat2 или более сложный метод комбинирования кадров Chat-Univ, PLLaVA все еще имеет возможности для улучшения за счет улучшения стратегии объединения или включения более совершенных визуальных кодировщиков. CO (согласованность) измеряет, насколько последовательно генерируется модель при столкновении с различными вопросами, которые приводят к схожим ответам. По сравнению с базовой версией, за исключением IG-VLM, модель автора работает лучше с точки зрения согласованности.
MVBench — это комплексный тест понимания видео, который фокусируется на проблемах, требующих общего понимания нескольких кадров. Как показано в таблице 3, средняя производительность PLLaVA на 20 задачах превысила предыдущий SOTA VideoChat2 на 13,7%. Если мы углубимся в каждый аспект MVBench, наш метод очень хорошо справится с 17 задачами, что указывает на то, что наша модель имеет преимущества в точном понимании многих мелких деталей видео. Однако авторы также отмечают, что некоторые аспекты авторской модели все еще нуждаются в доработке, например, CI (Контрфактический вывод) и OS (Objective Shuffle). CI используется для прогнозирования того, что может произойти, если произойдет определенное событие, а OS используется для определения конечного положения цели в игре с окклюзией. Эти два аспекта требуют сильных рассуждений и воображения для ответа. VideoChat2 использует специализированный видеокодер, который предварительно обучается на крупномасштабных видеоданных и настраивается с использованием данных вывода видео и изображений, поэтому он работает лучше в этих аспектах. ### анализировать

Авторская PLLaVA представляет собой простой и эффективный по параметрам метод адаптации MLLM изображений к видеообласти. Авторы также предлагают возможный метод масштабирования модели, которого, по их мнению, трудно достичь с помощью других методов, таких как ChatUniv [12] и IG-VLM [14]. Ниже автор приводит некоторые объяснения формы пула и анализ ее влияния на веса LoRA для различных задач.
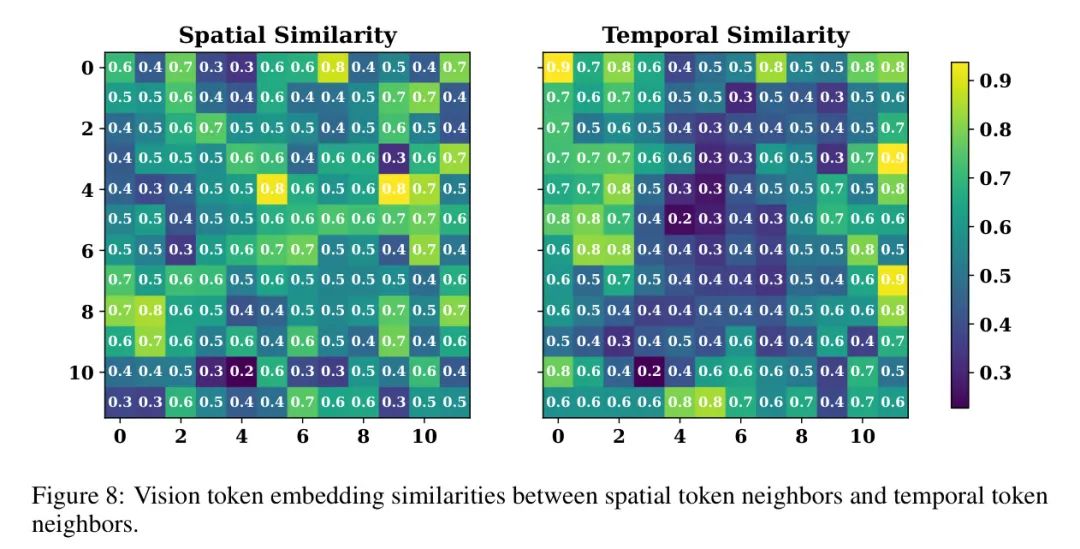
Временное или пространственное объединение? В разделе 4.2 авторы иллюстрируют влияние временного и пространственного объединения, делая вывод, что объединение по временному измерению постоянно приводит к снижению производительности по сравнению с сохранением исходного количества кадров. Авторы объяснили это явление вмешательством в характеристики маркеров. В MLLM изображений функции извлекаются из кадров изображения/видео с помощью модели CLiP-ViT, которая генерирует встроенный патч для каждого кадра изображения/видео, в результате чего получается форма
характеристики видео. Объединение изменено
(время),
(высота) и
(ширина) размер. С локальным объединением по пространственным измерениям (локальное объединение по одному изображению/кадру, изменение
и
) по сравнению с объединением по временному измерению (изменение
) может изменить исходные характеристики кадра. Чтобы проверить эту гипотезу, автор на рисунке 8 визуализирует сходство между пространственными и временными помеченными соседями для видеообъекта. Два подрисунка показывают, что сходство между пространственными соседями значительно выше, чем сходство между временными соседями. Это наблюдение подтверждает потенциальную возможность того, что временное объединение может привести к искажению исходных обозначенных признаков.
Модели LLM предназначены для понимания последовательностей. Они способны моделировать временные отношения даже без предварительной обработки агрегирования временной информации.
изображение? видео? Или оба? Оптимизация после обучения определяется как объединение параметров LLM изображения MLLM с весами LoRA LLM, полученными из образцов видео. Соответствующий коэффициент слияния может быть очень эффективным для повышения производительности моделей, обученных на образцах видеотекста низкого качества. Здесь авторы обсуждают влияние различных вариантов соотношения слияния на качество понимания. Как показано на рисунке 9, ось X представляет значение альфа LoRA. \begin{таблица}
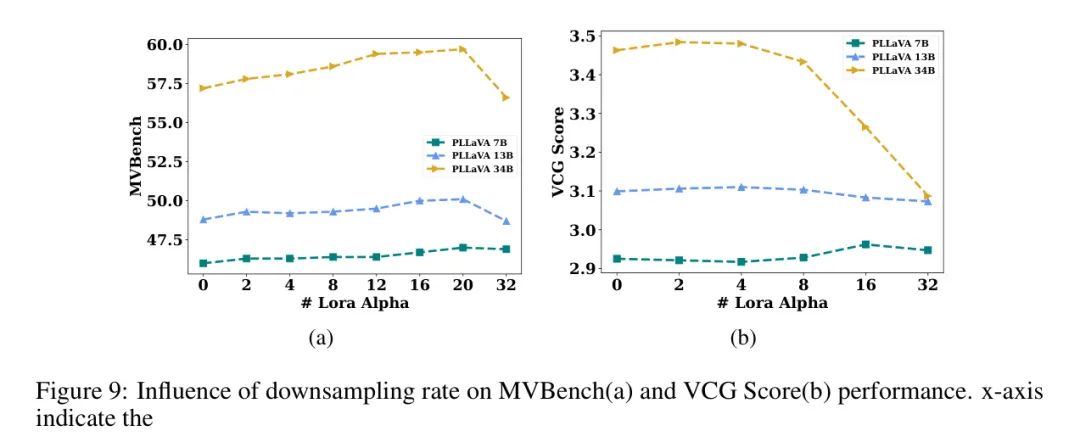
также,Из этих двух графиков видно,Сочетание соотношения веса видео и изображения с экстремальными значениями 0и32 может повысить производительность.
Case Studies
В дополнение к этим количественным результатам авторы также качественно изучили возможности понимания видео модели PLLaVA. Автор показывает несколько примеров заголовков на рисунке 10. Судя по видео, по сравнению с ИГ-ВЛМ, ПЛЛа ВА 34Bверновидео Идентификация более подробная,Включая одежду и окружающую среду, которую носит главный герой.,Даже некоторые слова в видео. также,Как показано на рисунке 10(b).,PLLaVA может лучше понимать содержание видео и более правильно,ВЛюди существуют, играя в бадминтон, а не в волейбол. Эти ошибки, допущенные IG-VLM, могут быть связаны с пониженным разрешением при сшивке кадров в сетку при разработке метода существования. Объединение выполняется после окончания кодирования кадра для уменьшения размерности.,Это приводит к меньшим потерям информации.

Dense Recaption
Учитывая возможности PLLaVA по созданию субтитров, авторы дополнительно протестировали его задачу приема и предоставили набор данных субтитров Inter4K [33], содержащий видео размером 1K. Пример показан на рисунке 11. По сравнению с конвейером Open-Sora GPT-4 наша модель лучше передает детали субтитров и выделяет информацию о движении в видео, что указывает на то, что PLLaVA может внести свой вклад в сообщество по созданию видео.

ссылка
[1].PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
