Шокирующий дебют межъязыкового «синхронного перевода с использованием искусственного интеллекта»! Meta и Google последовательно совершают крупные прорывы, подрывая голосовой перевод

Редактор: Так хочется спать
【Шин Джиген Введение】MetaGoogle публикует важные результаты один за другим!MetaБесшовная коммуникация с открытым исходным кодомголоспереводить Модель,Google выпускает Translation 3 — крупный прорыв в области неконтролируемой голосовой передачи.
По случаю 10-летия Meta AI исследовательская группа представила прорыв в области перевода речи — модель «Бесшовного общения».

Будучи первой «унифицированной моделью» с открытым исходным кодом, Seamless объединяет все функции трех других моделей SOTA (SeamlessExpressive, SeamlessStreaming и SeamlessM4T v2), обеспечивая более естественное и реалистичное межъязыковое общение в реальном времени.
Можно даже сказать, что он по сути реализует концепцию универсального переводчика речи.
Сразу после этого Google также поделился своим прорывом в области автоматического перевода речи — Translation 3.
Используя SpecAugment, встраивание MUSE и обратный перевод, Translatotron 3 может лучше обрабатывать нетекстовые нюансы речи, такие как паузы, скорость речи, личность говорящего и т. д., при переводе словарного запаса.
Мало того, Translatotron 3 также может учиться непосредственно на одноязычных данных, избавляясь от зависимости от параллельных данных.

Адрес статьи: https://arxiv.org/abs/2305.17547.
Результаты показывают, что Translation 3 превосходит традиционные системы с точки зрения качества перевода, сходства говорящих и естественности речи.
Исследуя будущее коммуникации, Транслатотрон 3 может преодолевать языковые барьеры с беспрецедентной эффективностью и точностью.
Бесшовный: унифицированный «бесшовный» голосовой перевод
Seamless объединяет высокое качество и многоязычность SeamlessM4T v2, низкую задержку SeamlessStreaming и согласованность выражений SeamlessExpressive в единую систему.
В результате Seamless также является первой моделью потокового перевода, которая может одновременно сохранять стиль голоса и интонацию.
SeamlessExpressive: идеальное сохранение интонации голоса
Хотя существующие инструменты перевода хорошо справляются с записью разговорного контента, их результат часто зависит от монотонных роботизированных систем преобразования текста в речь.
Напротив, SeamlessExpressive сохраняет нюансы речи, такие как паузы и скорость речи, а также стиль голоса и эмоциональный тон.
Чтобы сохранить стиль голосов говорящего на разных языках, исследователи разработали новые подход в базе SeamlessM4T.v2 Модель добавила выразительности кодер. Этот процесс гарантирует, что генерация единиц соответствует ожидаемой скорости и ритму речи.
Кроме того, замена модульного вокодера HiFi-GAN в SeamlessM4T v2 на выразительный генератор преобразования единиц в речь, зависящий от исходной речи, обеспечивает плавную передачу тона, эмоций и стиля.
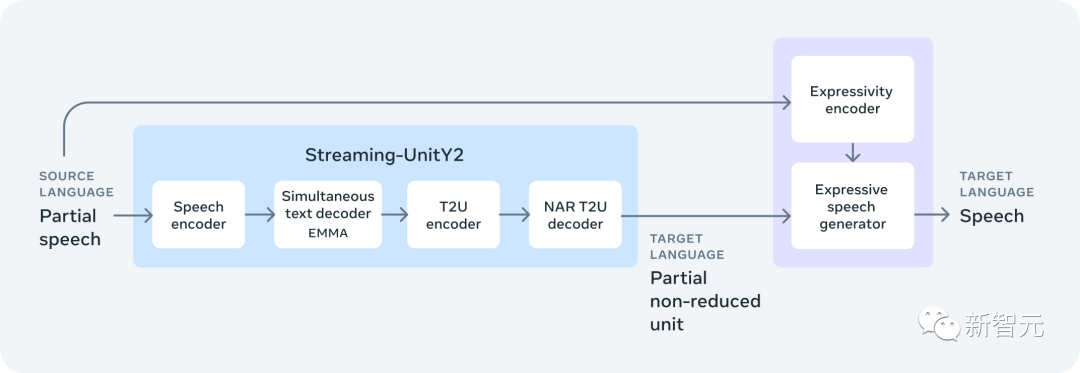
SeamlessStreaming: ИИ-версия «синхронного перевода»
SeamlessStreaming — это первая крупномасштабная многоязычная модель с задержкой перевода около двух секунд и почти такой же точностью, как и у офлайн-моделей.
SeamlessStreaming основан на SeamlessM4T v2 и поддерживает автоматическое распознавание речи и перевод речи в текст почти для 100 языков ввода и вывода, а также перевод речи в речь почти для 100 языков ввода и 36 языков вывода.
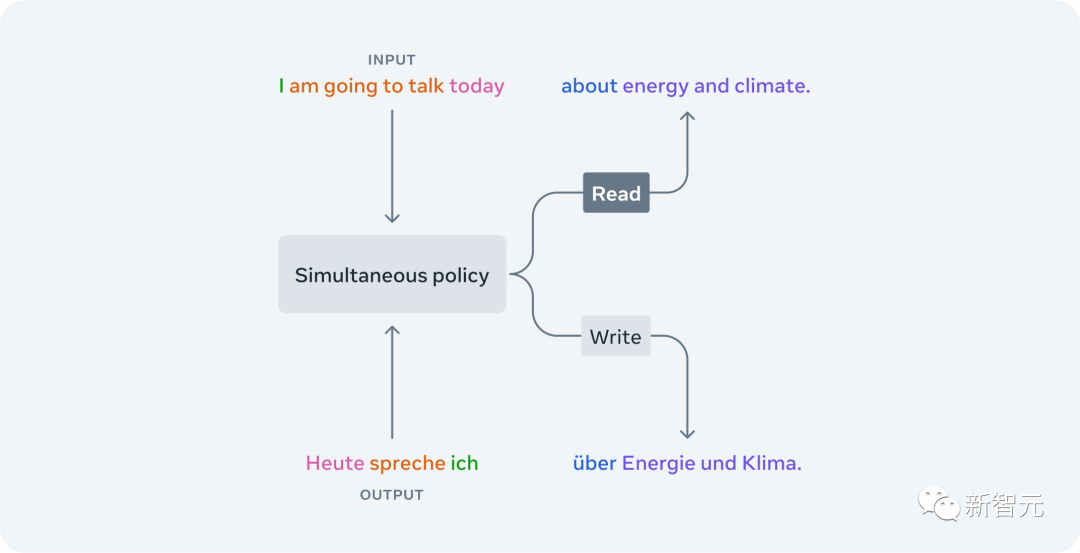
Самая продвинутая модель потоковой передачи Meta AI, SeamlessStreaming, интеллектуально решает, когда достаточно контекста для вывода следующего целевого текстового или речевого сегмента.
Стратегии чтения/записи, изученные с помощью SeamlessStreaming,Он решит, стоит ли «записывать» и сгенерирует вывод на основе части входного звука.,Или «читать» и продолжать ждать дальнейшего вхождения. и,Вы также можете адаптировать структуру к разным языкам.,Таким образом, мы повышаем производительность во многих разных языковых парах.
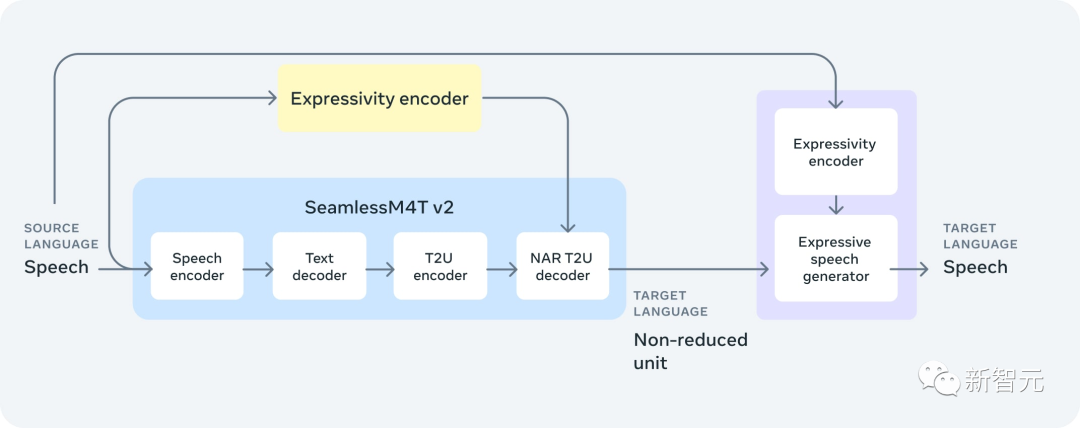
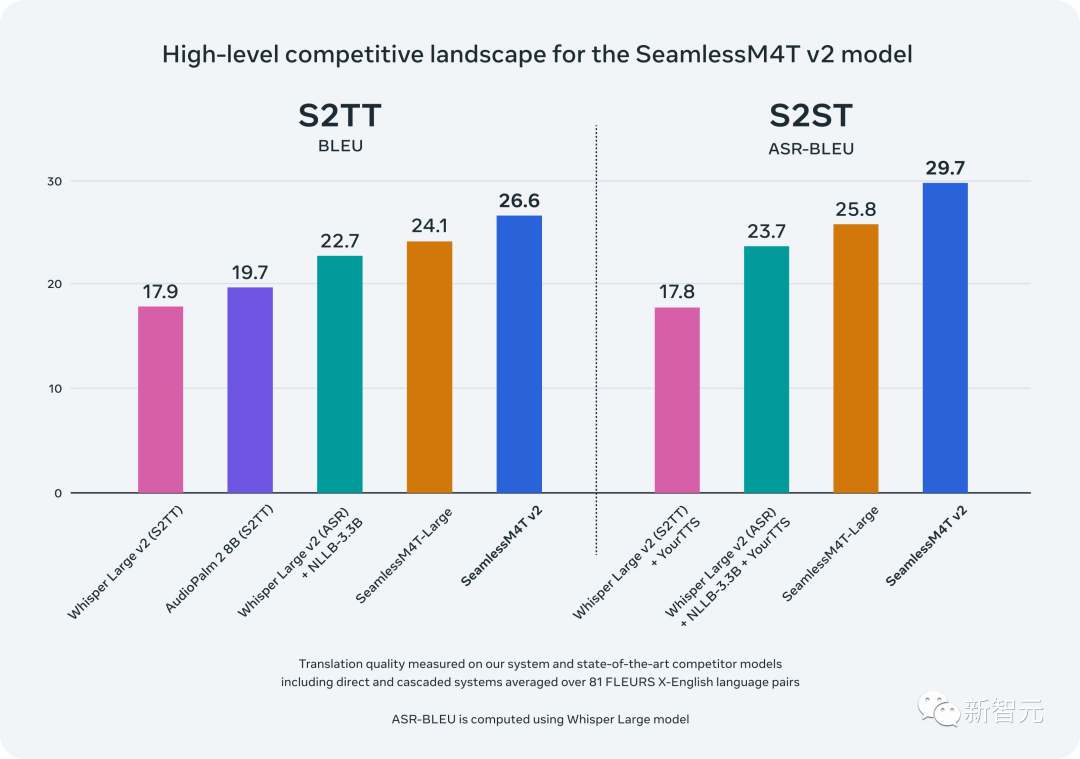
SeamlessM4T v2: выше качество, выше точность
В августе 2023 года Meta AI выпустила первую версию SeamlessM4T — базовую многоязычную и многозадачную модель, которая предоставляет результаты SOTA для перевода и транскрипции речи и текста.
Исходя из этого, в ноябре исследователи выпустили улучшенную версию SeamlessM4T v2 в качестве основы для новых моделей SeamlessExpressive и SeamlessStreaming.
Обновленный бесшовный M4T v2 использует неавторегрессионный декодер преобразования текста в единицы, тем самым улучшая согласованность вывода текста и голоса.
Среди них w2v-BERT 2.0кодер основан на 4,5 миллионах часов голосовыхтренироваться. По сравнению с предыдущей версией, первая версия тренированных имела всего 1 миллион часов.
Кроме того, SeamlessM4T v2 также добавляет больше данных для языков с низким уровнем ресурсов с помощью нового SeamlessAlign.
Результаты оценки показывают, что производительность SeamlessM4T v2 при выполнении таких задач, как BLEU, ASR-BLEU и BLASER 2, значительно выше, чем у предыдущей модели SOTA.
SeamlessAlignExpressive
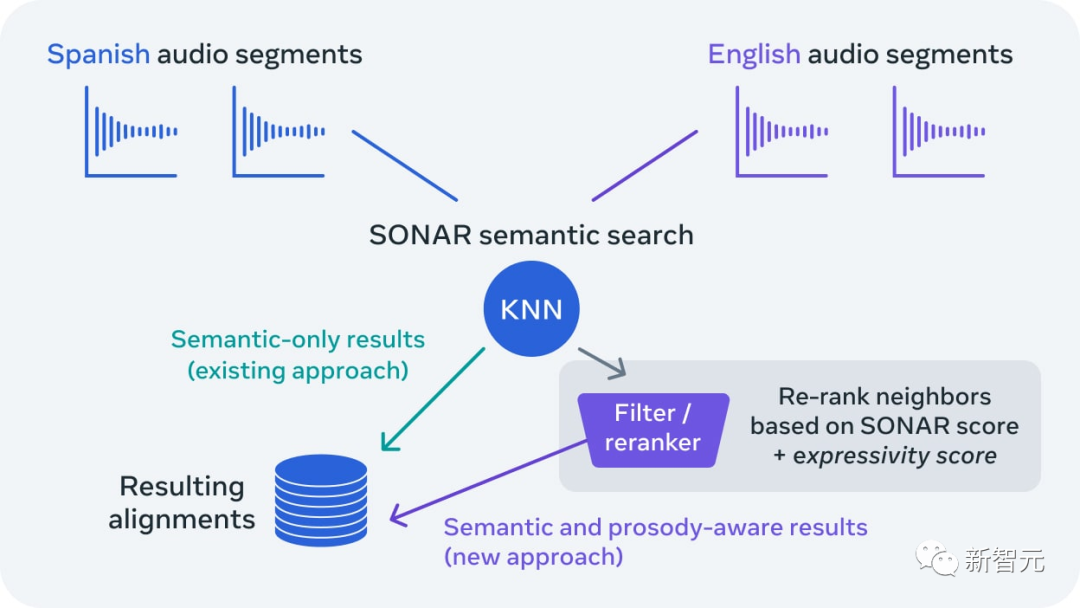
Опираясь на предыдущую работу над WikiMatrix, CCMatrix, NLLB, SpeechMatrix и SeamlessM4T, Meta AI запускает SeamlessExpressive, первую программу выравнивания речи.
На основе необработанных данных программа выразительного выравнивания автоматически обнаруживает пары аудиоклипов, которые не только имеют одинаковое значение, но и имеют одинаковую общую выразительность.
Основываясь на этом, Meta также создала первый крупномасштабный набор эталонных данных для тестирования выравнивания многоязычного звука — SeamlessAlignExpressive.
Транслатотрон 3: возглавляем новую эру перевода речи без присмотра
Архитектура перевода речи в речь без учителя Translatotron 3, предложенная Google и DeepMind, не только открывает двери для перевода между большим количеством языковых пар, но также открывает двери для перевода нетекстовых речевых атрибутов, таких как паузы, скорость речи и личность говорящего. .
Этот метод не требует прямого контроля целевого языка и позволяет сохранить другие характеристики исходной речи (например, интонацию, эмоции и т. д.) в процессе перевода.
Транслатотрон 3 не требует какого-либо непосредственного контроля целевого языка при сохранении других особенностей исходной речи (таких как интонация, эмоция и т. д.), а также
Отказ от необходимости использовать двуязычные речевые наборы данных.
Его конструкция включает в себя три ключевых аспекта:
1. Используйте SpecAugment для автоматического предварительного птренирования всей Модели в виде маски.
SpecAugment — это простой метод улучшения данных идентификации голоса.,Работает на логарифмической спектрограмме звука вхождения (а не на самом исходном звуке).,Тем самым эффективно улучшая способность кодера к обобщению.
2. Неконтролируемое встраивание на основе MUSE.
Многоязычное неконтролируемое внедрение выполняется на непарных языках, что позволяет Модели изучить пространство внедрения, общее для исходного и целевого языков.
3. Потери при реконструкции на основе обратного перевода
Этот метод можно использовать совершенно без присмотра для тренироватьсякодер-декодерS2STМодель.
Отображение эффектов (испанский-английский)
входить
Синтез ТТС
Translatotron 3
структура
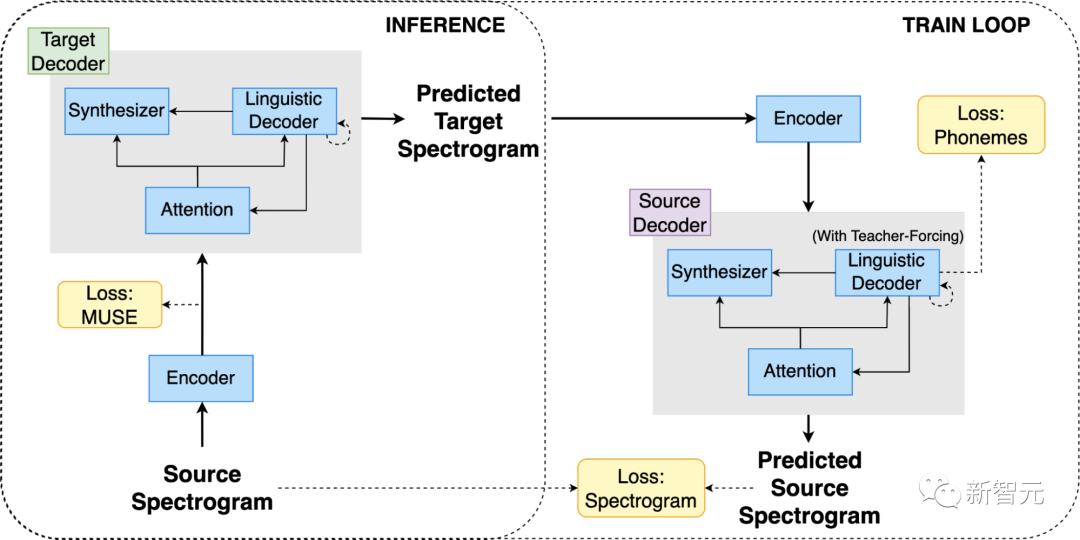
Translatotron 3 использует общий кодировщик для кодирования исходного и целевого языков. Среди них декодер состоит из декодера языка, синтезатора голоса (отвечающего за генерацию звука перевода голоса) и одного модуля внимания.
По сравнению с Транслатотроном предыдущего поколения 2,Транслатотрон 3 оснащен двумя декодерами.,один для исходного языка,Другой — для целевого языка.
В процессе тренироваться исследователи использовали одноязычные наборы голосово-текстовых данных (эти данные состоят из пар голос-текст; перевод не производился).
кодер
Вывод кодера разделен на две части: первая часть содержит семантическую информацию, а вторая часть содержит акустическую информацию.
Среди них первая половина вывода тренироваться во встраивание текста спектрограммы в MUSE. Вторая половина обновляется без потери MUSE.
Стоит отметить, что исходный и целевой языки используют один и тот же кодер.
Благодаря многоязычному характеру вложений MUSE кодер может изучать многоязычное пространство встраивания исходного и целевого языков.
Таким образом,кодер может кодировать голос на обоих языках в общее пространство встраивания,Вместо того, чтобы сохранять отдельное пространство для встраивания для каждого языка,Таким образом, кодирование вхождения становится более эффективным и действенным.
декодер
декодер состоит из трех разных частей, а именно декодера языка, синтезатора голоса и модуля внимания.
Транслатотрон 3 оснащен двумя независимыми декодерами: для исходного языка и целевого языка.
тренироваться
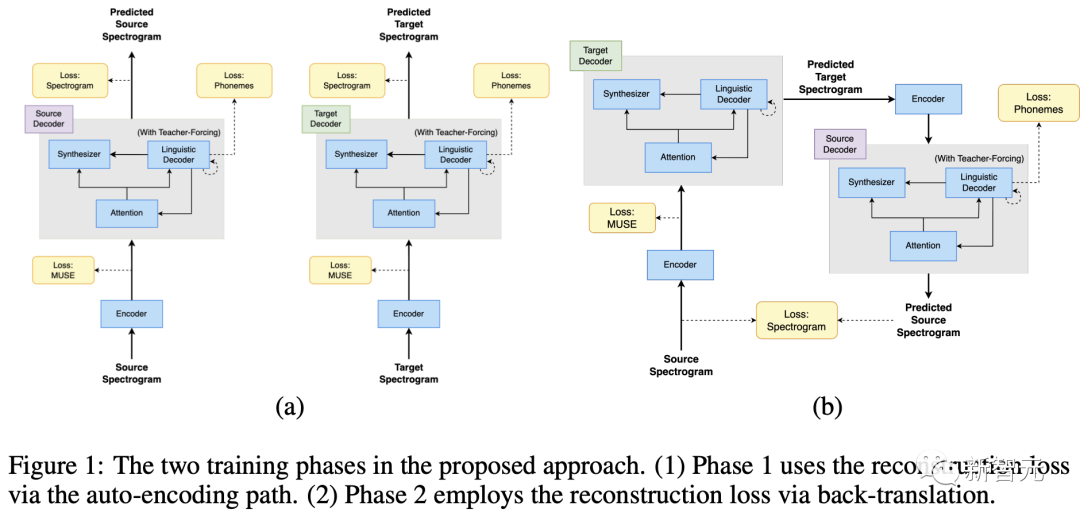
тренироваться состоит из двух этапов: (1) автоматического кодирования и реконструкции (2) обратного перевода;
На первом этапе,тренироваться, используя потери MUSE и потери реконструкции в сети,тем самым автоматически кодируя содержимое входа в многоязычное пространство для встраивания.,Убедитесь, что сеть генерирует значимые многоязычные представления.
на втором этапе,Далее тренироваться в сети переводитьвходить по спектрограмме с использованием обратного перевода потерь. Чтобы облегчить проблему катастрофического забывания,и убедитесь, что скрытое пространство является многоязычным,На этом этапе все еще используются потери MUSE и потери реконструкции.
Чтобы гарантировать, что кодер усвоит значимые свойства вхождения.,Вместо простого рефакторинга входить,Исследователи применили SpecAugment для кодервхождения на обоих этапах. Оказывается,путем улучшениявходитьданные,Это может эффективно улучшить способность кодера к обобщению.
- Потери MUSE: Потери MUSE измеряют сходство между многоязычным внедрением спектрограммы вхождения и многоязычным внедрением спектрограммы обратного перевода. - Потери на реконструкцию: Потери при реконструкции измеряют сходство между спектрограммой вхождения и спектрограммой обратного перевода.
производительность
В оценку включен набор данных Common Voice 11, а также два синтетических набора данных, полученных на основе наборов данных Conversation и Common Voice 11.
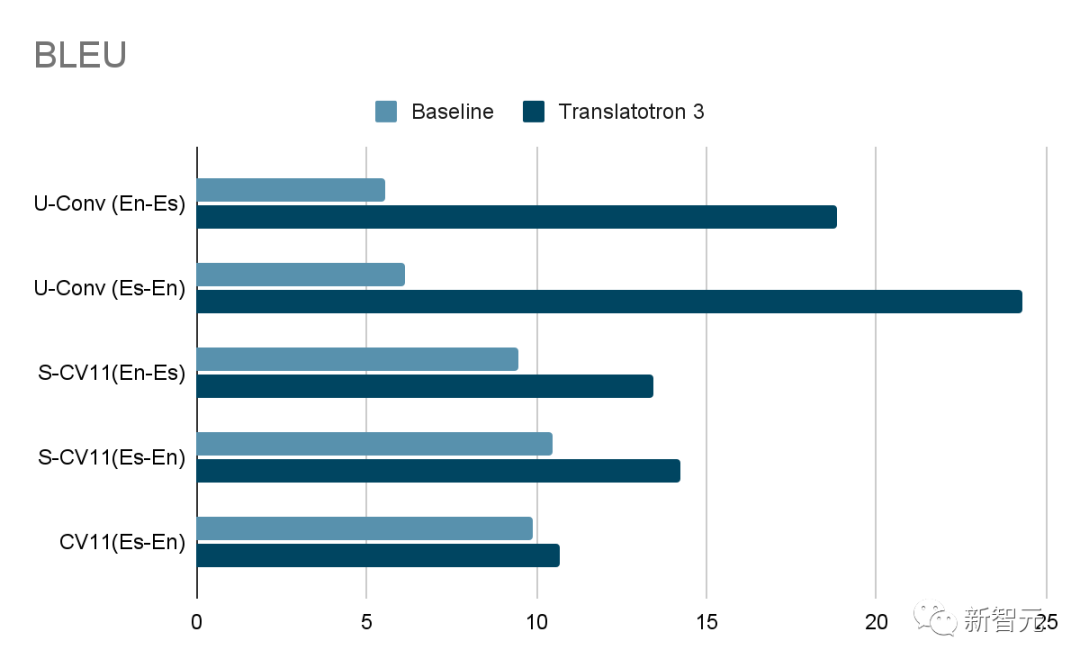
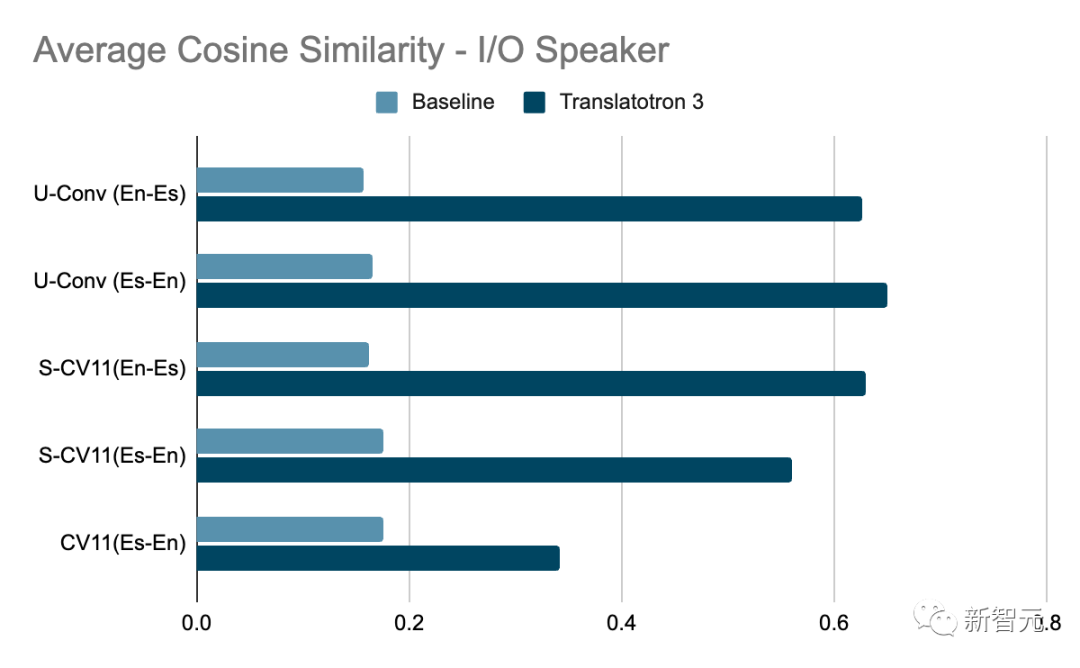
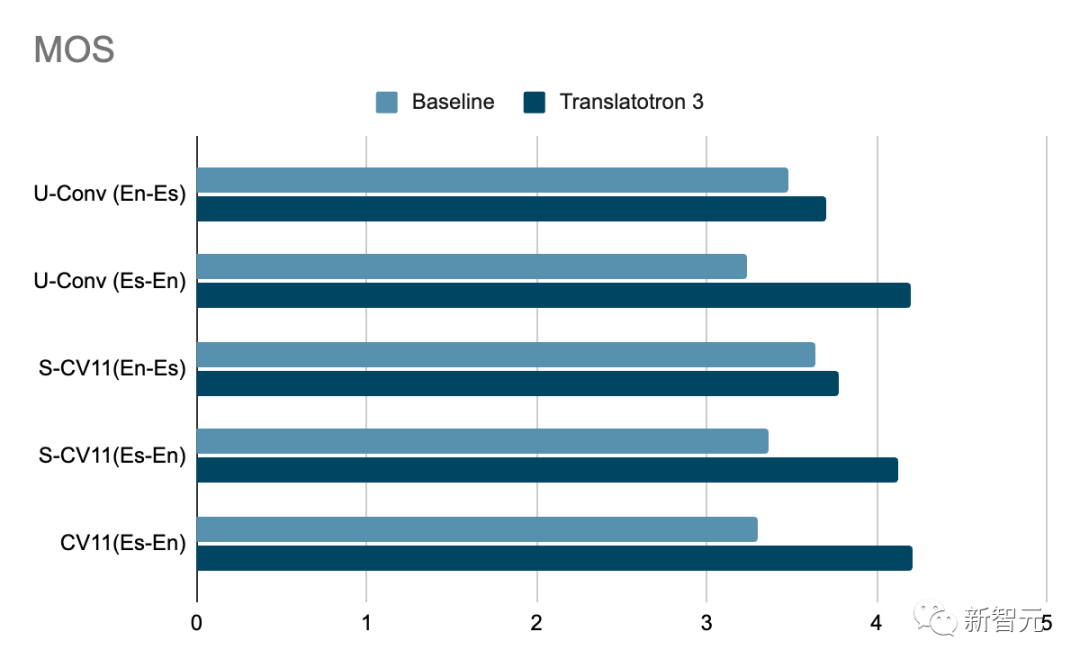
Среди них качество перевода измеряется путем сравнения BLEU (чем выше, тем лучше) транскрипции ASR (автоматического распознавания речи) переведенной речи с соответствующим эталонным переведенным текстом. Качество голоса измеряется показателем MOS (чем выше, тем лучше). Кроме того, сходство говорящих измеряется средним косинусным сходством (чем выше, тем лучше).
Поскольку Translatotron 3 является неконтролируемым методом, в качестве базовой линии исследователи использовали каскадную систему S2ST, состоящую из ASR, неконтролируемого машинного перевода (UMT) и TTS (преобразования текста в речь).
Результаты показывают, что Translatotron 3 работает намного лучше, чем базовый вариант, по всем аспектам, таким как качество перевода, сходство говорящих и качество речи, а его производительность особенно выдающаяся в разговорном корпусе.
Кроме того, Translatotron 3 обеспечивает естественность речи, аналогичную естественности реальных аудиосэмплов (измеряется в MOS, чем выше, тем лучше).
Ссылки:
https://ai.meta.com/research/seamless-communication/
https://blog.research.google/2023/12/unsupervised-speech-to-speech.html




Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
