Сходства: набор инструментов для точного расчета сходства и поиска семантического соответствия, реализация нескольких алгоритмов в нескольких измерениях, охватывающих текст, изображения и другие поля, поддержка текстового поиска, поиска изображений, поиска текста, поиска изображений и поиска соответствия изображений.
Сходства: набор инструментов для точного расчета сходства и поиска семантического соответствия, реализация нескольких алгоритмов в нескольких измерениях, охватывающих текст, изображения и другие поля, поддержка текстового поиска, поиска изображений, поиска текста, поиска изображений и поиска соответствия изображений.
Сходства Инструментарий расчета сходства и поиска семантического соответствия реализует различные алгоритмы расчета сходства и поиска совпадений, поддерживая текст, изображения и т. д.
1. Расчет сходства текста (сопоставление текста)
- Косинусное сходство: найдите косинус двух векторов.
- Скалярное произведение: найдите внутреннее произведение двух векторов после нормализации.
- Расстояние Хэмминга, расстояние Левенштейна, евклидово расстояние, манхэттенское расстояние и т. д.
- семантическая модель
- Модель сопоставления текста CoSENT【рекомендовать】
- Модель BERT (текстовое векторное представление)
- Модель сопоставления текста SentenceBERT
- буквальная модель
- Word2Vec поверхностное семантическое представление текста【рекомендовать】
- синонимы цилин
- Соответствие семам Хаунета
- BM25、RankBM25
- TFIDF
- SimHash
2. Расчет сходства изображений (сопоставление изображений)
- семантическая модель
- CLIP(Contrastive Language-Image Pre-Training)
- VGG(doing)
- ResNet(doing)
- Извлечение признаков
- pHash【рекомендовать】, dHash, wHash, aHash
- SIFT, Scale Invariant Feature Transform(SIFT)
- SURF, Speeded Up Robust Features(SURF)(doing)
3. Расчет сходства изображения и текста
4. Поиск матчей
- SemanticSearch:Поиск векторного сходства,Используйте косинус Similarty + Topk — эффективный расчет, на порядок быстрее, чем расчет методом грубой силы один к одному.
6. Демонстрационный дисплей
Compute similarity score Demo: https://huggingface.co/spaces/shibing624/text2vec

Semantic Search Demo: https://huggingface.co/spaces/shibing624/similarities
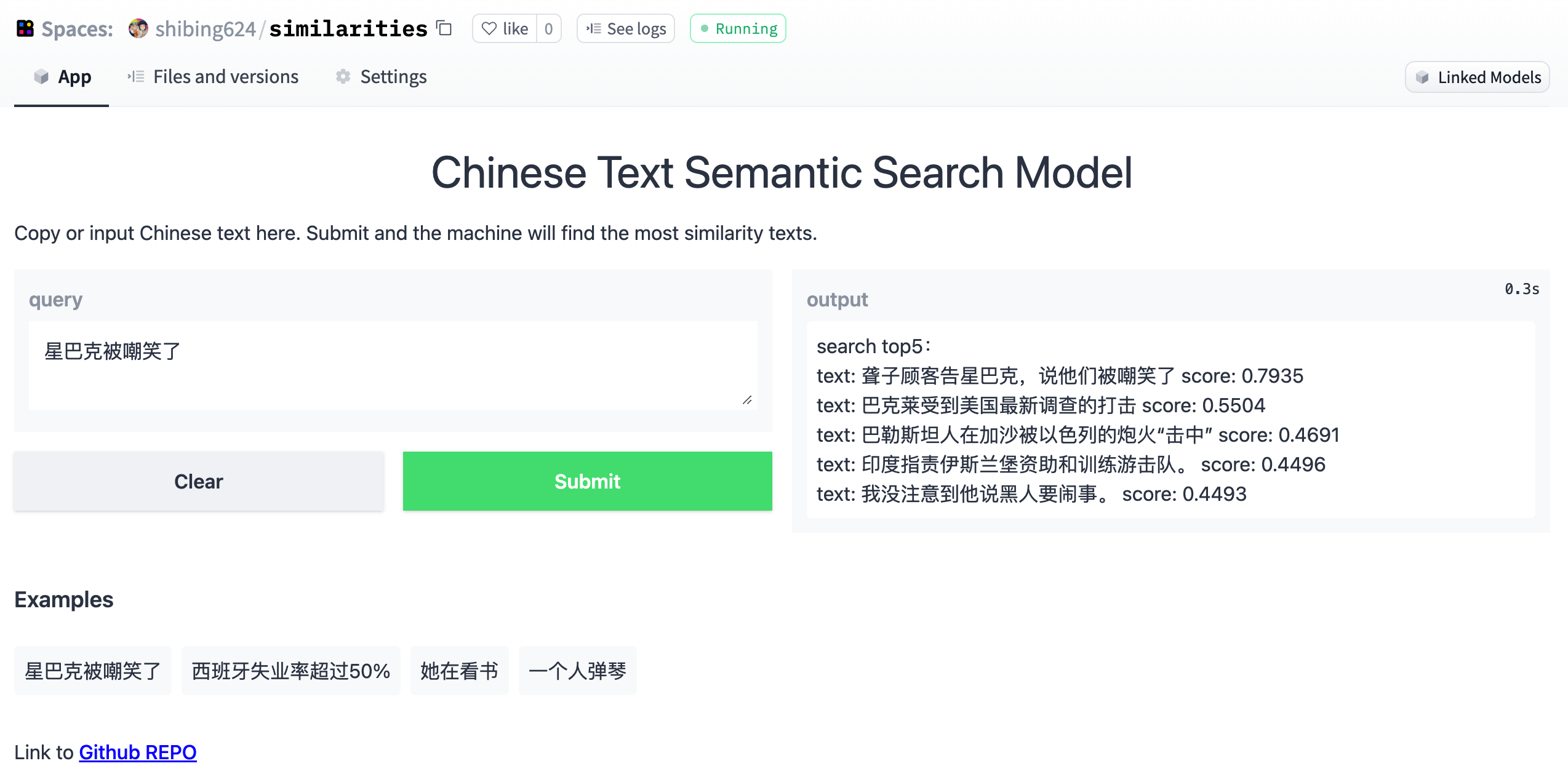
6.1 Результаты оценки модели сопоставления текста на китайском языке
Model | ATEC | BQ | LCQMC | PAWSX | STS-B | Avg | QPS |
|---|---|---|---|---|---|---|---|
Word2Vec | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 33.86 | 10283 |
SBERT-multi | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 41.99 | 2371 |
Text2vec | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 48.25 | 2572 |
В результирующем значении используется коэффициент Спирмена
Model:
- Cilin
- Hownet
- SimHash
- TFIDF
- Install
pip3 install torch # conda install pytorch
pip3 install -U similaritiesor
git clone https://github.com/shibing624/similarities.git
cd similarities
python3 setup.py install7. Рекомендуемые сценарии использования
7.1. Расчет семантического сходства текста.
example: examples/text_similarity_demo.py
from similarities import Similarity
m = Similarity()
r = m.similarity('Как сменить банковскую карту, привязанную к Huabei', «Huabei меняет привязанную банковскую карту»)
print(f"similarity score: {float(r)}") # similarity score: 0.855146050453186Метод сходства по умолчанию:
Similarity(corpus: Union[List[str], Dict[str, str]] = None,
model_name_or_path="shibing624/text2vec-base-chinese",
max_seq_length=128)- возвращаемое значение:косинус
scoreДиапазон-1, 1. Чем больше значение, тем оно более похоже. corpus:Для поискаdocнабор,Требуется только для поиска,Формат ввода:список предложенийList[str]или{corpus_id: sentence}изDict[str, str]Форматmodel_name_or_path:模型名称или模型路径,По умолчанию он начинается сHF model hub下载并использовать中искусство语义匹配模型shibing624/text2vec-base-chinese,Если это многоязычная сцена,Может быть заменено многоязычной соответствующей моделью.shibing624/text2vec-base-multilingualmax_seq_length:输入句子из最大长度,Максимум — это максимальная длина, поддерживаемая соответствующей моделью.,Серия БЕРТ - 512.
7.2. Поиск семантического соответствия текста.
Как правило, текст, наиболее похожий на запрос, находится в наборе кандидатов документов. Он часто используется в таких задачах, как сопоставление вопросов по сходству и поиск сходства текста в сценариях контроля качества.
example: examples/text_semantic_search_demo.py
import sys
sys.path.append('..')
from similarities import Similarity
#1.Compute cosine similarity between two sentences.
sentences = ['Как поменять банковскую карту, привязанную к Huabei',
«Huabei меняет привязанную банковскую карту»]
corpus = [
«Huabei меняет привязанную банковскую карту»,
«Когда я открыл Huabei»,
«Россия предостерегает Украину от соглашения с ЕС»,
«Штормы похоронили 16 дюймов снега на северо-востоке Нью-Джерси»,
«Директор ЦРУ посещает Израиль для переговоров по Сирии»,
«Человек погиб в результате взрыва бомбы на пакистанской базе»,
]
model = Similarity(model_name_or_path="shibing624/text2vec-base-chinese")
print(model)
similarity_score = model.similarity(sentences[0], sentences[1])
print(f"{sentences[0]} vs {sentences[1]}, score: {float(similarity_score):.4f}")
print('-' * 50 + '\n')
#2.Compute similarity between two list
similarity_scores = model.similarity(sentences, corpus)
print(similarity_scores.numpy())
for i in range(len(sentences)):
for j in range(len(corpus)):
print(f"{sentences[i]} vs {corpus[j]}, score: {similarity_scores.numpy()[i][j]:.4f}")
print('-' * 50 + '\n')
#3.Semantic Search
model.add_corpus(corpus)
res = model.most_similar(queries=sentences, topn=3)
print(res)
for q_id, c in res.items():
print('query:', sentences[q_id])
print("search top 3:")
for corpus_id, s in c.items():
print(f'\t{model.corpus[corpus_id]}: {s:.4f}')output:
Как поменять банковскую карту, привязанную к Huabei vs Huabei меняет привязанную банковскую карту, score: 0.8551
...
Как поменять банковскую карту, привязанную к Huabei vs Huabei меняет привязанную банковскую карту, score: 0.8551
Как поменять банковскую карту, привязанную к Huabei vs Когда я активировал Huabei? score: 0.7212
Как поменять банковскую карту, привязанную к Huabei vs Россия предостерегает Украину от соглашения с ЕС score: 0.1450
Как поменять банковскую карту, привязанную к Huabei vs Штормы засыпали северо-восток 16-дюймовым снегом в Нью-Джерси; score: 0.2167
Как поменять банковскую карту, привязанную к Huabei vs Директор ЦРУ посетил Израиль для переговоров по Сирии score: 0.2517
Как поменять банковскую карту, привязанную к Huabei vs Мужчина погиб при взрыве на базе в Пакистане score: 0.0809
Huabei меняет привязанную банковскую карту vs Huabei меняет привязанную банковскую карту, score: 1.0000
Huabei меняет привязанную банковскую карту vs Когда я активировал Huabei? score: 0.6807
Huabei меняет привязанную банковскую карту vs Россия предостерегает Украину от соглашения с ЕС score: 0.1714
Huabei меняет привязанную банковскую карту vs Штормы засыпали северо-восток 16-дюймовым снегом в Нью-Джерси; score: 0.2162
Huabei меняет привязанную банковскую карту vs Директор ЦРУ посетил Израиль для переговоров по Сирии score: 0.2728
Huabei меняет привязанную банковскую карту vs Мужчина погиб при взрыве на базе в Пакистане score: 0.1279
query: Как поменять банковскую карту, привязанную к Huabei
search top 3:
Huabei меняет привязанную банковскую карту: 0.8551
Когда я активировал Huabei: 0.7212
Директор ЦРУ посещает Израиль для переговоров по Сирии: 0.2517косинус
scoreиз值范围-1, 1. Чем больше значение, тем больше запрос похож на корпусный текст.
7.2.1 Расчет семантического сходства многоязычного текста и поиск соответствия
Многоязычность: включая китайский, английский, корейский, японский, немецкий, итальянский и другие языки.
example: examples/text_semantic_search_multilingual_demo.py
7.3. Быстрый поиск приближенного семантического соответствия текста.
Поддерживает поиск приблизительного семантического соответствия Annoy и Hnswlib, который часто используется для сопоставления задач поиска в миллионах наборов данных.
example: examples/fast_text_semantic_search_demo.py
7.4. Подсчет сходства текста и поиск соответствия.
Он поддерживает вычисление сходства и поиск буквального соответствия синонимов Cilin, Hownet, WordEmbedding, Tfidf, SimHash, BM25 и других алгоритмов и часто используется для сопоставления текста при холодном запуске.
example: examples/literal_text_semantic_search_demo.py
from similarities import SimHashSimilarity, TfidfSimilarity, BM25Similarity, \
WordEmbeddingSimilarity, CilinSimilarity, HownetSimilarity
text1 = "Как поменять банковскую карту, привязанную к Huabei"
text2 = "Huabei меняет привязанную банковскую карту"
corpus = [
«Huabei меняет привязанную банковскую карту»,
«Когда я открыл Huabei»,
«Россия предостерегает Украину от соглашения с ЕС»,
«Штормы похоронили 16 дюймов снега на северо-востоке Нью-Джерси»,
«Директор ЦРУ посещает Израиль для переговоров по Сирии»,
«Человек погиб в результате взрыва бомбы на пакистанской базе»,
]
queries = [
«Активирован ли мой Huabei?» ',
«Украину предупредила Россия»
]
m = TfidfSimilarity()
print(text1, text2, ' sim score: ', m.similarity(text1, text2))
m.add_corpus(corpus)
res = m.most_similar(queries, topn=3)
print('sim search: ', res)
for q_id, c in res.items():
print('query:', queries[q_id])
print("search top 3:")
for corpus_id, s in c.items():
print(f'\t{m.corpus[corpus_id]}: {s:.4f}')output:
Как поменять банковскую карту, привязанную к Huabei Huabei меняет привязанную банковскую карту sim score: 0.8203384355246909
sim search: {0: {2: 0.9999999403953552, 1: 0.43930041790008545, 0: 0.0}, 1: {0: 0.7380483150482178, 1: 0.0, 2: 0.0}}
query: Мой Huabei активирован?
search top 3:
Когда я активировал Huabei: 1.0000
Huabei меняет привязанную банковскую карту: 0.4393
Россия предостерегает Украину от соглашения с ЕС: 0.0000
...7.5. Подсчет сходства изображений и поиск совпадений.
Поддерживает расчет сходства изображений и поиск совпадений по алгоритмам CLIP, pHash, SIFT и другим.
example: examples/image_semantic_search_demo.py
import sys
import glob
from PIL import Image
sys.path.append('..')
from similarities import ImageHashSimilarity, SiftSimilarity, ClipSimilarity
def sim_and_search(m):
print(m)
# similarity
sim_scores = m.similarity(imgs1, imgs2)
print('sim scores: ', sim_scores)
for (idx, i), j in zip(enumerate(image_fps1), image_fps2):
s = sim_scores[idx] if isinstance(sim_scores, list) else sim_scores[idx][idx]
print(f"{i} vs {j}, score: {s:.4f}")
# search
m.add_corpus(corpus_imgs)
queries = imgs1
res = m.most_similar(queries, topn=3)
print('sim search: ', res)
for q_id, c in res.items():
print('query:', image_fps1[q_id])
print("search top 3:")
for corpus_id, s in c.items():
print(f'\t{m.corpus[corpus_id].filename}: {s:.4f}')
print('-' * 50 + '\n')
image_fps1 = ['data/image1.png', 'data/image3.png']
image_fps2 = ['data/image12-like-image1.png', 'data/image10.png']
imgs1 = [Image.open(i) for i in image_fps1]
imgs2 = [Image.open(i) for i in image_fps2]
corpus_fps = glob.glob('data/*.jpg') + glob.glob('data/*.png')
corpus_imgs = [Image.open(i) for i in corpus_fps]
#2.image and image similarity score
sim_and_search(ClipSimilarity()) # the best result
sim_and_search(ImageHashSimilarity(hash_function='phash'))
sim_and_search(SiftSimilarity())output:
Similarity: ClipSimilarity, matching_model: CLIPModel
sim scores: tensor([[0.9580, 0.8654],
[0.6558, 0.6145]])
data/image1.png vs data/image12-like-image1.png, score: 0.9580
data/image3.png vs data/image10.png, score: 0.6145
sim search: {0: {6: 0.9999999403953552, 0: 0.9579654932022095, 4: 0.9326782822608948}, 1: {8: 0.9999997615814209, 4: 0.6729235649108887, 0: 0.6558331847190857}}
query: data/image1.png
search top 3:
data/image1.png: 1.0000
data/image12-like-image1.png: 0.9580
data/image8-like-image1.png: 0.9327
7.6. Взаимный поиск изображений и текста.
Модель CLIP не только поддерживает поиск изображений, но также поддерживает взаимный поиск между изображениями и текстами на китайском и английском языках:
import sys
import glob
from PIL import Image
sys.path.append('..')
from similarities import ImageHashSimilarity, SiftSimilarity, ClipSimilarity
m = ClipSimilarity()
print(m)
#similarity score between text and image
image_fps = ['data/image3.png', # yellow flower image
'data/image1.png'] # tiger image
texts = ['a yellow flower', 'тигр']
imgs = [Image.open(i) for i in image_fps]
sim_scores = m.similarity(imgs, texts)
print('sim scores: ', sim_scores)
for (idx, i), j in zip(enumerate(image_fps), texts):
s = sim_scores[idx][idx]
print(f"{i} vs {j}, score: {s:.4f}")output:
sim scores: tensor([[0.3220, 0.2409],
[0.1677, 0.2959]])
data/image3.png vs a yellow flower, score: 0.3220
data/image1.png vs тигр, score: 0.2112Справочная ссылка:https://github.com/shibing624/similarities



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
