Шэньчжэньский университет предложил операции Shift-ConvNets | Sparse/shift, позволяющие небольшим ядрам свертки достигать эффекта больших ядер свертки и дружественные к аппаратному обеспечению

Недавние исследования показывают, что отличные характеристики визуальных преобразователей (ВИТ) зависят от больших воспринимающих полей. Таким образом, конструкция большого ядра свертки становится идеальным решением, позволяющим снова сделать сверточные нейронные сети (CNN) мощными. Однако типичные большие ядра свертки на самом деле являются недружественными к аппаратному обеспечению операторами, что приводит к снижению совместимости на различных аппаратных платформах. Поэтому неразумно просто увеличивать размер ядра свертки. В этой статье автор показывает, что небольшие ядра свертки и операции свертки могут достичь приблизительного эффекта больших ядер свертки. Затем авторы предлагают оператор сдвига, который поможет сверточным нейронным сетям улавливать долгосрочные зависимости с помощью разреженного механизма, оставаясь при этом дружественным к аппаратному обеспечению. Результаты экспериментов показывают, что оператор сдвига авторов значительно повышает точность традиционной CNN, одновременно значительно снижая вычислительные требования. В ImageNet-1k наша модель CNN со смещением превосходит самые современные модели. Код и модель: https://github.com/lidc54/shift-wiseConv.
1 Introduction
Развитие нейронных сетей позволило добиться значительных прорывов в области машинного обучения, особенно в таких областях, как компьютерное зрение и обработка естественного языка. Являясь одной из ведущих архитектур на данный момент, сверточные нейронные сети широко используются в обработке естественного языка, компьютерном зрении и других областях. Тем не менее, разработка Transformer способствовала взрывному росту визуального распознавания в 2020-х годах. Он быстро заменил CNN как самую продвинутую модель компьютерного зрения.
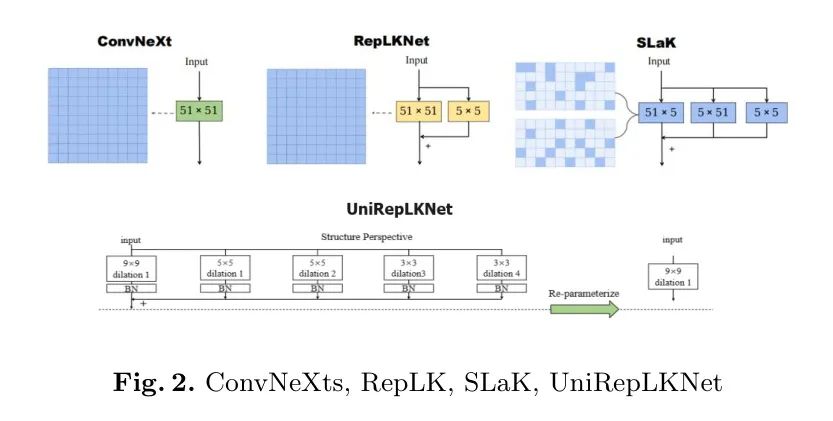
ConvNeXts — это прорывная работа, которая позволяет CNN конкурировать с Трансформерами. Он перепроектировал ResNet на основе Transformer и вновь привлек внимание к роли больших ядер свертки. Динг и др. [7] использовали репараметризацию признаков для увеличения размера ядра свертки до 31x31, что улучшило возможности модели в RepLK-net. Лю и др. [8] увеличили размер ядра до 51x51 за счет собственного разложения и разреженности обучения весовой матрицы, сохраняя постоянные преимущества в SLAK-сети и сохраняя постоянные преимущества предлагаемой архитектуры.
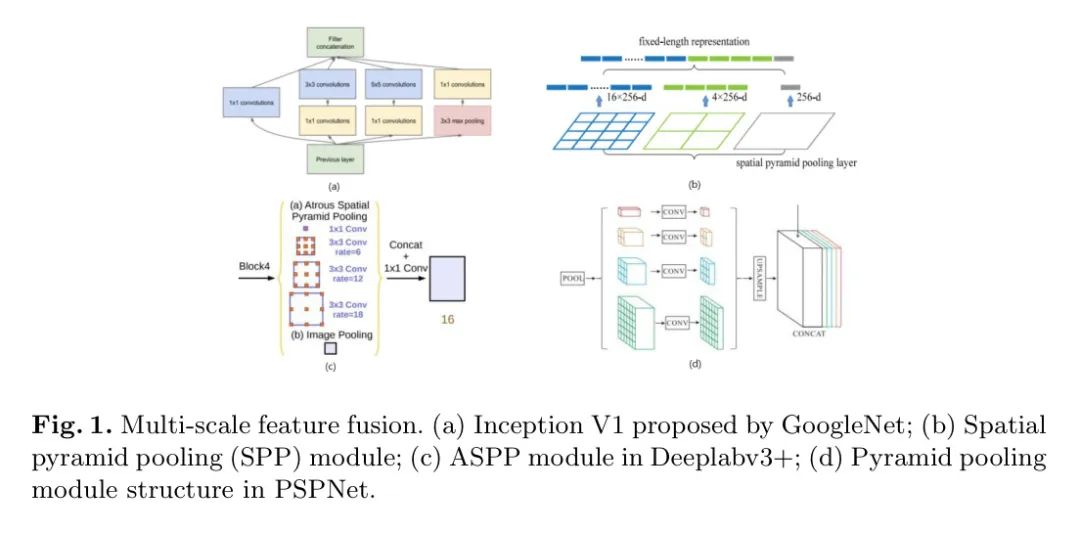
На самом деле, использование больших ядер свертки — не новое явление. В Alexnet широко используются свертки 11x11 и 5x5, закладывающие хорошую основу для последующих исследований. Впоследствии в CNN появилось множество классических Backbone-архитектур, например ResNet, которая широко используется и постоянно оптимизируется. В ранних версиях своего уровня Stem ResNet использовала большие ядра свертки. Аналогично, GoogleNet Inception V1 использует несколько параллельных структур ядра свертки разного размера для объединения информации, как показано на рисунке 1(a).
В ходе последующих исследований большие части ядра свертки в базовых архитектурах, включая Alexnet, Resnet и GoogleNet, были постепенно заменены ядрами меньшего размера. VGG-net представляет концепцию рецептивного поля и полагает, что объединение небольших ядер теоретически может достичь того же эффекта, что и большие ядра, но с меньшими параметрами и вычислительными затратами. Еще одним преимуществом является добавление большего количества нелинейных слоев для повышения выразительности сети. Позже исследовательская группа Лиму обобщила методы обучения ResNet в статье [12] и предложила новую структуру ResNet, которая исключает использование больших ядер на уровне Stem ResNet.
Однако есть некоторые области, где использование больших ядер свертки не исчезло полностью:
- Похоже на: Начало Технология иерархического многомасштабного объединения функций V1 неоднократно упоминалась и улучшалась. Например: в SPPnet многомасштабный уровень пула и обычная свертка эффективно образуют большое ядро свертки в структуре модуля пирамидального пула, как показано на рисунке 1(d). Для дальнейшего улучшения этого метода объединения функций был использован модуль ASPP (Attenuated Spatiotemporal Pyramid Pooling) в DeepLab и Trident. Структура Trident в Networks использует постепенно увеличивающиеся агрессивные свертки для достижения аналогичных функций, как показано на рисунке 1 (c).
- Кроме того, практика использования больших рецептивных полей для удаленного слияния признаков также является долгосрочной технологией. Атрусная свертка, представленная в FCN, является широко используемым методом сегментации. SegNeXt использует параллельные свертки размером 1x7, 1x11и1x21 для сегментации объектов. Глобальный Convolutional Сеть (GCN) использует сложенные свертки 1xkиkx1 для достижения той же цели. Кроме того, некоторые методы исследования мелкозернистого выделения признаков, такие как [18, 19, 20], который использует умножение матриц после сверточных слоев для установления долгосрочных зависимостей объектов. Аналогичные операции применяются для широко используемых нелокальных структур.
- Deformable Convolutional Сети (DCN) достигают большого восприимчивого поля за счет использования меньшего количества параметров. Эта идея привела к множеству исследований. Динамический Snake Свертка (DSConv) добавляет дополнительные ограничения на основе DCN для адаптации к сценариям сегментации кровеносных сосудов. Линейный ядро применяет идеи DCN к разреженным трехмерным облакам точек,Для достижения более сильного восприятия и более высокой эффективности. В [25],Используйте идеи DCN для точной настройки границ сегментации экземпляров.
Вышеупомянутое предполагает применение концепции больших ядер свертки.,Независимо от всего или части да,Все они показывают важность агрегирования функций для долгосрочных зависимостей функций. Это подтверждено экспериментами ConvNeXts, RepLK-netиSLAK. Дин и др. [3] привели аргумент.,То есть ядро сверткибольшой или маленький квадратный корень. Глубина сложения и настоящее ощущение дикости становятся Сравнивать. Эксперименты доказали, что необходимо большое ядро свертки. Однако, учитывая ядерную мощь или Учитывая неизбежную эволюцию маленького, автор может ожидать больших эффектов ядра, которых можно достичь только с помощью маленьких ядер свертки. Фактически, ParCNetV2 расширяет размер ядра до большой входной карты объектов. или маленький дважды. Продолжающееся увеличение размера ядра, похоже, достигло точки убывающей отдачи. с другой стороны,Зависимости функций не должны быть слишком плотными.,Как показывает Трансформер. поэтому,Возникает интуитивный вопрос:Могут ли CNN создавать разреженные долгосрочные зависимости, используя стандартные свертки?
Чтобы справиться с этой проблемой, автор предложил метод: добиться эффекта большого ядра свертки путем сдвига стандартной свертки, а затем получить свертку разреженной группы путем обрезки. Автор называет этот оператор оператором сдвига. Этот оператор сочетается с принятой структурой переопределения параметров для повышения производительности модели. Он легко интегрирует эффекты больших ядер свертки с достижениями в стандартных CNN.
2 Proposed Method
Decomposition and Combination of Convolution
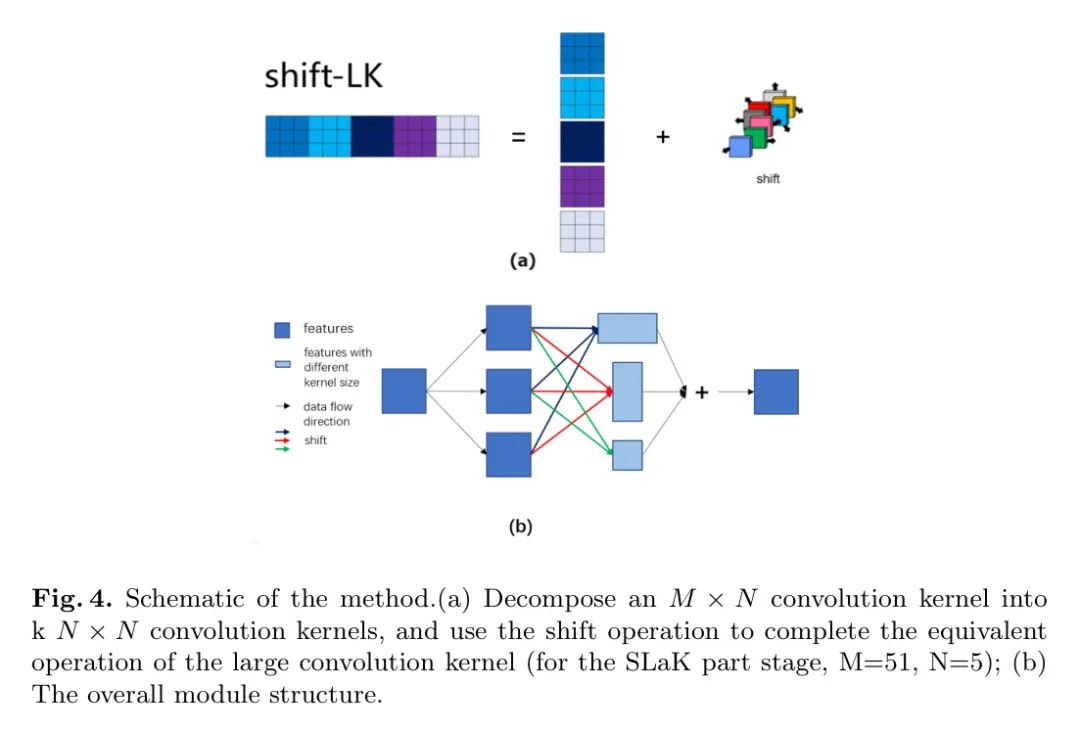
На основе непрерывной эволюции больших ядер свертки автор предлагает оператор Shift-wise. Улучшенная структура модуля показана на рисунке 4(а). В частности, авторы преобразуют большие ядра свертки в серию обычных меньших ядер свертки, а затем применяют операцию сдвига к каждому результату свертки.
В частности, традиционную свертку можно выразить уравнением 1:
в
Представляет положение скользящего окна на изображении или карте объектов.
и
Представляет ширину и высоту ядра свертки соответственно.
Представляет информацию о местоположении.
и
Представляет вес и особенности соответствующей позиции. Для общности предположим
. Большие ядра свертки можно разложить (разложенные ядра свертки с большими структурами) посредством следующего преобразования, как показано на рисунке 2:
округляется в большую сторону. Разложенное ядро свертки легко увидеть из формулы, то есть
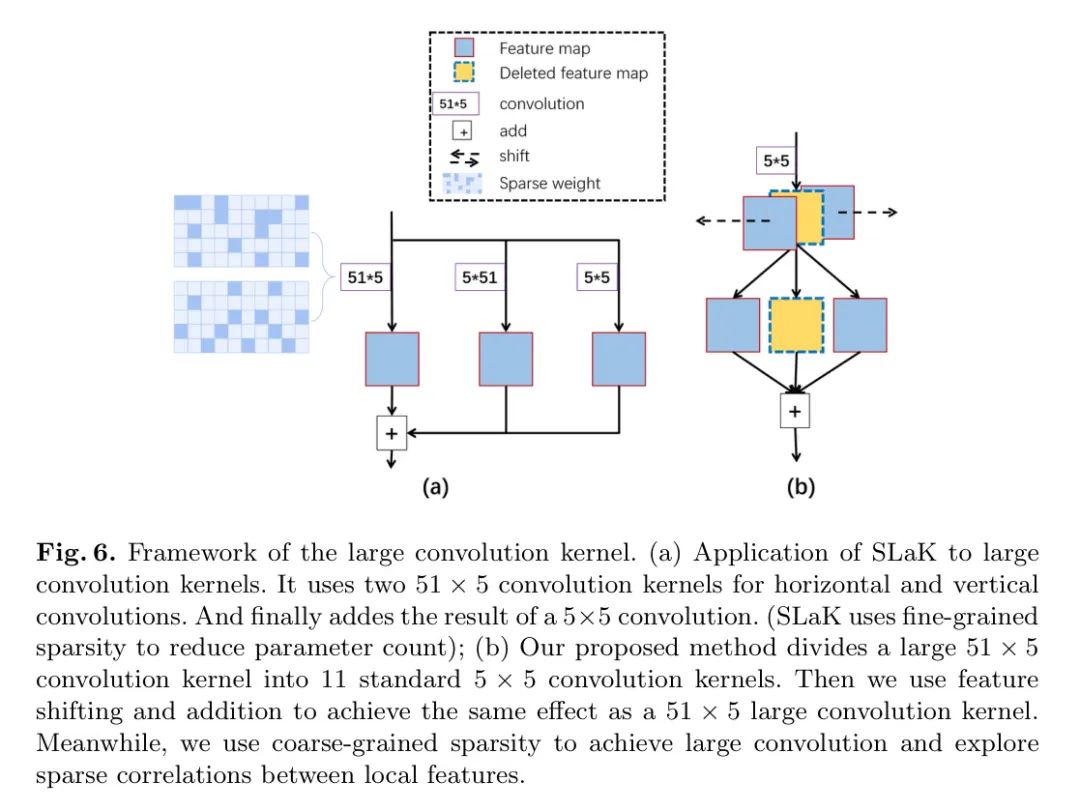
ситуация. Его можно заменить несколькими обычными небольшими ядрами свертки. конечно,Это требует выравнивания гиперпараметров,Например, управление смещением и настройки заливки. Рисунок 4(a) обеспечивает более интуитивное понимание,И используйте квадраты разных цветов, чтобы представить это отношение замены.
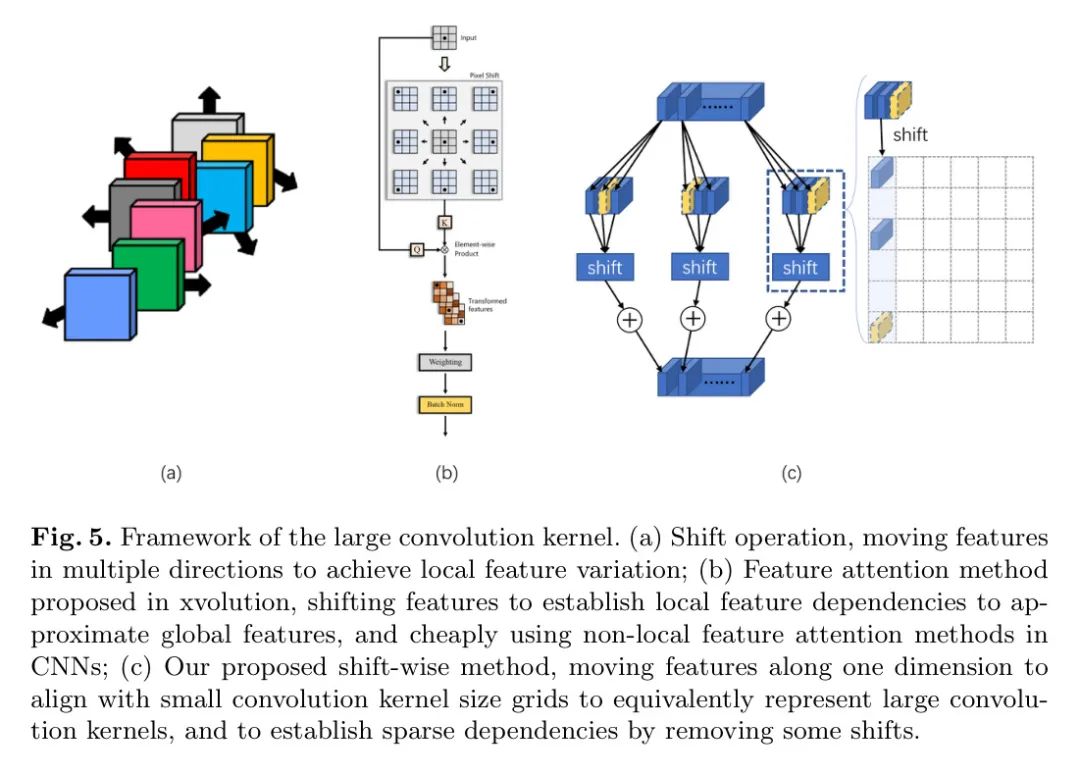
Здесь свертка 15x3 может быть эквивалентна свертке 5x3x3. В этом случае требуется операция смены. В отличие от предыдущего случая, сдвиг требует перемещения дальше в одном измерении и сделать его таким же, как
Выравнивание размерной сетки. Чтобы представить эту разницу смещения более подробно, авторы используют схематическую диаграмму на рисунке 5 (c).
Sparse Dependencies of Large Convolution Kernels
Большие ядра свертки могут устанавливать долгосрочные зависимости в пространстве признаков. Однако биологическое визуальное понимание часто игнорирует некоторую информацию. Transformer также создает разреженные зависимости. Хотя SLaK также использует мелкозернистую разреженную матрицу весов. Однако в связи с локальным информационным полем трудно сказать, что в СЛа К действительно установлены разреженные отношения внимания. Эта проблема приводит к избыточности вычислений на семантическом уровне высокого уровня, что представляет собой нечто большее, чем просто покрытие, которое снижает вычислительные усилия на семантическом уровне низкого уровня. Сокращение вычислений на семантических уровнях низкого уровня еще менее идеально.
Авторский метод усовершенствования также очень прост. во время тренировки,Обрежьте некоторые связи. Пунктирные цветные блоки на рисунках 5(c) и 6(b) указывают на то, что канал обрезан.,Как показано на рисунке 5(c) и рисунке 6(b). Благодаря этой грубой обрезке,Можно получить свертку разреженной группы. посредством последующих операций добавления,Это гарантирует, что общий выход канала модуля останется неизменным.
Для этого метода,Зависимости можно непрерывно определять с точки зрения многообразия данных в ходе процесса обучения.,сохраняя при этом общую структуру сети неизменной。Автор называет этоГрупповая смена работы。Общая структура представлена на рисунке.4(b)показано。
- первый,Примените операцию группового сдвига к тому же входу,для имитации нескольких размеров ядра свертки,Создать несколько ветвей вывода
- Затем выберите канал из каждой группы, чтобы сформировать ветку Identity.
- наконец,Объедините все выходные ветки группы в одну ветку
В этой статье используются 3 ядра свертки, аналогичные SLaK:
,
и
(в
) без дальнейшего изучения. При этом автор называет эту общую структуру оператором сдвига.
иSLaKВзаимно Сравнивать,Более общая форма оператора сдвига да, предложенная автором,Ограничения могут быть смягчены еще больше. Сюда входят размер и форма ядра свертки, а также метод объединения информации. Из-за сдвига и разреженности,Автор вводит новое понятие: фокус. надлинаисосредоточиться по ширине, соответствующей СЛа К Kernel большой или маленький
и
。
здесь,Автор формально определяет оператор сдвига как метод,первый Укажитесосредоточиться надлинаисосредоточиться на ширину прямоугольной области и выберите размер меньше или равный для фокусировки на ширину ядра свертки и настроить распределение этих сверток для объединения информации. СОЗРЕЗОДЕГО Длина на не обязательно должна быть меньше текущего размера карты объектов. Для этого случая автор немного корректирует Формулу 2, чтобы получить Формулу 3:
в
Представляет все заранее определенные непересекающиеся небольшие свертки.
Указывает размер небольшого ядра свертки.
и
Соответственнососредоточиться надлинаисосредоточиться наширина。
значит с
связанные функции. Соответственно, вес и смещение характеристик
с
Соответствующие функции выражаются как
。
Intermodule Feature Manipulation
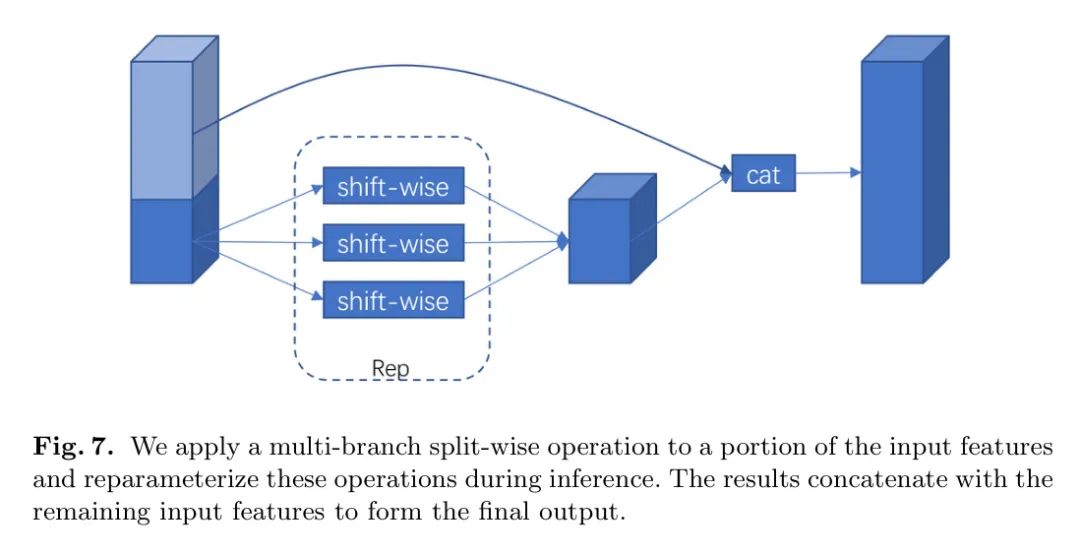
Чтобы уменьшить объем вычислений при выводе,Автор пытается управлять функциями внутри модулей. Конкретно,Автор объединяет технологии «призрак» и репараметризации (реп) в один модуль.,Как показано на рисунке 7.
Theoretical Computational Complexity Changes
Настройки эксперимента следующие: модуль СЛа К имеет две ветки, одна
Ветвь свертки , одна из них
Ветка сертификата личности, все ветки являются ветвями глубокой свертки (
). Модуль смены использует модуль, сочетающий в себе стили «призрак» и «реп», в котором содержится
Группа
Kernel большой или маленькийсвертка,И с соответствующими сменными операциями. здесь,
да
округлено. Предположим, что размер входного объекта
Представляет партию соответственно. channel, heightиwidth。
Глубина вычислительной сложности для СЛа К,Автор получает следующую формулу,Как показано на рисунке 4. «+» до и после части ядра свертки указывает на большую часть ядра свертки и малую часть ядра свертки. Для слияния-
ситуация, автор не рассматривает ее в этой части
Количество параметров слоя и сложность вычислений. Небольшая часть ядра свертки теоретически может быть объединена в две большие ветви с помощью метода Rep на этапе вывода, поэтому
Это также можно игнорировать. Соответственно, авторы вывели ряд параметров глубины СЛа К, как показано на рисунке 5.
Вычислительная сложность операции сдвига определяется уравнением 6. здесь,
,
и
да Размеры объектов после заполнения, они будут больше исходного размера С выравнивать
(в
)。
Ветка Identity выбирается случайным образом из результатов свертки Group.
особенности, каждая ветка имеет
канал. Две большие ветки ядра свертки изменят порядок функций из результатов свертки Group. Две большие ветви ядра свертки будут выполнять добавление функций после операции сдвига. все
Каждый канал подвергается одной и той же операции сдвига. Функция сложения определяет необходимые операции сдвига и сложения. Вычислительные затраты на операцию сложения составляют
выражать. Автор заметил, что операция Shift да представляет собой своего рода разреженную групповую свертку.
Соответствующее количество параметров для операции сдвига определяется уравнением 7. Вычислительная сложность С, скорость преобразования SLaKиshift, определяется уравнением 8. Пока игнорирую(
,
)и(
,
), и
。
Для SLaK первые четыре этапа
,
, соотношение [1,85, 1,96, 2,0, 1,73, 2,0]. Учитывая(
,
)и(
,
), и
,Это значение будет немного ниже. Однако,Свертки Sparse Group в посменных операциях значительно увеличат его. Автор рассчитал
и
Количество параметров Коэффициент сравнения,Как показано на рисунке 9. iSLaKphase С выравнивание,Количество параметров и вычислительная сложность операций Shift уменьшены примерно вдвое.
4 Experimental Setup and Result Analysis
Experimental Configuration
Сеть Shift (обозначенная как SW) сохраняет оптимизированную структуру ResNet в ConvNeXt. На каждом этапе сети авторы используют разное количество блоков. В частности, структура SW-T использует блоки [3, 3, 9, 3], а структура SW-S/B использует блоки [3, 3, 27, 3]. Короткая сторона ядра равна 5, а длинная сторона на каждом этапе меняется на [51, 49, 47, 13]. Модуль Stem использует
Свертка с шагом 4.
О введении вахтового режима работы,Ларт и др. [50] суммировали пять возможных операций: индексирование срезов.,torch.roll,Деформированная свертка,Свертка по глубине и выборка сетки F.grid_sample. Эти операции требуют больших вычислительных затрат. поэтому,Авторы используют taichi[51] для переписывания соответствующих операторов.
Evaluation on Imagenet-1k
Imagenet-1kдабольшая визуальная база данных,Для исследования программного обеспечения для визуального распознавания объектов. Он предоставляет более 1000 изображений различных категорий.,Используется для обучения и тестирования различных алгоритмов распознавания изображений.
Как указано в разделе 3.1.,Оператор сдвига может быть полностью эквивалентен большому ядру свертки, используемому в SLaK. Это требует тщательной настройки отступов и смещения. Авторы называют эту эквивалентную версию «экв-СЛа К-Т». Затем,Для обучения без разреженной группы и
Модуль ПО, использует автор
и обозначим его как «p-SW». когда
При , авторы обозначают его как «p2-SW».
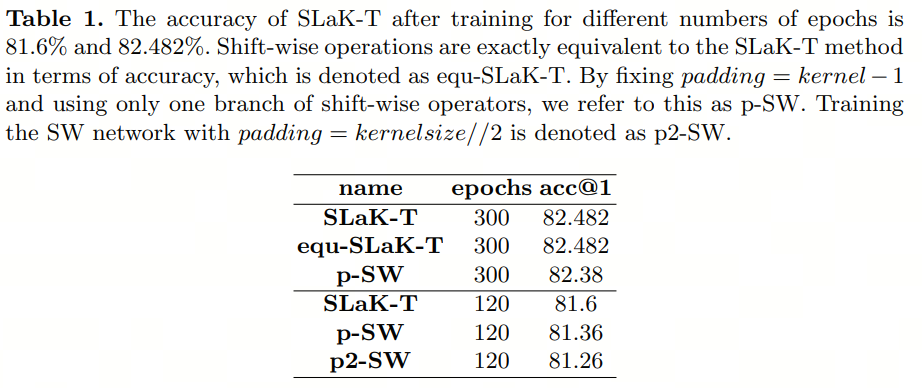
Точность этих нескольких настроек подробно показана в Таблице 1. Авторы отмечают, что при уменьшении количества параметров почти вдвое точность посменной работы практически равна СЛа К-Т, обученной за 120 эпох. Автор обнаружил, что
Сравнивать
лучше. Автор будет
Установите значение по умолчанию.
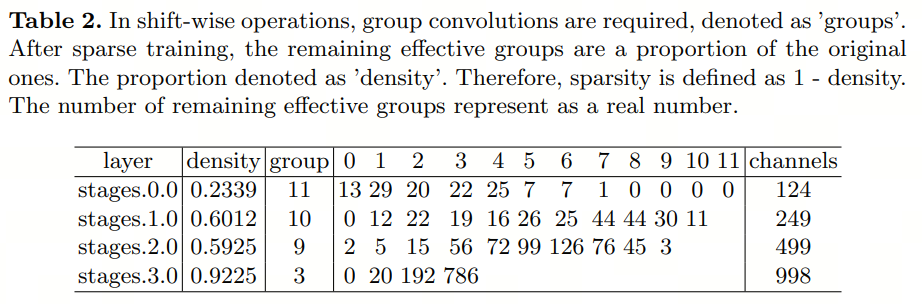
Для дальнейшего анализа разреженной посменной структуры сети,Авторы представляют разреженность первого слоя каждого этапа в таблице 2. очевидно,на более ранней стадии,Разреженность выше,Меньше группы необходимо для достижения эффекта больших ядер свертки. на более позднем этапе,Разреженность постепенно уменьшается. Эти оставшиеся действительные группы полностью управляются данными.,Демонстрирует большой потенциал для повышения эффективности рассуждений.
Чтобы сохранить эффективность вычислений и повысить точность,Автор использует несколько ветвей, представленных в модуле смены. Несколько ветвей имеют общую разреженную маску.,Обеспечить возможность репараметризации параметров при разреженном обучении. Результаты показаны в таблице 3. Посменный модульный подход сохраняет разреженность, показанную в Таблице 2.,И добился более высокой точности сравнения СLaK.
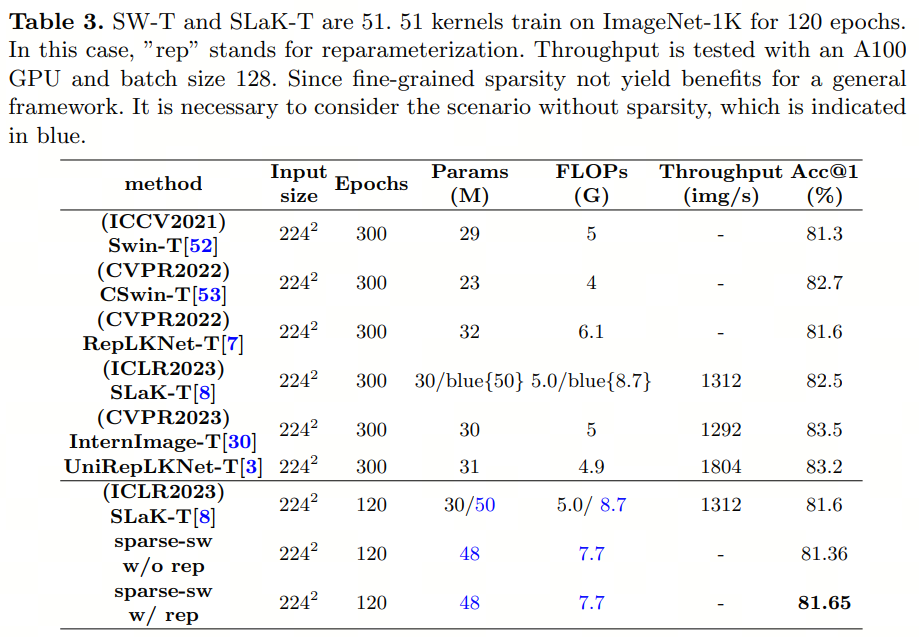
Из таблицы 4 видно, что по сравнению с СЛа К вычислительная сложность модуля сдвига в операциях свертки существенно снижается. Сокращение их использования может улучшить общую производительность вычислений.
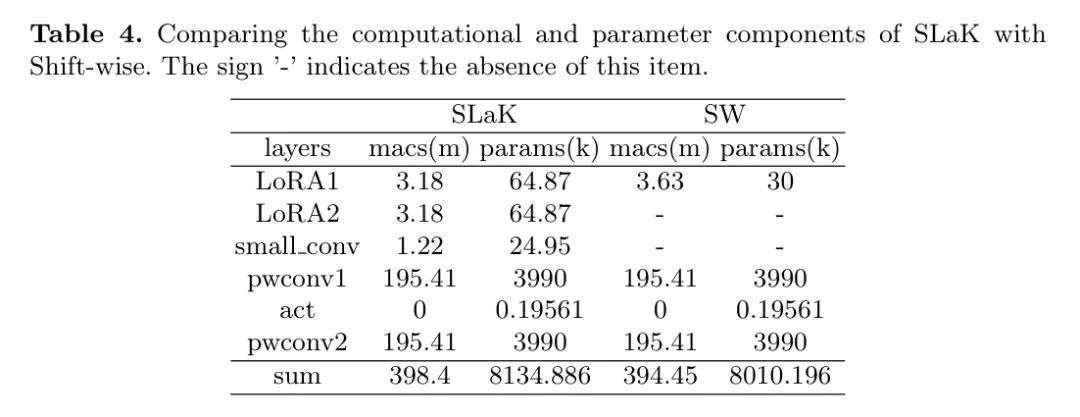
В то же время автор протестировал время работы сменного модуля на одной ветке, как показано в Таблице 5. Результаты показывают, что предложенный оператор снижает временные затраты при определенной разреженности. Учитывая, что SLaK использует двухветвевую сеть, а модуль сдвига использует только половину количества сверток, сокращение времени вывода становится еще более значительным.

5 Conclusions
В последние годы масштабные визуальные Transformer (Ви Т) добилась значительного прогресса. В то же время исследования по улучшению сверточных нейронных сетей (CNN) также добились быстрого прогресса. В этой статье предложенный оператор достигает крупномасштабных ядерных эффектов посредством регулярной свертки, которая является более аппаратной. обеспечениедружелюбиеипрограммное обеспечениеэффективность。
для различных устройств,Исследования автора позволяют применять последние достижения CNN с меньшими затратами. Автор не только добился успехов в оптимизацииэффективности,А также начал изучать способы улучшения работы CNN. Эффективный способ создания пространственно разреженных корреляций. Установленные долгосрочные разреженные зависимости обусловлены данными,Это может облегчить проблемы миграции последующих задач, которые могут быть вызваны проектированием вручную. Предлагаемые операторы требуют базовых процедур чтения данных.,И есть дальнейший потенциал в многоэтапном слиянии. в то же время,Необходимы дальнейшие исследования нового пространства проектирования конструкции разреженных зависимостей.
ссылка
[1].Shift-ConvNets: Small Convolutional Kernel.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
