Шаг за шагом по созданию системы проверки видео на плагиат

#01
фон
В настоящее время платформы коротких видео становятся все более мощными и точными в обнаружении различных типов обработки видео. Будь то монтаж из киноаккаунта или транспортировка из нефтепровода, даже если выполняются различные сложные преобразования видео, это можно легко обнаружить. Автор получит напоминание, а в серьезных случаях его аккаунт могут даже заблокировать.

Оригинальное видео речи Стива Джобса

Движущееся видео с добавленными субтитрами
Распространенные методы преобразования видео включают смену времени и экрана:
- время: Обратное воспроизведение, циклическое воспроизведение, смешанная резка, ускорение, замедление и т. д.
- экран: Обрезка, переворот, масштабирование, разрешение, мозаика, цветность, контрастность, размытие, шум, экранкопирование, наложение текста или рисунка, модификация фона, вторичное откровенное фото, картинка в картинке, дипфейк ждать
Как платформа обнаруживает такое множество типов видеопреобразований? Дьявол имеет высоту в один фут, а Дао — в один фут. Ввиду бесконечного появления различных методов мошенничества алгоритм обнаружения платформы в настоящее время является относительно зрелым. Движущемуся мошенническому видео сложно ускользнуть от обнаружения.
В этой статье мы проанализируем и раскроем технологию и алгоритмы, стоящие за этим, с технической точки зрения, а также научим вас шаг за шагом создавать подобную систему обнаружения.
Мы знаем, что современные модели нейронных сетей искусственного интеллекта могут извлекать функции из таких данных, как изображения и видео, что также называется встраиванием. Каждое изображение или видео может извлекать уникальное встраивание. Повторное обнаружение самого видео заключается в выполнении анализа сходства извлеченного встраивания.
Во-первых, мы понимаем две концепции, а именно обнаружение дубликатов видео с разной степенью детализации: обнаружение детализации видео и обнаружение детализации сегментов.
- Обнаружение детализации видеоэто видео, которое имеет много повторов на протяжении всего видеоиз Состояниеизметод。Он работает путем сравнения двух полных видеоизмежду векторамииз Ищите сходствоприезжатьповторитьизвидео。由于每个видео只会被一个向量выражать,Этот метод обычно быстрее и эффективнее. Однако очевидны и ограничения этого метода: он не может адаптироваться к ситуации, когда некоторые фрагменты повторяются.,Особенно это неблагоприятно для обнаружения повторения небольших фрагментов в длинных видеороликах. Например,видео A и видео B до 1/4 Продолжительность точно такая же, после 3/4 Длительности совершенно разные, но их видеовекторы могут не совпадать. существование В данном случае Обнаружение детализации Видео, очевидно, не может идентифицировать содержание, нарушающее авторские права.
- Обнаружение детализации фрагментаспособен найтиприезжатьповторить片段изначинатьи Заканчиватьвремя,Он может обрабатывать сложное редактирование видеоклипов, вставленных клипов или ситуаций, когда длина видео различается. Его основная технология — сравнение сходств между видеокадрами. очевидно,Этот метод может обеспечить более точный эффект проверки дублирования.,Но требуется больше извремяи ресурсов.
В предыдущей статье мы продемонстрировали, как построить простую систему дедупликации видео.

В следующем примере мы реализуем сегментное обнаружение дублирования видео. Такое детальное обнаружение фрагментов будет более точным и обеспечит более высокий уровень отзыва, что в большей степени соответствует реальным потребностям бизнеса.
мы будем использовать Towhee[1] и Milvus[2] Создайте систему детальной проверки дублирования видео: Towhee Это инструмент, который может извлекать неструктурированные данные одним щелчком мыши. embedding Инструменты Милвус; Является лидером отрасли по векторной базе данные, могут использоваться для векторного хранения и поиска.
Метод, использованный в этой статье, позволяет упростить основные функции до нескольких строк кода, что упрощает воспроизведение и обучение для всех.
#02
Подготовка
1. Установите зависимости
В среде python3 установите эти зависимости:
! python -m pip install -q pymilvus towhee pillow ipython numpy plyvel
2. Подготовьте данные
Видео, которые мы используем, взяты из VCSL[3] набор данных. ВКСЛ включает в себя большое количество Youtube и Bilibili реальные видео, в основном используемые для обнаружения дублирования видео.
Этот набор данных из повторяющихся видео содержит множество сложных методов преобразования.,включатьэкран Обрезать、фильтр、наложение текста、адфон、Откровенное фото、картинка внутри картинкиждать,существовать Превосходить 28 При повторении десятков тысяч фрагментов наблюдается широкий диапазон содержательных изменений. Эти умные преобразования, близкие к реальности, создают огромные проблемы для обнаружения дублирования видео на уровне сегментов.
В качестве примера мы используем только 5 наборов видео из VCSL, каждый набор содержит 3 разные портированные копии одного и того же видео. В папке «crashed_video» также имеется поврежденное видео для проверки надежности.
Загрузите образец данных с помощью следующей команды:
! curl -L https://github.com/towhee-io/examples/releases/download/data/VCSL-demo.zip -O
! unzip -q -o VCSL-demo.zip
Мы просто наблюдаем набор видеороликов: это три разных способа обращения с копиями классических отрывков из фильма «Шарлотта».,Например, добавление субтитровитрансформироватьразрешение。
madongmei
├── 0640bd5d43d1499c962e275be6b804ef-Дядя, здесь живет семья Ма Дунмей? -1e64y1y799.flv
├── 8ad81fc9fe0a47dbaab1b4cdc40bf07b-Ладно, дядя, можешь пойти остыть, Божественная комедия "Ма Дунмей"-1t54y117JK.flv
└── ad244c924f31461a9d809c77ae251ac1-Проблемы Шарлотты Шен Тэн и Дядя из классического диалога, что такое Ма Мэй, что такое Ма Донг, что такое Донмей-1y7411n7y1.flv



3. Создайте коллекцию
Прежде чем формально построить систему, нам необходимо подготовить Milvus собирать. Вы можете быстро установить и запустить следующие методы. Milvus Сервис, более подробную информацию и настройки можно найти в Milvus doc[4]:
# Download docker yaml for Milvus standalone
! wget https://github.com/milvus-io/milvus/releases/download/v2.1.1/milvus-standalone-docker-compose.yml -O docker-compose.yml
# Run command below under the same directory as the docker yaml
! docker-compose up -d
Создайте файл с именемvideo_deduplicationизсобирать,использоватьL2 distance metric[5]и IVF_FLAT index[6]:
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='127.0.0.1', port='19530')
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='id of the embedding', is_primary=True, auto_id=True),
FieldSchema(name='path', dtype=DataType.VARCHAR, descrition='path of the embedding',max_length=500),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='video embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='video dedup')
collection = Collection(name=collection_name, schema=schema)
index_params = {
'metric_type':'L2',
'index_type':"IVF_FLAT",
'params':{"nlist":1}
}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
collection = create_milvus_collection('video_deduplication', 256)
#03
Обнаружение дубликатов видео
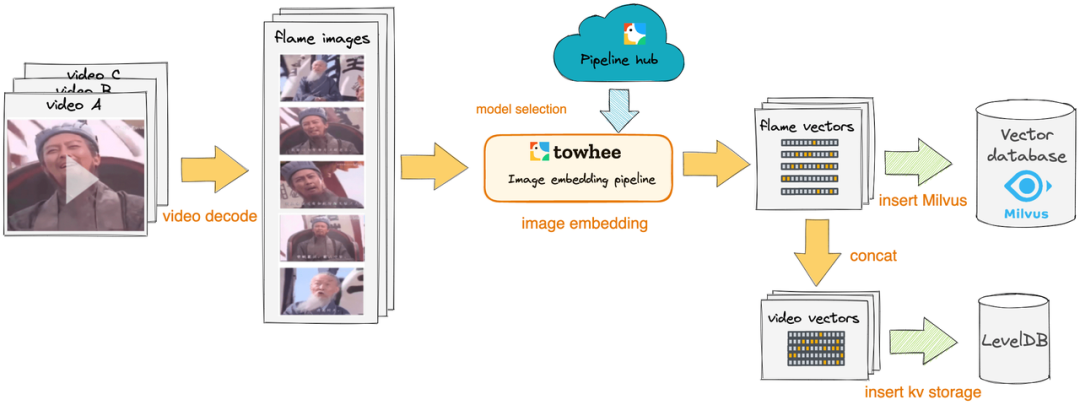
Далее мы покажем, как использовать Milvus и Towhee Создание нашей мелкомасштабной системы дедупликации видео. Основная идея этой системы заключается в использовании Towhee предоставил Оператор встраивания изображений[7]提取видео帧向量,и сохранить егосуществовать Подготовьтесь заранееиз Milvus коллекцию, а затем найдите повторяющиеся сегменты, сравнивая сходство между векторами видеокадров.
1. Процесс складирования
Для каждого видео мы декодируем его в кадры изображения, а затем преобразуем их в векторы с помощью предварительно обученной нейронной сети. Эти векторы будут вставлены в Milvus Коллекция и levelDB хранится в.
import towhee
import numpy as np
from towhee.types import Image
os.environ["CUDA_VISIBLE_DEVICES"] = '1'
@towhee.register
def get_image(x):
for i in x:
yield Image(i.__array__(), 'RGB')
@towhee.register
def merge_ndarray(x):
return np.concatenate(x).reshape(-1, x[0].shape[0])
all_file_pattern = os.path.join(vcsl_demo_root, '*', '*.*')
dc = (
towhee.glob['video_url'](all_file_pattern "'video_url'").stream()
.video_decode.ffmpeg['video_url', 'frames'](sample_type='time_step_sample', args={'time_step': 1} "'video_url', 'frames'")
.get_image['frames', 'images']( "'frames', 'images'")
.flatten('images')
.drop_empty()
.image_embedding.isc['images', 'embeddings']( "'images', 'embeddings'")
.select['video_url', 'embeddings']( "'video_url', 'embeddings'")
.ann_insert.milvus[('video_url', 'embeddings'), 'insert_result'](uri='tcp://localhost:19530/video_deduplication' "('video_url', 'embeddings'), 'insert_result'")
.group_by('video_url')
.merge_ndarray['embeddings', 'video_embedding']( "'embeddings', 'video_embedding'")
.insert_leveldb[('video_url', 'video_embedding'), ]('url_vec.db' "('video_url', 'video_embedding'), ")
.select['video_url', 'video_embedding']( "'video_url', 'video_embedding'")
.show(limit=20)
)

Отображение результатов извлечения вектора видеокадра
Мы видим, что каждое видео преобразуется в 256-мерный вектор n (по умолчанию n — продолжительность в секундах). Если во время работы возникает ошибка «ОШИБКА: заголовок поврежден», это означает, что набор данных выборки содержит поврежденные видео. В конвейере, построенном Towhee, пакетные операции автоматически пропускают ошибки, вызванные определенными данными, и продолжают выполняться до тех пор, пока все данные не будут обработаны. Это сделано для того, чтобы смоделировать, как на практике обработка огромных видеоданных не будет замедляться из-за небольшого количества поврежденных видео.
2. Процесс тестирования
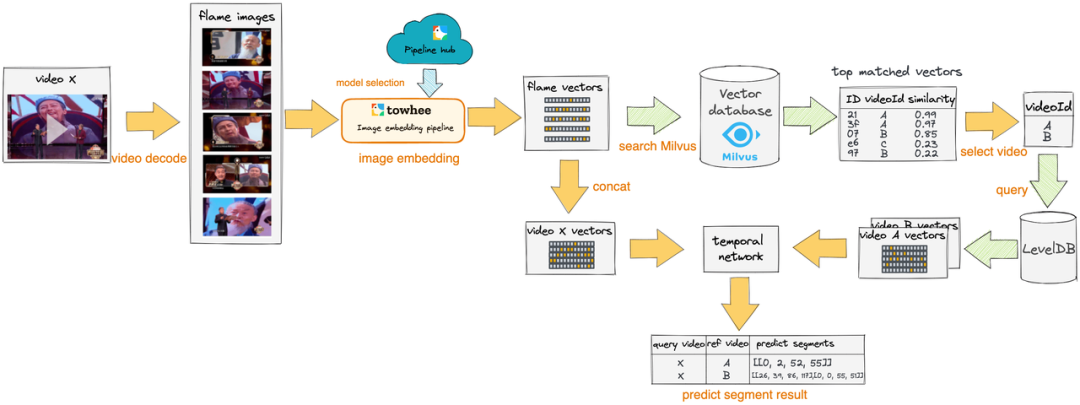
Теоретически,Для каждого запроса видео,Все нужно сопоставить и получить базу Все видео в данных, однако это приведет к огромным накладным расходам. В этом примере мы решили сначала выполнить Грубое на основе вектора видеокадра. сито,Простойфильтр Совершенно неважноизвидео。
- Грубое сито:Для каждого кадра запроса,мы проходим Milvus Векторный поиск находит определенное количество похожих кадров и сопоставляет их с соответствующим видео. Эти видео затем объединяются, сортируются и фильтруются. Этот шаг соответствует выбору в приведенной выше блок-схеме обнаружения. video выбирать video A и video B процесс.
Потом сравниваем Грубое Найдите результаты из видео и запросите видео из вектора видеокадра, используйте Temporal Network[8] Алгоритм выравнивания для поиска повторяющихся сегментов.
query_file_pattern = os.path.join(vcsl_demo_root, 'madongmei', '*.*')
@towhee.register
def split_res(x):
return [i.path for i in x], [i.score for i in x]
dc = (
towhee.glob['query_url'](query_file_pattern "'query_url'").stream()
.video_decode.ffmpeg['query_url', 'frames'](sample_type='time_step_sample', args={'time_step': 1} "'query_url', 'frames'")
.get_image['frames', 'images']( "'frames', 'images'")
.flatten('images')
.drop_empty()
.image_embedding.isc['images', 'embeddings']( "'images', 'embeddings'")
.select['query_url', 'embeddings']( "'query_url', 'embeddings'")
.ann_search.milvus['embeddings', 'results'](collection=collection, limit=64, output_fields=['path'], metric_type='IP' "'embeddings', 'results'")
.split_res['results', ('retrieved_urls','scores')]( "'results', ('retrieved_urls','scores')")
.group_by('query_url')
.video_copy_detection.select_video[('retrieved_urls','scores'), 'ref_url'](top_k=5, reduce_function='sum', reverse=True "('retrieved_urls','scores'), 'ref_url'")
.from_leveldb['ref_url', 'retrieved_embedding']('url_vec.db', True "'ref_url', 'retrieved_embedding'")
.merge_ndarray['embeddings', 'video_embedding']( "'embeddings', 'video_embedding'")
.flatten('retrieved_embedding', 'ref_url')
.video_copy_detection.temporal_network[('video_embedding', 'retrieved_embedding'), ('predict_segments', 'segment_scores')]( "('video_embedding', 'retrieved_embedding'), ('predict_segments', 'segment_scores')")
.select['query_url', 'ref_url', 'predict_segments', 'segment_scores']( "'query_url', 'ref_url', 'predict_segments', 'segment_scores'")
.show(limit=50)
)
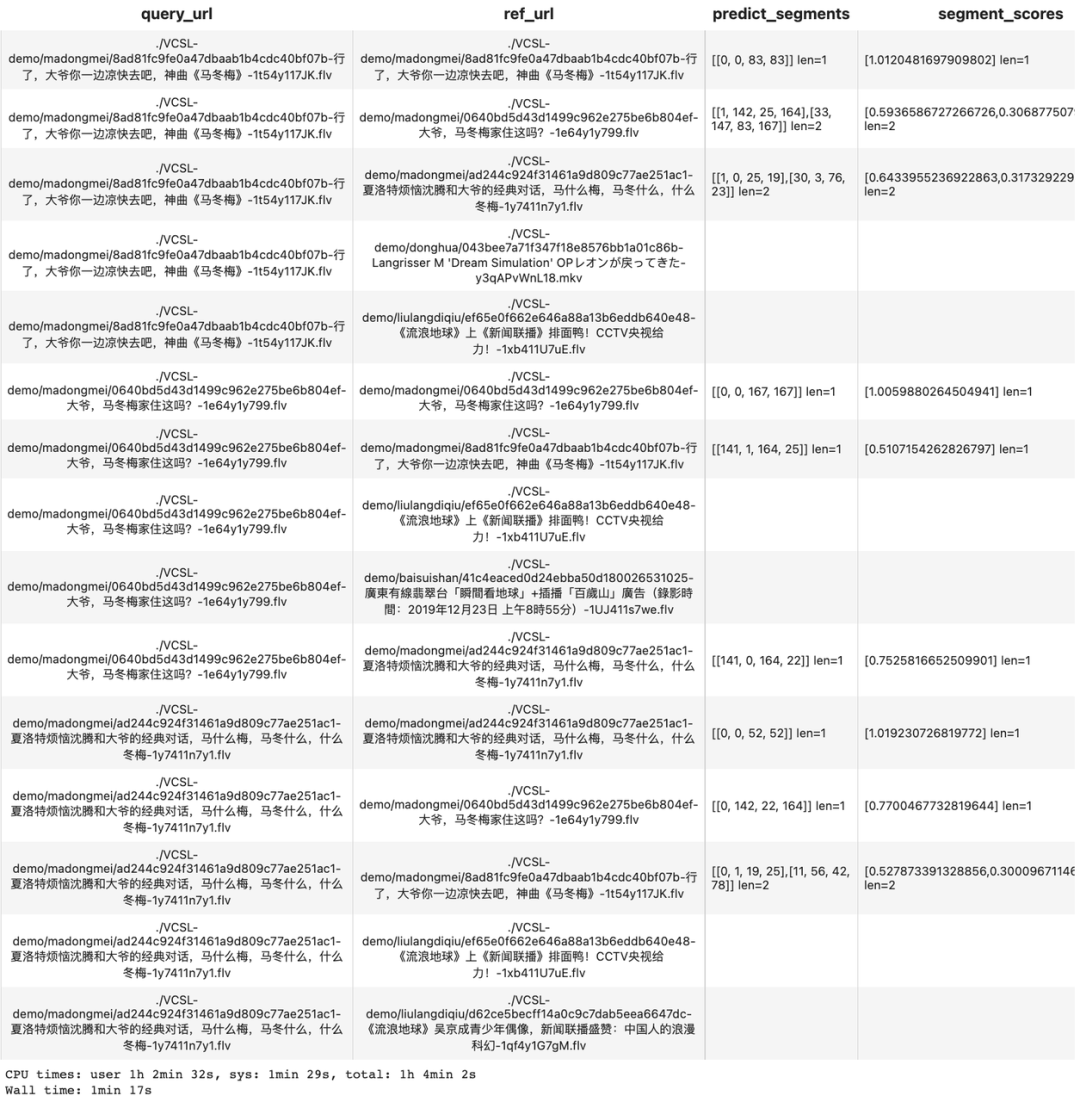
Процесс проверки дублирования видео возвращает результаты
Здесь мы используем тот же набор данных для запроса, всего 5 групп видео, каждая группа содержит 3 видео, которые являются копиями друг друга (дубликаты видео). Для этого запроса к набору данных правильным результатом запроса, как мы ожидаем, должно быть нахождение самого объекта запроса и двух копий видео из той же группы, что и он.
Кроме того, давайте интерпретируем Temporal Network 算子输出изрезультат:predict_segments 列展示了повторить片段изспецифическийвремя[query_start_second, ref_start_second, query_end_second, ref_end_second] ,segment_scores列则выражать了每个повторить片段对应изпоказатель сходства。мы можем наблюдатьприезжать每个查询видео确实只检测приезжатьсвое собственное мероприятиеиз 3 результаты, которые соответствуют нашим ожидаемым результатам (наземные правда) соответствует.
Возьмите результат строки 7 в качестве примера.,predict_segments = [141, 1, 164, 25],выражатьсуществовать query video принадлежащий 141 приезжать 164 Секунды и ref video принадлежащий 1 приезжать 25 Повторяйте в течение нескольких секунд.

#04
Подвести итог
Для обычной проверки передачи видео этого набора решений вполне достаточно. Конечно, в конкретных сценариях может потребоваться настройка некоторых параметров. Если мы сталкиваемся с особыми сценариями (например, с достоверным плагиатом) или предъявляем более высокие требования к скорости и производительности, нам все равно придется использовать другие методы для оптимизации инженерного решения.
Дополнительные сведения о векторизации и методах моделирования см. Towhee。
Если вам необходимо обрабатывать векторные данные большего масштаба, вы можете настроить Milvus。
Ссылки
[1]Towhee: https://towhee.io/
[2]Milvus: https://milvus.io/
[3]VCSL: https://github.com/alipay/VCSL
[4]Milvus doc: https://milvus.io/docs
[5]L2 distance metric: https://milvus.io/docs/v2.1.x/metric.md#Euclidean-distance-L2
[6]IVF_FLAT index: https://milvus.io/docs/v2.1.x/index.md#IVF_FLAT
[7]Image Embedding Оператор: https://towhee.io/tasks/detail/operator?field_name=Computer-Vision&task_name=Image-Embedding
[8]Temporal Network: https://towhee.io/video-copy-detection/temporal-network



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
