[Серия Цзе Шу] Flink интегрирует KafkaSource & Данные о потреблении в реальном времени (10)
01 Введение
Flink предоставил Apache Kafka Connectoruse Exactly-once из существующей семантики Kafka topic серединачитатьиписатьданные。
Фактический адрес исходного кода, доступна загрузка в один клик: https://gitee.com/shawsongyue/aurora.git
Модуль: aurora_flink_connector_kafka
Пример: KafkaSourceStreamingJob02 Зависимость разъема
2.1 Зависимости коннектора Kafka
<!--kafkaполагаться start-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.2-1.18</version>
</dependency>
<!--kafkaполагаться end-->2.2 базовые базовые зависимости
Если эта зависимость не введена, ошибка будет сообщена непосредственно при запуске проекта: Исключение в потоке «main» java.lang.NoClassDefFoundError: org/apache/flink/connector/base/source/reader/RecordEmitter
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.18.0</version>
</dependency>03 Как использовать разъем
Kafka Source Классы сборки предназначены для создания Экземпляр KafkaSource. В следующем фрагменте кода показано, как построить KafkaSource потреблять “input-topic” Данные с самого раннего сайта, Используйте группы потребителей "моя группа" и будет Kafka Тело сообщения десериализуется в строку. 。
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
#Следующие атрибуты существуют build KafkaSource Необходимо указать, когда:
1.Bootstrap сервер, через setBootstrapServers(String) метод Конфигурация
2. Группа потребителей идентификатор, через setGroupId(String) Конфигурация
3. Подписаться из Topic / Partition
4. Используется для разбора Kafka информацияизпротивоположныйсериализацияустройство(Deserializer)04 Подписка на сообщения
Kafka Source предоставляет 3 метода подписки на темы/разделы.
4.1 Подписка на тему
Вы можете подписаться на сообщения из всех разделов в списке тем.
KafkaSource.builder().setTopics("topic-a", "topic-b");4.2 Подписка на регулярные выражения
Подпишитесь на все разделы в теме, соответствующие регулярному выражению.
KafkaSource.builder().setTopicPattern("topic.*");4.3 Подписка на раздел столбца раздела
Подписаться на указанный раздел
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"
new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet);05 Анализ сообщений
1. В коде необходимо предоставить десериализатор (Deserializer) для анализа сообщений Kafka. Десериализатор определяется setDeserializer(KafkaRecordDeserializationSchema), где KafkaRecordDeserializationSchema определяет, как анализировать ConsumerRecord Kafka.
2. Если вам нужны только данные в части тела (значения) сообщения Kafka, вы можете использовать метод setValueOnlyDeserializer(DeserializationSchema) в классе конструкции KafkaSource, где DeserializationSchema определяет, как анализировать двоичные данные в теле сообщения Kafka. .
3. Также доступен Kafka Предоставленный парсер анализировать Kafka тело сообщения. Например, используя StringDeserializer Грядущий генерал Kafka Тело сообщения преобразуется в строку
import org.apache.kafka.common.serialization.StringDeserializer;
KafkaSource.<String>builder()
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));06 Начальная точка потребления
Kafka source Возможность инициализации через сайтустройство(OffsetsInitializer)указать разныеиз Смещение начинает потреблять
KafkaSource.builder()
// Начать потребление с позиции из, представленной группой потребителей, без указания стратегии сброса позиции.
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// Потребление начинается с позиции, представленной группой потребителей. Если представленная позиция не существует, используется самая ранняя позиция.
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// Начинайте потреблять, когда временная метка больше или равна указанной временной метке (в миллисекундах).
.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))
// Начать потребление с самой ранней позиции, использовать по умолчанию
.setStartingOffsets(OffsetsInitializer.earliest())
// Начните потреблять с последней позиции
.setStartingOffsets(OffsetsInitializer.latest());07 Ограниченный/неограниченный режим
7.1 Потоковая передача
При работе в режиме потоковой передачи вы также можете указать точку остановки использования, используя setUnbounded(OffsetsInitializer)`. Когда все разделы достигнут указанного смещения остановки, Kafka Source завершит операцию.
7.2 Тип партии
Вы можете использовать setBounded(OffsetsInitializer), чтобы указать смещение остановки, чтобы источник Kafka запускался в пакетном режиме. Kafka Source завершает работу, когда все разделы достигают смещения остановки.
08 Другие атрибуты
Произвольные свойства могут быть установлены для Kafka Source и Kafka Consumer с помощью setProperties(Properties) и setProperty(String, String).
8.1 Элементы конфигурации KafkaSource
(1)client.id.prefix
Укажите префикс идентификатора клиента, который будет использоваться для потребителей Kafka.
(2)partition.discovery.interval.ms
Определите интервал времени, в течение которого Kafka Source проверяет наличие новых разделов.
(3)register.consumer.metrics
Индикаторы, указывающие, регистрировать ли Kafka Consumer во Flink
(4)commit.offsets.on.checkpoint
Укажите, следует ли отправлять сайт потребления брокеру Kafka во время контрольной точки.
8.2 Элементы потребительской конфигурации Kafka
(1) key.deserializer
Всегда установлено значение ByteArrayDeserializer.
(2) value.deserializer
Всегда установлено значение ByteArrayDeserializer.
(3) auto.offset.reset.strategy
Переопределяется OffsetsInitializer#getAutoOffsetResetStrategy()
(4) partition.discovery.interval.ms
будет перезаписано на -1 в пакетном режиме
09 Динамическая проверка разделов
Чтобы обрабатывать такие сценарии, как расширение темы или создание новой темы, без перезапуска задания Flink, Kafka Source настроен на периодическую проверку наличия новых разделов в предоставленном режиме подписки «Тема/раздел». Чтобы включить динамическую проверку разделов, задайте для раздела part.discovery.interval.ms неотрицательное значение:
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000"); // Каждый 10 Проверяйте новые разделы каждую секунду10 Время события и водяной знак
По умолчанию Kafka Source использует метку времени в сообщении Kafka в качестве времени события. Вы можете определить свою собственную стратегию водяных знаков, чтобы извлечь время события из сообщения и отправить водяной знак дальше по течению.
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy");11 Представление места потребления
Kafka source существовать checkpoint ЗаканчиватьОтправить текущийизместо потребления , чтобы обеспечить Flink из checkpoint статус и Kafka broker Сайт подачи выше соответствует. Если не включен checkpoint,Kafka source зависит от Kafka consumer Внутренняя логика автоматической отправки по времени на сайте, функция автоматической отправки обеспечивается enable.auto.commit и auto.commit.interval.ms два Kafka consumer Настройте элементы конфигурации.
Примечание: Кафка source не зависит отВ broker При фиксации сайта для восстановления не удалось выполнить задание. Отправка сайтов — это всего лишь вопрос отчетности. Kafka consumer Группа потребления из Прогресс потребления, чтобы существовать broker терминал для мониторинга.
12 Мониторинг
12.1 Диапазон индикатора
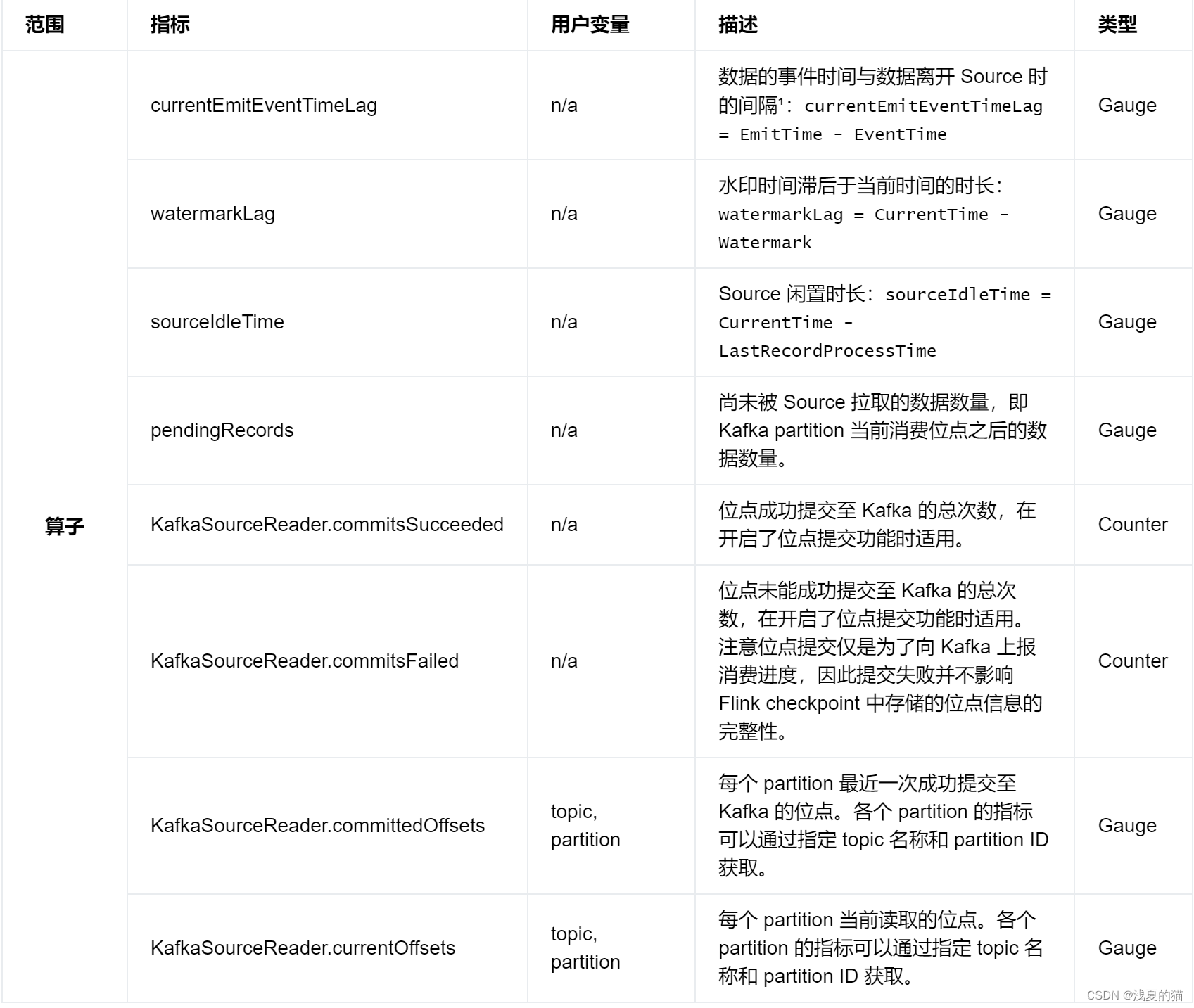
12.2 Потребительские метрики Kafka
Kafka consumer извсеиндекс Все зарегистрированысуществоватьиндекс Группа KafkaSourceReader.KafkaConsumer Вниз. Например Kafka consumer изиндекс records-consumed-total Волясуществовать Должен Flink Об этом сообщается в индикаторе: .operator.KafkaSourceReader.KafkaConsumer.records-consumed-total。
Вы можете использовать элементы конфигурации register.consumer.metrics Настройте, регистрироваться ли Kafka consumer изиндекс . По умолчанию эта опция установлена на true。
о Kafka consumer изиндекс, вы можете обратиться к Apache Kafka документ Узнайте больше подробностей.
13 Сертификация безопасности
1. Включение шифрования и аутентификации, связанных с безопасностью. Конфигурация,Только Воля Безопасность Конфигурациякак Другие объекты недвижимости Конфигурациясуществовать Kafka source Просто поднимитесь. В следующем фрагменте кода показано, как настроить конфигурацию. Kafka source использовать PLAIN как SASL механизм и обеспечить JAAS Конфигурация
KafkaSource.builder()
.setProperty("security.protocol", "SASL_PLAINTEXT")
.setProperty("sasl.mechanism", "PLAIN")
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";");2.Используйте SASL_SSL как Безопасностьпротоколииспользовать SCRAM-SHA-256 как SASL механизм 。 еслисуществовать Операция JAR середина Kafka Зависимости клиента из сброса пути к классам (переместить класс), модуль входа (login модуль) из пути к классам может отличаться, поэтому войдите в модуль в соответствии с его существованием. JAR серединаактуал из пути к классам, чтобы переписать приведенную выше конфигурацию
KafkaSource.builder()
.setProperty("security.protocol", "SASL_SSL")
// SSL Конфигурация
// Конфигурация сервера обеспечивает truststore (CA Сертификат) из пути
.setProperty("ssl.truststore.location", "/path/to/kafka.client.truststore.jks")
.setProperty("ssl.truststore.password", "test1234")
// Конфигурация необходима, если требуется аутентификация клиента. keystore (закрытый ключ) из пути
.setProperty("ssl.keystore.location", "/path/to/kafka.client.keystore.jks")
.setProperty("ssl.keystore.password", "test1234")
// SASL Конфигурация
// Воля SASL механизм Конфигурациядля as SCRAM-SHA-256
.setProperty("sasl.mechanism", "SCRAM-SHA-256")
// Конфигурация JAAS
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";");14 Принцип реализации исходного кода Kafka
Разделение источника
Исходный код Kafka Исходные точки (разделение исходного кода) означает, что тема Kafka разделена на один раздел. Исходный код Kafka Исходные точки включает в себя:
- Должен фрагментарное представление из topic и partition
- Должен раздел стартового сайта
- Должен partition остановить сайт, когда source Применимо при работе в пакетном режиме существования.
Kafka source Осколок состояния хранится одновременно Должен partition изтекущийместо потребления,Должен Статус шардинга Волявстречасуществовать Kafka читатель исходников (источник читатель) делает снимок час Волятекущийместо потреблениядержатьдляотправная точка потребленияк Воля Статус шардинга Преобразовать в неизменяемыйиз Шардинг。
Доступно для просмотра KafkaPartitionSplit и KafkaPartitionSplitState класс для подробностей.
Разделенный перечислитель
Kafka source перечислитель из шарда отвечает за проверку текущего существования из topic / partition В режиме подпискиизновый Шардинг(partition),и Воля Шардинг Распределить поровну междучитатель исходников (источник reader)。 Уведомление Kafka source из Шардингперечислятьустройствовстреча Воля Шардинг Активно подталкивайте кисточникчитатьустройство,Поэтому ему не нужно обрабатывать запросы осколков от читателя исходного кода.
Читатель исходного кода
Kafka source расширенная версия Source Reader SourceReaderBase,ииспользовать Повторное использование одного потока(single thread мультиплекс) из потоковой модели, используйте один с помощью шардированного считывателя (split читатель) водитель из KafkaConsumer для обработки нескольких разделов. Новости будут существовать из Kafka После его удаления программа чтения фрагментов середина немедленно его анализирует. Статус шардинга То есть текущий прогресс потребления сообщений будет существовать. KafkaRecordEmitter середина обновляется, а существующие отправляются в нисходящем направлении в указанное время события.
Практическая демонстрация исходного кода 15 проектов
15.1 Структура пакета

15.2 Введение зависимостей
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xsy</groupId>
<artifactId>aurora_flink_connector_kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<!--Настройки недвижимости-->
<properties>
<!--java_JDKВерсия-->
<java.version>11</java.version>
<!--mavenПлагин упаковки-->
<maven.plugin.version>3.8.1</maven.plugin.version>
<!--Скомпилированная кодировкаUTF-8-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!--Кодировка выходного отчетаUTF-8-->
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<!--jsonданные Инструменты обработки форматов-->
<fastjson.version>1.2.75</fastjson.version>
<!--log4jВерсия-->
<log4j.version>2.17.1</log4j.version>
<!--flinkВерсия-->
<flink.version>1.18.0</flink.version>
<!--scalaВерсия-->
<scala.binary.version>2.11</scala.binary.version>
</properties>
<!--Универсальныйполагаться-->
<dependencies>
<!-- json -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!--================================Интегрируйте внешниеполагаться==========================================-->
<!--Интегрированная система ведения журналов start-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
</dependency>
<!--Интегрированная система ведения журналов end-->
<!--kafkaполагаться start-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.2-1.18</version>
</dependency>
<!--kafkaполагаться end-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.18.0</version>
</dependency>
</dependencies>
<!--Компилируем и упаковываем-->
<build>
<finalName>${project.name}</finalName>
<!--Упаковка файлов ресурсов-->
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml</include>
</includes>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:force-shading</exclude>
<exclude>org.google.code.flindbugs:jar305</exclude>
<exclude>org.slf4j:*</exclude>
<excluder>org.apache.logging.log4j:*</excluder>
</excludes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.aurora.KafkaStreamingJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<!--Единое управление плагинами-->
<pluginManagement>
<plugins>
<!--mavenПлагин упаковки-->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
<configuration>
<fork>true</fork>
<finalName>${project.build.finalName}</finalName>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<!--компилировать Плагин упаковки-->
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>${maven.plugin.version}</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>UTF-8</encoding>
<compilerArgs>
<arg>-parameters</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<!--КонфигурацияMavenпроектсерединануждатьсяиспользоватьиз Удаленный склад-->
<repositories>
<repository>
<id>aliyun-repos</id>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<!--используется для Конфигурацияmavenплагиниз Удаленный склад-->
<pluginRepositories>
<pluginRepository>
<id>aliyun-plugin</id>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</project>15.3 Создание файла конфигурации
(1)application.properties
Адрес кластера #kafka
kafka.bootstrapServers=localhost:9092
#kafkaconsumergroup
kafka.group=aurora_group(2)log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp15.4 Создание задания коннектора Kafka
package com.aurora;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.KafkaSourceBuilder;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.OffsetResetStrategy;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashSet;
import java.util.regex.Pattern;
/**
* @author Легкое лето из кота
* @description kafka Коннекториспользуетдемонстрационное задание
* @datetime 22:21 2024/2/1
*/
public class KafkaSourceStreamingJob{
private static final Logger logger = LoggerFactory.getLogger(KafkaStreamingJob.class);
public static void main(String[] args) throws Exception {
//==============1. Получить параметры========================== = =
//определение пути к файлу
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink_connector_kafka\\src\\main\\resources\\application.properties";
//Метод 1: напрямую обращаться к встроенному классу инструмента
ParameterTool paramsMap = ParameterTool.fromPropertiesFile(propertiesFilePath);
//===============2. Инициализируем параметры Кафки========================. = ===
String bootstrapServers = paramsMap.get("kafka.bootstrapServers");
String topic = paramsMap.get("kafka.topic");
String group = paramsMap.get("kafka.group");
//=================3.Создать Кафкуданныеисточник============================= KafkaSourceBuilder<String> kafkaSourceBuilder = KafkaSource.builder();
//(1)Установим адрес Кафки
kafkaSourceBuilder.setBootstrapServers(bootstrapServers);
//(2)Устанавливаем потребление этой группы идентификаторов
kafkaSourceBuilder.setGroupId(group);
//(3)Устанавливаем тему и поддерживаем несколько добрых комбинаций тем
setTopic(kafkaSourceBuilder);
//(4)Устанавливаем режим потребления и поддерживаем несколько добрых режимов потребления
setStartingOffsets(kafkaSourceBuilder);
//(5)Установим устройство антисериализации
setDeserializer(kafkaSourceBuilder);
//(6)Создаем все параметры
KafkaSource<String> kafkaSource = kafkaSourceBuilder.build();
//(7) Динамическая проверка нового раздела, 10 Проверяйте новые разделы каждую секунду
kafkaSourceBuilder.setProperty("partition.discovery.interval.ms", "10000");
//=================4. Создайте рабочую среду Flink=================.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> dataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source");
//==================5.данные Простая обработка=====================
dataStreamSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String record, Collector<String> collector) throws Exception {
logger.info("толькосуществоватьиметь дело сkafkaданные:{}", record);
}
});
//=================6. Запускаем сервис=======================. === ==============
env.execute();
}
/**
*
* @description Настройки режима темы
* 1. Установите одну тему
* 2. Установите несколько тем.
* 3. Установите список тем.
* 4. Установите тему соответствия регулярным выражениям.
* 5. Подписаться на указанный раздел Раздел
*
* @author Легкое лето из кота
* @datetime 21:18 2024/2/5
* @param kafkaSourceBuilder
*/
private static void setTopic(KafkaSourceBuilder<String> kafkaSourceBuilder) {
//Композиция 1: установка одной темы
kafkaSourceBuilder.setTopics("topic_a");
//Комбо 2: установить несколько тем
// kafkaSourceBuilder.setTopics("topic_a", "topic_b");
//Композиция 3: Установить список тем
// kafkaSourceBuilder.setTopics(Arrays.asList("topic_a", "topic_b"));
// Комбинация 4: установка темы соответствия регулярному выражению
// kafkaSourceBuilder.setTopicPattern(Pattern.compile("topic_a.*"));
//Комбинация 5: подписаться на указанный раздел раздела, указать, какой раздел использовать тему, а также поддерживает использование нескольких тем и нескольких разделов.
// final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(new TopicPartition("topic_a", 0), new TopicPartition("topic_b", 4)));
// kafkaSourceBuilder.setPartitions(partitionSet);
}
/**
* @description структура потребления
* 1.Начать потребление с позиции из, представленной группой потребителей, без указания стратегии сброса позиции.
* 2.Потребление начинается с позиции, представленной группой потребителей. Если представленная позиция не существует, используется самая ранняя позиция.
* 3.Начинайте потреблять, когда временная метка больше или равна указанной временной метке (в миллисекундах).
* 4. Начать потребление с самого раннего положения.
* 5.Начните потреблять с последней позиции,То есть потребление начинается с момента регистрации
*
* @author Легкое лето из кота
* @datetime 21:27 2024/2/5
* @param kafkaSourceBuilder
*/
private static void setStartingOffsets(KafkaSourceBuilder<String> kafkaSourceBuilder){
//Режим 1: Начать потребление с позиции из, представленной группой потребителей, без указания стратегии сброса позиции.,Эта добрая стратегия сообщит об исключения, Не установлен моментальный снимок или смещение автоматической фиксации: вызвано by: org.apache.kafka.clients.consumer.NoOffsetForPartitionException: Undefined offset with no reset policy for partitions: [topic_a-3]
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.committedOffsets());
//модель2:Потребление начинается с позиции, представленной группой потребителей. Если представленная позиция не существует, используется самая ранняя позиция.
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST));
//модель3:Начинайте потреблять, когда временная метка больше или равна указанной временной метке (в миллисекундах).
kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L));
//Режим 4: Начать потребление с самой ранней позиции
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.earliest());
//модель5:Начните потреблять с последней позиции,То есть потребление начинается с момента регистрации
// kafkaSourceBuilder.setStartingOffsets(OffsetsInitializer.latest());
}
/**
* @description Настройте десериализатор для поддержки нескольких добрых методов десериализации.
* 1.сопределение Как разобратьkafkaданные * 2.ИспользуйтеKafka Предоставленный парсеробработка
* 3. Устанавливайте только обратную сериализацию kafkaizvalue.
*
* @author Легкое лето из кота
* @datetime 21:35 2024/2/5
* @param kafkaSourceBuilder
*/
private static void setDeserializer(KafkaSourceBuilder<String> kafkaSourceBuilder){
//1.сопределение Как разобратьkafkaданные// KafkaRecordDeserializationSchema<String> kafkaRecordDeserializationSchema = new KafkaRecordDeserializationSchema<>() {
// @Override
// public TypeInformation<String> getProducedType() {
// return TypeInformation.of(String.class);
// }
//
// @Override
// public void deserialize(ConsumerRecord<byte[], byte[]> consumerRecord, Collector<String> collector) throws IOException {
// //сопределениеанализироватьданные
// byte[] valueByte = consumerRecord.value();
// String value = new String(valueByte);
// //Отправить сообщение
// collector.collect(value);
// }
// };
// kafkaSourceBuilder.setDeserializer(kafkaRecordDeserializationSchema);
//2.ИспользуйтеKafka Предоставленный парсеробработка
// kafkaSourceBuilder.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
//3. Устанавливайте только обратную сериализацию kafkaizvalue.
kafkaSourceBuilder.setValueOnlyDeserializer(new SimpleStringSchema());
}
}5.1 Проверка сочетаний тем
1. Информацию о конструкции Kafka можно найти в другом моем блоге: https://blog.csdn.net/weixin_40736233/article/details/136002105.
2. Использованиеkafka создает две темы: theme_a, theme_b, 1 копию и 5 разделов (скрипт среды Windows — .bat, среда Linux — .sh).
#Создать тему
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 5 --topic topic_a
kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 5 --topic topic_b
#тема запроса
kafka-topics.bat --bootstrap-server localhost:9092 --list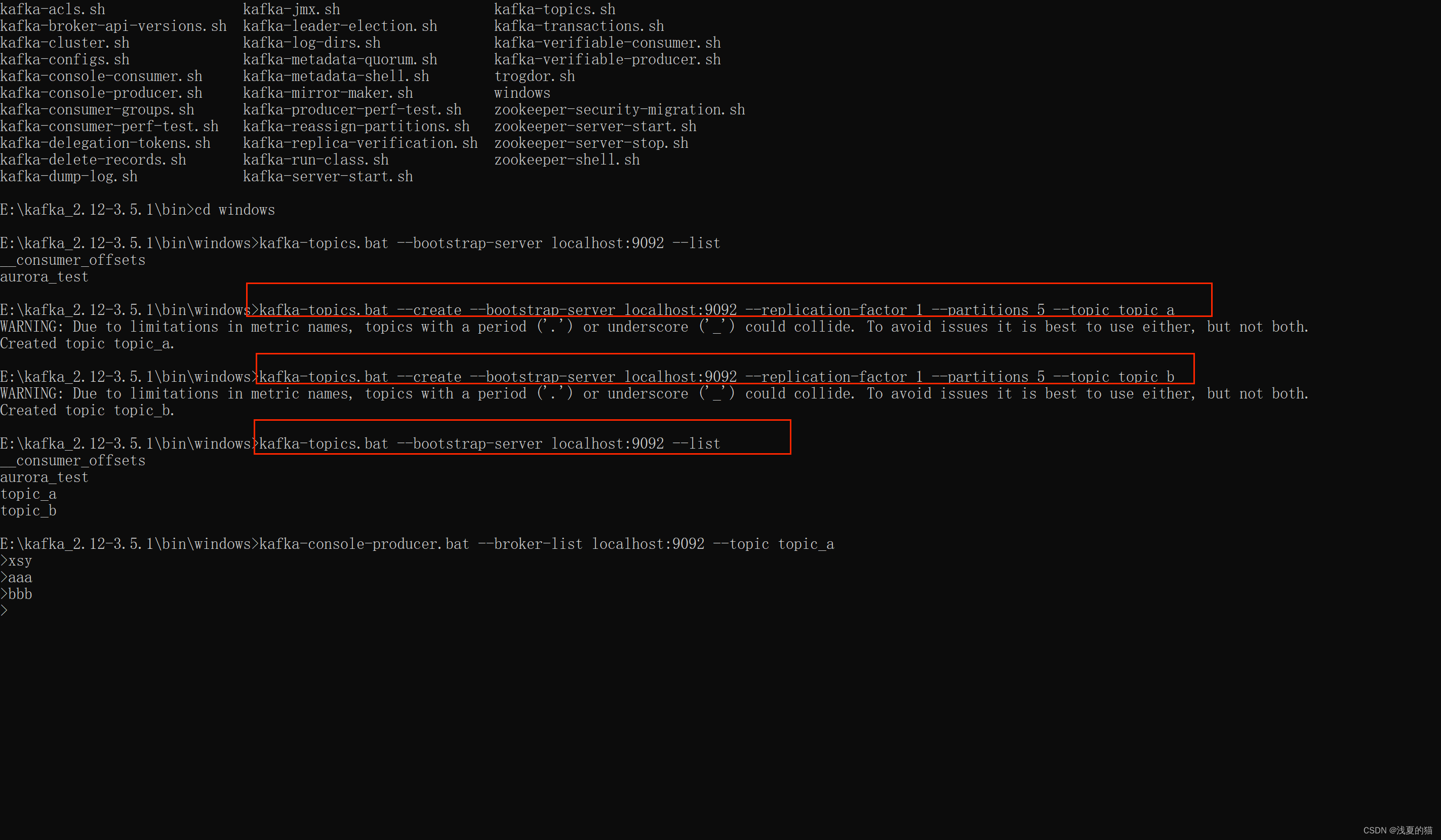
(1) Комбинация 1. Настройка потребления по одной теме.
Запустите потребление программы Flink и запустите продюсера с помощью команды kafka. Имитировать генерацию данных
#Стартовый продюсер
kafka-console-producer.bat --broker-list localhost:9092 --topic topic_a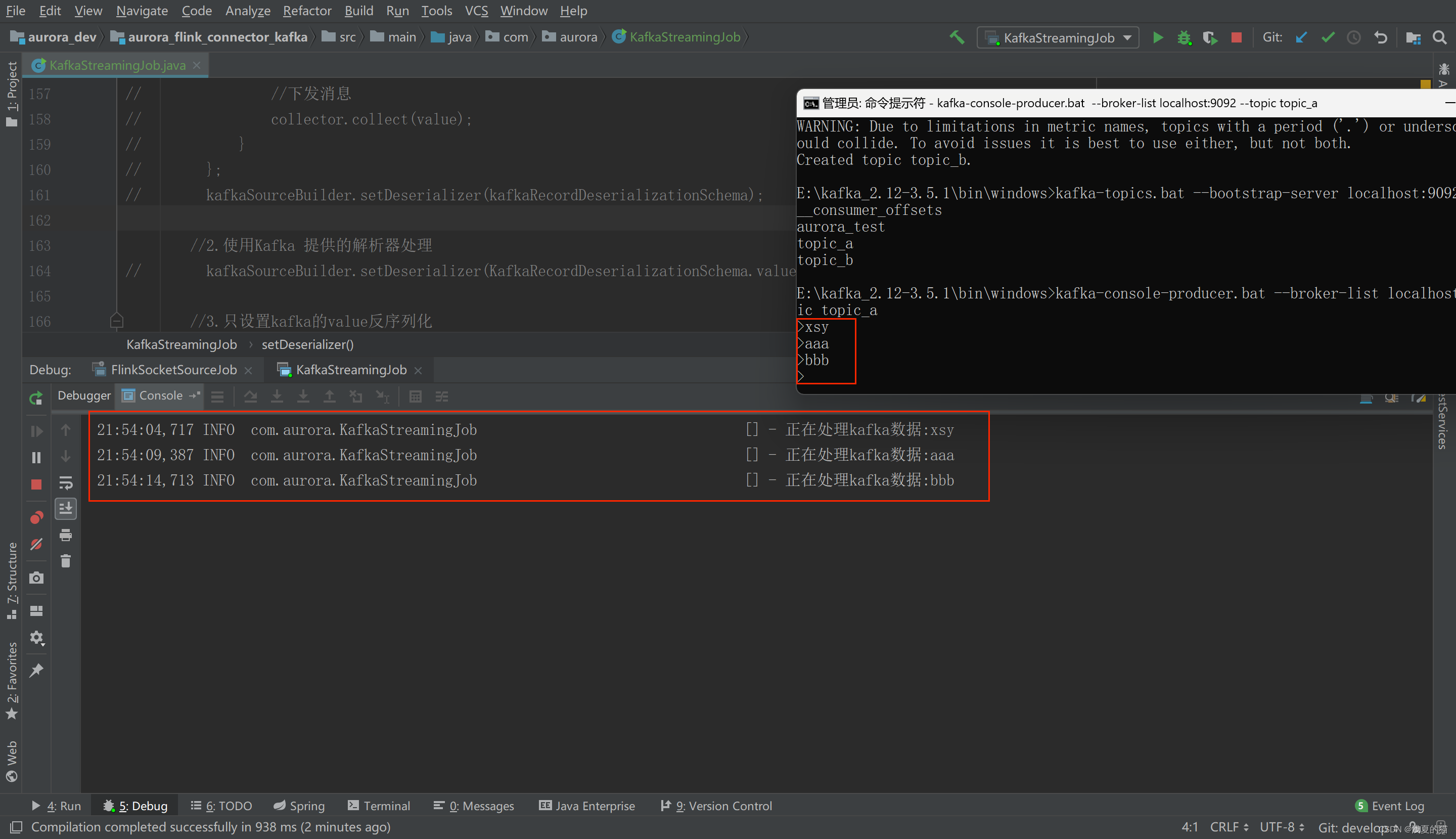
(2) Комбинация 2: установка нескольких тем
#Отпустите комбинацию комментариев 2 из кода
Запустите потребление программы Flink и запустите продюсера с помощью команды kafka. Имитировать генерацию данных
#Запускаем два производителя и создаём темы Topic_a и Topic_bданные соответственно
kafka-console-producer.bat --broker-list localhost:9092 --topic topic_a
kafka-console-producer.bat --broker-list localhost:9092 --topic topic_b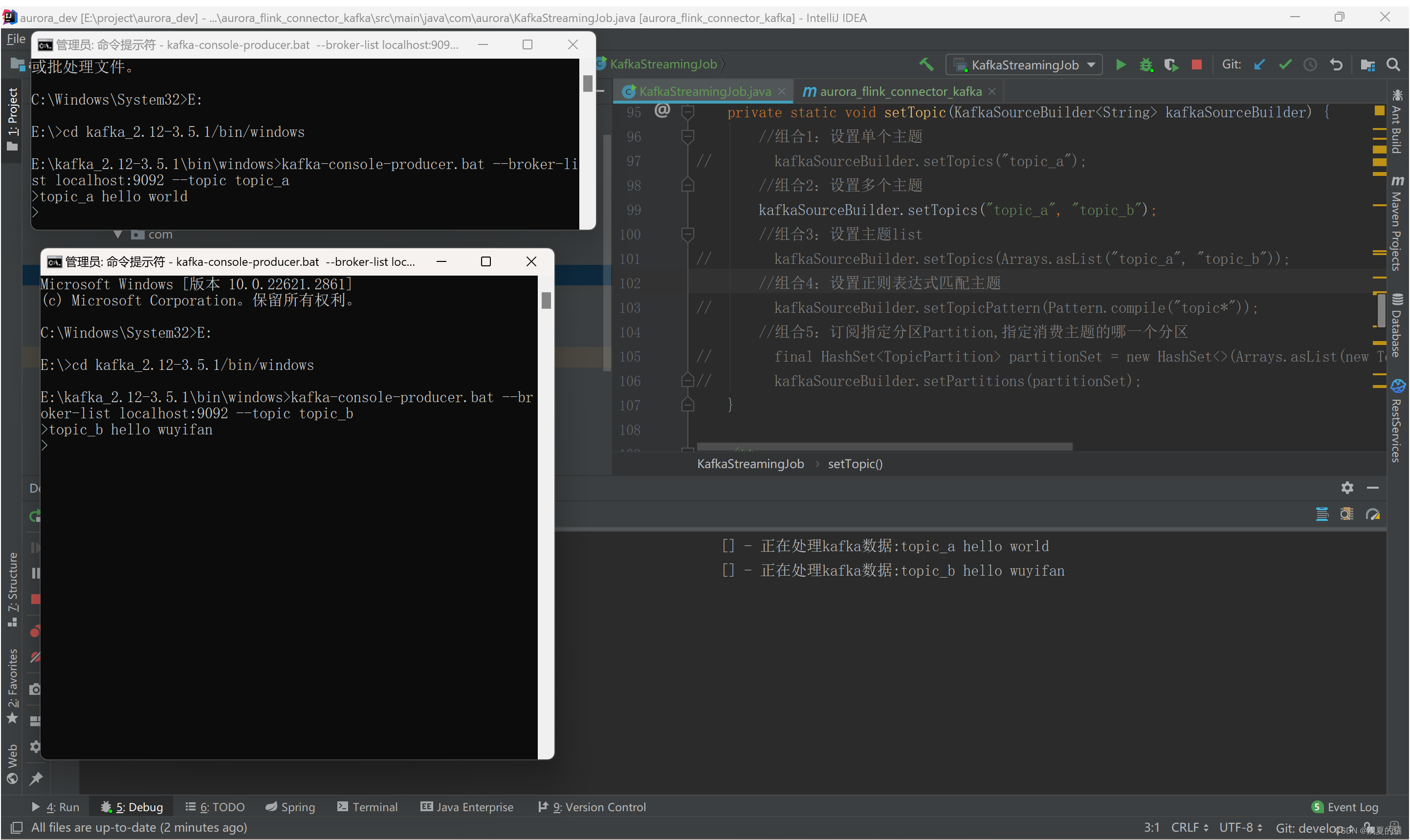
(3) Комбинация 3: Установите список тем, действуйте, как на шаге (2).
(4) Комбинация 4. Установите тему соответствия регулярным выражениям,
Подписывайтесь только на все разделы темы_a, не подписывайтесь на тему_b, программа будет использовать только тему_а.,Не будет использовать theme_b
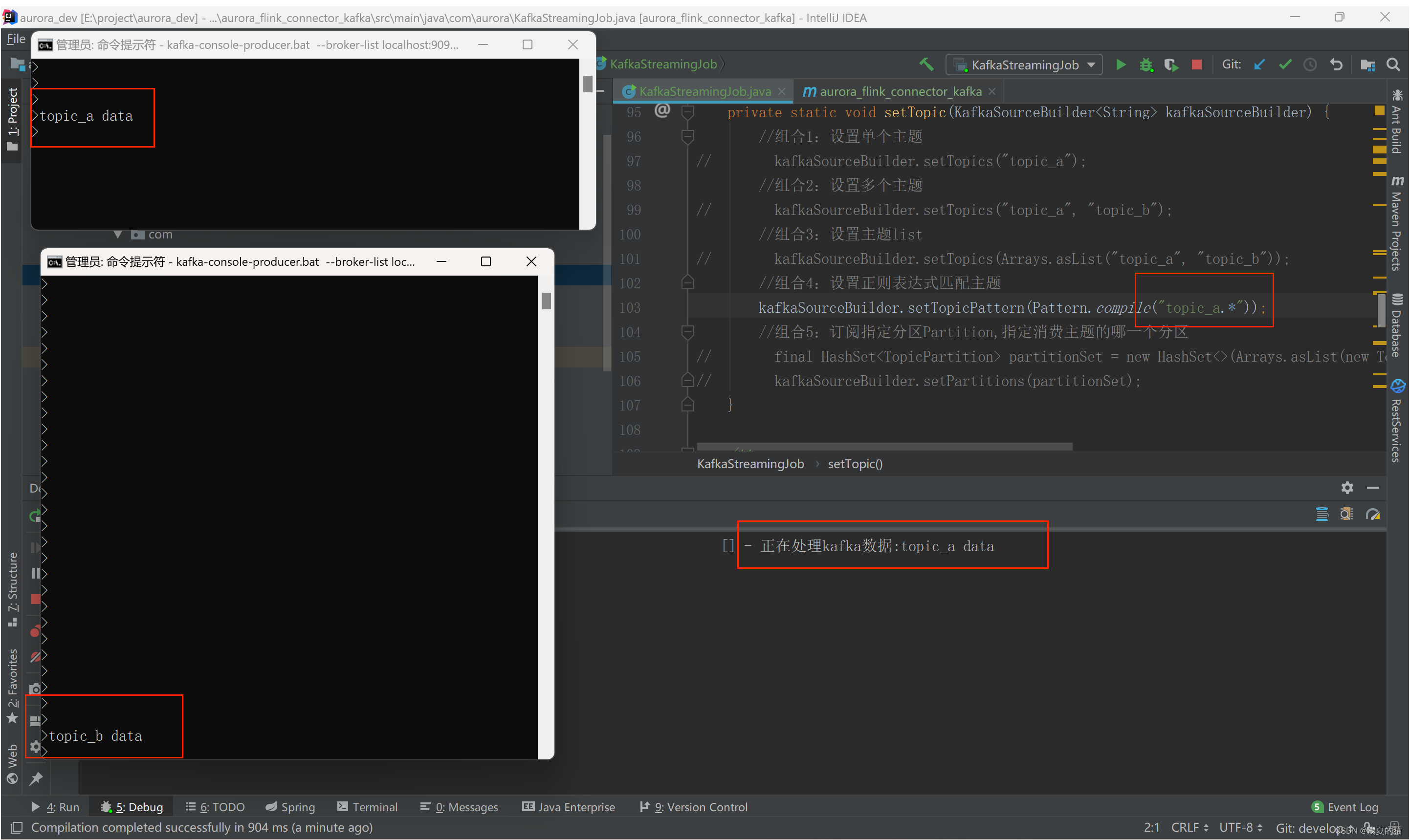
(5) Комбинация 5: Подписаться на указанный раздел Раздел и указать, какой раздел темы потребления
#Проверяем, в какой раздел попало сообщение,Попадание в раздел существования0 поглотит,Других разделов нет
./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic theme_a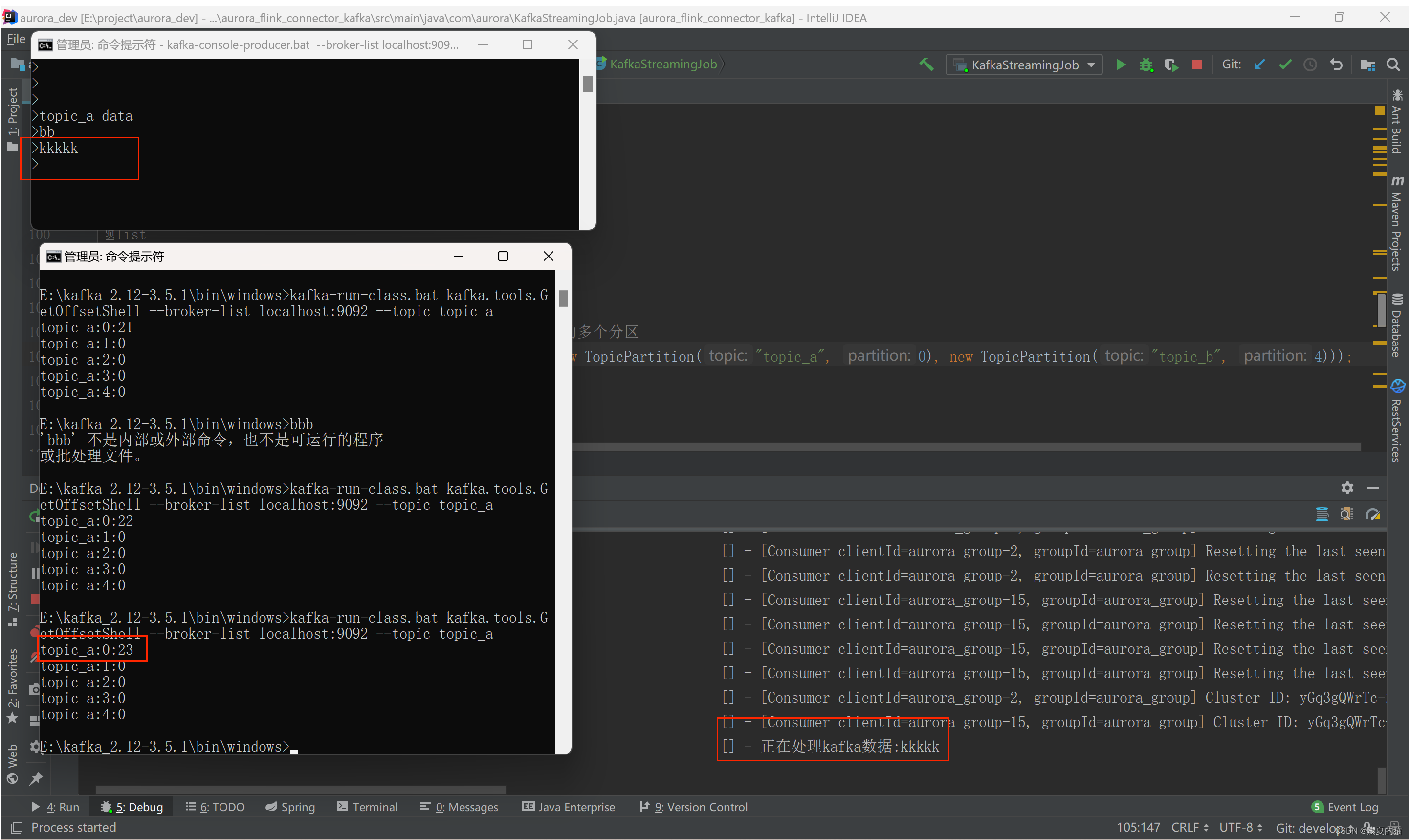



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
