Серия технических решений NL2SQL (1): NL2API, выбор технического пути NL2SQL; выбор LLM и навыки оперативного проектирования, раскрывающие пути оптимизации реализации проекта;
Серия технических решений NL2SQL (1): NL2API, выбор технического пути NL2SQL; выбор LLM и навыки оперативного проектирования, раскрывающие пути оптимизации реализации проекта;
Серия практик NL2SQL (1): Углубленный анализ навыков применения проекта Prompt в text2sql.
1. Введение в NL2SQL и интеллектуальный анализ данных больших моделей.
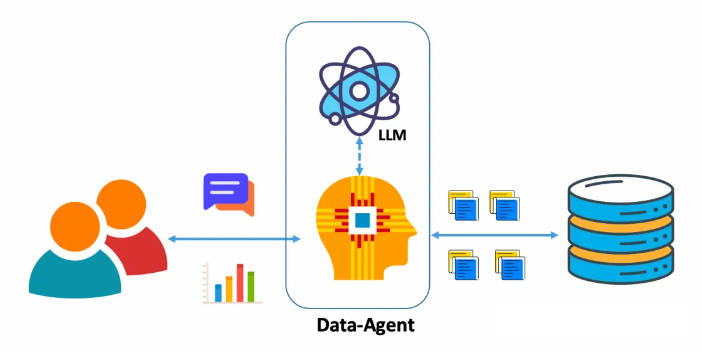
Цель задачи NL2SQL — преобразовать вопросы пользователей о базе данных на естественном языке в соответствующие запросы SQL. С развитием LLM использование LLM для NL2SQL стало новой парадигмой. В этом процессе особенно важно то, как использовать быстрые проекты для изучения возможностей LLM NL2SQL.
Текущая ситуация: хотя большие языковые модели становятся все более мощными в непрерывном итерационном процессе, приложения корпоративного уровня, такие как бизнес-аналитика, гораздо сложнее, чем анализ файла Excel и обобщение файла PDF:
- Структура данных сложна.:информационная система предприятияиз Структура данных сложна.Секс – это гораздо больше, чем несколько простых из Excel файлы, крупное корпоративное приложение может иметь сотни или тысячи объектов данных, поэтому в реальных приложениях большие BI Система будет агрегирована, упрощена и абстрагирована на новый семантический уровень на внешней стороне для облегчения понимания.
- Большой объем данных:Аналитические приложения в основном ориентированы на большие исторические данные.,Даже некоторые данные перед анализом проходят несколько уровней агрегирования. Это определяет, что данные невозможно просто перевести в файлы для анализа и обработки в корпоративных приложениях.
- Потребности в анализе сложны:Корпоративные приложенияиз Потребности в анализе данных включают своевременный запрос、Отображение отчетов и показателей в различных измерениях、Детализация данных вверх и вниз、потенциальная информацияиз Раскопки и т. д.,Многие требования имеют более сложную логику внутренней обработки.
Эти характеристики определяют, что нынешнее применение больших языковых моделей в анализе корпоративных данных не может быть полностью заменено. настоящий моментвсеизили частьиз Инструменты анализа。это уместноиз Позиционирование может быть:В качестве эффективного дополнения к существующим методам анализа данных он предоставляет лицам, принимающим бизнес-решения, инструмент анализа, который проще использовать и взаимодействовать в некоторых сценариях спроса.
Конкретные сценарии применения включают в себя:
- Своевременный запрос данных。Предоставить оперативные или статистические данныеиз Простой пользовательский запрос,Конечно, вы просто используете естественный язык.
- Обновление возможностей традиционных инструментов BI.много Традиция BI Инструмент будет определять абстрактный семантический слой, одно из его значений — сделать анализ данных более удобным для бизнес-персонала. Большие модели естественным образом обладают сильными возможностями семантического понимания, поэтому Традиция BI Вполне естественно, что некоторые из его функций эволюционируют в интерактивный анализ, основанный на естественном языке.
- Простой анализ данных и аналитика.в некоторых сценарияхиз Интерактивный анализ данных и аналитика,Можно использовать большие языковые модели.из Code Генеративные возможности и алгоритмы позволяют обнаруживать скрытые закономерности в данных.
1.1 Знакомство с тремя основными техническими решениями
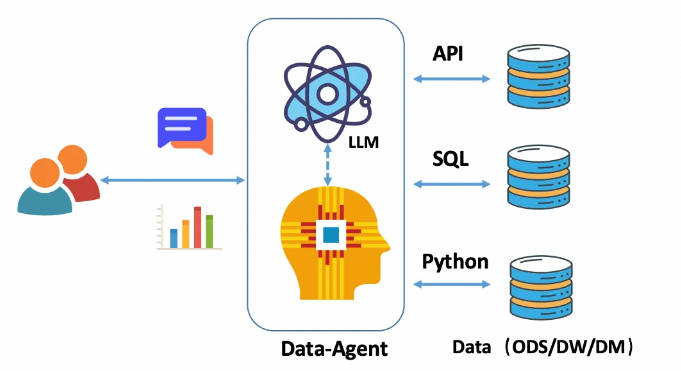
- API анализа данных с естественного языка, text2API
Некоторые существующие инструменты BI открывают независимые API на основе собственных семантических уровней для расширения приложений. Таким образом, это естественный способ преобразования естественного языка в вызовы этих API анализа данных. Конечно, вы также можете реализовать этот уровень API самостоятельно.
Особенностью этого решения является то, что оно ограничено уровнем API, который мы проанализируем позже.
- Естественный язык для реляционной базы данных SQL, text2SQL
Это также одна из возможностей большой модели, которая в настоящее время привлекает наибольшее внимание (по сути тоже специальная текст2код). потому что SQL является относительно стандартизированнымизязык запросов к базе данных,И он полностью интерпретируется и выполняется самой базой данных.,поэтому ПучокПреобразование естественного языка в SQL — самое простое и разумное решение с кратчайшим путем реализации.。
- Код естественного языка для анализа данных, а именно text2Code.
То есть решение интерпретатора кода. Проще говоря, это позволить ИИ написать свой собственный код (обычно Python), а затем автоматически запустить его локально или в «песочнице» для получения результатов анализа. Конечно, большинство современных интерпретаторов кода предназначены для анализа и обработки локальных данных (например, файлов CSV). Поэтому при работе с данными в базах данных в корпоративных приложениях необходимо учитывать особые соображения в сценариях использования.
2. Решение 1: text2API
Используйте следующий рисунок, чтобы представить общую архитектуру решения text2API:
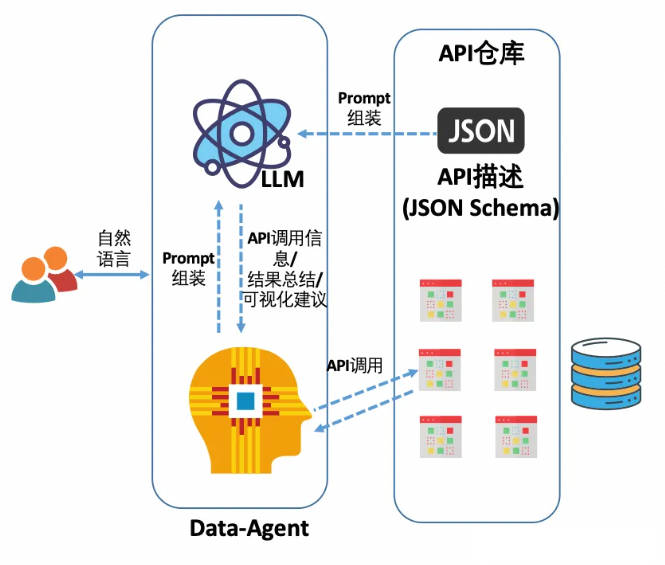
Основной процесс
- Прежде всего, вам необходимо определить четко определенный интерфейс API для анализа данных (например, открытый API существующей системы BI). Он должен быть полностью спроектирован и реализован в соответствии с соответствующими бизнес-условиями, чтобы сформировать «инструкцию по использованию API». руководство» (описание схемы JSON, то есть в описании инструмента «Инструменты агента»).
- Пользователь вводит естественный язык, и система использует LLM для преобразования входных вопросов пользователя в вызовы инструментов API, включая имя API и извлеченные параметры.
- Вызовите указанный API на основе ответа LLM, чтобы получить возвращенные данные. В зависимости от ситуации в некоторых сценариях может потребоваться добавить возвращенные данные к пользовательскому вводу и снова передать их в LLM, и LLM выведет окончательный ответ на результаты анализа клиента.
2.1 Вопрос 1: Обсуждение реализации Text2API
Как реализовать возможности text2API в больших языковых моделях? Поскольку это специальный API для частного корпоративного приложения, он не может полагаться на некоторые модели text2Tool, обученные на общедоступных API в Интернете.
- Как правило, вам необходимо использовать проект подсказки, чтобы модель большого языка реализовала это преобразование за вас, например, такую подсказку:
"""
Пожалуйста, соблюдайте следующие требования и ограничения:
1. Обратитесь к следующему списку инструментов, чтобы найти инструмент, который вам нужно использовать, и выведите следующее содержимое в формате JSON, чтобы использовать этот инструмент. Обратите внимание, что следующий контент появляется в выводе только один раз:
{"api_calls":[{"name":name of tool,"args":{"arg1":value1,"arg2":value2...}}]}
2. Пожалуйста, в соответствии с инструментом определения с параметрами описывать для генерации текста вызова, Эталонные случаи следующие:
Список инструментов:
[
{
"name": "get_current_weather",
"description": «Получить текущую информацию о погоде для данного места»,
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": «Нужно проверить погоду и город»
}
},
"required": ["location"]
}
}
],
Пользовательский ввод: Запросить погоду в Пекине
Текст обратного вызова в формате JSON:
{"api_calls":[{"name":"get_current_weather","args":{"location":"Beijing"}}]}
3. Если вы не можете понять намерения пользователя, ответьте: «Я не могу понять ваши намерения».
4. Пожалуйста, в соответствии Вопросы пользователя и контекст для анализа и извлечения содержимого параметра, необходимого для вызова этого инструмента.
5. Непосредственно выведите приведенный выше результат JSON без каких-либо ненужных объяснений.
Контекст:
{context}
Список инструментов:
{tools}
Вопрос пользователя:
{question}
"""После использования LLM для преобразования естественного языка в вызовы и параметры API, анализируя выходные данные, мы можем вызвать соответствующий API для получения результатов. Конечно, фактическое использование требует тщательной настройки и повторного тестирования Prompt для проверки точности и стабильности.
2.2 Проблема 2: слишком много корпоративных API
В крупномасштабных корпоративных прикладных системах BI требования к анализу данных могут быть очень сложными, и даже если учитывать только часть требований, количество потенциальных API может быть очень большим. Из-за того, что большие языковые модели не имеют состояния, каждый раз, когда мы вводим пользовательский вопрос, нам теоретически необходимо иметь всю спецификацию API. Это может привести к тому, что контекст превысит максимально допустимое количество токенов модели.
- Одним из возможных решений является: С помощью возможности семантического поиска в векторной базе данных все инструменты, то есть API, фильтруются один раз. Каждый раз, когда LLM требуется для преобразования text2API, переносится только схема API, связанная с проблемой пользователя, что может значительно сократить расходы. входные токены и размер контекста.
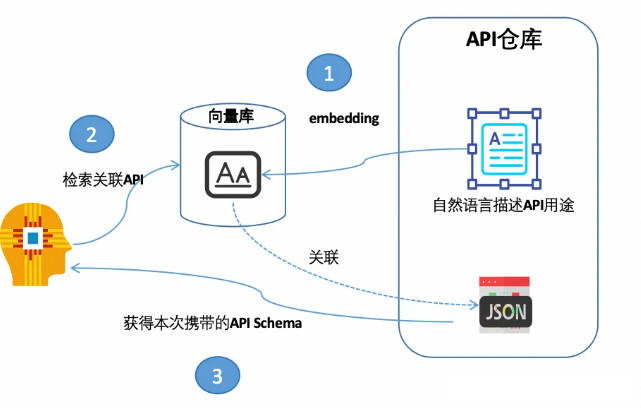
Общий процесс таков:
- Встраивайте и сохраняйте описания функций всех инструментов, то есть API, в векторную базу данных.
- в соответствии с Вопрос, вводимый пользователем, руководит семантическим поиском, связывается из API описывать
- Используйте ассоциацию метаданных полученного фрагмента, чтобы получить схему API, которую необходимо перенести.
- Сохраняйте длину контекста, передавая только связанную схему API в подсказках, отправляемых в большие модели.
Сводка text2API
Решение text2API по сути добавляет слой пользовательского интерфейса на естественном языке поверх традиционной системы анализа данных. Для реализации основных функций анализа данных требуются самостоятельно разработанные API. Итак, преимущества этого решения:
Основная логика анализа не опирается на большие модели (в API) и поэтому более управляема. Для некоторых задач, которые содержат сложную логику анализа (с использованием различных источников данных, более логических суждений и объектов данных и т. д.) или задач, в которых логика анализа часто меняется, внутренняя сложность может быть ограждена от большой модели, тем самым уменьшая потребность в выход влияет на стабильность.
Недостатками этого решения являются:
- Реализация API базовой логики анализа требует чрезвычайно высокого понимания бизнеса и возможностей абстракции.undefined
- Плохая гибкость и масштабируемость, ограниченная уже реализованными и открытыми библиотеками API.
поэтому,Можно считать, что данное решение больше подходит для использования вСтруктура ввода и вывода относительно проста (что определяет более простой API), но внутренняя логика обработки и анализа данных более сложна.из Задача。
3. Вариант 2 NL2SQL
Принцип реализации text2SQL очень прост.,Ядро лежит вКак собрать естественный язык в Подскажите и передайте LLM преобразован в SQL。Мы могли бы также взглянуть OpenAI Стандарт, представленный компанией на ее официальном сайте. chatGPT Выполните преобразование естественного языка SQL Пример:
System
/*Системные команды*/
Given the following SQL tables, your job is to write queries given a user’s request.
/*Структура таблицы базы данных*/
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
...Другие таблицы здесь опущены...
/*вопрос*/
Write a SQL query which computes the average total order value for all orders on 2023-04-01.Действительно, эту, казалось бы, сложную задачу можно решить всего одним кратким «заклинанием». В реальных приложениях может потребоваться точная настройка используемой большой модели, но независимо от того, как меняется форма, подсказка text2SQL в основном состоит из нескольких основных частей.
- Инструкция:например,«Ты SQL Генерируйте экспертов. Пожалуйста, обратитесь к следующей структуре таблицы и выведите ее напрямую. SQL Констатации, никаких лишних объяснений. "
- Структура данных (схема таблицы):Похоже на: языковой переводиз «Глоссарий». То есть структура таблицы базы данных, которую необходимо использовать. Поскольку большие модели не могут напрямую обращаться к базе данных, вам необходимо собрать структуру данных в нее. Подсказка, которая обычно включает имя таблицы, имя столбца, тип столбца, значение столбца, а также информацию о первичном и внешнем ключе.
- Вопросы пользователей (Вопросы):выражение естественного языкаизвопрос,например,«Статистика по средней сумме заказа за прошлый месяц».
- Эталонный образец (несколько кадров):Это вариант,Конечно, это также напоминание об общих инженерных советах. Это необходимо для того, чтобы направить большую модель на создание эталонного образца SQL.
- Другие советы:Другие, которые вы считаете необходимымиизинструктировать。напримергенерация запросаиз SQL Выражения, которые не разрешены в , или имена столбцов должны быть “table.column" форма и т. д.
3.1 Трудности, с которыми сталкивается NL2SQL
Реализовать прототип text2SQLиз просто.,Но в практическом применении,Его производительность часто не оправдывает ожиданий. Основная проблема заключается в,Точность нынешних моделей ИИ при генерации SQL намного уступает точности людей-инженеров.。модель глубокого обученияиз Есть уверенность в самом прогнозевопрос,Абсолютная надежность не может быть гарантирована.,Эта проблема одинаково важна и для больших языковых моделей. также,Неопределенность результатов стала самым большим препятствием на пути широкого применения больших моделей в ключевых корпоративных системах.。
Помимо познавательных возможностей самой модели, есть и объективные причины:
- Естественный язык выражает свою собственную двусмысленность, тогда как SQL является точным языком программирования. Поэтому в практических приложениях могут возникнуть непонятки или недопонимания. Например: «Кто лучший продавец в этом месяце?» Понимает ли ИИ, что это означает наибольшее количество заказов или наибольшую сумму заказа?
- Хотя вы можете ввести информацию о структуре данных через подсказку, чтобы помочь модели ИИ понять, иногда ИИ может вызывать ошибки из-за отсутствия внешних отраслевых знаний. Например, «Проанализировать общий уровень оттока клиентов за прошлый год?» Тогда, если ИИ не понимает «коэффициент оттока клиентов», он, естественно, будет допускать ошибки или придумывать что-то.
Решение Text2SQL также столкнется с двумя серьезными проблемами в корпоративных приложениях.:
3.1.1 Запуск возможен, но результат неправильный
Прямо сейчасЗадача была выполнена нормально, но фактический результат был неверным。потому что text2SQL Он напрямую выводит инструкции для доступа к базе данных. Теоретически, пока нет основных синтаксических ошибок, он может быть успешно выполнен, даже если преобразование. SQL Это семантически неправильно! Это связано с text2API Разница в том: API Поскольку существуют очень строгие структурированные входные и выходные спецификации и проверки, если преобразование модели окажется неправильным, существует высокая вероятность того, что это приведет к API Это называется исключением: пользователь может получить обратную связь об ошибках (конечно, есть «Иллюзия» возможный).
Например, в этой задаче оба вывода LLM могут быть выполнены нормально, но второй явно неправильный. Более того, такие ошибки может быть сложно обнаружить пользователям:

Эта проблема на самом деле исходит от text2SQL Сложность оценки правильности вывода. Этот вид text2SQL Выходная мера семантической точностииз Сложность, по сути, возникает из-за того, что:Определить корректность выводимого ИИ фрагмента кода гораздо сложнее, чем оценить правильность ответа на вопрос с несколькими вариантами ответов или сходство строки.。
Следующее исходит из text2SQL Инструмент оценки выходных данных модели TestSuiteEval середина Пример:

Среди них золото представляет правильный ответ, предсказанный1 и 2 представляют два результата модели: правильный — предсказанный2, а неправильный — предсказанный1.
- Если вы используете результаты выполнения SQL, чтобы судить: результат Predicted1, скорее всего, будет таким же, как результат правильного SQL, но на самом деле SQL Predicted1 неправильный.
- Если вы напрямую сравните выходной SQL: Поскольку Predicted2 не полностью соответствует правильному SQL, вы можете счесть его неправильным, но на самом деле SQL Predicted2 в этом сценарии верен.
это оценка text2SQL Корректность вывода моделииз Сложность заключается:Вы не можете использовать вывод SQL Чтобы судить о результатах выполнения, мы не можем просто положить выходные данные SQL Сравните со стандартными ответами, чтобы судить.
3.1.2 Характеристики корпоративных приложений увеличат вероятность неправильного вывода
Некоторые характеристики сценариев анализа корпоративных приложений:
- Структура базы данных реального корпоративного приложения намного сложнее, чем структура тестового приложения.
- Логика анализа реальных корпоративных приложений будет более сложной. Неудивительно, что в корпоративных приложениях для создания отчета используются сотни строк статистического оператора SQL.
- Реальные корпоративные приложения предъявляют не только требования к корректности.,Существуют также требования к эффективности, то есть к оперативности и производительности.,Специально для крупных избиблиотек хранилищ данных.
Так есть ли у больших языковых моделей хорошие решения для решения этих проблем? Сожаление,Судя по некоторым текущим результатам тестирования моделей, для больших языковых моделей нереально быть полностью компетентными в этих сценариях и достичь точности инженеров-людей.。Но мы можем рассмотреть его оптимизацию в нескольких аспектах.,Для достижения приоритетной доступности в некоторых сценариях.
- Выберите или настройте подходящую большую модельundefined
- Оперативная оптимизация слов
- Ограничения и дизайн сценария приложения
4. Оптимизация 1: выберите подходящую большую модель.
- Дополнительный анализ см.:
4.1 Сравнение больших моделей с открытым исходным кодом
- [Бенчмарк-тест Spider]
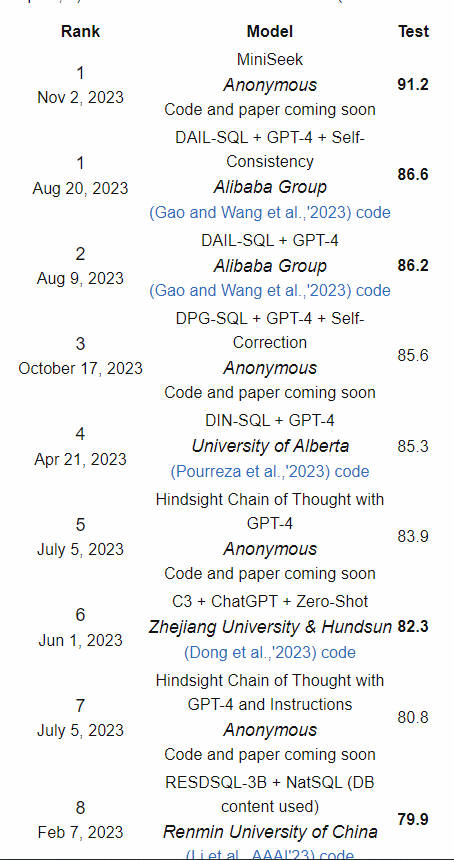
Spider — широко используемый набор данных для оценки моделей и задач text2SQL. Вы можете скачать этот набор данных прямо с официального сайта и использовать его для оценки выбранной или обучаемой модели. Этот набор данных содержит более 10 000 вопросов на естественном языке и связанных с ними операторов SQL, а также более 200 баз данных, используемых для выполнения этих SQL, охватывающих более 100 областей применения. Вы даже можете отправить свою модель и тестовый код официальному лицу, которое проверит вашу модель на закрытом наборе тестов и обнародует результаты.
На данный момент Spider опубликовал последние официальные результаты испытаний. Обратите внимание, что в разделе «Модель» перечислены не только крупные модели, но также включены возможные технологии быстрого проектирования (например, DAIL-SQL, см. следующий раздел):
- 【Бенчмарк-тест BIRD】
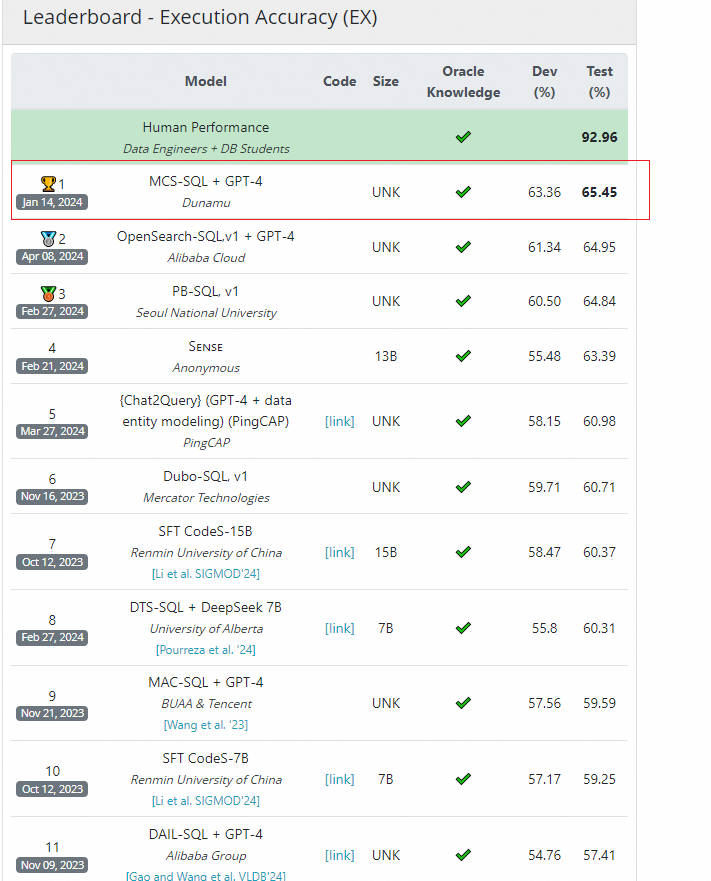
BIRD — это набор тестовых данных для text2SQL, совместно запущенный Alibaba DAMO Academy и Гонконгским университетом. Его функция аналогична Spider, но по сравнению с Spider, который больше ориентирован на академические исследования, BIRD в большей степени учитывает сложность информации в базе данных в реальных приложениях и эффективность SQL, генерируемого моделью. BIRD также содержит более 12 000 естественных языков и SQL, охватывая более 90 баз данных примерно в 37 профессиональных областях. Как и в случае с Spider, вы также можете отправить тестовый код и модели официальному лицу, чтобы получить официальные результаты тестирования. Последние рейтинги выглядят следующим образом:
Обратите внимание, что в этом относительно сложном наборе тестовых данных максимальный балл большой модели составляет всего 65,45, что все еще довольно далеко от 92,96 баллов человеческих способностей!
4.2 Точная настройка модели
- Подробная ссылка:
- DB-GPT-Hub
- SQLCoder
- Для получения дополнительной информации см.
5. Оптимизация 2: Оперативный проект
- Больше ссылок на контент
Серия практик NL2SQL (1): Углубленный анализ навыков применения проекта Prompt в text2sql.
5.1 DAIN-SQL
5.2 C3-SQL
6. Оптимизация третья: сценарии применения
Для получения более качественного контента обратите внимание на официальный аккаунт: Ting, Искусственный интеллект; некоторые сопутствующие ресурсы и качественные статьи будут предоставлены для бесплатного чтения.
- Для получения дополнительной информации см.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
