Серия Spark — (6) Управление памятью Spark
6. Управление искровой памятью
При выполнении приложения Spark кластер Spark запускает два потока JVM: Driver и Executor. Первый является основным процессом управления и отвечает за создание контекста Spark, отправку заданий Spark (задания) и преобразование заданий в вычислительные задачи (задачи). ). Каждый процесс-исполнитель координирует планирование задач. Последний отвечает за выполнение определенных вычислительных задач на рабочих узлах и возврат результатов драйверу. Он также обеспечивает функции хранения для RDD, которые необходимо сохранить. Поскольку управление памятью Драйвера относительно простое, в этой статье в основном анализируется управление памятью Исполнителя. Память Spark в контексте относится конкретно к памяти Исполнителя.
6.1 Планирование памяти в куче и вне кучи
Как процесс JVM, управление памятью Executor основано на управлении памятью JVM, более детально распределяя пространство в куче JVM, чтобы полностью использовать память. В то же время Spark вводит технологию off-heap, которая позволяет напрямую освобождать пространство в системной памяти рабочего узла для дальнейшей оптимизации использования памяти.
Память внутри кучи единообразно управляется JVM, а память вне кучи напрямую запрашивается и освобождается из операционной системы.
1. Куча памяти
Размер Память в куче,Параметр spark.executor.memory настраивается при запуске приложения Spark. Параллельные задачи Исполнителя Память разделяют кучу JVM,ЭтиПамять, занимаемая задачами при кэшировании данных RDD и широковещательных данных, планируется как память хранения, а память, занимаемая этими задачами при выполнении Shuffle, планируется как память выполнения (Execution).,Для остальных частей специального планирования не требуется.,Эти экземпляры объектов внутри Spark,Или экземпляр пользовательского объекта в приложении Spark.,Все занимают оставшееся место,в разных режимах управления,Эти три части занимают разное количество места.
Управление кучной памятью в Spark представляет собой управление логическим планированием, поскольку приложение и освобождение памяти, занятой экземплярами объектов, выполняются JVM, и Spark может записывать память только перед применением и освобождением.
Подать заявку на память:
- Spark создает новый экземпляр объекта в коде.
- JVM выделяет пространство из кучи, создает объекты и возвращает ссылки на объекты.
- Spark сохраняет ссылку на объект,Запишите пространство, занимаемое этим объектом
Свободная память:
- Искра записывает Память, выпущенную объектом,Удалить ссылку на объект
- Подождите, пока механизм сборки мусора JVM освободит кучу, занимаемую объектом.
Объекты JVM могут храниться сериализованным образом. Процесс сериализации заключается в преобразовании объекта в двоичный поток байтов. По сути, его можно понимать как преобразование цепного хранилища прерывистого пространства в непрерывное пространство или блочное хранилище при доступе. , Требуется десериализация. Для сериализованных объектов в Spark, которые представлены в виде потоков байтов, объем занимаемой ими памяти можно рассчитать напрямую, а для несериализованных объектов объем занимаемой ими памяти приблизительно оценивается посредством периодической выборки.
Экземпляры объектов, помеченные как выпущенные Spark, скорее всего, на самом деле не будут переработаны JVM. В результате фактически доступная память меньше, чем доступная память, записанная Spark, что делает невозможным полностью избежать исключений нехватки памяти (OOM).
2. Память вне кучи
Чтобы дополнительно оптимизировать использование памяти и повысить эффективность сортировки во время Shuffle, Spark вводит память вне кучи, которая позволяет напрямую открывать пространство в системной памяти рабочего узла и хранить сериализованные двоичные данные.
Память вне кучи означает, что объекты памяти размещаются в памяти за пределами кучи виртуальной машины Java. Эта память напрямую управляется операционной системой (а не виртуальной машиной). Результатом этого является сохранение кучи меньшего размера, чтобы уменьшить влияние сборки мусора на приложение.
С помощью JDK Unsafe API (начиная с версии Spark 2.0 управление памятью хранения вне кучи больше не основано на Tachyon, а такое же, как и исполнительная память вне кучи, реализованная на основе JDK Unsafe API), Spark может напрямую управлять внешней кучей памяти, сокращая ее. Устраняются ненужные накладные расходы на память, а также частое сканирование и перезапуск GC, что повышает производительность обработки. Память вне кучи может быть точно применена и освобождена (причина, по которой память вне кучи может быть точно применена и освобождена, заключается в том, что применение и освобождение памяти больше не проходят через механизм JVM, а напрямую применяются к операционной системе. JVM очищает память. Невозможно точно указать момент времени, поэтому точного освобождения добиться невозможно), а пространство, занимаемое сериализованными данными, можно точно рассчитать, что снижает сложность управления и уменьшает количество ошибок по сравнению с в. -куча памяти.
Память вне кучи не включена по умолчанию. Ее можно включить, настроив параметр spark.memory.offHeap.enabled, а размер пространства вне кучи задается параметром spark.memory.offHeap.size. За исключением того, что другого пространства нет, память вне кучи и память в куче делятся одинаково, и все одновременно выполняемые задачи совместно используют память хранения и память выполнения.
6.2 Управление пространством памяти
1. Управление статической памятью
В соответствии с механизмом управления статической памятью, первоначально принятым в Spark, размеры памяти хранения, памяти выполнения и других воспоминаний фиксируются во время работы эталонной программы Spark, но пользователи могут настроить их перед запуском эталонной программы.
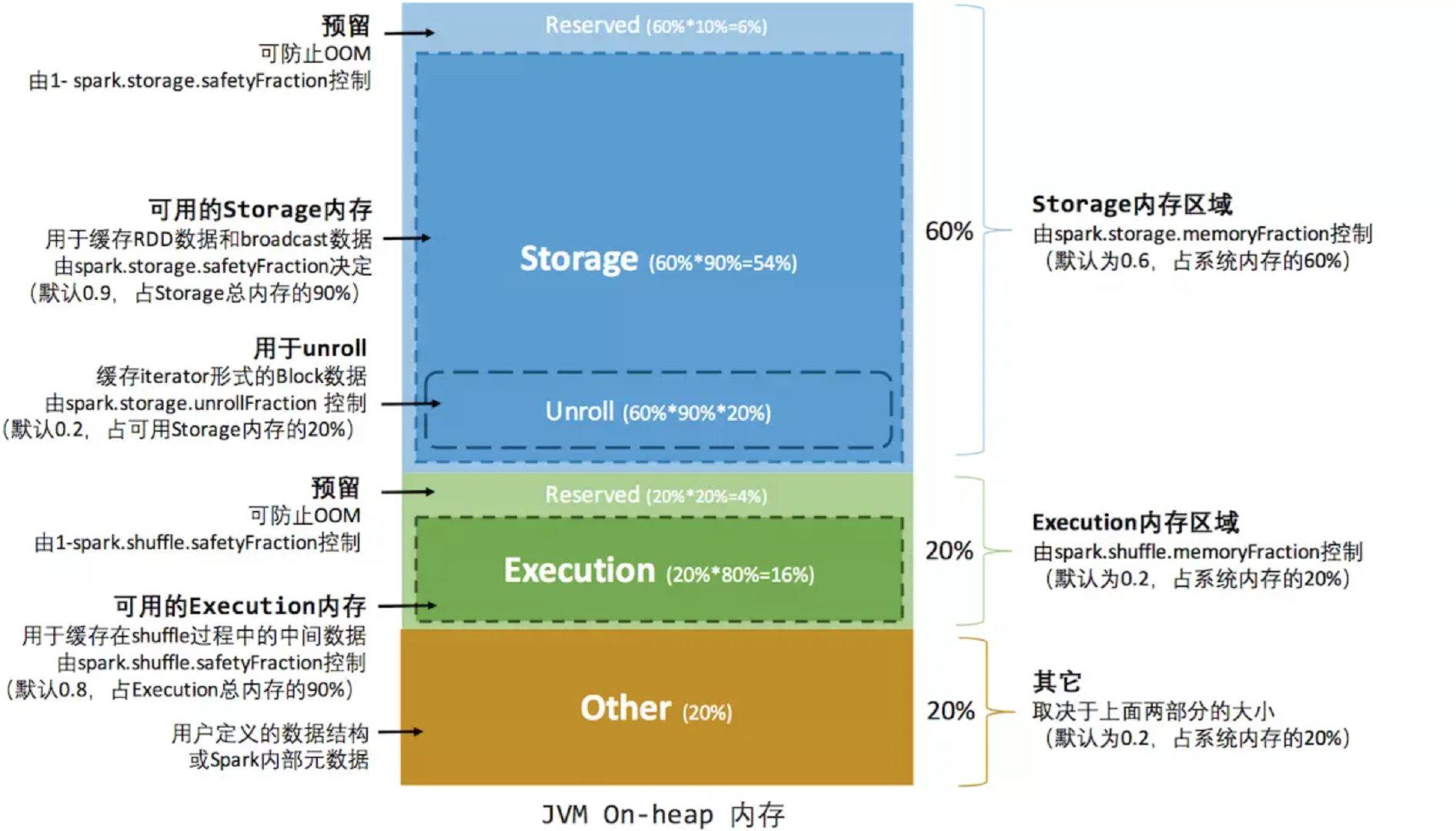
Доступная память = systemMaxMemory * spark.storge.memoryFraction * spark.storage.safetyFraction
доступная исполнительная память = systemMaxMemory * spark.shuffle.memoryFraction * spark.shuffle.safetyFraction
Зарезервированная страховая область — это просто логический план. Spark не обрабатывает ее по-другому при конкретном использовании. Управление ею остается на усмотрение JVM, как и с другой памятью.
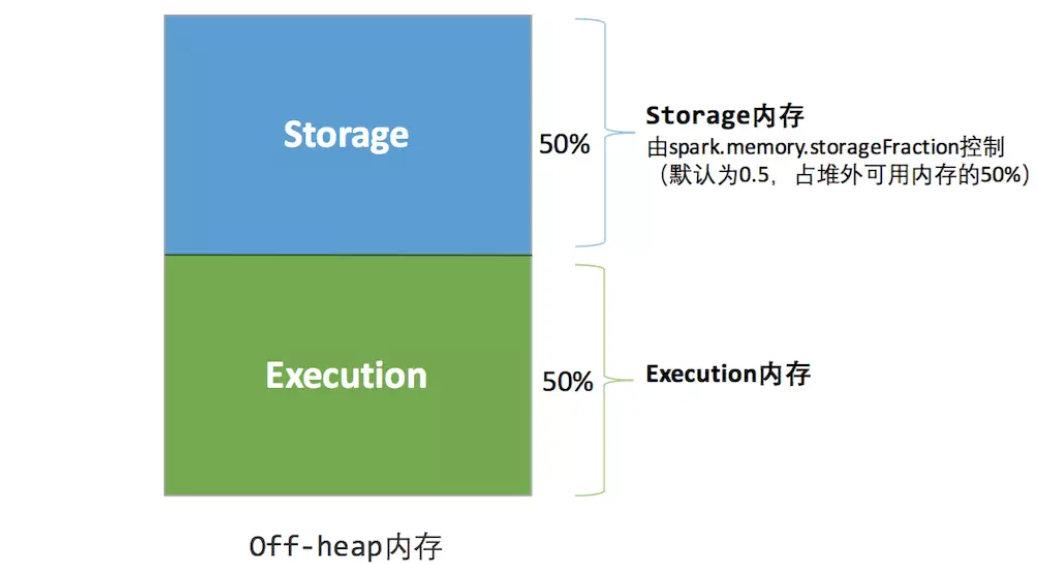
Память вне кучиРаспространение проще,толькохранилище Памятьи исполнение Память,Определяется параметром spark.memory.storageFraction.,Поскольку место, занимаемое Память вне кучи, можно точно вычислить,Поэтому нет необходимости устанавливать зону страхования.
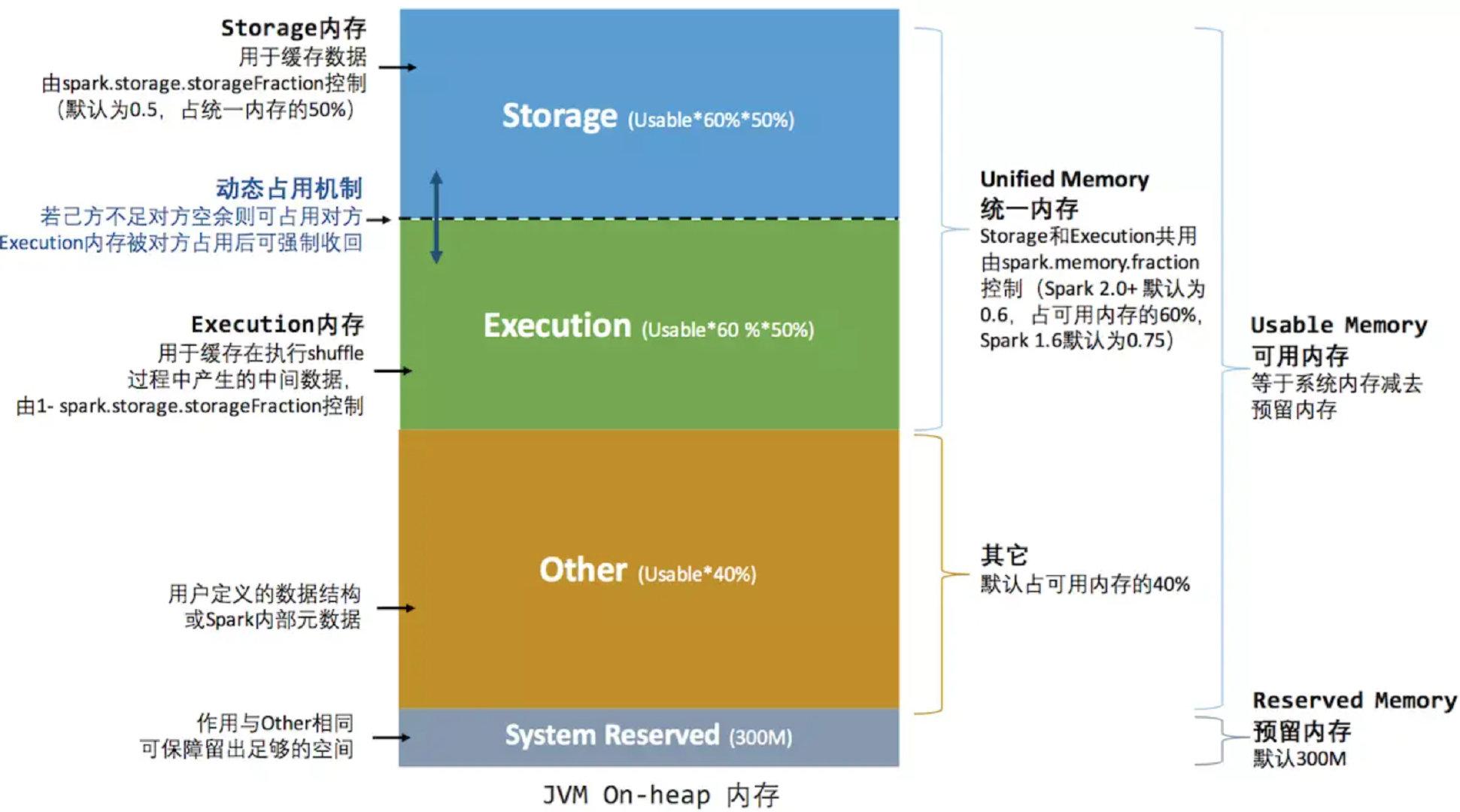
2. Единое управление памятью
Механизм унифицированного управления памятью, представленный после Spark 1.6, отличается от управления статической памятью тем, что память хранения и память выполнения используют одно и то же пространство и могут динамически занимать область пространства объекта.
Структура памяти вне кучи унифицированного управления памятью показана на рисунке ниже:
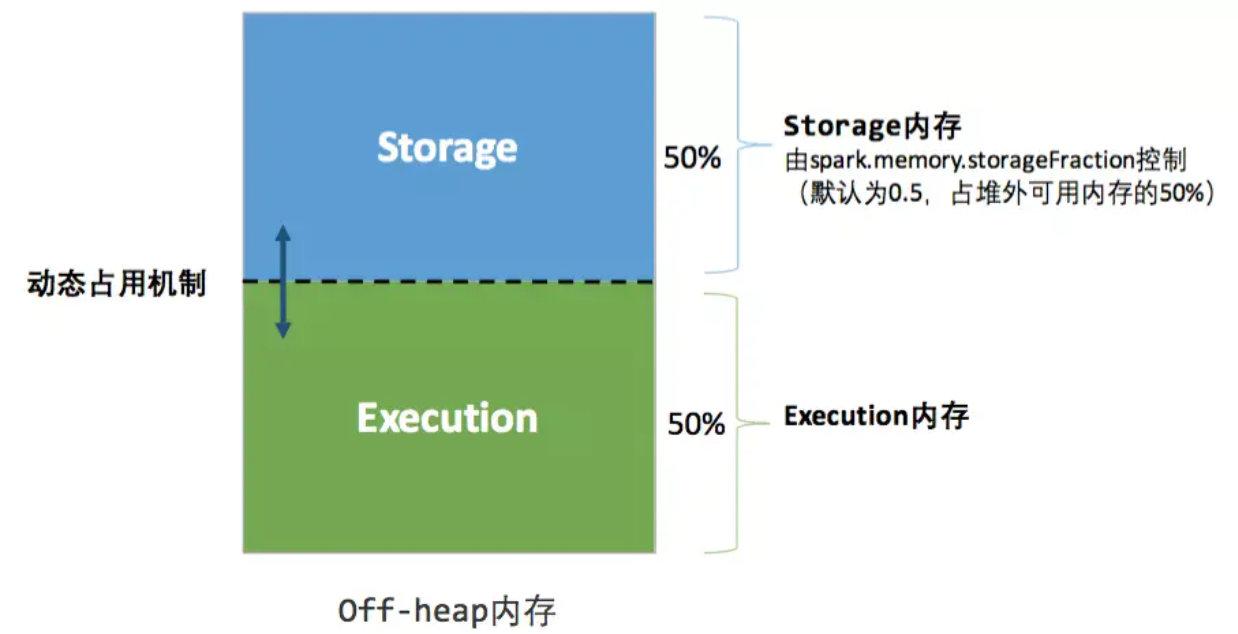
Важная оптимизация заключается в механизме динамической занятости, правила которого следующие:
- Установите базовую хранилище Память и регион выполнения Память (параметр Spark.storage.storageFraction),Этот параметр определяет размер пространства, которое имеет каждая сторона.
- Когда недостаточно места для обеих сторон,Затем хранилище переносится на жесткий диск, если у одного недостаточно места, а у другого есть свободное место;,Вы можете занимать пространство друг друга.
- Место, использованное для выполнения Память, занято другой стороной.,Вы можете позволить другому лицу перенести занятую часть на жесткий диск.,Затем верните заемное пространство.
- После того, как место хранилища Память занято другой стороной,Невозможно заставить другую сторону вернуть его.,В процессе перемешивания необходимо учитывать множество факторов, которые сложнее реализовать.
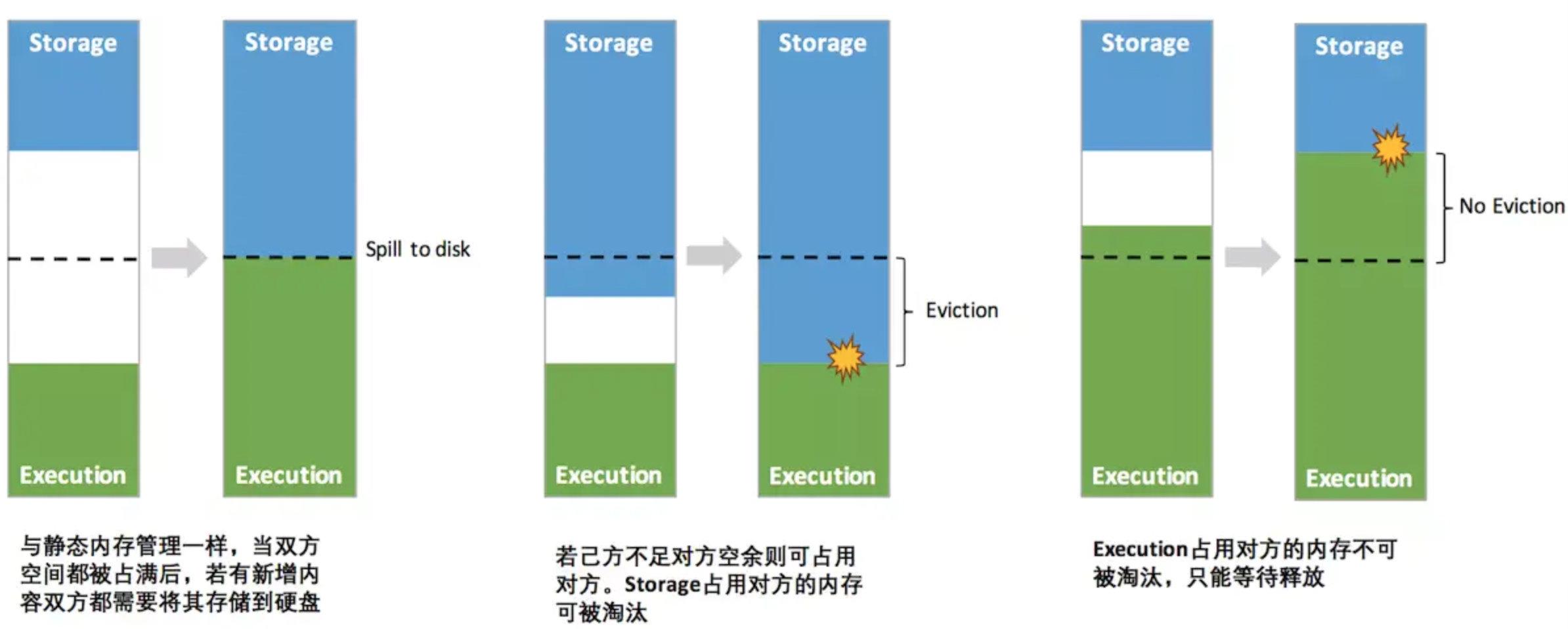
Благодаря унифицированному механизму управления памятью Spark в определенной степени улучшает использование ресурсов памяти в куче и вне кучи и упрощает разработчикам обслуживание памяти Spark. Однако это не означает, что разработчики могут сидеть сложа руки и расслабляться. поэтому, если пространство для хранения слишком велико или содержит слишком много кэшированных данных, это приведет к частой полной сборке мусора и снижению производительности выполнения задач, поскольку кэшированные данные RDD обычно находятся в памяти в течение длительного времени.
6.3 Управление памятью
1. Механизм сохранения RDD
Как наиболее фундаментальная абстракция данных Spark, RDD представляет собой набор записей разделов, доступных только для чтения (раздел). Его можно создать только на основе набора данных в стабильном физическом хранилище или создать новый путем выполнения операций преобразования. другие существующие RDD. Между преобразованным RDD и существующим RDD существуют отношения зависимости, образующие родословную. Благодаря lineage Spark каждый RDD может быть восстановлен.
Когда задача считывает раздел в начале запуска, она сначала определяет, сохранился ли раздел. Если нет, необходимо проверить контрольную точку или пересчитать в соответствии с происхождением. Поэтому, если вам нужно выполнить несколько действий с RDD, вы можете использовать метод persist или кэширования в первом действии, чтобы сохранить или кэшировать RDD в памяти или на диске, тем самым улучшая скорость вычислений в последующих действиях. Фактически, метод кэширования использует уровень хранения по умолчанию MEMORY_ONLY для сохранения RDD в памяти, поэтому кэш представляет собой особый вид сохранения. Конструкция памяти в куче и вне кучи позволяет унифицировать планирование и управление памятью, используемой при кэшировании RDD.
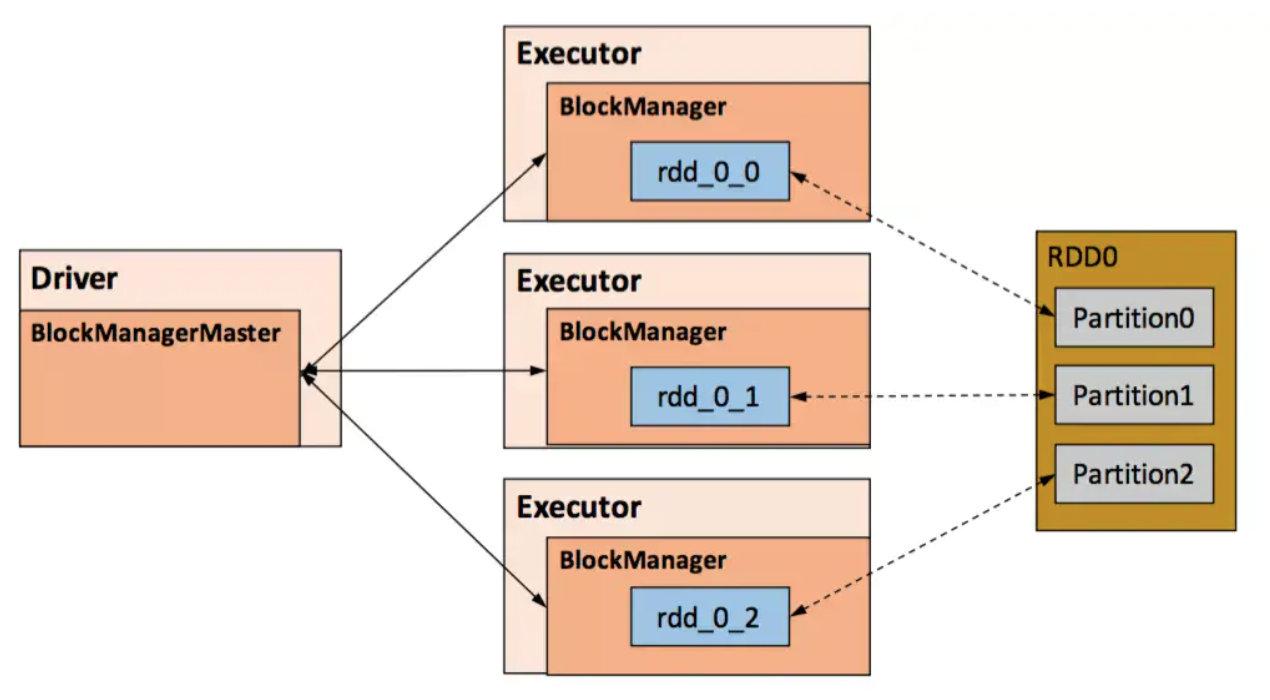
Сохранение RDD обеспечивается модулем Spark Storage, который отделяет RDD от физического хранилища. Модуль Storage отвечает за управление данными, генерируемыми Spark в процессе расчета, и инкапсулирует функции хранения данных в памяти или на диске, локально или удаленно. В конкретной реализации модули Storage на стороне Driver и Executor образуют архитектуру master-slave, то есть BlackManager на стороне Driver является Master, а BlockManager на стороне Executor является ведомым. Модуль Storage логически использует блок в качестве базовой единицы хранения. Каждый раздел RDD однозначно соответствует блоку после обработки (формат BlockId — rdd_RDD-ID_PARTITION-ID). Мастер отвечает за управление и обслуживание информации метаданных блоков для всего приложения Spark. Ведомому устройству необходимо сообщать Мастеру статус обновления блока и получать команды от Мастера, например, на добавление или удаление RDD.
При сохранении RDD Spark предоставляет 7 различных типов MEMORY_ONLY, MEMORY_AND_DISK и т. д., а уровень хранения представляет собой комбинацию следующих 5 переменных:

Семь уровней хранения в Spark следующие:
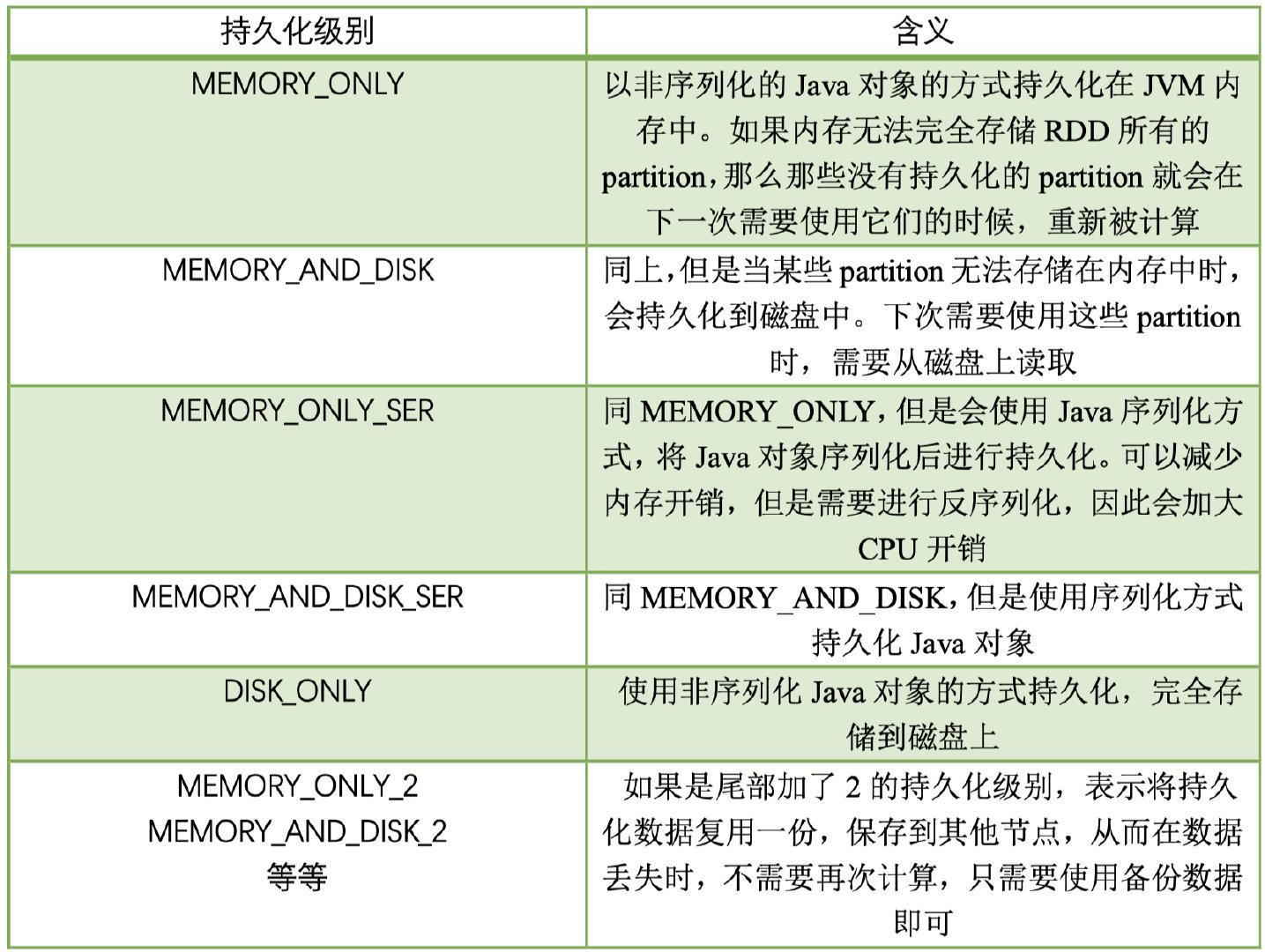
Путем анализа структуры данных видно, что уровень хранения определяет метод хранения раздела RDD (то есть блока) в трех измерениях:
- место хранения:диск/В куче Память/За пределами кучи Память,Например, MEMORY_AND_DISK одновременно находится и на диске, и в куче.,Реализовано резервное резервное копирование. OFF_HEAP находится только за пределами кучи Памятьхранилище,В настоящее время, выбирая Память за пределами кучи, вы не можете одновременно хранить в других местах.
- Форма хранения:BlockКэшировать вхранилище Памятьназад,Будь то в несериализованном виде. Например, MEMORY_ONLY — это метод несериализации хранилища.,OFF_HEAP — хранилище метода сериализации.
- Количество копий: если оно больше 1, требуется удаленное резервное резервное копирование на другие узлы. Например, для DISK_ONLY_2 требуется 1 удаленная резервная копия.
2. Процесс кэширования RDD
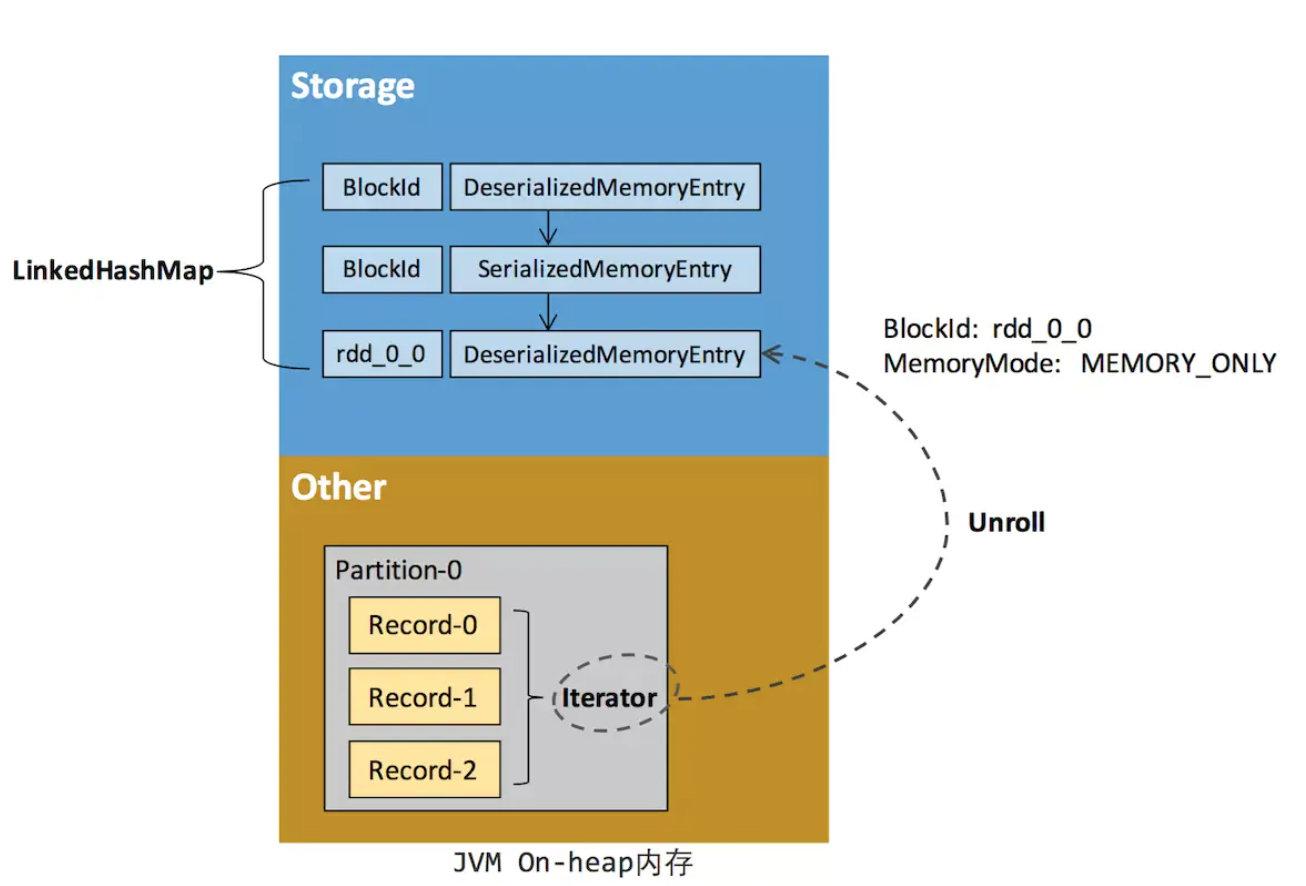
Прежде чем RDD будет кэширован в памяти хранилища, доступ к данным в разделе обычно осуществляется с использованием структуры данных итератора (Iterator). Каждый сериализованный или несериализованный элемент данных (запись) в разделе может быть получен через итератор. Эти экземпляры объекта Record логически занимают пространство других частей кучи JVM. Пространства разных записей в одном разделе не являются общими. то же самое. Не непрерывно.
После того, как RDD кэшируется в памяти хранения, раздел преобразуется в блок, а запись занимает непрерывное пространство в куче или внекучной памяти. Процесс преобразования Parititon из прерывистого пространства хранения в непрерывное пространство хранения называется Unroll от Spark.
Блок имеет два формата хранения: сериализованный и несериализованный. Конкретный метод зависит от уровня хранения RDD. Модуль хранения каждого исполнителя использует связанную структуру карты (LinkedHashMap) для управления всеми экземплярами объектов Block в памяти кучи и вне кучи. Введение и удаление этой LinkedHashMap записывает приложение и освобождение памяти.
Поскольку нет никакой гарантии, что пространство хранения сможет вместить все данные в итераторе одновременно, текущая вычислительная задача должна обратиться к MemoryManager, чтобы получить достаточно места для развертывания, чтобы временно занять это пространство при развертывании. Если места недостаточно, Unroll выполнит это. потерпеть неудачу, когда будет достаточно места, он может продолжиться. Для сериализованных разделов необходимое пространство развертывания можно рассчитать напрямую и применить однократно. Несериализованные разделы должны применяться последовательно во время процесса обхода записи, то есть каждый раз, когда запись читается, необходимое для нее пространство развертывания выбирается и оценивается для применения. Когда места недостаточно, его можно прервать, чтобы. освободить занятое пространство развертывания.
Если развертывание наконец-то прошло успешно, пространство развертывания, занимаемое текущим разделом, преобразуется в пространство хранения обычного кэша RDD.
3. Ликвидация и размещение
Поскольку все вычислительные задачи одного и того же Исполнителя используют ограниченное пространство памяти, когда новый блок необходимо кэшировать, но оставшееся пространство недостаточно и не может быть динамически занято, старый блок в LinkedHashMap должен быть удален (вытеснение) и удален. Если уровень хранения Блока также включает требование хранить его на диске, его необходимо сбросить на диск (DROP), в противном случае Блок будет удален напрямую.
Правила исключения памяти для хранения:
- Удаленный блок должен иметь тот же режим памяти, что и новый блок.,Другими словами, те, кто оба принадлежат к внешней стороне кучи, являются теми, кто находится внутри кучи.
- Старый и новый блоки не могут принадлежать одному и тому же RDD, чтобы избежать циклического исключения.
- СДР, которому принадлежит блок, не может находиться в состоянии чтения, чтобы избежать проблем с согласованностью.
- Просматривайте блоки в LinkedHashMap и удаляйте их в порядке последнего использования (LRU), пока не будет достигнуто пространство, необходимое для нового блока. Среди них LRU является характеристикой LinkedHashMap.
6.4 Выполнение управления памятью
Память выполнения в основном используется для хранения памяти, занимаемой задачами при выполнении Shuffle. Shuffle — это процесс перераспределения данных RDD в соответствии с определенными правилами. Давайте посмотрим на использование исполнительной памяти на двух этапах записи и чтения Shuffle:
Shuffle Write
- Если вы выберете обычный метод сортировки на стороне карты,Обычно для сортировки будет использоваться внешний сортировщик.,В Память хранилищеданные в основном занимают внутренние служебные помещения.
- Если на стороне карты выбран метод сортировки Вольфрама,Затем используйте ShuffleExternalSorter для сортировки непосредственно по данным в хранилище сериализованной формы.,В Памятьхранилищеданные могут занимать внекучное и внутрикучное пространство выполнения.,Это зависит от того, включил ли пользователь Память вне кучи и достаточно ли выполнения Память вне кучи.
Shuffle Read
- правильно уменьшить побочные данные при агрегировании,Передать данные Агрегатору,существовать Памятьсерединахранилищеданныечас Занимает место выполнения в куче.
- Если вам нужно отсортировать окончательные результаты,Затем данные необходимо снова передать в externalSorter.,Занимает место выполнения в куче.
В ExternalSorter и Aggreator Spark будет использовать хеш-таблицу AppendOnlyMap для хранения данных в оперативной памяти кучи. Однако во время процесса перемешивания не все данные могут быть сохранены в хеш-таблице, когда эта хэш-таблица занята. Память будет периодически выбираться. Когда она достигнет определенного уровня и новая память выполнения не может быть запрошена из MemoryManager, Spark сохранит все ее содержимое в файле на диске. Этот процесс называется Spill, файлы, перегруженные на диск, окончательно удаляются. объединены (Объединить).
ссылка:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
