Серия Spark — (4) Планирование задач Spark
4. Планирование задач Spark
4.1 Основные компоненты
В этом разделе в основном представлены основные и связанные компоненты процесса работы Spark.
4.1.1 Driver
Узел драйвера Spark используется для выполнения основного метода в задаче Spark и отвечает за фактическое выполнение кода. Водитель несет основную ответственность за:
- Преобразование пользовательских программ в задачи (задания)
- Планирование задач между исполнителями
- Отслеживать выполнение Executor
- Отображать статус выполнения запроса через пользовательский интерфейс
4.1.2 Executor
Узел Spark Executor — это процесс JVM, который отвечает за выполнение определенных задач в заданиях Spark, причем эти задачи независимы друг от друга. При запуске приложения Spark узел Executor запускается одновременно и всегда существует на протяжении всего жизненного цикла приложения Spark. Если узел Executor выйдет из строя или выйдет из строя, приложение Spark сможет продолжить выполнение, а задачи на неисправном узле будут запланированы для продолжения работы на других узлах Executor.
Исполнитель имеет две основные функции:
- Отвечает за выполнение задач, составляющих приложение Spark, и возврат результатов в процесс драйвера;
- Они предоставляют хранилище в памяти для RDD, которые требуют кэширования в пользовательских программах через собственный менеджер блоков. RDD кэшируется непосредственно в процессе Executor, поэтому задачи могут в полной мере использовать кэшированные данные для ускорения операций во время выполнения.
4.1.3 SparkContext
В Spark SparkContext отвечает за связь с кластером, приложением ресурсов, распределением и мониторингом задач и т. д. Когда Исполнитель в рабочем узле завершает выполнение задачи, драйвер также отвечает за закрытие SparkContext. Обычно SparkContext может использоваться для представления драйвера (Driver).
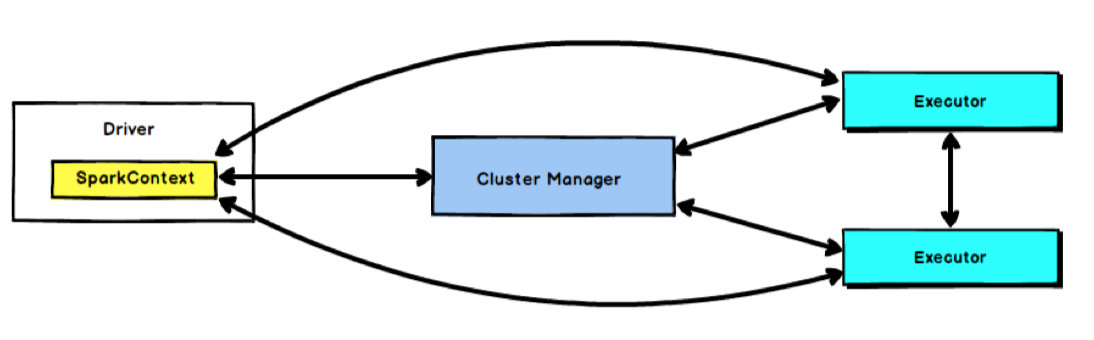
SparkContext — это единственный вход пользователя в кластер Spark, который можно использовать для создания RDD, аккумуляторов и широковещательных переменных в кластере Spark. SparkContext также является важным объектом во всем приложении Spark. Можно сказать, что он является основой расписания работы всего приложения (за исключением планирования ресурсов).
Основная функция SparkContext — инициализировать основные компоненты, необходимые для запуска приложений Spark, включая планировщик высокого уровня (DAGScheduler), планировщик нижнего уровня (TaskScheduler) и коммуникационный терминал планировщика (SchedulerBackend). Он также отвечает за. регистрация программы Spark с помощью ClusterManager подождите.
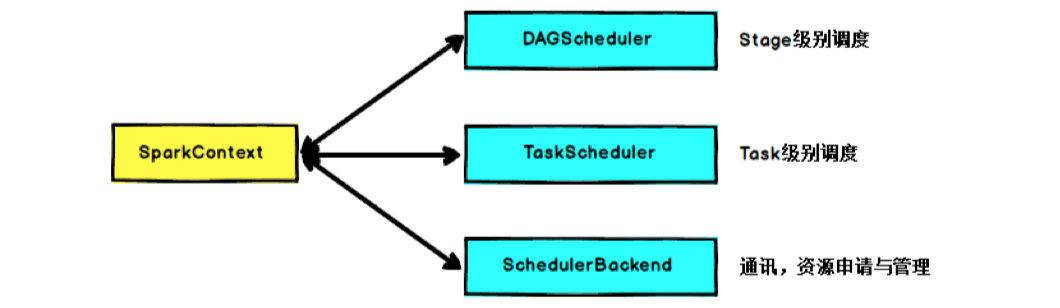
Когда оператор действия RDD запускает задание (Job), SparkContext вызывает DAGScheduler, чтобы разделить задание на несколько небольших этапов (этапов) на основе ширины и узких зависимостей. TaskScheduler будет планировать задачи (Task) каждого этапа. SchedulerBackend отвечает за подачу заявок и управление вычислительными ресурсами (т. е. исполнителем), выделенными кластером для текущего приложения.
На следующем рисунке описан процесс взаимодействия внутренних модулей ApplicationMaster, Driver и Executor при планировании задач в режиме Spark-On-Yarn:
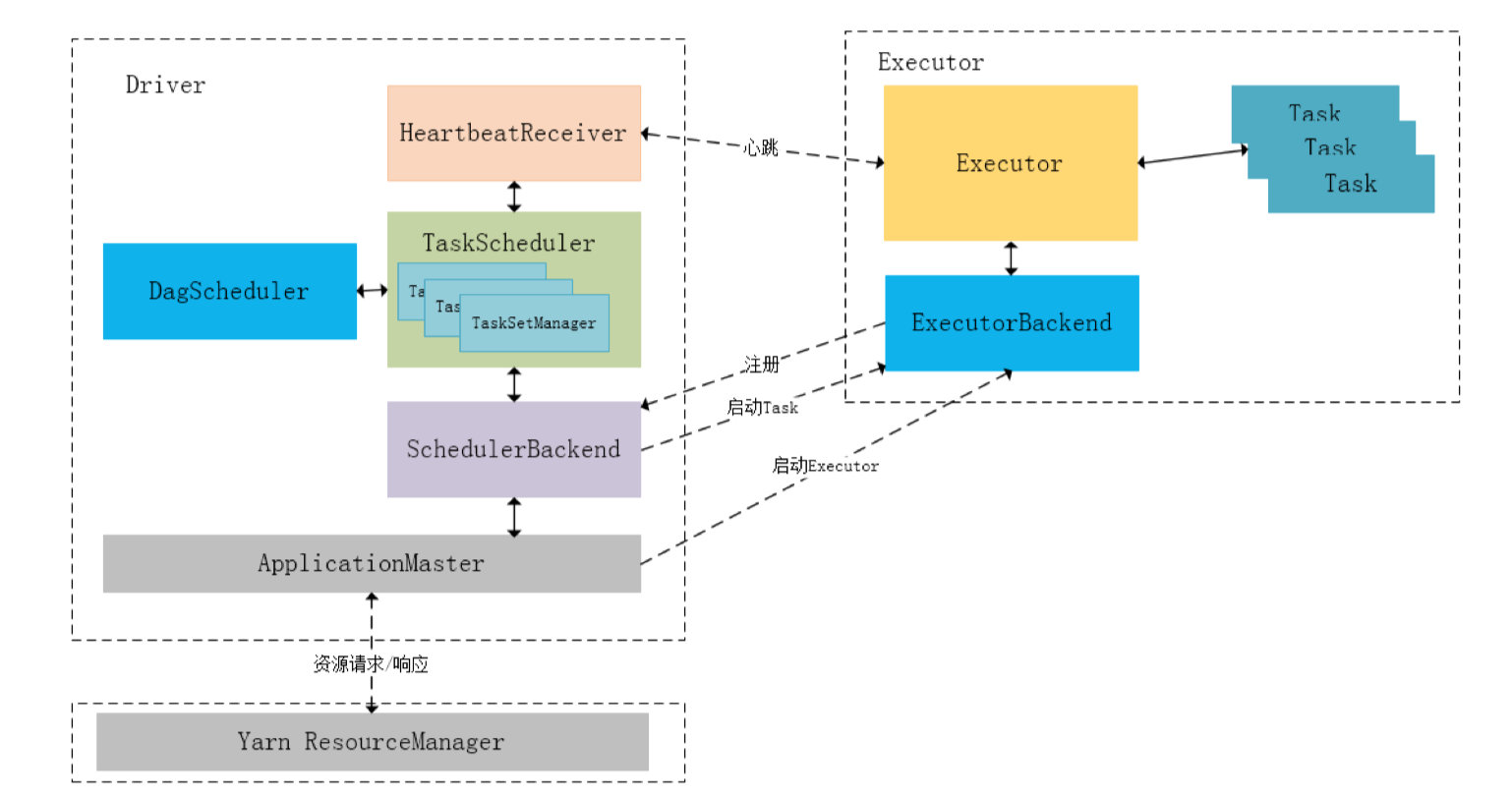
В процессе инициализации SparkContext драйвером он инициализирует DAGScheduler, TaskScheduler, SchedulerBackend и HeartbeatReceiver соответственно и запускает SchedulerBackend и HeartbeatReceiver. SchedulerBackend обращается за ресурсами через ApplicationMaster, постоянно получает соответствующие задачи от TaskScheduler и передает их в Executor для выполнения. HeartbeatReceiver отвечает за получение информации о пульсе Исполнителя, отслеживание состояния выживания Исполнителя и уведомление TaskScheduler.
4.2 YARN
Хотя Yarn не является компонентом Spark, программы Spark теперь в основном полагаются на Yarn для планирования, поэтому мы представим YARN специально.
Yarn (еще один переговорщик ресурсов) — это система управления ресурсами кластера Hadoop. Это общая система управления ресурсами, которая может обеспечить унифицированное управление ресурсами и планирование для приложений верхнего уровня. Ее внедрение улучшило использование, унифицированное управление ресурсами и данными. совместное использование кластера принесло огромную пользу.
4.2.1 Архитектура
Отдельный JobTracker и TaskTracker, который состоит из следующих компонентов:
a. Глобальный менеджер ресурсов ResourceManager. б. Каждый агент узла ResourceManager NodeManager. c. Представляет ApplicationMaster каждого приложения. d. Каждый ApplicationMaster имеет несколько контейнеров, работающих в NodeManager.

- Клиент: Отправьте заявку.
- Диспетчер ресурсов: это главный демон YARN, отвечающий за распределение и управление ресурсами между всеми приложениями. Всякий раз, когда он получает запрос на обработку, он пересылает его соответствующему менеджеру узла и соответствующим образом распределяет ресурсы для выполнения запроса. Он состоит из двух основных компонентов:
- Планировщик: он выполняет планирование на основе выделенных приложений и доступных ресурсов. Это чистый планировщик, что означает, что он не выполняет другие задачи, такие как мониторинг или трассировка, и не гарантирует перезапуск в случае сбоя задачи. Планировщик YARN поддерживает емкость Scheduler、Fair Плагины, такие как ресурсы раздела планировщика.
- Application Менеджер: Он отвечает за принимает приложение и проводник согласовывает первый контейнер. если задача не удалась и она перезапустится Application Master контейнер。
- Node Менеджер: Он отвечает за Hadoop кластер на одном узле и управляйте приложениями и рабочими процессами также этот конкретный узел. Его основная задача — не отставать от менеджера ресурсов. Он регистрируется в диспетчере ресурсов и отправляет периодические сообщения о состоянии работоспособности узла. Он отслеживает использование ресурсов, управляет журналами, а также уничтожает контейнер в соответствии с инструкциями менеджера ресурсов. Он также отвечает за создание процесса контейнера и на основе приложения. Запрос от мастера запускает его.
- Application Мастер: заявка отправляется в платформу как одно задание. Владелец приложения отвечает за согласование ресурсов с менеджером ресурсов и отслеживание статуса и хода выполнения отдельных приложений. Узел приложения запрашивает контейнер у диспетчера узлов, отправляя контекст запуска контейнера (CLC), который включает в себя все, что необходимо приложению для запуска. После запуска приложения оно время от времени будет отправлять отчеты о работоспособности менеджеру ресурсов.
- Контейнер: это набор физических ресурсов на одном узле, например. RAM、Ядра и диски процессора. контейнер вызывается контекстом запуска контейнера (CLC), который представляет собой переменную среды, содержащую、токен безопасности、Записывается такая информация, как зависимости.
Контейнер — это уровень абстракции, созданный Yarn для ресурсов. Как и в нашем ежедневном процессе разработки, нам часто необходимо инкапсулировать некоторые базовые вещи и предоставлять только интерфейс вызова верхнему уровню. Yarn также использует эту идею в управлении ресурсами.
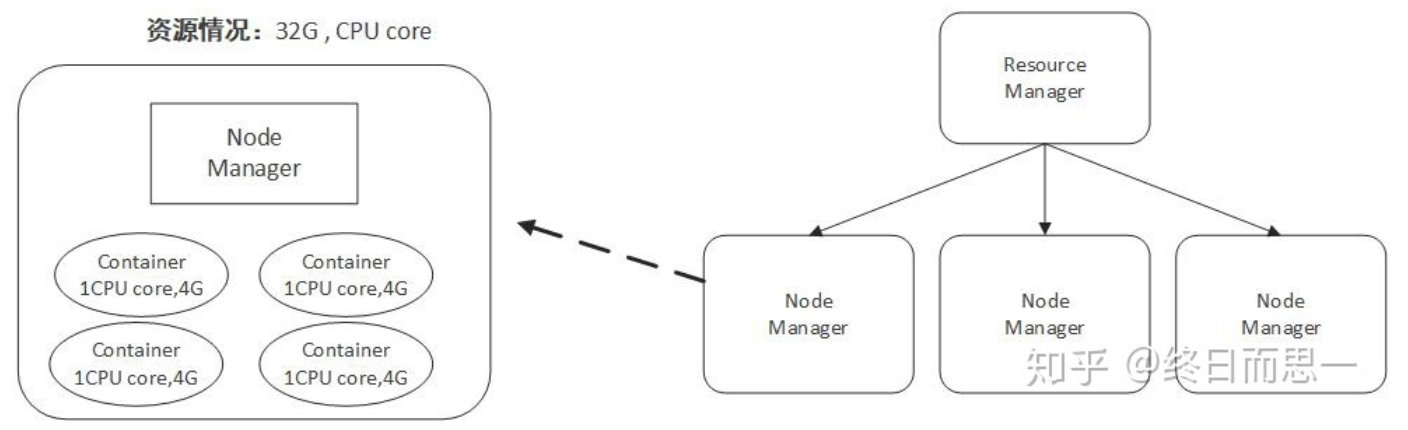
Как показано выше, Yarn инкапсулирует вычислительные ресурсы, такие как ядра ЦП и память, в контейнеры.
4.2.2 Процесс отправки задания

- Клиент отправляет заявку
- Диспетчер ресурсов выделяет контейнер для запуска диспетчера приложений.
- Диспетчер приложений регистрируется в диспетчере ресурсов.
- АМ от РМПрименятьконтейнер ресурсов
- Утреннее уведомление Node Manager 启动контейнер
- Код приложения выполняется в контейнере
- Клиент связывается с RM/AM и сообщает о статусе заявки
- После завершения задания AM отменяет регистрацию в RM.
4.3 Процесс запуска программы Spark
В реальных производственных средах методом развертывания кластеров Spark обычно является режим YARN-Cluster. В последующем содержимом анализа ядра методом развертывания кластера по умолчанию является режим YARN-Cluster.
На следующем рисунке показан полный процесс приложения Spark от отправки до запуска:
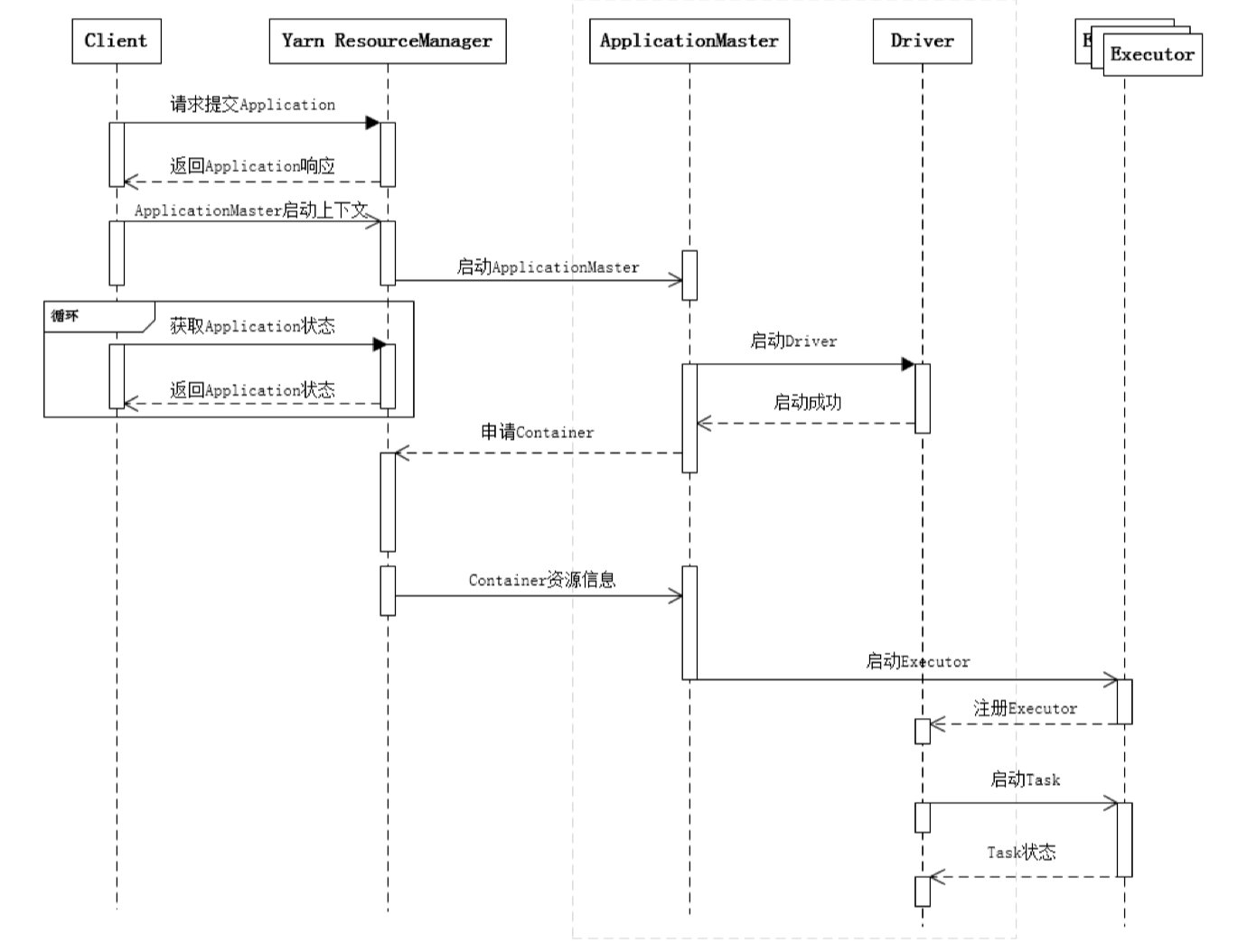
Чтобы отправить приложение Spark, сначала запросите ResourceManager через Клиент для запуска приложения и в то же время проверьте, достаточно ли ресурсов для удовлетворения потребностей приложения. Если условия ресурсов соблюдены, подготовьте контекст запуска приложения. ApplicationMaster, передайте его ResourceManager и в цикле отслеживайте состояние приложения.
Если в очереди отправленных ресурсов есть ресурсы, ResourceManager запустит процесс ApplicationMaster в NodeManager, а ApplicationMaster запустит фоновый поток драйвера отдельно. При запуске драйвера ApplicationMaster подключится к драйверу через локальный RPC и начнет работу. подать заявку на ресурсы Контейнера из ResourceManager. Запустите процесс Исполнителя (Исполнитель соответствует Контейнеру), когда ResourceManager возвращает Контейнер. ресурса, ApplicationMaster запускает Исполнитель в соответствующем Контейнере.
Поток Driver в основном инициализирует объект SparkContext и подготавливает контекст, необходимый для запуска. Затем, с одной стороны, он поддерживает соединение RPC с ApplicationMaster и обращается за ресурсами через ApplicationMaster. С другой стороны, он начинает планировать задачи в соответствии с. бизнес-логику пользователя и доставляет задачи к существующим незадействованным ресурсам исполнителя.
Когда ResourceManager возвращает ресурс Container в ApplicationMaster, ApplicationMaster пытается запустить процесс Executor в соответствующем контейнере. После запуска процесса Executor он обратно зарегистрируется в Driver. После успешной регистрации он поддерживает контрольный сигнал. Драйверу и ожидает, пока Драйвер распределит задачу. При распределении После выполнения задачи Драйверу сообщается статус задачи.
Как видно из приведенной выше диаграммы последовательности действий, Клиент несет ответственность только за подачу Заявления и мониторинг статуса Заявления. Планирование задач Spark в основном фокусируется на двух аспектах: применении ресурсов и распределении задач, которое в основном выполняется между ApplicationMaster, Driver и Executor.
4.4 Обзор планирования задач Spark
Программа Spark включает три концепции: задание, этап и задача.
- Задание ограничено методами действия. При обнаружении метода действия запускается задание;
- Stage — это подмножество Job, ограниченное широкими зависимостями RDD (т. е. Shuffle) и разделяющееся один раз при обнаружении Shuffle;
- Задача — это подмножество Stage, измеряемое степенью параллелизма (количество разделов). Количество разделов соответствует количеству задач.
Планирование задач Spark обычно осуществляется двумя способами: один — планирование на уровне этапов, а другой — планирование на уровне задач. Общий процесс планирования выглядит следующим образом.

Spark RDD формирует граф происхождения RDD, или DAG, с помощью операции преобразования. Наконец, посредством вызова Action задание запускается и запланировано для выполнения.
- DAGScheduler отвечает за планирование на уровне этапов, в основном разделяя задание на несколько этапов и упаковывая каждый этап в набор задач для планирования с помощью TaskScheduler.
- TaskScheduler отвечает за планирование на уровне задач, передавая DAGScheduler и TaskSet, как указано. Планирование передается Исполнителю для выполнения. В процессе планирования SchedulerBackend отвечает за предоставление доступных ресурсов. SchedulerBackend имеет несколько реализаций, которые подключены к различным системам управления ресурсами.
4.4.1 Планирование на уровне этапа Spark
На следующем рисунке представлена блок-схема планирования на уровне этапов Spark:
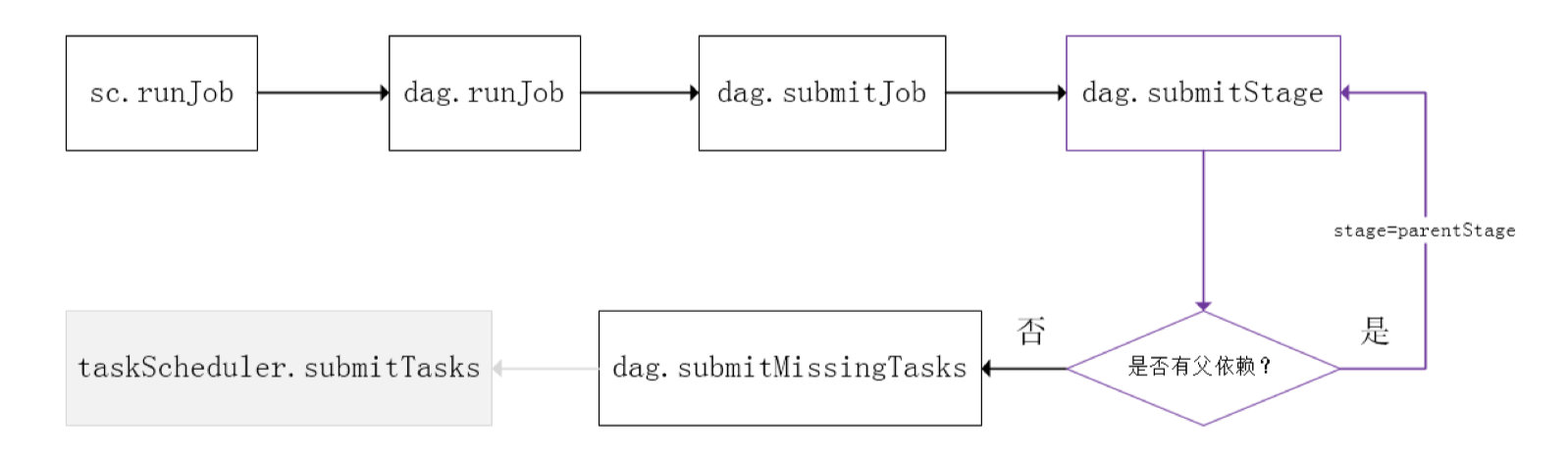
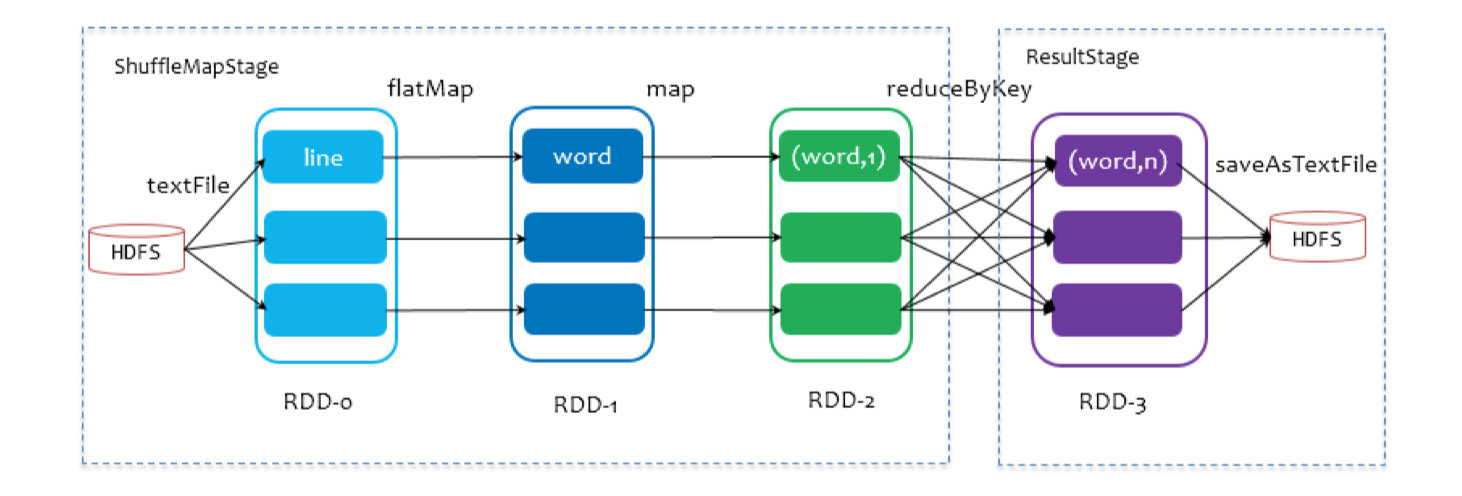
SparkContext передает задание DAGScheduler для отправки. Он разделит группу обеспечения доступности баз данных на основе кровного родства RDD и разделит задание на несколько этапов. Конкретная стратегия разделения заключается в использовании окончательного RDD для непрерывной оценки того, является ли родительская зависимость широкой. зависимости посредством обратного отслеживания зависимостей, то есть с использованием Shuffle в качестве границы для разделения этапов, узкозависимые RDD делятся на один и тот же этап, и можно выполнять вычисления в стиле конвейера, как показано в фиолетовой части процесса на рисунке выше. Разделенные этапы разделены на две категории: одна называется ResultStage и является самым последующим этапом DAG и определяется методом Action, а другая называется ShuffleMapStage и подготавливает данные для нижестоящего этапа.
На следующем рисунке WordCount используется в качестве примера, иллюстрирующего весь процесс:

Отправка этапа зависит от того, выполнен ли его родительский этап. Текущий этап можно отправить только после завершения выполнения родительского этапа. Если этап не имеет родительского этапа, отправка начинается с этого этапа. При отправке этапа информация о задаче (информация о разделах, методах и т. д.) будет сериализована, упакована в TaskSet и передана в TaskScheduler.
4.4.2 Планирование уровня задач Spark
Планирование задач Spark завершается TaskScheduler. Как видно из предыдущей статьи, DAGScheduler упаковывает этап в TaskSet и передает его TaskScheduler. TaskScheduler инкапсулирует TaskSet в TaskSetManager и добавляет его в очередь планирования. Структура TaskSetManager показана на рисунке ниже.

TaskSetManager отвечает за мониторинг и управление задачами на одном этапе, а TaskScheduler использует TaskSetManager как модуль для планирования задач. После инициализации TaskScheduler будет запущен SchedulerBackend. Он отвечает за работу с внешним миром, получение регистрационной информации Executor и поддержание статуса Executor. Когда TaskScheduler опрашивает его из SchedulerBackend, он будет следовать указанной стратегии из очереди планирования. . при планировании выберите TaskSetManager, чтобы запланировать запуск. Общий процесс вызова метода показан на рисунке ниже:

Принцип отправки Заданий TaskScheduler
- Получить все задачи в текущем наборе задач;
- На основе прежнего изTaskSet он инкапсулируется в соответствующий изTaskSetManager. Каждый TaskSet создаст соответствующий TaskSetManager. Функция TaskSetManager должна соответствовать статусу выполнения и управлению всеми Задачами. TaskScheduler использует TaskSetManager в качестве единицы планирования для выполнения задач;
- Добавьте инкапсулированный TaskSetManager в очередь ожидания планирования, и ScheduleBuilder определяет порядок планирования. ScheduleBuilder имеет два класса реализации: один — FIFOOSchedulerBuilder, а другой — FairSchedulerBuilder, а Spark по умолчанию использует режим планирования FIFO.
- При инициализации TaskSchedulerImpl вызывается метод start для запуска SchedulerBackend, а SchedulerBackend (фактически CoarseGrainedSchedulerBackend) вызывает метод riviveOffers. SchedulerBackend отвечает за взаимодействие с внешним миром, прием регистраций от Исполнителей и поддержание статуса Исполнителей.
- Вызовите метод liveOffers CoarseGrainedSchedulerBackend, чтобы запланировать задачи.
- В методе reviveOffers сообщение ReviveOffers отправляется в DriverEndpoint, чтобы инициировать выполнение запланированной задачи, а затем вызывает метод makeOffers после получения сообщения ReviveOffers.
- SchedulerBackend (на самом деле CoarseGrainedSchedulerBackend) отвечает за распространение вновь созданных задач исполнителям для выполнения.
Стратегия планирования
TaskScheduler поддерживает два типа стратегии. планирование, одно — ФИФО, также по умолчанию из Стратегия планирование, другой - ЧЕСТНЫЙ.
В процессе инициализации TaskScheduler будет создан экземпляр rootPool, который представляет корневой узел дерева и имеет тип Pool.
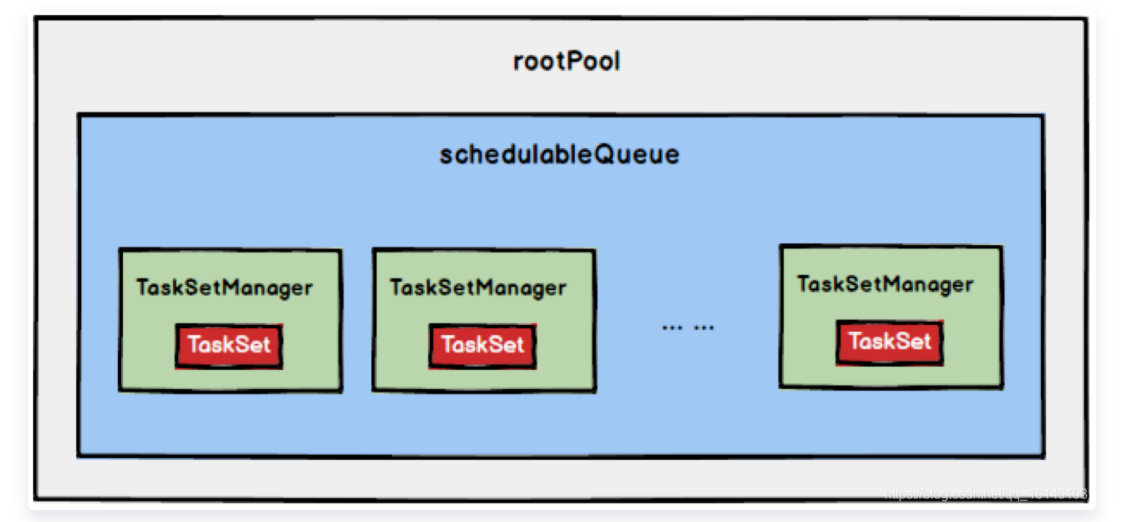
1. FIFOСтратегия планирования
если используется ФИФОстратегия планирования,Затем просто добавьте TaskSetManager в очередь в порядке очереди.,При удалении из очереди напрямую извлекайте самую расширенную очередь из TaskSetManager.,Его древовидная структура показана на рисунке ниже.,TaskSetManager сохраняется в очереди FIFO.
2. FAIRСтратегия планирования(0.8Начните поддерживать)
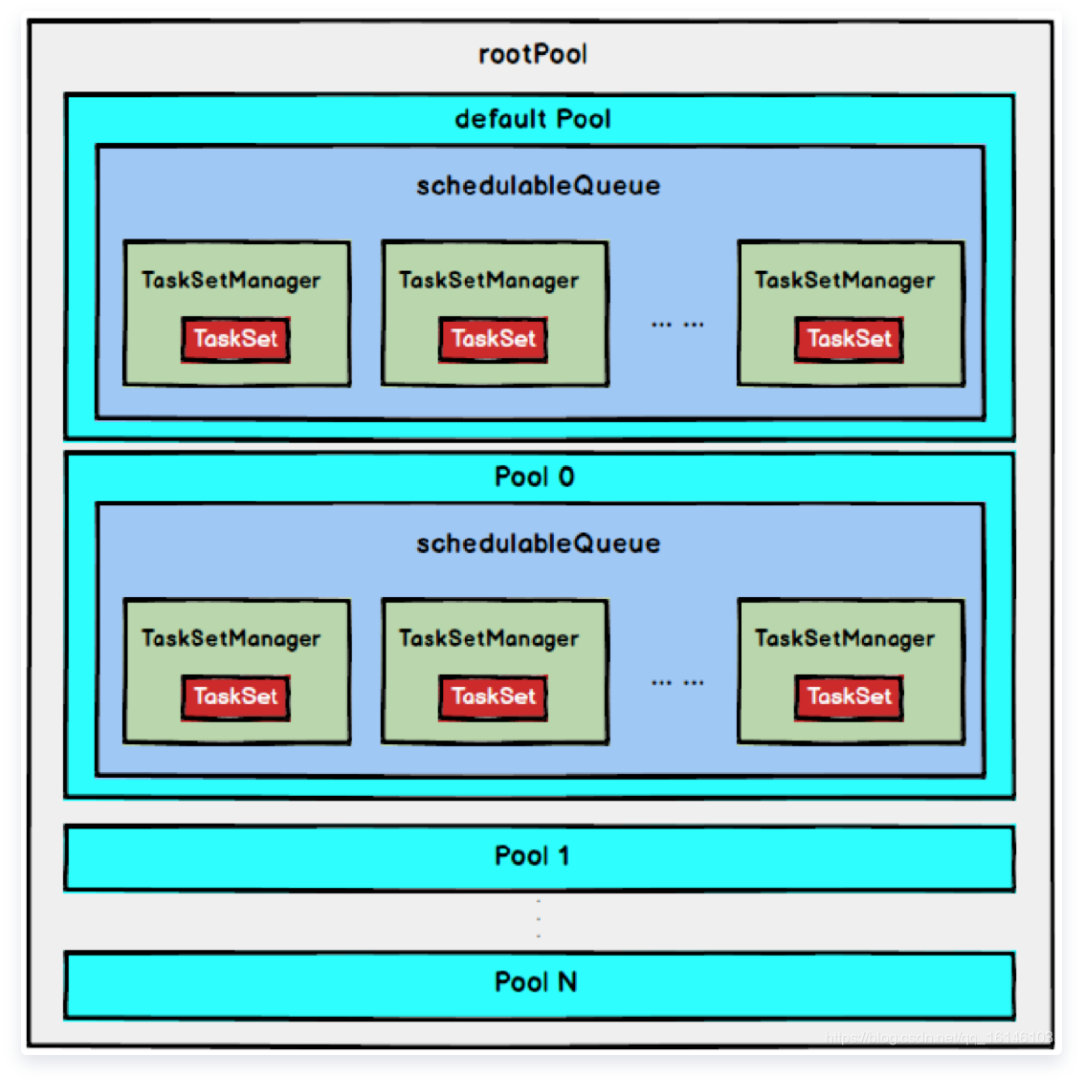
В режиме FAIR существует корневой пул и несколько подпулов, и каждый подпул хранит все распределяемые TaskSetMagagers.
В режиме FAIR вам необходимо сначала отсортировать подпул, а затем отсортировать TaskSetMagager в подпуле. Поскольку и Pool, и TaskSetMagager наследуют особенность Schedulable, они используют один и тот же алгоритм сортировки.
Сравнение процесса сортировки основано на Fair-share. Каждый объект, подлежащий сортировке, содержит три атрибута: значение RunningTasks (количество запущенных задач), значение minShare и значение веса. Значение RunningTasks и значение minShare будут всесторонне учитываться во время. сравнение и весовое значение.
Обратите внимание, что значения minShare и веса указаны в файле конфигурации справедливого планирования fairscheduler.xml. Пул планирования будет читать соответствующую конфигурацию этого файла на этапе построения.
Правила сравнения следующие:
- Если RunningTasks объекта A больше, чем его minShare, а RunningTasks объекта B меньше, чем его minShare, то B занимает место перед A (runningTasks, меньший, чем minShare, выполняются первыми);
- Если RunningTasks объектов A и B меньше, чем их minShare, то сравните соотношение RunningTasks с math.max(minShare1, 1.0) (использование minShare), и тот, кто меньше, будет ранжироваться первым (тот, у кого наименьшее значение); Использование minShare будет выполнено первым)
- Если RunningTasks объектов A и B оба больше, чем их minShare, то сравнивается соотношение RunningTasks к весу (коэффициент использования веса), и тот, кто меньше, занимает первое место. (те, у кого небольшой вес, будут выполняться первыми)
- Если все приведенные выше сравнения равны, то сравниваются имена.
Вообще говоря, процесс сравнения контролируется двумя параметрами minShare и Weight, так что первым может быть запущен тот, у которого минимальное использование minShare и вес (доля фактически запущенных задач меньше).
После завершения сортировки в режиме FAIR все TaskSetManager помещаются в ArrayBuffer, а затем по очереди извлекаются и отправляются Исполнителю для выполнения.
После получения TaskSetManager из очереди планирования, поскольку TaskSetManager инкапсулирует все задачи этапа и отвечает за управление и планирование этих задач, следующим шагом является то, что TaskSetManager извлекает задачи одну за другой в соответствии с определенными правилами и выдает их в TaskScheduler, а затем TaskScheduler передается SchedulerBackend и отправляет его исполнителю для выполнения.
Планировщик выставок можно запустить со следующими настройками:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf)локализованное планирование
DAGScheduler сокращает задание, разделяет этап и отправляет задачи, соответствующие этапу, путем вызова submitStage. submitMissingTasks. submitMissingTasks определяет предпочтительные местоположения каждой задачи, которую необходимо вычислить. Приоритетное положение раздела получается путем вызова getPreferrdeLocations. (), поскольку один раздел соответствует одной Задаче, приоритетная позиция этого раздела является приоритетной позицией задачи.
Для каждой задачи, которая должна быть отправлена в TaskSet TaskScheduler, приоритетное положение запроса соответствует приоритетному положению соответствующего раздела.
После получения TaskSetManager из очереди планирования следующим шагом TaskSetManager будет извлекать задачи одну за другой в соответствии с определенными правилами и передавать их TaskScheduler, а затем передавать их SchedulerBackend для отправки их Исполнителю. исполнение. Как упоминалось ранее, TaskSetManager инкапсулирует все задачи этапа и отвечает за управление и планирование этих задач. В зависимости от приоритетного положения каждой задачи определите уровень локальности задачи. Существует пять типов локальности в порядке от высокого к низкому приоритету:
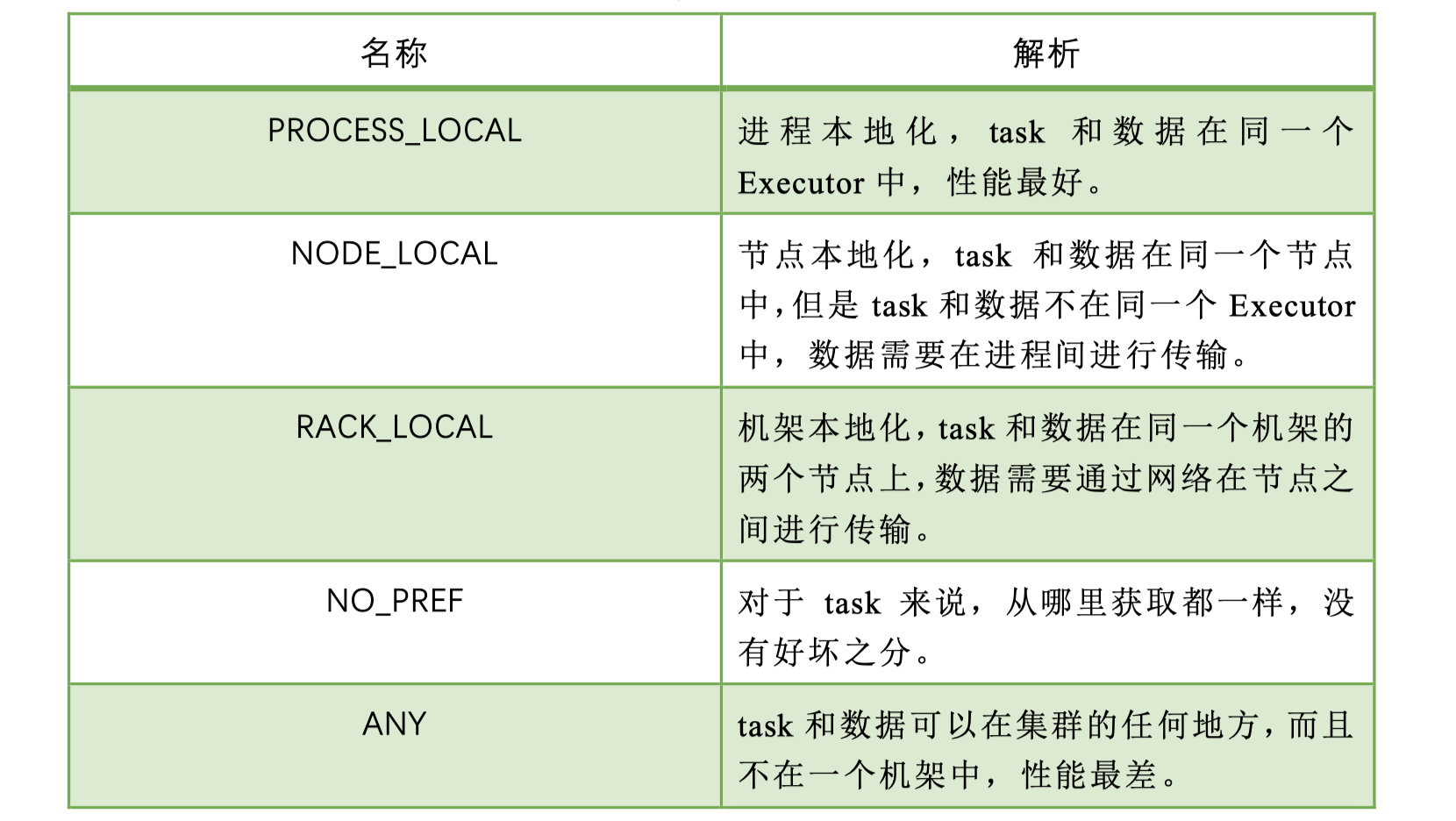
При планировании выполнения Spark всегда пытается запустить каждую задачу на самом высоком уровне локальности. Когда задача запускается на уровне локальности, но все узлы, соответствующие этому уровню локальности, не имеют свободных ресурсов и запуск завершается с ошибкой. уровень местности не будет немедленно понижен для запуска, но задача будет запущена с этим уровнем местности снова в течение определенного периода времени. Если лимит времени будет превышен, задача будет понижена и запущена, и будет запущен следующий уровень местности. предстать перед судом и так далее.
Увеличивая максимально допустимое время задержки для каждой категории, соответствующий Исполнитель на этапе ожидания может иметь соответствующие ресурсы для выполнения задачи, что в определенной степени улучшает производительность работы.
Неудачная повторная попытка и черный список
Помимо выбора соответствующей задачи для планирования и запуска, вам также необходимо отслеживать статус выполнения задачи. Как упоминалось ранее, именно SchedulerBackend работает с внешним миром после того, как задача передается исполнителю, чтобы начать выполнение. , Исполнитель сообщит о состоянии выполнения SchedulerBackend, а SchedulerBackend сообщит TaskScheduler, TaskSc Хедулер находит TaskSetManager, соответствующий Задаче, и уведомляет TaskSetManager, чтобы TaskSetManager знал статус сбоя и успеха Задачи. Для неудавшейся Задачи будет записано количество сбоев, если количество сбоев не превысило. максимальное количество повторов, затем верните его в пул задач для планирования, иначе все приложение завершится сбоем.
В процессе записи количества сбоев Задачи будут записаны идентификатор Исполнителя и Хост, на котором она в последний раз потерпела неудачу, так что в следующий раз, когда эта Задача будет запланирована, будет использоваться механизм черного списка, чтобы предотвратить ее планирование на узле, который в прошлый раз не удалось. Определенная отказоустойчивость. В черном списке записываются идентификатор исполнителя и хост, на котором в последний раз произошел сбой задачи, а также соответствующее время «черного списка». Время «черного списка» означает, что задачу не следует планировать на этом узле в течение этого периода.
ссылка:



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
