Серия NL2SQL Advanced (3): Подробное объяснение практик приложений с открытым исходным кодом Data-Copilot, Chat2DB и платформы оптимизации Text2SQL Vanna [Text2SQL]
Серия NL2SQL Advanced (3): Data-Copilot, Chat2DB, Vanna Платформа оптимизации Text2SQL, практика применения приложений с открытым исходным кодом, подробное объяснение Text2SQL.
Серия практик NL2SQL (1): Углубленный анализ навыков применения проекта Prompt в text2sql.
Цель задачи NL2SQL — преобразовать вопросы пользователей о базе данных на естественном языке в соответствующие запросы SQL. С развитием LLM использование LLM для NL2SQL стало новой парадигмой. В этом процессе особенно важно то, как использовать быстрые проекты для изучения возможностей LLM NL2SQL.
1.Data-Copilot
Связь:https://github.com/zwq2018/Data-Copilot
demoСвязь:https://huggingface.co/spaces/zwq2018/Data-Copilot
бумага Связь:https://arxiv.org/pdf/2306.07209.pdf
1.1 Соответствующее введение
краткое содержание:
Различные отрасли, такие как финансы, метеорология и энергетика, ежедневно генерируют большие объемы разнородных данных. Существует острая необходимость в инструменте для эффективного управления, обработки и отображения этих данных. DataCopilot автономно управляет и обрабатывает большие объемы данных путем развертывания больших языковых моделей (LLM), то есть объединяет обширные данные в различных областях (акции, фонды, компании, экономика и новости в реальном времени) для удовлетворения разнообразных запросов пользователей, расчетов, прогнозов, Визуализация и другие нужды. Вам нужно всего лишь ввести текст, чтобы сообщить DataCopilot, какие данные вы хотите увидеть. Нет необходимости выполнять утомительные операции или писать код самостоятельно. DataCopilot может автономно преобразовывать необработанные данные в визуальные результаты, которые лучше всего соответствуют намерениям пользователя, поскольку он может автономно помочь вам найти. и обрабатывать данные, анализировать данные и рисовать графики без помощи человека.
Многие исследования изучали LLMs потенциал. Например Sheet-Copilot、Visual ChatGPT、Audio GPT использовать LLMs Используйте инструменты в области зрения, голоса и других областях для анализа данных, редактирования видео и преобразования голоса. С точки зрения науки о данных таблицы, визуализации и аудио можно рассматривать как форму данных, и все эти задачи можно считать задачами, связанными с данными. поэтому,Возникает вопрос: в условиях универсальных данныхиз,LLMs Можете ли вы построить автоматизированные научные рабочие процессы, чтобы иметь дело с Различныйиданные Связанныйиз Задача?для достижения этой цели,Необходимо решить несколько задач:
(1) С точки зрения данных:Используйте напрямую LLMs Чтение и обработка огромных объемов данных не только непрактично, но и создает потенциальный риск утечки данных.
(2) С точки зрения модели:LLMs Плохо справляется с численными расчетами и может не иметь подходящих вызываемых внешних инструментов для удовлетворения разнообразных потребностей пользователей, что ограничивает LLMs коэффициент использования.
(3) С точки зрения задачи:хотя LLMs Демонстрирует сильные возможности работы с несколькими выборками, но многие задачи, связанные с данными, сложны и требуют сочетания нескольких операций, таких как поиск данных, вычисления и операции с таблицами, а результаты должны быть представлены в нескольких форматах, таких как изображения, таблицы, и текст. Они выходят за рамки текущего. LLMs способность.
Data-Copilot основан на LLM из системы,Используется для решения связанных с иданными из Задачах.,Подключен к миллиардам данных, разнообразных в зависимости от потребностей пользователей. Самостоятельно разрабатывает инструменты интерфейса.,Для эффективного управления, вызова, обработки и визуализации данных. При получении сложных запросов,Data-Copilot самостоятельно вызовет эти самостоятельно разработанные интерфейсы.,Создайте рабочий процесс, отвечающий намерениям пользователя。без помощи человекаизслучай,Он может умело конвертировать оригинальный контент из разных источников и форматов в гуманизированный результат.,Такие как графика, таблицы и текст.
- Основные вклады
- разработал общую систему DataCopilot, который объединяет источники из разных областей и разнообразных потребностей пользователей. LLM Интегрировано в весь процесс, сокращая утомительный труд и знания.
- Data-Copilot может управлять собой сам、иметь дело с、анализировать、предсказыватьи Визуализацияданные。когда запрос получен,Он преобразует необработанный контент в информативные результаты, которые лучше всего соответствуют намерениям пользователя.
- В качестве дизайнера и планировщика Data-Copilot Содержит два этапа: оффлайн Дизайн интерфейса (дизайнер) ионлайн Планирование интерфейс(Планировщик).
- Построен китайский финансовый рынок из Data-Copilot Demo
- основной метод
Data-Copilot — это общая система больших языковых моделей, состоящая из двух основных этапов: проектирование интерфейса и планирование интерфейса.
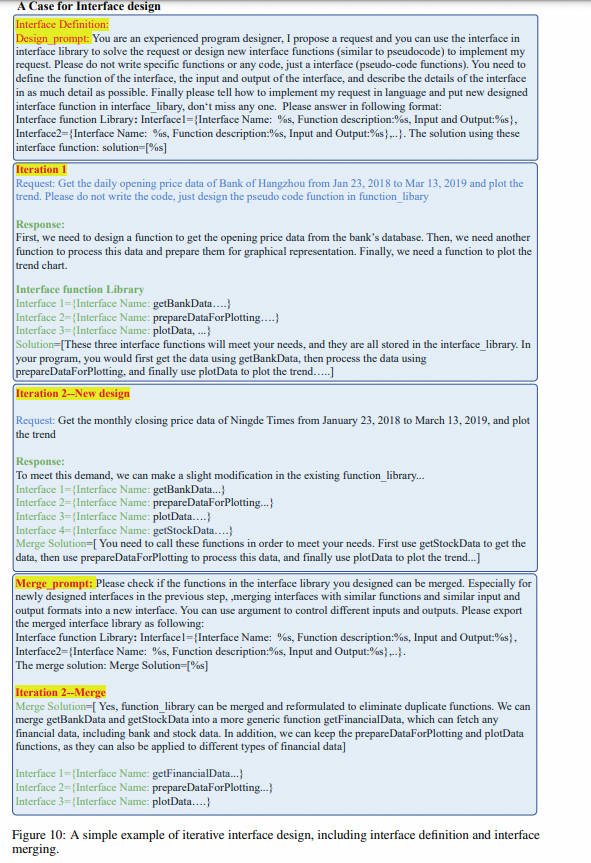
Дизайн интерфейса:Мы разработали self-request процесс создания LLM Возможность автономно генерировать достаточное количество запросов из небольшого количества начальных запросов. Затем, LLM Итеративно проектируйте и оптимизируйте интерфейсы на основе сгенерированных запросов. Эти интерфейсы описываются на естественном языке, что упрощает их расширение и перенос между различными платформами.
Планирование интерфейса:После получения запроса пользователя,LLM Согласно собственному описанию интерфейса и in context demonstration планировать и вызывать инструменты интерфейса, Разверните рабочий процесс, отвечающий потребностям пользователей, и представьте им результаты в различных формах.
В целом, Data-Copilot обеспечивает высокоавтоматизированную обработку и визуализацию данных за счет автоматического создания запросов и независимого проектирования интерфейсов для удовлетворения потребностей пользователей и отображения результатов пользователям в различных формах.
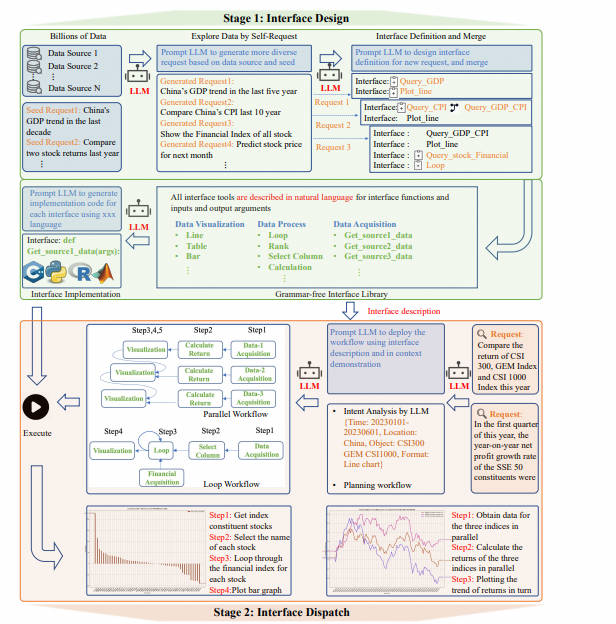
1 - Дизайн интерфейса
Как показано на рисунке, сначала необходимо реализовать управление данными, и для первого шага требуются инструменты интерфейса.
Data-Copilot разработает большое количество интерфейсов в качестве инструмента управления данными. Интерфейс представляет собой модуль, состоящий из естественного языка (описание функции) и кода (реализация), который отвечает за такие задачи, как сбор и обработка данных.
- Во-первых, LLM Запрашивать через несколько торрентов и автономно обрабатывать множество запросов (explore data by self-request)。
- Затем, LLM Спроектируйте соответствующие интерфейсы для этих запросов (интерфейс definition: Включены только описания и параметры) и постепенно оптимизируются на каждой итерации. интерфейса (interface merge)。
- Наконец, мы используем LLM Мощные возможности генерации изкодов для каждого интерфейса позволяют создавать отдельные исходные коды в библиотеке интерфейсов. (interface implementation)。
Этот процесс отделяет проектирование интерфейса от конкретной реализации, создавая универсальный набор инструментов интерфейса, способный удовлетворить большинство запросов.
2 – Планирование интерфейса
На предыдущем этапе мы приобрели различные инструменты общего интерфейса для сбора, обработки и визуализации данных. Каждый интерфейс имеет четкое и подробное функциональное описание. Как показано в двух примерах на рисунке 2, Data-Copilot формирует рабочий процесс от данных к множественным формам результатов, планируя и вызывая различные интерфейсы в запросах в реальном времени.
- Data-Copilot намерение сначалаанализироватьточно понимать пользователейизпросить。
- Как только намерения пользователя будут точно поняты, Data-Copilot Для обработки запросов пользователей будет запланирован разумный рабочий процесс. мы инструктируем LLM фиксированный форматиз JSON, представляющий каждый шаг расписания, например. step={"arg":"","function":"", "output":"","description":""}。
Руководствуясь описаниями и примерами интерфейсов, Data-Copilot организует планирование интерфейсов на каждом этапе, последовательно или параллельно.
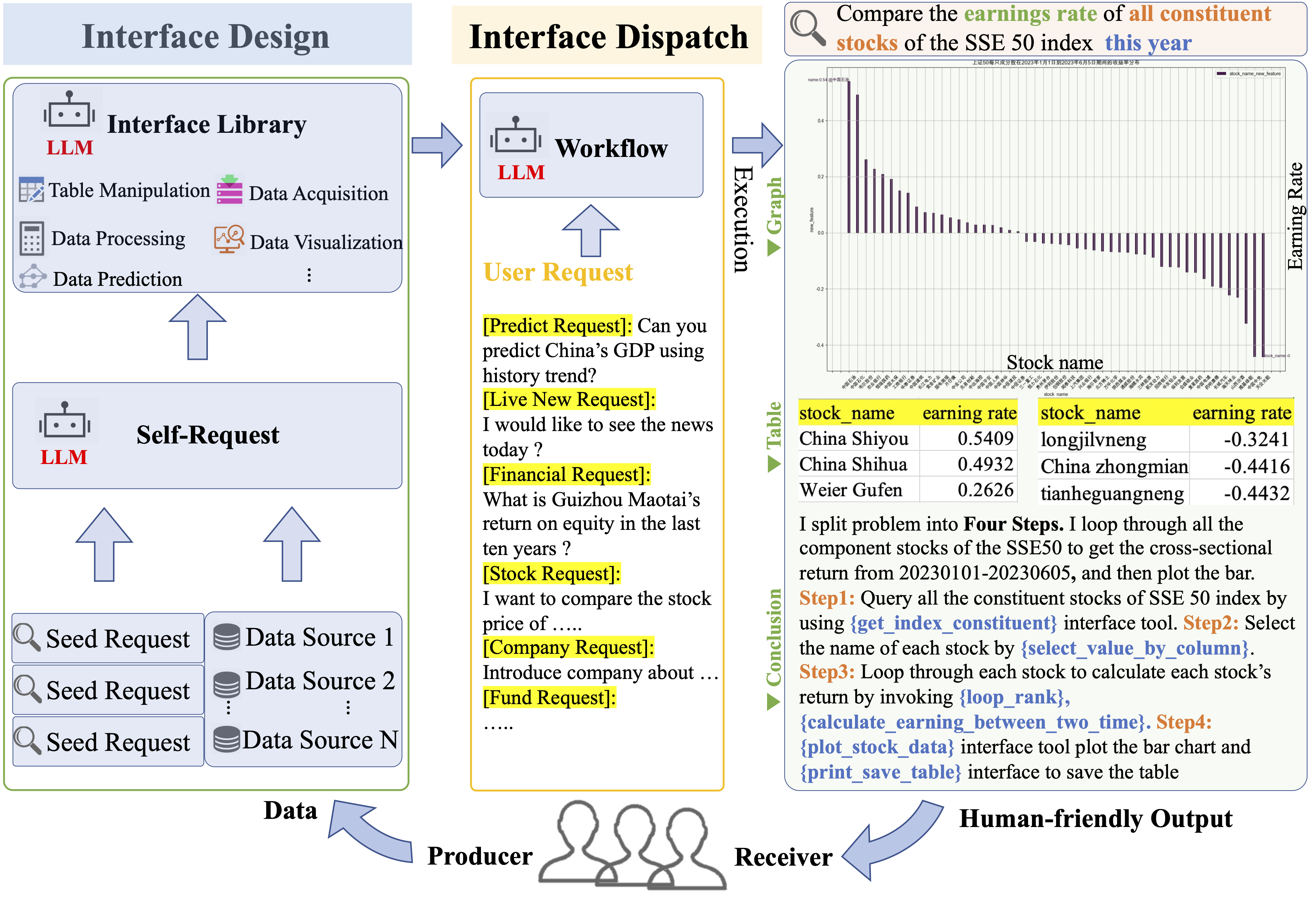
В качестве примера ниже:
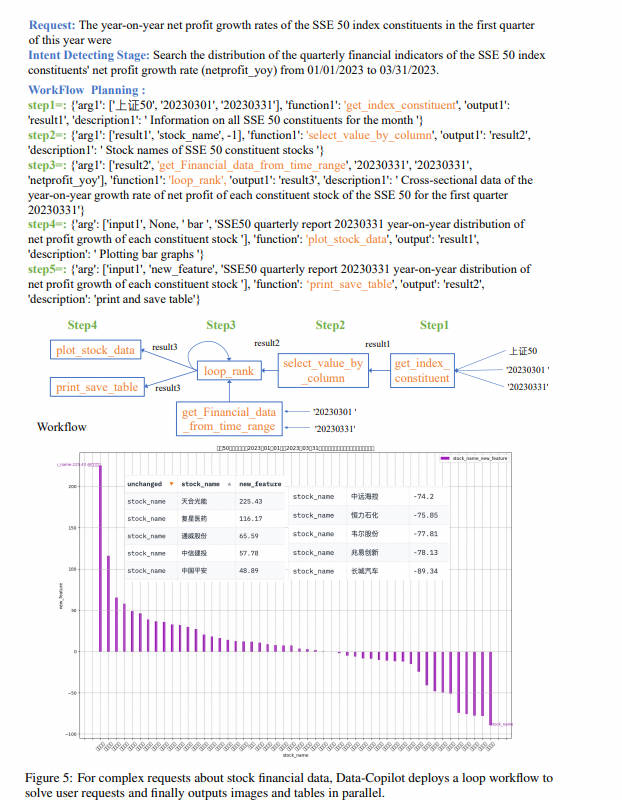
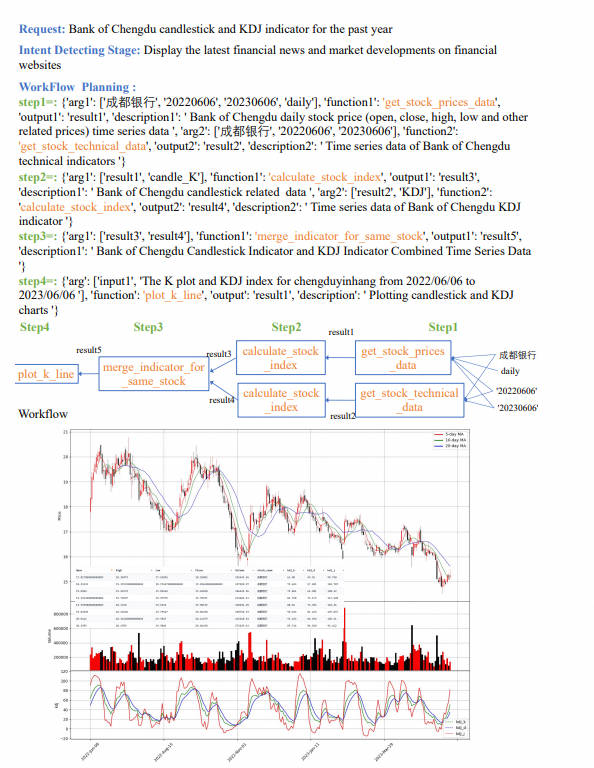
Каков годовой темп роста чистой прибыли всех акций, входящих в индекс Shanghai Composite 50, в первом квартале этого года? undefinedData-Copilot самостоятельно разработала следующий рабочий процесс:
Чтобы решить эту сложную проблему, Data-Copilot использует интерфейс loop_rank для реализации нескольких циклических запросов.
Наконец, рабочий процесс выполняется, и результаты следующие: по оси абсцисс указано название каждой из составляющих акций, а по оси ординат — годовой темп роста чистой прибыли в первом квартале.
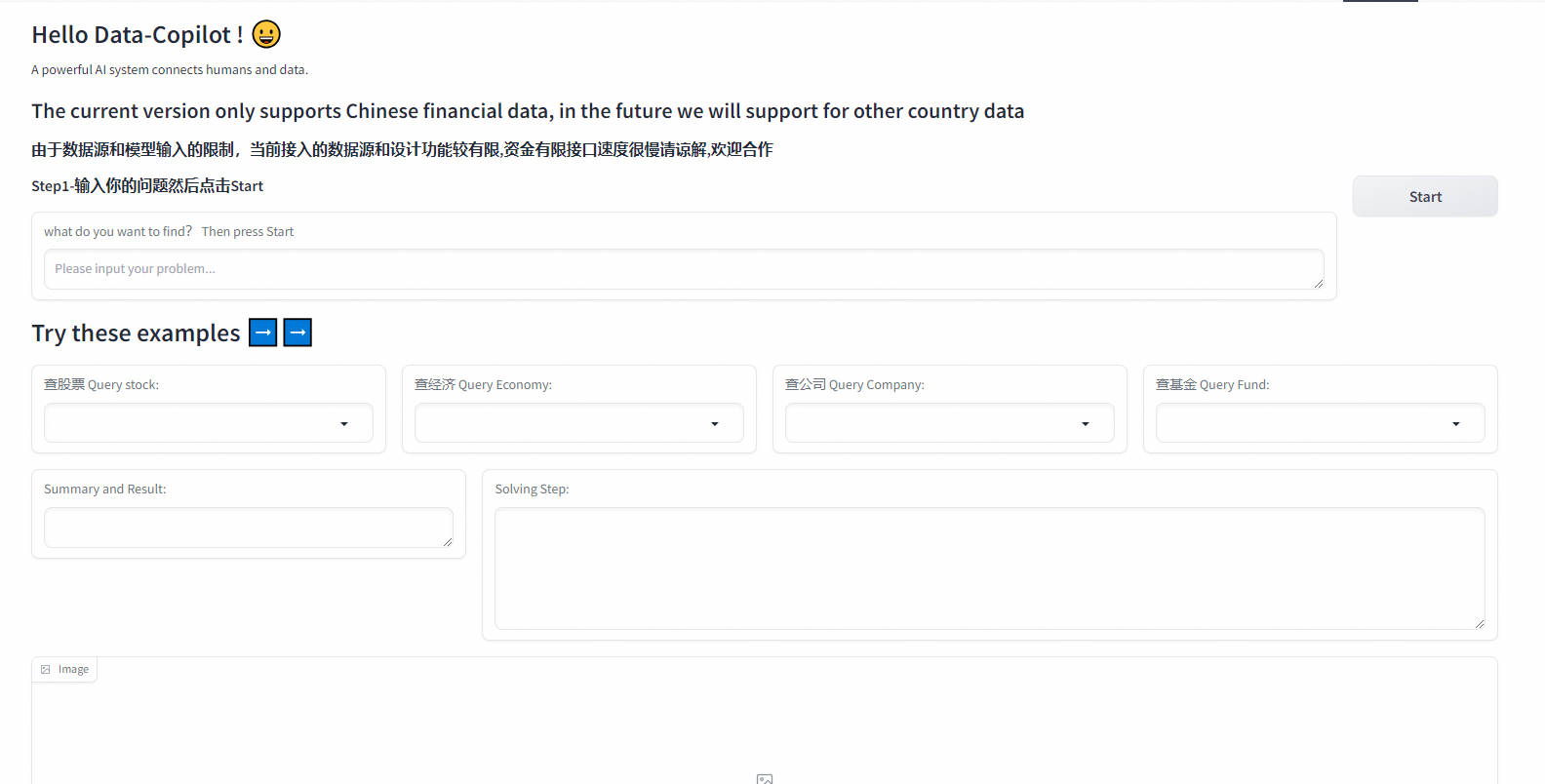
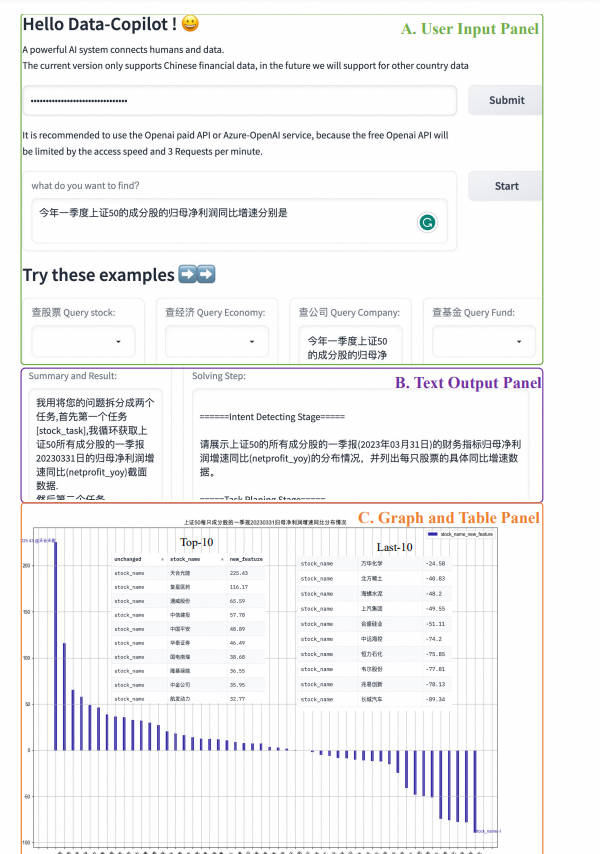
1.2 Как использовать
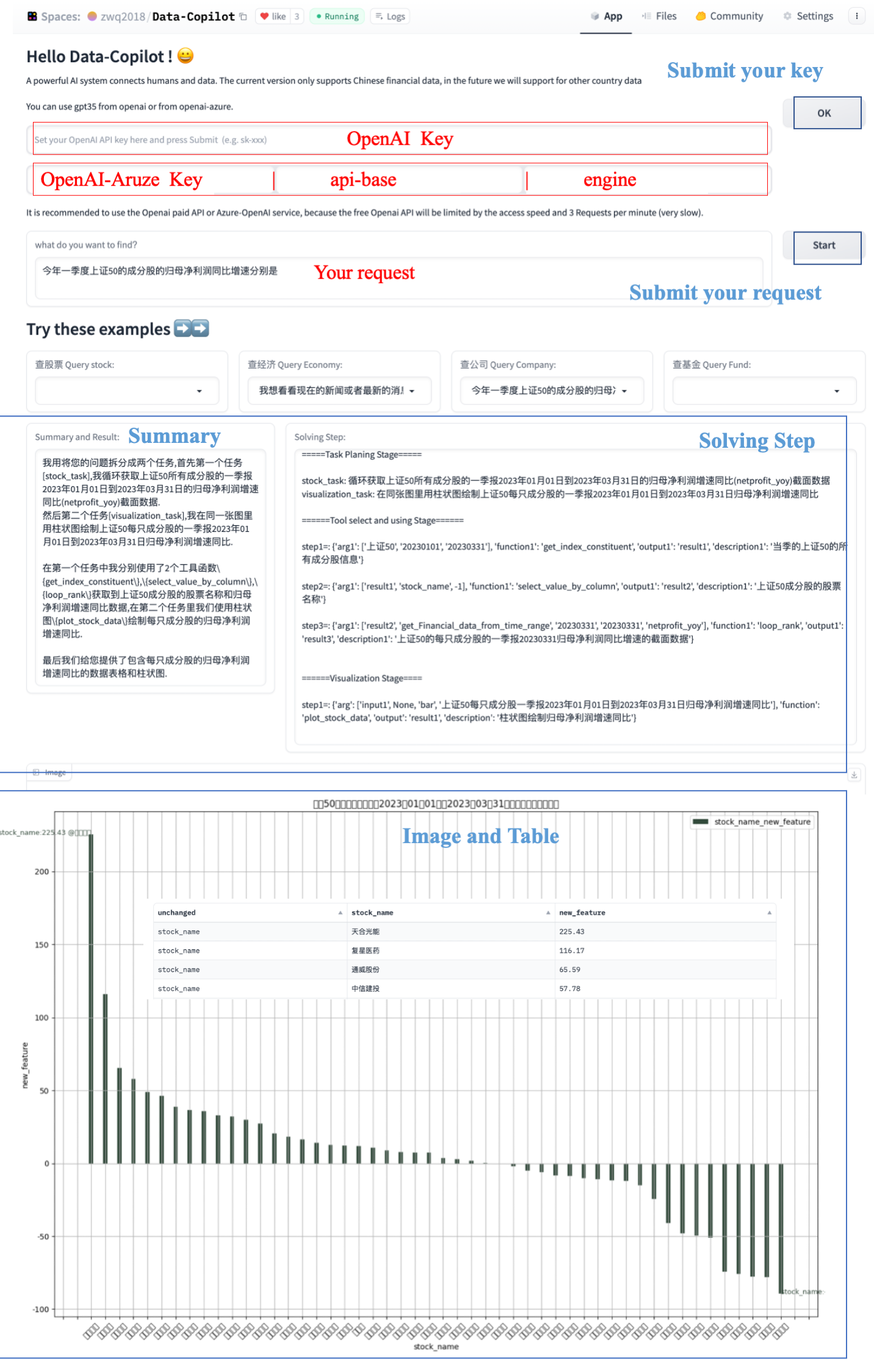
Откройте его в Spaces, чтобы получить доступ к китайским акциям, фондам и некоторым экономическим данным. Однако, поскольку длина входного токена gpt3.5 составляет всего 4 КБ, текущий объем доступа к данным все еще относительно невелик. В будущем Data-Copilot будет поддерживать больше данных с зарубежных финансовых рынков.
Шаг 1. Введите ключ Openai или Openai-Azure. Попробуйте использовать платный API Openai. Если вы планируете использовать службы Azure, не забудьте ввести API-базу и движок в дополнение к ключу.
Шаг 2: Нажмите кнопку «ОК», чтобы отправить
Шаг 3. Введите запрос, который вы хотите запросить, в текстовое поле или напрямую выберите вопрос из поля примера, и он автоматически появится в текстовом поле.
Шаг 4. Нажмите кнопку «Начать», чтобы отправить запрос.
Шаг 5: Data-Copilot отобразит промежуточный процесс планирования в разделе «Шаги решения» и отобразит текст (сводку и результаты), изображения и таблицы в конце.
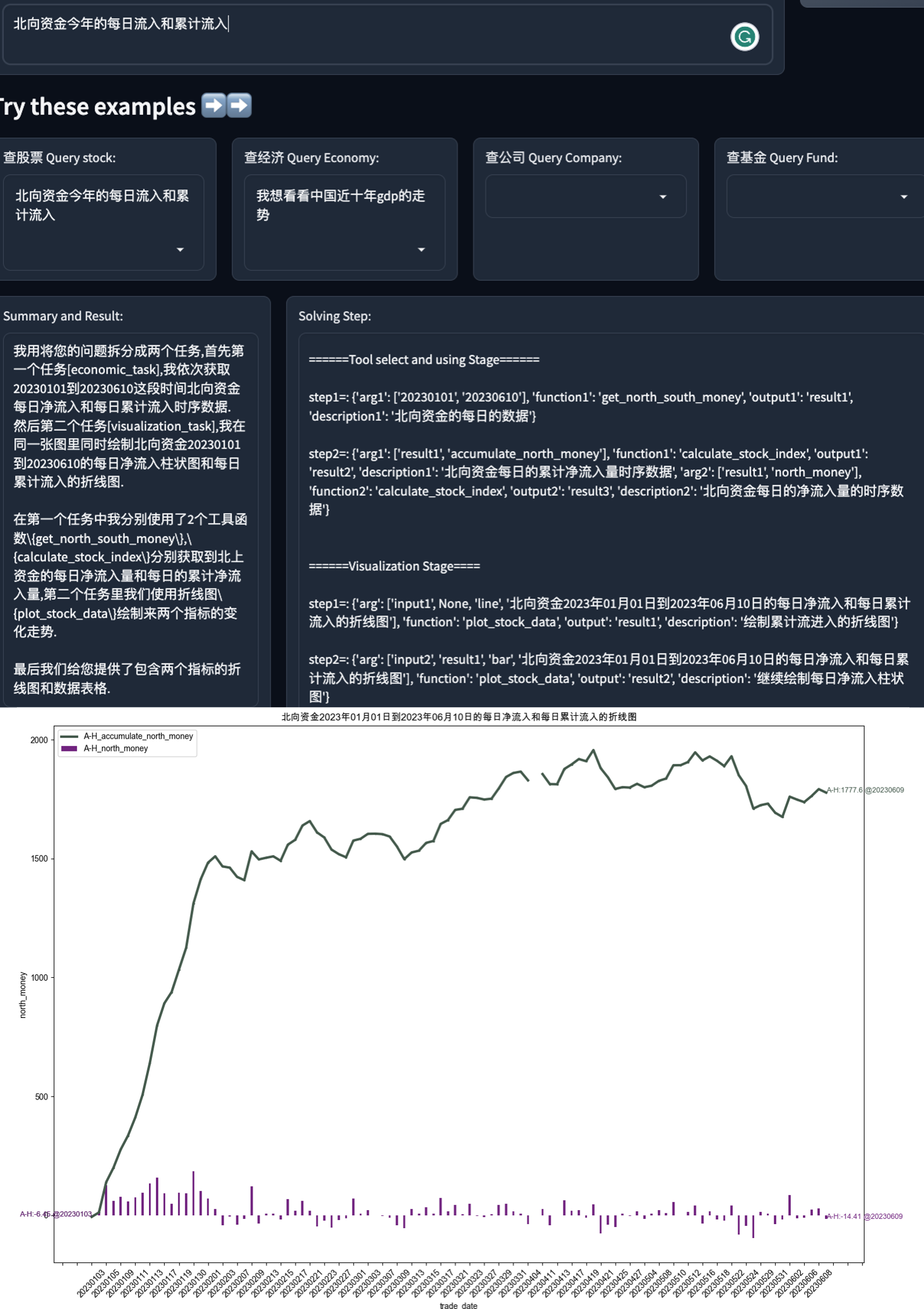
1.3 Отображение эффектов
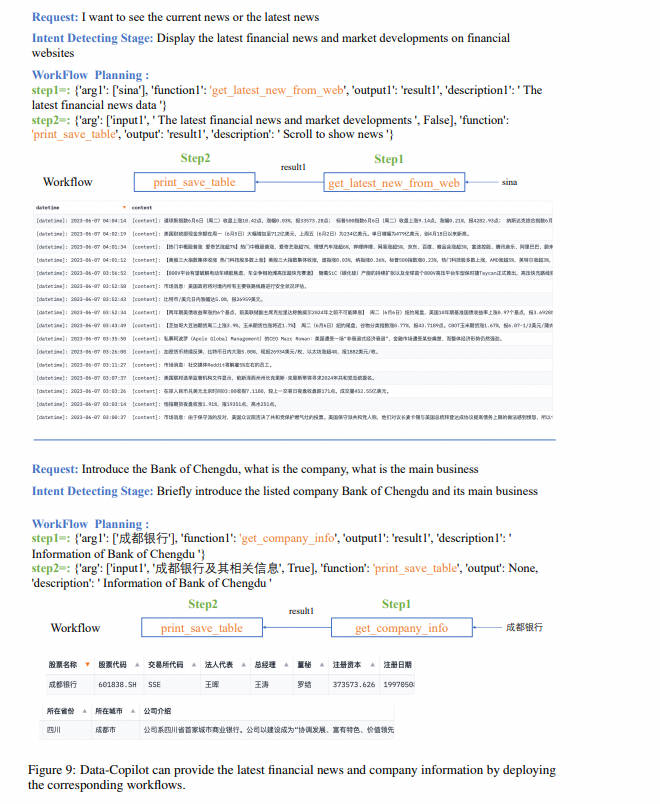
Вопрос пользователя: Прогноз квартала Китая на следующие четыре квартала Рабочий процесс развертывания GDPundef: Получить историю GDP данные ----> Прогнозирование будущего с помощью моделей линейной регрессии -----> Выходная таблица

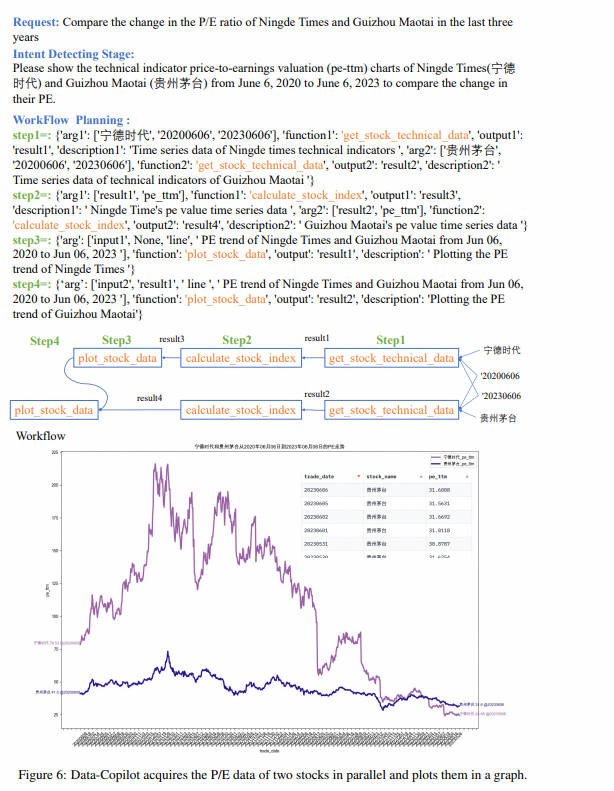
Я хочу посмотреть на коэффициенты P/E CATL и Kweichow Moutai за последние три года.
Рабочий процесс развертывания
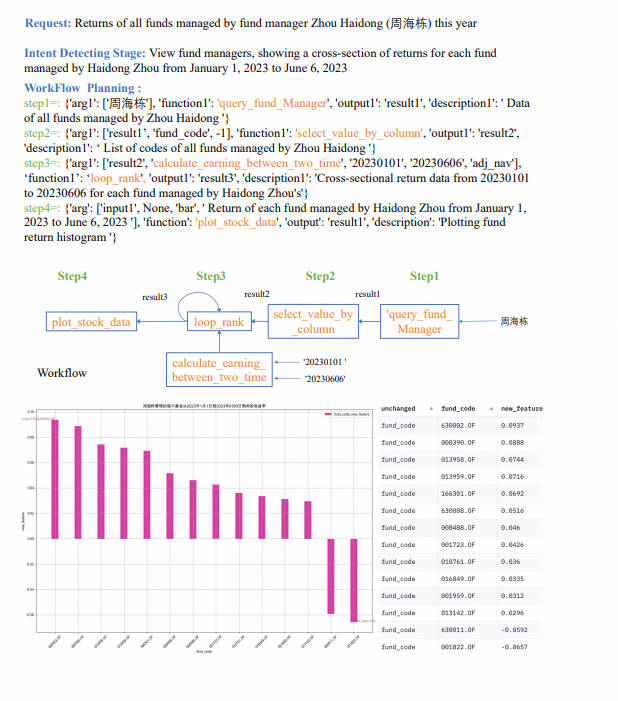
Вопрос пользователя: Какова доходность фондов, управляемых управляющим фондом Чжоу Хайдуном в этом году?
Показатели KDJ Банка Чэнду за прошедший год
Простой пример итеративного проектирования интерфейса, включая определение интерфейса и объединение интерфейсов.
Советы и дизайн презентации для этапа планирования интерфейса

2. Chat2DB
Chat2DBдаа ИИизданные менеджмент、развиватьианализироватьинструмент。его ядродаAIGC(ИИгенерироватькод)способность。оно может изменить природуязык Преобразовать вSQL,Преобразование SQL в естественный язык,Также доступна автоматическая отчетность,Значительно повысить эффективность работы персонала. через продукт,может быть достигнутоданныеуправлять、данныеразвиватьиданныеанализироватьиз Функция。Прямо теперь позволяет тем, кто не понимает SQL, использовать функцию быстрого запроса бизнес-данных и генерации отчетов.
Когда вы используете Chat2DB,Вы обнаружите, что этот искусственный интеллект очень мощный. когда вы делаете какую-либо операцию,Он даст вам несколько советов. Все эти предложения анализируются на основе Chat2DB изAIModel. Это поможет вам лучше выполнять свою работу. Когда вы занимаетесь разработкой библиотеки данных,Он поможет вам напрямую использовать естественный язык, генерировать SQL.,Дайте вам предложения по оптимизации SQL,Помочь вам проанализировать производительность SQLiz,Помочь вам проанализировать план выполнения SQLиз,Это также может помочь вам быстро провести тестовые данные SQL.,Оценить систему. код и т. д. Когда вы проводите анализ данных из,Он может подчиняться непосредственно вам,Помочь вам проанализировать данные,Помогите вам с отчетами по ограниченным данным и многим другим.
чиновник Связь:https://github.com/chat2db/Chat2DB/blob/main/README_CN.md
руководство Связь:https://docs.chat2db-ai.com/docs/start-guide/getting-started
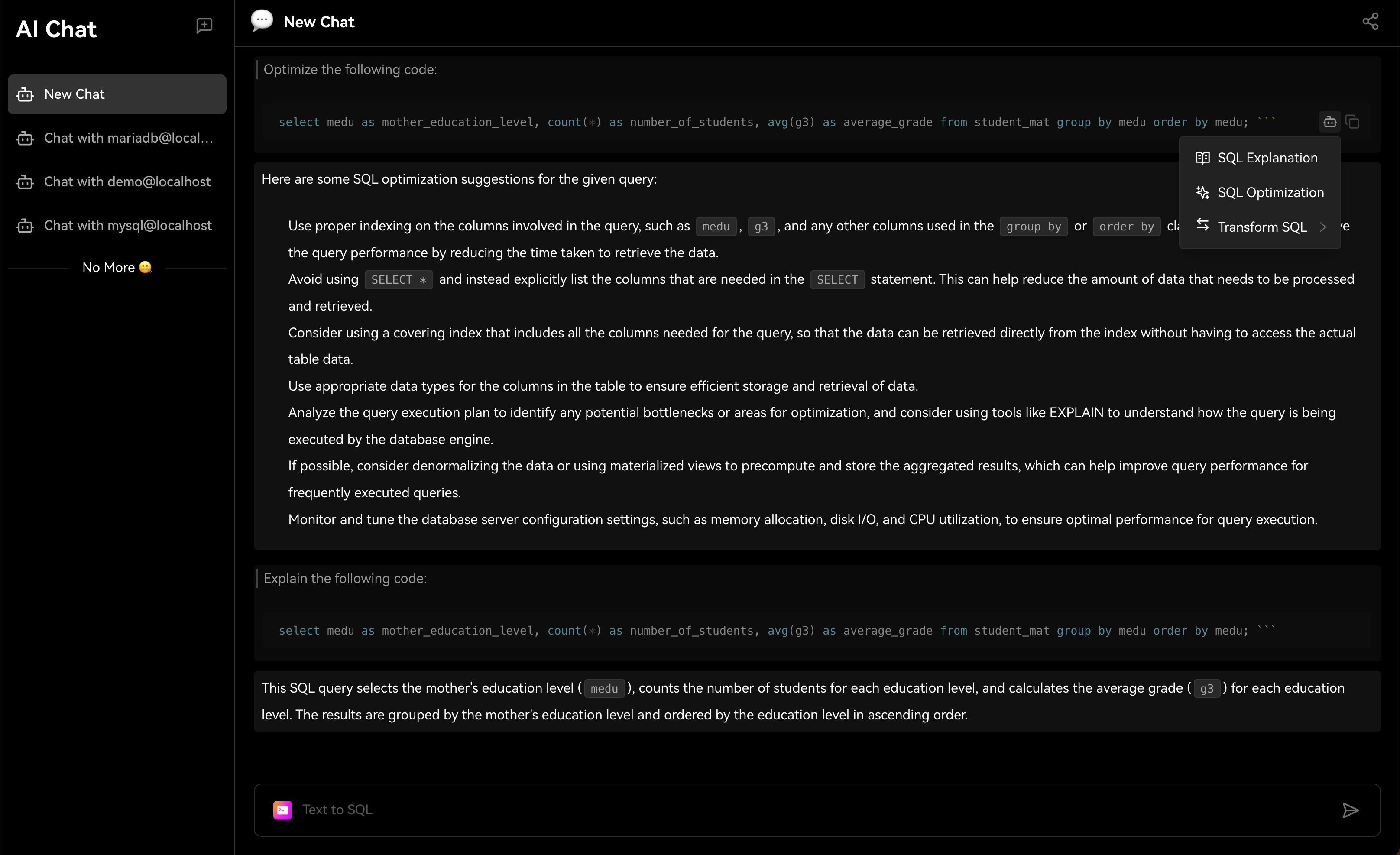
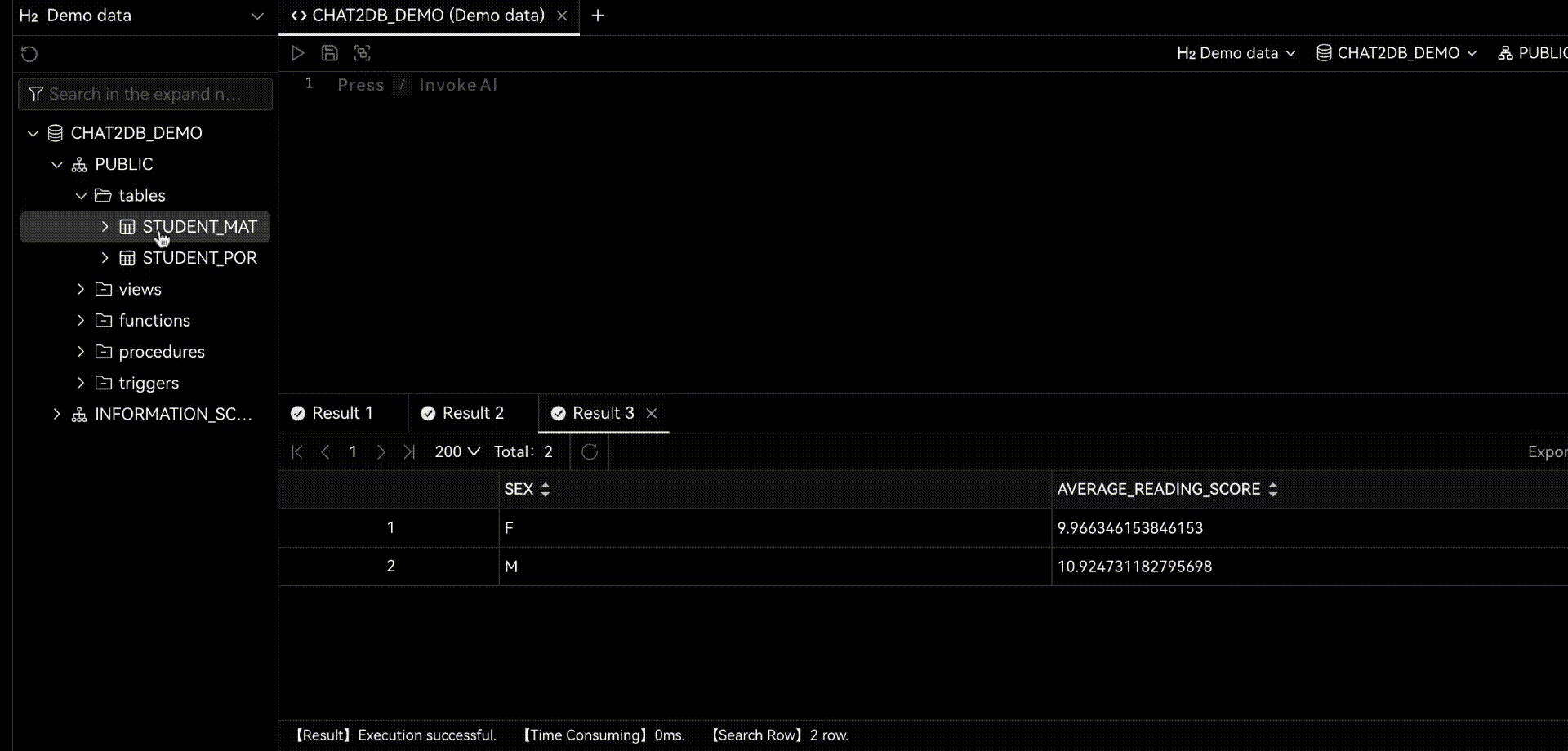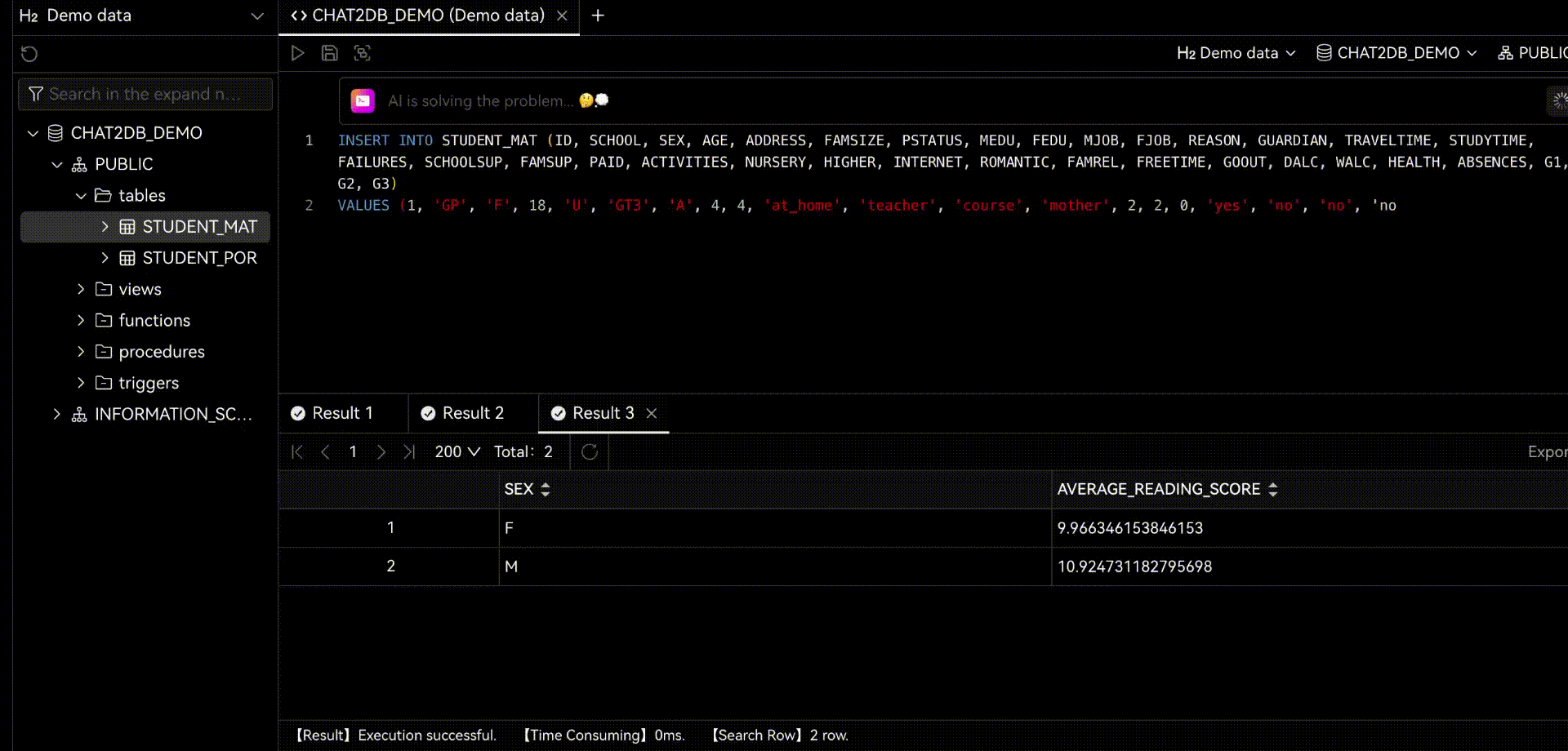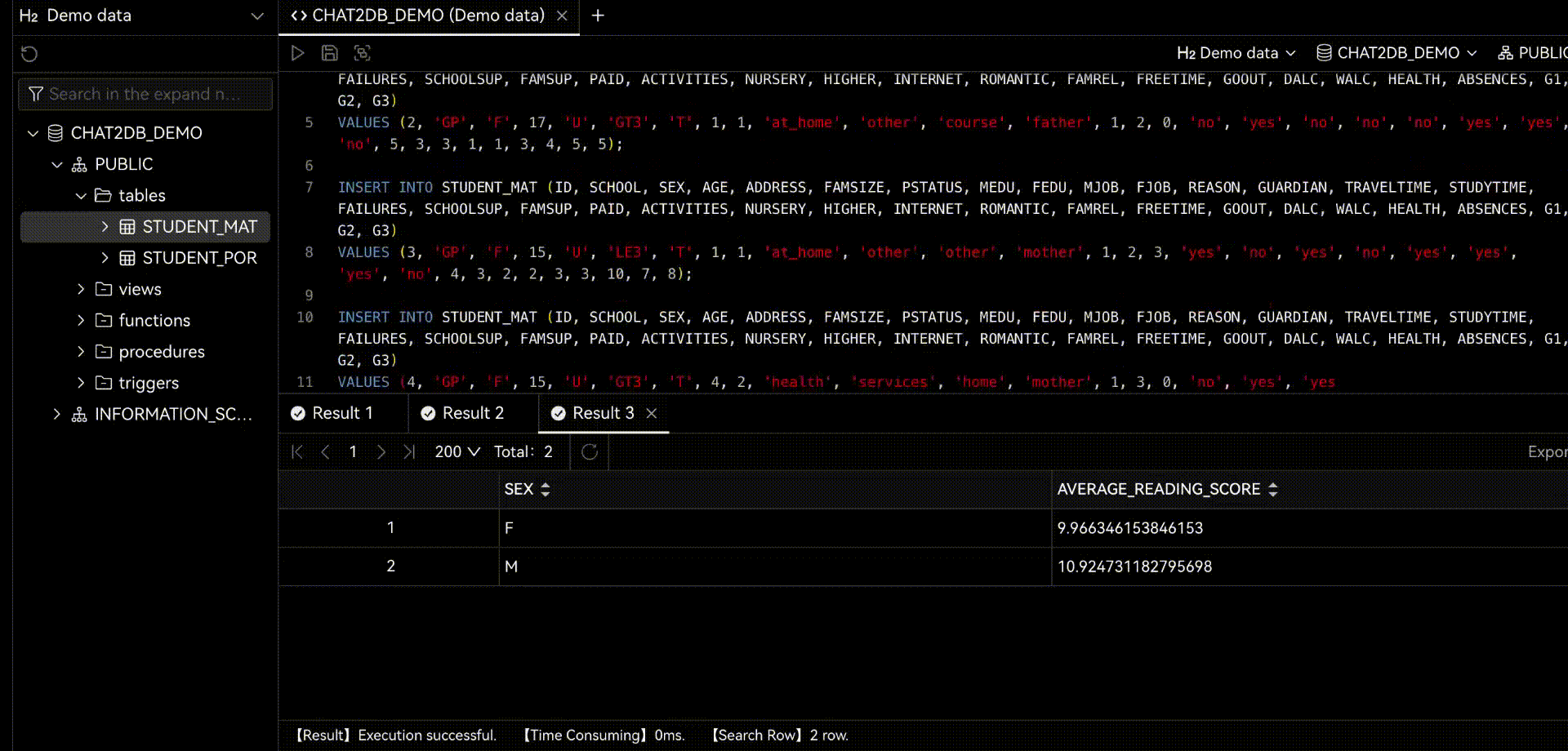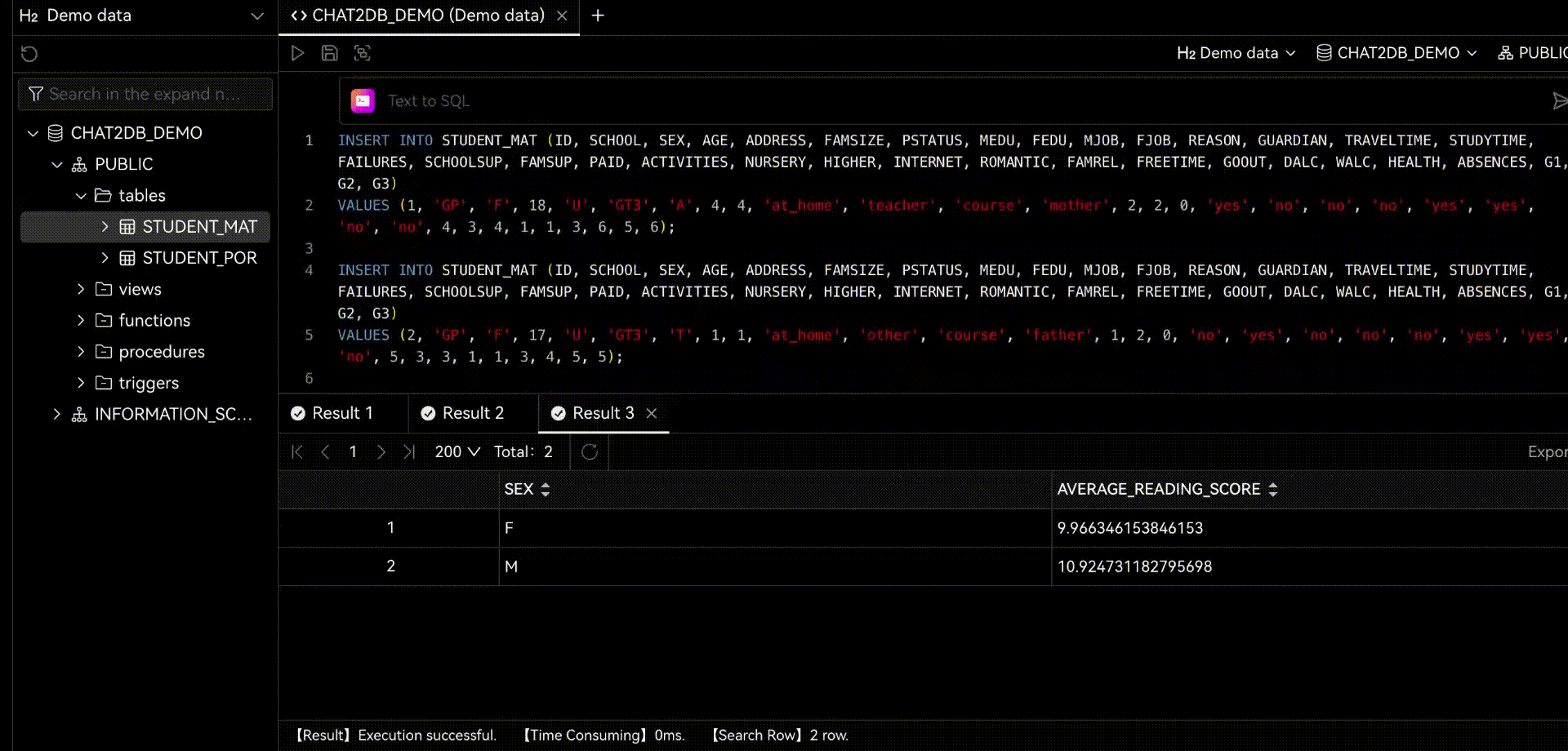
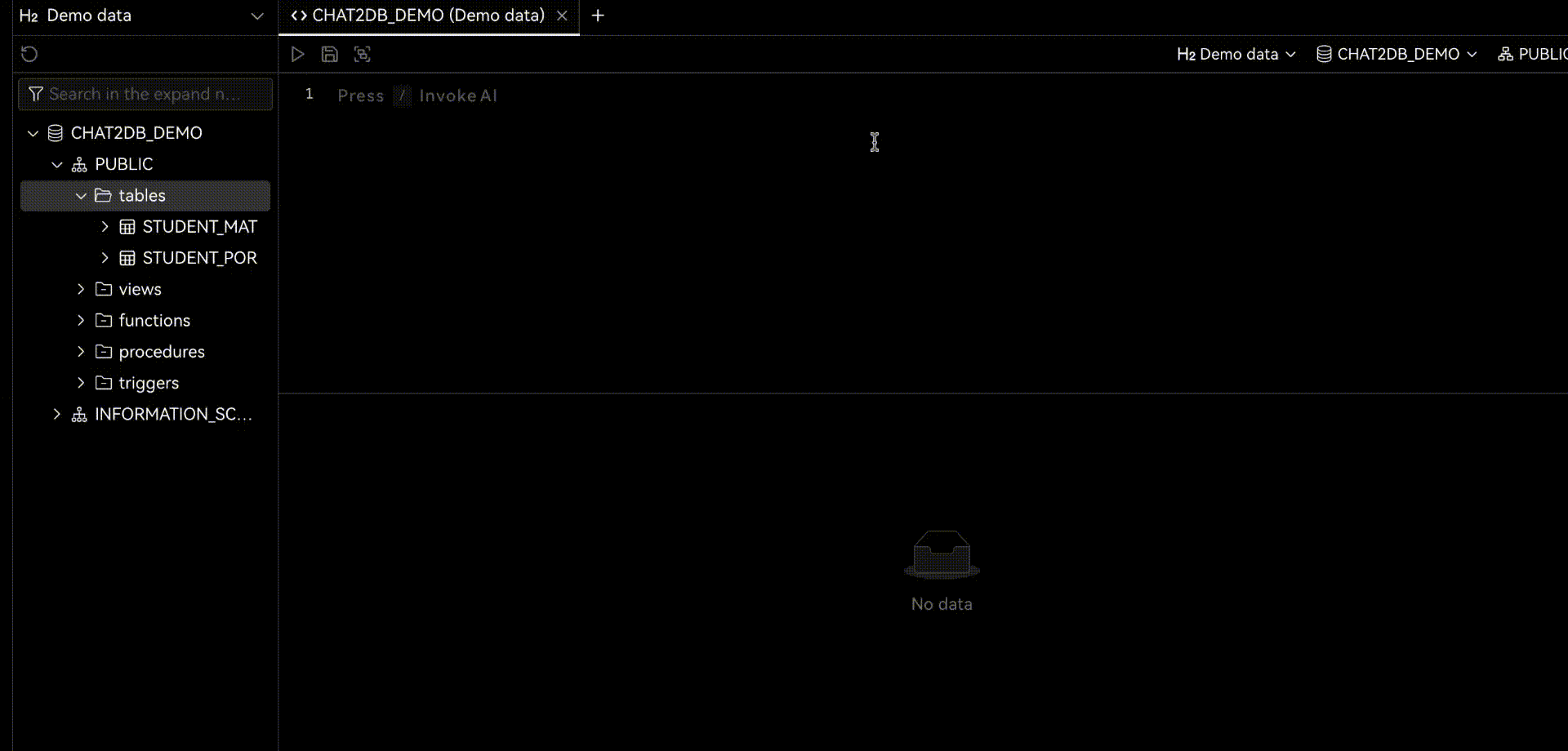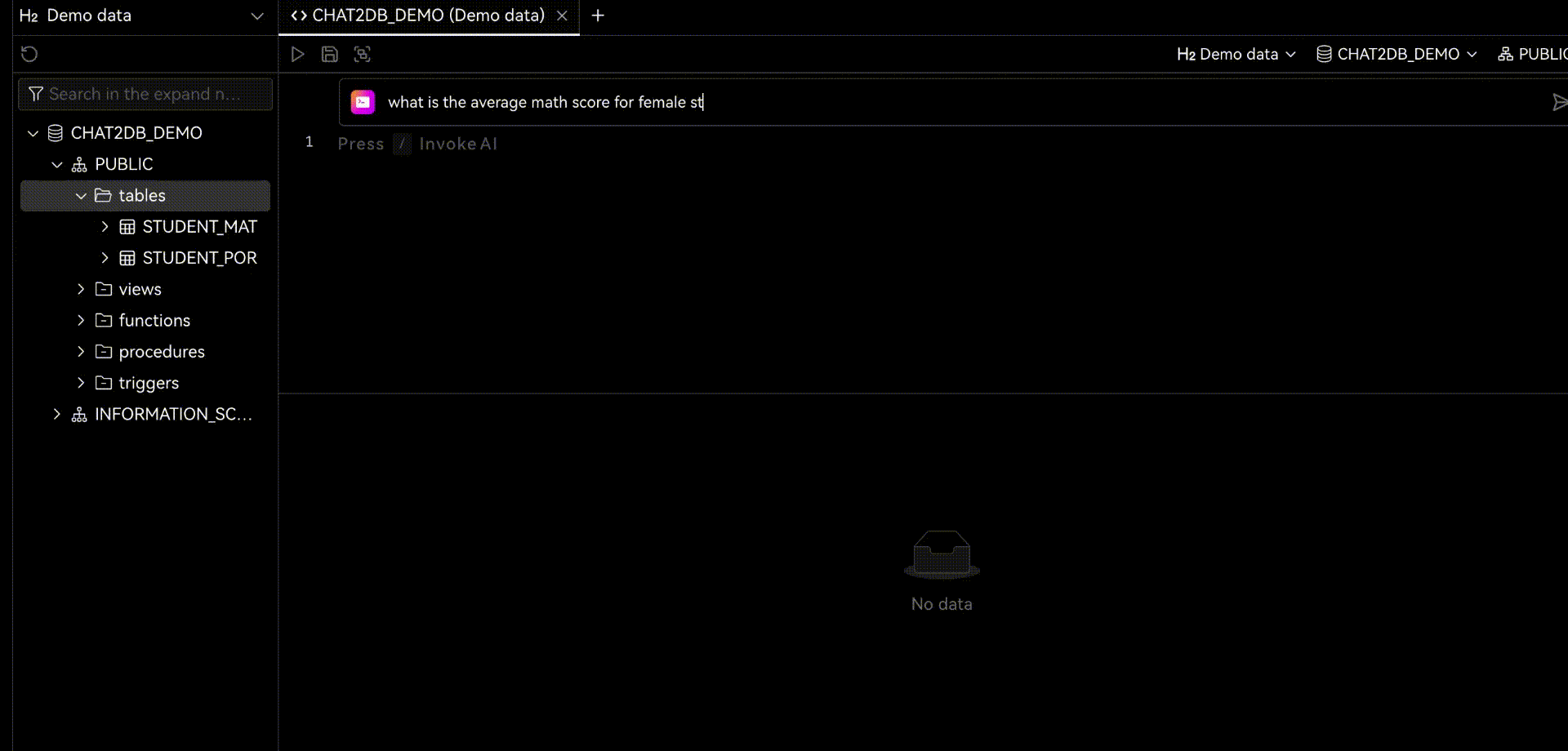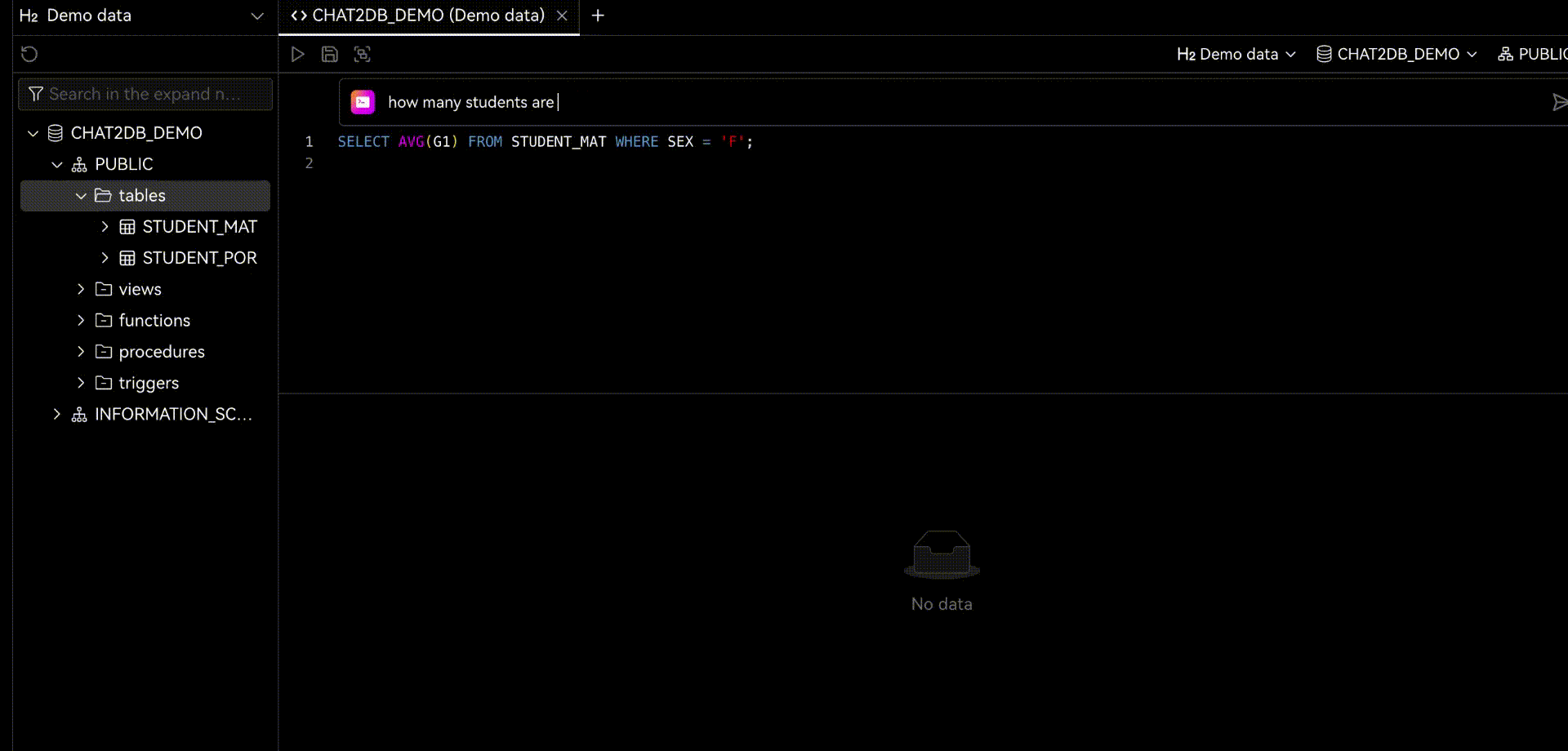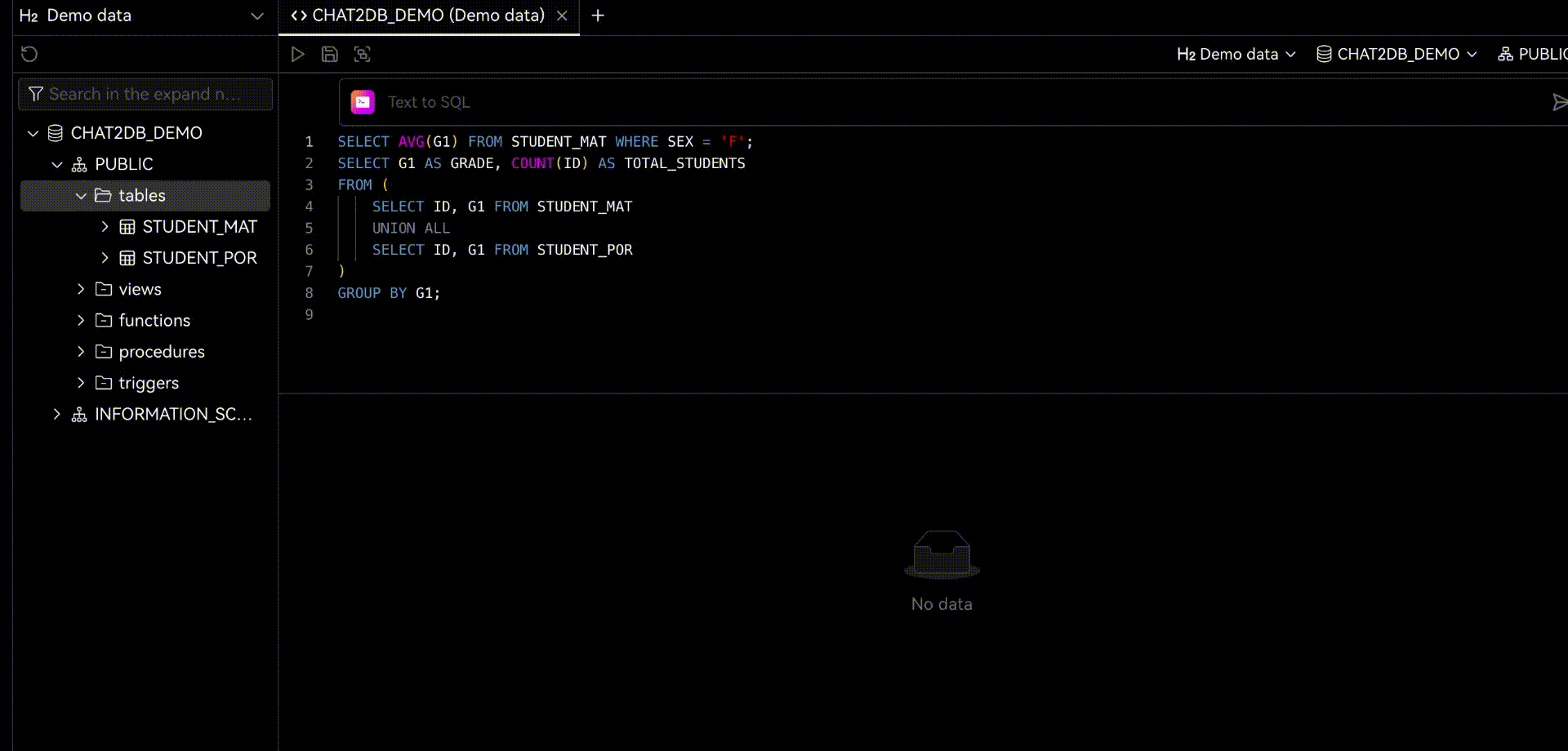
2.1 Chat2DB-GLM
Chat2DB-GLMдаChat2DBПроекты с открытым исходным кодомизкомпоненты,Разработан, чтобы обеспечить эффективный и действенный способ,будет естественнымязык Запрос Преобразовать вструктурированныйизSQLзаявление。Этот открытый исходный кодизChat2DB-SQL-7BМодель,Имеет 7B параметров,Тщательно настроен на основе CodeLlama. Эта модель специально разработана для естественного языка SQL.,Поддерживает различные SQLязыки.,и имеет длину контекста до 16 тыс. дело сспособность。
Модель Chat2DB-SQL-7B поддерживает широкий спектр языков SQL, включая, помимо прочего, Mysql, Postgres, Sqlite и другие общие языки SQL. Такая межъязыковая поддержка обеспечивает широкую применимость и гибкость модели.
2.2 Эффект модели
Chat2DB-SQL-7BМодель продемонстрировала отличную производительность в нескольких ключевых частях SQL. Ниже приводится обзор производительности да Модель в различных ключевых частях SQL.,Возьмем общий SQL в качестве примера.,на основеspiderданные Настройка в процессеиз Результаты оценки показывают Модельсуществоватьиметь дело Различные ключевые части SQL и различные функции SQL (например, функции даты、Строковые функции и т.п.) на способности.
язык | select | where | group | order | function | total |
|---|---|---|---|---|---|---|
Generic SQL | 91.5 | 83.7 | 80.5 | 98.2 | 96.2 | 77.3 |
Chat2DB-SQL-7B в основном настроен для языкаMySql, PostgreSQL и общего SQL. Хотя для других SQLязык,Эта модель по-прежнему обеспечивает базовые возможности преобразования.,Но при работе с конкретным языком специальные функции (такие как функции даты, строковые функции и т. д.),Могут возникнуть ошибки. С набором данных из изменений,Производительность моделей также может различаться.
Обратите внимание, что эта модель предназначена в первую очередь для академических исследований и учебных целей. Хотя мы стремимся обеспечить точность вывода модели, мы не можем гарантировать ее работоспособность в производственной среде. Этот проект и его участники не несут ответственности за любые потенциальные убытки, возникшие в результате использования этой модели. Мы рекомендуем пользователям при использовании моделей тщательно оценивать их пригодность для конкретных случаев использования.
2.3 Модельное обоснование
Вы можете загрузить модель через преобразователи. Обратитесь к следующему фрагменту кода, чтобы использовать модель Chat2DB-SQL-7B. Производительность модели будет зависеть от приглашения. Попробуйте использовать парадигму подсказки в следующем примере. model_path в следующем блоке кода можно заменить на путь к вашей локальной модели.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
model_path = "Chat2DB/Chat2DB-SQL-7B" # Здесь вы можете изменить его на локальный путь Модельиз.
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto",trust_remote_code=True, torch_dtype=torch.float16,use_cache=True)
pipe = pipeline( "text-generation",model=model,tokenizer=tokenizer,return_full_text=False,max_new_tokens=100)
prompt = "### Database Schema\n\n['CREATE TABLE \"stadium\" (\\n\"Stadium_ID\" int,\\n\"Location\" text,\\n\"Name\" text,\\n\"Capacity\" int,\\n\"Highest\" int,\\n\"Lowest\" int,\\n\"Average\" int,\\nPRIMARY KEY (\"Stadium_ID\")\\n);', 'CREATE TABLE \"singer\" (\\n\"Singer_ID\" int,\\n\"Name\" text,\\n\"Country\" text,\\n\"Song_Name\" text,\\n\"Song_release_year\" text,\\n\"Age\" int,\\n\"Is_male\" bool,\\nPRIMARY KEY (\"Singer_ID\")\\n);', 'CREATE TABLE \"concert\" (\\n\"concert_ID\" int,\\n\"concert_Name\" text,\\n\"Theme\" text,\\n\"Stadium_ID\" text,\\n\"Year\" text,\\nPRIMARY KEY (\"concert_ID\"),\\nFOREIGN KEY (\"Stadium_ID\") REFERENCES \"stadium\"(\"Stadium_ID\")\\n);', 'CREATE TABLE \"singer_in_concert\" (\\n\"concert_ID\" int,\\n\"Singer_ID\" text,\\nPRIMARY KEY (\"concert_ID\",\"Singer_ID\"),\\nFOREIGN KEY (\"concert_ID\") REFERENCES \"concert\"(\"concert_ID\"),\\nFOREIGN KEY (\"Singer_ID\") REFERENCES \"singer\"(\"Singer_ID\")\\n);']\n\n\n### Task \n\nНа основании предоставления базы данных информация о схеме, как many singers do we have?[SQL]\n"
response = pipe(prompt)[0]["generated_text"]
print(response)- Требования к оборудованию
Модель | Минимальная память графического процессора (вывод) | Минимальная память графического процессора (эффективная точная настройка параметров) |
|---|---|---|
Chat2DB-SQL-7B | 14GB | 20GB |
- Модельскачать
- huggingface:Chat2DB-SQL-7B
- modelscope:Chat2DB-SQL-7B
3. Платформа оптимизации Vanna Text2SQL.
- На основе языка Python. Может использоваться непосредственно в ваших собственных проектах через пакет PyPi vanna.
- RAGрамка。Многие люди понимаютRAGСамый типичныйизприложениеда Частная база знаний Вопросы и ответы,Вносите личные знания с помощью подсказок, чтобы повысить точность ответов LLM. Но RAG сам по себе является решением для быстрого улучшения.,Его можно использовать в других сценариях применения LLM. Например, мы уже представили это при создании агента инструментов.,Схема useRAG может уменьшить объем информации об API, вводимой в Prompt.,Уменьшить контекстное окно занятий,Сохранить токены. Затем Ванна оптимизирует входной LLMизPrompt через схему RAG.,Чтобы максимизировать точность преобразования естественного языка в SQLиз,улучшатьданныеанализироватьрезультатиз Доверие。
3.1 Принцип работы Ванны
чиновник Связь:https://github.com/vanna-ai/vanna
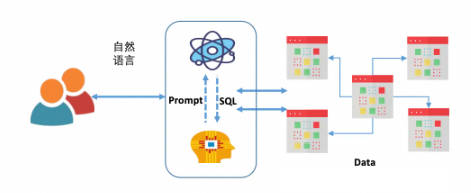
Сам принцип работы диалогового робота относительно прост:
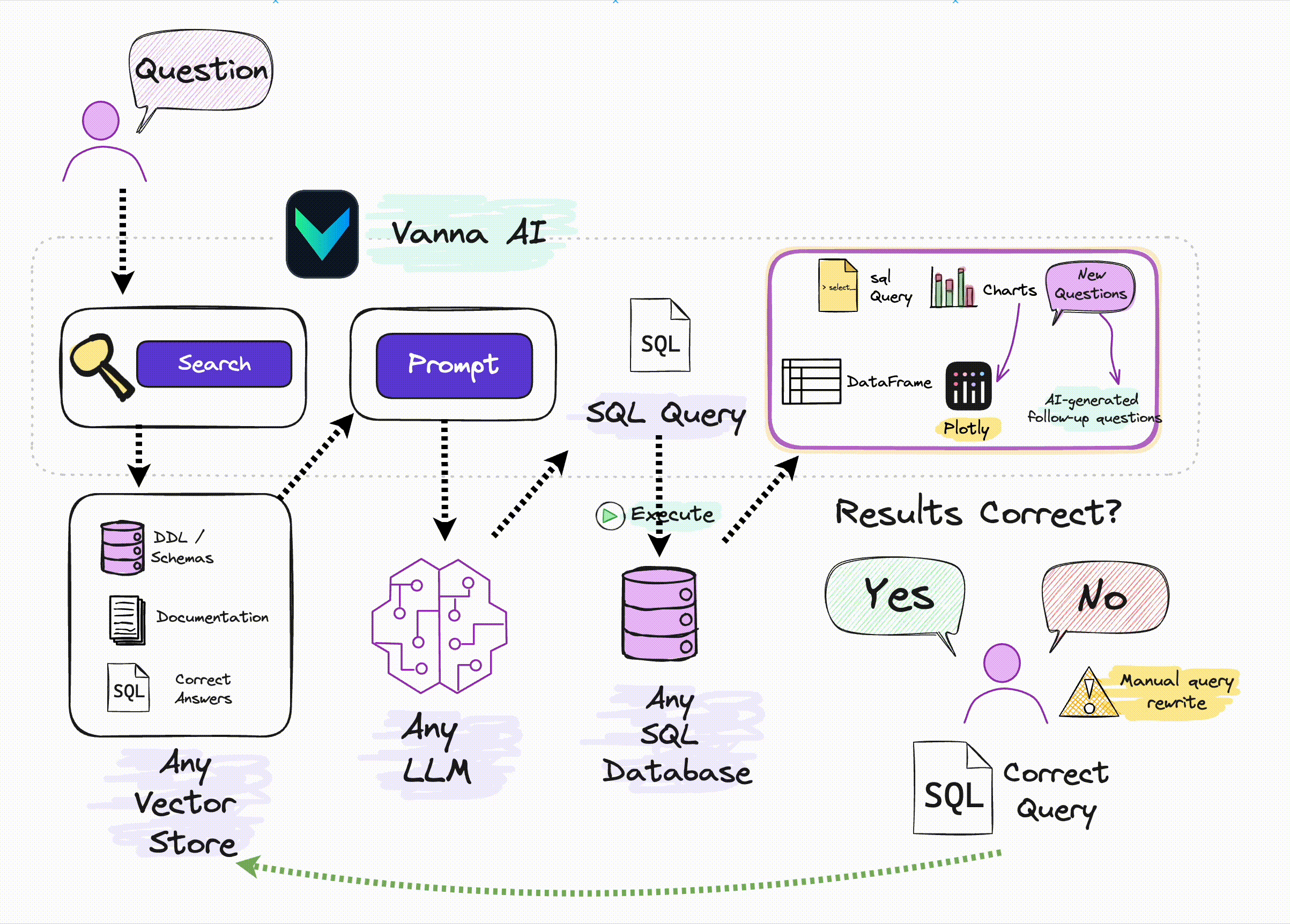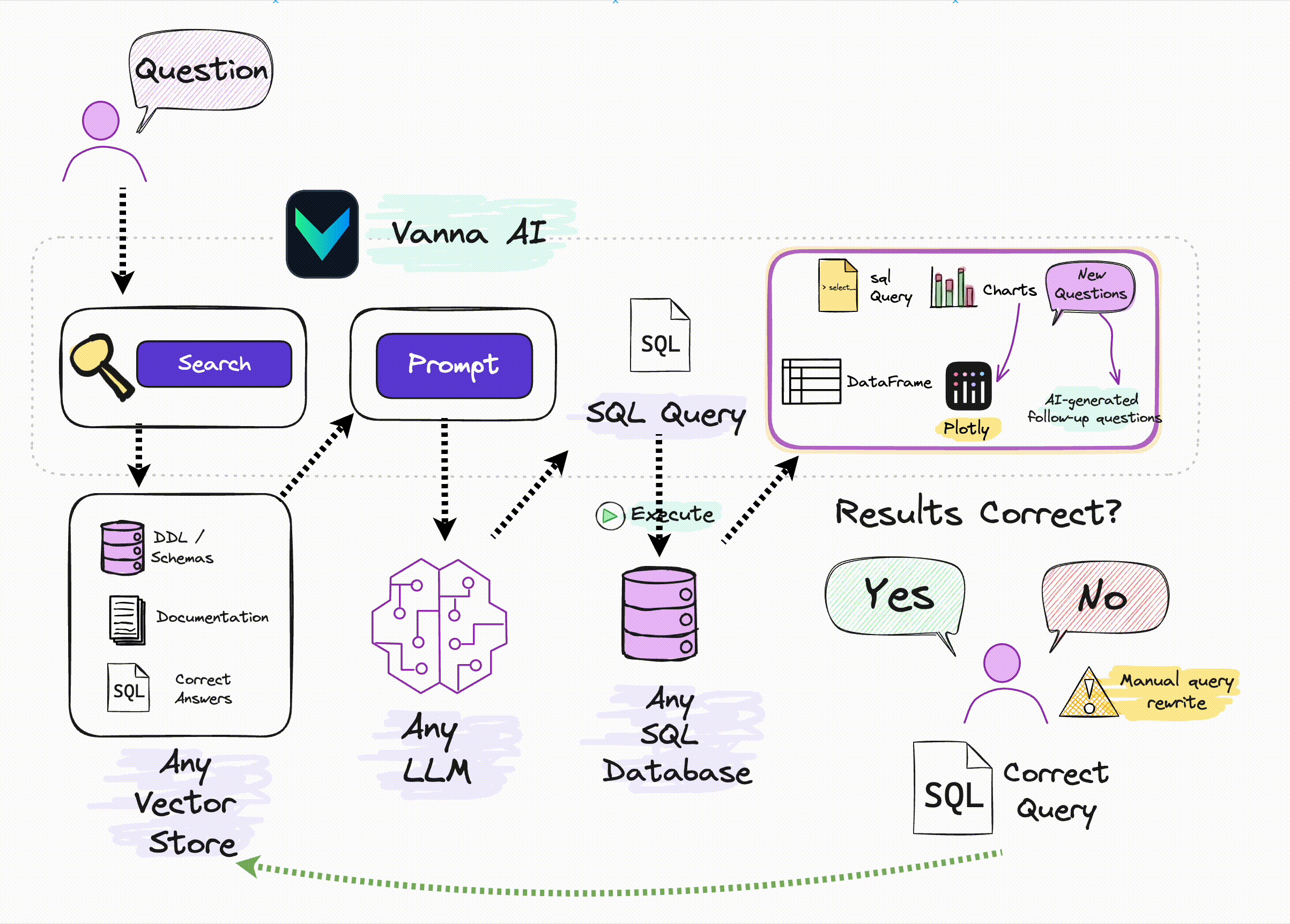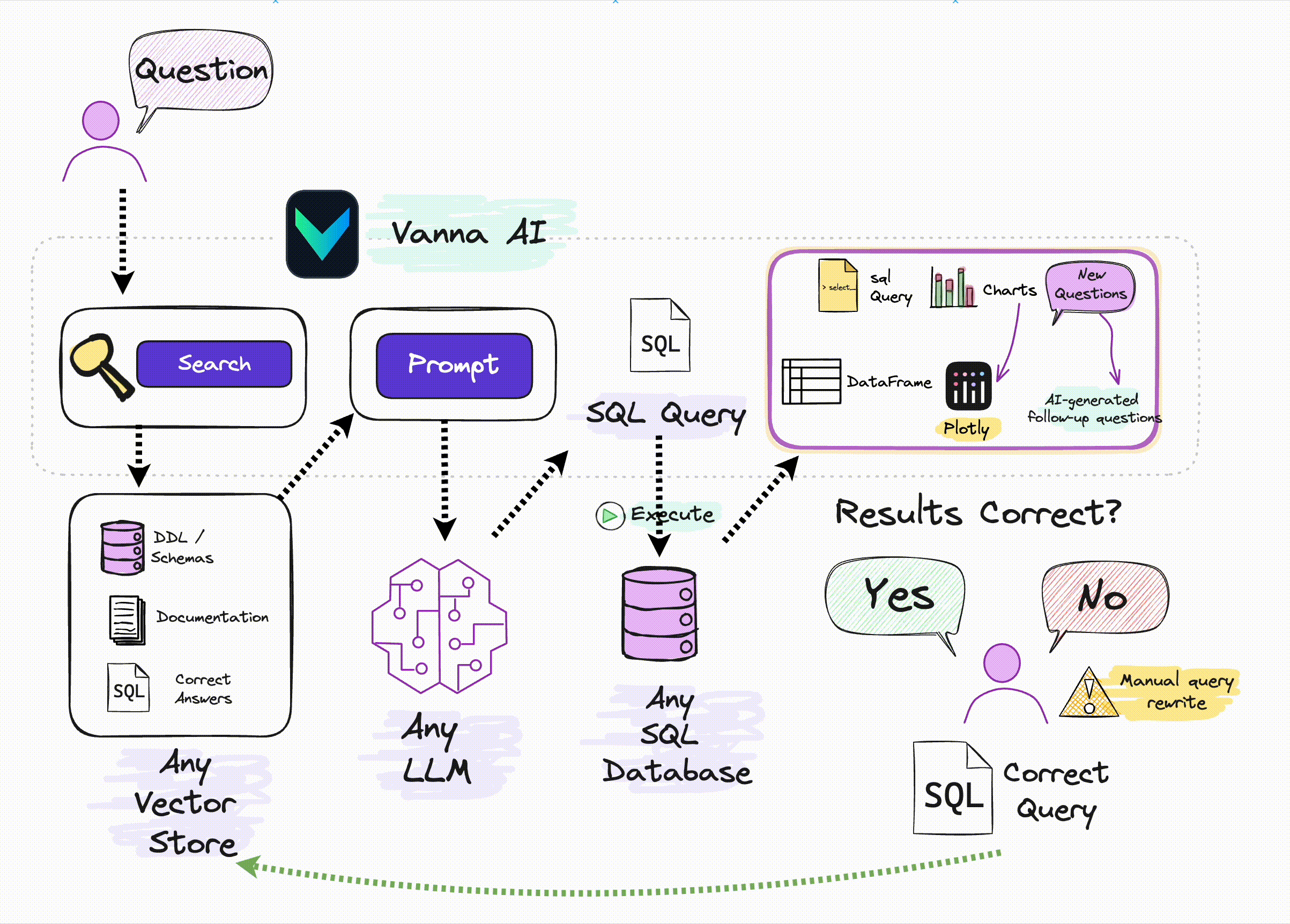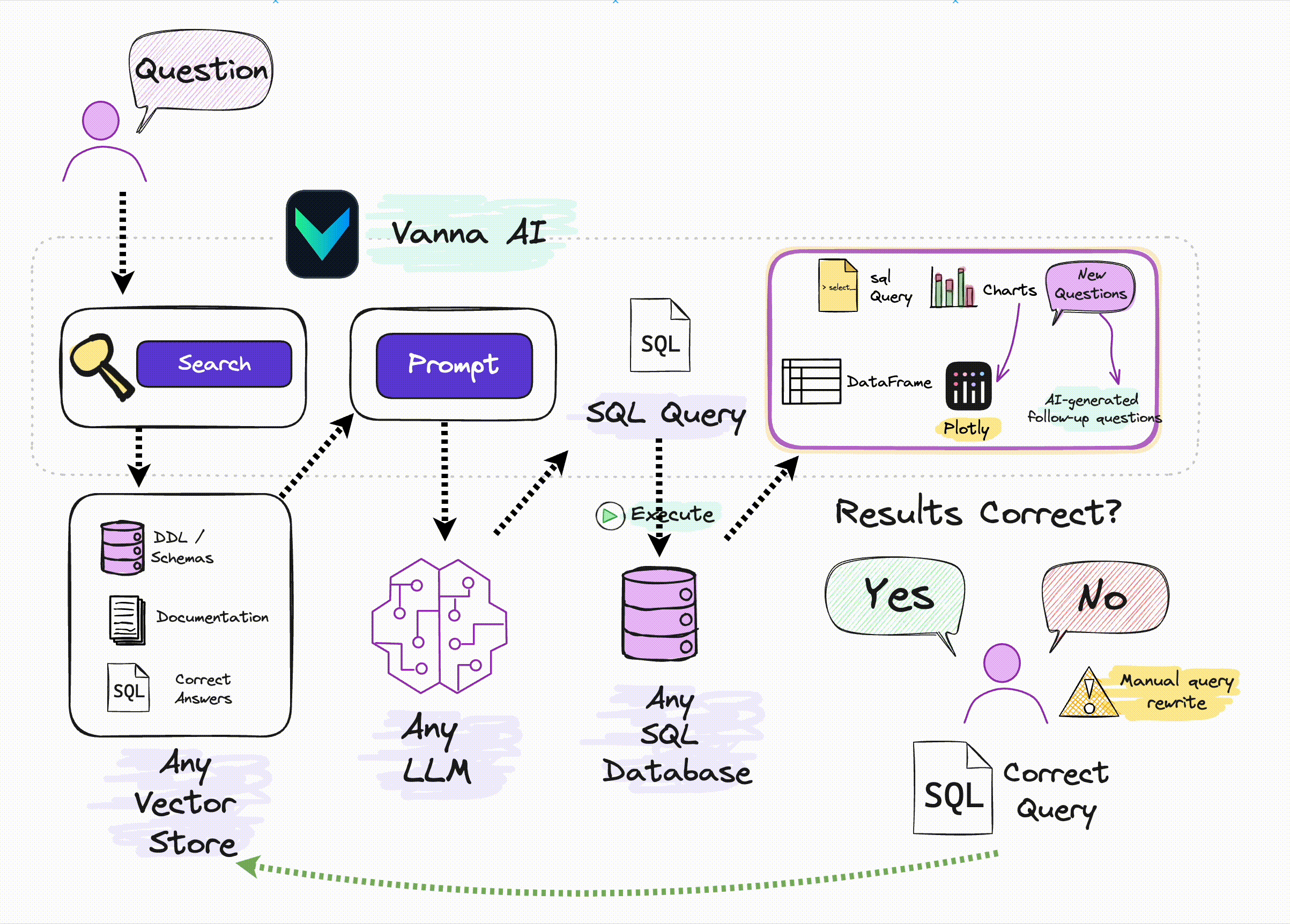
Ключевым моментом здесь является следующее: если вы не оптимизируете на уровне большой модели (например, для SQL тонкая настройка), то единственным методом оптимизации является Подскажите, многие отчеты о технических исследованиях, упомянутые в предыдущих статьях, основаны на Prompt оптимизация,Но они относительно сложны。Vanna да С Помощь относительно проста и ее легче понять из RAG метод, созданный путем улучшения поиска Подскажите увеличить SQL Генерируемая точность:
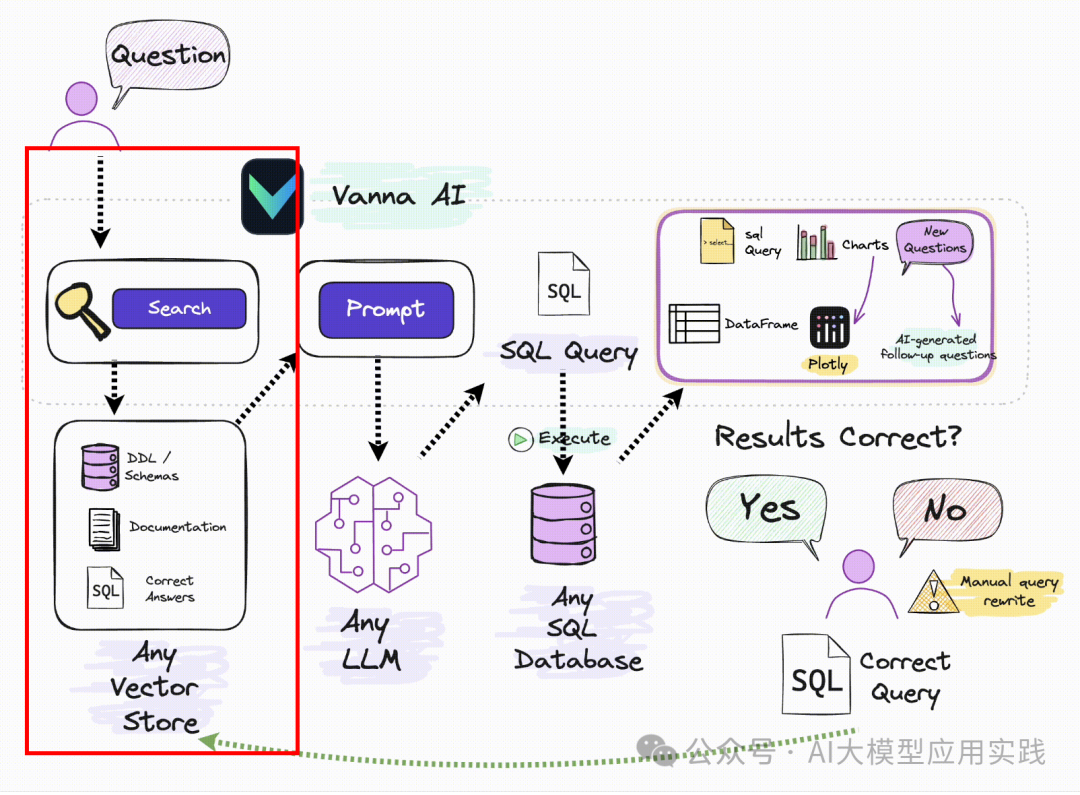
Источник: Официальное изображение Vanna.ai.
Из этой картинки мы можем понять, что ключевыми принципами Ванны являются:
С помощьюданные Библиотекаиз DDL заявление, данные юаней (данные описания библиотеки, информация о самих данныхиз), соответствующая документация, справочные примеры SQL Подождите, чтобы обучить одного RAG из «модель» (вложение + векторная библиотека); и при получении описания проблемы на естественном языке пользователя от RAG Извлеките релевантный контент с помощью семантики в Модели, а затем соберите его в Подскажите и передайте LLM генерировать SQL。
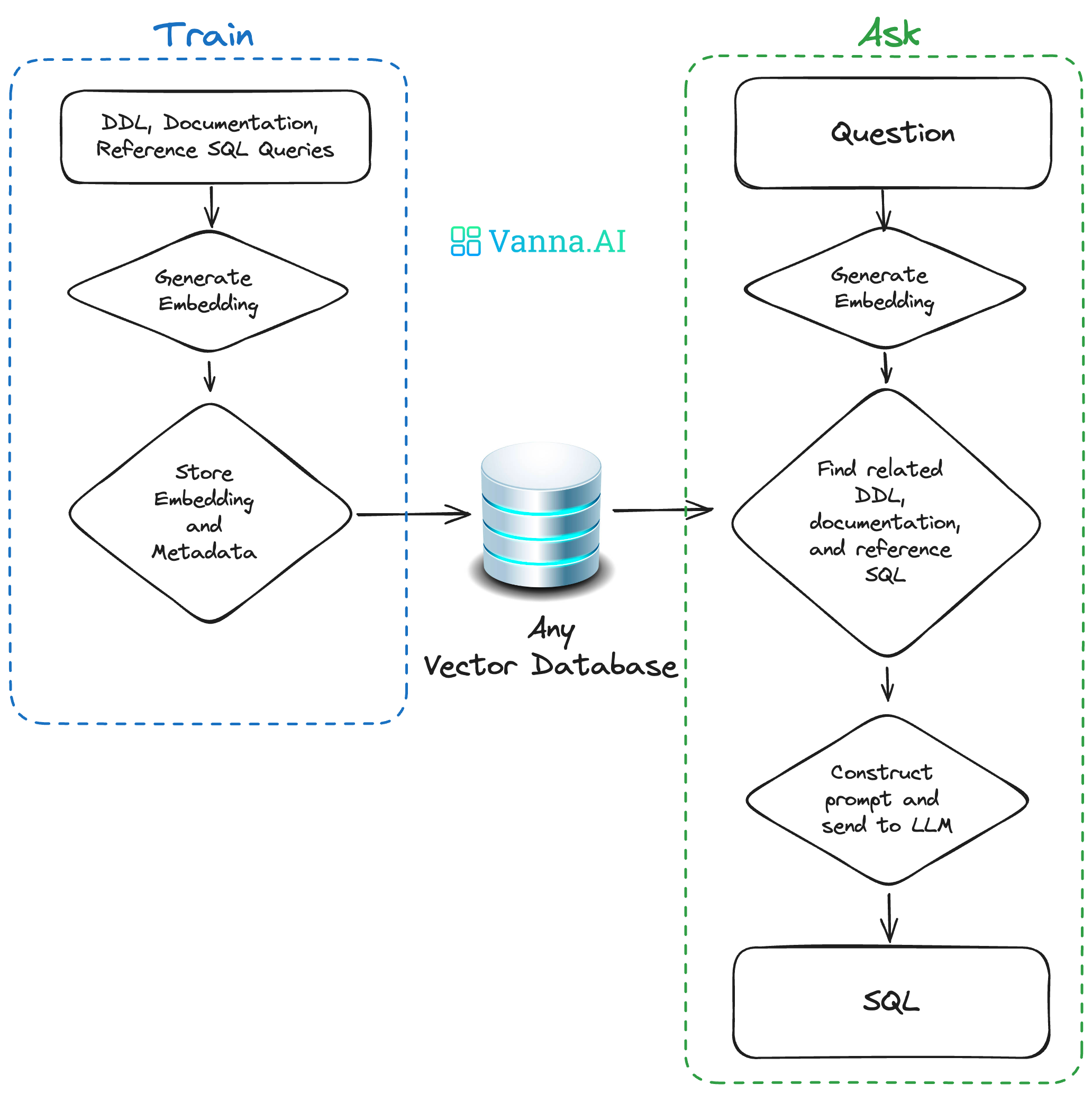
Поэтому используйте Vanna Основные этапы делятся на два этапа:
Шаг 1: Тренируйтесь на своих изданных РАГ "Модель"
Пучок DDL/Schemas Описание, документация, ссылки SQL Ожидание доставки Vanna тренировать одного для RAG Поиск из «Модель» (векторная библиотека).
Vanna из RAG Обучение модели поддерживает следующие методы:
1. Оператор DDL
DDL полезный Vanna понимает информацию о структуре таблиц вашей изданной библиотеки.
vn.train(ddl="CREATE TABLE my_table (id INT, name TEXT)")
2. Содержание документа
Можете ли вы из Enterprise、приложение、Библиотека данных, связанная с любым содержанием документа, при условии, что полезный Ванна верен, например, объяснение существительных, уникальных для вашей отрасли, из、Специальные показатели и методы расчета и т.д.
vn.train(documentation="Our business defines XYZ as ABC")
3. SQL или вопросы и ответы по SQL
Прямо сейчас SQL Из примеров ясно, что полезная отличная модель обучения направлена на вашу библиотеку данных, поскольку знания, особенно даполезное понимание контекста вопроса, могут быть значительно улучшены. sql генерироватьправильность。
vn.train(question="What is the average age of our customers?",sql="SELECT AVG(age) FROM customers")
4. План тренировок (план)
Это vanna Предоставляет простой метод автоматического обучения больших баз данных. С помощью RDBMS Сами изданные элементы библиотеки, данные, информация для обучения. RAG model,понять Библиотека Внутриизструктура таблицы、Список、связь、Примечания и другая полезная информация.
df_information_schema=vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
plan=vn.get_training_plan_generic(df_information_schema)
vn.train(plan=plan)Шаг 2: Предложите «Вопросы», получите ответы
RAG После завершения обучения модели вопросы можно задавать непосредственно на естественном языке. Ванна встречаиспользовать RAG и LLM генерировать SQL и автоматически возвращает результаты после запуска.
3.2 Расширение и настройка ванна
Из вышесказанного vanna Из введения принципа мы можем знать, что есть три основные связанные инфраструктуры:
- Database,Прямо сейчас необходимо запросить из реляционной библиотеки данных
- VectorDB,Прямо сейчас нужно сохранить РАГ "Модель" из векторной библиотеки
- LLM,Прямо сейчас для выполнения нужно использовать избольшойязык Модель Text2SQL Задача
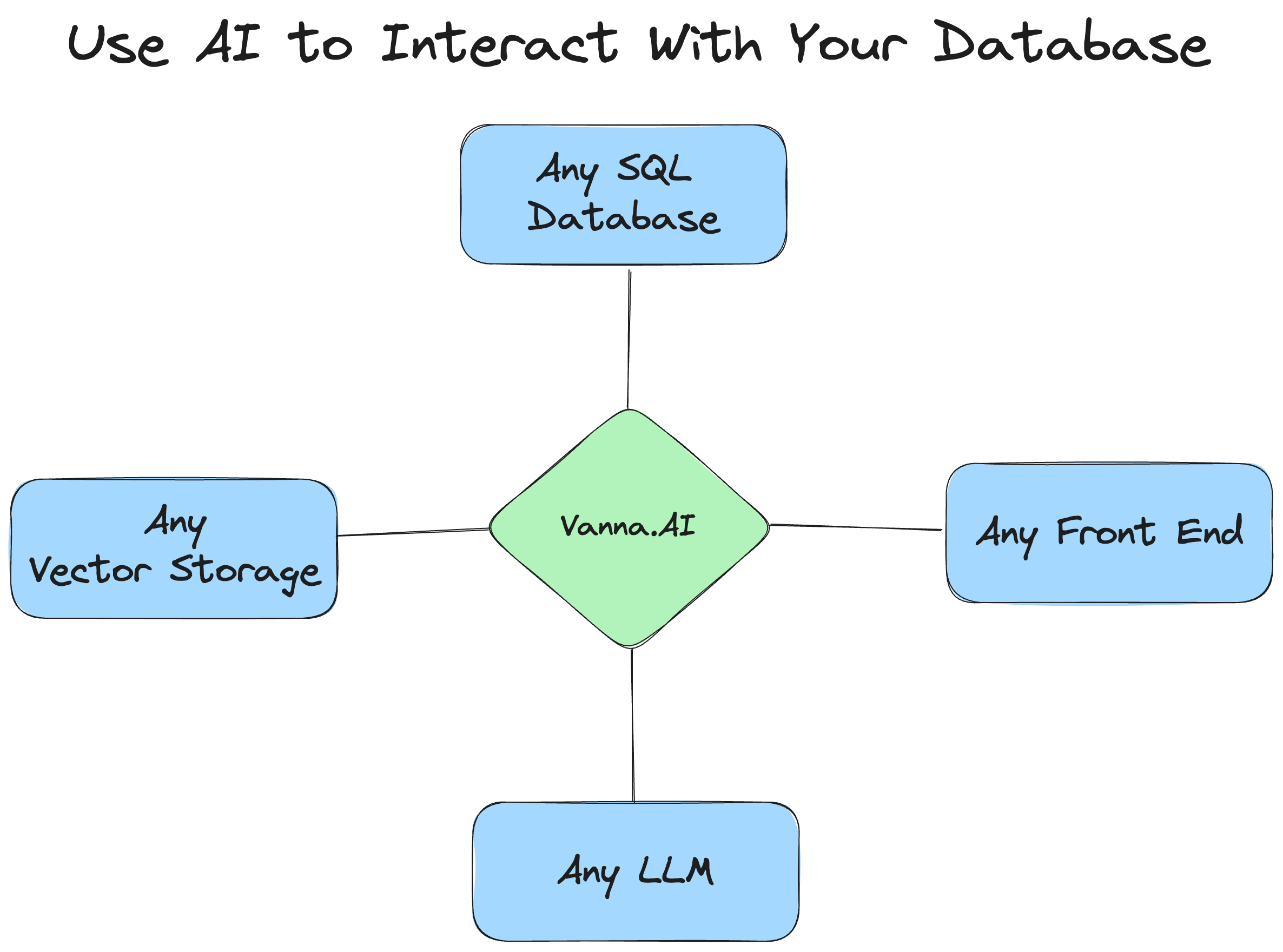
Дизайн Vanna обладает очень хорошими возможностями масштабируемости и персонализации и может поддерживать любую библиотеку данных, библиотеку векторных данных и большие файлы.
【Настроить LLM Библиотека векторов】
По умолчанию Ванна Поддержка с помощью онлайн LLM Услуги (стыковка OpenAI) и векторную библиотеку, для этих двух никаких настроек делать не нужно, Прямо сейчас доступен. Так что используйте Vanna Самый простой прототип требует всего пять элементов:
import vanna
from vanna.remote import VannaDefault
vn = VannaDefault(model='model_name', api_key='api_key')
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask("What are the top 10 albums by sales?")Обратите внимание на использование Vanna.AI изонлайн LLM Сервис библиотеки векторов, сначала необходимо зайти на https://vanna.ai/ Чтобы подать заявку на создание учетной записи, пожалуйста, обратитесь к следующей части фактического теста для получения подробной информации.
Если вам нужно использовать собственный локальный из LLM или векторную библиотеку, например, используя собственную OpenAI Аккаунт и ChromaDB Библиотека векторов, вы можете расширить свою собственную Vanna объект и передать персональную конфигурацию Прямо сейчас Может。
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
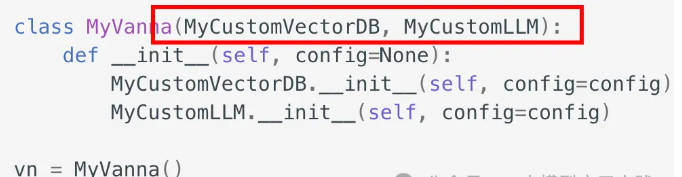
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, config=config)
vn = MyVanna(config={'api_key': 'sk-...', 'model': 'gpt-4-...'})Конечно здесь из OpenAI_Chat и ChromaDB_VectorStore да Vanna Уже встроенная поддержка LLM и VectorDB。Если вам нужна поддержка, встроенной поддержки нет. LLM и VectorDB, вам нужно сначала расширить свои возможности LLM категория VectorDB Класс, реализуйте необходимые методы (подробнее см. в официальной документации), а затем расширяйте свои собственные Vanna объект:
【Настроитьсвязьформаданные Библиотека】
Vanna Поддерживается по умолчанию Postgres,SQL Server,Duck DB,SQLite и другие библиотеки реляционных данных.,Автоматический доступ к этому типу библиотеки данных может быть выполнен напрямую.,выполнитьданныеразговорный робот。ноЕсли вам необходимо подключить собственное предприятие из других библиотек данных,Например, на предприятии Mysql или Oracle., вам необходимо определить персонализированный run_sql метод и возвращает Pandas Dataframe Прямо сейчас Может。специфический Может Ссылка нижеиз Фактическое измерениекод。
- Справочная ссылка
Ванна: Быстро построить разговорного бота на основе большой библиотеки МоделииRAGизSQLданные за 10 минут. :https://mp.weixin.qq.com/s/-dQYHcK_Ji_jNydgBJxEGw
Для получения более качественного контента, пожалуйста, обратите внимание на публичном аккаунте: Тин, искусственный интеллект предоставит некоторые соответствующие ресурсы и высококачественные статьи для бесплатного чтения;



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
