[Серия MySQL] Архитектура MySQL
Прежде чем мы начнем понимать основные функции MySQL, сначала нам нужно взглянуть на глобальную перспективу и посмотреть, как работает и выполняется SQL. Таким образом, мы можем построить мысленную картину того, как различные компоненты MySQL работают вместе, что поможет нам глубже понять сервер MySQL.
1. Логическая архитектура MySQL
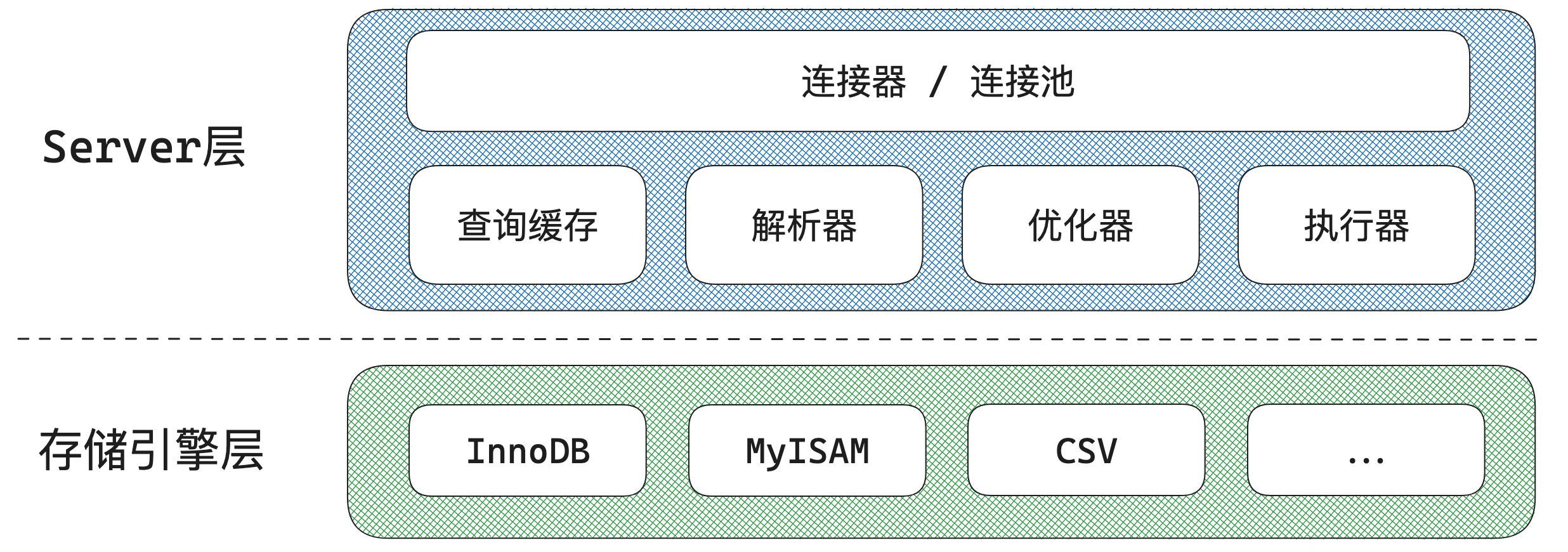
Архитектура MySQL разделена на два уровня: уровень сервера и уровень механизма хранения.
Уровень сервера: отвечает за установление соединений, анализ и выполнение SQL. Здесь реализовано большинство основных функциональных модулей MySQL, включая пулы соединений, исполнители, оптимизаторы, парсеры, препроцессоры, кеши запросов и т. д. Кроме того, все встроенные функции (такие как дата, время, математические функции и функции шифрования и т. д.) и все функции механизма перекрестного хранения (например, хранимые процедуры, триггеры, представления и т. д.) реализованы на уровне сервера;
Уровень механизма хранения: отвечает за хранение и извлечение данных. Поддерживает несколько механизмов хранения, таких как InnoDB, MyISAM и Memory. Различные механизмы хранения используют один уровень сервера. Наиболее часто используемым механизмом хранения сейчас является InnoDB. Начиная с версии MySQL 5.5, InnoDB стал механизмом хранения данных MySQL по умолчанию. Структура индексных данных, о которой мы часто говорим, реализуется уровнем механизма хранения.
2. Принцип выполнения оператора SELECT
2.1. Разъем
Когда мы получаем доступ к серверу MySQL через клиента, первым шагом является трехстороннее подтверждение TCP, поскольку MySQL передается на основе протокола TCP.
Процесс подключения сначала требует трехстороннего подтверждения TCP, поскольку MySQL передается на основе протокола TCP.
После успешного установления сетевого соединения TCP между сервером и клиентом будет установлен сеанс, а затем будут проверены имя пользователя и пароль для входа. Сначала будет запрошена информация из его собственной таблицы пользователей, чтобы определить, были ли они введены. имя пользователя существует. Если оно существует, будет проверено, правильный ли введенный пароль. После правильного пароля из пула соединений будет выделен свободный поток для поддержания соединения текущего клиента. Если простаивающий поток отсутствует, будет создан новый рабочий поток. После этого поток запросит разрешения, принадлежащие пользователю, и авторизует их. При выполнении последующего SQL он сначала определит, получены ли соответствующие разрешения.
После того, как время простоя соединения превысит максимальное время простоя (wait_timeout), соединитель автоматически отключит его.
После того, как сервер активно отключит неактивное соединение, клиент не узнает об этом сразу. Он не получит ошибку до тех пор, пока клиент не инициирует следующий запрос.
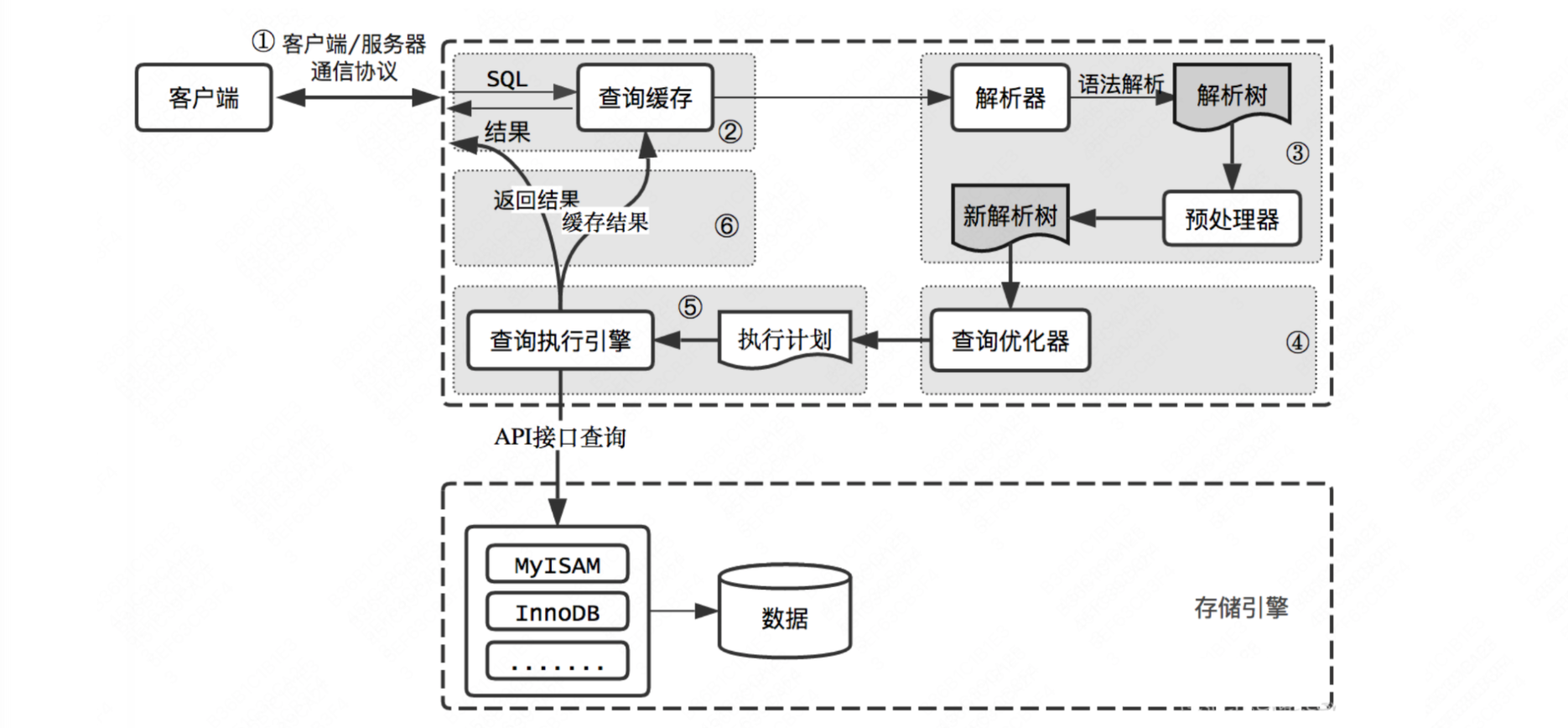
2.2. Пул соединений
Пул соединений предназначен для установки достаточного количества подключений к базе данных при запуске программы и формирования этих подключений в пул соединений, при этом программа динамически применяет, использует и освобождает соединения в пуле. В основном для повторного использования потоков, управления потоками и ограничения максимального количества соединений.
Когда клиент пытается установить соединение с MySQL, MySQL отправляет внутренний поток для обработки всей последующей работы клиента.
Частое создание и удаление потоков потребляет много ресурсов. Повторное использование потоков позволяет не только снизить накладные расходы, но и избежать таких проблем, как переполнение памяти.
Пул соединений с базой данных может устанавливать минимальное и максимальное количество соединений:
- самый маленькийсоединятьчисло:дасоединять Бассейн поддерживается в хорошем состоянииданные Библиотекасоединять,Если приложение не интенсивно использует библиотеку данных, используйте,Будет потрачено много ресурсов библиотеки данных;
- Максимальное количество подключений: максимальное количество подключений, на которое можно подать заявку в пуле дасоединять.,Если количество запросов на соединение библиотеки данных превышает количество раз,Последующие запросы на подключение библиотеки данных будут добавлены в очередь ожидания прибытия.
2.3. Кэш запросов.
Если есть оператор запроса (оператор выбора), MySQL сначала будет искать кэшированные данные в кеше запросов (кеше запросов), чтобы увидеть, выполнялась ли эта команда ранее. Этот кеш запроса хранится в памяти в форме ключ-значение. Ключ — это хеш-значение оператора запроса SQL, а значение — результат запроса оператора SQL.
Если оператор запроса попадает в кеш запросов, значение будет возвращено непосредственно клиенту. Если оператор запроса не попадает в кэш запросов, выполнение продолжится. После завершения выполнения результаты запроса будут сохранены в кэше запросов.
Кэширование запросов часто приносит больше вреда, чем пользы, поскольку любое обновление таблицы приводит к очистке всех кэшей запросов в таблице. Поэтому версия MySQL8.0 напрямую удаляет кеш запросов.
Упомянутый здесь кеш запросов находится на уровне сервера, то есть в версии MySQL 8.0 удаляется кеш запросов на уровне сервера, а не опрос буфера в механизме хранения Innodb.
2.4. Анализ SQL
Прежде чем официально выполнить оператор запроса SQL, MySQL сначала проанализирует оператор SQL, и эта работа будет завершена анализатором. Анализатор может преобразовать входной оператор SQL в форму, понятную компьютеру (синтаксическое дерево).
Парсер будет делать следующие две вещи:
- Лексический анализ: MySQL идентифицирует ключевые слова на основе входной строки и строит синтаксическое дерево SQL;
- Синтаксический анализ. По результатам лексического анализа синтаксический анализатор будет оценивать ввод в соответствии с грамматическими правилами. SQL Соответствует ли высказывание да грамматическим правилам.
Общая структура синтаксического дерева следующая:
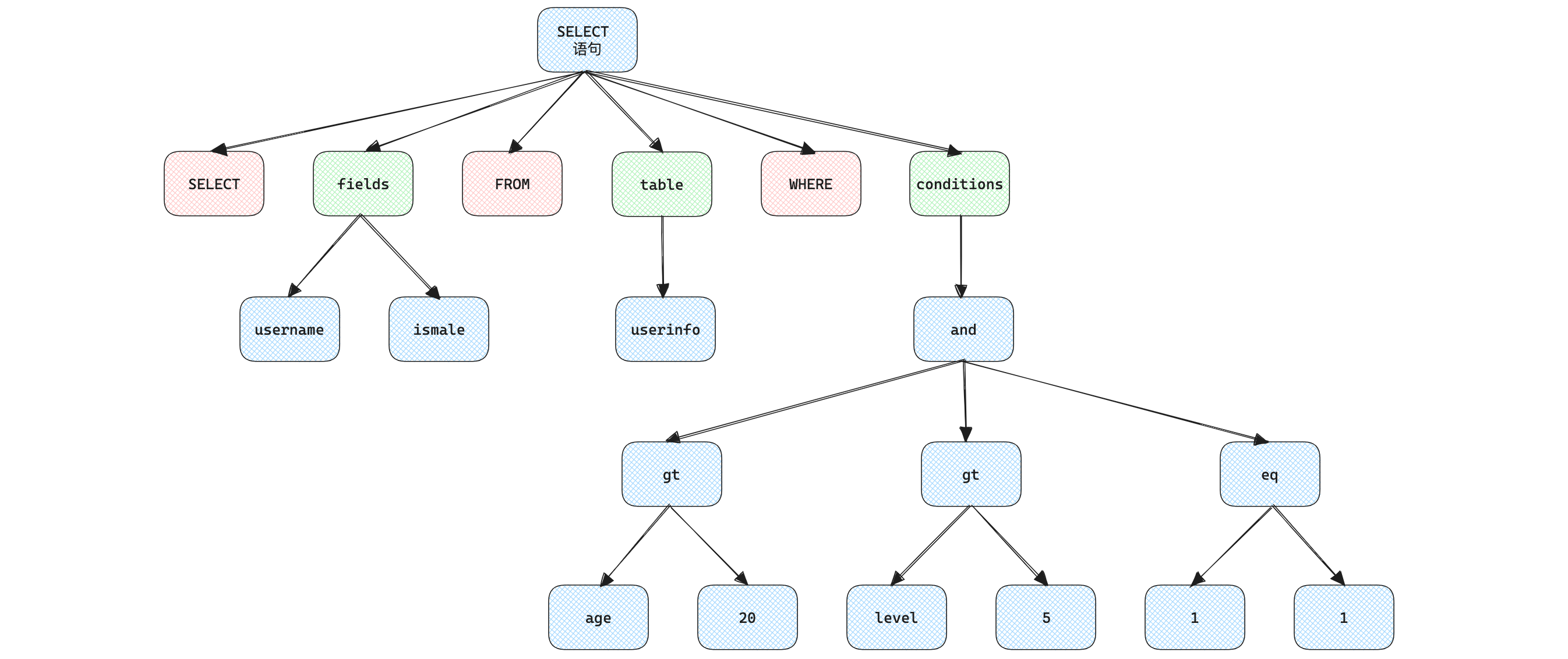
При возникновении ошибок лексического и синтаксического анализа синтаксический анализатор выдает исключения. Например, есть ошибки в грамматической структуре, неузнаваемые символы и т. д.
Таблицы или поля не существует, это не делается в анализаторе, а делается на этапе предобработки.
2.5. Выполнить SQL
Каждый оператор SQL можно разделить на следующие три этапа: ① подготовка, этап предварительной обработки; ② оптимизация, этап оптимизации; ③ выполнение, этап выполнения;
Препроцессор: проверьте SQL Существует ли таблица или поле в инструкции запроса; select * в * символ, распространяется на все поля таблицы;
Оптимизатор: оптимизатор сформулирует несколько планов выполнения на основе синтаксического дерева, а затем определит оптимальный план выполнения.
- Когда в таблице несколько индексов,Решите, какой индекс использовать;
- Когда оператор имеет несколько ассоциаций таблиц (объединений),Определите порядок каждой таблицы.
Исполнитель: определите права пользователя, а затем выполните операторы SQL в соответствии с планом выполнения.
2.6. Процесс запроса ВЫБОР
Кратко опишите поток выполнения оператора SQL-запроса:
- Клиент через соединение MySQL Служить;
- соединятьуспешный назад SQL Отправка интерфейса SQL запрос заявления;
- Когда интерфейс SQL получает оператор запроса SQL, он сначала кэширует запрос. Если есть попадание, он будет возвращен клиенту, в противном случае он будет передан синтаксическому анализатору;
- Парсер получает SQL После утверждения будет оцениваться, правильна ли грамматика да, и если она правильна, она будет сгенерирована. SQL Синтаксическое дерево передается оптимизатору, в противном случае клиенту сообщается об ошибке;
- Оптимизатор сформирует оптимальный план выполнения на основе синтаксического дерева SQL и передаст его на исполнение исполнителю;
- Исполнитель берет план выполнения «приехать» и настраивает механизм хранения данных для получения ответа с данными клиенту;
- Заканчивать! ! !
3. Принцип выполнения оператора UPDATE
В базе данных мы говорим update Фактически операции включают обновление, вставку и удаление. Если вы это видели MyBatis Вы должны знать исходный код Executor Есть только doQuery() и doUpdate() метод, нет doDelete() и doInsert()。
3.1. Буферный пул.
Во-первых, InnnoDB Все данные размещаются на диске InnoDB. Существует наименьшая логическая единица операций с данными, называемая страницей (индексная страница и страница данных). Для работы с данными мы не используем каждый раз диск напрямую, поскольку скорость диска слишком низкая. Инно ДБ Используется технология пула буферов, которая заключается в помещении страниц, считанных с диска, в область памяти. Эта область памяти называется Buffer Pool.
При следующем чтении той же страницы сначала определите, находится ли она в пуле буферов. Если да, прочитайте ее напрямую, не обращаясь к диску повторно.
При изменении данных,Сначала измените страницы в пуле буферов. Когда страница данных памяти несовместима,Мы называем это грязной страницей. Инно ДБ Внутри есть специальный фоновый поток. BufferPool Данные записываются на диск, и время от времени на диск записывается несколько модификаций. Это действие называется чисткой.
BufferPool да InnoDB Внутри это очень важное сооружение, а его интерьер разделен на несколько зон. Здесь мы пользуемся возможностью зайти на официальный сайт, чтобы познакомиться поближе. InnoDB структура памятиидискструктура。
3.2. Структура памяти InnoDB и структура диска.
BufferPool в основном разделен на три части: пул буферов, буфер изменений, индекс AdaptiveHash и буфер журнала (повтора).
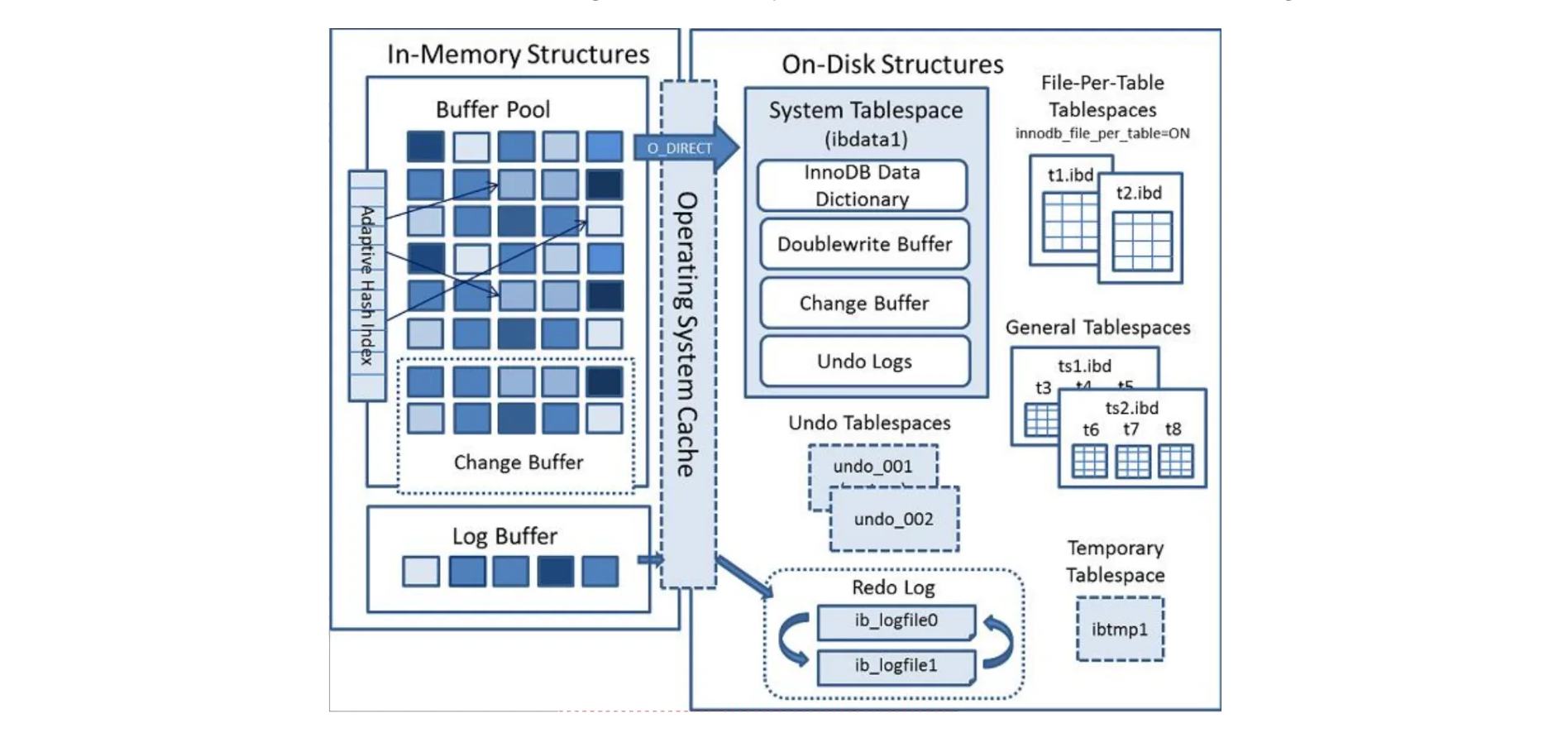
3.2.1、BufferPool
BufferPool Кэшированная информация о странице, включая страницу данных и индексную страницу. Проверьте статус сервера, их много BufferPool Сопутствующая информация:
SHOW STATUS LIKE '%innodb_buffer_pool%';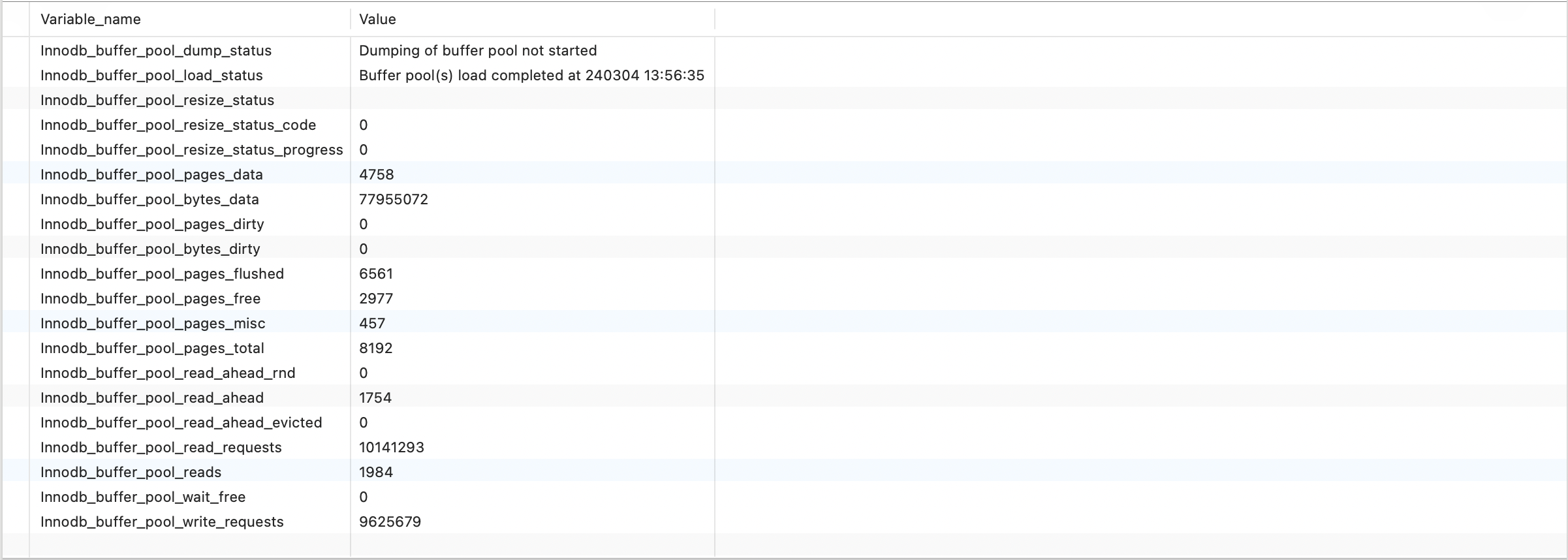
Подробные значения этих статусов можно узнать на официальном сайте и воспользоваться функцией поиска.
BufferPool Размер по умолчаниюда 128M (134217728 байт), можно регулировать. Параметры просмотра (системные переменные):
SHOW VARIABLES like' %innodb_buffer_pool%';Подробное значение этих параметров можно узнать на официальном сайте и воспользоваться функцией поиска.
Что делать, если пул буферов памяти заполнен? Инно ДБ использовать LRU Алгоритм управления пулом буферов (реализация связанного списка, а не традиционный) LRU, разделенный на Юнф и Старый), удаленные данные являются данными горячей точки.
Буфер памяти играет важную роль в повышении производительности чтения и записи. Подумайте над вопросом: когда необходимо обновить страницу данных, если страница данных находится в BufferPool Если он существует, обновите его напрямую. В противном случае вам необходимо загрузить приезжающую память с диска, а затем работать со страницей данных памяти. Другими словами, если пул буферов не задействован, должен быть сгенерирован хотя бы один диск. ИО, есть ли способ его оптимизировать?
3.2.2、ChangeBuffer
Если эта страница данных не проиндексирована однозначно,Дублирования данных не происходит.,Нет необходимости загружать индексную страницу с диска, чтобы определить, не является ли данныеда дубликатом (проверка уникальности). В этом случае можно сначала поместить модификацию Записывать в буферный пул памяти.,Тем самым улучшая скорость выполнения операторов обновления (Вставка, Удаление, Обновление).
Эта областьда ChangeBuffer。5.5 звонил раньше InsertBuffer Буферизация вставки теперь также поддерживается Delete и Update。
Последняя операция записи ChangeBuffer на страницу данных называется слиянием. Когда произойдет слияние? Существует несколько ситуаций: при доступе к этой странице данных или через фоновый поток, или когда база данных выключена, или журнал повторов заполнен.
Если большинство индексов в библиотеке данных не являются уникальными индексами,А бизнес да больше пишет и меньше читает,Не будет читаться сразу после записи данных,Вы можете использоватьиспользовать ChangeBuffer (буфер записи). Для компаний, которые пишут больше и меньше читают, увеличьте это значение:
SHOW VARIABLES LIKE 'innodb_change_buffer_max_size';Представляет соотношение ChangeBuffer и BufferPool, значение по умолчанию — 25%.
3.2.3、Log Buffer
Подумайте над вопросом: Когда грязные страницы в BufferPool не были сброшены на диск,библиотека данных не работает или перезапущена,Эти данные потеряны. Если операция записи пишет приехать наполовину,Это может даже повредить файл данных, в результате чего библиотека данных станет недоступной.
Чтобы избежать этой проблемы, InnoDB Записывать все операции модификации страницы конкретно в файл журнала и выполнять операции восстановления из этого файла при запуске базы данных (реализация crash-safe)——использовать Это обеспечивает долговечность транзакций。
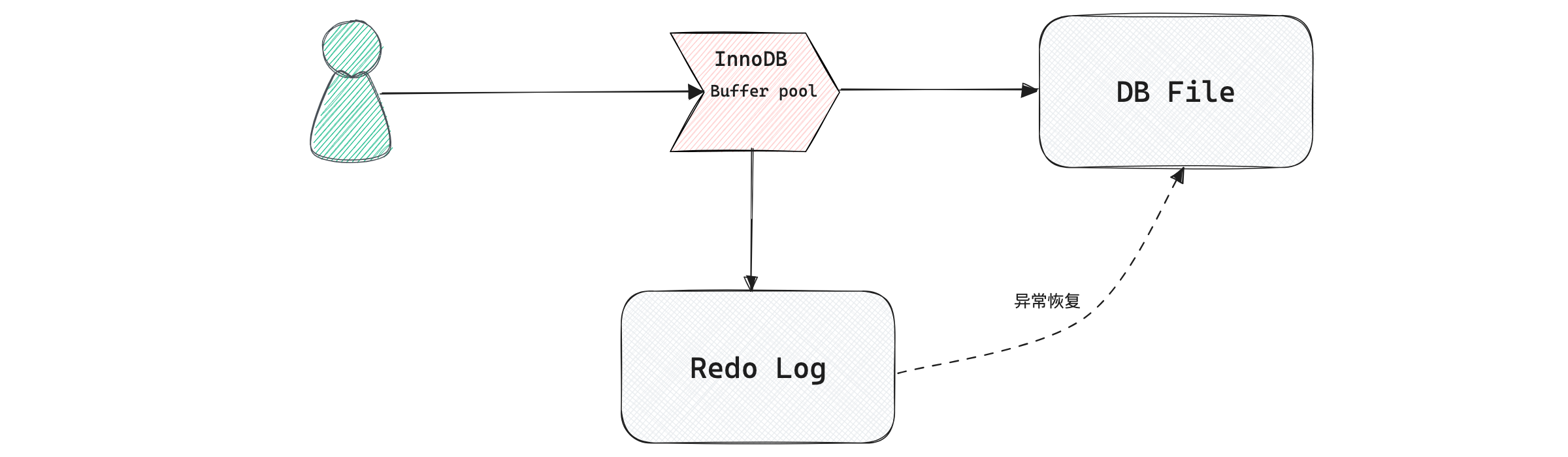
Этот файл взят с дадиска Redo Журнал (называемый журналом повторного выполнения), соответствующий /var/lib/mysql/ в каталоге ib_logfile0 и ib_logfile1,по 48 миллионов каждый.
Этот лог идиск соответствует всему процессу , на самом деле просто да MySQL внутри WAL Технология (упреждающая запись Logging),Ключевой момент - сначала написать журнал,Напишите еще раздиск。
show variables like 'innodb_log%';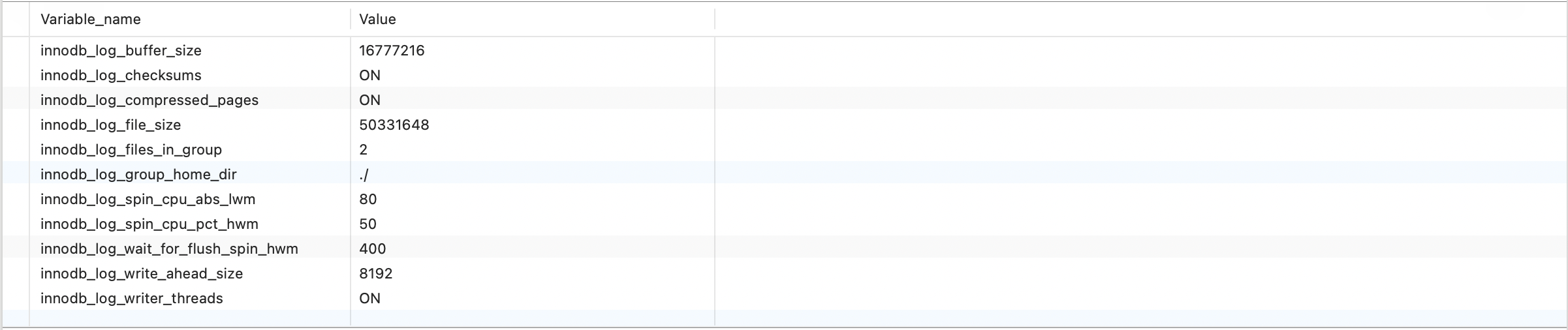
вопрос:такой жеда Писатьдиск,для Что не является прямым Писатьприезжать db file Зайти внутрь? Зачем сначала писать журнал, а потом писать на диск?
Давайте сначала узнаем о случайности I/O и заказываю I/O Понятие: наименьшая составная единица диска да сектора, обычно да. 512 байты. Операционная система идиск, работающий с диском, чтение и запись, наименьшая единица блока Block。
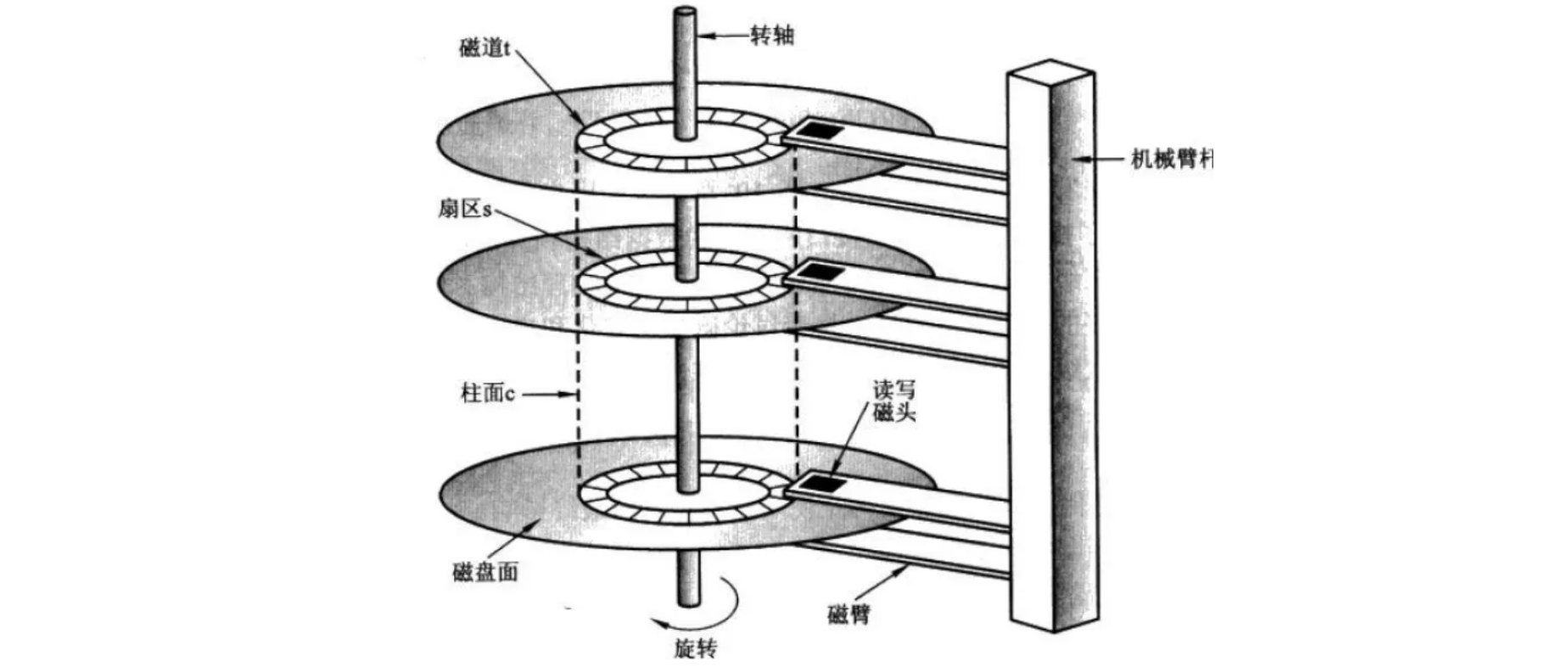
Если нужная нам информация хаотично разбросана по разным секторам разных страниц,Затем, чтобы найти соответствующие данные для проживания, вам нужно дождаться, пока магнитный рычаг прибытия повернется для указанной страницы.,Затем диск ищет сектор, соответствующий месту проживания.,Только тогда мы сможем найти нужную нам часть данных.,Выполняйте этот процесс последовательно, пока не найдете все предметы.,вот онодаслучайный И.О., чтение данных происходит медленнее.
Если предположить, что мы нашли первый фрагмент данных, а остальные необходимые данные находятся за этим фрагментом данных, то нет необходимости в повторной адресации, и мы можем получить нужные нам данные последовательно. Это называется последовательным вводом-выводом.
Флэш-диск (запись памяти на диск) случайный Ввод-вывод во время записи журнала для заказа Ввод/вывод, последовательный I/O Более эффективный. Таким образом, предварительная запись изменений в журнал может отложить возможность очистки и тем самым повысить пропускную способность системы.
конечно Redo Log Не обязательно каждый раз писать диск напрямую. Buffer Pool Имеется область памяти (Журнал Buffer) специально используется для сохранения содержимого, которое будет записано в файл журнала. 16M, он также может сохранить диск IO.
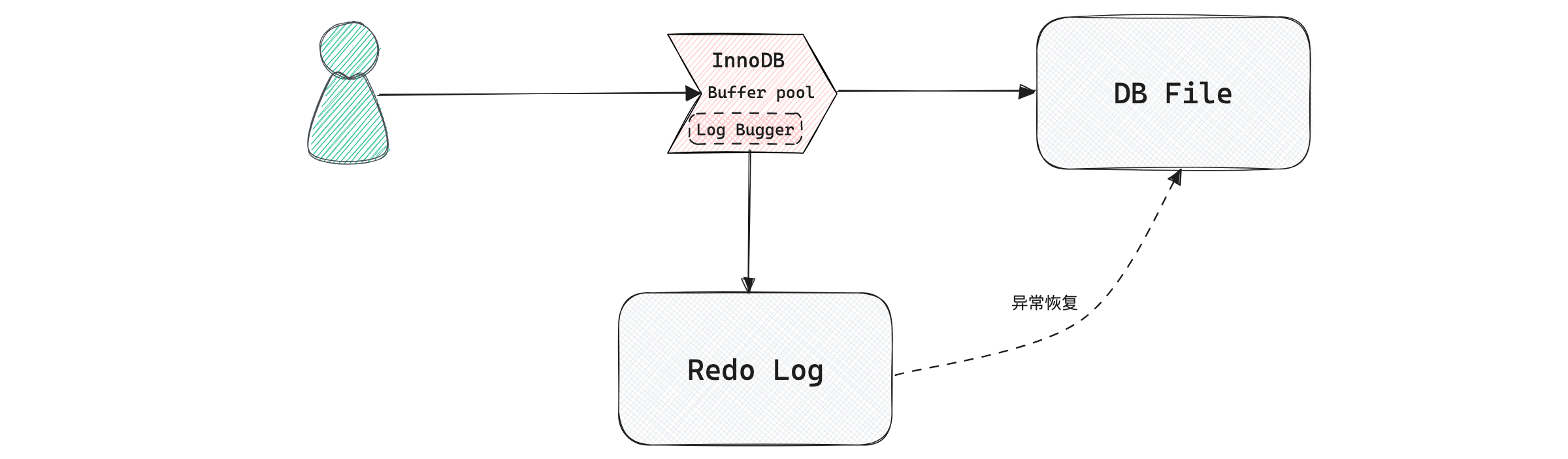
Нужно обратить внимание на: Повторить Log Контент в основном посвящен восстановлению после сбоев. файл данных диска, данные из bufferpool。Redo Log Запишите диск, а не файл данных. Итак, журнал Buffer когда писать log файл? Когда мы пишем данныеприезжатьдиск, сама операционная система имеет кеш. румянец Просто запишите буфер операционной системы, чтобы приезжать на диск.
Особенности журнала повторов:
- Журнал повторов реализован механизмом хранения InnoDB.,Не все системы хранения данных имеют его;
- Статус после обновления страницы да Записанные,И какие изменения были внесены на страницу да Записать,Принадлежит физическому журналу;
- Redo Log Размер фиксирован, предыдущее содержимое будет перезаписано.
Кроме Redo Помимо журнала, существует также журнал, связанный с изменениями, который называется Undo Журнал (журнал отмены или журнал отката) записывает состояние данных до совершения транзакции, разделенное на insert Undo Log и update Undo Бревно. Если при изменении данных возникает исключение, вы можете использовать Undo Log Для реализации операций отката (сохранение атомарности).
3.3. ОБНОВЛЕНИЕ процесса обновления.
Понятно Redo Log и Undo Лог, подведем итоги Update Операционный процесс.
UPDATE user set name = 'lizhengi' where id=1;- Обязательно перед выполнением: ① соединятьустройствосоединятьданные Библиотека;② Анализатор узнает об этом операторе обновления посредством лексического и синтаксического анализа ③; Оптимизатор решает использовать индекс использования и т. д. ④; Исполнитель несет ответственность за конкретный процесс исполнения;
- Транзакция начинается из памяти (буфера poll)илидиск(data файл) берёт страницу данных, содержащую эти данные, из «Приехать» и возвращает её в Server привод;
- Server Исполнитель изменяет значение для этой строки data на странице данных.
lizhengi; - Записывать
name=lisa(первоначальная стоимость)приезжать Undo Log; - Записывать
name=lizhengiприезжать Redo Log; - Настройка использования интерфейса механизма хранения, Запись страницы данных прибытия buffer пул (изменить
name= lizhengi); - Фиксация транзакции.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
