Серия LLM «Обучение больших моделей, которую необходимо знать» (11): Теория и практика автоматической оценки больших моделей и подробное объяснение структуры оценки больших моделей
Серия LLM «Обучение больших моделей, которую необходимо знать» (11): Теория и практика автоматической оценки больших моделей и подробное объяснение структуры оценки больших моделей
0.Предисловие
Оценка модели большого языка (LLM) является ключевым звеном в разработке и применении LLM. Современные методы оценки можно разделить на ручную оценку и автоматическую оценку. По сравнению с ручной оценкой, технология автоматической оценки обладает характеристиками высокой эффективности, хорошей последовательности, воспроизводимости и хорошей надежности и постепенно стала центром отраслевых исследований.
Технологию автоматической оценки моделей можно разделить на две категории: на основе правил и на основе моделей:
- Метод, основанный на правилах:
- Тест в основном фокусируется на объективных вопросах, таких как вопросы с несколькими вариантами ответов. Тестируемый LLM определяет лучший ответ, понимая контекст/вопрос.
- Разберите ответ LLM и сравните его со стандартным ответом.
- Вычисление показателей (точность, румяна, синева и т. д.)
- Модельный метод:
- модель рефери(e.g. GPT-4、Claude、Expert Models/Reward models)
- LLM Peer-examination
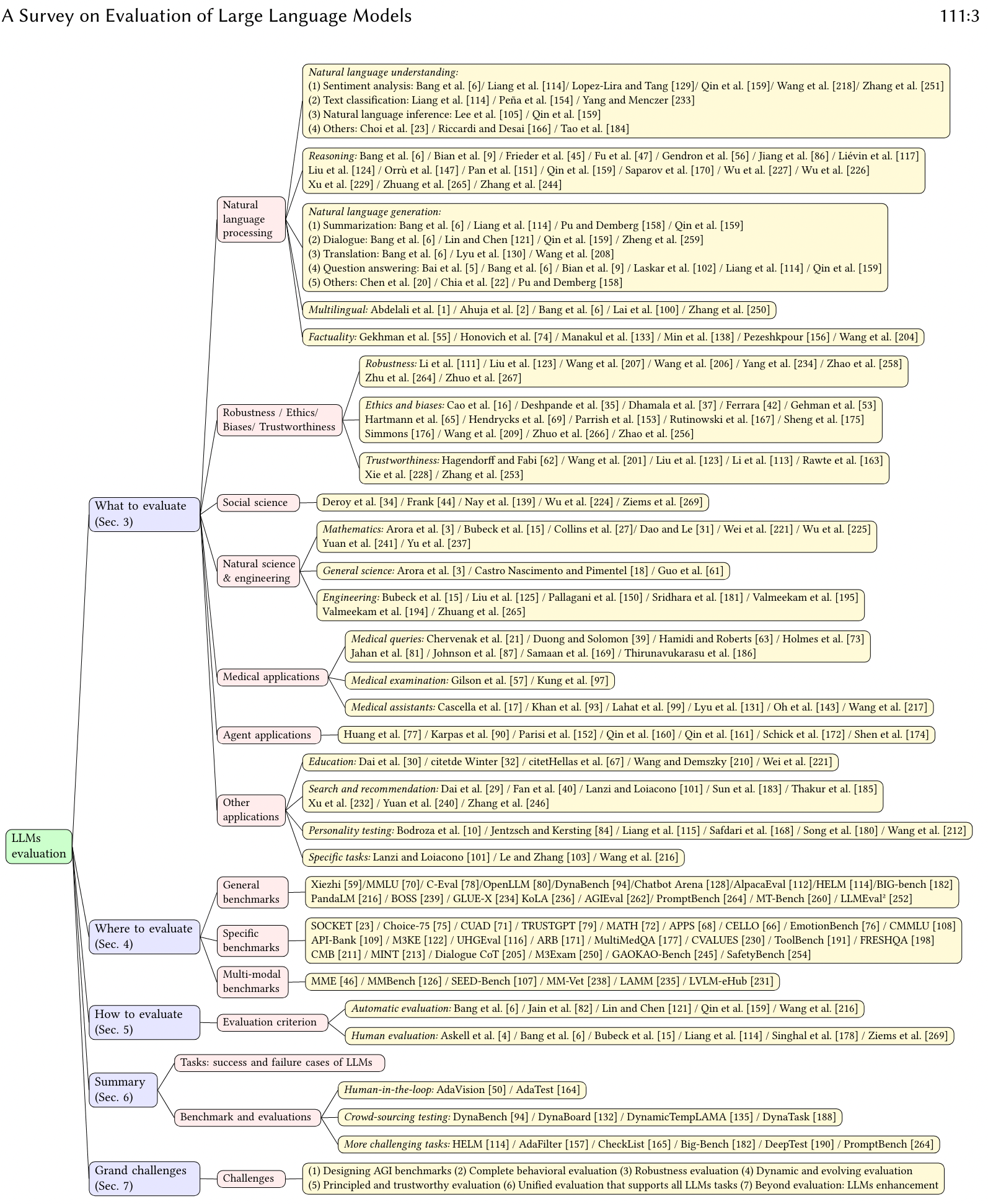
Как оценить LLM
- Какие размеры?
- Семантическое понимание (Понимание)
- Рассуждение
- Профессиональные способности (напр. coding、math)
- Возможности приложений (MedicalApps, AgentApps, AI-FOR-SCI …)
- Инструкция, которой необходимо следовать (Инструкция Following)
- Надежность
- Предвзятость
- Галлюцинации
- Безопасность
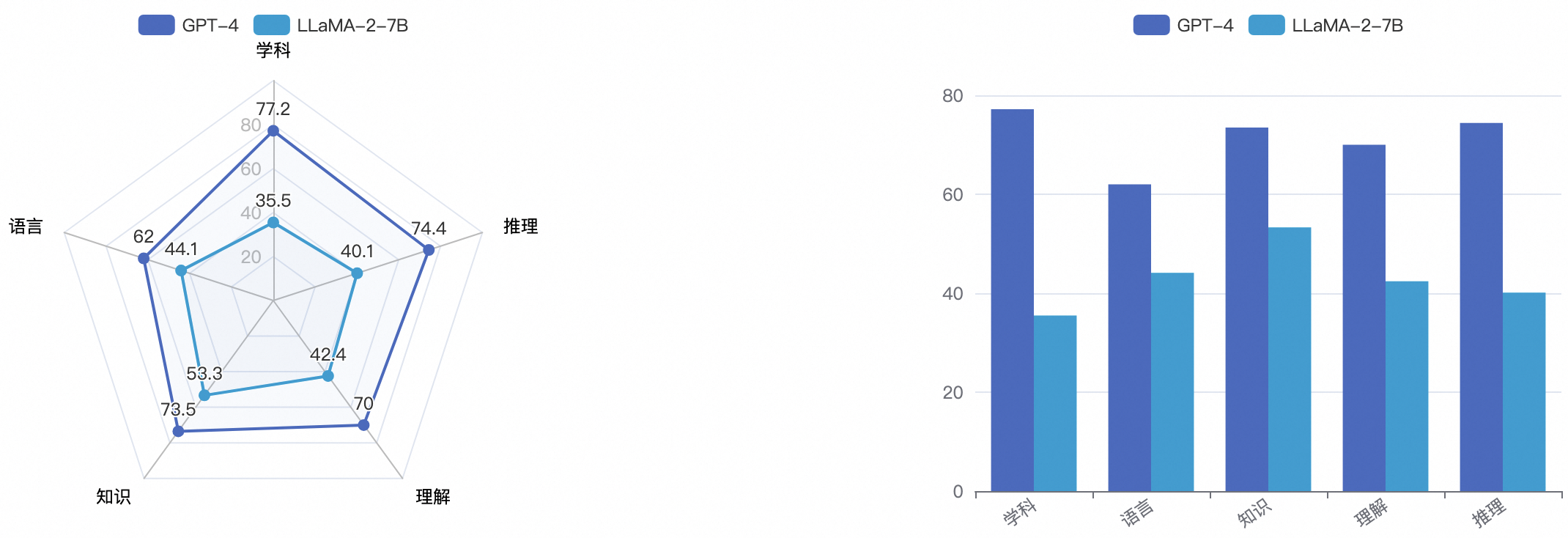
Пример: ГПТ-4 vs Сравнительная оценка размеров возможностей LLaMA2-7B
1. Метод автоматической оценки.
Оценка эффективности модели
- Тесты & Metrics)
Набор данных | описывать | Индекс оценки | Образец |
|---|---|---|---|
MMLU | MassiveMultitaskLanguageUnderstanding Многозадачный набор данных,Состоит из вопросов с несколькими вариантами ответов по различным темам. Охватывает такие области, как STEM, гуманитарные и социальные науки. Включает 57 подзадач,Включает элементарную математику, США. история、Информатика、Законы и так далее. | Accuracy | Question: In 2016, about how many people in the United States were homeless? A. 55,000 B. 550,000 C. 5,500,000 D. 55,000,000 Answer: B |
TriviaQA | Набор для понимания чтения данных, содержит более 650 000 троек вопросов-ответов. Он включает в себя 95 тысяч пар вопросов и ответов, предоставленных энтузиастами викторин. + Написание самостоятельно собранных фактических документов | EM(ExactMatch) F1 (word-level) | (Документ с вопросами-ответами) |
MATH | 12 500 математических задач, каждая с пошаговым решением. | Accuracy | |
HumanEval | HumanEval (Hand-Written Evaluation Set) Написанное от руки решение проблемы данных, требующие создания правильных фрагментов кода на основе заданного вопроса и шаблона кода. Содержит 164 высококачественных вопроса, охватывающих пять языков программирования: Python, C++, Java, Go, и JavaScript。 | pass@k | { “task_id”: “test/0”, “prompt”: “def return1():\n”, “canonical_solution”: " return 1", “test”: “def check(candidate):\n assert candidate() == 1”, “entry_point”: “return1” } |

- Автоматическая оценка на основе правил
Основной процесс

- По мнению Набора данные исходный вопрос для создания подсказки
Пример (несколько кадров)

Пример: малозарядный with CoT
# Examples in BBH
Evaluate the result of a random Boolean expression.
Q: not ( ( not not True ) ) is
A: Let's think step by step.
Remember that (i) expressions inside brackets are always evaluated first and that (ii) the order of operations from highest priority to lowest priority is "not", "and", "or", respectively.
We first simplify this expression "Z" as follows: "Z = not ( ( not not True ) ) = not ( ( A ) )" where "A = not not True".
Let's evaluate A: A = not not True = not (not True) = not False = True.
Plugging in A, we get: Z = not ( ( A ) ) = not ( ( True ) ) = not True = False. So the answer is False.
Q: True and False and not True and True is
A: Let's think step by step.
Remember that (i) expressions inside brackets are always evaluated first and that (ii) the order of operations from highest priority to lowest priority is "not", "and", "or", respectively.
We first simplify this expression "Z" as follows: "Z = True and False and not True and True = A and B" where "A = True and False" and "B = not True and True".
Let's evaluate A: A = True and False = False.
Let's evaluate B: B = not True and True = not (True and True) = not (True) = False.
Plugging in A and B, we get: Z = A and B = False and False = False. So the answer is False.- Модель Прогноз
Generate
# Demo -- model_genereate Генерировать ответ напрямую
def model_generate(query: str, infer_cfg: dict) -> str:
inputs = tokenizer.encode(query)
input_ids = inputs['input_ids']
...
# Process infer cfg (do_sample, top_k, top_p, temperature, special_tokens ...)
generation_config = process_cfg(args)
...
# Run inference
output_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
generation_config=generation_config,
)
response = tokenizer.decode(output_ids, **decode_kwargs)
return responseLikelihood
#Demo -- Метод model_call вычисляет логарифмическое правдоподобие
# context + continuation Сращивание, пример:
# Question: Какая столица Франции?
# Choices: А.Пекин Б.Париж К. Бургер Д.Нью-Йорк
# pair-1: (ctx, cont) = (Какая столица Франции?,А.Пекин)
# pair-2: (ctx, cont) = (Какая столица Франции?,Б.Париж)
# pair-3: (ctx, cont) = (Какая столица Франции?,К. Бургер)
# pair-4: (ctx, cont) = (Какая столица Франции?,Д.Нью-Йорк)
# Logits -->
def loglikelihood(self, inputs: list, infer_cfg: dict = None) -> list:
# To predict one doc
doc_ele_pred = []
for ctx, continuation in inputs:
# ctx_enc shape: [context_tok_len] cont_enc shape: [continuation_tok_len]
ctx_enc, cont_enc = self._encode_pair(ctx, continuation)
inputs_tokens = torch.tensor(
(ctx_enc.tolist() + cont_enc.tolist())[-(self.max_length + 1):][:-1],
dtype=torch.long,
device=self.model.device).unsqueeze(0)
logits = self.model(inputs_tokens)[0]
logits = torch.nn.functional.log_softmax(logits.float(), dim=-1)
logits = logits[:, -len(cont_enc):, :]
cont_enc = cont_enc.unsqueeze(0).unsqueeze(-1)
logits = torch.gather(logits.cpu(), 2, cont_enc.cpu()).squeeze(-1)
choice_score = float(logits.sum())
doc_ele_pred.append(choice_score)
# e.g. [-2.3, 1.1, -12.9, -9.2], length=len(choices)
return doc_ele_pred2. Показатели оценки (Метрики)
- WeightedAverageAccuracy Средневзвешенная точность
- Растерянность
- Rouge (Recall-Oriented Understudy for Gisting Evaluation)
- Bleu (Bilingual evaluation understudy)
- ELO Rating System
- PASS@K
2.1 Автоматическая оценка на основе модели
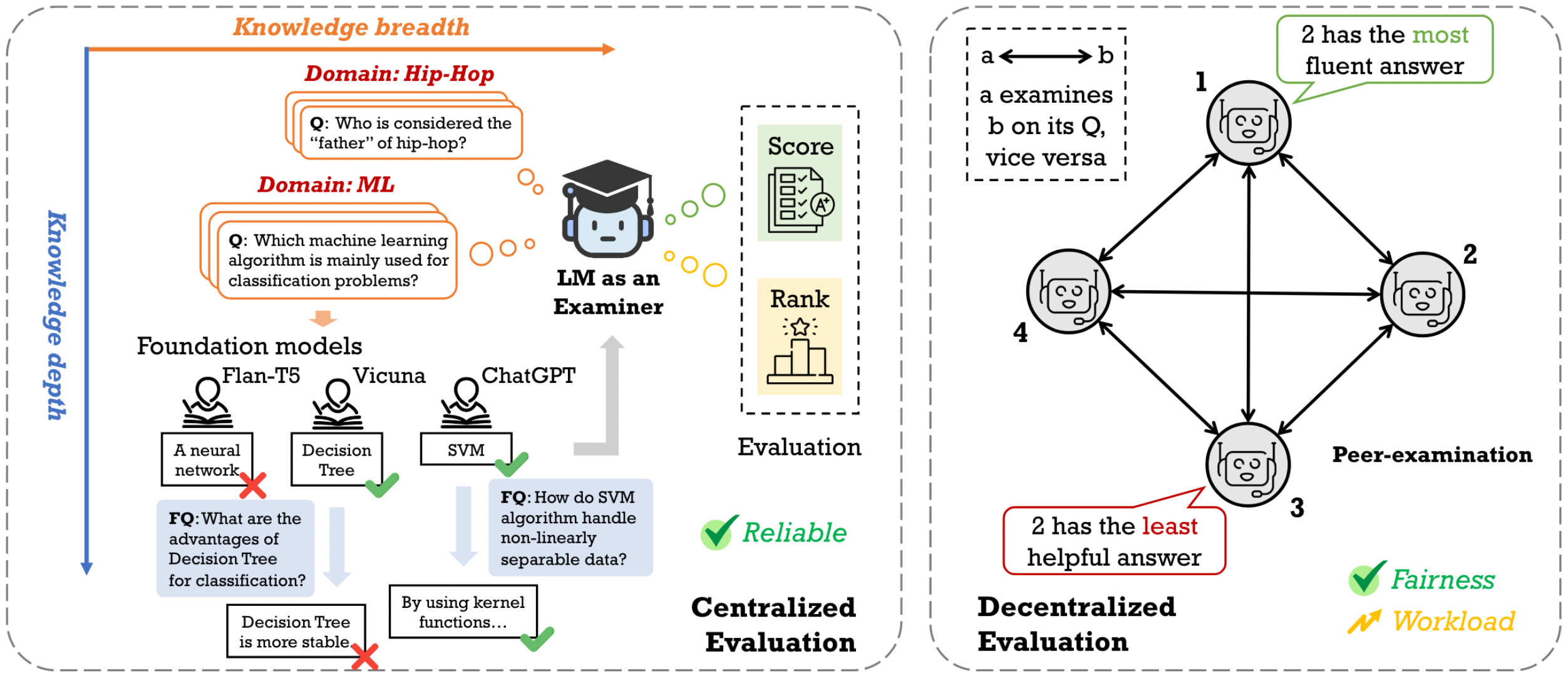
- Централизованная оценка
- Централизованная В режиме настройки,модель Есть только один рефери, высокая надежность, но простая в получении модель. предвзятое влияние рефери
- идти Централизованная оценка
- идти Централизованная метод оценки требует коллегиальной экспертизы между Моделью
- Он характеризуется хорошей справедливостью, но большим объемом вычислений и низкой надежностью.
модель рефери
- GPT-4, Claude, Qwen-Max и т. д. (API продукта)
- PandLM、Auto-J (tuned from LLM, like LLaMA)
- Reward models (Ranking learning)
- Chatbot Arena -Режим арены
- (Battle count of each combination of models, from LMSYS)
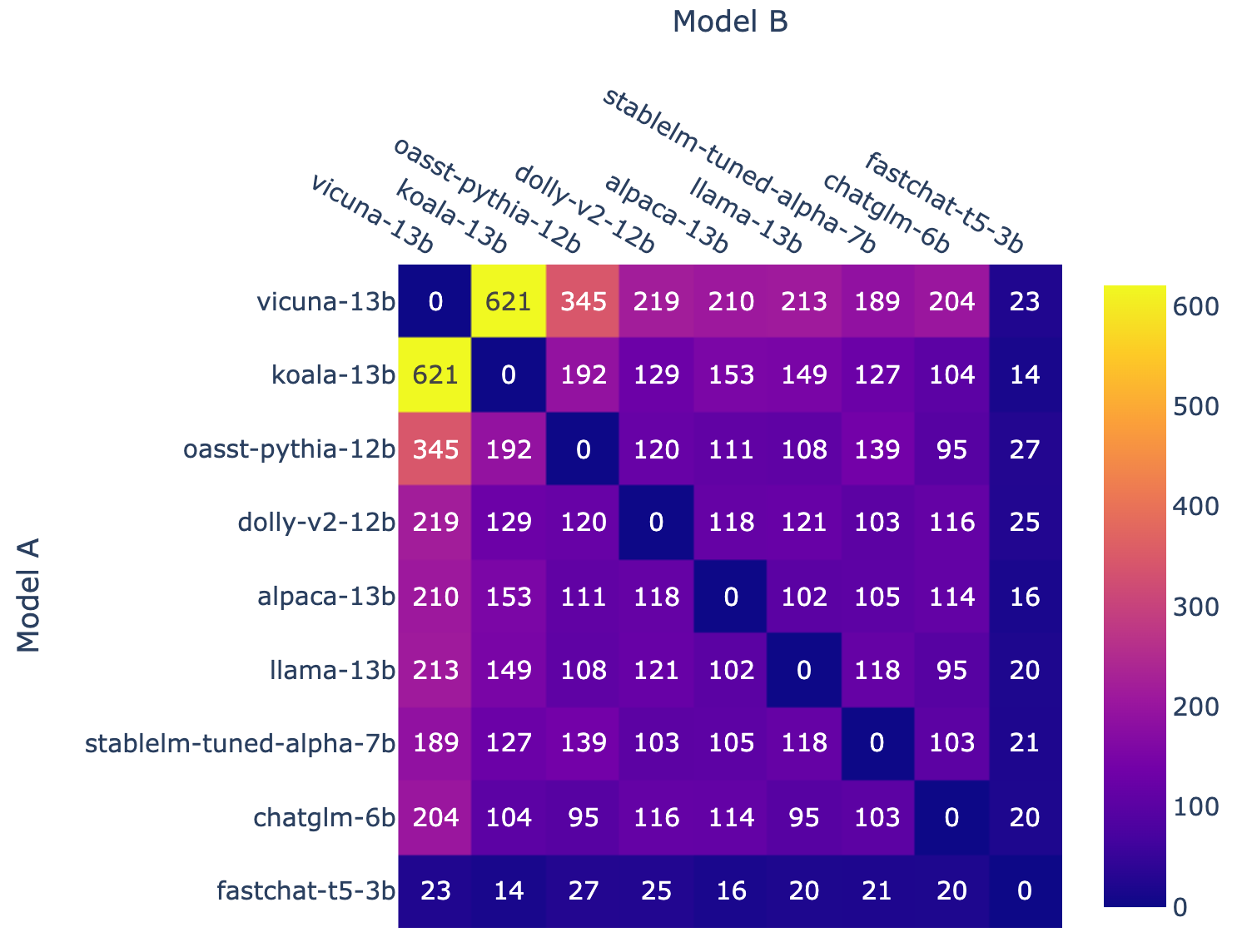
- (Fraction of Model A wins for all non-tied A vs. B battles, from LMSYS)
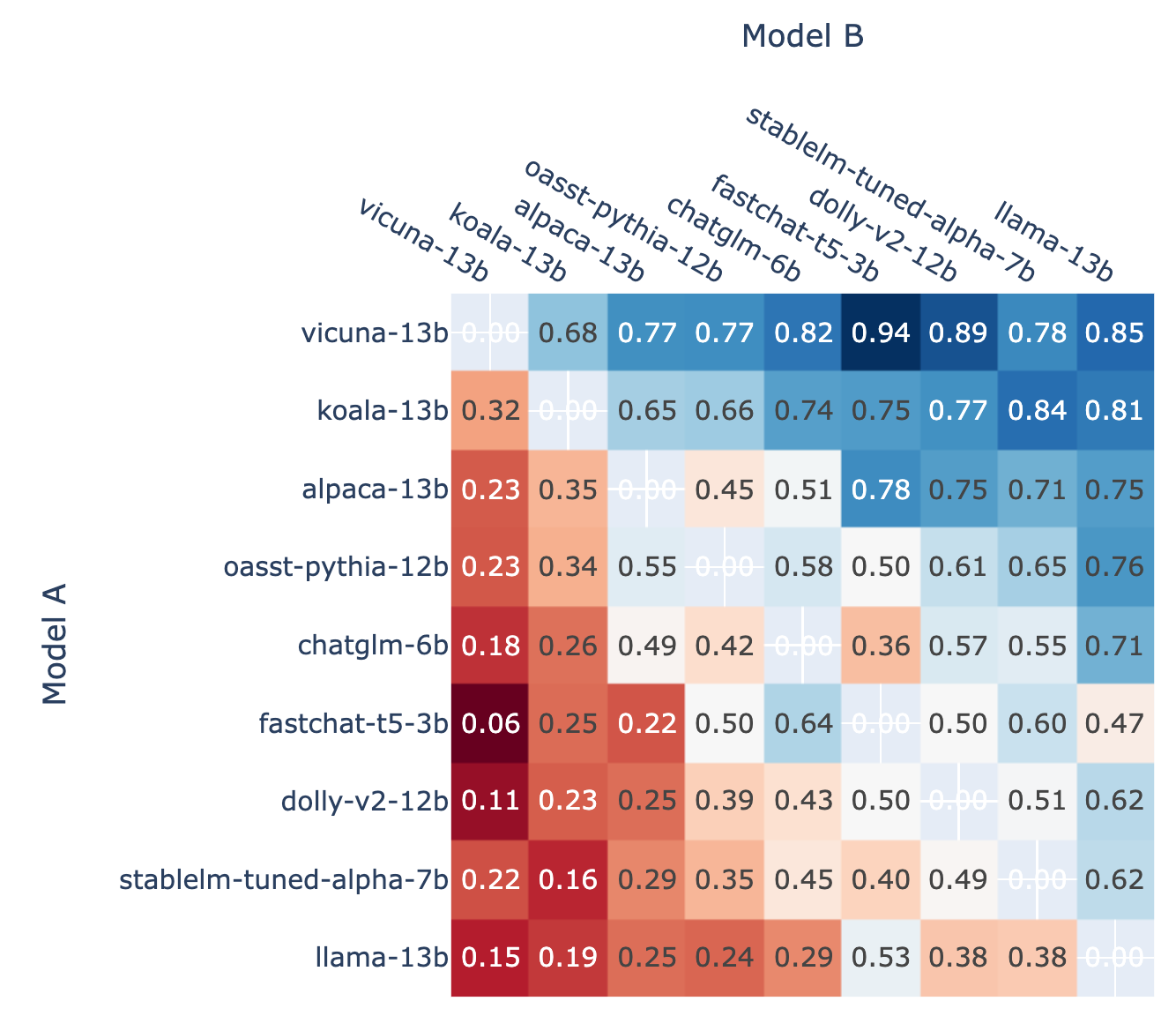
- LLM командование атакой и защитой
- вводное обучение (Побуждает Модель выводить целевой ответ, из SuperCLUE)

- Вредная инструктирующая инъекция (Внесите в подсказку реальное вредоносное намерение, from SuperCLUE)

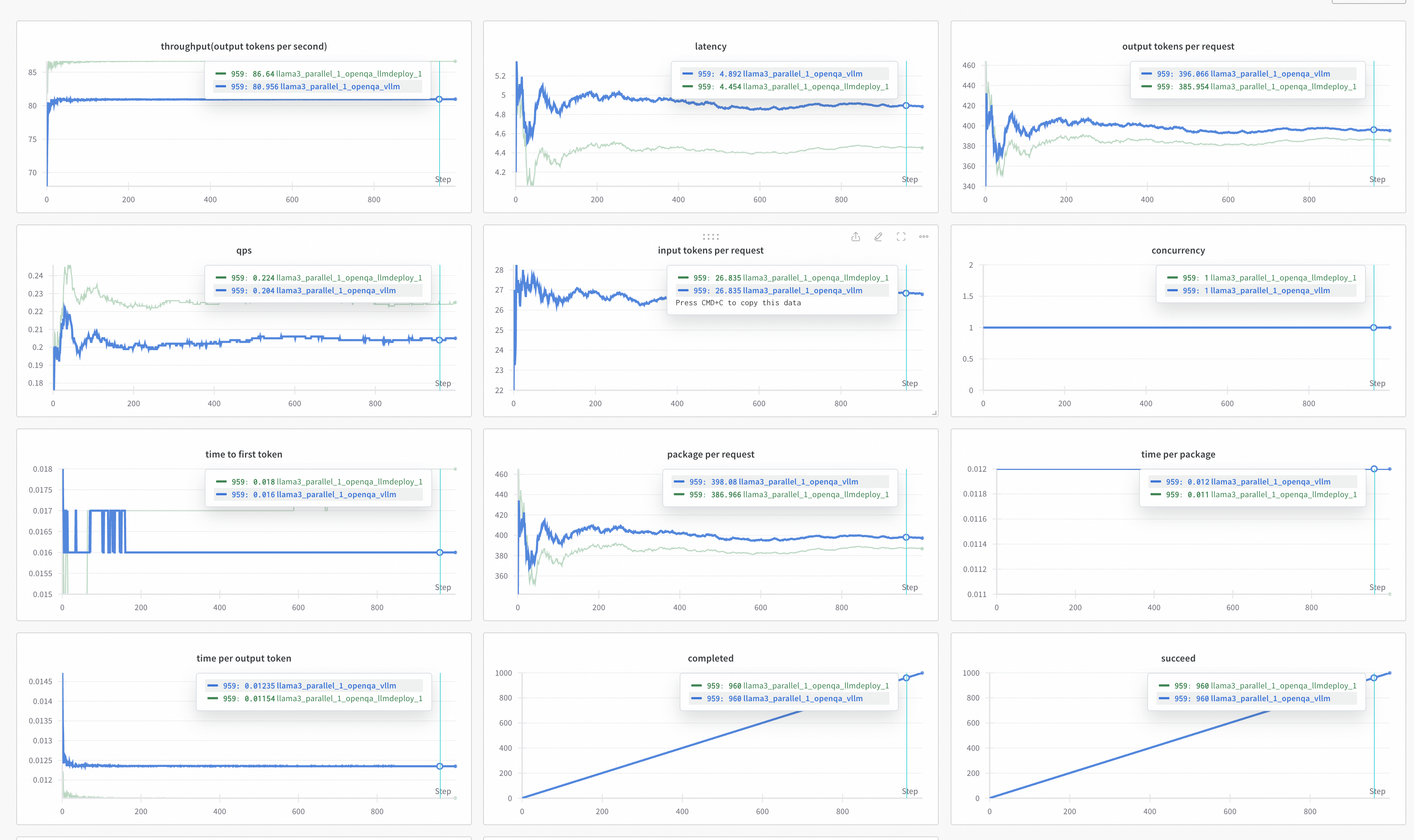
2.2 Оценка эффективности модели
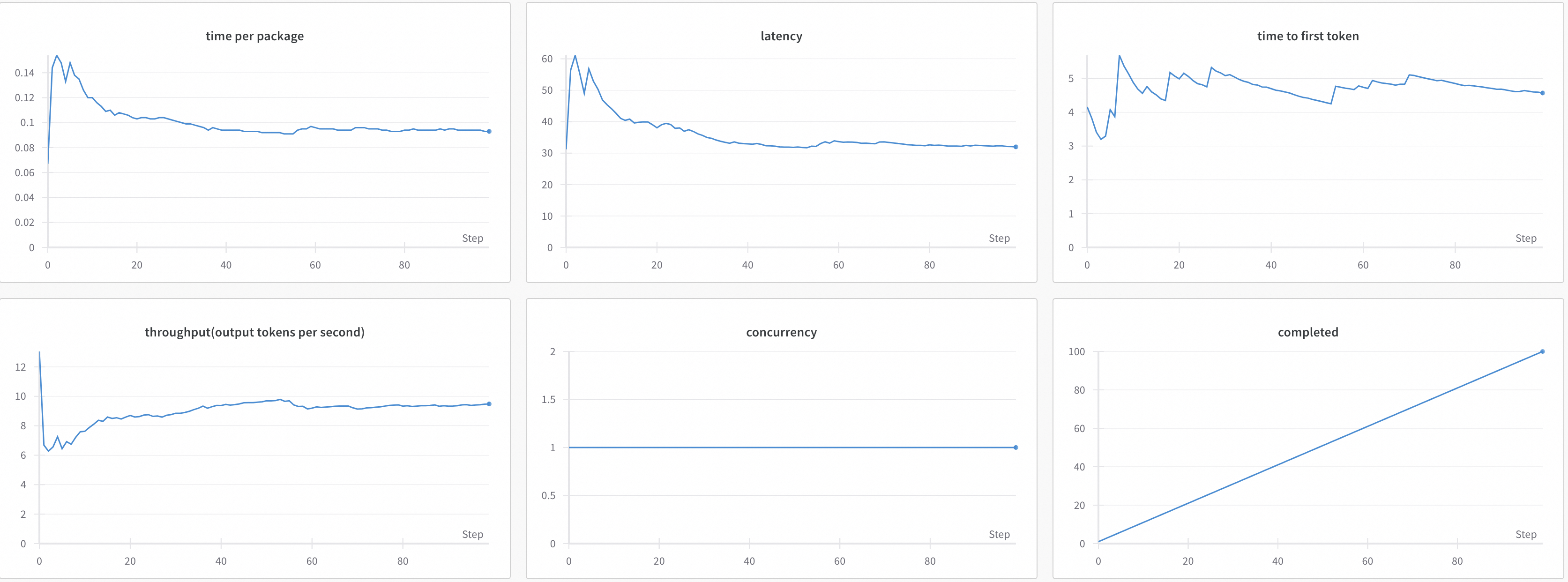
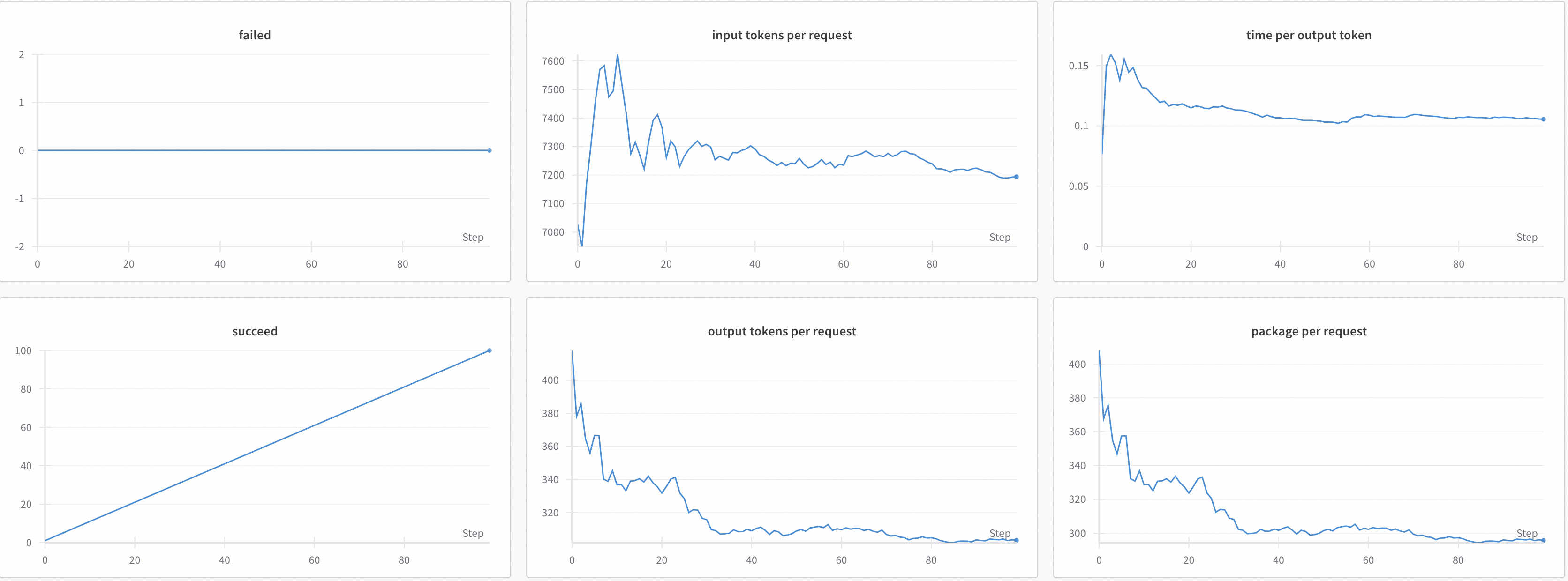
model serving performance evaluation
Название индикатора | иллюстрировать |
|---|---|
Time | Общее время теста (единицы времени — секунды) |
Expected number of requests | Ожидаемое количество запросов, которые будут отправлены,и файл подсказки и ожидаемое число связаны |
concurrency | Количество параллелизма |
completed | Выполненные запросы |
succeed | Количество успешных запросов |
failed | Количество неудачных запросов |
qps | среднее количество запросов в секунду |
latency | средняя задержка |
time to first token | Средняя задержка первого пакета |
throughput | выходных токенов/секунд среднее количество выходных токенов в секунду |
time per output token | Среднее время, необходимое для создания токена. Всего выходных_токенов/Общее время. |
package per request | Среднее количество пакетов на запрос |
time per package | среднее время на упаковку |
input tokens per request | Среднее количество входных токенов на запрос |
output tokens per request | Среднее количество токенов, выводимых за запрос |
2.3 Проблемы и вызовы
- Базовый сбой&данные Уступи дорогу
- статический набор данныеи Быстро развивающиеся возможности LLM образуют пробел, приводящий к провалу тестов
- Публичные тесты были переданы в отделы разработки PT, CPT, SFT и другие каналы разработки LLM.
Решение: динамичный Набор данных
- модель Верхний предел способностей рефери
- модель Рефери имеет очевидные пределы возможностей, и трудно претендовать на оценочную работу с большим количеством сцен и более сильной моделью.
- проблема обобщения
- Проблемы диагностики галлюцинаций LLM
3. Практика оценки LLM
Платформа LLMuses — легкая, комплексная платформа автоматической оценки для больших моделей.
GitHub: https://github.com/modelscope/llmuses
Свойства фрейма
- Предустановленные часто используемые тестовые тесты, в том числе: MMLU, C-Eval, GSM8K, ARC, HellaSwag, TruthfulQA, MATH, HumanEval, BBH, GeneralQA и т. д.
- Внедрение общеиспользуемых показателей оценки (метрик)
- Унифицированный доступ к модели, совместимый с интерфейсами генерации и чата нескольких серий моделей.
- Автоматическая оценка объективных вопросов
- Автоматическая оценка сложных задач с помощью экспертов Модель
- Режим Арены (Арена)
- Формирование и визуализация отчета об оценке
- LLMпроизводительность Обзор(Performance Evaluation)
Установка среды
# 1. Загрузка кода
git clone git@github.com:modelscope/llmuses.git
# 2. Установить зависимости
cd llmuses/
pip install -r requirements/requirements.txt
pip install -e .- Простой обзор
python llmuses/run.py --model ZhipuAI/chatglm3-6b --datasets ceval --outputs ./outputs/test --limit 10- –model: ModelScopeМодельid, (https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary) , также может быть локальным путем к Модели
- –datasets: Набор данныхизid
- –limit: (каждая подзадача) максимальное количество оценочных образцов
- Оценка с параметрами
python llmuses/run.py --model ZhipuAI/chatglm3-6b --outputs ./outputs/test2 --model-args revision=v1.0.2,precision=torch.float16,device_map=auto --datasets arc --limit 10- –model-args: Параметры модели, разделенные запятыми, формат ключ=значение.
- –datasets: Набор имя данных, см. «Набор» ниже. глава списка данных
- –mem-cache: Использовать ли кэш памяти. Если он включен, запущенные файлы будут автоматически кэшироваться и сохраняться на локальном диске.
- –limit: Максимальная сумма оценки для каждого подмножества
- Режим арены – одиночный режим
Одиночный режим с использованием экспертной модели (GPT-4) для оценки тестируемого LLM.
# Example
python llmuses/run_arena.py --c registry/config/cfg_single.yaml --dry-run- Режим арены – базовый режим
Базовый режим: выберите базовую модель и сравните другие LLM, которые будут протестированы с этой моделью.
# Example
python llmuses/run_arena.py --dry-run --c registry/config/cfg_pairwise_baseline.yaml- Режим арены – парный режим
Парный режим, тестируемый LLM воспроизводится парами.
python llmuses/run_arena.py -c registry/config/cfg_arena.yaml --dry-run
- Отчет об оценке эффективности
Храните данные в заранее определенном формате и используйтеstreamlit для запуска сервисов визуализации.
# Usage:
streamlit run viz.py -- --review-file llmuses/registry/data/qa_browser/battle.jsonl --category-file llmuses/registry/data/qa_browser/category_mapping.yaml- Визуализация отчета
- Оценка производительности модели (Perf Eval)
Пример отчета об оценке эффективности
4. Рамки оценки больших моделей
Ссылка: https://github.com/modelscope/eval-scope
Оценка большой языковой модели (LLM) Оценка) стала важным процессом и средством оценки и улучшения большой Модели. Чтобы лучше поддерживать оценку большой Модели, мы предложили llmusesramka, которая в основном включает в себя следующие части:
- Предустановка нескольких часто используемых тестовых тестов данных,В том числе: MMLU, CMMLU, C-Eval, GSM8K, ARC, HellaSwag, TruthfulQA, MATH, HumanEval и т. д.
- Внедрение общеиспользуемых показателей оценки (метрик)
- Унифицированный доступ к модели, совместимый с интерфейсами генерации и чата нескольких серий моделей.
- Автоматическая оценка (оценщик):
- Автоматическая оценка объективных вопросов
- Автоматическая оценка сложных задач с помощью экспертов Модель
- Создание отчета об оценке
- Режим Арены (Арена)
- Инструменты визуализации
- Модельпроизводительность Оценивать
- Функции
- Легкий, минимизируйте ненужную абстракцию и настройку.
- Легко настроить
- Вам нужно реализовать только один класс для доступа к новому Набору. данных
- Модель Может быть размещен наModelScopeначальство,Просто нужноmodel Вы можете начать проверку одним щелчком мыши, используя свой идентификатор.
- Поддержка локального уровня. Модель может быть развернута локально.
- Оценивать Визуализация отчетапоказывать
- Богатые индикаторы оценки
- Процесс автоматической оценки на основе модели поддерживает несколько режимов оценки.
- Одиночный режим: Экспертная модель оценивает одну модель.
- Pairwise-baseline mode: и baseline Модельконтраст
- Pairwise (all) mode: Все модели попарное сравнение
4.1 Подготовка окружающей среды
Мы рекомендуем использовать conda для управления средой и pip для установки зависимостей:
- Создать среду Конды
conda create -n eval-scope python=3.10
conda activate eval-scope- Установить зависимости
pip install llmuses- Установить из исходного кода
- Скачать исходный код
git clone https://github.com/modelscope/eval-scope.git- Установить зависимости
cd eval-scope/
pip install -e .4.2 Быстрый старт
- Простая оценка В указанном количестве Набор Чтобы оценить определенную Модель по данным, процесс выглядит следующим образом: Если он установлен с помощью git, его можно выполнить по любому пути:
python -m llmuses.run --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --limit 100Если вы используете исходный код для установки, выполните по пути eval-scope:
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets mmlu ceval --limit 10Среди них параметр –model указывает ModelScope модели. model id,Модель Связь:ZhipuAI/chatglm3-6b
- С оценкой параметров
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --model-args revision=v1.0.2,precision=torch.float16,device_map=auto --datasets mmlu ceval --use-cache true --limit 10python llmuses/run.py --model qwen/Qwen-1_8B --generation-config do_sample=false,temperature=0.0 --datasets ceval --dataset-args '{"ceval": {"few_shot_num": 0, "few_shot_random": false}}' --limit 10параметриллюстрировать:
- –model-args: Параметры модели, разделенные запятыми, формат ключ=значение.
- –datasets: Набор имя данных, поддерживает ввод нескольких наборов данных,Используйте пробелы для разделения,См. ниже
Набор данных列表章节 - --use-cache: использовать ли локальный кеш,По умолчанию
false;если дляtrue,тогда комбинация данных Модели Набора, которая уже была оценена, не будет оцениваться снова,Чтение непосредственно из локального кеша - –dataset-args: Набор данныхизevaluation настройки, передаются в формате json, ключ — Набор имя данных, значение — это параметр. Обратите внимание, что оно должно соответствовать значению параметра –datasets.
- –few_shot_num: количество нескольких выстрелов
- –few_shot_random: следует ли случайным образом выбирать несколько кадров,Если не установлено,По умолчанию верно
- –limit: Максимальная сумма оценки для каждого подмножества
- –template-type: Этот параметр необходимо указать вручную, чтобы eval-scope мог правильно определить тип Модели и использовать его для установки модели. generation config。
О --template-type,Подробную информацию см.:Список типов моделей Вы можете использовать следующий метод для просмотра шаблона модели. type list:
from llmuses.models.template import TemplateType
print(TemplateType.get_template_name_list())4.3 Использование локальных наборов данных
Набор данных По умолчанию размещается по адресуModelScopeначальство,Для загрузки требуется подключение к Интернету. Если нет сетевого окружения,Вы можете использовать локальный Набор данных, процесс выглядит следующим образом:
- Загрузить Набор данных на локальный компьютер
#Если текущий локальный рабочий путь — /path/to/workdir
wget https://modelscope.oss-cn-beijing.alyuncs.com/open_data/benchmark/data.zip
разархивировать data.zipЗатем распакованный Набор Путь к данным:/path/to/workdir/data каталог, который будет передан в качестве значения параметра –dataset-dir на последующих шагах.
- Создание задач оценки с использованием локального набора данных.
python llmuses/run.py --model ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-dir /path/to/workdir/data --limit 10
#параметриллюстрировать
#--dataset-hub: Набор источник данных, значение перечисления: `ModelScope`, `Local`, `HuggingFace` (TO-DO) По умолчанию — ModelScope.
#-dataset-dir: Когда --dataset-hub имеет значение «Локальный», этот параметр относится к локальному набору данныхпуть; если --dataset-hub Установите значение ModelScope. or `HuggingFace`, значение этого параметра — Набор путь к кэшу данных.- (Необязательно) Загрузить обзоры Модели в автономной среде. Файлы моделей, размещенные на ModelScope Для загрузки сторона концентратора должна быть подключена к Интернету. Если вам необходимо создать оценочную задачу в автономной среде, выполните следующие действия:
#1. Подготовьте локальную папку модели. Структура папки относится к ссылке Chatglm3-6b: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files.
#Например, загрузите всю папку Модель по локальному пути /path/to/ZhipuAI/chatglm3-6b
#2. Выполнять задачи автономной оценки
python llmuses/run.py --model /path/to/ZhipuAI/chatglm3-6b --template-type chatglm3 --datasets arc --dataset-hub Local --dataset-dir /path/to/workdir/data --limit 104.4. Используйте функцию run_task для отправки задач оценки.
- Задачи настройки
import torch
from llmuses.constants import DEFAULT_ROOT_CACHE_DIR
#пример
your_task_cfg = {
'model_args': {'revision': None, 'precision': torch.float16, 'device_map': 'auto'},
'generation_config': {'do_sample': False, 'repetition_penalty': 1.0, 'max_new_tokens': 512},
'dataset_args': {},
'dry_run': False,
'model': 'ZhipuAI/chatglm3-6b',
'datasets': ['arc', 'hellaswag'],
'work_dir': DEFAULT_ROOT_CACHE_DIR,
'outputs': DEFAULT_ROOT_CACHE_DIR,
'mem_cache': False,
'dataset_hub': 'ModelScope',
'dataset_dir': DEFAULT_ROOT_CACHE_DIR,
'stage': 'all',
'limit': 10,
'debug': False
}- выполнять задачи
from llmuses.run import run_task
run_task(task_cfg=your_task_cfg)4.4.1 Режим Арены (Арена)
Режим арены позволяет оценивать несколько моделей-кандидатов посредством парных сражений, и вы можете использовать процесс автоматической оценки AI Enhanced Auto-Reviewer (AAR) или ручную оценку, чтобы окончательно получить отчет об оценке. Пример процесса: следует:
- Экологическая подготовка
a. данные Подготовить,questions Ссылка на формат данных: llmuses/registry/data/question.jsonl.
b. Если вам нужно использовать процесс автоматической оценки (AAR), вам необходимо настроить соответствующие переменные среды. Мы используем GPT-4. based Если взять в качестве примера процесс автоматического рецензента, необходимо настроить следующие переменные среды:
> export OPENAI_API_KEY=YOUR_OPENAI_API_KEY- Конфигурационный файл
Конфигурация процесса оценки арены файлссылка: llmuses/registry/config/cfg_arena.yaml
Полеиллюстрировать: questions_file: question путь к данным
answers_gen: Результаты прогнозирования модели-кандидата генерируются с поддержкой нескольких моделей. Вы можете контролировать, следует ли включать модель, с помощью параметра Enable.
reviews_gen: Результаты оценки генерируются. В настоящее время GPT-4 используется в качестве автоматического рецензента по умолчанию. Вы можете указать, следует ли включать этот шаг, с помощью параметра Enable.
elo_rating: ELO rating алгоритм,Вы можете контролировать, следует ли включать этот шаг, с помощью параметра Enable.,Обратите внимание, что этот шаг зависит от файла review_file, который должен существовать.- Выполнить скрипт
#Usage:
cd llmuses
#режим пробного запуска (Модельответ генерируется нормально, но экспертная Модель не запускается, и результаты оценки будут генерироваться случайным образом)
python llmuses/run_arena.py -c registry/config/cfg_arena.yaml --dry-run
#Выполняем процесс оценки
python llmuses/run_arena.py --c registry/config/cfg_arena.yaml- Визуализация результатов
#Usage:
streamlit run viz.py -- --review-file llmuses/registry/data/qa_browser/battle.jsonl --category-file llmuses/registry/data/qa_browser/category_mapping.yaml4.4.2 Режим оценки одной модели (одиночный режим)
В этом режиме мы оцениваем выходные данные только одной модели без попарных сравнений.
- Конфигурационный файл
Процесс оценки Конфигурационного файлссылка: llmuses/registry/config/cfg_single.yaml
Полеиллюстрировать: questions_file: question путь к данным
answers_gen: Результаты прогнозирования модели-кандидата генерируются с поддержкой нескольких моделей. Вы можете контролировать, следует ли включать модель, с помощью параметра Enable.
reviews_gen: Результаты оценки генерируются. В настоящее время GPT-4 используется в качестве автоматического рецензента по умолчанию. Вы можете указать, следует ли включать этот шаг, с помощью параметра Enable.
rating_gen: rating алгоритм,Вы можете контролировать, следует ли включать этот шаг, с помощью параметра Enable.,Обратите внимание, что этот шаг зависит от файла review_file, который должен существовать.- Выполнить скрипт
#Example:
python llmuses/run_arena.py --c registry/config/cfg_single.yaml4.4.3 Режим сравнения базовой модели (режим Pairwise-baseline)
В этом режиме мы выбираем базовую модель, сравниваем и оцениваем другие модели с помощью базовой модели. В этом режиме можно легко добавлять новые модели в таблицу лидеров (вам нужно только один раз запустить и оценить новую модель и базовую модель).
- Конфигурационный файл
Процесс оценки Конфигурационного файлссылка: llmuses/registry/config/cfg_pairwise_baseline.yaml
Полеиллюстрировать: questions_file: question путь к данным
answers_gen: Результаты прогнозирования модели-кандидата генерируются с поддержкой нескольких моделей. Вы можете контролировать, следует ли включать модель, с помощью параметра Enable.
reviews_gen: Результаты оценки генерируются. В настоящее время GPT-4 используется в качестве автоматического рецензента по умолчанию. Вы можете указать, следует ли включать этот шаг, с помощью параметра Enable.
rating_gen: rating алгоритм,Вы можете контролировать, следует ли включать этот шаг, с помощью параметра Enable.,Обратите внимание, что этот шаг зависит от файла review_file, который должен существовать.- Выполнить скрипт
#Example:
python llmuses/run_arena.py --c llmuses/registry/config/cfg_pairwise_baseline.yaml4.5 Список наборов данных
DatasetName | Link | Status | Note |
|---|---|---|---|
mmlu | mmlu | Active | |
ceval | ceval | Active | |
gsm8k | gsm8k | Active | |
arc | arc | Active | |
hellaswag | hellaswag | Active | |
truthful_qa | truthful_qa | Active | |
competition_math | competition_math | Active | |
humaneval | humaneval | Active | |
bbh | bbh | Active | |
race | race | Active | |
trivia_qa | trivia_qa | To be intergrated |
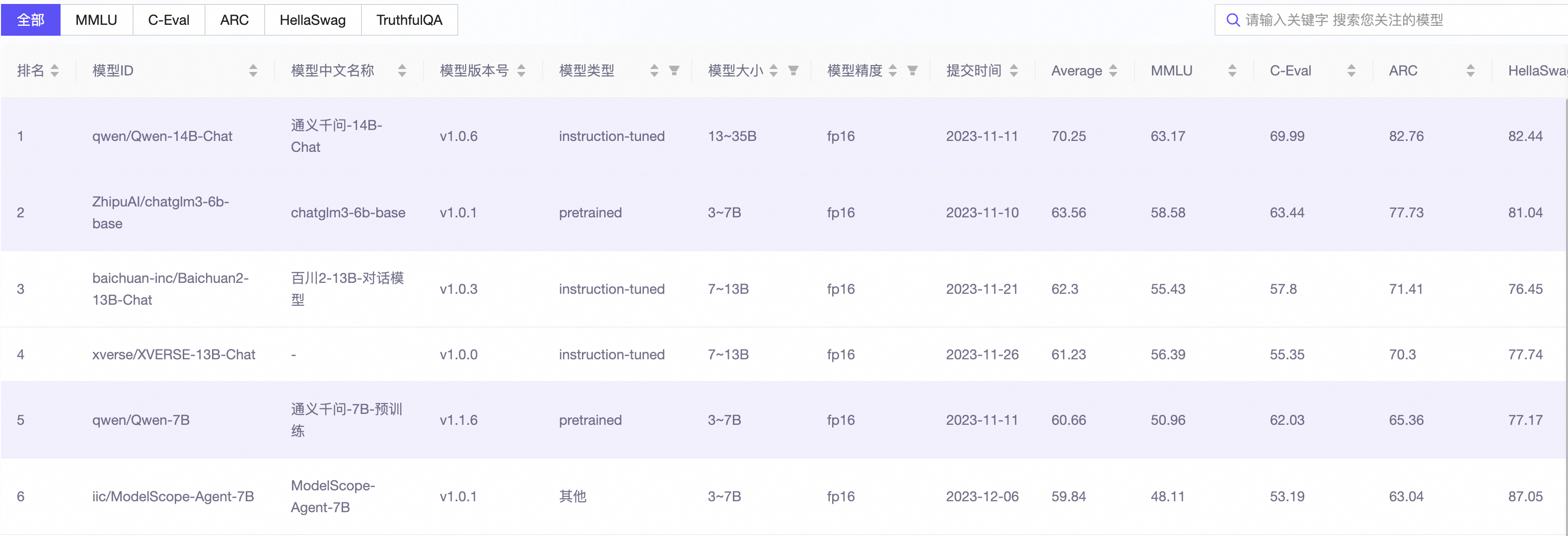
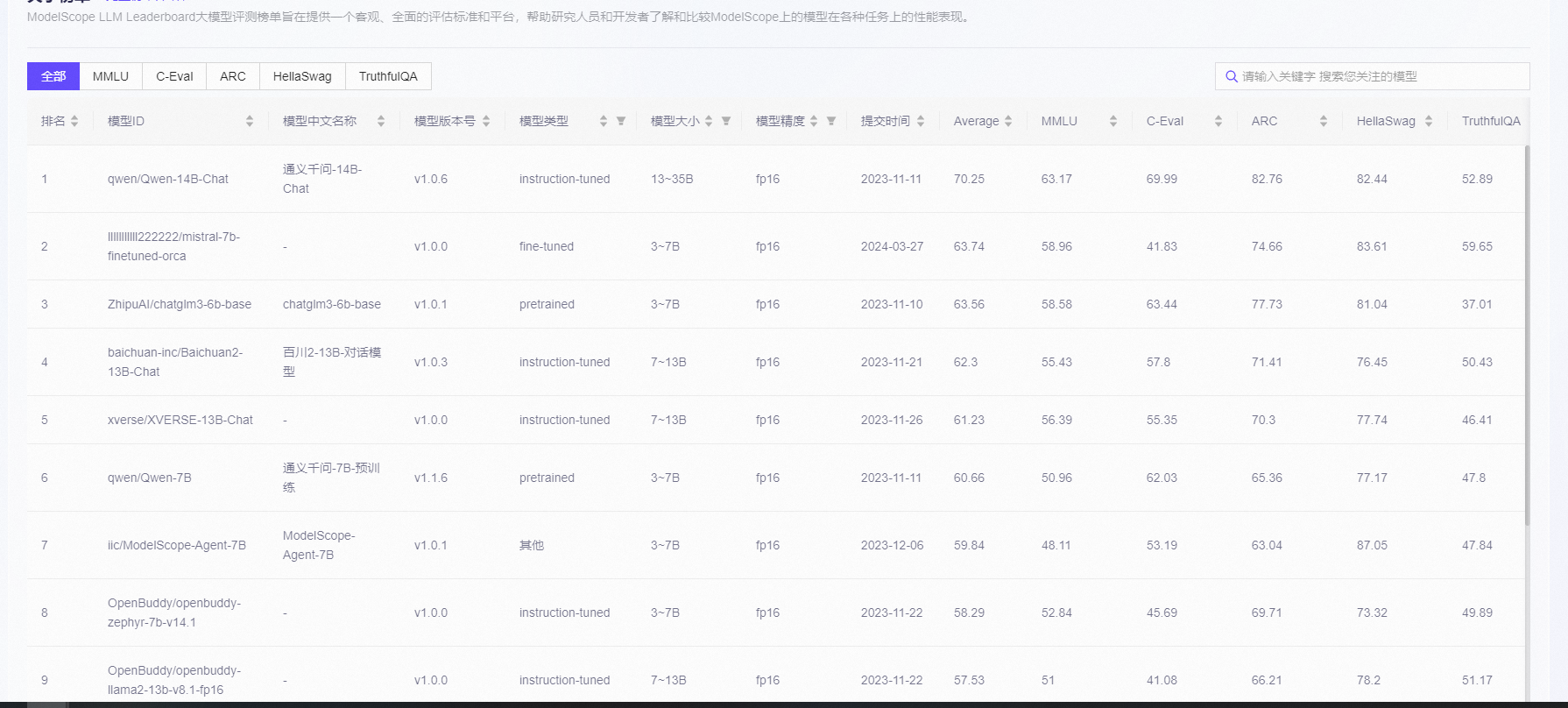
4.6 Список лидеров
ModelScope LLM Leaderboard Большая оценка модели Список призван предоставить объективный и всеобъемлющий стандарт оценки и платформу, которая поможет исследователям и разработчикам понять и сравнить производительность при выполнении различных задач в ModelScope.
4.7 Эксперименты и отчеты
Model | Revision | Precision | Humanities | STEM | SocialScience | Other | WeightedAvg | Target | Delta |
|---|---|---|---|---|---|---|---|---|---|
Baichuan2-7B-Base | v1.0.2 | fp16 | 0.4111 | 0.3807 | 0.5233 | 0.504 | 0.4506 | - | |
Baichuan2-7B-Chat | v1.0.4 | fp16 | 0.4439 | 0.374 | 0.5524 | 0.5458 | 0.4762 | - | |
chatglm2-6b | v1.0.12 | fp16 | 0.3834 | 0.3413 | 0.4708 | 0.4445 | 0.4077 | 0.4546(CoT) | -4.69% |
chatglm3-6b-base | v1.0.1 | fp16 | 0.5435 | 0.5087 | 0.7227 | 0.6471 | 0.5992 | 0.614 | -1.48% |
internlm-chat-7b | v1.0.1 | fp16 | 0.4005 | 0.3547 | 0.4953 | 0.4796 | 0.4297 | - | |
Llama-2-13b-ms | v1.0.2 | fp16 | 0.4371 | 0.3887 | 0.5579 | 0.5437 | 0.4778 | - | |
Llama-2-7b-ms | v1.0.2 | fp16 | 0.3146 | 0.3037 | 0.4134 | 0.3885 | 0.3509 | - | |
Qwen-14B-Chat | v1.0.6 | bf16 | 0.5326 | 0.5397 | 0.7184 | 0.6859 | 0.6102 | - | |
Qwen-7B | v1.1.6 | bf16 | 0.387 | 0.4 | 0.5403 | 0.5139 | 0.4527 | - | |
Qwen-7B-Chat-Int8 | v1.1.6 | int8 | 0.4322 | 0.4277 | 0.6088 | 0.5778 | 0.5035 | - |
- Target – The official claimed score of the model on the dataset
- Delta – The difference between the WeightedAvg score and the Target score
- Settings: (Split: test, Total num: 13985, 5-shot)
Model | Revision | Precision | Humanities | STEM | SocialScience | Other | WeightedAvg | Avg | Target | Delta |
|---|---|---|---|---|---|---|---|---|---|---|
Baichuan2-7B-Base | v1.0.2 | fp16 | 0.4295 | 0.398 | 0.5736 | 0.5325 | 0.4781 | 0.4918 | 0.5416 (official) | -4.98% |
Baichuan2-7B-Chat | v1.0.4 | fp16 | 0.4344 | 0.3937 | 0.5814 | 0.5462 | 0.4837 | 0.5029 | 0.5293 (official) | -2.64% |
chatglm2-6b | v1.0.12 | fp16 | 0.3941 | 0.376 | 0.4897 | 0.4706 | 0.4288 | 0.4442 | - | - |
chatglm3-6b-base | v1.0.1 | fp16 | 0.5356 | 0.4847 | 0.7175 | 0.6273 | 0.5857 | 0.5995 | - | - |
internlm-chat-7b | v1.0.1 | fp16 | 0.4171 | 0.3903 | 0.5772 | 0.5493 | 0.4769 | 0.4876 | - | - |
Llama-2-13b-ms | v1.0.2 | fp16 | 0.484 | 0.4133 | 0.6157 | 0.5809 | 0.5201 | 0.5327 | 0.548 (official) | -1.53% |
Llama-2-7b-ms | v1.0.2 | fp16 | 0.3747 | 0.3363 | 0.4372 | 0.4514 | 0.3979 | 0.4089 | 0.453 (official) | -4.41% |
Qwen-14B-Chat | v1.0.6 | bf16 | 0.574 | 0.553 | 0.7403 | 0.684 | 0.6313 | 0.6414 | 0.646 (official) | -0.46% |
Qwen-7B | v1.1.6 | bf16 | 0.4587 | 0.426 | 0.6078 | 0.5629 | 0.5084 | 0.5151 | 0.567 (official) | -5.2% |
Qwen-7B-Chat-Int8 | v1.1.6 | int8 | 0.4697 | 0.4383 | 0.6284 | 0.5967 | 0.5271 | 0.5347 | 0.554 (official) | -1.93% |
4.8 Инструменты оценки эффективности
Инструмент стресс-тестирования, ориентированный на большой язык Модель,Настраивается для поддержки различных форматов набора данных.,И различные форматы протоколов API.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
