Серия Hadoop MapReduce: Map, Shuffle, уменьшить
Сегодняшняя рекомендация: поиграйте с рабочим процессом ИИ: шаг за шагом создайте гибкий автоматизированный процесс.
Ссылка на статью:https://cloud.tencent.com/developer/article/2470497
В этой статье представлены основные концепции рабочего процесса, управляемого событиями пошагового метода контроля и управления процессом выполнения приложения, а также демонстрируется его использование с помощью практического кода.
Предисловие
- Hadoop — это платформа распределенных вычислений с открытым исходным кодом, предназначенная для обработки крупномасштабных данных. Первоначально разработанный Apache Software Foundation, он обеспечивает экономичное хранение и обработку огромных объемов данных в распределенных кластерах. Основные компоненты Hadoop включают распределенное хранилище (HDFS) и распределенные вычисления (MapReduce), а также набор вспомогательных инструментов.
- В этой статье основное внимание будет уделено
Распределенные вычисления (MapReduce), Hadoop MapReduce Это модель распределенных вычислений, предназначенная для обработки крупномасштабных наборов данных. Это значительно повышает эффективность обработки данных за счет разложения задач на несколько подзадач и их параллельного выполнения в распределенном кластере. В этой статье будет подробно разобран MapReduce из Трех ядерэтап: Этап карты、Этап перемешивания и Уменьшить фазу, чтобы помочь вам глубже понять механизм его работы.
Обзор базового процесса MapReduce
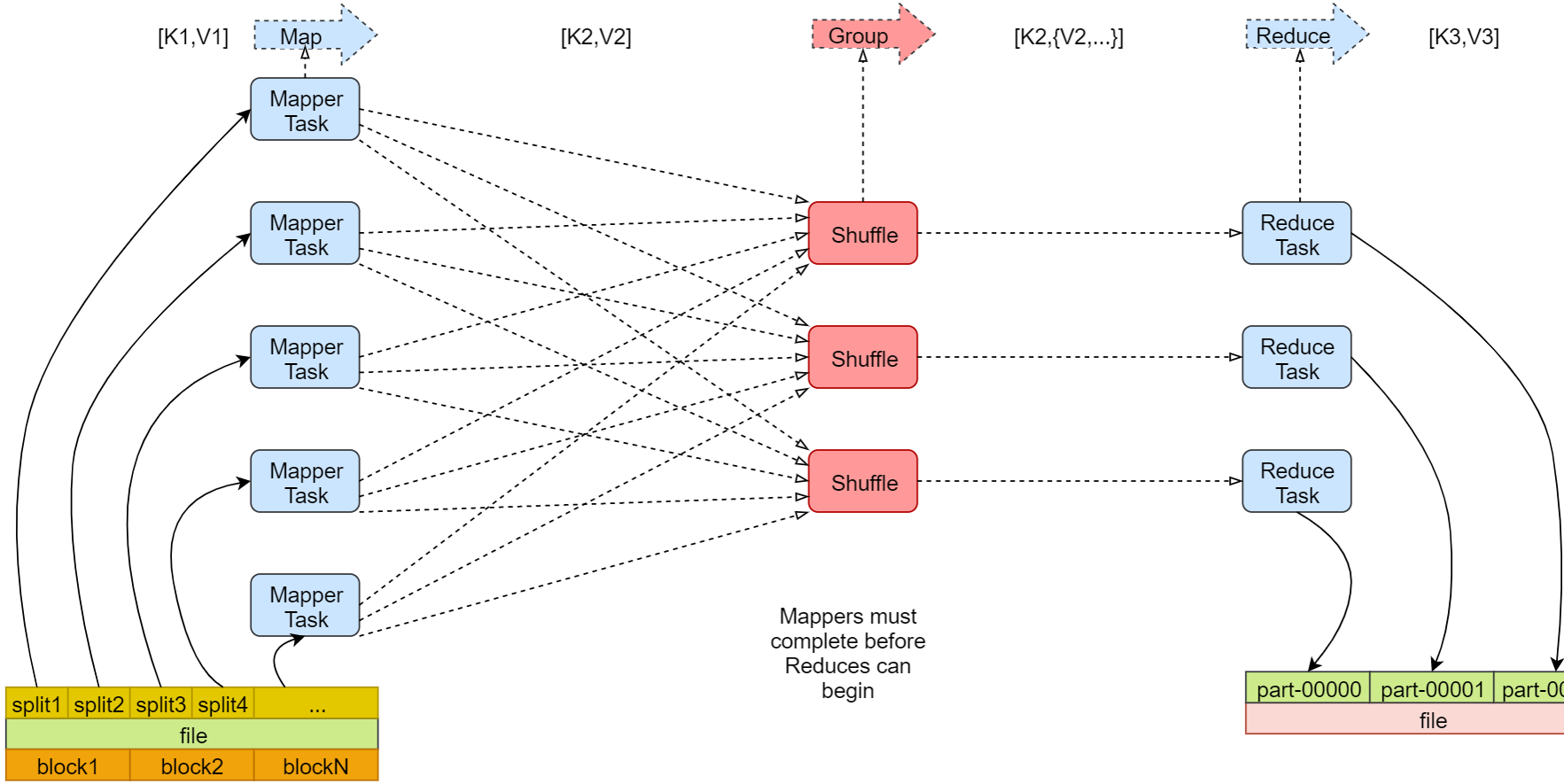
- для лучшего понимания
MapReduceВычислительная модель,Выше приведена блок-схема моего поиска в Интернете.,может быть ясноиз Видно, что весь процесс можно условно разделить на триэтап:Map、Shuffle、Reduce,Но на самом деле в существование вступил три этапа назад,Существует также этап осколков данных.,Таким образом, мы можем разделить весь процесс на следующие четыре этапа:
1. Фрагментация входных данных: данные Воля разбиваются на несколько логических блоков, причем каждый блок делится на Mapper иметь дело с.
2、Этап карты: Обработка входных данных и преобразование их в ключевые значения верно (key, value)。
3、Этап перемешивания:верно Этап картыиз Вывод секционируется, сортируется и группируется.
4、Уменьшить фазу:верно Все значения одного и того же ключа агрегируются или вычисляются, и выводится окончательный результат.Подробное объяснение трех основных этапов MapReduce.
Этап карты
- Преобразуйте входные данные в форму промежуточных пар ключ-значение (ключ, значение).
Принцип работы
- Формат ввода: InputFormat Hadoop (по умолчанию — TextInputFormat) разбивает необработанные данные на логические записи и передает их в Mapper.
1. Каждый логический блок состоит из Mapper Обработка, чтение входных данных и формирование промежуточных результатов.
2. Пользователи должны осознавать map() Метод, определяющий, как входные данные Воли преобразуются в промежуточные. (key, value) верно。- Пример
Введите данные:
hello hadoop
hello world
Выходные данные
(hello, 1), (hadoop, 1), (hello, 1), (world, 1)Этап перемешивания
- Воля Этап картыиз Промежуточные результаты организованы как Reducer Доступные форматы включают секционирование, сортировку и группировку.
- находится между Map и Reduce процесс между ними можно разделить на Map приличный shuffle и Reduce приличный Shuffle。
конкретные шаги
Раздел
- В соответствии с функцией секционирования (по умолчанию используется хеш-функция). hash(key) % num_reducers) Воля промежуточные значения ключей верно присваиваются разным из Reducer。 Идентичные пары ключ-значение будут отправлены на один и тот же адрес. Reducer。
Сортировать
- Глобально сортируйте промежуточные пары ключ-значение по ключу.
- Сортировка может выполняться локально на стороне Mapper или глобально объединяться и сортироваться на стороне Редюсера.
Группировка (Объединить и Группировать)
- На стороне Редюсера все значения с одинаковым ключом объединяются в список.
- При необходимости используйте функцию «Объединитель» для предварительного агрегирования промежуточных результатов на стороне Mapper, чтобы уменьшить сетевой трафик.
- Пример
Введите данные:
(hello, 1), (hadoop, 1), (hello, 1), (world, 1)
Выходные данные
Reducer 1: (hadoop, [1])
Reducer 2: (hello, [1, 1]), (world, [1])- Уведомление:
Этап Растворение может стать узким местом в производительности, поскольку задействованы большие объемы данных в операциях сетевой передачи и сортировки.
Уменьшить фазу
- верный Этап перемешивания После группировки промежуточные результаты суммируются или рассчитываются, и выводится окончательный результат.
Принцип работы
1、входить:<key, list(values)>,То есть каждый ключ должен иметь список значений.
2. Пользователи должны осознавать reduce() метод,Определите, как правильно иметь все значения одного и того же ключа. дело с.- Пример
Введите данные:
(hadoop, [1])
(hello, [1, 1])
(world, [1])
Выходные данные
(hadoop, 1)
(hello, 2)
(world, 1)Сценарии применения MapReduce
- Анализ данных: например, обработка журналов и анализ потока кликов.
- Обработка текста: например, полнотекстовое индексирование и статистика частоты слов.
- Крупномасштабные вычисления: такие как умножение матриц, обработка графов.
MapReduce Практика Java
Настройка среды Hadoop
- Основная демонстрация этой статьи
MapReduce:Map、Shuffle、ReduceТри процесса, поэтому при установке используются готовые docker Реализация зеркала:
docker pull sequenceiq/hadoop-docker:2.7.1
# бегать Hadoop контейнер с одним узлом
docker run -it --name hadoop-master -p 8088:8088 -p 9870:9870 -p 9000:9000 sequenceiq/hadoop-docker:2.7.1- После успешной установки служба доступа запускается нормально?
HDFS NameNode Интерфейс: http://xxxxx:9870
YARN ResourceManager Интерфейс: http://xxxx:8088Реализация кода
- Ниже мы покажем, как использовать Java Реализуйте базовую программу статистики частоты слов (WordCount), включая Mapper、Reducer и Driver полного Java добрый. .
- WordCountMapper.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("\\s+");
for (String str : words) {
word.set(str); // Установить текущее слово
context.write(word, one); // Выходное слово и значение счета (1)
}
}
}- WordCountReducer.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum); // Установить значение результата
context.write(key, result); // Выведите общее количество слов
}
}- WordCount.java (класс драйвера)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: WordCount <input path> <output path>");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Word Count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Сервер отправки пакетов работает
- Загрузить файлы статистики в HDFS
wordcount.txt
hadoop hello hadoop
world
# загрузить
hdfs dfs -mkdir -p /input/wordcount
hdfs dfs -put wordcount.txt /input/wordcount- Запустить расчет программы
hadoop jar xxx/hadoop-wordcount-1.0-SNAPSHOT.jar com.example.WordCount- Посмотреть результаты бега
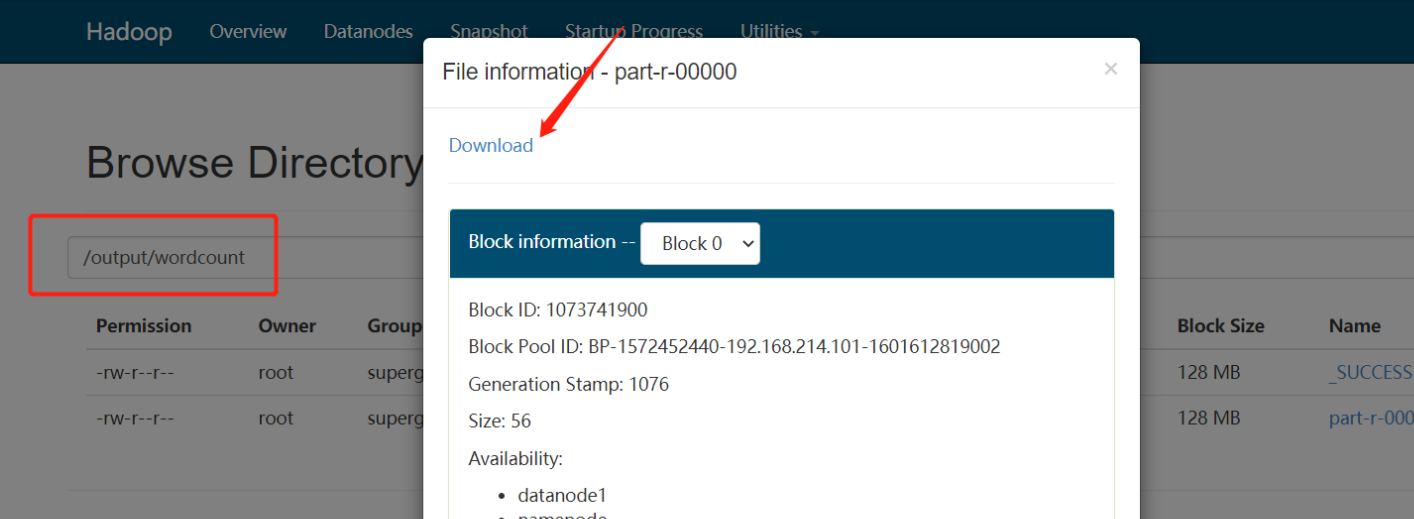
- Просмотр файлов статистики
hadoop 1
hello 2
world 1Профиль
👋 привет, я Lorin Лорейн, один Java Разработчик бэкэнд-технологий!девиз:Technology has the power to make the world a better place.
🚀 Моя страсть к технологиям — это моя мотивация продолжать учиться и делиться ими. Мой блог — это место, посвященное экосистеме Java, серверной разработке и новейшим технологическим тенденциям.
🧠 Будучи энтузиастом серверных технологий Java, я не только с энтузиазмом изучаю новые возможности языка и глубину технологий, но также с энтузиазмом делюсь своими идеями и передовым опытом. Я верю, что обмен знаниями и сотрудничество с сообществом могут помочь нам расти вместе.
💡 В моем блоге вы найдете подробные статьи об основных концепциях Java, базовой технологии JVM, часто используемых платформах, таких как Spring и Mybatis, управлении базами данных, таких как MySQL, промежуточном программном обеспечении для обработки сообщений, таком как RabbitMQ и Rocketmq, оптимизации производительности и т. д. Я также поделюсь некоторыми советами по программированию и методами решения проблем, которые помогут вам лучше освоить программирование на Java.
🌐 Я поощряю взаимодействие и создание сообщества, поэтому, пожалуйста, оставляйте свои вопросы, предложения или запросы по темам и дайте мне знать, что вас интересует. Кроме того, я буду делиться последними новостями Интернета и технологий, чтобы вы всегда были в курсе последних событий в мире технологий. Я с нетерпением жду возможности вместе с вами двигаться вперед по пути технологий и исследовать безграничные возможности мира технологий.
📖 Следите за обновлениями моего блога и давайте вместе стремиться к техническому совершенству.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
