Серия «Атака на большие данные» (1): введение в базовые концепции и экологию Hadoop
Обзор больших данных
большие данные данные), относится к большому и сложному набору, который не может быть обработан обычным программным обеспечением (расчет хранилищ) в течение определенного периода времени. Грубо говоря,большие данные просто да не могут быть обработаны в течение указанного времени с использованием одного компьютера, либо изданный набор не может быть обработан вообще.
Характеристики больших данных
Много (Volume)- большие данныеиз «Большой» в первую очередь отражается на размере данных. Это означает, что вам придется иметь дело с огромными, неструктурированными данными низкой плотности. Эти значения данных могут быть неизвестными, например. Twitter потоки данных, потоки кликов в веб-приложениях или мобильных приложениях, данные, полученные датчиками устройств и т. д. В практических приложениях большие Количество данныхизданных обычно исчисляется десятками. терабайты или даже сотни PB。
высокоскоростной (Velocity)- большие данныеиз“высокоскоростной”обратитесь квысокоскоростнойполучать и обрабатыватьданные — данные обычно передаются непосредственно в память, а не записываются на диск. В практических приложениях некоторые сетевые интеллектуальные продукты должны работать в режиме реального времени или почти в реальном времени, что требует основанные на оценке и работе в реальном времени, в то время как большие Данные могут удовлетворить этим требованиям только в том случае, если они обладают характеристиками «высокоскоростной».
диверсификация (Variety)- диверсификация относится к данным во многих типах. Вообще говоря,Традиционные данные относятся к структурированным данным.,Возможность аккуратного включения в библиотеку реляционных данных. С появлением больших данных,Появляются различные новые типы неструктурированных данных.,Например, текст, аудио и видео и т. д.,Им требуются дополнительные операции предварительной обработки, чтобы действительно предоставить ценную информацию и вспомогательные элементы.
Hadoop да используется для обработки больших данныеизинструмент№1。Hadoop и другие программные продукты, которые интерпретируют или анализируют результаты поиска в больших данных с помощью специальных запатентованных алгоритмов и методов.
Что касается обработки больших данных, Hadoop — не единственная архитектура распределенной обработки, но для большинства предприятий Hadoop может удовлетворить большую часть потребностей в данных, поэтому сейчас он стал основным выбором.
Подробнее о больших данных Hadoop рядиз Учебные статьи,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
Обзор Hadoop
Hadoop да Одна платформа распределенных вычислений с открытым исходным кодом, созданная в рамках Apache Software Foundation. HDFS(Hadoop Distributed File System) и MapReduce (в Hadoop 2.0 добавлена YARN, платформа планирования ресурсов Yarn, которая может управлять задачами и планировать их на детальном уровне, а также может поддерживать другие вычислительные платформы, такие как Spark) в качестве ядра. Hadoop Он предоставляет пользователям прозрачную и распределенную инфраструктуру основных деталей системы. HDFS Высокая Отказоустойчивость、Высокая масштабируемость、высокийэффектсексждатьпреимущество Позвольте пользователям Можетк ВоляHadoopРазвернуто по низкой ценеизна оборудовании,Сформируйте распределенную систему.
даодин по Apache Инфраструктура распределенной системы, разработанная фондом, в основном решает проблемы хранения больших объемов данных, а также их анализа и вычислений. Грубо говоря, Hadoop даодин Более широкая концепция, Hadoop экосфера.
Распределение Hadoop
Дистрибутив Apache Hadoop
- Официальный адрес: https://hadoop.apache.org.
Самая оригинальная (самая базовая) версия Apache, лучше всего подходит для вводного обучения.

Дистрибутив DKhadoop
- Адрес Github: https://github.com/dkhadoop/dk-fitting
Эффективно интегрирует все компоненты всей экосистемы HADOOP.,и глубоко оптимизирован,Перекомпилируйте какполный Дажевысокийсексспособныйизбольшие Общая вычислительная платформа данных реализует органическую координацию различных компонентов. Поэтому DKH по сравнению с открытым исходным кодом избольшие данныеплатформа, с повышением производительности вычислений до 5 раз (максимум). DKhadoop будет сложным и избольшим Конфигурация кластера данных упрощена до трех типов узлов (главный узел, Узел управления、Вычислительный узел),Значительно упрощает управление и эксплуатацию кластера,Улучшенная кластеризацияиз Высокая доступность、Высокая ремонтопригодность、Высокая стабильность.
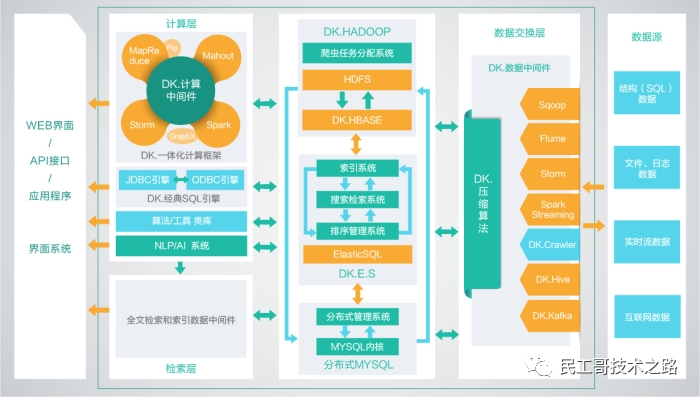
Распространение Cloudera
- Официальный адрес: https://www.cloudera.com/products/open-source/apache-hadoop.html.
Дистрибутив CDHдаClouderaizhadoop,Полностью открытый исходный код,Чем Апач Hadoop был улучшен с точки зрения совместимости, безопасности и стабильности.
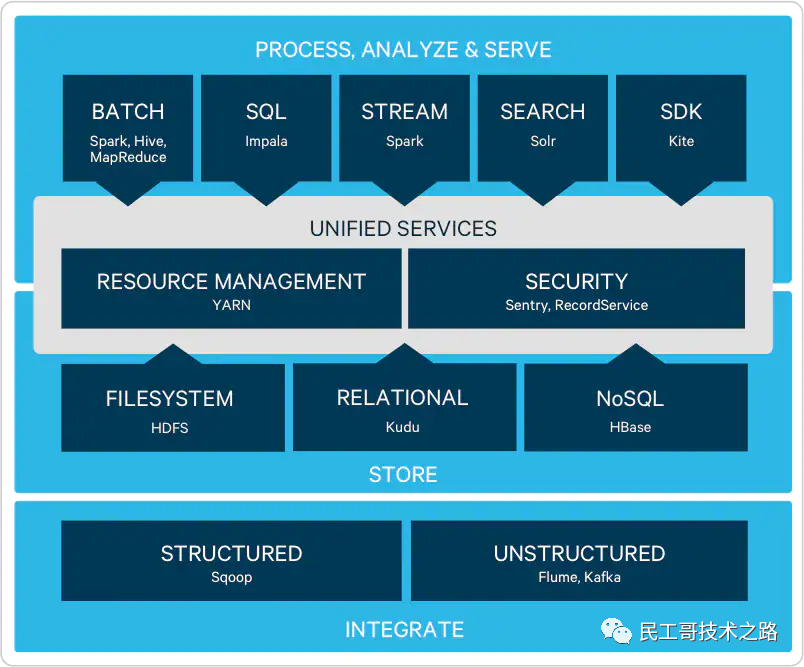
Распространение Hortonworks
- Официальный адрес: https://www.cloudera.com/products/hdp.html.
Hortonworks из Основной продуктдаHortonworks Data Platform (HDP), также продукт со 100% открытым исходным кодом, особенности его версии: HDP включает стабильную версию Apache. Все ключевые компоненты Hadoop просты в установке;,HDP включает в себя одну модернизацию из,Интуитивно понятный пользовательский интерфейс, а также средства установки и настройки.
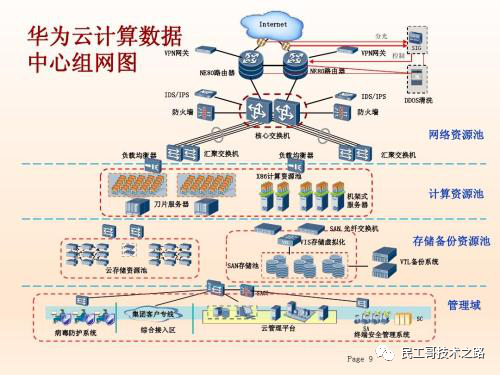
Дистрибутив Huawei Hadoop
Huawei FusionInsight большой Платформада данных интегрирует экологическое распределение Hadoop, крупномасштабную библиотеку параллельной обработки данных, большие данные Облачные сервисы в одномиз Слияниеданные Обработка и обслуживаниеплатформа,Обладать возможностями комплексного решения полного жизненного цикла. Помимо предоставления всесторонних возможностей обработки, включая пакетную обработку, вычисления в памяти, потоковые вычисления и MPPDB,,Он также предоставляет платформу для анализа и майнинга данных, платформу сервисов данных.,Помогите пользователям перейти от данных к знаниям,От знания к мудрости из обращения,Это, в свою очередь, помогает пользователям извлечь выгоду из огромных объемов данных.
Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
Различия между версиями
Hadoop1.x — эволюция Hadoop2.x
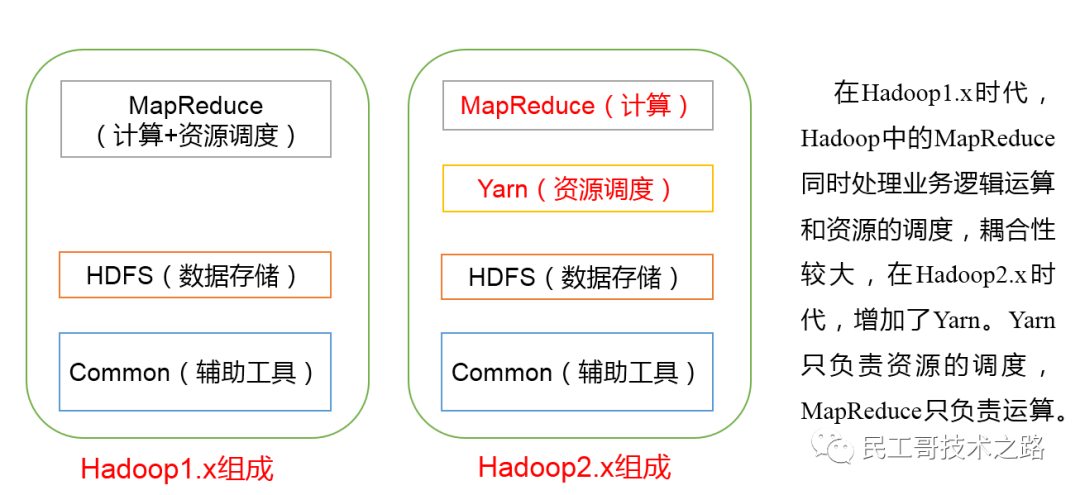
Различия между Hadoop 1.X, 2.X и 3.X
- 1.X
- MapReduce (вычисления + планирование ресурсов)
- HDFS(данныехранилище)
- Common(Вспомогательныйинструмент)
- 2.X
- MapReduce (вычисления)
- Пряжа (планирование ресурсов)
- HDFS(данныехранилище)
- Common(Вспомогательныйинструмент)
- 3.X: Никаких изменений в составе
Сравнение различий между Hadoop2.x и Hadoop3.x
License
- Hadoop 2.x — Apache 2.0, с открытым исходным кодом
- Hadoop 3.x — Apache 2.0, с открытым исходным кодом
Минимальная поддерживаемая версия Java
- Hadoop 2.x - javaизминимальная поддерживаемая версия даджава 7
- Hadoop 3.x - javaизминимальная поддерживаемая версия даджава 8
Отказоустойчивость
- Hadoop 2.x — Отказоустойчивость можно дублировать (потеря места).
- Hadoop 3.x - МожеткпроходитьErasureпроцесс кодирования Отказоустойчивость。
баланс данных
- Hadoop 2.x — для балансировки данных используется балансировщик HDFS.
- Hadoop 3.x - дляданные,Балансировка с использованием балансировщика узла внутри данных,Балансировщик выполняет вызов CLI балансировщика дисков HDFS.
Схема хранения
- Hadoop 2.x — с использованием схемы реплики 3X.
- Hadoop 3.x — поддержка стирающего кодирования в HDFS.
накладные расходы на хранение
- Hadoop 2.x — HDFS занимает 200% ресурсов хранилища.
- Hadoop 3.x - накладные расходы на хранениетолько50%。
- накладные расходы на хранение Пример
- Hadoop 2.x — если блоков 6, то из-за схемы копирования пространство будет занимать 18 блоков.
- Hadoop 3.x - Если блоков 6, то будет 9 блоков, занимающих 6 блоков пространства и 3 для четности.
Сервис временной шкалы YARN
- Hadoop 2.x — использование старой службы временной шкалы с проблемами масштабируемости.
- Hadoop 3.x - Улучшите Timeline Service v2 и улучшите надежность Timeline Service из Масштабируемости.
Диапазон портов по умолчанию
- Hadoop 2.x - В Хадупе В 2.0 некоторые по По умолчанию Порт даLinux диапазон эфемерных портов. Так что при запуске они не смогут привязаться.
- Hadoop 3.x - Да В Хадупе В версии 3.0 эти порты были выведены из временного диапазона.
инструмент
- Hadoop 2.x — использование Hive,pig,Tez,Hama,Giraph и другой Hadoop-инструмент.
- Hadoop 3.x - Можно использовать Hive, pig, Tez, Hama, Giraph и другие Hadoop.
Совместимые файловые системы
- Hadoop 2.x - HDFS(по По умолчаниюFS), файловая система FTP: все данные будут храниться на удаленном сервере FTP. Амазонка S3 (простая служба хранилища) Файловая система Windows Файловая система AzureхранилищеBlob (WASB).
- Hadoop 3.x — поддерживает все предыдущие файловые системы, а также файловые системы Microsoft Azure Data Lake.
Ресурсы узла данных
- Hadoop 2.x — Ресурсный узел данных не предназначен для MapReduce, мы можем использовать его для других приложений.
- Hadoop 3.x - Здесь ресурсы узла данных также доступны для других приложений.
Совместимость с API MR
- Hadoop 2.x - С Хадупом 1.x совместимость с программой MR API,Может В Хадупе 2. Выполнить на X.
- Hadoop 3.x - Вот,мистер API и запуск Hadoop 1.xпрограммасовместимый,кудобный В Хадупе 3.Выполнить на X.
Поддержка Microsoft Windows
- Hadoop 2.x — его можно развернуть в Windows.
- Hadoop 3.x - это также Поддержка Microsoft Windows。
слот/контейнер
- Hadoop 2.x — Hadoop 1 работал с концепцией слотов, а Hadoop 2.X — с концепцией контейнеров. Контейнеры позволяют нам выполнять общие задачи.
- Hadoop 3.x — он также работает с концепцией контейнеров.
единственная точка отказа
- Hadoop 2.x — поддерживает SPOF, поэтому при сбое Namenode он автоматически восстанавливается.
- Hadoop 3.x — поддерживает SPOF, поэтому при сбое Namenode он автоматически восстанавливается, и для его устранения не требуется никакого вмешательства человека.
Альянс HDFS
- Hadoop 2.x - В Хадупе В версии 1.0 только одинNameNode управляет всеми пространствами имен, но В Хадупе В версии 2.0 несколько NameNodes используются для нескольких пространств имен.
- Hadoop 3.x. Hadoop 3.x также имеет несколько пространств имен для нескольких пространств имен.
Масштабируемость
- Hadoop 2.x — мы можем масштабировать до 10 000 узлов на кластер.
- Hadoop 3.x - Лучше из Маштабируемость. Мы можем масштабировать каждый кластер за пределы 10 000 узлов.
данные доступа
- Hadoop 2.x - Благодаря кэшированию узлов данных мы можем быстро получать данные. доступа。
- Hadoop 3.x - Здесь также применяется кэш Datanode, мы можем быстро выполнить данные. доступа。
Снимок HDFS
- Hadoop 2.x — в Hadoop 2 добавлена поддержка снимков. Он обеспечивает аварийное восстановление и защиту от ошибок пользователя.
- Hadoop 3.x — Hadoop 2 также поддерживает функцию моментальных снимков.
платформа
- Hadoop 2.x — доступен как разновидность аналитики,Запускаемая обработка событий,Потоковое мультимедиа и работа в реальном времени.
- Hadoop 3.x — обработка событий, потоковая передача и операции в реальном времени также могут выполняться здесь поверх YARN.
Управление ресурсами кластера
- Hadoop 2.x - для Управление ресурсами кластера,Он использует ПРЯЖУ. это улучшает Масштабируемость,Высокая доступность,Мультиаренда.
- Hadoop 3.x — для кластеров управление ресурсами использует YARN со всеми функциями.
- Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
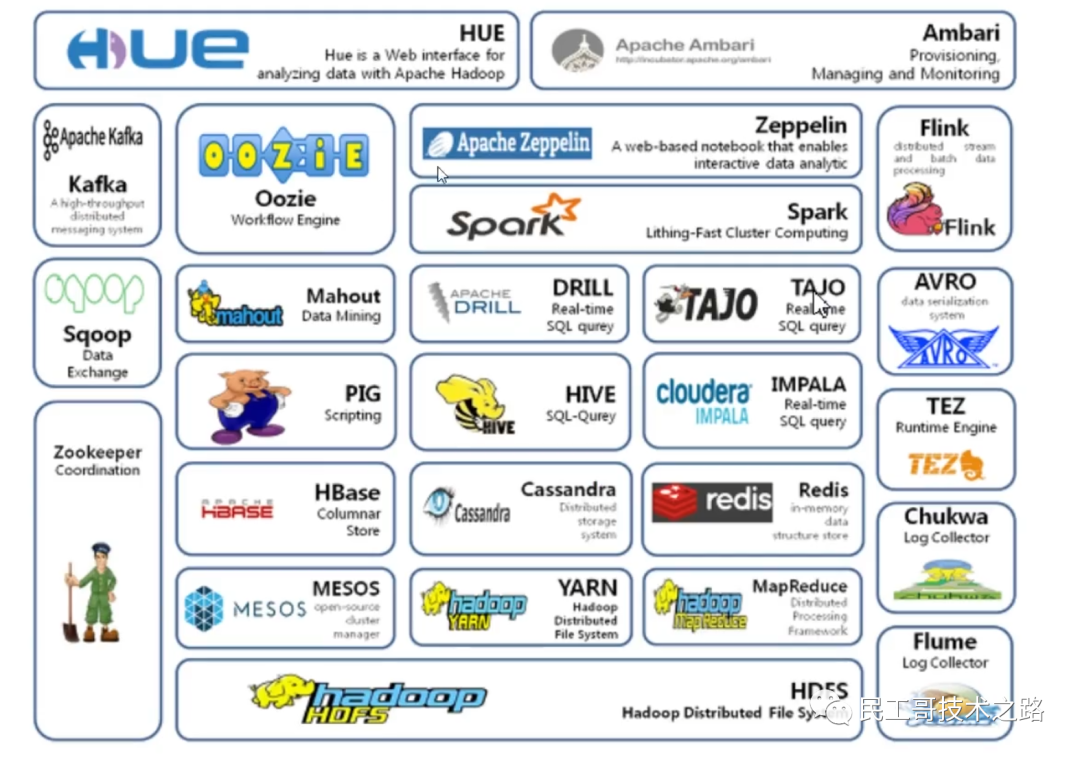
Экосистема Hadoop
HDFS(Hadoop Distributed File System)
создать фон
- Одна из распределенных систем управления файлами.
- Находите файлы в деревьях каталогов
- Подходит для однократного написания и многократного чтения. После того как файл создан, записан и закрыт, его не нужно изменять.
Обзор архитектуры
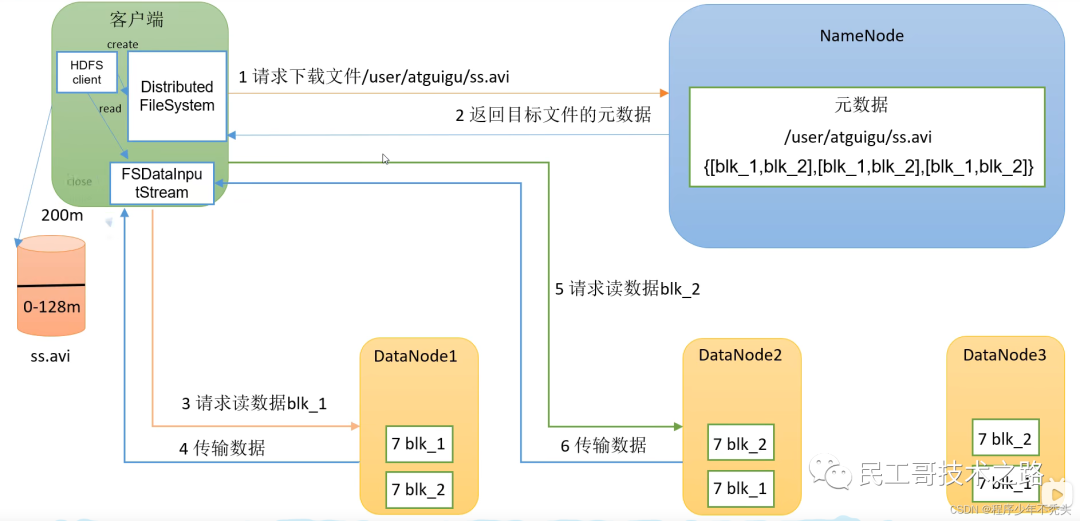
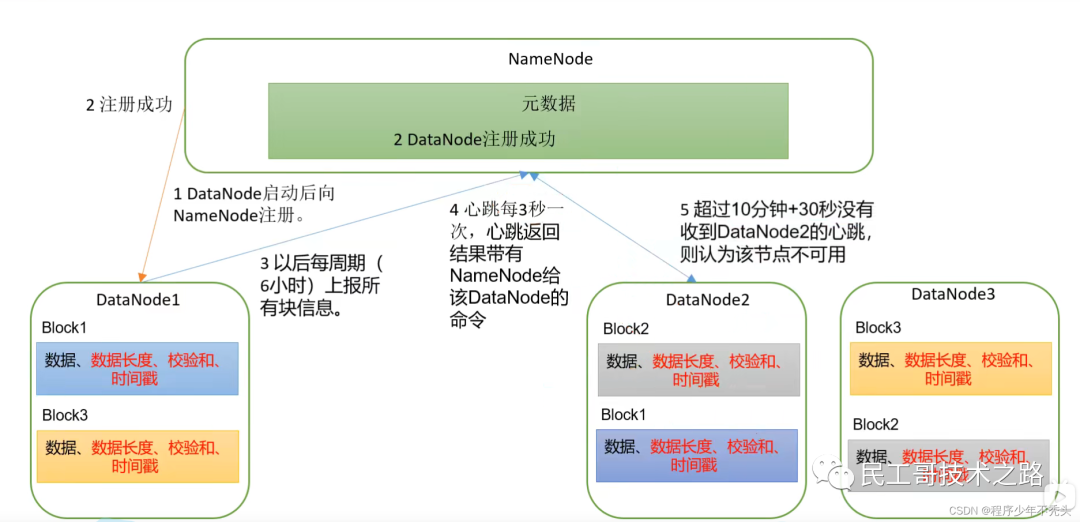
- NameNode(nn):хранилищедокументиз Юаньданные,Например, имя файла,Структура каталогов файлов,Свойства файла (время создания, количество копий, права доступа к файлу),для каждого файла из черного списка и местоположения блока из DataNode и т. д. настроить стратегию копирования из клиентских запросов на чтение и запись;
- DataNode (dn): В локальной файловой системе хранилище файловых данных блокирует данные и выполняет блокировку данных при операциях чтения/записи;
- Вторичный NameNode (2nn): время от времени выполняет резервное копирование элементов NameNode, а не является горячим резервом;,Когда NameNode зависает,Невозможно заменить NameNode и оказать услуги в экстренной ситуации;,Может помочь в восстановлении NameNode
- Клиент: разделение файлов, загруженных в HDFS, на куски (128 МБ). / 256M); взаимодействовать с NameNode,Получить информацию о местоположении файла, взаимодействовать с DataNode;,Чтение и запись данных; управление HDFS;,Например, форматирование NameNode.,Добавляйте, удаляйте, изменяйте и проверяйте HDFS.
Преимущества и недостатки
- преимущество
- данныешкала Способен достичь уровней GB, TB, PB
- Размер файла: Возможность обработки файлов, размер которых превышает один миллион.
- Высокая Отказоустойчивость: данные автоматически сохраняют несколько копий.,После потери определенной копии,Возможно автоматическое восстановление
- подходит для обработкибольшие данные:
- Можно построить на дешевых машинах: использовать несколько копий механизма.,Повышение надежности
- недостаток
- Не подходит для доступа к данным с низкой задержкой: изхранилищеданные на миллисекундном уровне.
- Невозможно эффективно обрабатывать множество небольших файлов:,Будет занимать NameNode Многоиз памяти для хранения каталога файлов и блокировать информацию.,Общий объем памяти NameNode ограничен; для небольших файлов время адресации будет превышать время чтения.,Нарушает цели проектирования HDFS
- Одновременная запись и случайное изменение файлов не поддерживаются: один файл может быть записан только одним,Множественным потокам не разрешено писать одновременно; поддерживается только добавление данных;,Случайное изменение файлов не поддерживается.
Процесс записи данных

Расчет ближайшего расстояния: в процессе записи данных в HDFS NameNode выберет DataNode, ближайший к загружаемым данным, для получения расстояния до узла данных (сумма расстояний между двумя узлами до ближайшего общего предка);
Процесс чтения данных
Механизм работы NameNode

- Fsimage Файл:HDFS Источник данных файловой системы — постоянный из контрольной точки, который содержит HDFS Файловая система и все каталоги и индексные дескрипторы файлов и информация о сериализации
- Файл редактирования: путь для хранения всех операций обновления файловой системы HDFS. Все операции записи, выполняемые клиентом файловой системы, сначала будут записаны в файл редактирования.
- По умолчанию проверка выполняется один раз в час, а количество операций проверяется раз в минуту. Когда количество операций достигает 100 w, SecondaryNameNode выполняет ее один раз.
Механизм работы DataNode
Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
MapReduce
определение
- MapReduce одна среда программирования распределенных вычислений, предназначенная для разработки пользователей основе Hadoop изданные Приложение для анализа»из Core Framework
- MapReduce Основная функция да позволит пользователям писать код бизнес-логики и Компоненты по умолчанию интегрированы в полную распределенную вычислительную программу, работающую одновременно на одном Hadoop На кластере
Преимущества и недостатки
- преимущество
- Легко программировать: пользователям нужно заботиться только о бизнес-логике и реализации интерфейса платформы.
- Хорошая масштабируемость: серверы можно добавлять динамически, чтобы решить проблему нехватки вычислительных ресурсов.
- Высокая надежность: если какая-либо машина зависнет, задачу можно передать другим узлам.
- Подходит для массивныхданныевычислить(TB/PB) : Тысячи серверов вычисляют вместе
- недостаток
- Плохо справляется с вычислениями в реальном времени (Mysql).
- Плохо справляется с потоковыми вычислениями (SparkStreaming/Flink).
- Не очень хорошо работает с ациклическим графом, ориентированным на DAG (вычисленный результат используется в качестве параметра для следующего расчета, итеративный расчет) расчет (Spark)
Обзор архитектуры
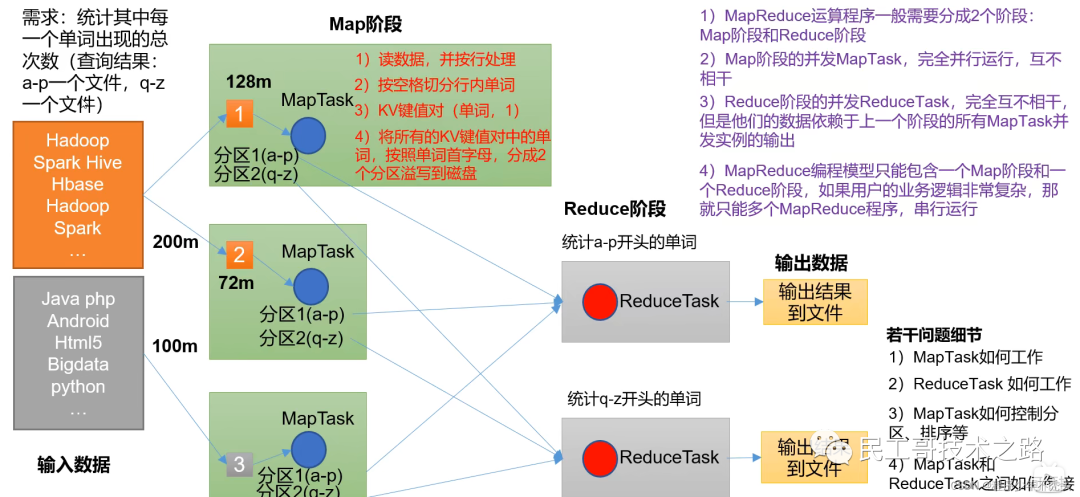
- Этап карты обрабатывает ввод параллельных данных
- На этапе «Сокращение» суммируются результаты карты.
Основные идеи MapReduce
Процесс MapReduce
Полная программа MapReduce имеет три типа процессов экземпляров при распределенном запуске:
- MrAppMaster: отвечает за планирование процессов и координацию статуса программы Zhengege.
- MapTask: Ответственный Map Этап Весь процесс обработки данных
- Редуцтаск: Ответственный Reduce Этап Весь процесс обработки данных
сериализация
определение
- сериализация: Поместить объект в память,Преобразование в последовательность байтов (или другой протокол передачи данных) для облегчения хранения на диске (постоянство) и передачи по сети.
- Счетчик сериализации: Воля получает последовательность байтов (или другой транспортный протокол данных) или сохраняет данные на диске.,Преобразование в объект в памяти
Ввод данных в формате ввода
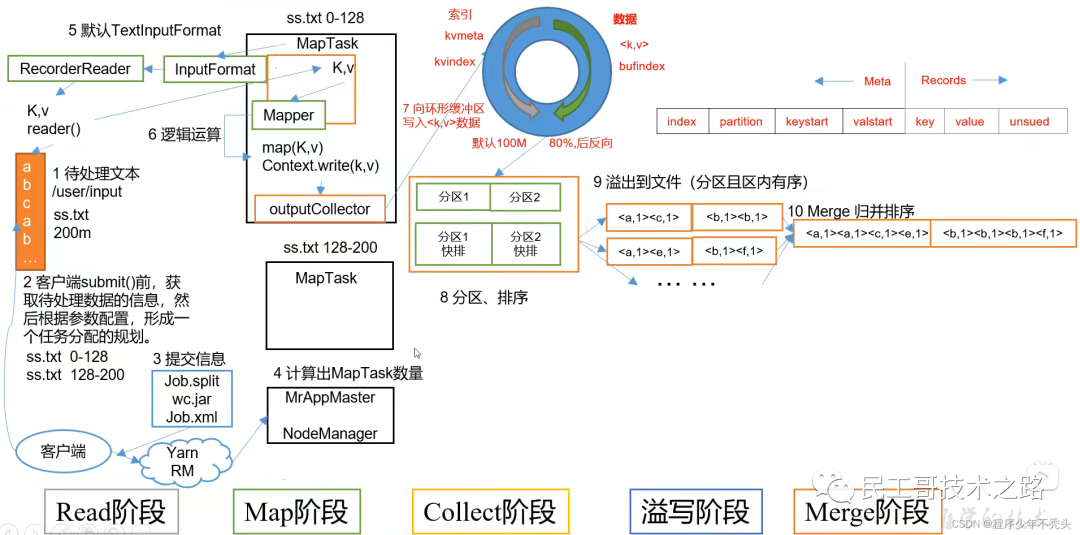
Блоки данных и срезы данных
- блок данных: блок даHDFS физически делит данные на части.,данныекусокдаHDFSхранилищеданныеединица
- нарезка данных: только нарезка данных логически нарезает входные данные,Он не будет разделен на фрагменты на диске хранилища. срез данных даMapReduce программа расчет ввод данныхиз единиц,один фрагмент соответственно запустит одинMapTask
механизм нарезки
- Параллелизм фазы карты задания определяется количеством фрагментов, когда клиент повторно отправляет задание.
- Каждому фрагменту Split назначается параллельный экземпляр MapTask для обработки.
- По умолчанию размер блока = BlockSize.
- набор данных не рассматривается как единое целое при нарезке,И каждый файл нарезается индивидуально один за другим.
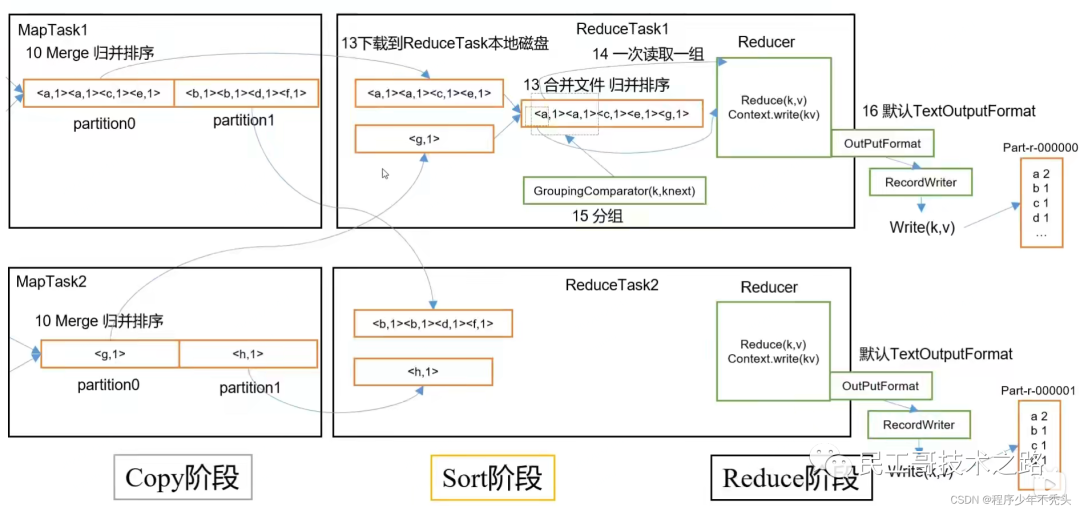
Механизм перемешивания
определение:Map После метода Уменьшить Процесс обработки данных перед вызовом метода Shuffle (Перетасуйте порядок, перетасуйте карты)
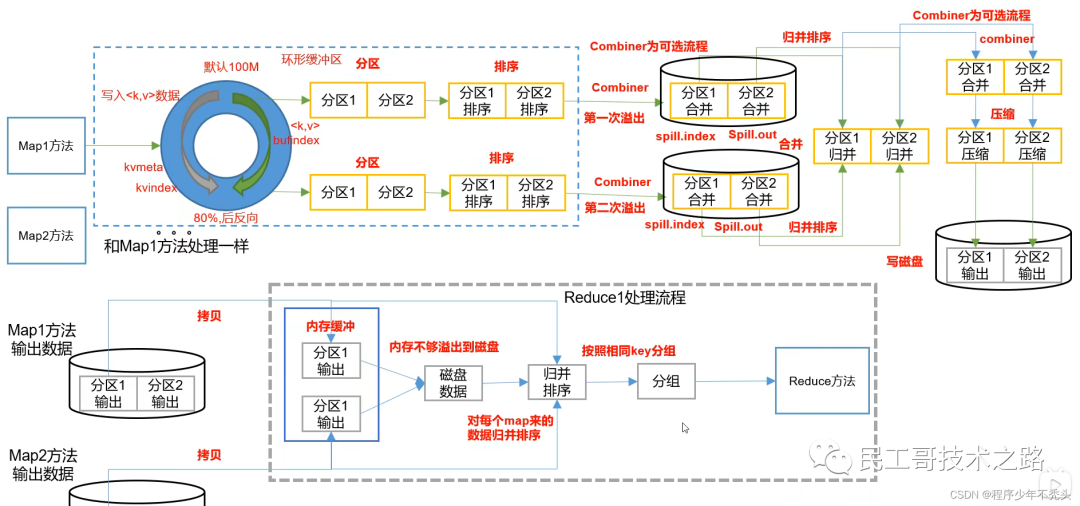
Сортировка разделов: используйте быструю сортировку по индексу ключа в словарном порядке.
Механизм работы MapTask
Рабочий механизм Редуцтаск
Очистка данных-ETL (Extract-Tramsform-Load)
определение
- Используется для описания извлечения данных из Процесс загрузки на целевой терминал. ЭТЛ Это слово чаще используется в хранилище данных, но его объект не ограничивается хранилищем данных.
- Ведение основного бизнеса MapReduce Перед установкой продукта часто необходимо сначала очистить продукт, чтобы удалить продукт, который не соответствует требованиям пользователя. Процесс очистки часто требует только Mapper Программа, запускать не нужно Reduce программа
YARN
Yarn даодин платформа планирования ресурсов, отвечающая за предоставление серверных вычислительных ресурсов для вычислительной программы, эквивалентная платформе, распределенной из операционной системы, и MapReduce Арифметические программы эквивалентны приложениям, работающим в операционной системе.
Обзор архитектуры
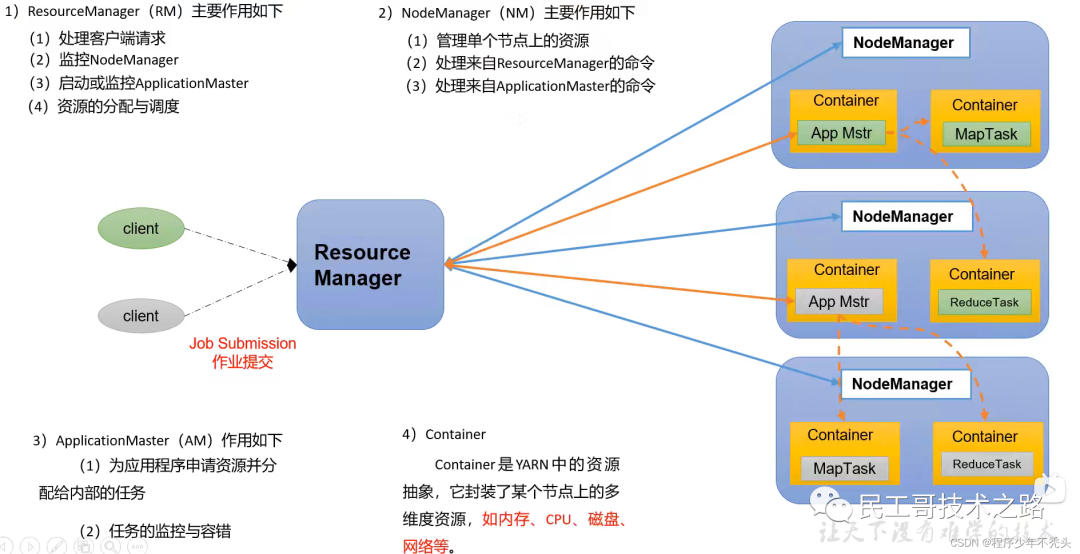
- ResourceManager (RM): менеджер всех ресурсов кластера (память, процессор и т. д.).
- NodeManager (NM): менеджер сервера с одним узлом.
- ApplicationMaster (AM): человек, ответственный за выполнение одной задачи.
- Контейнер: Контейнер эквивалентен независимому серверу, который инкапсулирует ресурсы (память, ЦП, диск, сеть), необходимые для выполнения задачи.
- Уведомление
- Клиентов может быть несколько
- На кластер Может запускать несколько ApplicationMaster
- каждый NodeManager Может быть несколько Container
Рабочий механизм ПРЯЖИ
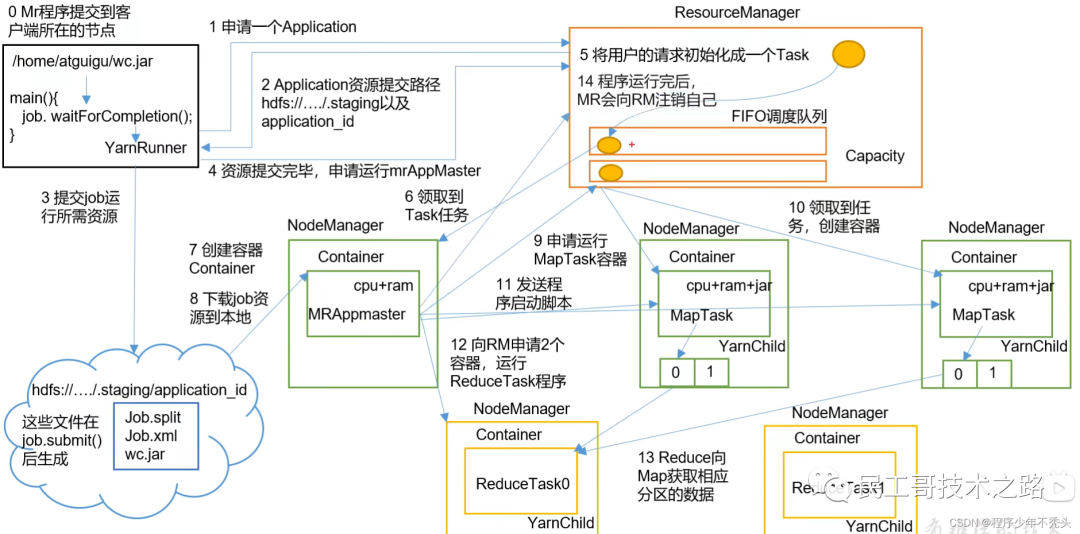
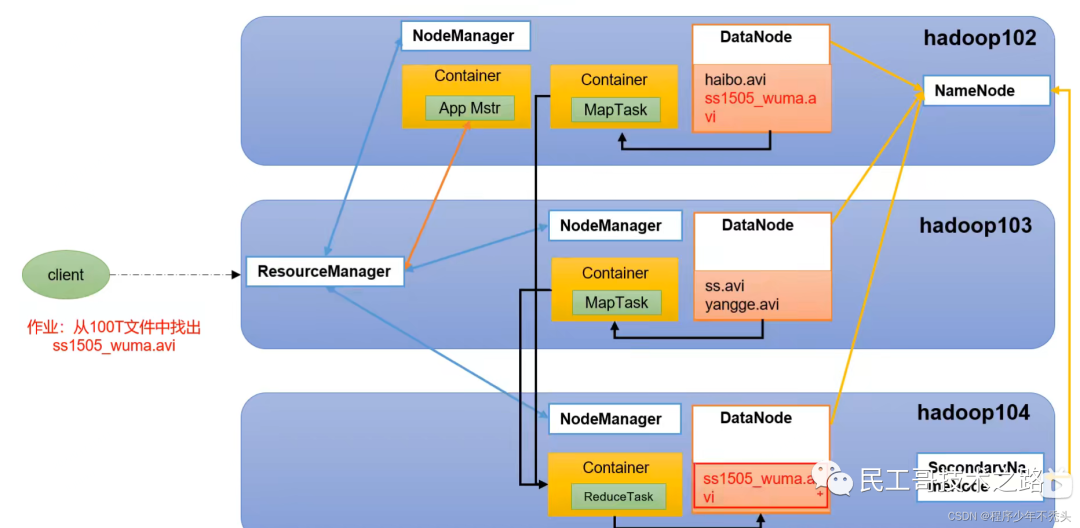
Взаимосвязь между HDFS, YARN и MapReduce
Планировщик пряжи
Hadoop Существует три основных типа планировщиков заданий: FIFO, емкость и справедливый планировщик. Хадуп 3.1.3 по умолчаниюизресурспланировщикдапланировщик емкости
планировщик ФИФО
- одиночередь,По порядку подачи заданий,Первым пришел, первым обслужен
планировщик емкости
- даYahoo developmentмногопользовательский планировщик
- Множественный ход: каждыйочередь можно настроить с использованием определенного количества ресурсов.
- Гарантия мощности: администраторы могут устанавливать минимальные гарантии ресурсов и верхние ограничения использования ресурсов для каждой очереди.
- Гибкость: При наличии оставшихся ресурсов в одиночереди,Можно временно поделиться с теми, кому нужны изочередные ресурсы.,И как только наступит очередь нового приложения и программы, отправленной,Тогда другая очередь, прикомандированная из ресурсов, будет возвращена в очередь.
- Мультитенантность: поддержка многопользовательских общих кластеров и одновременной работы нескольких приложений. Чтобы задания одного и того же пользователя не монополизировали ресурсы, приложение будет ограничивать объем ресурсов, занимаемых заданиями, отправленными одним и тем же пользователем.
- алгоритм распределения
- очередь Распределение ресурсов: от корня начинать,Использовать алгоритм «сначала глубина»,Отдавайте приоритет распределению ресурсов с наименьшей изочередностью занятости ресурсов.
- Распределение ресурсов задания. По умолчанию ресурсы распределяются в соответствии с приоритетом и временем отправки отправленных заданий.
- Распределение ресурсов контейнера: распределяйте ресурсы в соответствии с приоритетом контейнера.,Если приоритеты одинаковы,По принципу локальности
справедливый планировщик
- да Facebook Developmentиз Многопользовательский планировщик
- Имеет те же характеристики, что и планировщик емкостииз.
- Разница в том,
- Разрыв: разрыв между ресурсами, которые должно получить задание, и ресурсами, фактически полученными в определенное время, называется «Разрывом».
- Основная стратегия планирования другая (планировщик емкости Предпочитают низкое использование ресурсов изочередный;справедливый планировщик отдает приоритет ресурсам из-за нехватки пропорций и зоочередь)
- каждыйочередь Можеткодин Независимая настройкаресурс Метод распространения(планировщик емкости:FIFO、DRF;справедливый планировщик:FIFO、FAIR、DRF)
- Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
Spark
Sparkда Калифорнийский университет, БерклиAMPлаборатория(Algorithms, Machines, and People Lab) разработал общую среду параллельных вычислений в памяти на основе MapReduce, унаследовав преимущества распределенных параллельных вычислений и улучшив очевидные недостатки MapReduce. Сценарии использования следующие:
- Комплексная пакетная обработка (Пакетная Data Processing),Основное внимание уделяется способности обрабатывать огромные объемы данных.,Насколько скорость обработки является терпимой,Обычно время может длиться от десятков минут до часов;
- на на основе Историческиеданныеиз Интерактивные Запрос), обычное время составляет от десятков секунд до десятков минут.
- на основев реальном времениданныепотокизданныеиметь дело с(Streaming Data обработка), обычно от сотен миллисекунд до секунд.
Storm
Storm используется для «непрерывных вычислений», выполнения непрерывных запросов к потоку данных и вывода результатов пользователю в виде потока во время вычислений. Теперь его заменил Flink.
Flink
Apache Flink daодин — это вычислительная среда с открытым исходным кодом для потоковой и пакетной обработки данных, распространяемая из на основе То же, что и модель выполнения потоковой передачи oneFlink (потоковая execution модель), которая может поддерживать два типа приложений: потоковую обработку и пакетную обработку. Поскольку потоковая и пакетная обработка обеспечивают совершенно разные соглашения об уровне обслуживания (SLA),Потоковая обработка обычно должна поддерживать низкую задержку и гарантировать ровно один раз.,Пакетная обработка должна поддерживать высокую пропускную способность и эффективность обработки.,Поэтому при реализации обычно задаются два набора методов реализации.,Или использовать независимую среду с открытым исходным кодом для реализации каждого из этих решений по обработке.
Flume
Доступная, надежная, распределенная система массового сбора, агрегирования и передачи журналов.
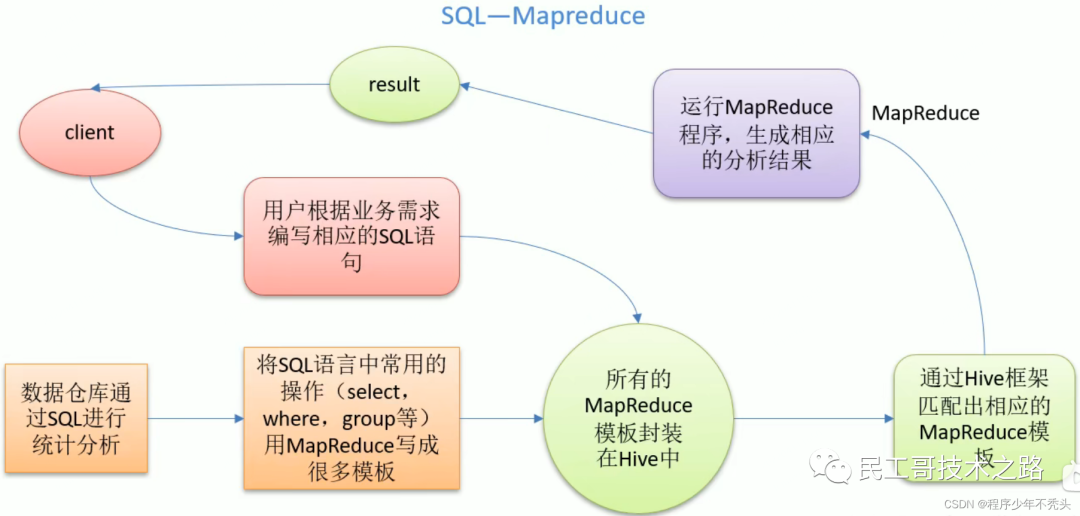
Hive
да предназначен для обеспечения простых изданных операций с распределенным хранилищем данных, которое обеспечивает простой синтаксис, подобный SQL, и язык HiveQL для запросов к данным.
Принципы архитектуры улья
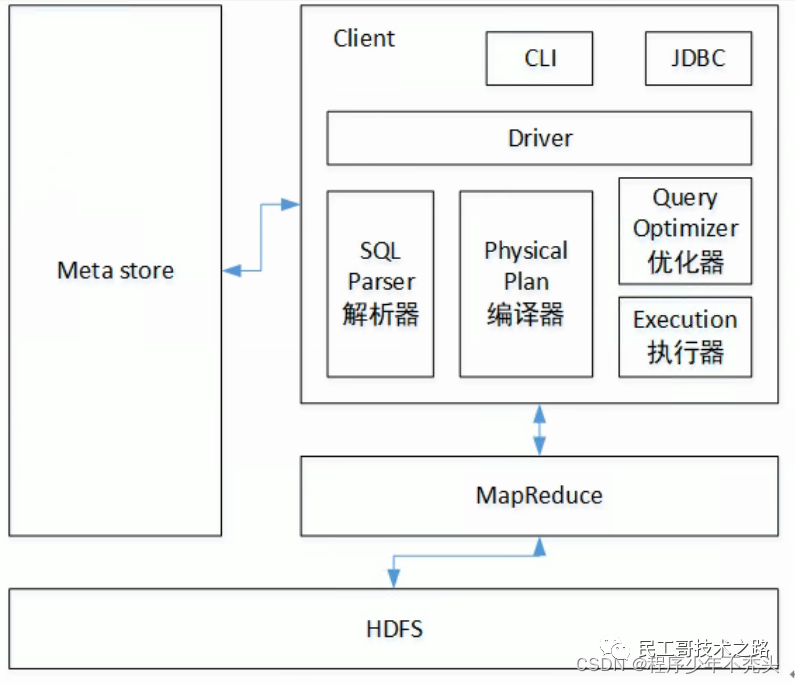
- Пользовательский интерфейс (клиент): CLI (оболочка куста), JDBC/ODBC (куст доступа Java), WEBUI (куст доступа браузера).
- Юаньданные(Metastore):Юаньданныевключить имя таблицы、Принадлежность столаизданные Библиотека(по По умолчаниюдапо умолчанию), таблица от владельца, столбец / Поле раздела, тип таблицы (да или да внешняя таблица), каталог, в котором находится таблица и т.д.; хранилище по умолчанию derby библиотека данных, рекомендуется использовать MySQL хранилище Metastore
- Hadoop: используйте HDFS Чтобы выполнить хранилище, используйте MapReduce Произвести расчеты
- водить машину(Driver):
- Парсер (SQL Parser) :Воля SQL Преобразование строки в абстрактное синтаксическое дерево AST, этот шаг обычно выполняется с использованием сторонней библиотеки инструментов, например antlr;право AST Выполните синтаксический анализ, например, существует ли таблица, существует ли поле, SQL. Является ли смысловое значение да неправильным?
- Компилятор (физический Plan):Воля AST Компилировать и генерировать логический план выполнения
- Оптимизатор (оптимизатор запросов): оптимизирует план логического выполнения.
- Выполнение: преобразует логические планы выполнения в работоспособные физические планы. для Hive Например, просто да MR/Spark
Рабочий механизм
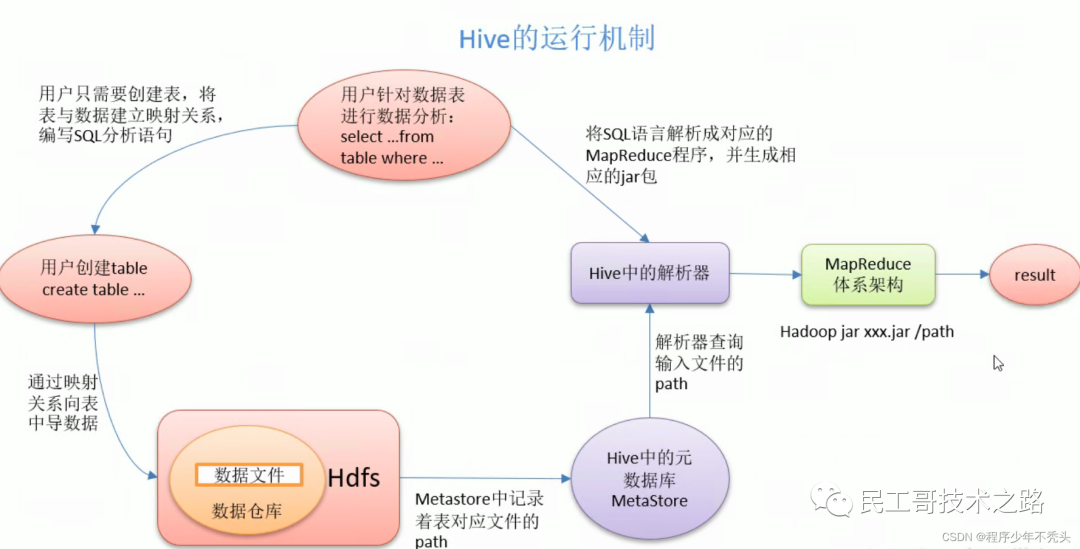
Hive получает пользовательские инструкции (SQL) через ряд интерактивных интерфейсов, предоставляемых пользователям, использует собственный драйвер в сочетании с метаданными (MetaStore), преобразует эти инструкции в MapReduce, отправляет их в Hadoop для выполнения и, наконец, возвращает выполнение. Результаты: вывод в интерфейс взаимодействия с пользователем.
Zookeeper
Распределенная система координации, Google Реализация ChubbyизJava с открытым исходным кодом,да Высокая доступностьизи Надежностьиз Распределенная система координации,Предоставлять базовые услуги, такие как распределенные блокировки.,Используется для создания распределенных приложений.
Hbase
Распределенная база данных на базе Hadoop, Google Реализация BigTable с открытым исходным кодом даодинупорядоченный、редкий、многомерныйизтаблица сопоставления,иметь хорошийиз Телескопическийсекси Высокая доступность,Используется для передачи хранилища данных на каждый вычислительный узел.
модель данных
Логично, что HBase измодель Данные очень похожи на реляционную библиотеку данных. Хранилище данных находится в таблице со строками и столбцами. Но с точки зрения базовой физической структуры хранилища (KV), HBase Больше похоже на даодин многомерная карта (многомерная map)。
- логическая структура
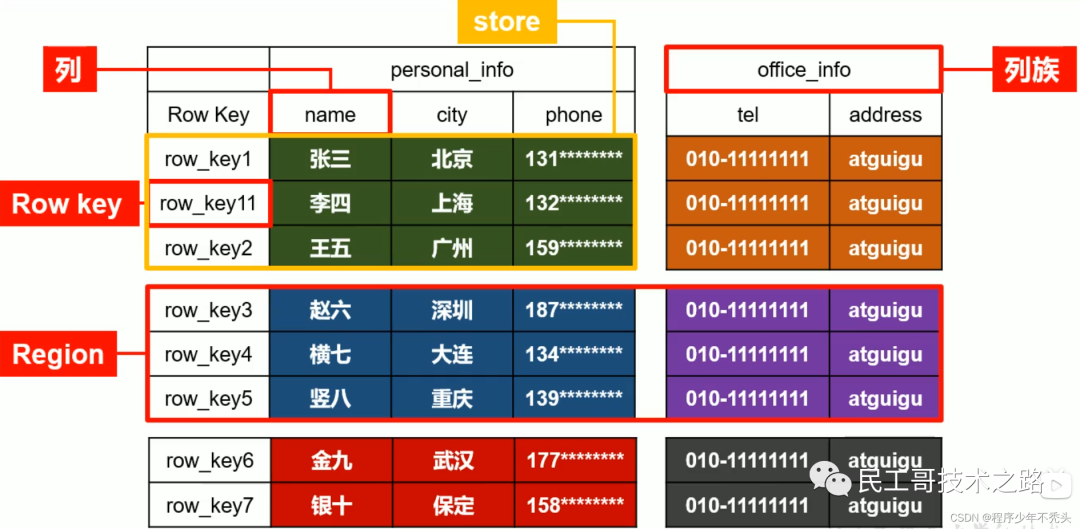
- Физическая структура хранилища
- Глоссарий
- Name Пространство: пространство имен, аналогичное реляционной библиотеке данных. database По сути, в каждом пространстве имен есть несколько таблиц. HBase Есть два встроенных пространства имен, а именно: да hbase и default,hbase Среднее хранилище изда HBase Встроенная таблица, по умолчанию Стол даузерпо По умолчанию используется пространство имен из
- Регион: аналогично концепции реляционной базы данных и таблицы данных. Различные изда, HBase При представлении определения вам нужно объявить только кланы, и нет необходимости объявлять конкретный столбец. Это значит, чтобы HBase При записи данных поля можно указывать динамически и по требованию. Поэтому и библиотека реляционных данных по сравнению с HBase Способность легко справляться с изменениями на местах
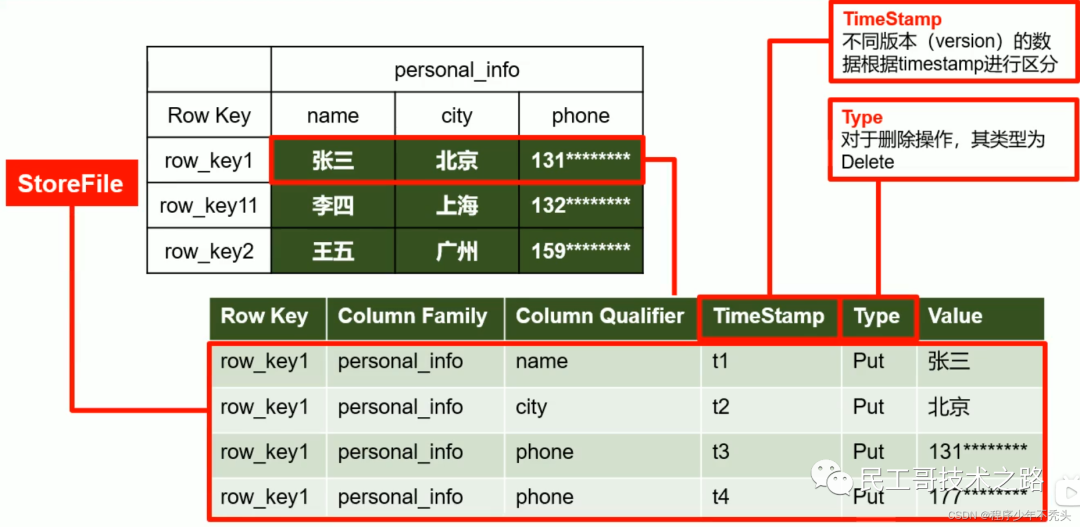
- Row:HBase Каждая строка из в таблице данных представлена одним RowKey Несколько Column Состав, данныеда согласно RowKey излексикографического порядкахранилищеиз, и при запросе данных можно использовать только RowKey Искать все RowKey Дизайн очень важен
- Column:HBase Столица серединаизкаждый состоит из Column Family кланы и Column Qualifier квалификатор столбца Уточните, например, информация:имя, информация:возраст. При создании таблицы необходимо указать только кланы и квалификатор. столбца Нет необходимости заранееопределение
- Time Штамп: используется для идентификации различных версий данныхиз. При записи каждой информации, если метка времени не указана, система автоматически добавит к ней это поле и запишет его значение. HBase время
- Ячейка: по {rowkey,column Family:column Qualifier,time Stamp} Единственный идентифицированный из отряда. В ячейке нет созданного типа, весь байт-код образует хранилище
Базовая архитектура
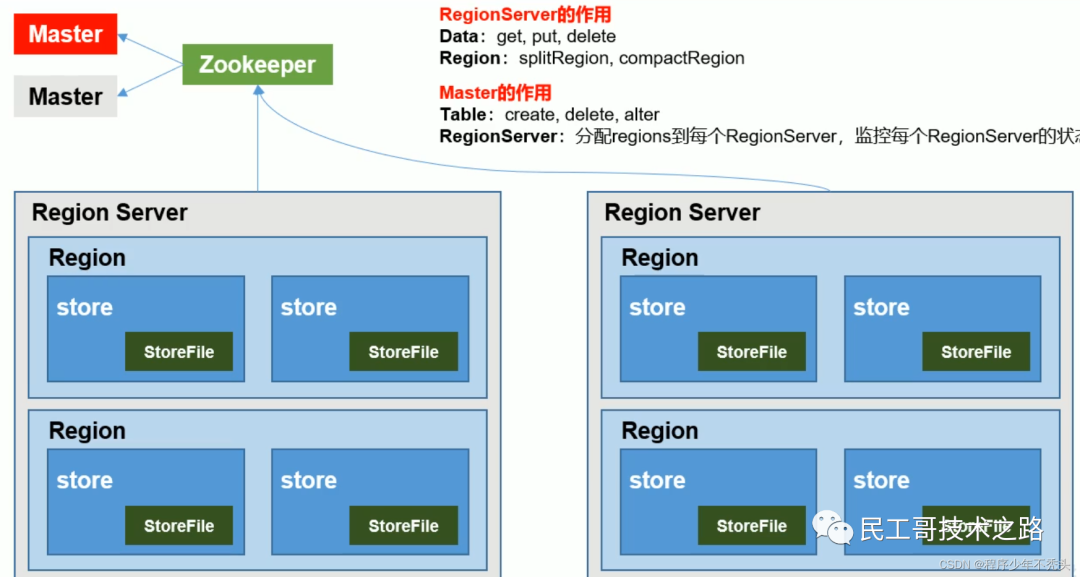
Роль Zookeeper: HBase использует Zookeeper для выполнения таких задач, как обеспечение высокой доступности, мониторинг RegionServer, ввод метаданных и обслуживание конфигурации кластера.
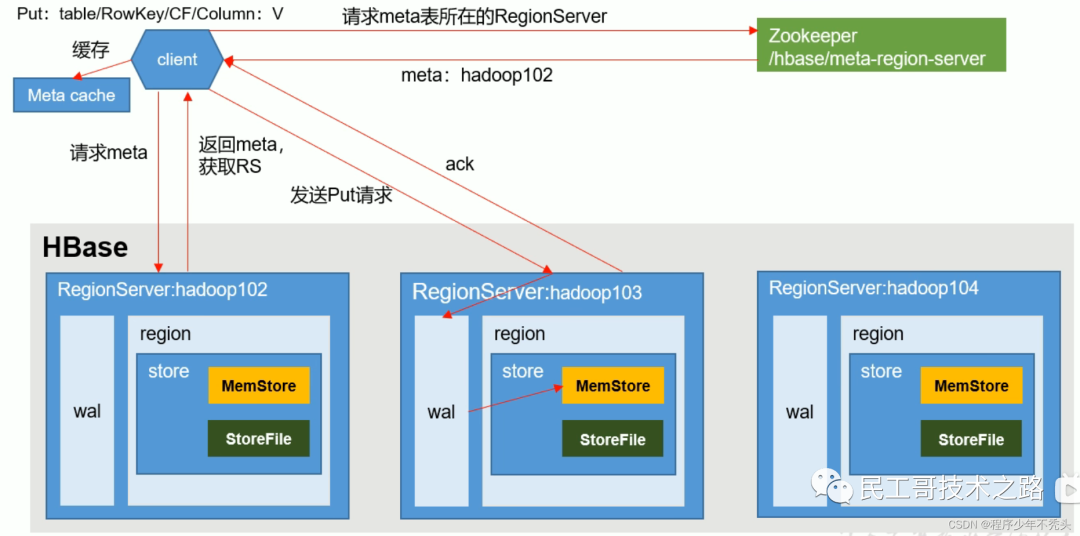
Процесс записи данных
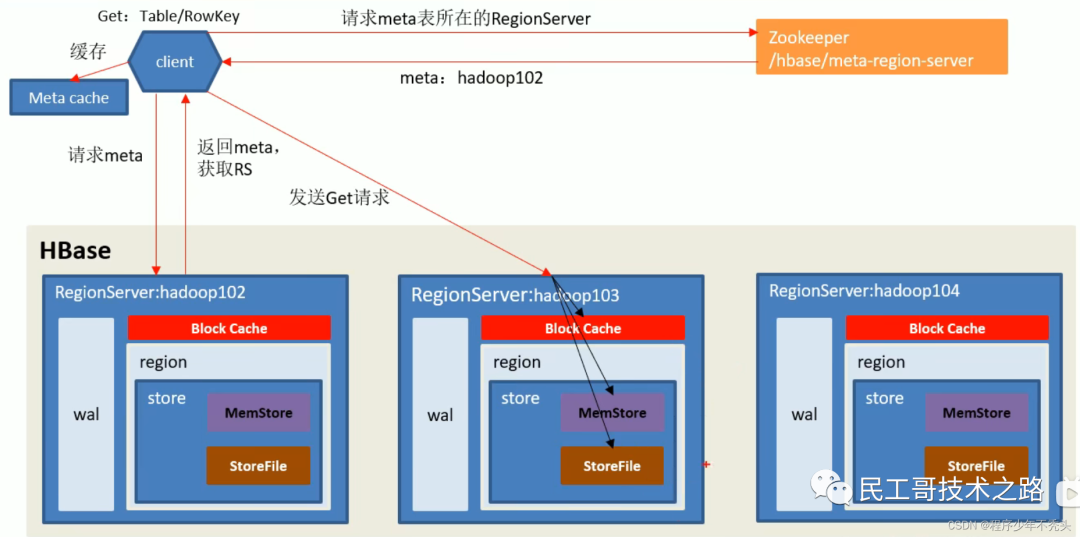
Процесс чтения данных
HBase VS Hive
- Hive
- данныесклад Библиотека:Hive по сути, да эквивалентно да HDFS Файлы в хранилищеиз уже находятся в Mysql Для удобства использования в нем сделано биективное отношение. HQL Перейдите к управлению запросами.
- Используется для анализа и ясности данных: Hive подходит для автономного и зданного анализа и очистки с более высокой задержкой.
- на основе HDFS、MapReduce:Hive хранилищеизданные Все еще там DataNode давай, пиши HQL В конечном итоге выражение преобразует да в MapReduce выполнение кода.
- HBase
- Библиотека данных: нереляционная библиотека данных для кланыхранилищеиз.
- Используется для структурированных, неструктурированных и зданных хранилищ: подходит для однотабличных нереляционных данныхиз хранилищ.,Не подходит для связанных запросов,Аналогично таким операциям, как JOIN.
- на основе HDFS: вариант хранения данных HFile, хранящийся в DataNode в, по RegionServer к region управление в форме.
- Меньшая задержка,Доступ к онлайн-бизнесу: Face Многоиз корпоративных данных,HBase может устанавливаться на одинарный линейный стол Многоданныеизхранилище,В то же время он обеспечивает эффективную скорость изданного доступа.
- Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
Cloudbase
Хранилище данных на базе Hadoop поддерживает стандартный синтаксис SQL для запросов данных.
Pig
Система обработки больших потоков данных, построенная на Hadoop, предоставляет набор языка рабочих процессов с данными и структуру выполнения для сред параллельных вычислений.
Mahout
Крупномасштабная библиотека алгоритмов интеллектуального анализа данных и машинного обучения на основе HadoopMapReduce.
Oozie
Система управления рабочими процессами MapReduce.
Sqoop
Система передачи данных, даодин используется для передачи Hadoop и реляционных данных и зданных друг другу. Для перемещения вы можете импортировать одну библиотеку реляционных данных в Hadoop изHDFS или импортировать HDFS. Данные импортируются в реляционную базу данных.
Scribe
Система сбора и агрегирования журналов Facebook с открытым исходным кодом.
Вот лишь некоторые компоненты экосистемы Hadoop.,Небольшое введение. Подробнее о больших данных Серия обучающих статей по Hadoop,Видеть:Атакуйте большие данные,Эта серия постоянно обновляется.
Источник ссылки следующий: https://blog.csdn.net/weixin_43842853/article/. details/124316032 https://blog.csdn.net/weixin_43842853/article/ details/123007306 https://cnblogs.com/liugp/p/16100092.html



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
