Секреты основных принципов Кафки скрыты в этих 19 картинках!
Использование Kafka может отделить систему, сократить пики трафика, буферизовать и обеспечить асинхронную связь между системами. Kafka идеально подходит для использования в таких сценариях, как отслеживание активности, обмен сообщениями, метрики, ведение журналов и потоковая передача. В этой статье в основном представлены основные понятия Kafka.

Общая структура Кафки
На рисунке ниже показано много подробностей о Кафке, поэтому пока не обращайте на это внимания:
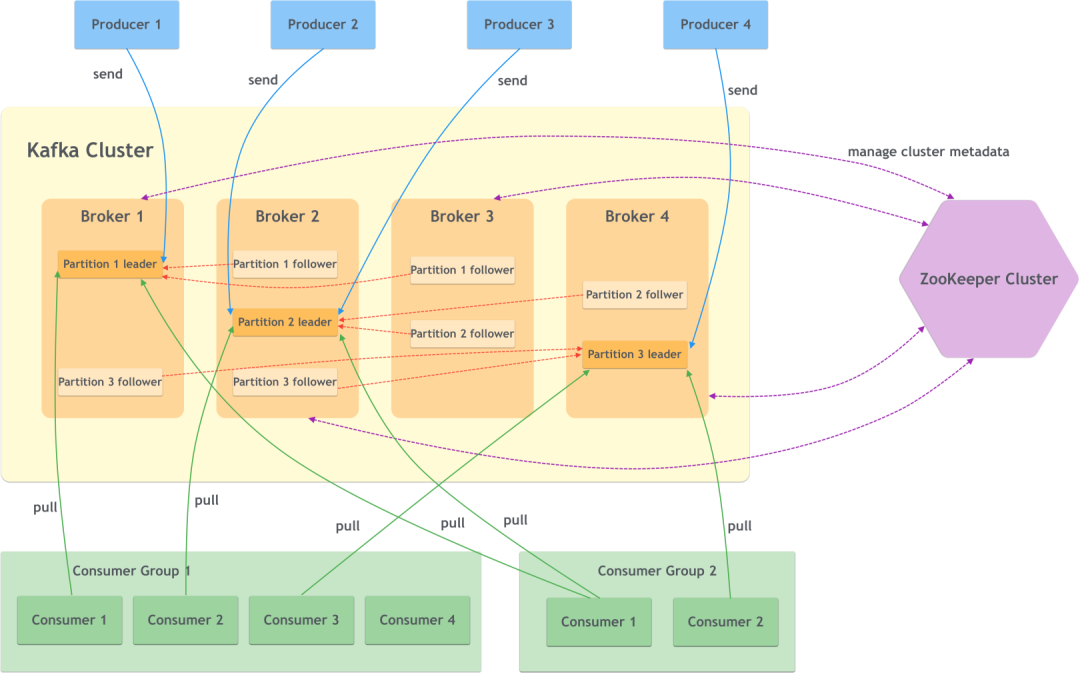
На рисунке показаны некоторые важные компоненты Kafka, которые будут представлены один за другим.
(1) Брокер
Узел сервисного агента. Фактически это экземпляр или сервисный узел Kafka, а несколько брокеров составляют кластер Kafka.
(2) Продюсер
продюсер. То есть сторона, пишущая сообщение, пишет сообщение брокеру.
(3) Потребитель
потребитель. То есть сторона, читающая сообщение, читает сообщение от брокера.
(4) Группа потребителей
группа потребителей. Один или несколько потребителей образуют группу потребителей, и разные группы потребителей могут подписываться на сообщения по одной и той же теме, не затрагивая друг друга.
(5) Смотритель зоопарка
Kafka использует Zookeeper для управления метаданными кластера, выбора контроллера и других операций.
(6) Тема
тема. Каждое сообщение принадлежит определенной теме, и Кафка делит сообщения по темам, что представляет собой логическую классификацию.
(7) Перегородка
Раздел. Сообщения одной темы могут быть разделены на несколько разделов, причем один раздел принадлежит только одному мастеру.
вопрос.
(8) Реплика
копия. Раздел может иметь несколько копий для улучшения аварийного восстановления.
(Девять)Лидер и последователь
Если раздел имеет несколько копий, требуется метод синхронизации. Kafka использует один главный и несколько подчиненных устройств для синхронизации сообщений. Основная копия обеспечивает возможности чтения и записи, тогда как подчиненная копия не обеспечивает чтение и запись и служит только резервной копией главной копии.
(10) Смещение
компенсировать. Каждое сообщение в разделе имеет смещение раздела, в котором оно находится. Это смещение однозначно определяет расположение сообщения в текущем разделе и гарантирует порядок внутри этого раздела, но не гарантирует порядок между разделами.
Проще говоря, Kafka как система обмена сообщениями по сути является системой данных. Поскольку это система данных, необходимо решить две фундаментальные проблемы:
- Когда мы передаем данные Кафке,Как хранить кафку;
- Когда мы просим Кафку получить данные,Как Кафка возвращается.


Как хранятся сообщения (логический уровень)
В настоящее время большинство систем данных хранят данные на диске в следующих форматах: журнал добавления и дерево B+. Kafka использует формат журнала добавления для хранения данных на диске. Общая структура выглядит следующим образом:
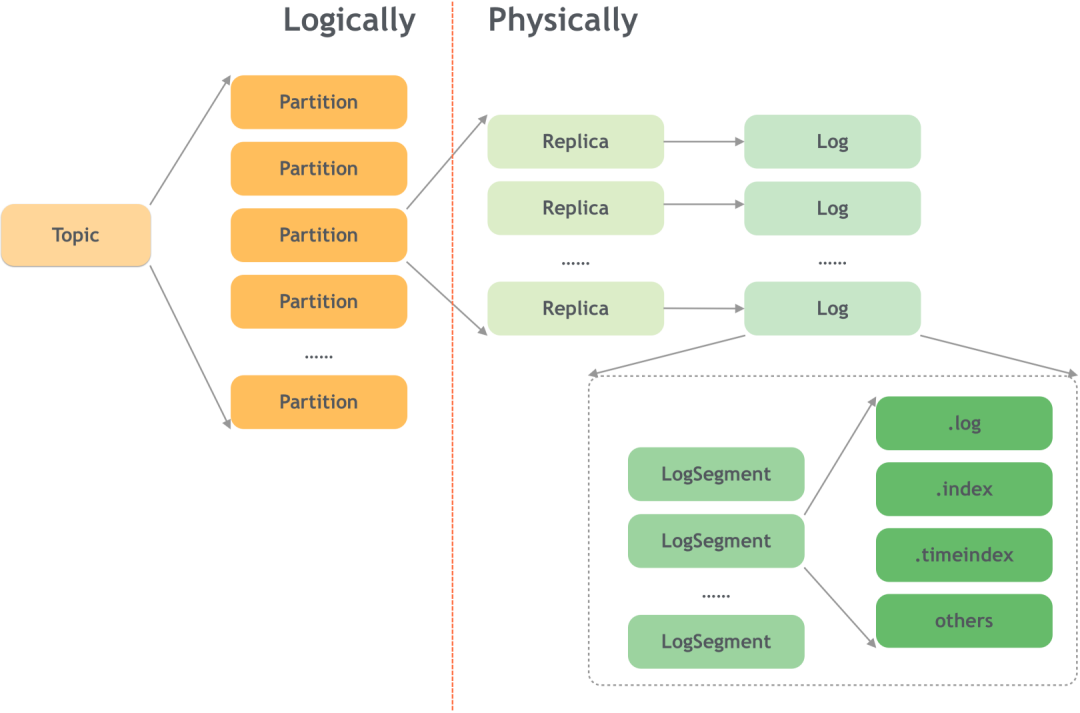
Формат добавления журнала может улучшить производительность записи (ведь добавлять нужно только в конец файла журнала), но в то же время поддержка чтения не очень дружелюбна. Чтобы улучшить производительность чтения, Kafka требует дополнительных операций.
Как хранятся данные Kafka — относительно большой вопрос. Начнем с логического уровня.
(1) Двухуровневая структура Тема+Раздел.
Kafka классифицирует сообщения на двух уровнях: теме и разделе.
Преимущества разделения темы на несколько разделов очевидны. Несколько разделов могут обеспечить Kafka возможности масштабируемости и горизонтального расширения, а избыточность разделов также может повысить надежность данных.
Различные разделы также можно развернуть на разных брокерах, а избыточные копии повышают надежность.
(2) Смещение
Для формата журнала добавления новые данные необходимо добавлять только в конец файла.
Для тем с несколькими разделами каждое сообщение имеет соответствующий раздел (разделитель), к которому необходимо добавить это сообщение. Это сообщение имеет уникальный идентификатор в разделе, в котором оно расположено, который представляет собой смещение:
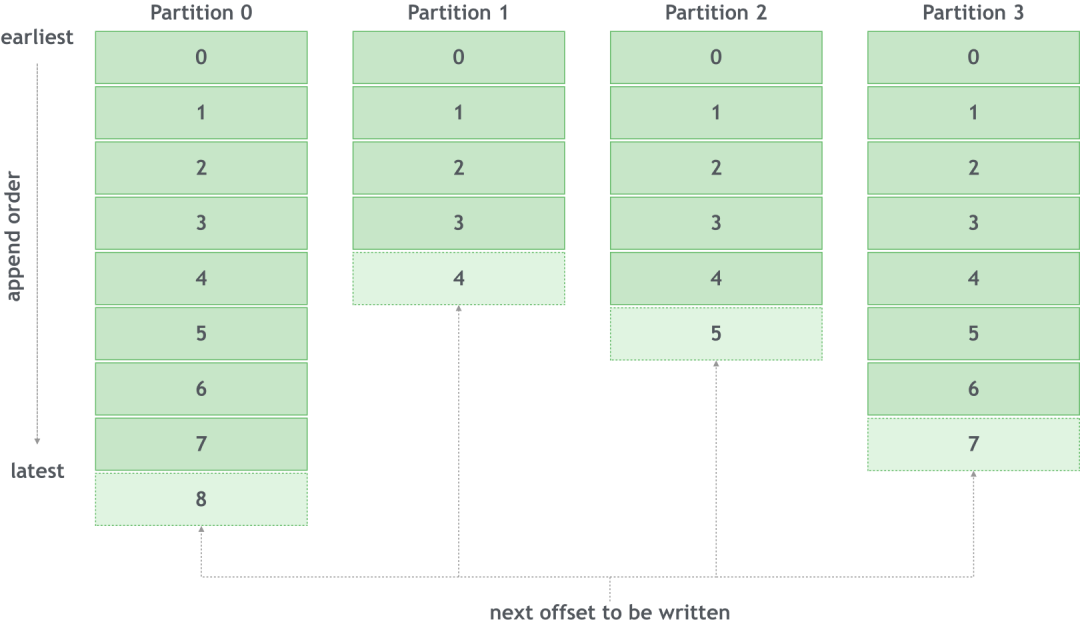
Такая конструкция имеет следующие характеристики:
- Разделение повышает производительность записи,и надежность данных;
- Порядок сообщений гарантируется внутри раздела, но не между разделами.
Зная, как Kafka хранит сообщения на логическом уровне, давайте посмотрим, как записывать и читать данные от имени пользователя.

Как записать данные
Далее давайте посмотрим, как записывать данные в Kafka с точки зрения пользователя.
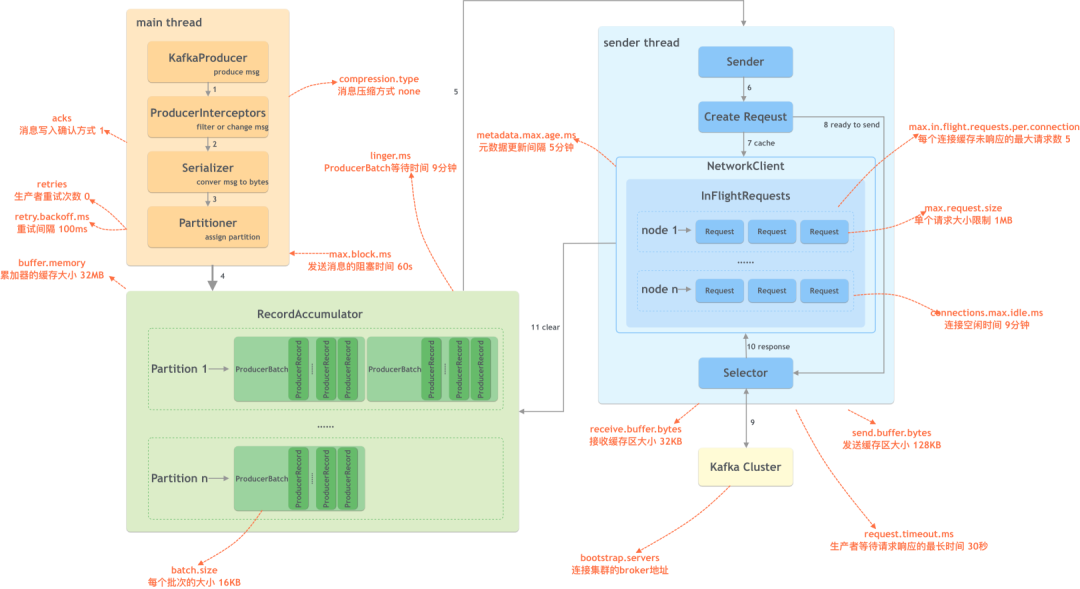
(1) Общий процесс
Общий процесс записи сообщений в Kafka производителем выглядит следующим образом:
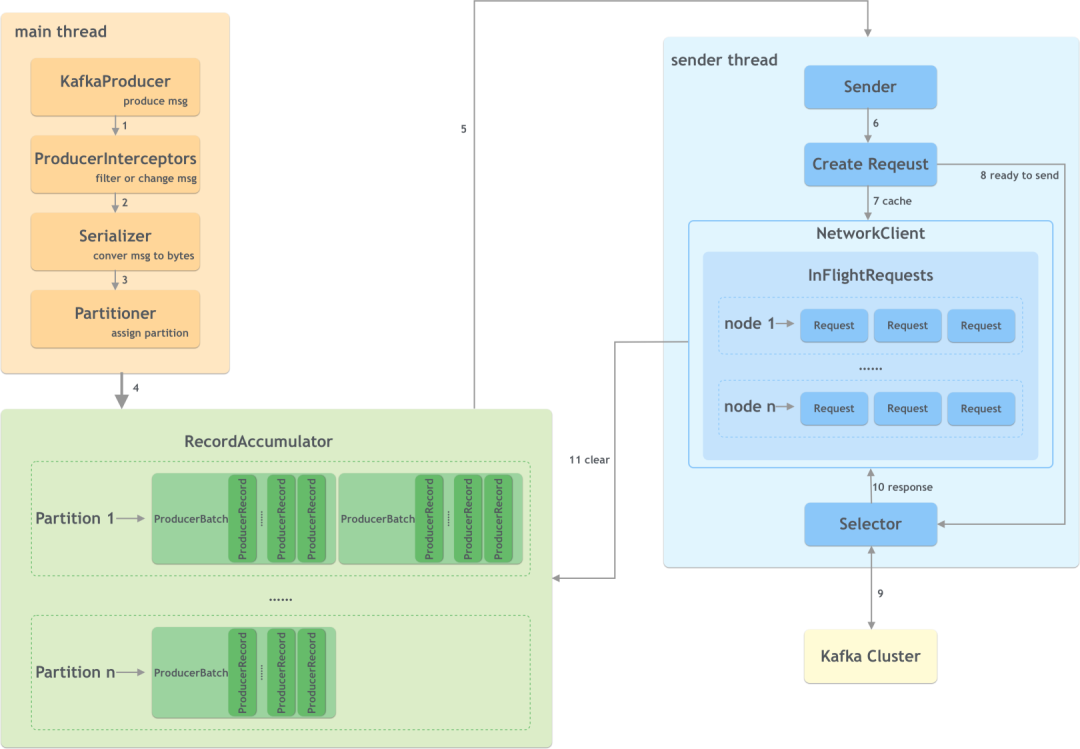
На производственной стороне в основном есть два потока: основной и отправитель. Они взаимодействуют через общую память RecordAccumulator.
Шаги следующие:
- KafkaProducer создает сообщения;
- Перехватчик производителя выполняет некоторую подготовительную работу перед отправкой сообщения, например, фильтрует сообщения, не соответствующие требованиям, изменяет содержимое сообщения и т. д.;
- Сериализатор преобразует сообщение в массив байтов;
- Средство разделения вычисляет целевой раздел сообщения, который затем сохраняется в RecordAccumulator;
- Поток отправки получает данные для отправки;
- Создавайте конкретные запросы;
- Если запросов слишком много, некоторые запросы будут кэшироваться;
- Отправьте подготовленный запрос;
- Отправить в кластер Kafka;
- получить ответ;
- убиратьданные。
Кэширование осуществляется в аккумуляторе сообщений RecordAccumulator. Размер кэша настраивается с помощью параметра buffer.memory, значение по умолчанию — 32 МБ. Накопитель управляет каждым сообщением в соответствии с разделом, и сообщения организуются в форме ProducerBatch (размер контролируется пакетом.размер, по умолчанию — 1 МБ). Чтобы повысить пропускную способность и уменьшить количество сетевых запросов, ProducerBatch может. содержать одно или несколько сообщений.
Когда сообщений не так много, пакет может не заполниться, но он не будет ждать слишком долго. Вы можете контролировать время ожидания через linger.ms, которое по умолчанию равно 0. Увеличение этого значения улучшает пропускную способность, но увеличивает задержку.
Когда скорость создания сообщений слишком высока и кэш переполнен, при продолжении отправки сообщений могут возникнуть блокировки или исключения. Это контролируется параметром max.block.ms. Значение по умолчанию — 60 секунд.
После того, как данные поступят и отправляющий поток создаст запрос, его необходимо повторно собрать и сгруппировать по узлам-брокерам, которым необходимо отправить. Каждый узел — это количество запросов, которые могут быть кэшированы каждым соединением. передается элементом управления max.in.flight.requests.per .connection, по умолчанию 5. Размер каждого запроса контролируется параметром max.reqeust.size, значение по умолчанию — 1 МБ.
(2) Способ доставки
Есть три способа отправки сообщений:
- Выстрелить и забыть: просто отправьте и проигнорируйте результаты, что имеет самую высокую производительность и худшую надежность;
- синхронный (синхронизация): дождитесь, пока кластер подтвердит, что сообщение успешно записано, прежде чем вернуться.,Высочайшая надежность,Производительность намного хуже;
- Асинхронный (асинхронный): укажите обратный вызов, который вызывается после того, как Kafka возвращает ответ для подтверждения асинхронной отправки.
Первые два отправляются синхронно, а последний — асинхронно. Однако асинхронная отправка здесь не обеспечивает возможности обратного вызова.
Так как же Кафка может подтвердить сообщение после того, как продюсер его отправит? Это включает в себя параметр acks:
- acks = 1, значение по умолчанию — 1, что означает, что операция успешна, пока успешно записана ведущая копия раздела;
- acks=0,Продюсеру не нужно ждать ответа от сервера.,данные могут быть утеряны;
- acks=-1 или acks=все,Все реплики в синхронном состоянии необходимы для подтверждения успешной записи.,Самый надежный,Производительность также плохая.
(3) Важные параметры производителей

Как читать сообщения
(1) Новости потребления
- структура потребления
Вообще говоря, существует два режима потребления сообщений: режим push и режим pull, а потребление в Kafka основано на режиме pull. Потребители постоянно вызывают опрос для получения сообщений для потребления. Основной режим следующий (псевдокод):
while(true) {
records := consumer.Pull()
for record := range records {
// do something with record
}
}- Представление смещения
Сообщения в Kafka имеют уникальный идентификатор смещения. Для потребителей Kafka должен уведомляться каждый раз, когда используется сообщение, чтобы использованные данные не были извлечены при следующем получении сообщения (повторное использование не учитывается)). Позиция сообщения о том, что потребитель употребил, является смещением потребления, например:
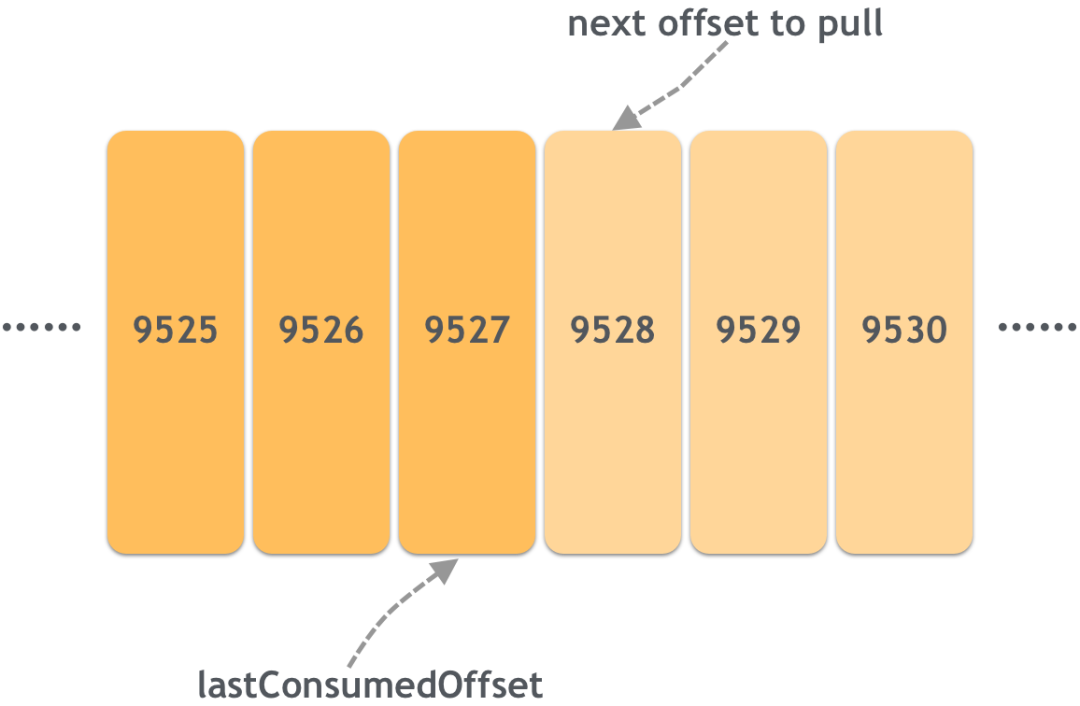
Предполагая, что 9527 в настоящее время извлекает максимальное смещение сообщения и завершил его использование, тогда смещение потребления этого потребителя равно 9527, а смещение потребления, которое должно быть отправлено, равно 9528, что указывает на позицию следующего сообщения, которое необходимо извлечь. .
Потребители могут получать несколько сообщений одновременно,Затем будет метод отправки. Kafka по умолчанию использует автоматическую отправку.,То есть максимальное смещение сообщения в каждом разделе, которое будет автоматически подтянуто за пять секунд (соответствующие параметры — Enable.auto.commit и auto.commit.interval.ms). Однако это может привести к повторному потреблению и потере предметов.
Давайте сначала посмотрим на повторное потребление:

Последнее отправленное смещение потребления — 9527, что означает, что сообщения 9526 и ранее были потреблены; сообщения, полученные в настоящее время этим запросом, — это 9527, 0528 и 9529. Следовательно, единственное, что должно быть отправлено после успешного потребления, — это 9. 530; Потребитель в настоящее время обрабатывает сообщение 9528. Если в это время потребитель повесит трубку и если 9530 не было отправлено в это время, то сообщения между 9527 и 9529 будут назначены следующему потребителю, что приведет к повторной обработке. сообщение 9527.
Давайте посмотрим на потерю сообщений. Тем не менее, на рисунке выше, если потребитель только что получил три сообщения с 9527 по 9529 и случайно отправил 9530 автоматически, и потребитель в это время вешает трубку, то оно будет отправлено до обработки, что приведет к потере этих трех сообщений. сообщения.
(2) Стратегия распределения разделов
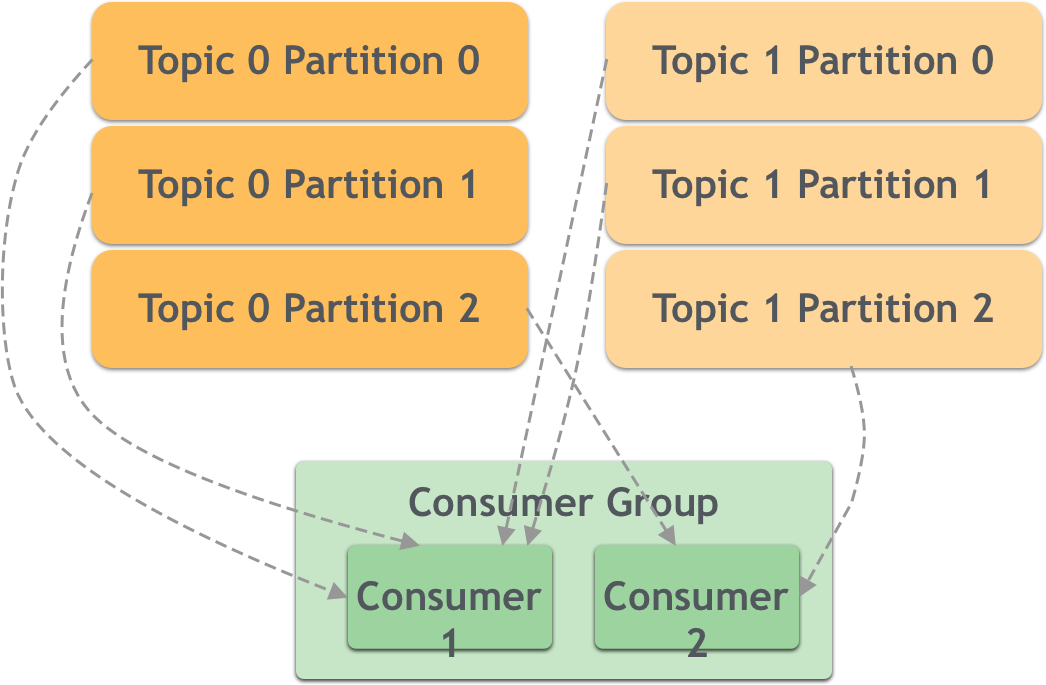
Сообщения хранятся в Kafka в нескольких разделах, поэтому сообщения в разделах сообщений потребителя также имеют стратегию распределения разделов. В качестве примера возьмите исходное изображение, которое представляет собой часть группы потребителей ниже:
Всего существует три раздела. Группа потребителей 1 имеет четыре группы потребителей, поэтому одна из них простаивает; группа потребителей 2 имеет две группы потребителей, поэтому одна группа потребителей должна обрабатывать два раздела.
Стратегия распределения разделов потребителей Kafka настраивается с помощью параметра part.asigment.strategy, который выглядит следующим образом:
- Диапазон: Распределяется в соответствии с общим количеством потребителей и общим количеством разделов, но основан на детализации тем, поэтому может быть неоднородным. например:
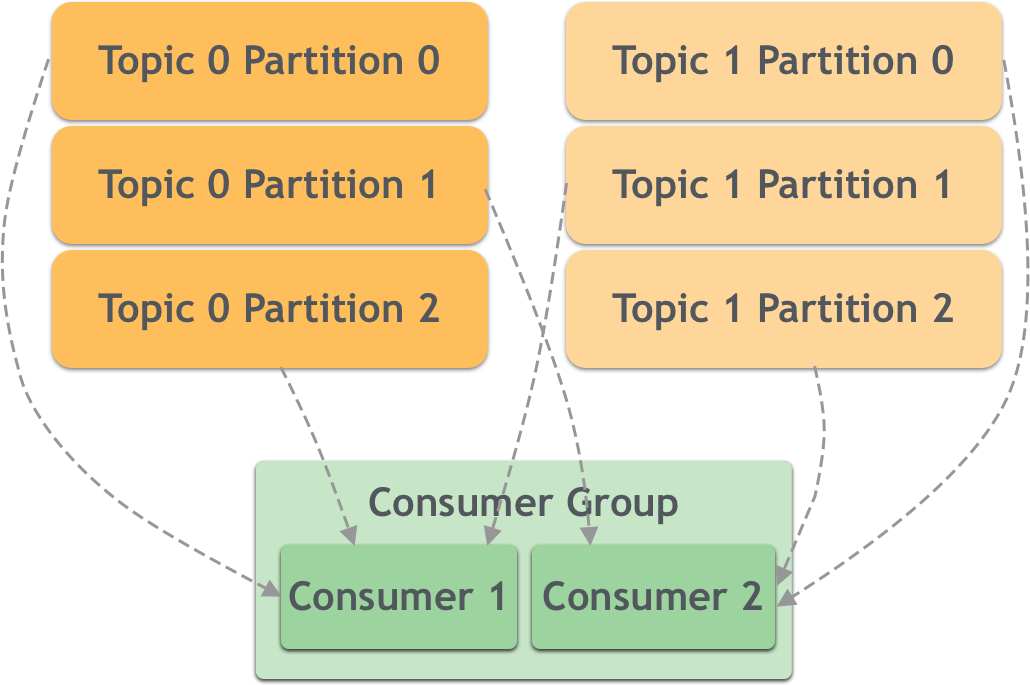
- RoundRobin: сортировка разделов всех потребителей в группе потребителей и всех тем, на которые подписаны потребители, в лексикографическом порядке, а затем выделение разделов каждому потребителю одновременно посредством опроса. например:
- Закреплено: эта стратегия более сложна. Цель состоит в том, чтобы распределить разделы как можно более равномерно и сохранить распределение как можно более согласованным с прошлым разом.
(3) Ребалансировка
Координация между потребителями осуществляется через координатора потребителей (ConsumerCoordinator) и координатора группы (GroupCoordinator). Одним из них является ребалансировка потребителей.
Следующие ситуации приведут к ребалансировке потребителей:
- Присоединяются новые потребители;
- Некоторые потребители отключаются от сети;
- Некоторые потребители активно уходят;
- Узел координатора группы, соответствующий группе потребителей, изменяется;
- Меняется количество подписанных тем или разделов.
Ребалансировка будет проходить в следующие этапы:
- FindCoordinator: потребитель находит машину, на которой находится координатор группы, а затем устанавливает соединение;
- JoinGroup: потребитель инициирует запрос координатору группы на присоединение к группе;
- SyncGroup: координатор группы распространяет план распределения разделов среди всех потребителей;
- Сердцебиение: потребитель входит в нормальное состояние и начинает биться сердцебиение.

Как хранить сообщения (физический уровень)
В предыдущем разделе мы рассказали, как Kafka хранит данные на логическом уровне, а затем переходит на физический уровень. Или эта картинка:
(1) Файлы журналов
Kafka использует добавление журнала для хранения данных. Новые данные необходимо добавлять только в конец файла журнала. Этот метод повышает производительность записи.
Но файлы не могут добавляться постоянно. Поэтому файл журнала в Kafka соответствует нескольким сегментам журнала LogSegment.
Используйте сегментацию для облегчения очистки. У Kafka есть две стратегии очистки журналов:
- бревно удаление (Log Retention): напрямую удалять бревно сегмент по определенной стратегии;
- бревносжатие(Log Сжатие): интегрируйте ключи каждого сообщения и сохраняйте только последнее значение под тем же ключом.
- бревно Удалить
Политики удаления журналов имеют срок действия и размер журнала. Срок хранения по умолчанию составляет 7 дней, а размер по умолчанию — 1 ГБ.
Хотя срок хранения по умолчанию составляет 7 дней, возможны более длительные сроки хранения. Поскольку текущий активный сегмент журнала не будет удален, если объем данных очень мал и текущий активный сегмент журнала не может быть разделен, он не будет удален.
Kafka будет периодически выполнять задачу по удалению журналов, соответствующих условиям удаления.
- бревносжатие
Сжатие журнала нацелено на ключи, и сохраняется только самое последнее из нескольких значений с одним и тем же ключом.
В то же время при сжатии журналов создаются файлы небольшого размера. Чтобы избежать слишком большого количества маленьких файлов, Kafka также объединит их во время очистки:
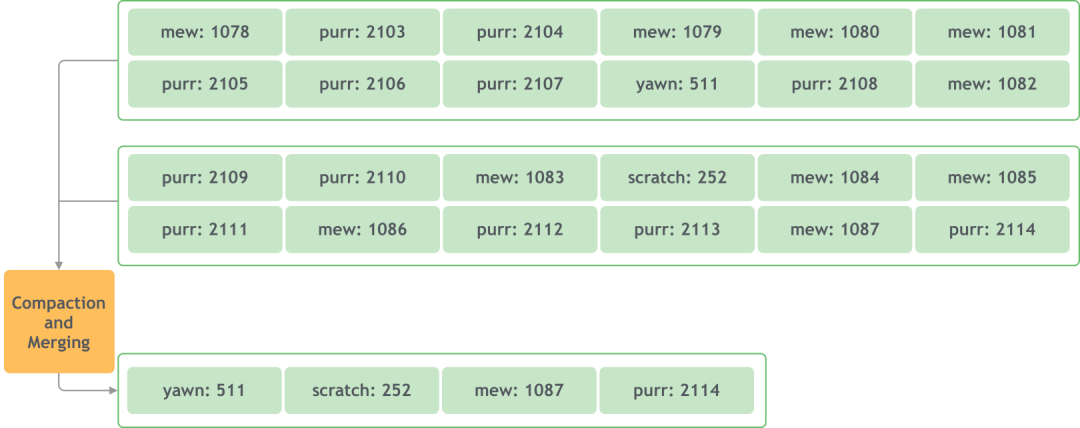
(2) Индекс журнала
Добавление журнала повышает производительность записи, но не очень удобно для чтения. Чтобы улучшить производительность чтения, необходимо снизить производительность записи и обеспечить баланс между чтением и записью. То есть сохранение индекса во время записи.
Kafka поддерживает два типа индексов: индекс смещения и индекс метки времени.
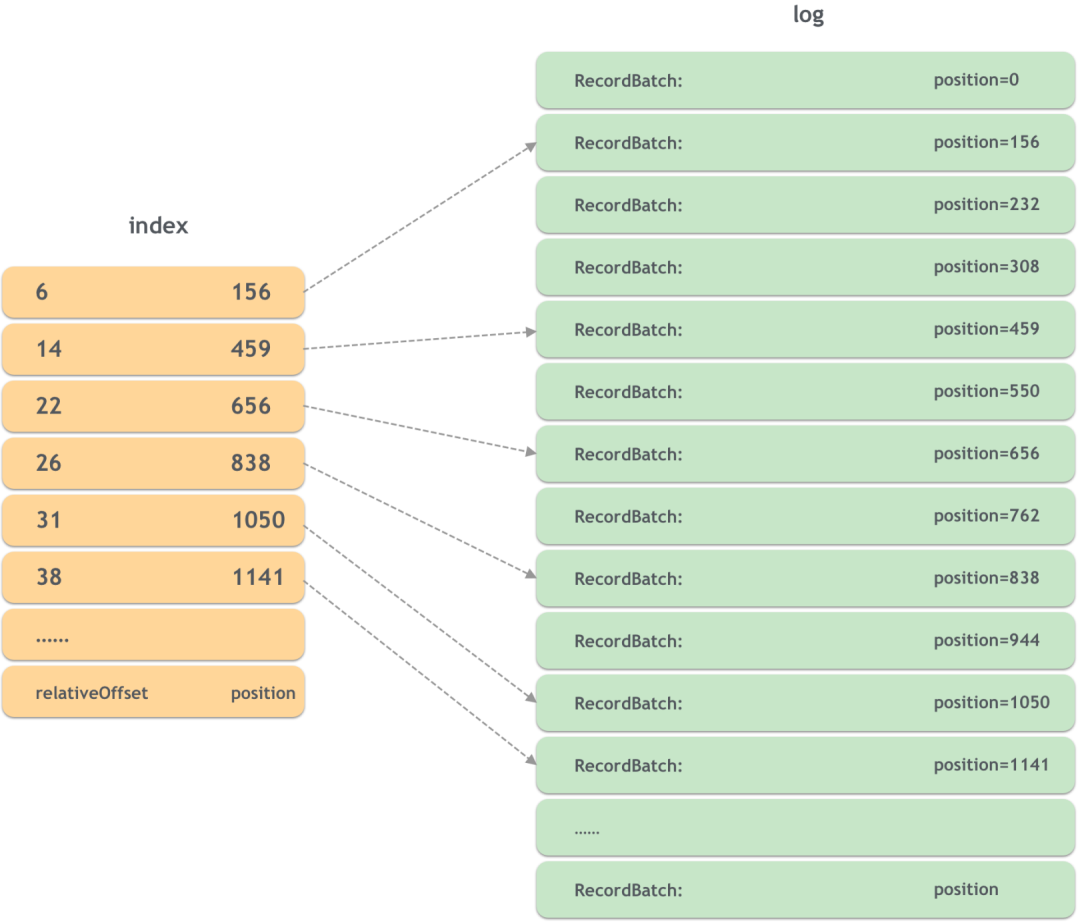
- индекс смещения
Чтобы быстро найти местоположение данного сообщения в файле журнала, можно просто сохранить сопоставление. Ключ — это смещение сообщения, а значение — это смещение в файле журнала. Только в этом случае. требуется чтение одного файла. Соответствующее сообщение можно найти.
Однако, когда количество сообщений огромно, это сопоставление также станет очень большим. Kafka поддерживает разреженный индекс (разреженный индекс), то есть не все сообщения имеют соответствующую позицию. Для сообщений без сопоставления позиции можно решить двоичный поиск. это.
На следующем рисунке показан принцип индекса смещения:
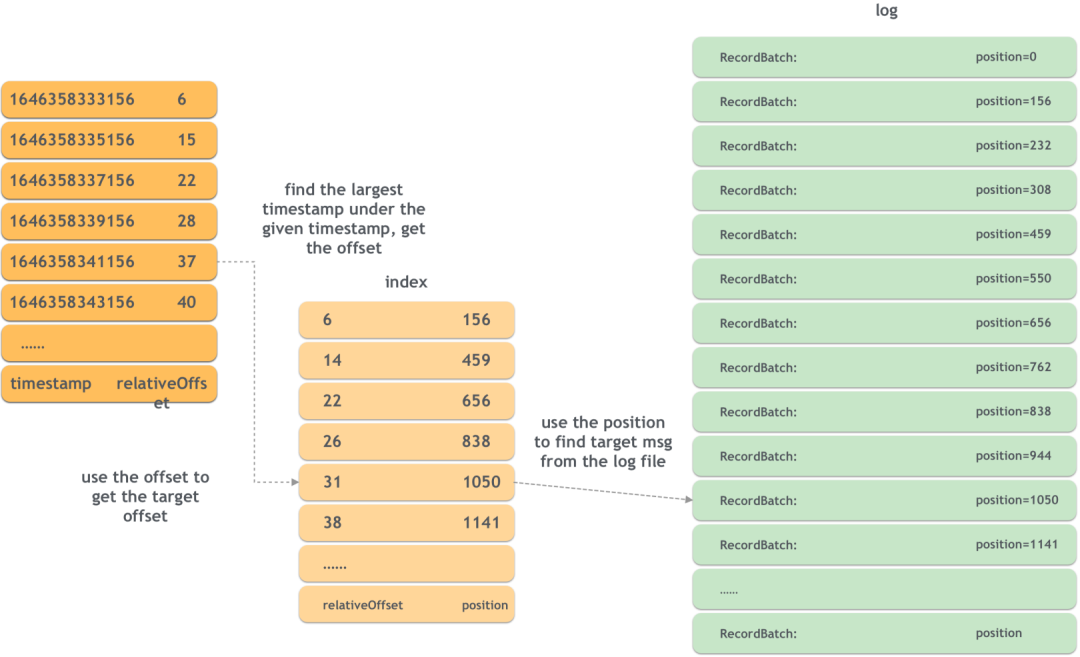
Например, если вы хотите найти местоположение сообщения со смещением 37, сначала проверьте, что в индексе нет соответствующей записи, затем найдите максимальное смещение, не превышающее 37, то есть 31, а затем выполните поиск сообщений. с 37 по порядку, начиная с 1050 в журнале.
- индекс временной метки
Индекс метки времени означает, что соответствующее смещение можно найти на основе метки времени. Индекс метки времени является вторичным индексом. Теперь вы можете найти смещение на основе метки времени, а затем использовать индекс смещения для поиска соответствующего местоположения сообщения. Принцип следующий:
(3) Нулевая копия
Kafka хранит данные на диске и использует добавление журналов для повышения производительности. Чтобы еще больше повысить производительность, Kafka использует технологию нулевого копирования.
Проще говоря, нулевое копирование означает прямое копирование содержимого файла на устройство сетевой карты в режиме ядра, что уменьшает переключение между режимом ядра и пользовательским режимом.
Ненулевая копия:
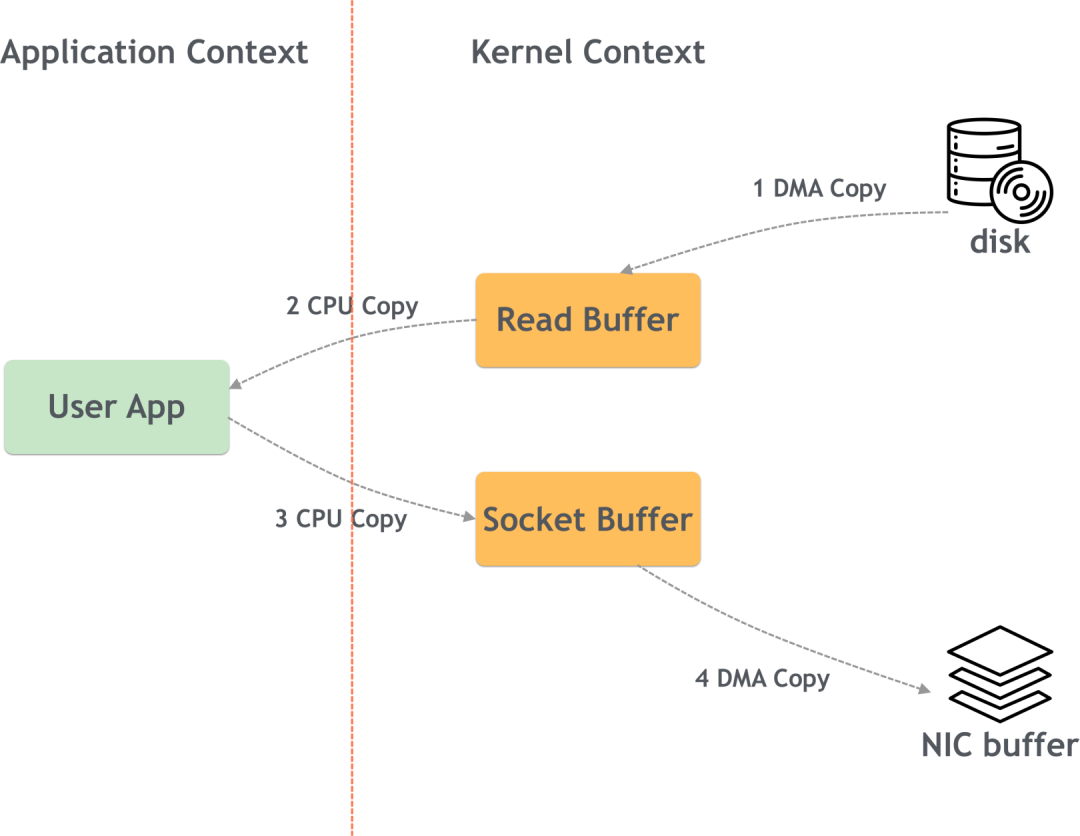
Нулевая копия:
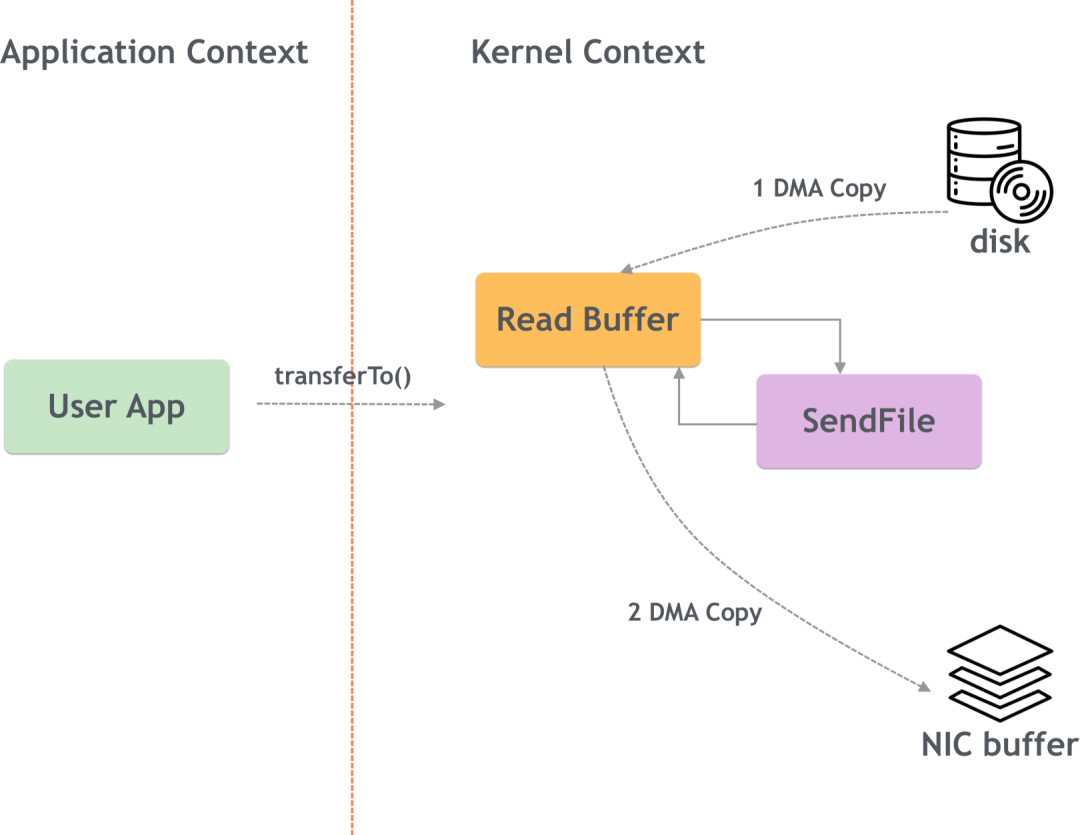

надежность Кафки
Kafka обеспечивает горизонтальное расширение за счет множества копий, повышая устойчивость к катастрофам и надежность. Вот взгляд на механизм множественного копирования Кафки.
(1) Некоторые концепции
На следующем рисунке показаны некоторые важные концепции синхронизации реплик (перспектива одного раздела):
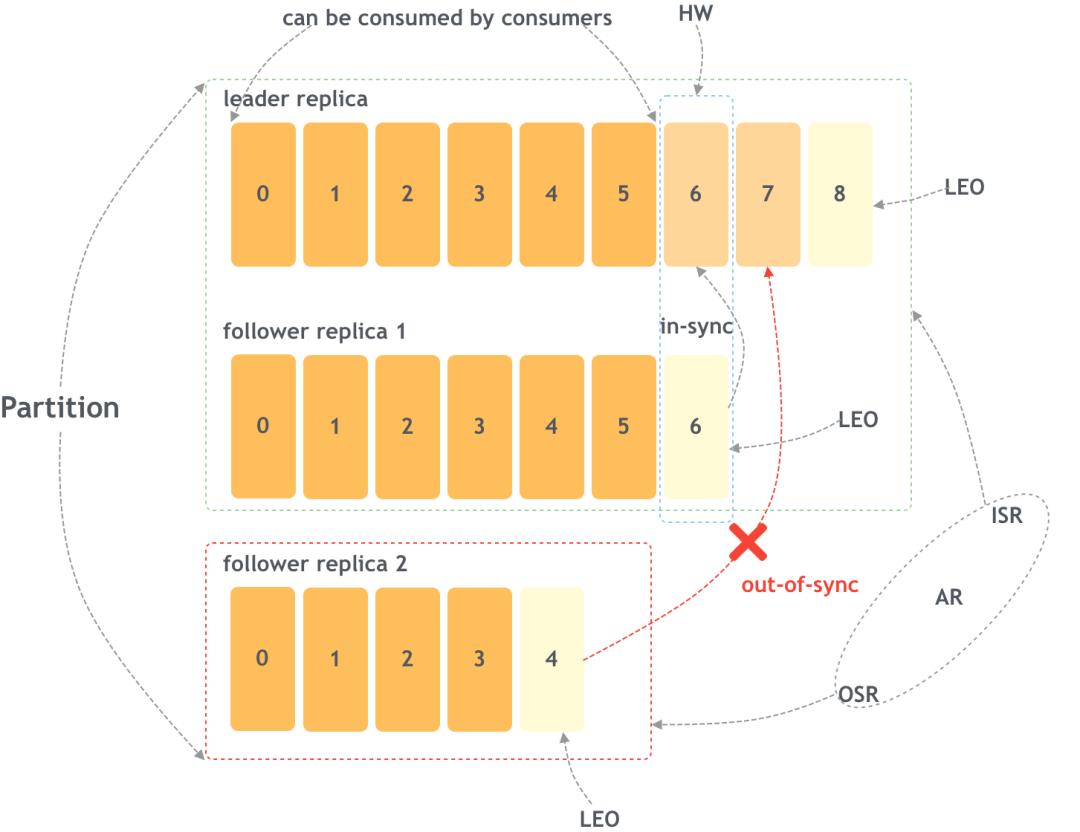
AR: Assigned Replicas
Все копии называются AR.
ISR: In-Sync Replicas
ISR — это подмножество AR, то есть набор всех реплик, синхронизированных с первичной репликой.
OSR: Out-of-Sync Replicas
OSR также является подмножеством AR, набором всех реплик, которые не соответствуют первичной реплике. Итак, AR=ISR+OSR.
Kafka использует некоторые алгоритмы, чтобы определить, остается ли синхронизированной подчиненная реплика. Неисправная реплика также может повторно войти в ISR, догоняя главную реплику.
LEO: Log End Offset
LEO — это смещение, с которым будет записано следующее сообщение до того, как LEO будет записано в журнал. Каждая копия имеет свой собственный LEO.
HW: High Watermark
Среди всех реплик, которые синхронизируются с первичной репликой, наименьший LEO — это HW. Это смещение означает, что сообщения до этого были записаны в журналы всеми ISR, и потребители могут получить их, даже если первичная реплика выйдет из строя. одна из реплик ISR становится первичной, сообщение не будет потеряно.
(2) Обновление основной копии HW и LEO.
LEO и HW — это смещения сообщений, где HW — наименьший LEO среди всех ISR. На следующем рисунке показан процесс синхронизации сообщений от производителя к первичной реплике, а затем к подчиненной реплике:
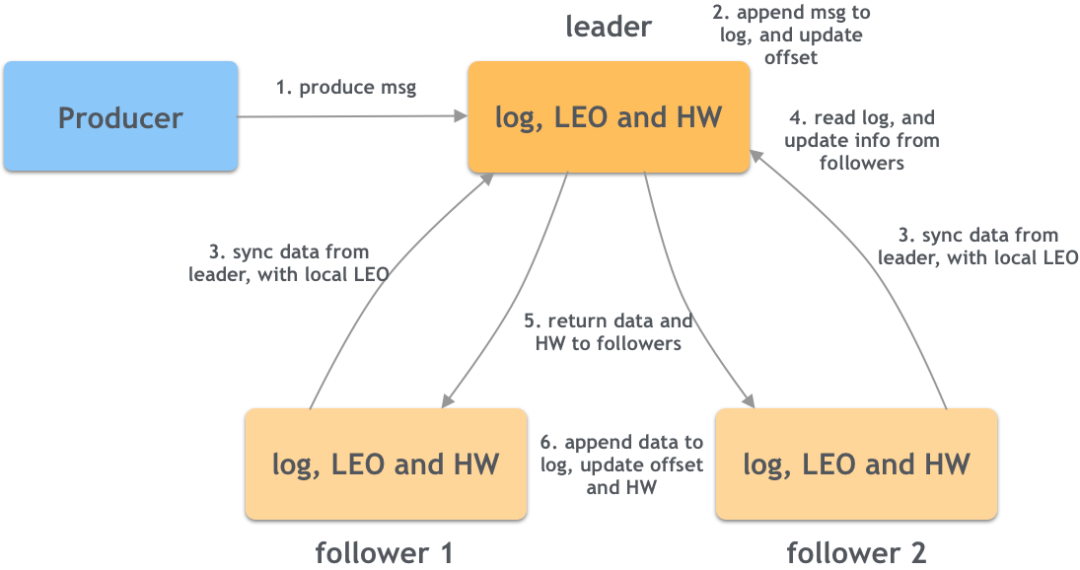
- Продюсер отправляет сообщение лидеру;
- Ведущий добавляет сообщение в бревно,и обновить свою собственную информацию о смещении,В то же время лидер также хранит информацию о последователях (например, LEO и т. д.);
- Последователь запрашивает синхронность у лидера и несет свой собственный LEO и другую информацию;
- Лидер читает бревно и извлекает сохраненную информацию каждого ведомого (LEO);
- Лидер возвращает данные ведомому вместе со своим собственным аппаратным обеспечением;
- После того, как подписчик получает данные, он добавляет их в свою бревно.,В то же время обновите собственное аппаратное обеспечение на основе возвращенного аппаратного обеспечения.,Метод заключается в том, чтобы взять минимальное значение собственных LEO и HW.
Как видно из вышеописанного процесса, аппаратное обеспечение ведущего устройства не увеличивается после процесса синхронизации. Только после того, как выполнена еще одна синхронизация и ведомый передает последний обновленный LEO ведущему, лидер может обновить аппаратное обеспечение. деревня может подтвердить, что сообщение действительно было. Все копии ISR были успешно записаны.
Аппаратное обеспечение лидера очень важно, поскольку это значение напрямую определяет данные, которые могут потреблять потребители.
(3) Эпоха лидера
Рассмотрим следующий сценарий. Первоначально лидер сохранил два сообщения: LEO=2 и HW=1:
Загрузка фотографий...
При синхронизации 1 ведомый получает данные. После добавления ему необходимо снова запросить ведущего (синхронизация 2) обновить аппаратное обеспечение ведущего и ведомого.
Таким образом, в обновлении аппаратного обеспечения возникнет пробел. Если синхронизация 1 прошла успешно и ведомый зависает перед синхронизацией 2, то аппаратное обеспечение после перезапуска все еще будет 1, и ведомый будет усекать журнал и приводить к потере m2. лидер в это время тоже зависнет, это произойдет. Ведомый станет лидером, и m2 будет полностью потерян (даже если перезапустить исходный лидер, его нельзя изменить).
Чтобы решить эту проблему, Kafka ввёл понятие эпохи лидера. По сути, это номер версии, в запросе на синхронизацию фолловера он не только передает свой LEO, но и привносит текущий LE при один раз смене лидера. , это значение увеличится на 1.
Благодаря информации о LE,Последователь не будет легко усечен после сбоя и перезапуска.,Вместо этого он запросит самую свежую информацию.,Это позволяет избежать проблемы потери данных в описанной выше ситуации.
В этой статье кратко описаны некоторые важные концепции Kafka простым языком и простыми диаграммами. На самом деле, Кафка — сложная система, и для глубокого понимания Кафки требуется больше знаний.
Об авторе

Valineliu
Инженер-разработчик серверной части Tencent
Инженер-разработчик серверной части Tencent в настоящее время отвечает за серверную разработку онлайн-редактирования Zhiying.
Рекомендация оригинальной темы FunTester~
- 900 оригинальных коллекций
- оригинальная коллекция 2021 года
- оригинальная коллекция 2022 года
- Специальная тема по тестированию функций интерфейса
- Темы тестирования производительности
- классные темы
- Java、Groovy、Go、Python
- Одиночный тест&белая коробка
- Стиль сообщества FunTester
- Тестирование теории куриного супа
- Функция видео FunTester
- Распространение кейсов: решения, ошибки, сканеры
- Тема автоматизации пользовательского интерфейса
- Специальная тема об инструментах тестирования
-- By FunTester



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
