[Сегментация изображений] Базовое использование преобразования и визуализации формата LabelMe/label.
Предисловие
Раньше я работал над контентом, связанным с обнаружением целей, и знаком с использованием LabelImg для аннотирования данных обнаружения. Однако недавно я попытался изучить сценарий сегментации изображений, и мне нужно было использовать LabelMe, чтобы пометить метки данных для сегментации. В этой статье описывается этот процесс.
Пример метки данных сегментации изображения
Возьмем в качестве примера сегментацию дорог.,Изображение нижеdeepglobeданныеконцентрированная группаданные,Справа спутниковый снимок,Ярлык изображения находится слева.,Выделите изображение с помощью маски.

Установка LabelMe
Установка очень проста, просто используйте pip для установки:
pip install labelmeПодготовка данных
Прежде чем начать, организуйте расположение данных в соответствии со следующим каталогом:
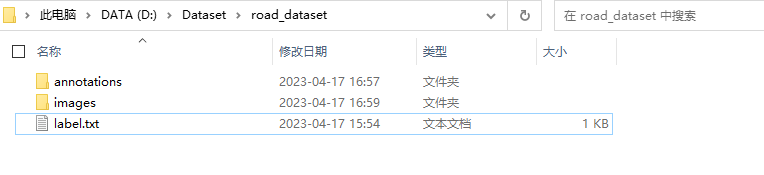
- аннотации: пустая папка, подготовленная для сохранения меток с аннотациями.
- изображения: размещайте изображения и копируйте в него данные изображений.
- label.txt: в основном используется для предварительной настройки категорий.
label.txtСодержимое файла следующее:
__ignore__
_background_
roadСодержимое предыдущей строки фиксировано и связано с последующим сценарием обработки. Третья строка начинается с названия категории. Здесь мне нужно только разделить дорогу, поэтому есть только одна категория дорог.
Использование программного обеспечения
первый вAnaconda Promptвойти внутрьданныекорневой каталог файла:
cd D:\Dataset\road_datasetЗатем запустите labelme:
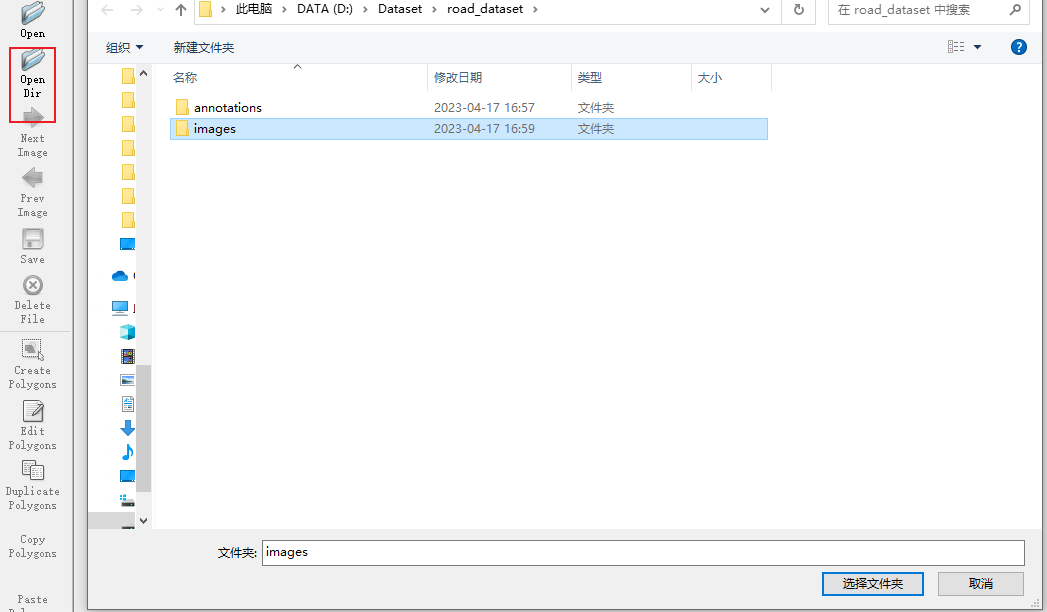
labelme --labels label.txtвыбиратьOpenDirИмпортировать изображения:
Установить папку вывода этикеток:
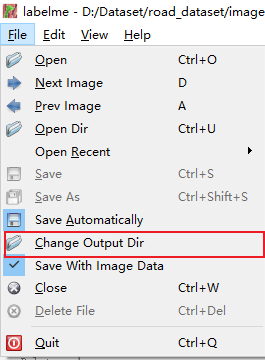
`
Установить ранее построенныйannotations:
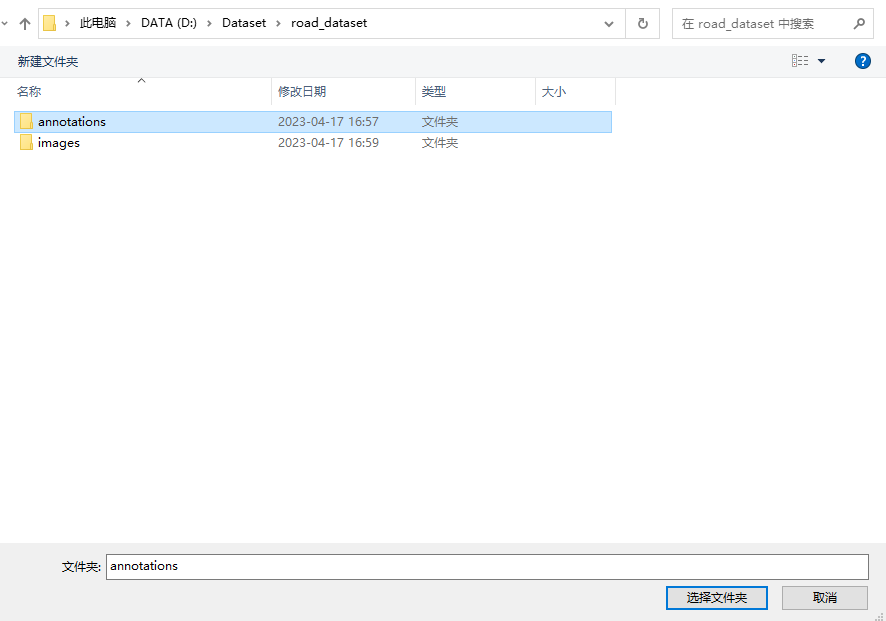
НажмитеCreate Polygons(быстрая клавишаCtrl+N),Окружите целевую точку,Похоже на вырез в PS,Соединены конец в конец,Просто сохраните его.

преобразование формата
После маркировки,можно получитьjsonтег формата。
Следующее необходимо сделать согласно метке преобразование form, получаем метку типа изображения.
Следующий код преобразования изменен сОфициальный склад Labelme,В основном изменена логика и путь загрузки файлов:
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import imgviz
import numpy as np
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default="D:/Dataset/road_dataset/annotations", help="input annotated directory")
parser.add_argument("--output_dir", default="D:/Dataset/road_dataset", help="output dataset directory")
parser.add_argument("--labels", default="D:/Dataset/road_dataset/label.txt", help="labels file")
args = parser.parse_args()
args.noviz = False
if not osp.exists(args.output_dir):
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "SegmentationClass"))
os.makedirs(osp.join(args.output_dir, "SegmentationClassPNG"))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, "SegmentationClassVisualization")
)
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_lbl_file = osp.join(
args.output_dir, "SegmentationClass", base + ".npy"
)
out_png_file = osp.join(
args.output_dir, "SegmentationClassPNG", base + ".png"
)
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
"SegmentationClassVisualization",
base + ".jpg",
)
with open(out_img_file, "wb") as f:
f.write(label_file.imageData)
img = labelme.utils.img_data_to_arr(label_file.imageData)
lbl, _ = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=label_file.shapes,
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
lbl,
imgviz.rgb2gray(img),
font_size=15,
label_names=class_names,
loc="rb",
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == "__main__":
main()После запуска появится еще несколько папок:
- JPEGImages: исходные изображения.
- SegmentationClass: метка формата npy
- SegmentationClassPNG: изображение маски
- SegmentationClassVisualization: наложение изображения маски и реального изображения сцены.
- class_names.txt: Все категории (включая фон)
Визуализация этикетки
Для этой задачи мне нужно только изображение белой маски, но визуализация маски labelme не дает соответствующего цветового интерфейса. Поэтому я использовал opencv, чтобы воссоздать программу визуализации маски:
import json
import cv2
import numpy as np
from tqdm import tqdm
import os
fill_color = (255, 255, 255)
root_dir = 'D:/Dataset/road_dataset'
def visualize_one(label_name):
with open(root_dir + '/annotations' + '/' + label_name + '.json', 'r') as obj:
dict = json.load(obj)
img = cv2.imread(root_dir + '/images' + '/' + label_name + '.jpg')
for label in dict['shapes']:
points = np.array(label['points'], dtype=np.int32)
black_img = np.zeros(img.shape)
cv2.polylines(black_img, [points], isClosed=True, color=fill_color, thickness=1)
cv2.fillPoly(black_img, [points], color=fill_color)
cv2.imwrite(root_dir + '/labels' + '/' + label_name + '.jpg', black_img)
if __name__ == '__main__':
os.mkdir(root_dir + '/labels')
for i in tqdm(os.listdir(os.path.join(root_dir, "annotations"))):
label_name = i[:-5]
visualize_one(label_name)После запуска вы можете плавно получить соответствующую метку.

ссылка
[1] Метка сегментации Labelme Использование программного обеспечения https://blog.csdn.net/qq_37541097/article/details/120162702



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
