Самая полная в истории сводка крупномасштабных наборов данных 3D-контроля на открытом воздухе
1. Набор данных KITTI
годы:2012Год;
автор:Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago;
Количество сцен:о50индивидуальный,сцена на открытом воздухе;
Количество категорий:общий9добрый,Они машина,Van,Truck,Pedestrian,Person_sitting,Cyclist,Tram,Misc,DontCare;
Стоит ли собирать 360°:нет;
Общий объем данных:включать7481Тренировочный набор Чжан,7518 тестовая коллекция,И соответствующие данные облака точек;
Общее количество аннотаций:о200,000 блоков 3D-аннотаций;
Модель датчика:GPS/IMUМодельOXTS RT 3003, модель лидара Velodyne. HDL-64E, модель камеры в оттенках серого — FL2-14S3M-C, модель цветной камеры — FL2-14S3C-C, частота лидара — 10 кадров в секунду, каждый цикл захватывает примерно 100 000 точек, самое короткое время затвора камеры — 2 мс и использует лидар для запуска съемки камерой, поэтому частота камеры совпадает с частотой лидара;
Ссылка на набор данных:https://www.cvlibs.net/datasets/kitti/index.php;
Введение:KITTIда Автономное Одна из наиболее важных коллекций данных в области вождения, которая предлагает большое количество реальных данных. сценв соответствии с,Используется для лучшего измерения и выполнения алгоритма тестирования. В дополнение к 3D-обнаружению целей,Набор данных KITTI также можно использовать для оценки стереоскопических изображений.,световой поток,визуальное определение дальности,Производительность технологий компьютерного зрения, таких как 3D-слежение в транспортных средствах. До 15 транспортных средств и 30 пешеходных объектов на изображение,Он также включает в себя различные степени окклюзии и усечения.


2. Набор данных nuScenes
годы:2019Год;
автор:nuTonomy;
Количество сцен:о1000индивидуальный场景,сцена на открытом воздухе,Собрано из Бостона и Сингапура;
Количество категорий:общий23добрый,Включая автомобиль,Pedestrian,Bus,Велосипед и т. д.;
Стоит ли собирать 360°:да;
Общий объем данных:включать40,000 данных изображений и соответствующие им данные облаков точек;
Общее количество аннотаций:о1400,000 блоков 3D-аннотаций;
Модель датчика:общий配备Понятно6индивидуальный相机МодельBasler acA1600-60gc, разрешение — 1600x900. За исключением угла обзора задней камеры 110°, угол обзора остальных пяти камер составляет 70°. Центральный угол поля зрения передней и боковой камеры составляет 55 градусов. частота сбора данных камеры составляет 12 Гц. Использовалась 32-строчная модель LiDAR, Velodyne. HDL32E, частота сбора данных 20 Гц, также оснащен 5 моделями радаров: Continental ARS 408-21 и модель GPS/IMU Advanced. Navigation Spatial;
Ссылка на набор данных:https://www.nuscenes.org/nuscenes#overview;
Введение:nuScenesда Автономное NuScenes, один из наиболее важных наборов данных в области вождения, по сравнению с набором данных KITTI, имеет больший размер и также записывает данные радара (собираемые с радара). Набор данных состоит из 1000 сцен, длительность каждой сцены 20 секунд. В каждой сцене 40 ключевых кадров, то есть 2 ключевых кадра в секунду, а остальные кадры — это развертки. Ключевые кадры аннотированы вручную. Каждый кадр содержит несколько аннотаций. Аннотация имеет форму границы. В поле отмечен не только размер, диапазон, но также категория, видимость и т. д. Этот набор данных очень хорош с точки зрения количества выборок и формы аннотации. Он записывает собственную траекторию движения автомобиля (относительно глобальных координат) и содержит множество датчиков, которые можно использовать для реализации более интеллектуальных алгоритмов распознавания и восприятия. алгоритм слияния.

3. Набор данных Waymo
годы:2020Год;
автор:Waymo ООО и Google LLC
Количество сцен:общий1150индивидуальный场景,В основном собрано из Сан-Франциско.,Mountain Вью, Феникс и т. д.;
Количество категорий:общий4добрый,Транспортные средства,Pedestrians,Велосипедисты и знаки;
Собирать ли 360°: да;
Общий объем данных:общий Включать 2030 роликов по 20 секунд каждый;
Общее количество аннотаций:о12,600,000 блоков 3D-аннотаций;
Модель датчика:Включать1индивидуальныйmid-range LiDAR, 4 ближнего действия LiDAR, 5 камер (фронтальная и боковая), а также LiDAR и камеры синхронизированы и откалиброваны;
Ссылка на набор данных:https://waymo.com/open/;
Введение:Waymoда Автономное Одна из наиболее важных коллекций данных в области вождения, она очень большая и в основном используется для поддержки автономного управления. вождение Исследование технологии восприятия. Waymo в основном состоит из двух наборов данных: Perception Набор данных и движение Набор данных. Среди них Восприятие Набор данных включает в себя 3D-аннотацию, 2D-аннотацию панорамной сегментации, аннотацию ключевой точки, 3D-аннотацию семантической сегментации и т. д. Движение Набор данных в основном используется для исследования интерактивных задач. Он содержит в общей сложности 103 354 клипа продолжительностью 20 секунд, помеченных различными объектами и соответствующими данными трехмерных карт.

4. Набор данных Lyft L5
годы:2019Год;
автор:Woven Planet Holdings;
Количество сцен:общий1805индивидуальный场景,открытый;
Количество категорий:общий9добрый,Включая автомобиль,Pedestrian,traffic фонари и т. д.;
Стоит ли собирать 360°:да;
Общий объем данных:включать46,000 данных изображений и соответствующие им данные облаков точек;
Общее количество аннотаций:о1300,000 блоков 3D-аннотаций;
Модель датчика:включать2индивидуальныйLiDARs,Это 40 и 64 строки соответственно.,Устанавливается на крышу и бампер.,Его разрешение составляет 0,2°.,Было собрано около 216 000 точек при частоте 10 Гц. также,Также включает в себя 6 камер с обзором на 360° и 1 телеобъектив.,Частота сбора данных камеры и LiDAR одинакова.
Ссылка на набор данных:https://level-5.global/data/;
Введение:Lyft L5 представляет собой полный набор наборов данных для автономного вождения уровня L5. Он считается «крупнейшим общедоступным набором данных для автономного вождения в отрасли» и охватывает прогнозирование. Набор данных и восприятие Набор данных. Среди них предсказание Набор данных охватывает парк испытаний беспилотных автомобилей в Пало На Альто встречаются различные цели, такие как автомобили, велосипедисты и пешеходы. Восприятие Набор данных охватывает реальные данные, собранные с помощью LiDAR и камер, установленных в автопарках, и вручную аннотирует большое количество трехмерных ограничивающих рамок.

5. Набор данных H3D
годы:2019Год;
автор:Honda Research Institute;
Количество сцен:общий160индивидуальный场景,открытый;
Количество категорий:общий8добрый;
Стоит ли собирать 360°:нет;
Общий объем данных:включать27,000 данных изображений и соответствующие им данные облаков точек;
Общее количество аннотаций:о1100,000 блоков 3D-аннотаций;
Модель датчика:общий配备Понятно3индивидуальный相机МодельGrasshopper 3. Все разрешения — 1920x1200. За исключением угла обзора задней камеры, который составляет 80°, угол обзора двух других камер составляет 90°. Используется 64-строчный LiDAR модели Velodyne. HDL64E S2 и модель GNSS+IMU ADMA-G;
Ссылка на набор данных:http://usa.honda-ri.com/H3D;
Введение:Исследовательский институт Хонды в2019Год3Выпустите свою систему автономного вождения в мартеданныенаборH3D。Долженданныенабор使用3D Сканер LiDAR собрал трехмерные данные обнаружения и отслеживания нескольких объектов, содержащие 160 многолюдных и интерактивных дорожных сцен с более чем 1 миллионом помеченных экземпляров в 27 721 кадре.

6. Набор данных ApplloScape
годы:2019Год;
автор:Baidu Research;
Количество сцен:общий103индивидуальный场景,открытый;
Количество категорий:общий26добрый,включая малые автомобили,big транспортные средства, пешеход, мотоциклист;
Стоит ли собирать 360°:нет;
Общий объем данных:включать143,906изображенияданные,и соответствующие данные облака точек;
Общее количество аннотаций:Общее количество аннотацийнеизвестный;
Модель датчика:общий Конфигурация Понятно2индивидуальныйVUX-1HA laser сканеры, 6 камер VMX-CS6 (две фронтальные камеры имеют разрешение 3384х2710) и лазерное устройство IMU/GNSS; сканеры используют два лазерных луча для сканирования окружающей среды с помощью широко используемого Velodyne. По сравнению с HDL64E, сканер может получать облака точек с более высокой плотностью и более высокой точностью (5 мм/3 мм);
Ссылка на набор данных:http://apolloscape.auto/index.html;
Введение:ApolloScapeЗависит отRGBВидео и соответствующая композиция плотного облака точек。Включать超过140Kкартинки,И каждое изображение имеет семантическую информацию на уровне пикселей. данные, собранные в стране,По сравнению с некоторыми зарубежными коллекциями данных,Набор ApolloScapeданные содержит более сложные дорожные сцены.,Большое количество разнообразных целей,И похож на набор KITTIданные,Также включает в себя легкий,Moderate,Жесткие три подмножества.

7. Набор данных Арговерс
годы:2019Год;
автор:Argo ИИ и т. д.;
Количество сцен:общий113индивидуальный场景,открытый,Включая США,Pennsylvania,Miami,Флорида и др.;
Количество категорий:общий15добрый,Включает автомобиль,Pedestrian,Stroller,Животное и т. д.;
Стоит ли собирать 360°:да;
Общий объем данных:включать44,000 данных изображений и соответствующие им данные облаков точек;
Общее количество аннотаций:о993,000 блоков 3D-аннотаций;
Модель датчика:иKITTIиnuScenesсходство,Набор данных Argoverse Конфигурация с двумя 32-проводными датчиками LiDAR,Номер модели — VLP-32. в то же время,Включает 7 камер кругового обзора высокого разрешения.,Разрешение 1920x1200.,2 фронтальные камеры,Разрешение 2056x2464;
Ссылка на набор данных:https://www.argoverse.org/;
Введение:ArgoverseвданныеотArgo Подмножество территорий, где тестируются беспилотные автомобили AI, в Майами и Питтсбурге — двух городах США с разными проблемами городского вождения и местными привычками вождения. Записи данных датчиков, или «сегменты журналов», включаются в разные сезоны, погодные условия и разное время суток, чтобы обеспечить широкий спектр реальных сценариев вождения. Он содержит 3D-аннотации отслеживания для 113 сцен, каждый сегмент длится 15–30 секунд, и содержит в общей сложности 11 052 цели отслеживания. Среди них 70% аннотированных объектов — транспортные средства, а остальные — пешеходы, велосипеды, мотоциклы и т. д. Кроме того, Argoverse содержит картографические данные высокой четкости, в основном включая 290 километров карт полос движения в Питтсбурге и Майами, например; как местоположение, соединения, сигналы светофора, высота и т. д. информация.
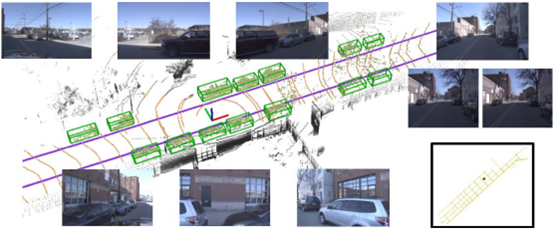
8. Набор данных Matterport3D
годы:2017Год;
автор:Princeton University,Stanford Университет и т. д.;
Количество сцен:общий90индивидуальный建筑物,внутренние сцены;
Общий объем данных:общий194,400 изображений RGB-D, 10,800 панорамных изображений, 24,727,520 текстурированных треугольников;
Модель датчика:Matterportизданныеполучать,Фотоаппаратура, установленная на штативе,Есть 3 цветные камеры и 3 камеры глубины.,Распространены в верхней, средней и нижней частях. для каждой панорамы,Его нужно повернуть вертикально в 6 разных сторон (то есть сделать снимок под углом 60 градусов),Каждая цветная камера снимает изображения с расширенным динамическим диапазоном. когда камера вращается,3 камеры глубины продолжают снимать данные,Интегрируйте для создания изображения глубины 1280x1024.,Зарегистрировано с каждой цветной фотографией. Каждое панорамное изображение состоит из 18 цветных изображений.,Центральная точка — это точно рост фотографирующего человека.
Ссылка на набор данных:https://niessner.github.io/Matterport/#explore;
Введение:Matterport3D,представляет собой массивный RGB-Дданный набор. Предоставляются реконструкция поверхности, поза камеры, а также аннотации семантической сегментации 2D и 3D. Matterport3D обеспечивает точное глобальное выравнивание и обширный, разнообразный набор панорам, охватывающих все здание.,Делает возможным выполнение различных задач компьютерного зрения.,включатьkeypoint matching、view overlap prediction、normal prediction、semantic segmentation,scene классификацияждать;

Reference
[1] https://blog.csdn.net/weixin_40994913/article/details/83663270;
[2] 3D Object Detection for Autonomous Driving: A Survey,Pattern Recognition;
[3] https://gas.graviti.com/open-datasets?usedScene=Autonomous+Driving&from=cn&page=2;
Эта статья предназначена только для академического обмена. Если есть какие-либо нарушения, свяжитесь с нами, чтобы удалить статью.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
