Самая мощная семантическая векторная модель Zhiyuan с открытым исходным кодом BGE! Китайские и английские оценки значительно превзошли OpenAI и Meta.
Источник: Исследовательский институт Чжиюань.
【Шин Джиген Введение】Чигенский университет Модель Добавление еще одного участника в технологический ландшафт——BAAI General Встраивание, китайские и английские оценки полностью превосходят OpenAI, Meta и т. д.
Семантическая векторная модель (модель внедрения) широко используется в таких важных областях, как поиск, рекомендации и интеллектуальный анализ данных.
В эпоху больших моделей это необходимая технология для решения различных ограничений или недостатков больших моделей, таких как проблемы иллюзий, проблемы своевременности знаний и проблемы сверхдлинного текста. Однако высококачественные семантические векторные модели в современном китайском мире по-прежнему относительно редки и редко имеют открытый исходный код.
Чтобы ускорить решение ограничений больших моделей, Wisdom недавно выпустила самую мощную коммерчески доступную китайскую и английскую семантичную векторную модель с открытым исходным кодом BGE (BAAI General Embedding), которая превосходит все аналогичные модели в сообществе как по семантической семантике на китайском, так и на английском языках. точность поиска и общие возможности семантического представления, такие как встраивание текста OpenAI 002 и т. д. Кроме того, BGE поддерживает наименьшую размерность вектора среди моделей с одинаковой величиной параметра и его использование дешевле.

FlagEmbedding:https://github.com/FlagOpen/FlagEmbedding
Ссылка на модель BGE: https://huggingface.co/BAAI/
Репозиторий кода BGE: https://github.com/FlagOpen/FlagEmbedding.
Ссылка на тест оценки C-MTEB: https://github.com/FlagOpen/FlagEmbedding/tree/master/benchmark
Все коды, связанные с этой моделью BGE, имеют открытый исходный код из проекта FlagEmbedding в рамках системы с открытым исходным кодом технологии больших моделей FlagOpen, нового раздела, посвященного технологиям и моделям внедрения. Исследовательский институт Чжиюань продолжит предоставлять академическим и промышленным кругам более полные полнофункциональные технологии для крупных моделей.
В то же время, ввиду отсутствия в настоящее время комплексных тестов для оценки в китайском сообществе, команда Zhiyuan выпустила самый большой и наиболее полный китайский тест для оценки возможностей представления семантических векторов C-MTEB (Chinese Massive Text Embedding Benchmark), который включает в себя 6 основных категорий задач оценки и 31 набор данных, закладывающих надежную основу для оценки способности комплексного представления китайских семантических векторов. Все тестовые данные и оценочные коды находятся в открытом доступе.
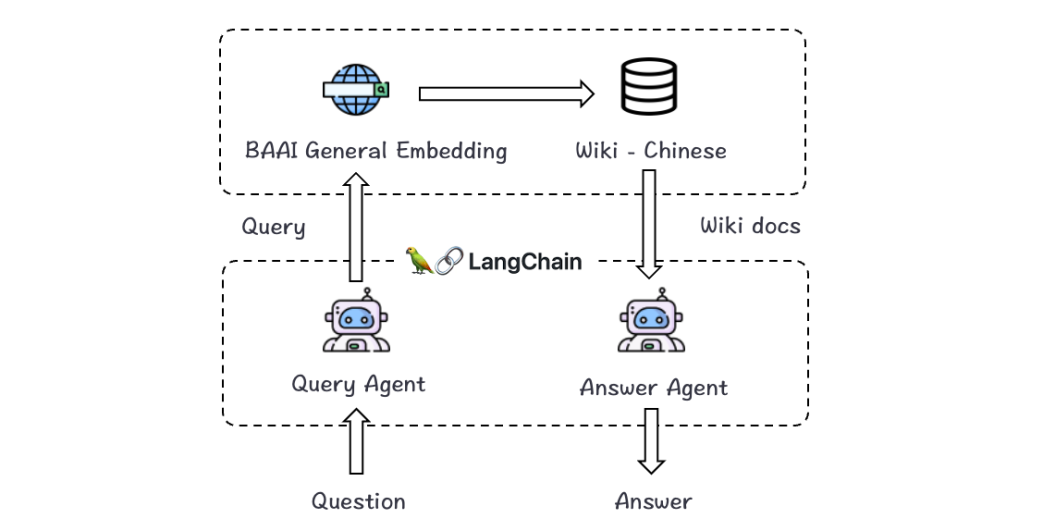
Хорошие новости, достойные внимания разработчиков приложений для крупных моделей: объединив LangChain с Zhiyuan BGE, вы можете легко настроить помощников по вопросам и ответам на местные знания, не тратя больше средств на обучение вертикальных больших моделей.
Точность поиска значительно выше: отличная производительность при выполнении 87 задач на китайском и английском языках.
BGE в настоящее время является самой мощной семантической векторной моделью для китайских задач, а ее возможности семантического представления полностью превосходят аналогичные модели с открытым исходным кодом.
Экспериментальные результаты C-MTEB, оценки способности комплексного представления китайских семантических векторов (таблица 1), показывают, что китайская модель BGE (BGE-zh) имеет особенно значительное преимущество в возможностях поиска, наиболее часто используемых в больших языках. модели, а точность извлечения примерно в 1,4 раза выше, чем у OpenAI Text Embedding 002.
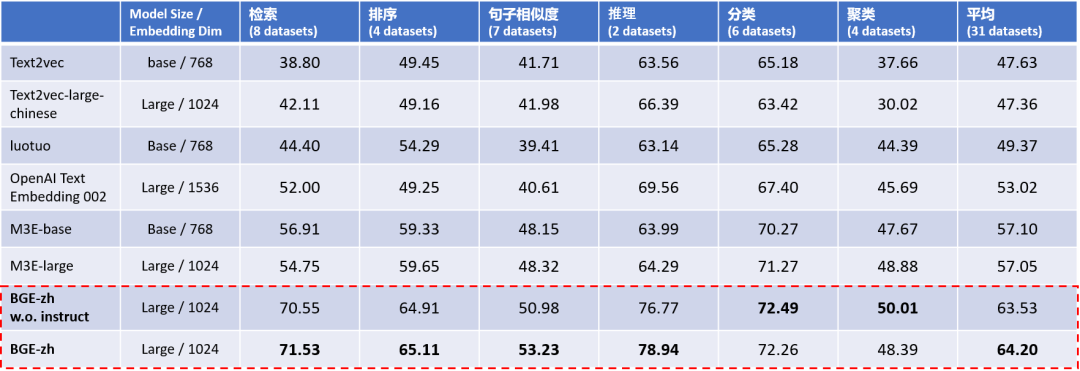
Таблица 1. Оценка способности комплексного представления китайских семантических векторов (C-MTEB)
Примечание: База ~100M, Большой ~300M, XXL ~11BBGE в столбце «Размер модели» без инструкции: Входной терминал BGE не использует инструкцию.
Как и в случае с китайским языком, способность семантического представления английской модели BGE (BGE-en) также превосходна. Согласно результатам оценки английского эталонного теста MTEB (таблица 2), несмотря на то, что в сообществе существует множество отличных базовых моделей, BGE по-прежнему превосходит все предыдущие аналогичные модели с открытым исходным кодом по двум основным параметрам: общий показатель (средний) и возможности поиска. (Поиск).
При этом возможности BGE значительно превосходят самый популярный вариант в сообществе: OpenAI Text Embedding 002.
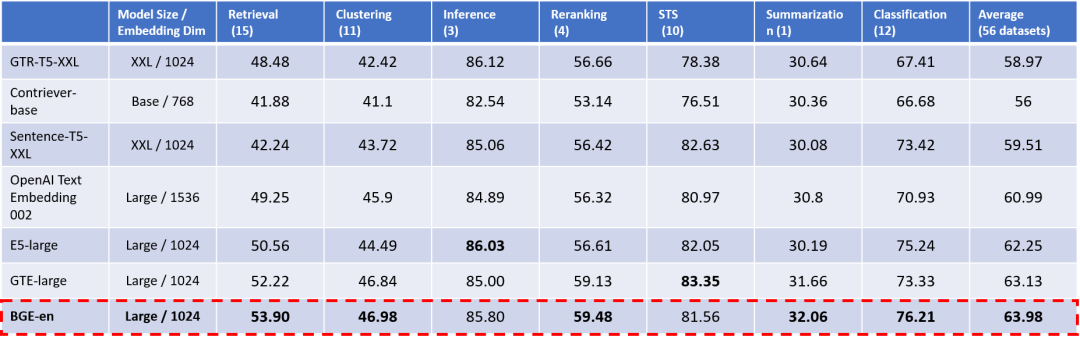
Таблица 2. Оценка способности комплексного представления английских семантических векторов (MTEB) Примечание. В столбце «Размер модели» укажите «Базовый ~100M», «Большой» ~300M, XXL ~11B.
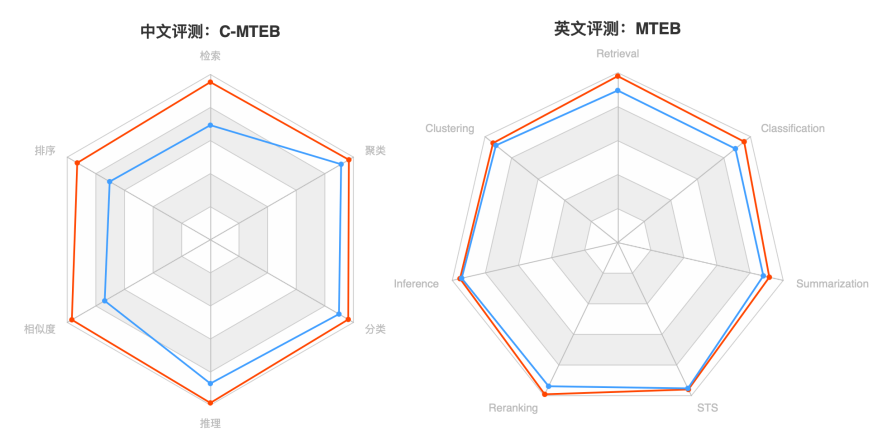
Рисунок 1. Китайский C-MTEB (слева), английский MTEB (справа). Примечание. BGE — красный, OpenAI Text Embedding 002 — синий.
Китайский семантический вектор, комплексный тест оценки C-MTEB
Ранее китайскому сообществу не хватало всеобъемлющего и эффективного эталона оценки. Исследовательская группа BGE полагалась на существующие китайские наборы данных из открытых источников для создания эталона оценки китайских семантических векторов, C-MTEB (Chinese Massive Text Embedding Benchmark, как показано на рисунке). Таблица 3).
Конструкция C-MTEB отсылает к английскому эталону MTEB [12] той же категории, который охватывает в общей сложности 6 основных категорий задач оценки (поиск, сортировка, сходство предложений, рассуждение, классификация и кластеризация) и включает в себя 31 связанную задачу. наборы данных.
C-MTEB в настоящее время является крупнейшим и наиболее полным тестом оценки китайских семантических векторов, обеспечивающим экспериментальную основу для надежного и всестороннего тестирования возможностей комплексного представления китайских семантических векторов.
В настоящее время все тестовые данные и оценочный код C-MTEB находятся в открытом доступе вместе с моделью BGE.
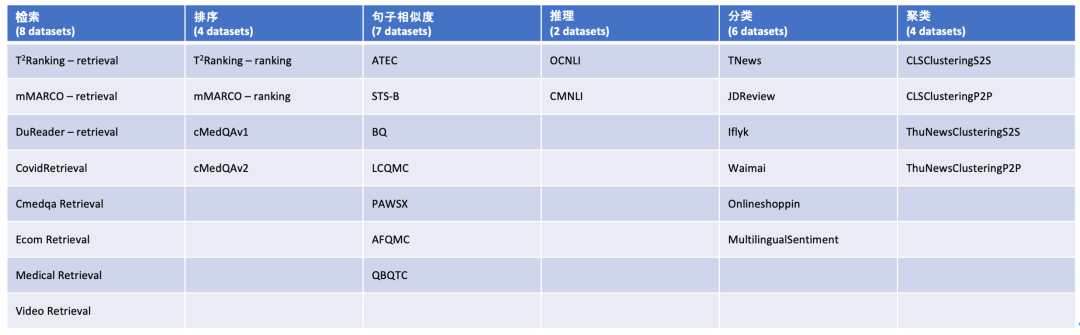
Таблица 3. Размеры задачи оценки C-MTEB и наборы данных
Технические особенности: эффективное предварительное обучение + крупномасштабная точная настройка текстовых пар.
Превосходные возможности семантического представления BGE основаны на двух элементах: 1) предварительном обучении представлению и 2) крупномасштабном обучении текстовых пар.
BGE использует алгоритм предварительного обучения RetroMAE [5,6] (рис. 2) для представления в двух крупномасштабных корпусах Wudao [10] и Pile [11]: входные данные с низкой частотой маски кодируются в семантический вектор (Embed ), а затем объединить входные данные с высокой степенью маскировки с семантическим вектором, чтобы восстановить исходные входные данные. Таким образом, BGE может использовать немаркированный корпус для адаптации базы языковой модели к задачам семантического представления.
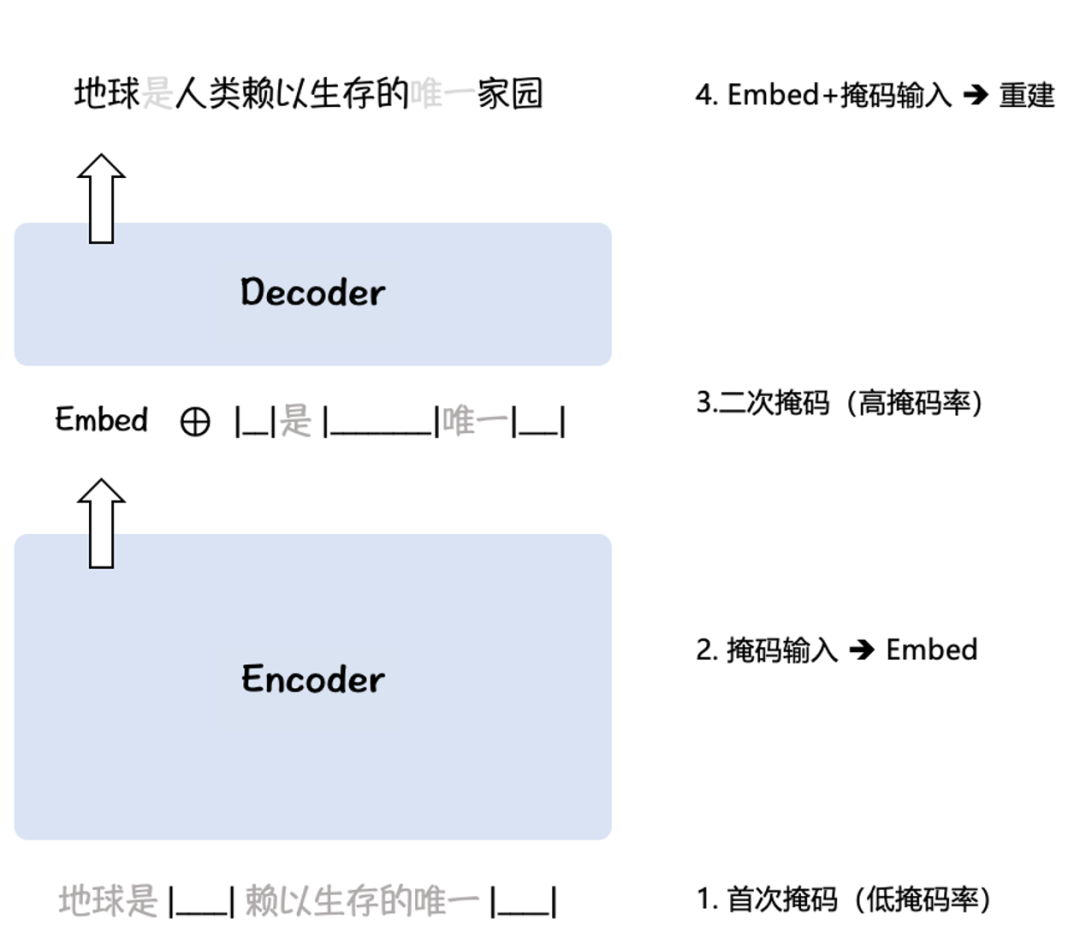
Рисунок 2. Схема алгоритма предварительного обучения RetroMAE
BGE сконструировала до 120 млн и 232 млн пар выборок данных для китайского и английского языков соответственно, тем самым помогая модели справляться с различными задачами семантического сопоставления в реальных сценариях, а также с помощью усиления отрицательной выборки [7] и интеллектуального анализа выборки из сложных в отрицательные [7]. 8] дополнительно повышает сложность контрастного обучения, достигает размера отрицательной выборки до 65 тыс. и повышает различительную способность семантических векторов.
Кроме того, BGE опирается на идею настройки инструкций [9], применяет асимметричный метод добавления инструкций и добавляет описания сцен со стороны проблемы, улучшая общие возможности семантических векторов в многозадачных сценариях, как показано на рисунке. 3:
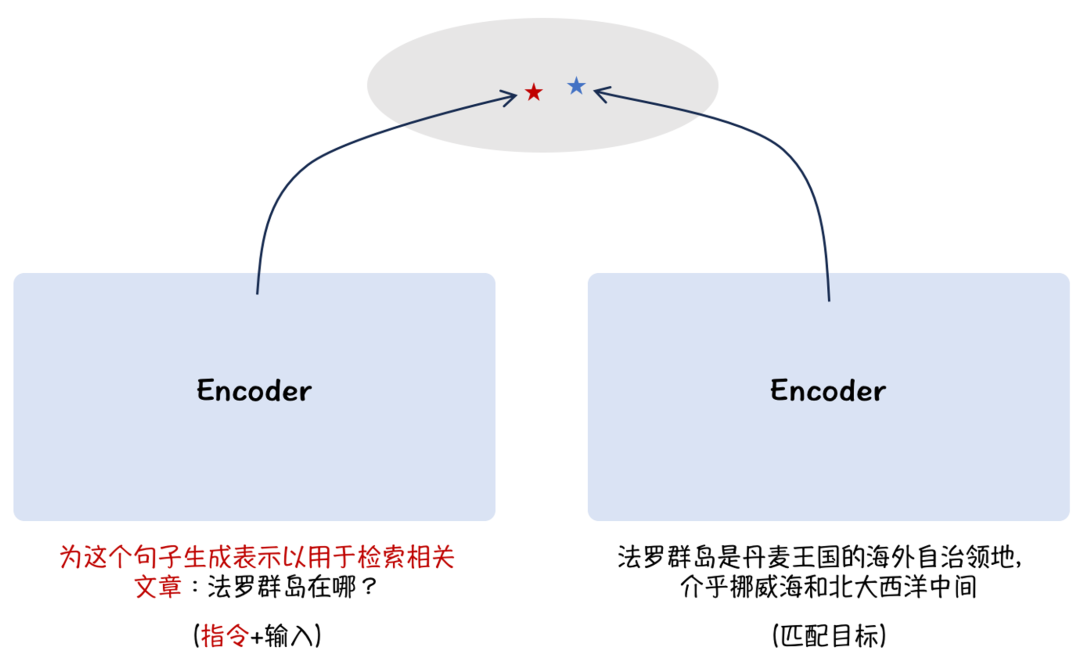
Рисунок 3. Внедрение подсказок сцены для улучшения многозадачности
Таким образом, BGE в настоящее время является наиболее эффективной семантической векторной моделью, особенно с точки зрения возможностей семантического поиска.
Его выдающиеся возможности предоставляют важные функциональные компоненты для создания больших приложений языковых моделей (таких как понимание прочитанного, ответы на вопросы в открытой области и диалог на основе знаний). По сравнению с предыдущими моделями с открытым исходным кодом, BGE не увеличивает размер модели или векторные размеры, тем самым сохраняя ту же эффективность работы и хранения.
В настоящее время как китайская, так и английская модели BGE имеют открытый исходный код, а код и веса соответствуют протоколу MIT, поддерживая бесплатное коммерческое использование.
Являясь важной частью системы с открытым исходным кодом технологии больших моделей FlagOpen компании Wisdom, BGE будет продолжать совершенствовать и обновлять ее, чтобы расширить возможности создания большой модели экологической инфраструктуры.
Ссылка на модель BGE: https://huggingface.co/BAAI/
Репозиторий кода BGE: https://github.com/FlagOpen/FlagEmbedding.
Официальный сайт FlagOpen: https://flagopen.baai.ac.cn/
Расширение знаний о семантических векторных моделях
1. Что такое семантическая векторная модель?
Семантическая векторная модель (модель внедрения) широко используется в таких важных областях, как поиск, рекомендации и интеллектуальный анализ данных. Она преобразует образцы данных естественной формы (такие как язык, код, изображения, аудио и видео) в векторы (т. е. непрерывные цифровые данные). последовательности) и использует «Расстояние» между векторами измеряет «корреляцию» между выборками данных.
2. В эпоху больших моделей необходимы технологии, помогающие облегчить проблемы с галлюцинациями, проблемы с долговременной памятью и т. д.
- Приобретать знания в ногу со временем
Оно может основываться только на поэтапных «жестких» резервах знаний при обучении моделей, что является важным фактором, приводящим к галлюцинациям у крупных моделей при ответе на вопросы. С помощью семантических векторных моделей крупные модели могут получить «живые знания», идущие в ногу со временем, а ответы новые и точные. В частности, установление индекса базы знаний (Индекс) в определенной вертикальной области с помощью семантической векторной модели может эффективно дополнять мировые и местные знания для больших моделей: когда пользователь задает LLM вопрос, LLM получит его из самых последних и наиболее полных данных. База знаний Ответ.
- Улучшение долговременной памяти для больших моделей.
Большие модели надолго застряли в долговременной памяти. Существующие LLM имеют ограничения на длину входных данных контекста, что ограничивает возможности обработки длинных текстов. Используя модель семантического вектора, длинные документы можно структурировать для лучшего прямого взаимодействия с LLM, тем самым компенсируя недостатки возможностей обработки длинного текста.
3. Ключевые преимущества таких звездных приложений, как LangChain
OpenAI, Google, Meta и другие производители запустили модели семантических векторов и службы API для больших моделей, что напрямую способствовало рождению многих влиятельных инфраструктур и инструментов приложений для больших моделей в глобальном сообществе разработчиков больших моделей: таких как платформа приложений для больших моделей LangChain. , векторное хранилище базы данных Pinecone, инструмент индексирования форматирования документов Llama Index, помощник AutoGPT, умеющий самостоятельно «продумывать» шаги и выполнять задачи и т. д.
Ссылки:
[1] Unsupervised Dense Information Retrieval with Contrastive Learning (Contriever), https://arxiv.org/pdf/2112.09118.pdf
[2] Large Dual Encoders Are Generalizable Retrievers (GTR), https://aclanthology.org/2022.emnlp-main.669.pdf
[3] Text Embeddings by Weakly-Supervised Contrastive Pre-training (E5), https://arxiv.org/abs/2212.03533
[4] Introducing text and code embeddings (OpenAI Text Embedding), https://openai.com/blog/introducing-text-and-code-embeddings , https://openai.com/blog/new-and-improved-embedding-model
[5] RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder (RetroMAE), https://aclanthology.org/2022.emnlp-main.35/
[6] RetroMAE-2: Duplex Masked Auto-Encoder For Pre-Training Retrieval-Oriented Language Models (RetroMAE-2), https://aclanthology.org/2023.acl-long.148/
[7] Tevatron: An Efficient and Flexible Toolkit for Dense Retrieval (Tevatron), https://github.com/texttron/tevatron
[8] Dense Passage Retrieval for Open-Domain Question Answering (DPR), https://arxiv.org/abs/2004.04906
[9] One Embedder, Any Task: Instruction-Finetuned Text Embeddings (Instructor), https://instructor-embedding.github.io
[10] Wudao Corpora (Удао), https://github.com/BAAI-WuDao/Data
[11] The Pile: An 800GB Dataset of Diverse Text for Language Modeling (Pile), https://github.com/EleutherAI/the-pile
[12] MTEB: Massive Text Embedding Benchmark (MTEB), https://huggingface.co/blog/mteb



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
