SAM2 (Segment Anything Model 2) сегментация нового поколения для любой крупной модели, практическое резюме
Segment Anything Model 2 (SAM 2) Сегмент выпущен как компания Meta Модернизированная версия Anything Model (SAM), продемонстрировавшая значительную производительность в области сегментации изображений.

Ссылка на документ: https://arxiv.org/pdf/2408.00714.
Demo: https://sam2.metademolab.com Code: https://github.com/facebookresearch/segment-anything-2 Website: https://ai.meta.com/sam2
преимущество
- Повышенная точность сегментации:
- По сравнению с оригинальной моделью SAM, SAM 2 улучшил точность сегментации,Возможность более точно идентифицировать и сегментировать объект на изображениях и видео.
- Скорость обработки увеличена:
- SAM 2 увеличивается примерно в шесть раз, что позволяет быстрее генерировать маски сегментации, что подходит для сценариев приложений, требующих быстрого реагирования.
- Поддержка сегментации видео:
- Помимо сегментации изображений, SAM 2 также поддерживает сегментацию объектов в видео, предоставляя мощные инструменты для обработки и анализа видео.
- Возможность обработки в реальном времени:
- SAM 2 идеально подходит для приложений, требующих обработки в реальном времени.,Такие как приложения дополненной реальности (AR) и виртуальной реальности (VR).,Способен сегментировать среду вокруг пользователя в режиме реального времени.
- Способность обобщения Zero-Shot:
- SAM 2 имеет хорошие возможности нулевой миграции.,Может работать с невидимыми данными без дополнительного обучения.,Это позволяет применять его в самых разных визуальных областях.
- Обширные данные обучения:
- SAM Обучающий набор из 2 содержит 11 миллионов изображений и 11 миллиардов масок. данные обученияделатьSAM 2 становится мощной отправной точкой для обучения новым задачам сегментации изображений.
характеристика
- Архитектура модели с подсказками:
- SAM 2 может реагировать на различные запросы, например, на нажатие、коробка、даже текст)для получения результатов сегментации,Такая гибкость позволяет пользователям легко определять целевые объекты в соответствии со своими потребностями.
- Архитектура кодировщика-декодера:
- SAM 2, скорее всего, продолжит использовать Архитектуру кодировщика-декодера,Кодировщик отвечает за извлечение функций,Декодер используется для генерации масок сегментации.
- Эффективный сетевой дизайн:
- Для увеличения скорости обработки SAM 2, может использовать оптимизированную сетевую структуру или более эффективные в вычислительном отношении компоненты.
- Адаптируемая делительная головка:
- Модель оснащена очень гибкой раскалывающей головкой.,Возможность генерировать соответствующие маски на основе разных подсказок.,Таким образом, адаптируясь к различным задачам сегментации.
- Поддержка мультимодального ввода:
- В дополнение к традиционному вводу изображений, SAM 2 также поддерживает последовательности видеокадров в качестве входных данных для сегментации видео.
- модуль внимания памяти:
- SAM 2 оснащен модулем внимания памяти,сосредоточиться на целевом объекте предыдущие воспоминания,Хранить информацию о предыдущих взаимодействиях,Это позволяет ему генерировать прогнозы по маске на протяжении всего видео.,И эффективно корректировать эти прогнозы на основе контекста памяти, хранящегося в ранее наблюдаемых кадрах.
- Поддержка задач PVS:
- Предоставляйте подсказки модели в любом кадре видео (например, положительный/отрицательный щелчок).、границакоробкаилиmask),Модель может распространять эти советы по получению объектной маски по всему видео.
- Открытый исходный код и поддержка сообщества:
- Мета со свободным Apache Лицензия 2.0 с общим SAM Код iModel с весом 2 способствует исследованиям и применению в сообществе.
SAM 2 продемонстрировал значительные преимущества и широкие перспективы применения в области сегментации изображений и видео благодаря своей высокой точности, высокой скорости, обширным возможностям поддержки и мощным возможностям генерализации с нулевым кадром.
Настоящий бой
Существует два способа реализации вывода SAM: напрямую использовать официальную модель SAM2, а другой — использовать Ultralytics.
SAM2 Настоящий бойец по мотивам официальной Модели.
Ссылка на гитхаб:
https://github.com/facebookresearch/segment-anything-2
Необходимо установить перед использованием SAM 2。потребности кодаpython>=3.10,а такжеtorch>=2.3.1и。Пожалуйста, следуйте здесьtorchvision>=0.18.1Инструкции по установке PyTorch и TorchVision Зависимости. Вы можете использовать следующее, чтобы GPU Установить на машину SAM 2:
git clone https://github.com/facebookresearch/segment-anything-2.git
cd segment-anything-2; pip install -e .
Затем загрузите модель: sam2_hiera_tiny.pt:
https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_tiny.pt
sam2_hiera_small.pt:
https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_small.pt
sam2_hiera_base_plus.pt:
https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_base_plus.pt
sam2_hiera_large.pt:
https://dl.fbaipublicfiles.com/segment_anything_2/072824/sam2_hiera_large.pt
тестовое изображение
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
Тестовое видео
import torch
from sam2.build_sam import build_sam2_video_predictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and instantly get the output on the same frame
frame_idx, object_ids, masks = predictor.add_new_points_or_box(state, <your_prompts>):
# propagate the prompts to get masklets throughout the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...
Способ 2: Вызов на основе инкапсуляции пакета Ultralytics
Установите необходимые пакеты。Установитьultralyticsи убедитесь, что его версия>=8.2.70,torchверсия тоже нужна>=2.0или Используйте последнюю версию напрямую
pip install -U ultralytics
Загрузите модель сегментации. Ссылка следующая:
СЭМ 2 маленькая ссылка:
https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_t.pt
SAM 2 small:
https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_s.pt
SAM 2 base
https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_b.pt
SAM 2 large
https://github.com/ultralytics/assets/releases/download/v8.2.0/sam2_l.pt
глобальная сегментация
from ultralytics import ASSETS, SAM
# Load a model
model = SAM("sam2_s.pt")
# Display model information (optional)
model.info()
# Segment image or video
results = model('car.jpg') # картинка рассуждения
# Display results
for result in results:
result.show()
Укажите точки или прямоугольные области для вывода изображений.
from ultralytics import SAM
# Load a model
model = SAM("sam2_b.pt")
# Display model information (optional)
model.info()
# Segment with bounding box prompt
results = model("path/to/image.jpg", bboxes=[100, 100, 200, 200])
# Segment with point prompt
results = model("path/to/image.jpg", points=[150, 150], labels=[1])
for result in results:
result.show()
видео рассуждения
from ultralytics import SAM
# Load a model
model = SAM("sam2_b.pt")
# Display model information (optional)
model.info()
# Run inference
model("path/to/video.mp4")
Сравнение SAM 2 и YOLOv8
Здесь мы сравниваем минимальную модель SAM 2 Meta SAM2-t с минимальной моделью сегментации YOLOv8n-seg от Ultralytics:
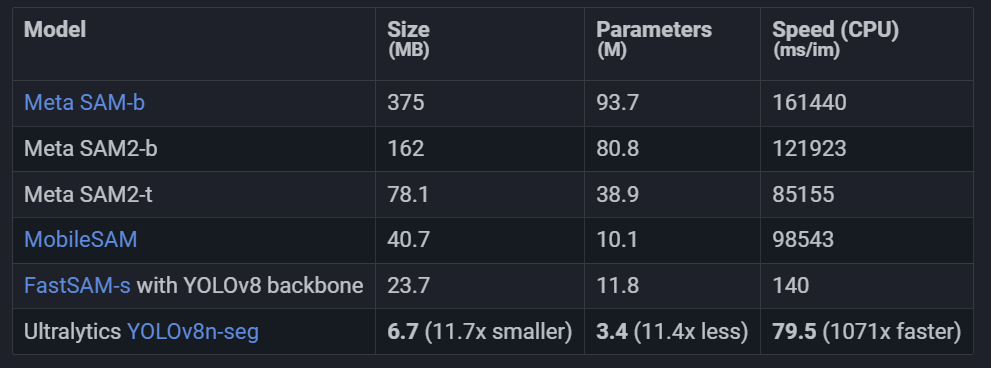
Это сравнение показывает Модельразмери Разница в скорости на порядок。Хотя SAM имеет уникальную возможность автоматически сегментировать, но это не YOLOv8 Прямой конкурент моделей сегментации, поскольку YOLOv8 Модели меньше, быстрее и эффективнее.
Автоматизированное аннотирование: эффективное создание набора данных
Автоматическое аннотирование — это мощная функция SAM 2, которая позволяет пользователям использовать предварительно обученные модели для быстрого и точного создания сегментированных наборов данных. Эта функция особенно полезна при создании больших наборов данных высокого качества без обширной ручной работы.
Используйте SAM 2 для автоматической маркировки вашего набора данных. Код выглядит следующим образом:
from ultralytics.data.annotator import auto_annotate
auto_annotate(data="path/to/images", det_model="yolov8x.pt", sam_model="sam2_b.pt")
параметр | тип | описывать | значение по умолчанию |
|---|---|---|---|
data | str | Путь к папке, содержащей изображения для аннотирования. | |
det_model | str, optional | Предварительно обученная модель обнаружения YOLO. По умолчанию — «yolov8x.pt». | 'yolov8x.pt' |
sam_model | str, optional | Предварительно обученная 2-сегментационная модель SAM. По умолчанию — «sam2_b.pt». | 'sam2_b.pt' |
device | str, optional | Устройство, на котором работает модель. По умолчанию пустая строка (ЦП или ГП, если доступен). | |
output_dir | str, None, optional | Каталог для сохранения результатов аннотаций. По умолчанию это папка «метки» в том же каталоге, что и «данные». | None |



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
