Руководство по выбору озера данных | Hudi и Iceberg. Углубленное сравнение возможностей обновления данных.
озеро данныхКак новое поколение инфраструктуры больших данных,продолжает оставаться популярным в последние годы,Многие передовые студенты обсуждают озеро Как следует строить данные Многие компании также строят или планируют построить собственное озеро? данных。На основании этого,естественно, породило множество опасений по поводуозеро данных Выборизобсуждатьи Исследовать。Но после поиска мы нашли,Большая часть того, что существует в Интернете, основана на более ранней информации из открытых источников.,На ранних стадиях исследования предприятия легко создать ошибочные впечатления и представления.
Итак, с этим вопросом,Планируем запустить серию статей по выбору озера данных.,На основе последней информации из открытых источников,отМодернизация архитектуры озера данныхНесколько важных широт, которые помогут вам провести более глубокие сравнения。Я надеюсь, что это может вдохновить других,Заставьте всех думать и резонировать,Учащиеся могут обсудить это вместе.
На практике мы обнаружили,Среди клиентов, планирующих обновить архитектуру озера данных,Поддержка транзакционных обновлений данныхОбычно это первый основной запрос каждого.。поэтому,В первой статье этой серии мы начнем с истории возникновения спроса.,и другое озеро Сравнение возможностей архитектуры данных при транзакциях данных, два аспекта помогают каждому в озере данных Принимайте более обоснованные решения на пути к выбору.
Фон спроса
В традиционной архитектуре автономного хранилища данных Hive стоимость обновления данных очень высока. Обновление части данных требует перезаписи всего раздела или даже всей таблицы. Поэтому в реальных бизнес-сценариях из-за таких соображений, как затраты на разработку и риски данных, никто не будет обновлять данные в хранилище данных Hive.
Однако с запуском Hive 3.0 таблицы Hive сделали большой шаг вперед в возможностях транзакций. При запуске 3.0 чиновник также сосредоточился на продвижении своих транзакционных возможностей. Однако в практическом применении все еще существуют очень большие ограничения, и очень немногие пользователи действительно внедрили его в производство. (Поддерживаются только внутренние таблицы транзакций ORC, а это означает, что вычислительные механизмы, такие как Spark, не могут напрямую выполнять разработку ETL/ELT для таблиц транзакций Hive. Такие компании, как CDH и Kangaroo Cloud, вложили средства в совместимость со Spark, но эффект не очень хороший. Отлично, намного меньше, чем ожидаются от приложений производственного уровня)
поэтому,В процессе отбора данных озера,Возможность эффективного одновременного обновлениястановится особенно важным。Это может изменить нашу Hive Хранилище данных сталкивается с проблемой высоких затрат на обновление данных и поддерживает обновление и удаление огромных объемов автономных данных.
Выбор реализации обновления данных
В настоящее время на рынке представлено несколько основных продуктов озера данных с открытым исходным кодом: Apache Iceberg, Apache Hudi и Delta.
В этой статье основное внимание будет уделено производительности Hudi и Iceberg при реализации обновления данных.
Реализация обновления данных Hudi
Hudi (Hadoop Update Delete Incremental), как видно из названия, был рожден для решения проблем обновления данных и инкрементных запросов в системе Hadoop. Чтобы понять, как Hudi реализует операции быстрого обновления в файловых системах, таких как HDFS, нам необходимо сначала понять несколько особенностей Hudi:
· Форма организации файлов таблицы Hudi: В каждом разделе (Partition) файлы данных разделены и организованы в группы файлов (FileGroup), и каждая группа файлов уникально идентифицируется FileID.
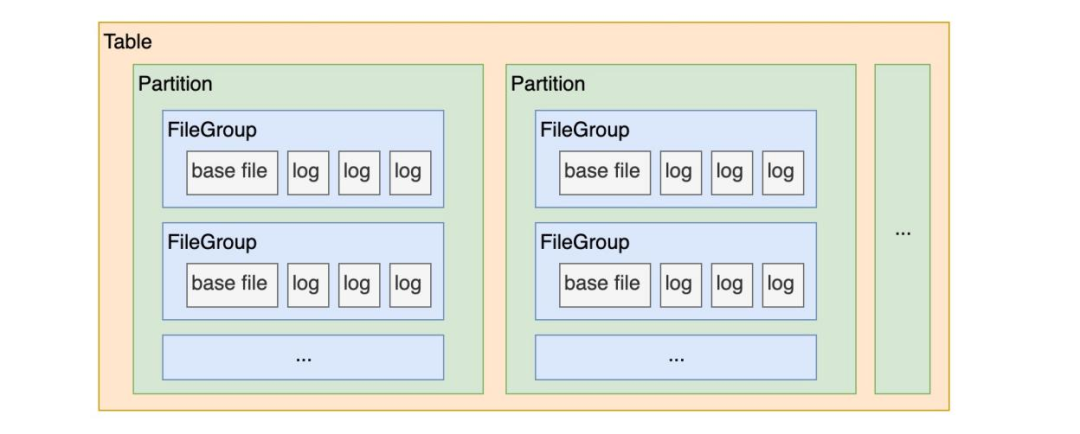
· Hudi Есть столДизайн индексаиз。
Объединив приведенные выше три характеристики, можно сделать вывод, что индекс таблицы Hudi может помочь нам быстро найти определенный фрагмент данных, существующий в определенной файловой группе определенного раздела, а затем выполнить над ним операцию обновления, т.е. , перепишите эту часть файловой группы.
Реализация обновления данных Iceberg
Iceberg из Официальное позиционирование такое.「Эффективный формат хранения для сценариев анализа больших объемов данных.」。Так что это не похоже на Hudi Он также имитирует шаблон проектирования бизнес-базы данных (первичный ключ + индекс) для обновления данных, но разрабатывает более мощную форму организации файлов для обновления данных. update Подробности эксплуатации см. на рисунке ниже:
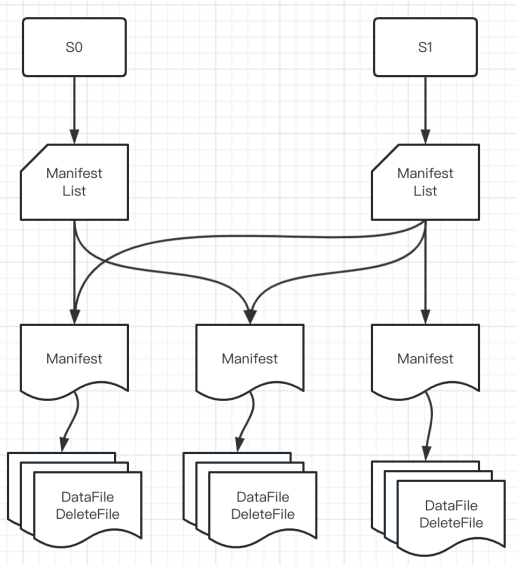
• Снимок: каждая фиксация пользователя создает новый снимок.
• Список манифестов: сохраняет все манифесты в текущем снимке.
• Манифест: сохраняет все файлы данных и удаляет файлы в текущем манифесте.
• Файл данных: файл, в котором хранятся данные.
• Удалить файл: файл, в котором хранятся «удаленные данные».
Основываясь на приведенной выше организации файлов, мы видим, что общая логика реализации обновления Iceberg такова:
· Сначала запишите удаляемые данные в «Удалить файл»;
· Затем «Файл данных» JOIN «Удалить файл» используется для сравнения данных для обновления данных.
Конечно, существует множество технических деталей для реализации этих двух шагов: например, использование порядкового номера для обеспечения порядка транзакций; «Удалить файл» определяет, следует ли использовать логику удаления позиции или удаления по равенству, на основе статуса файла на момент удаления; введение концепции равенства_идов для имитации первичных ключей и т. д.
Как выбрать
Просто посмотрим на это с точки зрения возможностей обновления данных:
· Hudi использует шаблон проектирования группа файлов + индекс + первичный ключ.,способен быть эффективнымУменьшите количество избыточных обновлений файлов данных.,Повысьте эффективность обновления данных.
· Iceberg также может добиться эффекта обновления данных за счет проектирования файловой организации, но при каждой фиксации будут создаваться новые файлы. Если запись/обновление происходит часто, проблема небольших файлов будет более серьезной. (Хотя официальный пакет также предоставляет небольшие возможности управления файлами, потребление ресурсов и сложность управления этой частью относительно выше, чем у Hudi)
Как применить это на практике
После того, как мы определимся с выбором озера данных, следующим вопросом становится то, как реализовать практическое применение в производственной среде.
Здесь нужно заранее разобраться с понятием типа таблицы,такой же видозеро данных表格式也有不同из Разница типов,Применимо к различным сценариям:
• COW (Копирование при записи): копирование таблицы при записи. Когда данные записываются/обновляются, исходный файл данных немедленно перезаписывается и создается новый файл данных.
• MOR (объединить при чтении): объединить таблицы при чтении. Когда данные записываются/обновляются, исходный файл не изменяется, записывается новый журнал/файл, а когда данные читаются позже, файл данных перезаписывается.
Исходя из разницы характеристик этих двух типов столов, мы даем следующие предложения:
· Если ваша таблица Lake нечасто записывается/обновляется и в основном используется для поддержки сценариев запроса/анализа данных, рекомендуется использовать таблицу COW.
· Если ваша таблица Lake часто записывается/обновляется (даже для сценариев разработки в реальном времени), рекомендуется использовать таблицу MOR.
Подвести итог
Не существует лучшей технической архитектуры, есть только наиболее подходящая техническая архитектура для текущего бизнеса.
Конечно, выбор озера данных нельзя судить только по одному параметру — возможности обновления данных. В будущем мы продолжим проводить сравнения различных архитектур озер данных по большему количеству измерений, таких как управление схемами, ускорение запросов и интеграция пакетных потоков. Приглашаем всех обсудить и пообщаться с нами.
Адрес для скачивания «Белой книги по отраслевой практике управления данными»:https://fs80.cn/380a4b
Адрес проекта:https://github.com/DTStack



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
