Руководство по развертыванию для использования TensorRT-LLM в производственной среде
TensorRT-LLM — это платформа с открытым исходным кодом, разработанная Nvidia для повышения производительности больших языковых моделей в производственных средах. Платформа основана на платформе компиляции глубокого обучения TensorRT для построения, компиляции и выполнения графиков вычислений, а также опирается на многие эффективные реализации ядра в FastTransformer и может использовать NCCL для завершения связи между устройствами.

Хотя такие платформы, как vLLM и TGI, являются отличной отправной точкой для расширенного вывода, им не хватает некоторых оптимизаций, что затрудняет их масштабирование в рабочей среде. Поэтому Nvidia разработала TensorRT-LLM на основе TensorRT. Крупные компании, такие как Anthropic, OpenAI, Anyscale и т. д., уже используют эту платформу для предоставления услуг LLM миллионам пользователей.
TensorRT-LLM
В отличие от других методов вывода, TensorRT LLM не использует необработанные веса для обслуживания модели. Он компилирует модель и оптимизирует ядро, чтобы ее можно было эффективно использовать на графических процессорах Nvidia. Преимущества в производительности от запуска скомпилированных моделей намного выше, чем от запуска исходных моделей. Это одна из основных причин, почему TensorRT LLM работает так быстро.

Необработанные веса модели передаются компилятору вместе с параметрами оптимизации, такими как уровень квантования, тензорный параллелизм, конвейерный параллелизм и т. д. Затем компилятор берет эту информацию и выводит двоичный файл модели, оптимизированный для конкретного графического процессора.
Но здесь весь процесс компиляции модели должен выполняться на графическом процессоре. Полученная скомпилированная модель также специально оптимизирована для графического процессора, на котором она выполняется. Например, если вы скомпилируете модель на графическом процессоре A40, возможно, вы не сможете запустить ее на графическом процессоре A100. Поэтому независимо от того, какой графический процессор используется во время компиляции, для вывода необходимо использовать один и тот же графический процессор.
Однако TensorRT LLM не поддерживает все большие языковые модели «из коробки» (причина в том, что архитектура каждой модели различна). Однако глубокая оптимизация на уровне графа, выполненная TensorRT, поддерживает большинство популярных моделей, таких как Mistral, Llama и Qwen. Конкретные поддерживаемые модели можно найти в официальном списке TensorRT LLM Github.
Преимущества TensorRT-LLM
Пакет Python TensorRT LLM позволяет разработчикам запускать LLM с максимальной производительностью без знания C++ или CUDA.
Внимание к страницам
Большие языковые модели требуют больших объемов памяти для хранения ключей и значений каждого токена. По мере того как входная последовательность становится длиннее, использование памяти может стать очень большим.
Обычно ключи и значения последовательности должны храниться рядом. Таким образом, даже если вы освободите место в памяти последовательности, вы не сможете использовать это пространство для других последовательностей. Это приводит к фрагментации и отходам.
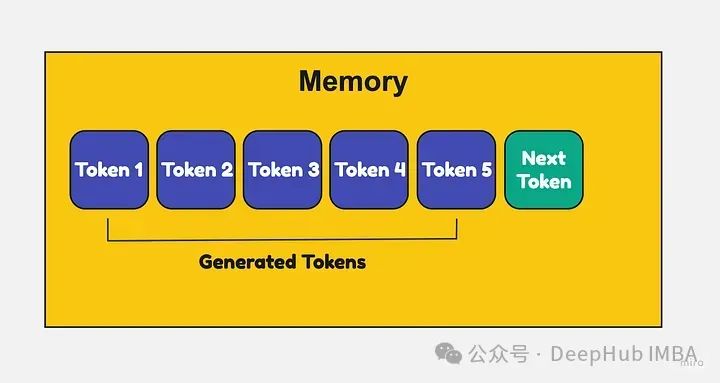
Внимание к страницам Разделяйте ключи/значения на страницы, а не на смежные страницы.,Это можно разместить в любом месте памяти.,Если вы отпустите некоторую нумерацию страниц посередине,Затем эти пространства можно использовать для других последовательностей.
Это предотвращает фрагментацию и позволяет более эффективно использовать память. Страницы могут динамически выделяться и освобождаться по мере необходимости при создании выходной последовательности.
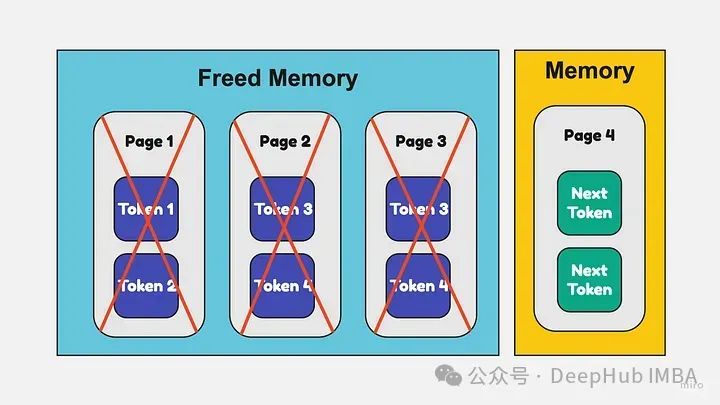
Эффективный KV-кэш
llm имеют миллиарды параметров, что делает их медленными и требует много памяти при выполнении вывода. KV-кэш помогает решить эту проблему, кэшируя выходные данные слоев и активации LLM, поэтому их не нужно пересчитывать для каждого вывода.
Вот как это работает:
Во время вывода, когда LLM выполняет каждый уровень, выходные данные кэшируются в хранилище значений ключей с уникальными ключами. Когда последующие выводы используют те же входные данные слоя, вместо повторного вычисления слоя кэшированные выходные данные извлекаются с помощью ключа. Это позволяет избежать избыточных вычислений, уменьшает активируемую память и повышает скорость вывода и эффективность памяти.
Далее мы начинаем развертывать модель с помощью TensorRT-LLM.
Руководство по развертыванию TensorRT-LLM
Первым шагом для развертывания модели с использованием TensorRT-LLM является ее компиляция. Здесь мы будем использовать инструкцию Mistral 7B v0.2. Для фазы компиляции требуется графический процессор, поэтому для удобства мы работаем непосредственно с Colab.
TensorRT LLM в основном поддерживает высокопроизводительные графические процессоры Nvidia. Поэтому мы выбрали графический процессор A100 40 ГБ на Colab.
Загрузите git-библиотеку TensorRT-LLM. Этот репозиторий содержит все модули и скрипты, необходимые для компиляции модели.
!git clone https://github.com/NVIDIA/TensorRT-LLM.git
%cd TensorRT-LLM/examples/llamaЗатем установите необходимые пакеты
!pip install tensorrt_llm -U --pre --extra-index-url https://pypi.nvidia.com
!pip install huggingface_hub pynvml mpi4py
!pip install -r requirements.txtСкачать модель
from huggingface_hub import snapshot_download
from google.colab import userdata
snapshot_download(
"mistralai/Mistral-7B-Instruct-v0.2",
local_dir="tmp/hf_models/mistral-7b-instruct-v0.2",
max_workers=4
)На этом этапе вы можете просмотреть каталог tmp/hf_models Colab, где вы можете увидеть веса моделей.
Затем загрузите модель и преобразуйте ее в определенный формат TensorRT LLM.
!python convert_checkpoint.py --model_dir ./tmp/hf_models/mistral-7b-instruct-v0.2 \
--output_dir ./tmp/trt_engines/1-gpu/ \
--dtype float16Следующим шагом будет компиляция модели с помощью команды trtllm-build. Если требуется квантование и другие оптимизации, здесь можно указать параметры. Для простоты я не использую никаких дополнительных оптимизаций.
!trtllm-build --checkpoint_dir ./tmp/trt_engines/1-gpu/ \
--output_dir ./tmp/trt_engines/compiled-model/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--max_input_len 32256Инструкция Mistral 7B v0.2 поддерживает длину контекста 32 КБ. Итак, здесь длина контекста устанавливается флагом max_input_length.
Сборка модели занимает 15-30 минут.
После того как модель скомпилирована, ее можно использовать напрямую. Здесь мы также представим метод развертывания модели. Существует множество способов развертывания этой скомпилированной модели, например, с помощью простых инструментов, таких как FastAPI, или более сложных инструментов, таких как сервер вывода Triton.
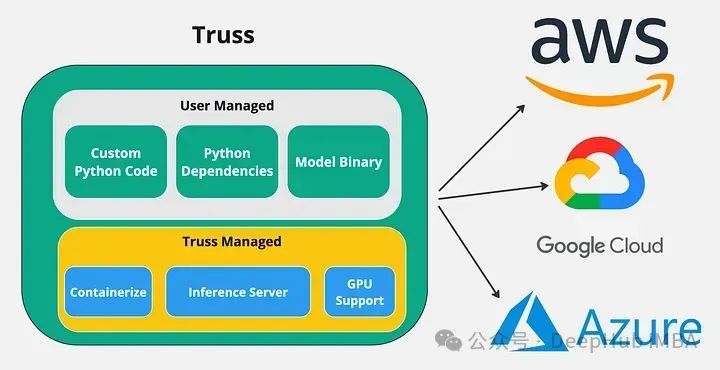
При использовании таких инструментов, как FastAPI, разработчики должны настроить сервер API, написать Dockerfile и правильно настроить CUDA. Это включает в себя множество серверных операций, с которыми мы иногда не знакомы, поэтому здесь мы представляем простой инструмент с открытым исходным кодом Truss. .
Truss позволяет разработчикам упаковывать свои модели с помощью графических процессоров и запускать их в любой облачной среде. Он имеет множество замечательных функций, которые упрощают интеграцию моделей. Основное преимущество использования Truss заключается в том, что модели с поддержкой графического процессора можно легко помещать в контейнер и развертывать в любой облачной среде.
Установить:
pip install --upgrade trussЕсли вы создаете проект фермы с нуля, вы можете запустить следующую команду:
truss init mistral-7b-tensort-llmmistral-7b-tensor-llm — это название нашего проекта, вы можете писать его как хотите. Выполнение приведенной выше команды автоматически сгенерирует файлы, необходимые для развертывания Truss.
Ниже приведена структура каталогов mistral-7b-tensor-llm-truss:
├── mistral-7b-tensorrt-llm-truss
│ ├── config.yaml
│ ├── model
│ │ ├── __init__.py
│ │ └── model.py
| | └── utils.py
| ├── requirements.txtВот краткое введение в вышеуказанные файлы:
1. config.yaml используется для установки различных конфигураций модели, включая ее ресурсы, зависимости, переменные среды и т. д. Здесь мы можем указать имя модели, зависимости Python для установки и системные пакеты для установки.
2. model/model.py — это ядро Truss. Он содержит код Python, который будет выполняться на сервере Truss. В model.py есть два основных метода: load() и Predict().
В методе загрузки мы загружаем скомпилированную модель с лица объятий и инициализируем TensorRT LLM. Метод прогнозирования получает HTTP-запрос и вызывает модель.
3. model/utils.py содержит некоторые вспомогательные функции файла model.py. Файл utils.py не был написан нами и его можно получить непосредственно из репозитория TensorRT LLM.
4. Содержит зависимости Python, необходимые для запуска скомпилированной модели, которую ферма будет использовать для инициализации нашей среды.
model.py содержит основной код для выполнения, давайте сначала посмотрим на функцию загрузки.
import subprocess
subprocess.run(["pip", "install", "tensorrt_llm", "-U", "--pre", "--extra-index-url", "https://pypi.nvidia.com"])
import torch
from model.utils import (DEFAULT_HF_MODEL_DIRS, DEFAULT_PROMPT_TEMPLATES,
load_tokenizer, read_model_name, throttle_generator)
import tensorrt_llm
import tensorrt_llm.profiler
from tensorrt_llm.runtime import ModelRunnerCpp, ModelRunner
from huggingface_hub import snapshot_download
STOP_WORDS_LIST = None
BAD_WORDS_LIST = None
PROMPT_TEMPLATE = None
class Model:
def __init__(self, **kwargs):
self.model = None
self.tokenizer = None
self.pad_id = None
self.end_id = None
self.runtime_rank = None
self._data_dir = kwargs["data_dir"]
def load(self):
snapshot_download(
"htrivedi99/mistral-7b-v0.2-trtllm",
local_dir=self._data_dir,
max_workers=4,
)
self.runtime_rank = tensorrt_llm.mpi_rank()
model_name, model_version = read_model_name(f"{self._data_dir}/compiled-model")
tokenizer_dir = "mistralai/Mistral-7B-Instruct-v0.2"
self.tokenizer, self.pad_id, self.end_id = load_tokenizer(
tokenizer_dir=tokenizer_dir,
vocab_file=None,
model_name=model_name,
model_version=model_version,
tokenizer_type="llama",
)
runner_cls = ModelRunner
runner_kwargs = dict(engine_dir=f"{self._data_dir}/compiled-model",
lora_dir=None,
rank=self.runtime_rank,
debug_mode=False,
lora_ckpt_source="hf",
)
self.model = runner_cls.from_dir(**runner_kwargs)вверху файла,Импортировали необходимые модули,Особенно tensorrt_llm тогда в функции загрузки;,мы используемsnapshot_downloadфункцияскачатькомпилироватьпозже Модель;а затем использоватьmodel/utils.pyслучайныйload_tokenizerфункция Скачать Токенизатор по модели, наконец, с использованием TensorRT; LLM использует класс ModelRunner для загрузки скомпилированной модели.
Ниже приведена функция прогнозирования
def predict(self, request: dict):
prompt = request.pop("prompt")
max_new_tokens = request.pop("max_new_tokens", 2048)
temperature = request.pop("temperature", 0.9)
top_k = request.pop("top_k",1)
top_p = request.pop("top_p", 0)
streaming = request.pop("streaming", False)
streaming_interval = request.pop("streaming_interval", 3)
batch_input_ids = self.parse_input(tokenizer=self.tokenizer,
input_text=[prompt],
prompt_template=None,
input_file=None,
add_special_tokens=None,
max_input_length=1028,
pad_id=self.pad_id,
)
input_lengths = [x.size(0) for x in batch_input_ids]
outputs = self.model.generate(
batch_input_ids,
max_new_tokens=max_new_tokens,
max_attention_window_size=None,
sink_token_length=None,
end_id=self.end_id,
pad_id=self.pad_id,
temperature=temperature,
top_k=top_k,
top_p=top_p,
num_beams=1,
length_penalty=1,
repetition_penalty=1,
presence_penalty=0,
frequency_penalty=0,
stop_words_list=STOP_WORDS_LIST,
bad_words_list=BAD_WORDS_LIST,
lora_uids=None,
streaming=streaming,
output_sequence_lengths=True,
return_dict=True)
if streaming:
streamer = throttle_generator(outputs, streaming_interval)
def generator():
total_output = ""
for curr_outputs in streamer:
if self.runtime_rank == 0:
output_ids = curr_outputs['output_ids']
sequence_lengths = curr_outputs['sequence_lengths']
batch_size, num_beams, _ = output_ids.size()
for batch_idx in range(batch_size):
for beam in range(num_beams):
output_begin = input_lengths[batch_idx]
output_end = sequence_lengths[batch_idx][beam]
outputs = output_ids[batch_idx][beam][
output_begin:output_end].tolist()
output_text = self.tokenizer.decode(outputs)
current_length = len(total_output)
total_output = output_text
yield total_output[current_length:]
return generator()
else:
if self.runtime_rank == 0:
output_ids = outputs['output_ids']
sequence_lengths = outputs['sequence_lengths']
batch_size, num_beams, _ = output_ids.size()
for batch_idx in range(batch_size):
for beam in range(num_beams):
output_begin = input_lengths[batch_idx]
output_end = sequence_lengths[batch_idx][beam]
outputs = output_ids[batch_idx][beam][
output_begin:output_end].tolist()
output_text = self.tokenizer.decode(outputs)
return {"output": output_text}Функция прогнозирования принимает некоторые входные данные модели, такие как подсказки, max_new_tokens, температура и т. д. Мы используем запросы для извлечения всех этих значений в верхней части функции. Вызовите модель LLM для генерации выходных данных с помощью функции self.model.generate. Функция генерации принимает различные параметры, помогающие контролировать выходные данные LLM.
Чтобы запустить нашу модель в облаке, ее также необходимо поместить в контейнер. Truss позаботится о создании Dockerfile и упаковке всего за нас, поэтому нам не нужно делать многого.
Создайте файл с именем main.py вне каталога mistral-7b-tensort-llm-truss. Вставьте в него следующий код:
import truss
from pathlib import Path
tr = truss.load("./mistral-7b-tensorrt-llm-truss")
command = tr.docker_build_setup(build_dir=Path("./mistral-7b-tensorrt-llm-truss"))
print(command)Запустите файл main.py и просмотрите каталог mistral-7b-tensort-llm-truss. Вы должны увидеть кучу автоматически сгенерированных файлов. Теперь вы можете использовать Docker для создания контейнера. Выполните последовательно следующие команды:
docker build mistral-7b-tensorrt-llm-truss -t mistral-7b-tensorrt-llm-truss:latest
docker tag mistral-7b-tensorrt-llm-truss <docker_user_id>/mistral-7b-tensorrt-llm-truss
docker push <docker_user_id>/mistral-7b-tensorrt-llm-trussЭти файлы конфигурации докера автоматически генерируются для нас truss. Давайте вкратце представим развертывание k8s. Я не буду подробно обсуждать настройку кластера GKE, поскольку это выходит за рамки данной статьи.
Создайте следующее развертывание Kubernetes:
apiVersion: apps/v1
kind: Deployment
metadata:
name: mistral-7b-v2-trt
namespace: default
spec:
replicas: 1
selector:
matchLabels:
component: mistral-7b-v2-trt-layer
template:
metadata:
labels:
component: mistral-7b-v2-trt-layer
spec:
containers:
- name: mistral-container
image: htrivedi05/mistral-7b-v0.2-trt:latest
ports:
- containerPort: 8080
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-tesla-a100
---
apiVersion: v1
kind: Service
metadata:
name: mistral-7b-v2-trt-service
namespace: default
spec:
type: ClusterIP
selector:
component: mistral-7b-v2-trt-layer
ports:
- port: 8080
protocol: TCP
targetPort: 8080Это стандартное развертывание Kubernetes с запуском контейнера с образом htrivedi05/mistral-7b-v0.2-trt:latest.
Развертывания можно создать, выполнив команду:
kubectl create -f mistral-deployment.yamlВыделение модулей Kubernetes занимает несколько минут. Как только модуль запустится, будет выполнена функция загрузки, которую мы написали ранее.
После загрузки модели в журнале модуля вы увидите что-то вроде Completed model.load() со временем выполнения 449234 миллисекунды. Чтобы отправлять запросы к модели через HTTP, нам нужно перенаправить сервис. Вы можете использовать следующую команду:
kubectl port-forward svc/mistral-7b-v2-trt-service 8080Откройте любой скрипт Python и запустите следующий код:
import requests
data = {"prompt": "What is a mistral?"}
res = requests.post("http://127.0.0.1:8080/v1/models/model:predict", json=data)
res = res.json()
print(res)Вы увидите следующий результат:
{"output": "A Mistral is a strong, cold wind that originates in the Rhone Valley in France. It is named after the Mistral wind system, which is associated with the northern Mediterranean region. The Mistral is known for its consistency and strength, often blowing steadily for days at a time. It can reach speeds of up to 130 kilometers per hour (80 miles per hour), making it one of the strongest winds in Europe. The Mistral is also known for its clear, dry air and its role in shaping the landscape and climate of the Rhone Valley."}Таким образом, наша служба вывода успешно развернута.
Тесты производительности
Я провел несколько пользовательских тестов и получил следующие результаты:
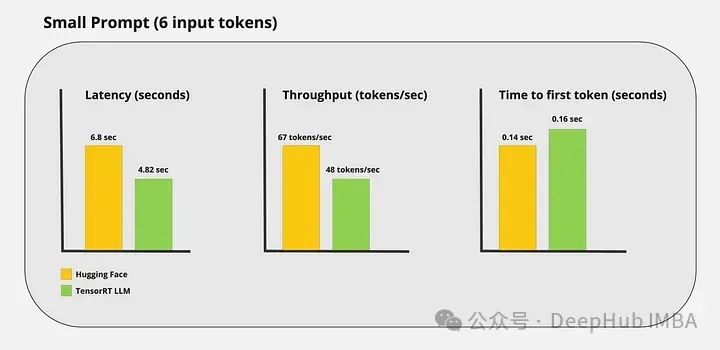
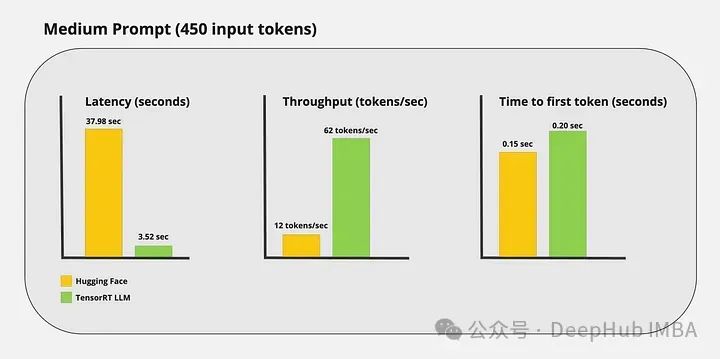
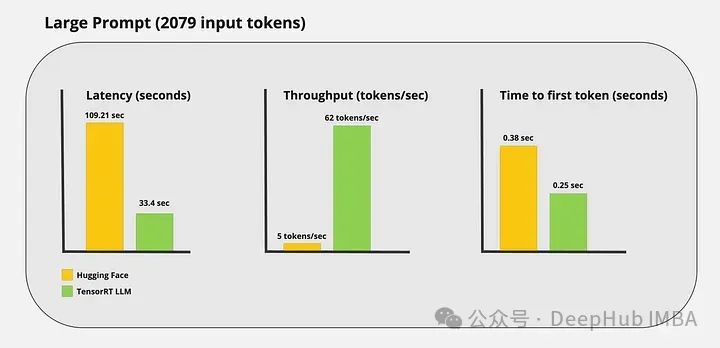
Видно, что ускоренный вывод TensorRT-LLM по-прежнему очень очевиден.
Подвести итог
В этой статье мы демонстрируем, как использовать TensorRT LLM для ускорения вывода модели, охватывая все этапы — от компиляции LLM до развертывания модели в производстве.
Хотя TensorRT LLM более сложен, чем другие оптимизаторы вывода, улучшение производительности также очень очевидно. Хотя эта структура все еще находится на ранней стадии разработки, она может обеспечить современную оптимизацию LLM. И это полностью открытый исходный код, и его можно коммерциализировать. Я считаю, что TensorRT LLM получит большее развитие в будущем, потому что, в конце концов, это собственный продукт NVIDIA.
Код TensorRT-LLM:
https://github.com/NVIDIA/TensorRT-LLM
Эта статья Колаб
https://colab.research.google.com/drive/1tJSMGbqYDstnChytaFb9F37oBspDcsRL
Автор: Хет Триведи



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
