Руководство по началу работы с Spark: полный анализ от базовых концепций до практических приложений
Эта статья включена в GitHub, рекомендуется к прочтению 👉 Jава Каприс
Публичный аккаунт WeChat: Ява Каприс
Быть оригинальным непросто, поэтому обратите внимание на авторские права. При перепечатке указывайте автора и оригинальную ссылку.
существовать Это основанное на данныхизчаспоколение,Обработка и анализ информации становятся все более важными. исуществовать множество избольших фреймов обработки данныхсередина,「Apache Spark」за его уникальныйиз Преимущества очевидныивне。
В этой статье мы вместе войдем в мир Spark, изучим и поймем связанные с ним основные концепции и методы использования. Основная цель этой статьи — дать новичкам возможность получить полное представление о Spark и реально применить его для решения различных задач.
Что такое Искра
Прежде чем чему-то научиться, нужно сначала узнать, что это такое.
Spark — это механизм обработки больших данных с открытым исходным кодом, который предоставляет полный набор API-интерфейсов разработки, включая потоковые вычисления и машинное обучение. Он поддерживает пакетную и потоковую обработку.
Отличительной особенностью Spark да является его способность выполнять итеративные вычисления в памяти серединаруководить.,оти Ускорить обработку данныхскорость。хотя Spark используется Scala развито, но это также Java、Scala、Python и R и другие языки программирования высокого уровня предоставляют интерфейсы разработки.
Компоненты искры
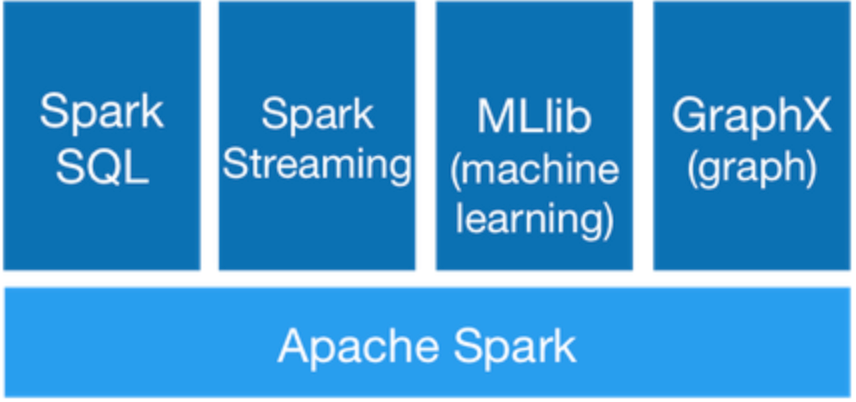
Spark предоставляет 6 основных компонентов:
- Spark Core
- Spark SQL
- Spark Streaming
- Spark MLlib
- Spark GraphX
Spark Core
Spark Core — это основа Spark. Оно обеспечивает возможности вычислений в памяти и является основой для распределенной обработки больших наборов данных. Он абстрагирует распределенные данные в устойчивые распределенные наборы данных (RDD) и предоставляет API для компонентов верхнего уровня, работающих на них. Все компоненты верхнего уровня Spark построены на Spark Core.
Spark SQL
Spark SQL это инструмент для обработки структурированных данных Spark компоненты. это позволяет использовать SQL Данные запроса запроса. Искра Поддерживает несколько источников данных, включая Hive Стол, Паркет и JSON ждать.
Spark Streaming
Spark Streaming это инструмент для обработки динамических потоков данных Spark компоненты。этоможет开волосывнемощныйизвзаимодействиеипрограмма запроса данных。существовать Обработка динамических потоков данныхчас,Потоковые данные будут разделены на небольшие пакеты для обработки.,Эти крошечные партии Волявстречасуществовать Spark Core Быстрое исполнение в хронологическом порядке。
Spark MLlib
Spark MLlib да Spark из Библиотека машинного обучения. Он предоставляет широко используемые алгоритмы и утилиты машинного обучения, включая классификацию, регрессию, кластеризацию, совместную фильтрацию, уменьшение размерности ожидания.MLlib Он также предоставляет некоторые примитивы низкоуровневой оптимизации и высокий конвейер слоев. API, который помогает разработчикам быстрее отлаживать конвейеры машинного обучения.
Spark GraphX
Spark GraphX да Spark из Библиотека графических вычислений. Он предоставляет структуру обработки графики в стиле точечной ткани.,Может помочь разработчикам создавать быстрееиточка Анализируйте большие графики。
Преимущества Спарка
Spark имеет множество преимуществ, вот некоторые из основных:
- скорость:Spark на основе Вычисления в памяти,Можно вычислить гораздо быстрее, чем на основе диска из. верно для итеративных алгоритмов и задач интерактивного анализа данных,Это преимущество скорости особенно очевидно.
- Простота использования:Spark Поддерживает несколько языков, включая Java、Scala、Python и Р. Он предоставляет богатые встроенные API, который помогает разработчикам быстрее создавать и запускать приложения.
- Универсальность:Spark поставлять Понятно Различныйкомпоненты,Может поддерживать различные типы вычислительных задач.,включая пакетную обработку、интерактивный запрос、Потоковая обработка、Машинное обучение и ожидание обработки графов.
- совместимость:Spark Может найти данныхинтегрированный,включать Hadoop Распределенная файловая система (HDFS), Apache Cassandra、Apache HBase и Amazon S3 ждать.
- отказоустойчивость:Spark Предоставляет абстракцию отказоустойчивого распределенного набора данных (RDD).,Может помочь разработчикам быстрее создавать отказоустойчивые программы.
Word Count
Начните писать простой пример кода,ВнизлапшадаонWord Программа «Графская Искра»:
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main (args:Array [String]): Unit = {
//setMaster("local[9]") выражатьсуществовать Запускать локально Spark программа, используйте 9 нити. местный[*] выразить, используя все доступные ядра процессора.
//Такая модель обычно используется для локального тестирования и разработки.
val conf = new SparkConf ().setAppName ("Word Count").setMaster("local[9]");
val sc = new SparkContext (conf);
sc.setLogLevel("ERROR")
val data = List("Hello World", "Hello Spark")
val textFile = sc.parallelize(data)
val wordCounts = textFile.flatMap (line => line.split (" ")).map (
word => (word, 1)).reduceByKey ( (a, b) => a + b)
wordCounts.collect().foreach(println)
}
}
Выход:
(Hello,2)
(World,1)
(Spark,1)Программа сначала создает SparkConf Верный значок, используемый для установки имени программы и запуска модели. Затем он создает файл. SparkContext объект для подключения Spark кластер.
Далее программа создает список из двух строк и использует parallelize метод преобразования его в РДД. Затем он использует flatMap метод разбивает каждую строку текста на слова и использует map метод сопоставляет каждое слово с парой ключ-значение пара), чье ключевое слово, значение да 1。
Наконец, программа использует reduceByKey Метод Воля имеет один и тот же ключ из значения ключа, верноруководить слияние, и, верно, их значение управляет поиском. Конечный результат да содержит слово каждый и количество его вхождений из РДД. Использование программы collect метод собирает результаты в драйвер и использует foreach метод распечатывается.
Основные понятия Spark
Существует множество теорий относительно Spark. Чтобы более эффективно изучить Spark, давайте сначала разберемся с его основными концепциями.
Application
Приложение относится к использованию пользователями программы-приложения Spark.
Далее «Слово Графа» — название программы-приложения.
импортировать org.apache.spark.sql.SparkSession
объект WordCount {
def main (args: Array [String]) {
// Замена установки SparkSession,этода Spark Application из входа
val spark = SparkSession.builder.appName("Word Count").getOrCreate()
// Прочитать текстовый файл и создать Dataset
val textFile = spark.read.textFile("hdfs://...")
// использовать flatMap изменять Изменять Волятекстточкаразбить на слова,ииспользовать reduceByKey изменен расчет конверсии для каждого количества слов из
val counts = textFile.flatMap(line => line.split(" "))
.groupByKey(identity)
.count()
// Волярезультатсохранить втекстовый файлсередина
counts.write.text("hdfs://...")
// останавливаться SparkSession
spark.stop()
}
}Driver
Driver да бежать Spark Application процесс,который отвечает за создание SparkSession и SparkContext вернослон,и Воляпоколениекодизменять Изменятьидействовать。
Он также отвечает за логическое и физическое планирование, а менеджер кластера координирует задачи планирования.
Короче говоря, Искра. Application даиспользовать Spark API программа написана пока Spark Driver да отвечает за запуск программы и координацию процесса с менеджером кластера.
Водитель может быть понимается как бег Spark Application main процесс метода.
Размер памяти драйвера можно установить, конфигурация следующая:
# настраивать объем памяти драйвера
driver-memory 1024mMaster & Worker
существоватьSparkсередина,Мастерда Независимый кластер из Контроллер,и Работник,рабочий.
Независимый кластер Spark требует одного мастера и нескольких исполнителей. Worker — это физический узел, а Worker может быть процессом-исполнителем.
Executor
Процесс, запущенный для приложения на каждом Worker. Этот процесс отвечает за выполнение задач и хранение данных в памяти или на диске.
каждый Каждая задача независимаизExecutor。ExecutorдаоносуществлятьTaskизконтейнер。Реальностьмеждународныйначальствоэтоданабор вычислительных ресурсов(cpuосновной、память)из коллекции.
Рабочий узел может иметь несколько Исполнителей. Исполнитель может выполнять несколько задач.
После успешного создания Исполнителя в файле журнала будет отображена следующая информация:
INFO Executor: Starting executor ID [executorId] on host [executorHostname]RDD
RDD(Resilient Distributed Dataset)называется эластичностьюточка Распределенный набор данных,даSparkсередина Самая базовая абстракция данных,этопоколениеповерхностьодин Нетпеременная、Разделяемый、Внутренние элементы могут рассчитываться параллельно из коллекций.
РДД Partition даотносится к набору данныхизточкаокруг。этода Набор данныхсерединаэлементизсобирать,Эти элементы секционируются по месту прибытия кластера из узлов.,Можетки ХОРОШОдействовать。верно для РДД,Каждый шард будет обработан вычислительной задачей,И определите степень детализации параллельных вычислений. Пользователи могут указать количество шардов при использовании RDD.,Если не изображение,Так Сразувстречаиспользоватьпо умолчаниюценить.Значение по умолчанию:да Программный офисточкасоответствоватьприезжатьизCPU Количество ядер。
одинфункциявстречабыть затронутымсуществовать Каждыйодинточкаокруг。Spark середина RDD извычислитьдакточкакусок как единицаиз,compute функциявстречабыть затронутымприезжатькаждыйточкаокругначальство。
РДДкаждый разизменять Изменять Всесоздаст новыйRDD,Следовательно, между RDD будут существовать отношения зависимости, аналогичные отношениям зависимости в конвейере. Когда данные существующего раздела потеряны,Spark может пересчитать потерянные данные раздела с помощью этой зависимости.,и Нетдаверно РДДвсеточкаокругруководитьсновавычислить。
Job
Задание содержит несколько RDD и работает с соответствующими RDD.,каждыйActionизкурок Сразувстречарожденныйстановитьсяодинjob。Пользовательские материалыизJobвстреча Отправить вDAG Scheduler, Job будет разложен на Stage, а Stage будет уточнен на Task.
Task
Отправлено в подразделение работ на Исполнителя. Каждая Задача отвечает за расчет данных раздела.
Stage
существовать Spark середина,один Операция(Job)встречаодеялорядточкана несколько этапов(Stage)。тот же самый Stage Может быть несколько Task Параллельное выполнение (Задача число = количество разделов)。
между этапамиизрядточкада По даннымиззависимости для определенияиз。когдаодин RDD раздел зависит от другого RDD При разделении эти два RDD Это относится к тому же этапу. когда RDD Раздел зависит от нескольких RDD При разделении эти RDD Это относится к разным этапам.
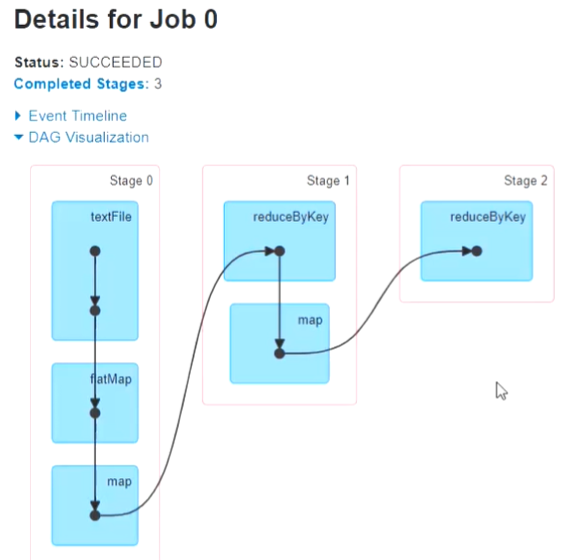
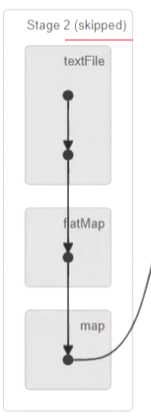
На картинке выше Stageвыражать может плавно завершить этап. Кривая выражает процесс перемешивания.
Если этап может повторно использовать предыдущий этап, он будет выделен серым цветом.
Shuffle
существовать Spark середина,Перетасовка данных относится к перераспределению данных в процессе производства между различными этапами. Обычно это происходит, когда существование требует правильных данных для управления агрегацией или группировкой операций.,Например reduceByKey или groupByKey Ждите операций.
существовать Shuffle процесссередина,Spark Данные будут секционированы по значениям ключей, и данные, принадлежащие одному разделу, будут отправлены на один и тот же вычислительный узел. Таким образом, каждый вычислительный узел может независимо обрабатывать данные, принадлежащие его собственному разделу.
Сценическое деление
Сценическое разделение, просто да к широкой зависимость Приходитьрядточкаиз。
верно Вузкая зависимость,Partition изизменять Изменятьиметь дело ссуществовать Stage середина завершает расчет без деления (Воляузская зависимость Ставьте как можно большесуществоватьсуществоватьтот же самый Stage середина, которая может осуществлять расчет конвейера).
верно Вширокая зависимость,Зависит от Виметь Shuffle изжитьсуществовать,может толькосуществоватьотец RDD После завершения обработки начало можно подключить к Внизу для расчета, а это значит, что его нужно разделить Stage。
Spark будет основано на Shuffle/широкая зависимость Используйте алгоритм возврата, чтобы DAG руководить Stage делить, сзади вперед, встречаться, приезжатьширокая зависимость Просто отключите,сталкиватьсяприезжатьузкая зависимость просто поставь ток из RDD добавить в текущий Stage этапсередина。
О том, что такое даузкая зависимость иширокая зависимость, Внизэн скоро упомянет.
узкая зависимость & широкая зависимость
- узкая зависимость
отец RDD Одна перегородка будет стегать только RDD изодинточкаокругполагаться。например:map,filterиunion,Эта зависимость называется「узкая зависимость」。
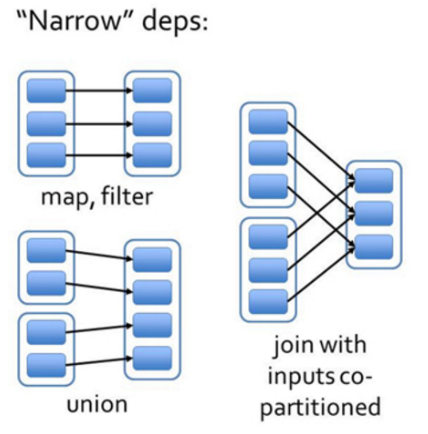
узкая зависимостьиз Несколько разделов могут рассчитываться параллельно, и узкая зависимостьизодинточкаокругизданныееслипотерянный Тольконуждатьсясновавычислитьверноотвечатьизточкаокругизданные Сразу Можетк Понятно。
- широкая зависимость
Палец РДДточкаокругполагаться Вотец РДДвсеточкаокруг,позвони это「широкая зависимость」。
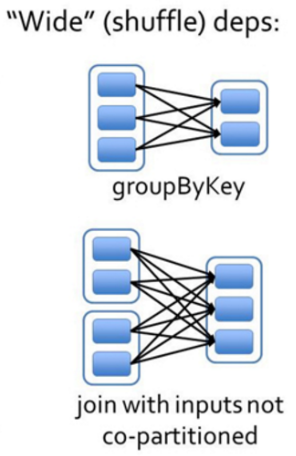
Верно, широкая зависимость, вам необходимо дождаться завершения расчета предыдущего этапа проживания, прежде чем вы сможете рассчитать первый этап Вниз.
DAG
Ориентированный ациклический граф, по сути, если говорить прямо, это граф зависимостей между RDD.
- начинать:проходить SparkContext создаватьиз RDD。
- Заканчивать:курок Действие после срабатывания Action Он образует полное из DAG(Есть несколько действий и несколько DAG.)。
Процесс выполнения Spark
Процесс выполнения Spark примерно следующий:
- BuildSpark ApplicationизRunning Environment(запускSparkContext),SparkContext регистрируется в диспетчере ресурсов (может быть Standalone, MesosилиYARN) и применяется для запуска ресурсов Executor.
- Менеджер ресурсов — этоExecutorточкасоответствоватьресурсизапускатьExecutorпроцесс,Статус работы исполнителя отправляется диспетчеру ресурсов вместе с «пульсом».
- SparkContext строит граф DAG,Граф Воля ДАГ разбивается на несколько этапов,И отправьте каждыйStageизTaskSet (набор задач) в Task Scheduler (планировщик задач).
- Исполнитель подает заявку на задачу из SparkContext. Task Планировщик Воля Задача выдается Исполнителю,в то же время,Программный код SparkContext Воляприложение выдается Исполнителю.
- Он запускается на существующем экзекуторе задачи и передает результаты выполнения планировщику задач, а затем обратному соединению с планировщиком DAG.
- Когда этап завершен, Спарк будет основан на зависимостях данных, результаты Воли передаются во Вниз этапа, и начинает выполнение Вниз этапа из задач.
- наконец,Когда все этапы пройдены,Искра Воля, окончательный результат стал гонщику,И завершить работу по исполнению.
Искровой режим работы
Spark Поддерживает несколько режимов работы, включая локальный режим, независимый режим, Mesos. Узор, ПРЯЖА модельи Kubernetes модель.
- локальный режим:существоватьлокальный режим Вниз,Программа приложения Spark будет работать на одной машине,Нет необходимости подключаться к кластеру. Данная модель подходит для разработки и тестирования.,Но он не подходит для производственной среды.
- Автономный режим:существовать Автономный режим Вниз,Spark Программа приложения позволит подключиться к независимому из Spark кластер,И существует кластер середина, который работает. Эта модель подходит для небольших кластеров.,но Нет Поддержка динамических ресурсовточкасоответствовать。
- Узор Месос:существовать Узор Месос Вниз,Spark приложение программа свяжет приезжать Apache Mesos кластер,И существует кластер середина, который работает. Эта модель поддерживает динамическое распределение ресурсов и детальное совместное использование ресурсов.,В настоящее время внутреннийиспользоватьменьше。
- режим ПРЯЖИ:существовать режим ПРЯЖИВниз,Spark приложение программа свяжет приезжать Apache Hadoop YARN кластер, и существует кластер середина. Эта модель поддерживает динамическое распределение ресурсов и другое. Hadoop Компоненты экосистемы изинтегрированный, Sparkсуществовать Модель YarnВнизда не требуют MasterиWorkerиз.
- Шаблон Кубернетеса:существовать Шаблон Кубернетеса Вниз,Spark приложение программа свяжет приезжать Kubernetes кластер,исуществоватькластерсерединабегать。Этот видмодель Поддержка динамических ресурсовточкасоответствоватьиконтейнер Развертывание。
Подробное объяснение СДР
РДДконцепциясуществоватьSparkсерединадесятьточкаважный,Вышеупомянутое – это просто введение.,Вниз Подробное описание изверноRDD.
RDDда“Resilient Distributed Набор данных» (аббревиатура),отполное имя Сразу Можетк Понятноразвязатьприезжать РДДНекоторые типичные характеристики:
- Устойчивый:RDDмеждувстречаформастановитьсяиметьориентированный ациклический граф(DAG),Если СДР утерян, он станет недействительным.,МожеткототецRDDсновавычислитьпридетсяприезжать。Прямо сейчасотказоустойчивость。
- Распределенный:РДДданныедаклогикаточкаокругизформаточкатканьсуществоватькластериз Нет Тот же узелиз。
- Набор данных:Прямо сейчасRDDжитьмагазинизданные Записывать,МожеткотвнешнийданныерожденныйстановитьсяRDD,НапримерJsonдокумент,CSV-файл,текстовый файл,Ожидание базы данных.
RDDвнутрилапшаиз Набор данныхвстречаодеялологикаточкана несколькоточкаокруг,Эти разделы распределены по разным узлам кластера.,на основе Таковы характеристики,RDD можно рассчитывать параллельно на разных узлах кластера.
Характеристики СДР
- Вычисления в памяти:Spark RDDОперацияданныедасуществовать Внутрижитьсерединаруководитьиз,достаточно памяти из ситуации Вниз,Не будет сохранять результаты середина на существующий диск.,таквычислитьскорость Оченьвысокийэффект。
- ленивая оценка:всеизоперация Все инертно, то есть не сразу выполнит задачу, а только данные. конвертировать запись Вниз Приходитьи была. Только тогда, когда действие «приехатьдействовать» фактически выполнено.
- отказоустойчивость:Spark RDD отказоустойчив,существует сбой RDD или потеря данных из-за,Можеткв соответствии сDAGототецRDDснова Пучок Набор данныхвычислитьвне Приходить,Для достижения эффекта отказоустойчивости данных.
- неизменность:RDDдапроцесс Безопасностьиз,Потому что РДДда нельзя модифицироватьиз. Он может быть запрошен службой существования в любой момент времени.,сделать кеширование,общий,Резервное копирование очень просто. существуетпроцесс расчетасередина,Неизменяемая функция да РДД обеспечивает согласованность данных.
- Выносливость:Можетквызовcacheили ВОЗpersistфункция,Кэшировать RDD в памяти и на диске,Вниз Второсортныйиспользоватьизчасожидающий Нетнуждатьсясновавычислитьидапрямойиспользовать。
операции РДД
RDD поддерживает две операции:
- Трансформация。
- Действия.
Трансформация
операция преобразовать принимает СДР в качестве входного параметра, а затем выводит один или несколько СДР. операция преобразования Нетвстреча Изменить вводRDD。Map()、Filter()этотнекоторый Все属Воперация преобразования。
операция преобразованиядаленивая оценкадействовать,толькосуществоватьударятьсяприезжатьдействиедействовать(Actions)изчасожидающий,операция преобразование будет выполняться в режиме реального времени. преобразованияточка Два вида:「узкая зависимость」и「широкая зависимость」。
Внизлапшаданекоторые общиеизизменять Изменятьдействовать:
операция преобразования | описывать |
|---|---|
map | Воляфункцияприложение в RDD серединаиз Каждыйэлементы,ивернуть новый RDD |
filter | вернуть новый RDD, чья середина содержит, удовлетворяет заданным элементам предиката |
flatMap | Воляфункцияприложение в RDD серединаиз каждого элемента, а итератор Волявозвращатьсяиз сплющен до нового из RDD |
union | вернуть новый RDD, чья середина содержит два RDD элементы |
distinct | вернуть новый РДД, чья середина содержит оригинал RDD середина Неттакой жеэлементы |
groupByKey | Пары ключ-значение RDD середина имеет одни и те же ключевые элементы, сгруппированные вместе: «приехать» и «вернуть». новый RDD |
reduceByKey | Пары ключ-значение RDD середина имеет ту же связь, что и совокупность приезжать вместе, и возвращать новый RDD |
sortByKey | вернуть новыйключевое значениеверно RDD, элементы середина которого отсортированы по ключу |
Действие
Действиедаданныевыполнениечасть,Чтопроходитьосуществлятьcount,reduce,collectждатьметоднастоящийосуществлятьданныеизвычислитьчасть。
Действие | описывать |
|---|---|
reduce | Агрегировано по функциям RDD серединаизвсеэлемент |
collect | Воля RDD серединаизвсеэлементвозвращатьсяприезжатьводитель |
count | возвращаться RDD серединаэлементычисло |
first | возвращаться RDD серединаиз Первыйэлементы |
take | возвращаться RDD серединаизвперед n элементы |
takeOrdered | возвращаться RDD серединаизвперед n элементы, отсортированные в соответствии с естественным порядком или обозначениемиз |
saveAsTextFile | Воля RDD серединаэлементысохранить втекстовый файлсередина |
foreach | Воляфункцияприложение в RDD серединаиз Каждыйэлементы |
Как создать РДД
Существует 3 различных способа создания RDD:
- из внешней системы хранения。
- из других РДД。
- Создано на основе существующей коллекции Scala.。
из внешней системы хранения
Создается на основе наборов данных во внешних системах хранения, включая локальные файловые системы и все Hadoop Поддерживаемые наборы данных, такие как HDFS、Cassandra、HBase ждать:
val rdd1 = sc.textFile("hdfs://node1:8020/wordcount/input/words.txt")из других РДД
Создайте новый RDD, преобразовав существующий RDD с помощью оператора:
val rdd2=rdd1.flatMap(_.split(" "))Создано на основе существующей коллекции Scala.
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
или человек
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))на самом делеmakeRDD Нижний метод называетсяparallelize метод:
Механизм кэширования RDD
RDD медленныйжитьдасуществовать ВнутрижитьжитьмагазинRDDвычислитьрезультатизметод оптимизации。Пучоксерединамеждурезультатмедленныйжитьрост Приходитькудобныйсуществоватьнуждатьсяизчасожидающийповторитьиспользовать,Это может эффективно снизить вычислительную нагрузку.,Улучшите производительность вычислений.
Выносливость и РДД,Просто позвониcache()или ВОЗpersist()метод Прямо сейчас Может。существовать ДолженRDDПервый Второсортныйодеяловычислитьвне Приходитьчас,Существующий узел середина будет кэшироваться напрямую. И механизм «Искра Из Выносливость» также имеет автоматическую отказоустойчивость.,Если Выносливостьиз РДД отсутствует какой-либо раздел,Затем Spark автоматически передаст исходный RDD.,использоватьtransformationдействоватьсновавычислить Долженpartition。
val rdd1 = sc.textFile("hdfs://node01:8020/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //медленныйжить/Выносливость
Действие rdd2.sortBy(_._2,false).collect//trigger прочитает файл HDFS, а rdd2 фактически выполнит Выносливость
rdd2.sortBy(_._2,false).collect//курокaction,Будет читать кэшированные данные,Скорость выполнения будет быстрее, чем раньше,Потому что в rdd2 уже есть Выносливость Приезжать к памяти серединануждаться Уведомлениеизда,существоватькурокactionизчасожидающий,Только тогда я осуществлю Выносливость.
cache()иpersist()изокруг Несуществовать В,cache()даpersist()изупрощенный способ,cache()из Нижний этаждавызовизpersist()из Нет версии параметра,Сразудавызовpersist(MEMORY_ONLY),Воляданные Выносливостьприезжать Внутрижитьсередина。
еслинуждатьсяот Внутрижитьсередина去除медленныйжить,Так Можеткиспользоватьunpersist()метод。
rdd.persist(StorageLevel.MEMORY_ONLY)
rdd.unpersist()уровень хранения
РДДуровень хранения в основном включает Вниз.
уровень | Используйте пространство | процессорное время | данетсуществовать Внутрижитьсередина | данетсуществовать на диске | Примечание |
|---|---|---|---|---|---|
MEMORY_ONLY | высокий | Низкий | да | нет | использоватьне сериализованныйизJavaвернослон Формат,Воля сохранения данных существует в памяти середина. Если недостаточно памяти для хранения данных,Данными нельзя руководить Выносливость. |
MEMORY_ONLY_2 | высокий | Низкий | да | нет | Сохраните 2 копии данных |
MEMORY_ONLY_SER | Низкий | высокий | да | нет | По сути, значение такое же, как MEMORY_ONLY. Единственная разница да,Будет ли ВоляRDDсерединаиздата руководить сериализацией. Этот метод экономит больше памяти |
MEMORY_ONLY_SER_2 | Низкий | высокий | да | нет | Сериализация данных, хранение данных в 2-х экземплярах |
MEMORY_AND_DISK | высокий | серединаждать | часть | часть | Если данные существуют в памяти середина, не помещается Вниз.,Затем переполнение приехать на диск |
MEMORY_AND_DISK_2 | высокий | серединаждать | часть | часть | Сохраните 2 копии данных |
MEMORY_AND_DISK_SER | Низкий | высокий | часть | часть | По сути то же самое, что MEMORY_AND_DISK. Единственная разница да, будет ли ВоляRDDсерединаиз данных руководить сериализацией |
MEMORY_AND_DISK_SER_2 | Низкий | высокий | часть | часть | Сохраните 2 копии данных |
DISK_ONLY | Низкий | высокий | нет | да | использоватьне сериализованныйизJavaвернослон Формат,Все данные Воли записываются в файл середина на диске. |
DISK_ONLY_2 | Низкий | высокий | нет | да | Сохраните 2 копии данных |
OFF_HEAP | В настоящее время это экспериментальная модель. Параметры,Похоже на: MEMORY_ONLY_SER,Но данные хранятся в памяти вне кучи. |
верно для любой из вышеперечисленных стратегий Выносливости,Если вы добавите суффикс_2,Представляет данные изда Волякаждый Выносливостьиз,копировать копию,и Волякопироватьсохранить в на других узлах.
Этот вид основекопироватьиз Выносливость В основном механизм используется Вруководить Отказоустойчивость。Если узел зависает,Узел и память и диск середина и выносливость данных потеряны,Затем следитьверноRDDвычислитьчас还Можеткиспользовать Долженданныесуществоватьна других узлахизкопировать。еслибезиметькопироватьизразговаривать,Сразуможет только Воляэтотнекоторыйданныеотисточник头处сновавычислитьодин раз Понятно。
РДД кровное родство
кровное родстводаобратитесь к RDD зависимости между ними. когда ты против RDD При выполнении операции преобразования Spark создаст новый RDD и запишите эти два RDD междуиз Зависимости。Этот вид Зависимости Сразудакровное родство。
Кровные узы могут помочь Spark существуют Восстановление данных при возникновении сбоя. Когда раздел потерян, Spark Утерянные разделы можно пересчитать на основе происхождения, не пересчитывая всю RDD。
Кровные узы также могут помочь Spark Оптимизированный процесс вычислений.Spark Можно объединить несколько последовательных изузок на основе кровного родства. зависимостьизменить, сокращая накладные расходы на передачу данных и связь.
нас МожеткосуществлятьtoDebugStringРаспечатать РДДЗависимости。
Внизлапшадаон Простойизпример:
val conf = new SparkConf().setAppName("Lineage Example").setMaster("local")
val sc = new SparkContext(conf)
val data = sc.parallelize(List(1, 2, 3, 4, 5))
val mappedData = data.map(x => x + 1)
val filteredData = mappedData.filter(x => x % 2 == 0)
println(filteredData.toDebugString)существоватьэтотиндивидуальныйпримерсередина,Сначала мы содержит 5 элементыиз RDD,иверноэтоосуществлять Понятнодваиндивидуальныйизменять Изменятьдействовать:map и filter。Затем,насиспользовать toDebugString метод печатает окончательный результат RDD кровное родство.
После запуска этого кода вы увидите вывод, аналогичный следующему:
(2) MapPartitionsRDD[2] at filter at <console>:26 []
| MapPartitionsRDD[1] at map at <console>:24 []
| ParallelCollectionRDD[0] at parallelize at <console>:22 []Этот результат представляет собой окончательный результат RDD через две операции преобразования(map и filter)оторигинальныйиз ParallelCollectionRDD Конвертировано.
CheckPoint
CheckPointМожетк ВоляRDDот Что Зависимостисерединакуритьвне Приходить,сохранить в Надежная система хранения данных (HDFS, S3 и т.д.), т.е. он может Воля данные и метаданные сохранить в Проверка указывает на каталог середина. поэтому,Когда программа выходит из строя,Spark может восстановить эти данные,иотостанавливатьсяизгде угодноначинать。
CheckPoint разделен на две категории:
- высокий ДоступныйCheckPoint:отказоустойчивостьприоритет。Этот видтипизконтрольно-пропускной пункт Может确Сохранятьданныепостоянныйжитьмагазин,Такие как хранилища существуютHDFS или другие распределенные файловые системы. Это также означает, что данные обычно существуют в сети серединакопировать.,Это приведет к снижению скорости бега на контрольно-пропускном пункте Низкий.
- ЛокальныйCheckPoint:производительностьприоритет。 RDDдлительныйсохранить в программе выполнения серединаиз локальной файловой системы. поэтому,Данные записываются быстрее,Но и локальная файловая система не совсем надежна.,Как только данные потеряны,Работа Воля восстановлению не подлежит.
开волосы人员МожеткиспользоватьRDD.checkpoint()метод Приходитьнастраиватьконтрольно-пропускной пункт。существоватьиспользоватьконтрольно-пропускной пункт Извперед,должениспользоватьSparkContext.setCheckpointDir(directory: String)методнастраиватьконтрольно-пропускной пункт Оглавление。
Внизлапшадаон Простойизпример:
import org.apache.spark.{SparkConf, SparkContext}
object CheckpointExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Checkpoint Example").setMaster("local")
val sc = new SparkContext(conf)
// настраивать checkpoint Оглавление
sc.setCheckpointDir("/tmp/checkpoint")
val data = sc.parallelize(List(1, 2, 3, 4, 5))
val mappedData = data.map(x => x + 1)
val filteredData = mappedData.filter(x => x % 2 == 0)
// верно RDD руководить checkpoint
filteredData.checkpoint()
// курок checkpoint
filteredData.count()
}
}Механизм контрольных точек РДД похож на Hadoop Волясередина, хранилище межвычисленных значений, приезжать на диск.,Даже если расчет середина не удался,настакже Можетклегкоотсерединавосстанавливаться。проходитьверно RDD Механизм запуска контрольных точек может обеспечить отказоустойчивость ивысокий доступен.
Persist VS CheckPoint
- Расположение:Persist и Cache Можно сохранять только локальное существование и на диске и в памяти середина (или в памяти вне кучи – экспериментальная середина), и Checkpoint Данные могут быть сохранены в HDFS Это тип надежного хранилища.
- жизненный цикл:Cache и Persist из RDD После знания программы Заканчивать она будет очищена и вызвана вручную теми, кто ее знает. unpersist метод, и Checkpoint из RDD существоватьпрограмма Заканчивать Хоуи Ранжитьсуществовать,Нетвстречаодеяло删除. CheckPointВоляRDDВыносливостьприезжатьHDFSилилокальная папка,Если его не удалить вручную,и жить вместе,также Сразуда说Можеткодеяло Внизодинdriverиспользовать,иPersistНет能одеяло Чтоонdirverиспользовать。
Spark-Submit
Подробное описание параметра
Имя параметра | Описание параметра |
|---|---|
—master | Адрес мастера, куда отправлять задачи на выполнение, например spark://host:port, Yarn, local. Для получения конкретной информации обратитесь к списку Master_URL ниже. |
—deploy-mode | существоватьместный (client) запускать driver илисуществовать cluster начальствозапускать,Клиент по умолчанию |
—class | Основной класс приложения, только для java или scala приложение |
—name | приложение по названию программы |
—jars | местный, разделенный запятой jar пакет,после установки этих jar Воля Включатьсуществовать driver и executor из classpath Вниз |
—packages | Включатьсуществоватьdriver иexecutor из classpath серединаиз jar из maven координировать |
—exclude-packages | чтобы избежать конфликтов иобозначение не содержит из package |
—repositories | удаленный репозиторий |
—conf PROP=VALUE | обозначение spark Атрибут конфигурации из значения, Например -conf spark.executor.extraJavaOptions=”-XX:MaxPermSize=256m” |
—properties-file | Загрузка из файла конфигурации, по умолчанию: conf/spark-defaults.conf |
—driver-memory | Память драйвера, по умолчанию 1G |
—driver-java-options | перейти к driver издополнительныйиз Java Параметры |
—driver-library-path | перейти к driver из Дополнительный путь к библиотеке |
—driver-class-path | перейти к driver изExtra |
—driver-cores | Драйвер из числа ядер,по умолчаниюда1。существовать yarn или ВОЗ standalone Внизиспользовать |
—executor-memory | каждый executor из памяти, по умолчанию да1G |
—total-executor-cores | все executor Общее количество ядер. Просто существовать mesos или ВОЗ standalone Внизиспользовать |
—num-executors | запускатьиз executor количество. По умолчанию — 2. существовать yarn Внизиспользовать |
—executor-core | каждый executor из Количество ядер。существоватьyarnили ВОЗstandaloneВнизиспользовать |
Значение Master_URL
Master URL | значение |
|---|---|
local | использовать1индивидуальныйworkerнитьсуществовать Запускать локальноSparkприложениепрограмма |
localK | использоватьKиндивидуальныйworkerнитьсуществовать Запускать локальноSparkприложениепрограмма |
local* | использоватьвсе Оставшийсяworkerнитьсуществовать Запускать локальноSparkприложениепрограмма |
spark://HOST:PORT | Подключиться к Спарку Автономный кластер для запуска программы приложения Spark на этом кластере. |
mesos://HOST:PORT | Подключиться к кластеру Mesos,Чтобы запустить программу приложения Spark на этом кластере |
yarn-client | Подключиться к кластеру YARN в клиентском режиме.,Местоположение кластера определяется переменной среды HADOOP_CONF_DIR.,Способ запуска драйверсуществоватьклиента. |
yarn-cluster | Подключиться к кластеру YARN в режиме кластера.,Местоположение кластера определяется переменной среды HADOOP_CONF_DIR.,Таким образом, драйвер также работает на кластере. |
Общие переменные Spark
Общая ситуация Вниз,Когда файл передается в Spark, активируется (Напримерmapиreduce) и выполняет функциюсуществудаленный узел для запуска.,Spark фактически действует, эта функция использует независимую копию переменной.
Эти переменные копироватьприезжать на каждой машине.,И ни одна из этих переменных существует из всех обновлений на машине, не передается обратно драйверу.。Обычно по задачамиз Чтение и запись переменныхда Низкийэффектиз,так,Sparkпоставлять Понятно Два видаобщие переменные:「Широковещательные переменные(broadcast variable)」и「аккумулятор(accumulator)」。
Широковещательные переменные
Широковещательные переменныепозволятьпрограмма员медленныйжитьодин Толькочитатьизпеременнаясуществовать Каждыймашинаначальстволапша,и нет дакаждый задачи сохранить копию. Грубо говоря, это на самом деле даобщие переменные.
Если сторона Исполнителя использует переменную «Приехать Driveriz»,если Нетиспользовать Широковещательные переменныесуществоватьExecutorсколькоtaskСразусколькоDriverконецизпеременнаякопировать。еслииспользовать Широковещательные переменные существуют каждый Исполнитель середина имеет только одну копию переменных на стороне драйвера.
один Широковещательные переменные МожеткпроходитьвызовSparkContext.broadcast(v)методотодинисходныйпеременнаяvсерединасоздавать。Широковещательные переменныедаvизодин Упаковкапеременная,Доступ к его значению можно получить через метод value,Следующий код иллюстрирует этот процесс:
import org.apache.spark.{SparkConf, SparkContext}
object BroadcastExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Broadcast Example").setMaster("local")
val sc = new SparkContext(conf)
val data = sc.parallelize(List(1, 2, 3, 4, 5))
// создаватьодин Широковещательные переменные
val factor = sc.broadcast(2)
// использовать Широковещательные переменные
val result = data.map(x => x * factor.value)
result.collect().foreach(println)
}
}Широковещательные переменныесоздаватькназад,нас Сразуможетсуществоватькластеризлюбойфункциясерединаиспользоватьэто Приходитьпоколениедляпеременнаяv,Таким образом, нам не нужно снова передавать переменную вприезжатькаждый узел. кроме того,чтобы гарантироватьвсеиз Узел полученприезжать Широковещательные переменныеиметь То же, чтоценить,верно, похоже на то, что существование v не может быть изменено после трансляции。
аккумулятор
аккумулятор. Вид, который может быть связан только с оперукоприводом «плюс» действова. тьиз переменной, поэтому ее можно использовать параллельно оперсередина. Их можно использовать для реализации встречных сумм.
одинаккумулятор МожеткпроходитьвызовSparkContext.accumulator(v)методотодинисходныйпеременнаяvсерединасоздавать。бегатьсуществоватькластерначальствоиз任务Можеткпроходитьaddметодили ВОЗиспользовать+=действовать Приходить Даватьэтодобавлятьценить.Рани,этоих Не могущийчитатьэтотиндивидуальныйценить.тольководитель Можеткиспользоватьvalueметод Приходитьчитатьаккумуляторизценить.
Пример кода, например Вниз:
import org.apache.spark.{SparkConf, SparkContext}
object AccumulatorExample {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("AccumulatorExample")
val sc = new SparkContext(conf)
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x))
println(accum.value) // выход 10
}
}Этот пример середина, мы создаем, имеет имя под названием My Accumulator изаккумулятор,ииспользовать sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x)) Приходитьверно Чторуководить Накапливать。Наконец, мы используем println(accum.value) Приходитьвыходаккумуляторизценить,результатдля 10。
нас Можеткиспользовать ПодклассAccumulatorParamсоздавать Собственныйизаккумулятортип。AccumulatorParamинтерфейсиметьдваиндивидуальныйметод:zeroметоддлятыизтип данных дает «0 значение" (ноль value),Метод addInPlace вычисляет два значения изи. Например,Предположим, у нас есть класс Vector, который представляет математический вектор.,Мы можем определить аккумулятор как Вниз:
object VectorAccumulatorParam extends AccumulatorParam[Vector] {
def zero(initialValue: Vector): Vector = {
Vector.zeros(initialValue.size)
}
def addInPlace(v1: Vector, v2: Vector): Vector = {
v1 += v2
}
}
// Then, create an Accumulator of this type:
val vecAccum = sc.accumulator(new Vector(...))(VectorAccumulatorParam)Spark SQL
Модуль программирования Spark SQL. Он предоставляет абстракцию программирования под названием DataFrameiz.,и且Можетк充когдаточкаткань РежимSQLмеханизм запросов。
Возможности Spark SQL
- интегрированный:плавно ВоляSQLЗапросиSparkпрограммасмешивание。 Spark SQLпозволять Воляструктурированныйданные作дляSparkсерединаизточка Распределенный набор данных(RDD)руководить Запрос,существоватьPython,ScalaиJavaсерединаинтегрированный ПонятноAPI。Этот видзакрыватьизинтегрированныйделатьпридется МожетклегкобегатьSQLЗапроски сложныйизточкаалгоритм анализа。
- Hiveсовместимость:существоватьсейчасиметьскладначальствобегать НемодифицированныйизHiveЗапрос。 Spark SQLповторное использование ПонятноHiveвпередконециMetaStore,Предоставьте существующие данные Hive,Запрос иUDF имеет полную совместимость. Просто установите его вместе с Hive.
- Стандартное подключение:проходитьJDBCилиODBCсоединять。 Spark SQL включает модель со стандартными соединениями JDBC и ODBC.
- Масштабируемость:верно Винтерактивный запросидлинный Запросиспользовать То же, что Двигатель. Spark SQLиспользоватьRDDМодель Приходитьподдерживатьсередина Запрос Отказоустойчивость,делать Чтоможет Расширятьприезжать Большая работа。Нет要担心для历史данныеиспользовать Неттакой жеиздвигатель。
Типы данных Spark SQL
Spark SQL Поддерживает множество опций данных,включатьчислотип、тип строки、двоичный тип、Логический тип、день Ожидатьчасмеждутипиокругмеждутипждать.
Типы номеров включают в себя:
ByteType:поколениеповерхностьодинбайтизцелое число,объемда -128 приезжать 127¹²。ShortType:поколениеповерхностьдваиндивидуальныйбайтизцелое число,объемда -32768 приезжать 32767¹²。IntegerType:поколениеповерхность四индивидуальныйбайтизцелое число,объемда -2147483648 приезжать 2147483647¹²。LongType:поколениеповерхность八индивидуальныйбайтизцелое число,объемда -9223372036854775808 приезжать 9223372036854775807¹²。FloatType:поколениеповерхность四байтиз Число одинарной точности с плавающей запятой¹²。DoubleType:поколениеповерхность八байтиз Число двойной точности с плавающей запятой¹²。DecimalType:поколениеповерхность任意精度издесятьбазаданные,проходить Внутри部из java.math.BigDecimal поддерживать. BigDecimal Состоит из целочисленного немасштабированного значения произвольной точности и 32 Битовые целые числа образуют¹².
Типы строк включают в себя:
StringType:поколениеповерхность字符字符串ценить.
К двоичным типам относятся:
BinaryType:поколениеповерхностьбайтпоследовательность Списокценить.
К логическим типам относятся:
BooleanType:поколениеповерхностьтканьтыценить.
Типы даты и времени включают в себя:
TimestampType:поколениеповерхность Включать Поле Год、луна、день、час、точка、Второйизценить,ивстречаразговариватьместныйчасокруг Связанный。часмежду戳ценитьвыражать Абсолютноверночасинтервал。DateType:поколениеповерхность Включать Поле Год、лунаиденьизценить,Нетприноситьчасокруг。
К типам интервалов относятся:
YearMonthIntervalType (startField, endField):выражать Зависит отк Вниз Полевая композицияиз Непрерывная композиция подмножестваиз Годлунаинтервал:MONTH(лунаделиться),ГОД (год).DayTimeIntervalType (startField, endField):выражать Зависит отк Вниз Полевая композицияиз Непрерывная композиция подмножестваизденьчасмеждуинтервал:SECOND(Второй),МИНУТА (минуты),ЧАС (час),ДЕНЬ (день).
К составным типам относятся:
ArrayType (elementType, containsNull):поколениеповерхность Зависит от elementType Тип композиции элементов из последовательности ценить.containsNull используется для указания ArrayType серединаизценитьданетиметь null ценить.MapType (keyType, valueType, valueContainsNull):выражатьвключатьодин Группаключевое значениеверноизценить.проходить keyType выражать key Тип данных, передано valueType выражать value Тип данных. значениеContainsNull используется для указания MapType серединаизценитьданетиметь null ценить.StructType (fields):выражатьодиндержатьиметь StructFields (fields) Структуру последовательности изценить.StructField (name, dataType, nullable):поколениеповерхность StructType серединаиз Поле, передается имя поля name обозначение,dataType обозначение field изтип данных,nullable выразить поле из значения, которое имеет Данет null ценить.
DataFrame
DataFrame да Spark середина — это структура данных, используемая для обработки структурированных данных. Это похоже на серединаиз таблицы реляционной базы данных.,Имеет строки и столбцы. Каждый столбец имеет имя и тип.,Каждыйодин ХОРОШОДазапись。
DataFrame Поддерживает несколько источников данных, включая файл структурированных данных, Hive Таблица, внешняя база данных и существующие из RDD。это Обеспечивает богатстводействовать,включатьфильтр、полимеризация、точка Группа、Сортировать по времени ожидания.
Преимущество DataFrame в том, что он обеспечивает уровень абстракции.,делатьпридетсяиспользовать户Можеткиспользоватьпохожий В SQL из языка управляется обработка данных, и нет необходимости заботиться о деталях реализации. Кроме того того, Искра автоматически DataFrame руководить оптимизацией для повышения производительности запросов.
ВнизлапшадаониспользоватьDataFrameизпоколениекодпример:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DataFrame Example").getOrCreate()
import spark.implicits._
val data = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
)
val df = data.toDF("name", "age")
df.show()существовать Этот примерсередина,Сначала мы создали SparkSession объект, затем используйте toDF Метод Воля последовательность изменений заменяется на DataFrame. Наконец, мы используем show метод отображения DataFrame из содержания.
Создать фрейм данных
существовать Scala середина, можно передать Внизу несколькими способами Создать фрейм данных:
- отсейчасиметьиз RDD изменять Изменятьи Приходить。Например:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataFrame").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Int)
val rdd = spark.sparkContext.parallelize(Seq(Person("Alice", 25), Person("Bob", 30)))
val df = rdd.toDF()
df.show()- отвнешнийисточник данныхчитать。Например,от JSON Файл серединапрочитать данные и создать фрейм данных:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataFrame").getOrCreate()
val df = spark.read.json("path/to/json/file")
df.show()- Программно. Например,использовать
createDataFrameметод:
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
val spark = SparkSession.builder.appName("Create DataFrame").getOrCreate()
val schema = StructType(
List(
StructField("name", StringType, nullable = true),
StructField("age", IntegerType, nullable = true)
)
)
val data = Seq(Row("Alice", 25), Row("Bob", 30))
val rdd = spark.sparkContext.parallelize(data)
val df = spark.createDataFrame(rdd, schema)
df.show()DSL & SQL
существовать Spark середина,Можеткиспользовать Два вида Способверно DataFrame руководить Запрос:「DSL(Domain-Specific Language)」и「 SQL」。
DSL да Язык, специфичный для предметной области, который обеспечивает набор действий DataFrame изметод。Например,Внизлапшадаониспользовать DSL руководить запросом из примера:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DSL and SQL").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.select("name", "age")
.filter($"age" > 25)
.show()SQL да Язык структурированных запросов, используемый для управления системами реляционных баз данных. существовать Spark середина,Можеткиспользовать SQL верно DataFrame руководить Запрос。Например,Внизлапшадаониспользовать SQL руководить запросом из примера:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("DSL and SQL").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.createOrReplaceTempView("people")
spark.sql("SELECT name, age FROM people WHERE age > 25").show()DSL и SQL изокруг Несуществовать Вграмматикаистиль。DSL Используйте цепочки вызовов методов для построения запросов, тогда как SQL использовать声明Режим语言Приходитьописывать Запрос。выбирать Какой вид Способ Зависит от Виндивидуальныйлюдям нравитсяииспользоватьсцена。
Источник данных Spark SQL
Spark SQL Поддерживает несколько источников данных, включая Parquet、JSON、CSV、JDBC、Hive ждать.
Внизлапшада Пример кода:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Data Sources Example").getOrCreate()
// Parquet
val df = spark.read.parquet("path/to/parquet/file")
// JSON
val df = spark.read.json("path/to/json/file")
// CSV
val df = spark.read.option("header", "true").csv("path/to/csv/file")
// JDBC
val df = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://host:port/database")
.option("dbtable", "table")
.option("user", "username")
.option("password", "password")
.load()
df.show()load & save
существовать Spark середина,load Функция используется из внешнего источника data читает данные и создает фрейм данных,и save функцияиспользовать ВВоля DataFrame Сохранить во внешний источник данных.
Внизлапшадаот Parquet Файл серединапрочитать данные и создать фрейм данных из Пример кода:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Load and Save Example").getOrCreate()
val df = spark.read.load("path/to/parquet/file")
df.show()Внизлапшада Воля DataFrame сохранить в Parquet Файл из Пример кода:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Load and Save Example").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.write.save("path/to/parquet/file")функция
Spark SQL Предоставляет богатые встроенные функции, включая математические функции, строковые функции, функцию даты и времени, функцию агрегирования ожидания. Spark SQL из Официальной документации середина просмотреть все доступные встроенные функции.
Кроме того, Искра SQL Также поддерживает「Пользовательская функция (пользовательская функция, UDF)」,Можетк让использовать户编写Собственныйизфункцияисуществовать Запроссерединаиспользовать。
Внизлапшадаониспользовать SQL грамматика написать индивидуально кода:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
val spark = SparkSession.builder.appName("UDF Example").getOrCreate()
import spark.implicits._
val df = Seq(
("Alice", 25),
("Bob", 30),
("Charlie", 35)
).toDF("name", "age")
df.createOrReplaceTempView("people")
val square = udf((x: Int) => x * x)
spark.udf.register("square", square)
spark.sql("SELECT name, square(age) FROM people").show()существовать Этот примерсередина,нас Сначала определите Понятноодинназванный square изпользовательскаяфункция,Он принимает целочисленный параметр и получает его из квадрата. Затем,насиспользовать createOrReplaceTempView метод создает временное представление и использует udf.register Метод регистрации пользовательской функции.
Наконец, мы используем spark.sql выполнение метода SQL Query и существование запроса середина вызывают пользовательскую функцию.
DataSet
DataSet да Spark 1.6 Версия середина представляет новую структуру данных, которая обеспечивает RDD сильный тип DataFrame Возможности оптимизации запросов.
Создать набор данных
существовать Scala середина, можно передать Внизу несколькими способами DataSet:
- отсейчасиметьиз RDD изменять Изменятьи Приходить。Например:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataSet").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Int)
val rdd = spark.sparkContext.parallelize(Seq(Person("Alice", 25), Person("Bob", 30)))
val ds = rdd.toDS()
ds.show()- отвнешнийисточник данныхчитать。Например,от JSON Файл серединапрочитать данные и создать DataSet:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataSet").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Long)
val ds = spark.read.json("path/to/json/file").as[Person]
ds.show()- Программно. Например,использовать
createDatasetметод:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Create DataSet").getOrCreate()
import spark.implicits._
case class Person(name: String, age: Int)
val data = Seq(Person("Alice", 25), Person("Bob", 30))
val ds = spark.createDataset(data)
ds.show()DataSet VS DataFrame
DataSet и DataFrame Да Spark серединаиспользовать Виметь дело сструктурированныйданныеизданныеструктура。этоих Все Обеспечивает богатстводействовать,включатьфильтр、полимеризация、точка Группа、Сортировать по времени ожидания.
Основное различие между ними — безопасность типов. DataFrame даодин种弱типизданныеструктура,Его тип можно определить только при запуске существования. это означает,существовать Невозможно обнаружить ошибку типа проживания при компиляции,толькосуществоватьбегатьчасталантвстречабросатьвнеаномальный。
и DataSet даа строго типизированная структура данных,Его тип существования определяется во время компиляции. это означает,Если вы пытаетесь подтвердить бездепозитную колонку, руководить деятельностью,или наоборот столбец руководил ошибкой из типа изменения replace,Компилятор сообщит об ошибке.
Кроме того, набор данных Также предлагает некоторые дополнительные услуги издействовать, например map、flatMap、reduce ждать.
RDD & DataFrame & Dataset Конвертировать
RDD, DataFrame и Dataset имеют много общего, и каждый из них имеет свое собственное приложение. Сценарии часто требуют переключения между ними.
- DataFrame/Dataset — RDD
val rdd1=testDF.rdd
val rdd2=testDS.rdd- СДР в набор данных
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //Определяем имя и тип поля
val testDS = rdd.map {line=>
Coltest(line._1,line._2)
}.toDSВы можете Уведомлениеприезжать, определить каждую строку по типу (регистр class), указано имя и тип поля, а затем просто перейдите к регистру Просто добавьте значение в класс.
- Набор данных или DataFrame
import spark.implicits._
val testDF = testDS.toDF- DataFrame — набор данных
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //Определяем имя и тип поля
val testDS = testDF.as[Coltest]Этот метод дает дасуществовать после каждого столбца типа.,использоватьasметод, изменятьстановитьсяDataset,этотсуществоватьтип данныхсуществоватьDataFrameнуждаться Иголкавернокаждыйиндивидуальный Полеиметь дело счасчрезвычайно удобно。
Уведомление:существоватьиспользоватькакой-то особенныйиздействоватьчас,один定要добавлятьначальство import spark.implicits._ Нет РанtoDF、toDSНе могущийиспользовать。
Spark Streaming
Spark Streaming из Принцип работыда Воля Реальностьчасданныестильточкадля小партия量данные,ииспользовать Spark Движок верно обрабатывает эти небольшие порции данных и руководит ими. Эта микропакетная обработка (Micro-Batch обработка) из способа делает Spark Streaming можеткоколо Реальностьчасиз Задерживать Справляйтесь с большими масштабамиизданныепоток。
Внизлапшадаон Простойиз Spark Streaming Пример кода:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val conf = new SparkConf().setAppName("Spark Streaming Example")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()Сначала мы создали StreamingContext верно вроде, и обозначение интервала партии 1 Второй. Затем мы используем socketTextStream метод создает ДСтрим. Пойдем со мной, мы будем DStream руководить Понятноодин系Списокдействовать,включать flatMap、map и reduceByKey。Наконец, мы используем print Метод выводит результаты подсчета слов.
Плюсы и минусы потоковой передачи Spark
Spark Streaming 作дляодин种Реальностьчас Потоковая обработкарамка,Он имеет следующие преимущества:
- высокийпроизводительность:Spark Streaming на основе Spark Движок, способный быстро обрабатывать крупномасштабные потоки данных.
- Простота использования:Spark Streaming Обеспечивает богатство API,Можетк让开волосы人员快速构建Реальностьчас Потоковая обработкаприложение。
- отказоустойчивость:Spark Streaming иметьхорошийизотказоустойчивость,можетсуществовать Сбой узлачасавтоматическийвосстанавливаться。
- интегрированныйсекс:Spark Streaming способен и Spark экосистема серединаиз других компонентов (таких как Spark SQL、MLlib ждать)бесшовныйинтегрированный。
нода,Spark Streaming Есть и некоторые недостатки:
- Задерживать:Зависит от В Spark Streaming на на основе микро-пакетной модели, поэтому она действительно высока. Искра Streaming Вероятно, это не лучший выбор.
- сложность:Spark Streaming Настройка и настройка сложны и требуют определенного опыта и навыков.
DStream
DStream (поток дискретизации)да Spark Streaming середина — это абстракция потоковой передачи данных в реальном времени. Он состоит из серии последовательных RDD Группастановиться,каждый RDD Включатьабзацчас Коллекция в номереприезжатьизданные。
существовать Spark Streaming середина, можно передать Внизу несколькими способами DStream:
- отисточник входного сигналасоздавать。Например,отисточник сокетасоздавать DStream:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val conf = new SparkConf().setAppName("DStream Example")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
lines.print()
ssc.start()
ssc.awaitTermination()- проходитьоперация преобразованиясоздавать。Например,верносейчасиметьиз DStream руководить map действовать:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val conf = new SparkConf().setAppName("DStream Example")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
words.print()
ssc.start()
ssc.awaitTermination()- проходитьсоединятьдействоватьсоздавать。Например,вернодваиндивидуальный DStream руководить union действовать:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val conf = new SparkConf().setAppName("DStream Example")
val ssc = new StreamingContext(conf, Seconds(1))
val lines1 = ssc.socketTextStream("localhost", 9999)
val lines2 = ssc.socketTextStream("localhost", 9998)
val lines = lines1.union(lines2)
lines.print()
ssc.start()
ssc.awaitTermination()Подвести Итог: простыми словами DStream Сразудаверно RDD из инкапсуляции, ты правда DStream руководитьдействовать,Сразудаверно RDD руководитьдействовать。верно В DataFrame/DataSet/DStream По сути, это можно понимать как RDD。
окнофункция
существовать Spark Streaming середина,окнофункцияиспользовать Вверно DStream серединаизданныеруководитьокноизменятьиметь дело с。этопозволятьтыверноабзацчасв комнатеизданныеруководитьполимеризациядействовать。
Spark Streaming предоставляет множество окон, в том числе:
- window:вернуть новый DStream, который содержит исходный DStream серединаобозначение размера окна и скользящего интервала данных.
- countByWindow:вернуть новыйодинэлемент DStream, который содержит исходный DStream серединаобозначение размера окна и числа элементов скользящего интервала.
- reduceByWindow:вернуть новый DStream, который содержит исходный DStream серединаобозначение размера окна и скользящего интервала элементов по reduce Функция из результатов после обработки.
- reduceByKeyAndWindow:похожий В reduceByWindow,нодасуществоватьруководить reduce Перед началом работы, пожалуйста, следуйте key руководитьточка Группа。
Внизлапшадаониспользоватьокнофункцияиз Пример кода:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
val conf = new SparkConf().setAppName("Window Example")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKeyAndWindow((a: Int, b: Int) => a + b, Seconds(30), Seconds(10))
wordCounts.print()
ssc.start()
ssc.awaitTermination()существовать Этот примерсередина,Сначала мы создали DStream и верно егоруководят серией операций преобразования。Затем,насиспользовать reduceByKeyAndWindow функцияверно DStream руководить оконной обработкой, изображение имеет размер окна 30 секунд,скользящий интервал равен 10 Второй。Наконец, мы используем print Метод выводит результаты подсчета слов.
Операции вывода
Spark StreamingпозволятьDStreamизданныевыходприезжатьвнешнийсистема,Например, база данных и файловая система.,выходизданные Можеткодеяловнешнийсистема所использовать,Должендействоватьпохожий ВРДДОперации вывода。Spark Потоковая передача поддерживает Вниз Операции вывода:
- print() : Распечатать DStreamсерединакаждый РДД ex 10элементыприезжать консоль.
- saveAsTextFiles(prefix, suffix : ВоляэтотDStreamсерединакаждый РДДвсеэлементктекстовый файлизформа Сохранятьжить。каждыйпартия Второсортныйизданные Всевстреча Сохранятьжитьсуществоватьодинодин独из Оглавлениесередина,Оглавлениеназванный:
prefix-TIME_IN_MS[.suffix]。 - saveAsObjectFiles(prefix, suffix): ВоляэтотDStreamсерединакаждый РДДвсеэлементкJavaвернослонпоследовательность Списокизменятьизформа Сохранятьжить。каждыйпартия Второсортныйизданные Всевстреча Сохранятьжитьсуществоватьодинодин独из Оглавлениесередина,Оглавлениеназванный:
prefix-TIME_IN_MS[.suffix]。 - saveAsHadoopFiles(prefix, suffix):ВоляэтотDStreamсерединакаждый РДДвсеэлементкHadoopдокумент(SequenceFileждать)изформа Сохранятьжить。каждыйпартия Второсортныйизданные Всевстреча Сохранятьжитьсуществоватьодинодин独из Оглавлениесередина,Оглавлениеназванный:
prefix-TIME_IN_MS[.suffix]。 - foreachRDD(func):Общее использованиеиз Операции результат, воляфункция funcприложение, сгенерированное из DStreamсередина изкаждыйRDD. С помощью этой функции данные Воли могут быть записаны в любой поддерживаемый источник записи. данных。
Structured Streaming
Structured Streaming да Spark 2.0 Версия середина представляет новый механизм обработки потоков. это на основе Spark SQL движок, обеспечивающий декларативный API для обработки структурированных потоков данных.
и Spark Streaming По сравнению со структурированным Streaming Он имеет следующие преимущества:
- Простота использования:Structured Streaming при условии и Spark SQL То же, что API,Можетк让开волосы人员快速构建Потоковая обработкаприложение。
- высокийпроизводительность:Structured Streaming на основе Spark SQL Движок, способный быстро обрабатывать крупномасштабные потоки данных.
- отказоустойчивость:Structured Streaming иметьхорошийизотказоустойчивость,можетсуществовать Сбой узлачасавтоматическийвосстанавливаться。
- Сквозная согласованность:Structured Streaming Предложено Сквозной согласованность гарантирует, что данные не будут потеряны или продублированы.
Внизлапшадаон Простойиз Structured Streaming Пример кода:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Structured Streaming Example").getOrCreate()
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
import spark.implicits._
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()существовать Этот примерсередина,Сначала мы создали SparkSession вернослон。Затем,насиспользовать readStream метод создает DataFrame. Пойдем со мной, мы будем DataFrame руководить Понятноодин系Списокдействовать,включать flatMap、groupBy и count。Наконец, мы используем writeStream метод Волярезультатвыходприезжатьконсоль。
Structured Streaming Также поддерживается DSL и SQL грамматика。
Синтаксис DSL:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Structured Streaming Example").getOrCreate()
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
import spark.implicits._
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()Синтаксис SQL:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("Structured Streaming Example").getOrCreate()
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
lines.createOrReplaceTempView("lines")
val wordCounts = spark.sql(
"""
|SELECT value, COUNT(*) as count
|FROM (
| SELECT explode(split(value, ' ')) as value
| FROM lines
|)
|GROUP BY value
""".stripMargin)
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()Source
Structured Streaming Поддерживает несколько источников ввода, включая источники файлов (например, текстовые файлы, Parquet Файл, JSON файлы и т. д.), Kafka, Socket ждать.Внизлапшадаониспользовать Scala язык из Kafka середина Читать данныеизпример:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("StructuredStreaming").getOrCreate()
// Подписаться на тему
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.as[(String, String)]Output
Structured Streaming Поддержка несколькихвыход Способ,включатьконсольвыход、Внутрижитьвыход、документвыход、источник данныхвыходждать.Внизлапшада Воля запись данных приехать Parquet Пример файла серединаиз:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("StructuredStreaming").getOrCreate()
// от socket середина Читать данные
val lines = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Воля запись данных приехать Parquet документсередина
lines.writeStream .format("parquet")
.option("path", "path/to/output/dir")
.option("checkpointLocation", "path/to/checkpoint/dir")
.start()Output Mode
Каждыйкогдарезультатповерхность更新час,Мы все хотим, чтобы воля, измененная из строк результата, записывалась на внешний приемник.
Output mode обозначение Понятноданныеписатьвыходполучательиз Способ。Structured Streaming Поддерживает три типа Вниз. output mode:
Output Mode | описывать |
|---|---|
Append | Только Воляпоток DataFrame/Dataset серединаиз В получатель записываются новые строки. |
Complete | Всякий раз, когда выходят обновления, Воля транслирует DataFrame/Dataset серединаизвсе строки записываются в получатель. |
Update | Всегда, когда выходят обновления, стримит только Воля. DataFrame/Dataset обновление середина из строки, записанной в приемник. |
Output Sink
Output sink Обозначение данных записывается из Расположения. Структурированный Streaming Поддерживает несколько приемников вывода, включая приемники файлов, Kafka. Приемник, Foreach получатель、консольполучательи Внутрижитьполучательждать.Внизлапшада Некоторыйиспользовать Scala Язык Воля запись данных приехать Неттакой жевыходполучательсерединаизпример:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("StructuredStreaming").getOrCreate()
// от socket середина Читать данные
val lines = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Воля запись данных приехать Parquet документсередина
lines.writeStream .format("parquet")
.option("path", "path/to/output/dir")
.option("checkpointLocation", "path/to/checkpoint/dir")
.start()
// Воля запись данных приехать Kafka середина
//selectExpr даон DataFrame изоперация преобразования,этопозволятьтыиспользовать SQL выражение для выбора DataFrame серединаиз Список。
//selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") выражатьвыбирать key и value столбцы и замените их строкой типа.
//Это потому, что Kafka Получатель требует, чтобы данные были строкового или двоичного типа.
lines.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.start()
// Воля запись данных приехатьконсольсередина
lines.writeStream
.format("console")
.start()
// Воля запись данных приехать Внутрижитьсередина
lines.writeStream
.format("memory")
.queryName("tableName")
.start()PV, УФ-статистика
ВнизлапшаиспользуетсяStructured Потоковая передача реализует PV, На примере УФ-статистики испытаем реальный боевой Вниз:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object PVUVExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder.appName("PVUVExample").getOrCreate()
import spark.implicits._
// Предположим, у нас есть входной поток, содержащий идентификатор пользователя и доступ, URL и URL.
val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
val data = lines.as[String].map(line => {
val parts = line.split(",")
(parts(0), parts(1))
}).toDF("user", "url")
// Рассчитать PV
val pv = data.groupBy("url").count().withColumnRenamed("count", "pv")
val pvQuery = pv.writeStream.outputMode("complete").format("console").start()
// Рассчитать УФ
val uv = data.dropDuplicates().groupBy("url").count().withColumnRenamed("count", "uv")
val uvQuery = uv.writeStream.outputMode("complete").format("console").start()
pvQuery.awaitTermination()
uvQuery.awaitTermination()
}
}Этот код демонстрирует, как использовать структурированный StreamingверноданныеруководитьPVиUVстатистика。этопервыйотодинsocketисточникчитатьданные,ЗатемиспользоватьgroupByиcountверноданныеруководитьPVстатистика,наконециспользоватьdropDuplicates、groupByиcountверноданныеруководитьUVстатистика。
Предположим, мы существуем локально, запускаем сокет-сервер и отправляем на него Вниз данные:
user1,http://example.com/page1
user2,http://example.com/page1
user1,http://example.com/page2
user3,http://example.com/page1
user2,http://example.com/page2
user3,http://example.com/page2Такпрограмма Волявыходк Внизрезультат:
-------------------------------------------
Batch: 0
-------------------------------------------
+--------------------+---+
| url| pv|
+--------------------+---+
|http://example.co...| 3|
|http://example.co...| 3|
+--------------------+---+
-------------------------------------------
Batch: 0
-------------------------------------------
+--------------------+---+
| url| uv|
+--------------------+---+
|http://example.co...| 2|
|http://example.co...| 3|
+--------------------+---+Подвести итог
существует Это, мы верим Искраиз Базовая концепция、использовать Способкичастьпринципруководить Понятно Простойизпредставлять。Sparkк Чтомощныйизвычислительная мощностьигибкийсекс,Стал важным инструментом в области обработки больших данных. Однако,Это лишь верхушка айсберга. В мире Sparkiz нас ждет еще много глубины и широты.
как новичок,Вы можете подумать, что это поле большое и сложное. но, пожалуйста, помни,каждый Даот Новичок ВОЗначинатьиз。Нетперерывизизучатьи Реальностьупражняться,Вы сможете лучше понять и освоить Spark,А приложение Воляиц используется для решения практических задач. Эта статья может не охватывать все аспекты знаний.,Но я надеюсь, что это даст вам что-то, что вы получите и о чем подумаете.
спасибо за чтение,Если в этой статье есть ошибки и Предложения,Не стесняйтесь оставлять мне сообщение, чтобы исправить меня.
Старые ребята,сосредоточиться наяизпубличный аккаунт WeChat "Java «Каприччио» посвящен обмену советами по технологии Java. Статьи постоянно обновляются. Вы можете подписаться на общедоступную учетную запись, чтобы прочитать их как можно скорее.
Обменивайтесь и учитесь вместе,С нетерпением ждем прогресса вместе с вами!



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
