RU | Предлагает большую модель генерации жестового языка: SignLLM, которая поддерживает 8 видов генерации жестового языка, и все они достигают SOTA!
введение
Язык жестов жизненно важен для общения людей с нарушениями слуха. Однако,Данные о языке жестов очень сложно получить и обработать.,Это ограничивает развитие модели производства языка жестов. Содействовать развитию области создания языка жестов.,Автор статьи предложилМногоязычный набор данных языка жестов Prompt2Sign,и тренировался с этимБольшая модель создания языка жестов: SignLLM.,Модель может генерировать несколько языков жестов параллельно.,Одновременно понимать сложный ввод естественного языка. Результаты экспериментов показывают,SignLLM достигает высочайшей производительности при выполнении задач SLP на 8 языках жестов,Демонстрация своей силы в создании многоязычного языка жестов.
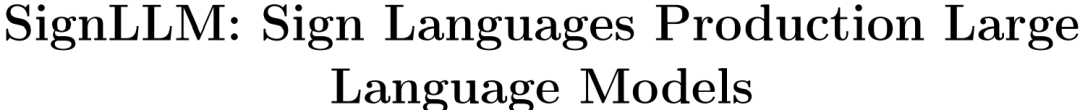
https://arxiv.org/pdf/2405.10718v1
Предыстория
Генерация языка жестов (Sign Language Production,SLP) направлен на создание человекоподобных аватаров на языке жестов (аватаров) из текстового ввода. Методы SLP, основанные на глубоком обучении, обычно включают в себя переход от текста к словарю (т. е. текстовый словарь, представляющий жесты или жесты), от словаря к жестам.,и, в конечном итоге, преобразование жестов в более привлекательные аватары на языке жестов, похожие на человеческие. Эти процессы сложны и их трудно упростить.,делатьПолучение и обработка данных языка жестов становится все труднее, что также серьезно снижает энтузиазм исследователей.。
В то же время в последнее десятилетие или около того исследования в этой области в основном опирались на набор данных немецкого языка жестов (PHOENIX14T) для задач генерации, распознавания и перевода языка жестов (SLP, SLR и SLT). Использование различных стандартных инструментов разными исследователями также увеличило сложность исследования. Хотя основные наборы данных сыграли важную роль в развитии области создания языка жестов, проблемы остаются при столкновении с новыми проблемами, такими как:
- 1.«Сложный формат» Существующий формат файла набора данных сложен и не содержит информации, непосредственно используемой для обучения;
- 2.«Трудоемкий»Ручное аннотирование словаря отнимает много времени.、трудоемкий,Требуется много ручной работы;
- 3.«Трудности в расширении»язык жестоввидеоданные Наборы обычно нужно брать у профессионала и перерабатывать.,Это затрудняет расширение набора данных.
Вышеуказанные проблемы ограничивают развитие жестового языка Модель. с этой целью,Автор статьи предложилодинPrompt2Sign, многоязычный набор данных языка жестов, направлен на устранение ограничений существующих наборов данных языка жестов.,И способствовать прогрессу исследований в задачах создания языка жестов (SLP), распознавания (SLR) и перевода (SLT).,Кроме того, автор также обучил многоязычную Большую модель языка жестов: SignLLM.,Создание скелетных жестов языка жестов на 8 языках.,И все достигли уровня СОТА.
Prompt2Sign
Набор данных Prompt2Sign получен из общедоступного набора данных языка жестов в Интернете и видео.,Охватывает 8 различных языков жестов, включая американский язык жестов (ASL).,Это делает его первой коллекцией данных, в которой интегрированы многоязычные языки жестов. На рисунке ниже показан обзор набора данных.,Содержит текст, подсказать слово、видеокадры, а также ключевые моменты данных.
Процесс производства этого набора данных выглядит следующим образом:
- Сначала используйте OpenPose для обработки видео,Нормализовать информацию о позе в видеокадрах в наш предопределенный формат.,Это уменьшает избыточность и облегчает обучение Модели с использованием seq2seq и text2text;
- Сократите необходимость в ручных аннотациях и повысьте экономическую эффективность за счет автоматического создания подсказок.
- наконец,Повышен уровень автоматизации обработки инструмента.,Сделайте инструмент эффективным и легким,Увеличение мощности обработки данных без дополнительной загрузки модели,Решены трудности ручной предварительной обработки и сбора данных.
Хотя набор данных Prompt2Sign открывает новые возможности в области создания языка жестов, он также требует улучшения существующих моделей. Потому что предыдущие модели столкнутся с некоторыми новыми проблемами при использовании новых наборов данных:
- Различия жестовых языков в разных странах означают, что разные жестовые языки невозможно обучать одновременно.,Это ограничивает многоязычные возможности Модели.
- Обработка большего количества языков и больших наборов данных приводит к медленному процессу обучения.,Также есть сложности со скачиванием, хранением и загрузкой данных.,Поэтому необходимо изучить методы высокоскоростной тренировки.
- Существующая структура Модель не может освоить больше языков.,Также трудно понять более сложную, естественную человеческую речь.,Необходимо повысить способность Модели к обобщению и способность понимать подсказки.
Чтобы преодолеть вышеуказанные проблемы, автор предложил SignLLM, которая является первой крупномасштабной моделью многоязычной генерации языка жестов (SLP), разработанной на основе набора данных Prompt2Sign, которая может генерировать скелетные жесты языка жестов на 8 языках на основе текстовых подсказок.
SignLLM
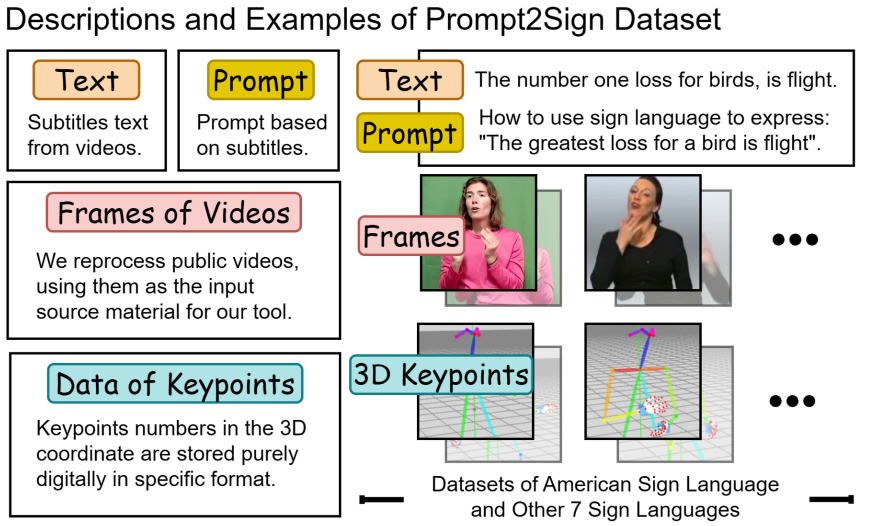
SignLLM имеет два разных режима: Multilingual Switching Framework (MLSF) и Prompt2LangGloss, которые предназначены для достижения эффективного многоязычного SLP, избегая при этом семантической путаницы и улучшая способность модели понимать сложный ввод на естественном языке.
На рисунке выше показаны входные и выходные данные модели в этой статье. Текст — это входные данные режима 1, а Prompt — входные данные режима 2. Эти два режима обрабатывают разные варианты использования, а именно:
- «Режим 1»Многоязычная система переключения (MLSF), который параллельно генерирует несколько жестовых языков путем динамического добавления групп кодеков.
- «Режим 2»Prompt2LangGloss,способен сделать SignLLM Поддерживает генерацию статических одногрупповых кодеков, предназначенных для понимания более сложного ввода на естественном языке.
Чтобы сократить затраты времени на обучение и ускорить процесс обучения модели на большем количестве языков и больших наборах данных, автор применяет концепцию RL к процессу обучения модели генерации жестового языка.
В частности, входная последовательность модели считается состояниями, выходная последовательность — действиями, а близость прогноза к фактическому результату определяет значение вознаграждения. За счет максимизации ожидаемого совокупного вознаграждения традиционная проблема минимизации среднеквадратической ошибки (MSE) переформулируется для применения стратегии RL к задаче генерации языка жестов.
Для дальнейшего повышения эффективности обучения в этой статье представлен приоритетный канал обучения (PLC). ПЛК преобразует вознаграждения в вероятности выборки и выбирает более ценные (т. е. с более высоким вознаграждением) образцы данных для обучения. Эта стратегия позволяет модели переключить свое внимание на наиболее ценные образцы на основе постоянно накапливаемых знаний, ускоряя процесс обучения.
Результаты экспериментов
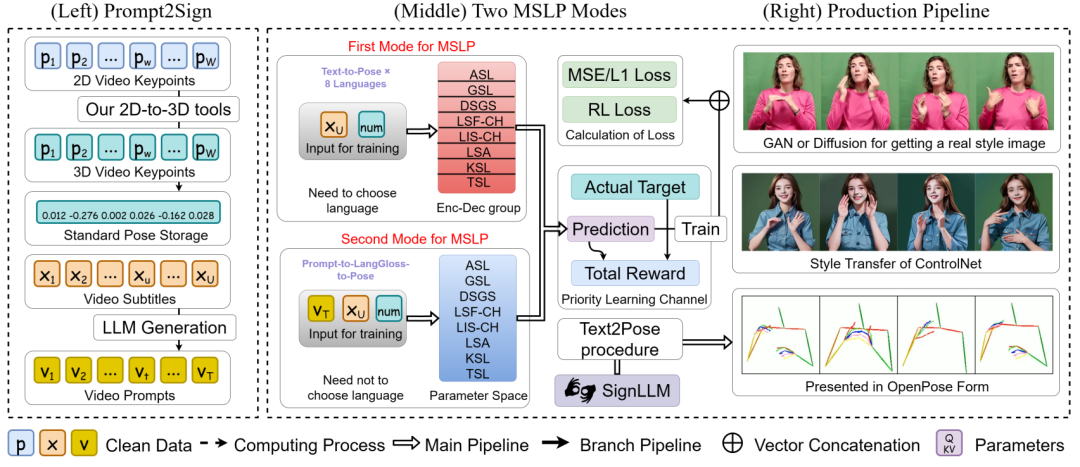
В следующей таблице показаны результаты сравнения SignLLM и базового уровня в задаче Text to Pose для набора данных ASL. Можно обнаружить, что SignLLM лучше, чем базовый метод.
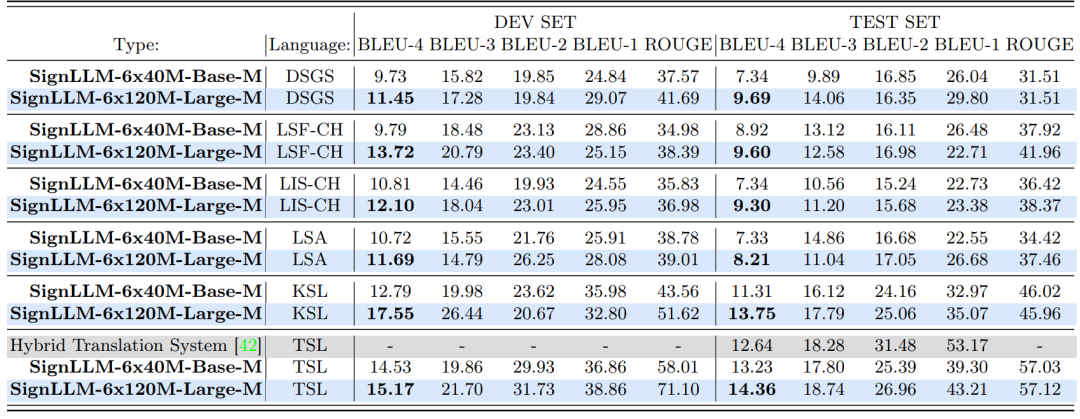
В следующей таблице показана производительность SignLLM в задаче MSLP для различных наборов данных языка жестов. SignLLM также показывает отличную производительность.
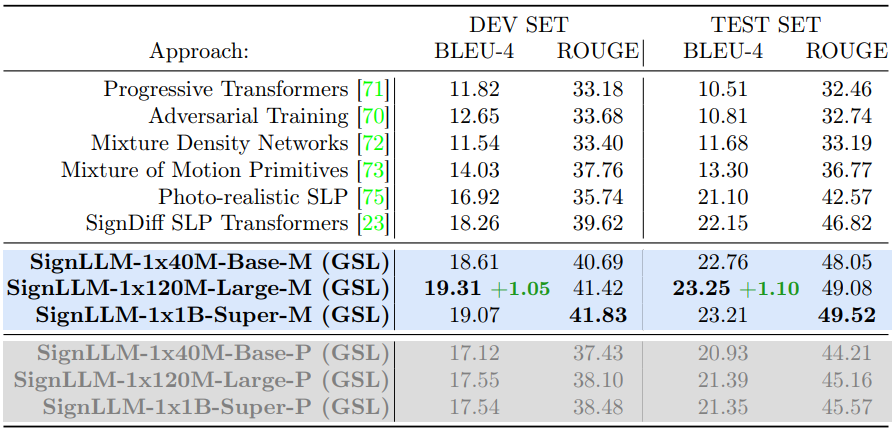
В следующей таблице показаны результаты сравнения SignLLM с современными методами в наборе данных немецкого языка жестов (GSL). Можно обнаружить, что SignLLM сопоставим или превосходит производительность текущих моделей SOTA.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
