RLHF и DPO: упрощение и улучшение тонкой настройки языковых моделей
Что такое РЛХФ?
Обучение с подкреплением обратной связи от человека (RLHF) Это передовой рубеж в области обучения, в котором человеческие предпочтения и рекомендации используются для обучения и совершенствования машинного обучения. По своей сути RLHF — это парадигма машинного обучения, которая сочетает в себе элементы обучения с подкреплением и обучения с учителем, что позволяет системам искусственного интеллекта учиться и принимать решения более гуманистическим способом. Важность RLHF заключается в его потенциале для решения некоторых фундаментальных проблем искусственного интеллекта, таких как необходимость того, чтобы модели понимали и уважали человеческие ценности и предпочтения. Традиционные модели обучения с подкреплением учатся посредством вознаграждений, генерируемых в результате взаимодействия с окружающей средой. RLHF С другой стороны, это представляет человеческую обратную связь как ценный источник рекомендаций. Эта обратная связь может помочь системе ориентироваться в пространстве принятия решений, оставаться в соответствии с человеческими ценностями и делать более осознанный и этичный выбор. РЛХФ Уже переходим от систем обработки естественного языка и рекомендаций к роботибеспилотным автомобилинашли применение в широком спектре。Путем включения обратной связи с людьми в процесс обучения,RLHF имеет возможность улучшить производительность модели.,Улучшите пользовательский опыт,И способствовать ответственному развитию технологий для ИИ.
Почему RLHF важен?
Обучение с подкреплением на основе отзывов людей стала важной и влиятельной концепцией в области искусственного интеллекта (ИИ).
- Ориентированный на людей ИИ: RLHF Одной из основных мотиваций является создание системы, более ориентированной на человека. Традиционному ИИМоделю часто не хватает понимания и уважения к человеческим ценностям и предпочтениям. РЛХФ Постарайтесь восполнить этот пробел, включив в процесс обучения обратную связь и рекомендации людей. Этот метод гарантирует, что системы ИИ соответствуют человеческим ценностям, что делает их более безопасными и полезными в реальных приложениях.
- Решение проблем со спецификацией вознаграждений: В стандартном обучении с подкреплениемсередина,Определение функции вознаграждения, которая точно отражает желаемое поведение агента ИИ, может оказаться сложной задачей. RLHF предлагает альтернативный метод.,Позволяет людям оставлять отзывы о поведении агента. Такая обратная связь, предоставляемая человеком, может служить более интуитивным и адаптируемым способом управления обучением.,Особенно в сложных и кропотливых задачах.
- Этическая разработка ИИ: Обеспечение того, чтобы системы ИИ действовали этично и не вели себя вредно или предвзято, является предметом растущей озабоченности. на. RLHF предлагает метод, который привносит этические соображения в обучение ИИ. Вовлекая людей в цикл обратной связи, RLHF может помочь выявить и смягчить предвзятость, обеспечить справедливость и уменьшить плохое поведение.
- Улучшенный пользовательский интерфейс:RLHF могу сделать ИИСистема обеспечивает более персонализированныйи Удовлетворительный пользовательский опыт。Изучая человеческие предпочтенияиобратная связь,Эти системы могут быть адаптированы к потребностям и предпочтениям отдельных пользователей.,Тем самым повышая удовлетворенность и участие пользователей.
- Междоменные приложения:RLHF Применимо к различным областям,Включает обработку естественного языка, роботы, беспилотные автомобили、Здравоохранение и т. д. Его универсальность делает его ценным инструментом для улучшения умственных способностей в различных приложениях.
- Безопасное и надежное развертывание искусственного интеллекта: вместе с ИИСистемы все больше интегрируются в общество,Обеспечение его безопасности и надежности имеет решающее значение. RLHF помогает разрабатывать продукты, которые более безопасны и менее подвержены случайным и нежелательным действиям. Это позволяет Модели учиться на реальных отзывах людей.,Это снижает риск катастрофического сбоя.
- Постоянные исследования и прогресс:RLHFэто быстро развивающаяся сфера,Постоянно проводить исследования и разработки. Его важность заключается в его потенциале раздвинуть границы того, чего может достичь ИИ.,Сделайте его более адаптируемым, более ответственный、Более соответствует человеческим ценностям.
Как работает РЛХФ?
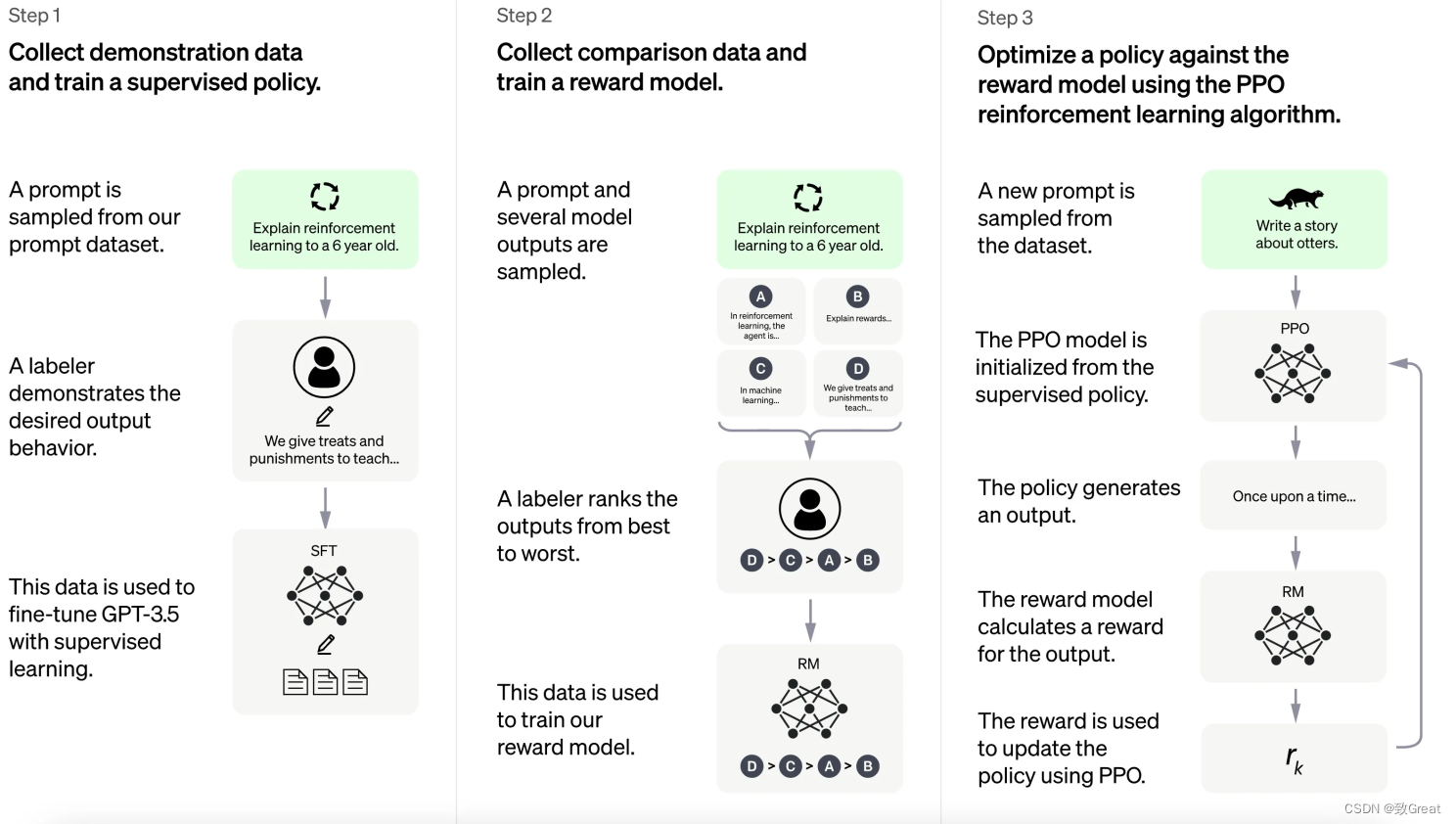
Обучение с подкреплением обратной связи от человека (RLHF) этомногоэтапный процесс,Используйте силу человеческого руководства для эффективного обучения ИИМодель. Он включает в себя несколько основных этапов, которые можно резюмировать следующим образом:
1. Предварительно обученная языковая модель:
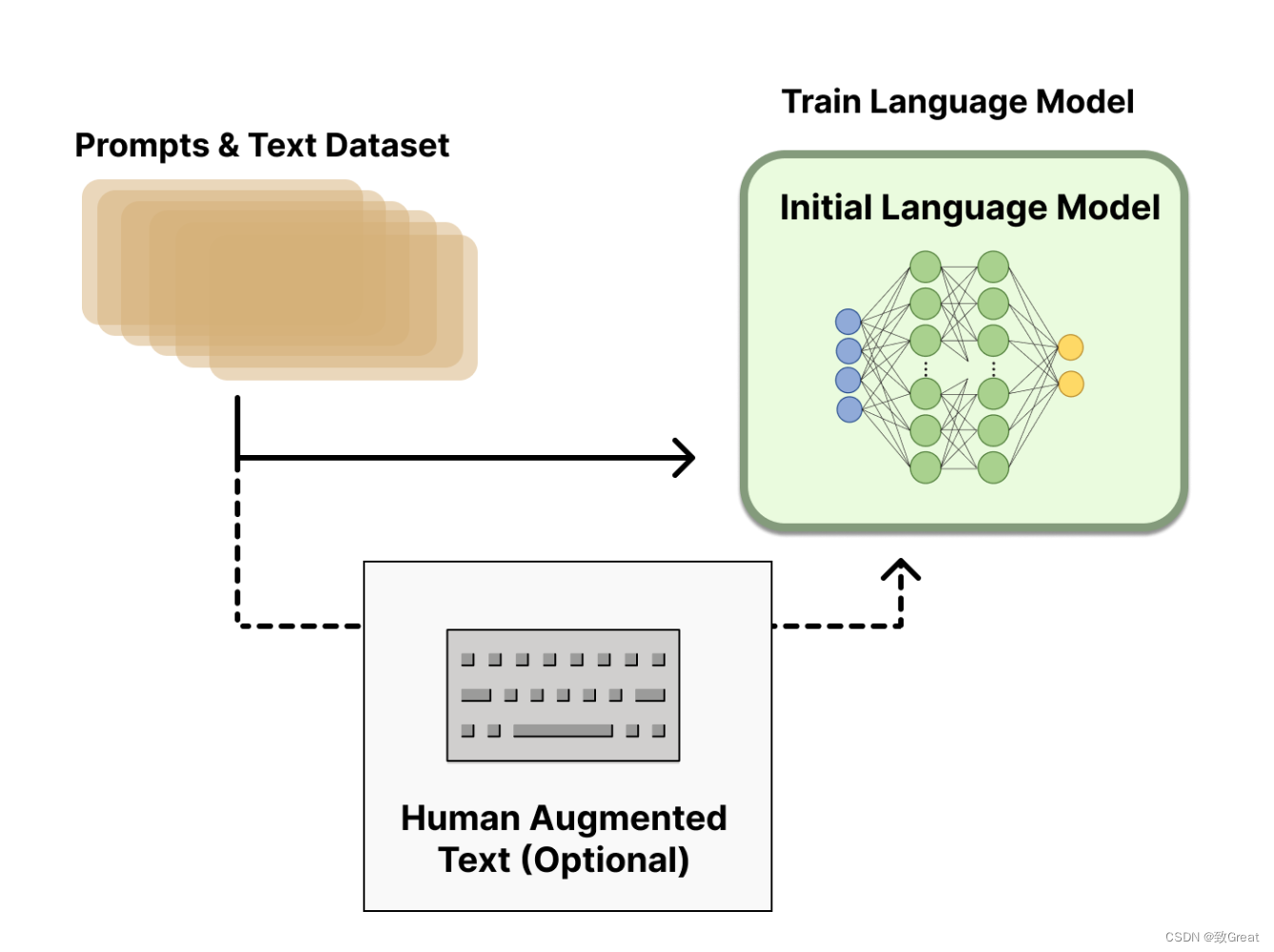
- Начните с традиционного метода предварительно обученной языковой модели. Эта начальная модель RLHF отправная точка.
- Выбор базового языка Модель может отличаться,От меньшей Модели до современной большой Модели с миллиардами параметров.
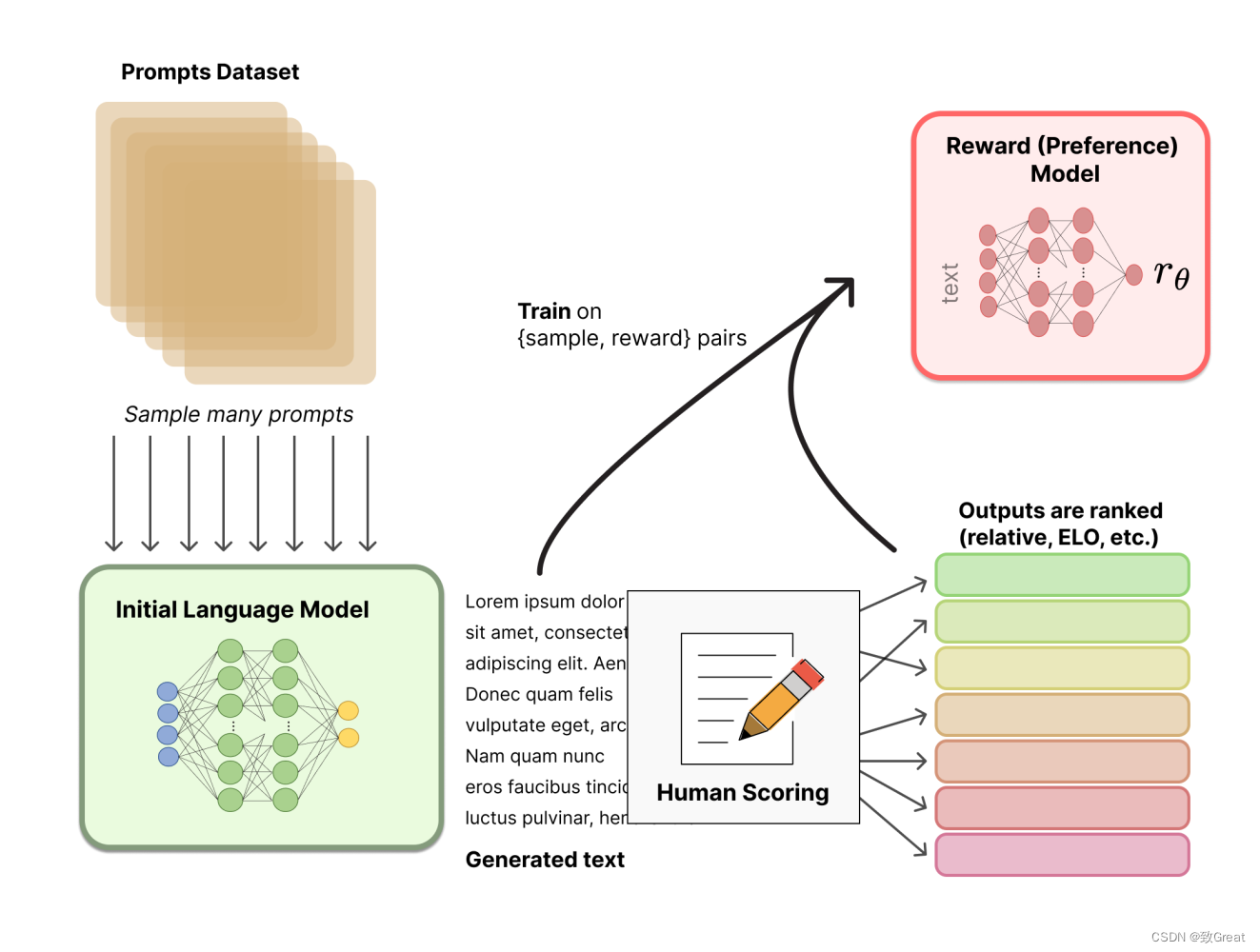
2. Соберите данные и обучите модель вознаграждения:
- в РЛХФ,Сгенерируйте данные для обучения модели вознаграждения.,Это играет жизненно важную роль в управлении поведением модели AI.
- Один из способов сбора данных — взаимодействие с человеком. Пользователи или эксперты предоставляют отзывы и оценку работы агента ИИ.
- Например,в языковых задачах,Пользователи могут оценивать различные ответы, сгенерированные ИИ.,Укажите, какие ответы являются предпочтительными.
- или,данные можно получить из демо-версии,Человек выполняет необходимые задачи в демонстрации,Предоставляйте контролируемые обучающие сигналы.
- Собранные данные используются для вознаграждения за обучение. Модель,Модель предсказывает, насколько «хорошим» или «предпочтительным» является тот или иной ход ИИ, основываясь на отзывах людей.
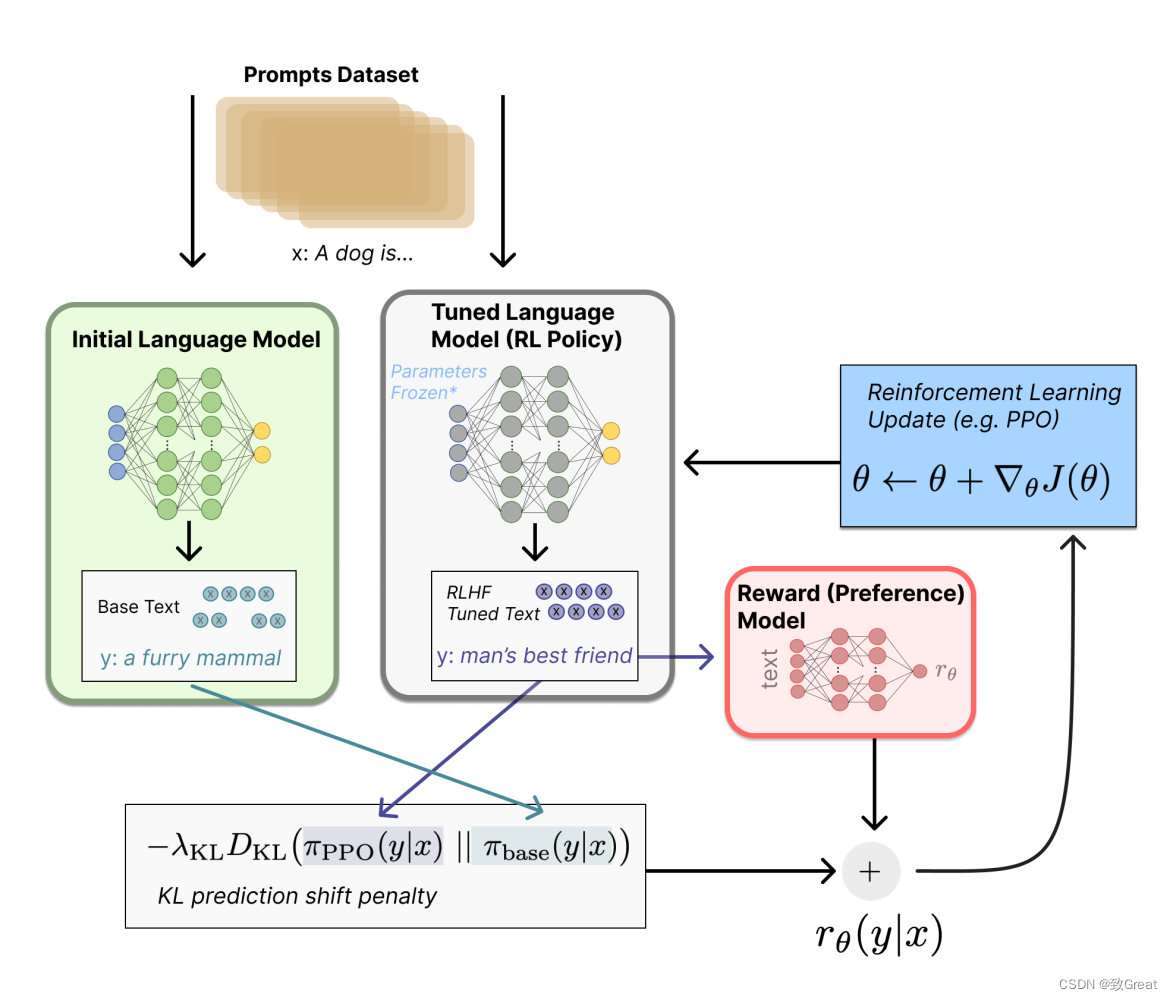
3. Точная настройка языковой модели
- использоватьобучение с подкреплением ТЕХНОЛОГИЯ тонкая на заранее обученном языке Модель настройка。
- В процессе тонкой настройки вознаграждайте Модель за управление движениями Модели. Модель стремится максимизировать совокупное вознаграждение на основе прогноза Модели вознаграждения.
- Агенты ИИ совершают действия в среде, а Модель вознаграждения обеспечивает обратную связь о качестве этих действий.
- Затем,Агент корректирует свои действия для получения операций с более высоким вознаграждением.,Эффективно учитесь на обратной связи с людьми.
- тонкая настройка Обычно включает в себя выполнение нескольких итераций, в ходе которых агент со временем совершенствует свое поведение.
4. Развертывание и итерация
- от тонкая настройканазад,Модель RLHF может быть использована в реальных приложениях.,Интерактивная или автономная работа пользователя.
- Отзывы пользователей во время развертывания могут быть использованы для дальнейшего усовершенствования Модели в итеративном процессе.
- Путем постоянного сбора отзывов пользователей и переподготовки Модель,Системы RLHF могут со временем адаптироваться и улучшать свои характеристики.
5. Оценка и мониторинг
- Непрерывная оценка и мониторинг необходимы для обеспечения того, чтобы модель RLHF работала должным образом.
- Отслеживайте такие показатели, как удовлетворенность пользователей, уровень успешности задач и этические соображения, чтобы оценить производительность Модели.
- если что-то пойдет не так,Модель можно обновлять и переобучать для устранения дефектов.
RLHF сочетает в себе предварительно обученные языковые модели с обратной связью, предоставляемой людьми. в сочетании для эффективной точной настройки AI Модель. Он устраняет разрыв между человеческими предпочтениями ИИ, что приводит к созданию более полезной и последовательной системы ИИ. Этот процесс обучения на основе отзывов людей представляет собой динамичный и повторяющийся процесс, который способствует улучшению нашего бизнеса.
Что такое оптимизация проксимальной политики (PPO)?
Оптимизация проксимальной политики (PPO) Это алгоритм обучения с подкреплением, используемый для обучения языковых моделей и других моделей машинного обучения. Он направлен на оптимизацию политической функции агента (в данном случае языковой модели) для максимизации ожидаемого совокупного вознаграждения в данной среде. ППО Известна своей комплексной моделью «Стабилизация секса и эффективность тренировок». Ниже приводится PPO О том, как работают языковые модели:
- Стратегия и функция ценности: PPO Здесь задействованы два ключевых компонента: функция политики (обычно представленная нейронной сетью) и функция ценности. Функция политики определяет действие или решение на основе входных данных, а функция ценности оценивает ожидаемое совокупное вознаграждение за следование определенной стратегии.
- Итерация стратегии: PPO следует за итерацией стратегический метод. Все начинается с первоначальной стратегии,и итеративно уточнять его для повышения производительности. во время каждой итерации,Модель Собирайте данные, взаимодействуя с окружающей средой. Для языка Модель,Это взаимодействие может включать в себя создание текста на основе подсказок ввода.
- целевая функция: PPO предназначен для максимизации Функция приходит с стратегией оптимизации. Эта функция объединяет два ключевых термина: суррогатную цель и термин регуляризации. Суррогатная цель использует данные, собранные во время текущей итерации, для измерения эффективности новой стратегии по сравнению со старой. Формализация терминологии не позволяет политике слишком сильно меняться.
- Обрезать: PPO Одной из отличительных особенностей является использование Обрезать, чтобы гарантировать, что обновления политики не будут слишком экстремальными. Обрезать ограничивает обновление стратегии определенным диапазоном, чтобы предотвратить серьезные изменения в стратегии, вызывающие неточности в процессе обучения.
- несколько Epoch: PPO Обычно выполняется на каждой итерации несколькооптимизации. эпоха. В каждую эпоху он обновляет политику, используя собранные данные. Повторяйте этот процесс, пока не найдете удовлетворительную стратегию.
- стратегическая оценка: Функция ценности в стратегической рейтинг играет жизненно важную роль. Он оценивает ожидаемую прибыль от следования текущей стратегии. Эта оценка помогает оценить качество стратегии и направить ее на доработку.
- Стабилизироватьсексиобразецэффективность: PPO пользуется популярностью за свою стабилизацию и эффективность выборки. и какое-то другое обучение с подкреплениемалгоритмпо сравнению с, он имеет тенденцию обеспечивать более плавное обновление политики, что делает его подходящим для обучения языкам Модели, где качество генерации текста имеет решающее значение.
PPO можно использовать для таких задач, как генерация текста, диалоговые системы и понимание естественного языка. Это помогает оптимизировать реакцию модели и корректировать ее поведение на основе сигналов обучения с подкреплением, что делает ее более эффективной в различных языковых приложениях.
В целом, оптимизация проксимальной политики — это метод обучения с подкреплением, который можно использовать для обучения языковых моделей генерированию связного и контекстуального текста, что делает его ценным для задач обработки и понимания естественного языка.
Прямая оптимизация предпочтений (DPO)
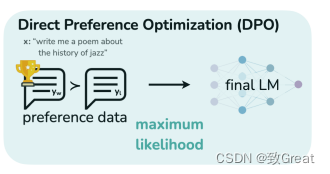
Прямая оптимизация предпочтений (DPO) это точно настроенная модель большого языка (LLM) к новому методу, который соответствует предпочтениям человека. и Включая сложноеобучение на основе отзывов людей с подкреплением (RLHF) Традиции метода разные, DPO упрощает процесс. Он работает путем создания набора данных пар человеческих предпочтений, каждая из которых содержит подсказку и два возможных способа ее выполнения — один предпочтительный и один непопулярный. Затем программа LL.M была доработана, чтобы максимизировать вероятность создания предпочтительных вариантов завершения и минимизировать вероятность создания непопулярных вариантов завершения. и RLHF По сравнению с ДПО Имеет множество преимуществ:
- Простота: DPO легче реализовать и обучить, что упрощает его использование.
- Стабилизироватьсекс: Нелегко попасть в локальную оптимальность и обеспечить более надежный процесс обучения.
- DPO требует меньше вычислительных ресурсов, что делает его вычислительно более легким.
- Эффективность: экспериментальные результаты показывают, что DPO может превосходить RLHF в таких задачах, как контроль эмоций, подведение итогов и построение диалогов.
DPO Ключевые особенности включают одноэтапный алгоритм, устойчивость к изменениям гиперпараметров и эффективность при выполнении различных задач обработки естественного языка. Если твоя цель тонкая настройка LLM Чтобы удовлетворить конкретные предпочтения человека, DPO Может предоставить более RLHF Более простой и эффективный вариант.
DPO VS RLHF
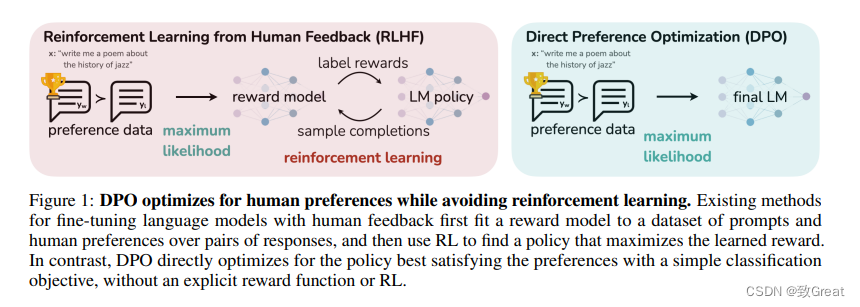
Прямая оптимизация предпочтений (DPO) и**Обучение с подкреплением обратной связи от человека (RLHF)** — это два разных метода, используемых для тонкой настройкабольшой язык Модель (LLM), чтобы соответствовать человеческим предпочтениям.
метод
DPO: DPO — это одноэтапный алгоритм, который можно оптимизировать напрямую. LLM для генерации предпочтительных ответов. Он формулирует проблему как задачу классификации с использованием набора данных пар человеческих предпочтений, где каждая пара содержит сигнал и два возможных завершения (одно предпочтительное, одно нежелательное). ДПО Максимизируйте вероятность создания предпочтительного завершения и минимизируйте вероятность создания непредпочтительного завершения. Это не предполагает несколько раундов обучения. RLHF:RLHF Это двухэтапный процесс. Во-первых, это соответствует модели вознаграждения, отражающей человеческие предпочтения. Затем он использует обучение с подкреплением для обучения LLM. руководитьтонкая настройка, чтобы максимизировать предполагаемое вознаграждение, сохраняя при этом согласованность исходной Модели. РЛХФ Требуется несколько раундов обучения, которые могут потребовать больших вычислительных ресурсов.
сложный
DPO:иRLHFпо сравнению с, DPO легче внедрить и обучить. Это не требует создания отдельной модели вознаграждения, от LLM Выборка или обширная настройка гиперпараметров. RLHF: Благодаря двухэтапному процессу подбора и точной настройки модели вознаграждения, RLHFболеесложный,И требования к расчетам выше。
Стабилизировать
DPO: DPO более устойчив к изменениям гиперпараметров. Во время тренировки меньше шансов попасть в локальный оптимум. RLHF: RLHF чувствителен к выбору гиперпараметров и может потребовать тщательной настройки, чтобы избежать несоответствий.
эффективность
DPO:иRLHFпо сравнению с, DPO Более эффективен в вычислениях и обработке данных. С его помощью можно достичь аналогичных или лучших результатов с меньшими ресурсами. RLHF:RLHF Для получения аналогичных результатов могут потребоваться больше вычислительных ресурсов и большие объемы данных.
способность
DPO:DPO Было доказано, что он эффективен при решении различных задач, включая контроль эмоций, подведение итогов и построение диалогов. В некоторых исследованиях он превосходит RLHF。 RLHF: RLHF также эффективен в согласовании LLM и человеческих предпочтений.,Но могут потребоваться более масштабные эксперименты.и Корректирование。
TRL — Обучение армированию трансформаторов
TRL(Transformer Reinforcement Learning) — это комплексная библиотека, предназначенная для использования при обучении. с Тренажерный конвертор с подкреплением, предназначенный для языковой модели. Он содержит множество инструментов, которые могут поддерживать все, от контролируемой тонкой Начиная с настройки (SFT), проходя этап моделирования вознаграждения (RM) и заканчивая оптимизацией. проксимальной политики (ППО) этап. Эта библиотека и🤗 Фреймворк Transformers легко интегрируется.
https://huggingface.co/docs/trl/index
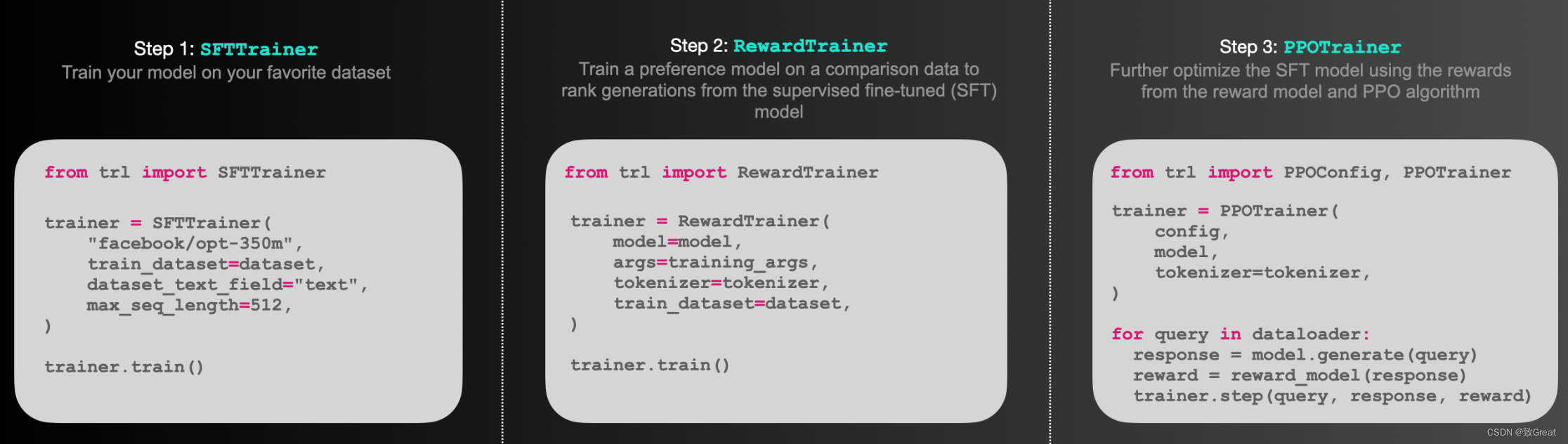
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=script_args.beta,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
dpo_trainer.save_model()Суммируя, DPO для RLHF Предлагает более простую, более стабилизирующую и более рассчитанную альтернативу эффективности для тонкой настройка LLM соответствовать человеческим предпочтениям. Оба варианта имеют свои преимущества и могут быть выбраны с учетом конкретных требований проекта и имеющихся ресурсов.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
