Решение проблем глубокого обучения | На основе Transformer, решение ограничений производительности пиковых нейронных сетей (SNN)!

Глубокое обучение имеет решающее значение для интерпретации сложных сред, особенно в таких областях, как автономная навигация и робототехника. Однако получение точных показаний глубины по данным камеры событий остается огромной проблемой. Камеры событий работают иначе, чем традиционные цифровые камеры, поскольку они непрерывно собирают данные и генерируют асинхронные двоичные импульсы, которые кодируют информацию о времени, местоположении и интенсивности света. Однако уникальный механизм выборки камер событий делает стандартные алгоритмы на основе изображений непригодными для обработки импульсных данных. Это побудило к разработке инновационных импульсно-чувствительных алгоритмов специально для камер событий. Эта задача еще больше усложняется нерегулярностью, непрерывностью, шумом, а также пространственными и временными свойствами импульсных данных. использовать Transformer Из-за сильной способности нейронных сетей к обобщению пространственно-временных данных автор предлагает чисто импульсный метод. Transformer Сеть для оценки глубины по данным пульсовых камер. Решить пульснейронную сеть(SNN)изпроизводительностьпредел,Авторы представляют новую одноэтапную кросс-модальную структуру передачи знаний.,использоватьискусственная нейронная сеть(ANN)из大型视觉基础Модель(DINOv2)из知识来增强在有限данныеначальствоSNNизпроизводительность。 Экспериментальные результаты автора на синтетических наборах данных и наборах реальных данных показывают, что по сравнению с существующими моделями авторский метод значительно улучшает как абсолютную относительную ошибку, так и квадратичную относительную ошибку (на 49% выше, чем у эталонной модели Spike-T, соответственно). и 39,77%). Помимо точности, предложенная модель также демонстрирует пониженное энергопотребление, что является критическим фактором для практического применения.
1 Introduction
Камеры, основанные на событиях, представляют собой биологические датчики, которые асинхронно захватывают визуальную информацию и сообщают об изменениях яркости в режиме реального времени [1, 2]. По сравнению с традиционными камерами, на К основным преимуществам датчиков событий относятся низкая задержка между запускающими событиями [3], низкое энергопотребление [4] и динамический диапазон [5]. Эти преимущества напрямую связаны с аппаратной конструкцией, т.е. основе事件из相机已经被应用于各种领域,Например, 3D-сканирование[6],Робот Видение[7]иавтомобильная промышленность[8]。Однако,на практике,на основе датчика событий фиксируются уникальные пульсданные,Эти данные кодируют информацию об изменениях интенсивности света в сцене. Чрезвычайно высокий уровень шума в данных,И отсутствуют общие алгоритмы обработки этих данных.,Обеспечивает возможности, сравнимые с традиционными алгоритмами машинного зрения при работе с данными традиционных цифровых камер.
Spiking Neural Networks (SNN) — это биологически вдохновленные модели нейронных сетей, которые имитируют поведение биологических нейронных сетей. В отличие от использования непрерывных значений в традиционных алгоритмах зрения, SNN используют дискретные функции, называемые импульсами, для представления и обработки информации [9]. Следовательно, это, естественно, идеальная парадигма для обработки выходных данных камеры на основе событий [10, 11, 12].
Оценка глубины является сложной задачей в области компьютерного зрения и широко используется в автономном вождении, автоматизированных роботах, мониторинге роста сельского хозяйства и мониторинге выбросов углекислого газа в лесах. Современные работы по прогнозированию глубины в основном сосредоточены на сочетании стандартных покадровых камер с искусственными нейронными сетями (ИНС) [13, 14, 15]. Однако камеры, основанные на событиях, и алгоритмы их обработки в приложениях для измерения глубины все еще находятся в зачаточном состоянии [5]. Существует еще много проблем, в том числе две основные проблемы: отсутствие магистральной сети SNN для извлечения признаков и низкая производительность моделей SNN.
Отсутствует проект магистральной сети SNN для оценки глубины импульсных данных. Камера событий генерирует непрерывный поток в двоичной нерегулярной структуре данных со сверхвысокими временными свойствами. SNN применяется к наборам данных камеры событий и реализуется посредством высокоуровневых архитектур использования ANN, таких как ResNet-подобный SNN и пульсовая рекурсивная нейронная сеть. сеть[16, 17, 18, 19]), чтобы улучшить производительность оценки глубины. На основе механизма самообслуживания для фиксации зависимостей на больших расстояниях в изображениях/видео, особенно видения пространственных и временных особенностей. Transformer [20, 21] (Ви Т) в настоящее время является самой популярной структурой ИНС. Это повышает производительность ИИ во многих задачах компьютерного зрения, таких как классификация/сегментация изображений [22, 7], обнаружение объектов [23] и оценка глубины [24, 25]. на основе Transformer SNN – это метод, который Transformer Новая SNN, архитектура которой объединена с SNN, имеет большой потенциал для устранения узкого места SNN в производительности при обработке данных потока импульсов.
В [26] авторы использовали исходную структуру ViT в качестве основы для извлечения особенностей из пространственно-временной области импульсных данных. Результаты показывают, что Transformer подходит для извлечения пространственно-временных характеристик из импульсных данных. Однако по сравнению с SNN исходная структура Transformer имеет большое количество операций умножения и потребляет чрезмерную вычислительную энергию. В [27] и [28] авторы предложили использовать чисто импульсное самообслуживание и остаточную связь, чтобы избежать неимпульсных вычислений в Transformer. Это важный шаг на пути к потенциальному применению Transformer для оценки глубины по импульсным данным.
Производительность модели SNN. Одной из самых больших проблем, с которыми в настоящее время сталкиваются SNN, является их неспособность достичь эквивалентной производительности при обработке пиковых данных, как это могут сделать ANN при обработке неимпульсивных данных. Импульсные данные недифференцируемы, что затрудняет обучение SNN с использованием алгоритма обратного распространения ошибки. Обратное распространение ошибки на основе градиента — мощный алгоритм для обучения ИНС, но его нельзя использовать напрямую для СНС [29]. Решением является прямое преобразование ИНС в СНС, но оно может привести к неопределенным ошибкам или потере информации о синхронизации импульса [19]. В то же время наборы данных на основе событий меньше по сравнению со статическими изображениями, используемыми для традиционного обучения ИНС, что делает СНС склонной к переобучению и ограничивает ее способность к обобщению [29]. Дистилляция знаний — это метод глубокого обучения, который переносит знания из модели учителя в модель ученика. Это позволяет обучить облегченную модель (модель ученика) столь же точной, как и более крупную модель (модель учителя). В настоящее время уже существует несколько моделей ИНС, обученных с использованием больших объемов данных, которые могут обеспечить нулевое обучение для оценки глубины. Эти модели теоретически могут быть перенесены в обучение моделей SNN.
в этой работе,Благодаря уникальным биологическим свойствам SNN и передовой кросс-модальной дистилляции знаний на основе модели видения (DINOv2),Автор предлагаетна на основе кросс-модальной дистилляции знаний, основанной на пульсе Transformer Сеть для оценки глубины. Насколько известно авторам, это первое исследование Transformer SNN используется для оценки глубины. Автор подчеркивает, что основные результаты данного исследования заключаются в следующем:
- Автор представляет инновационный импульс Transformer сеть, посвященная оценке глубины. Сеть включает в себя механизм остаточного обучения, управляемый пульсами, и механизм самоконтроля, который устраняет необходимость умножения с плавающей запятой и целочисленных чисел с плавающей запятой. Принцип действия основанульс. Такой подход значительно снижает потребление энергии, обеспечивая при этом высокую производительность.
- Авторы разрабатывают комплексную одноэтапную схему дистилляции знаний.,Черпайте вдохновение из последнего и среднего слоев большой визуальной базы «Искусственная нейронная сеть Модель» (DINOv2). Используя потерю домена и семантическую потерю,Авторский фреймворк эффективно передает знания в SNN,Облегчает эффективное обучение на ограниченных наборах данных.
- Авторы сравнивают с современными методами на реальных и синтетических наборах данных.,Была проведена тщательная экспериментальная оценка. Результаты показывают,Предложенный авторами метод надежно предсказывает карты глубины.,и значительно превосходит другие конкурирующие методы.
2 Related works
В этом разделе рассматриваются соответствующие работы по монокулярной оценке глубины на основе изображений и событий, пиковым нейронным сетям (SNN) и дистилляции знаний для SNN.
Image-based and Event-based Monocular Depth Estimations
Оценка глубины изображения направлена на измерение расстояния каждого пикселя относительно камеры. Монокулярная оценка глубины, то есть оценка глубины на основе одного изображения, является сложной, но многообещающей технологией. Его преимущество состоит в том, что не требуются два изображения, что делает его более практичным в реальных приложениях, например на мобильных устройствах, где невозможно захватить пару изображений. В зависимости от типа используемых данных авторы могут классифицировать монокулярные методы оценки глубины на методы, основанные на изображениях, и методы, основанные на событиях [14]. Монокулярная оценка глубины на основе изображений использует информацию из изображений RGB для оценки глубины, тогда как методы на основе событий используют импульсные данные, генерируемые камерами событий. Оценка монокулярной глубины на основе изображений более распространена, чем монокулярная оценка глубины на основе событий, поскольку изображения RGB легче собирать и обрабатывать. Камеры событий — это новый класс датчиков, которые выводят изменения яркости в виде асинхронного потока «событий», а не статических изображений. Это делает их идеальными для оценки глубины в сложных условиях слабого освещения и быстрого движения [33].
Недавние разработки в области глубокого обучения позволили разработать монокулярные модели оценки глубины, которые могут достичь удовлетворительной точности и надежности [14, 34, 35]. Подобно другим моделям глубокого обучения, эти модели обычно включают в себя общий кодировщик, который извлекает абстрактные функции из контекстной информации, и декодер, который восстанавливает информацию о глубине из функций. Для изображений RGB в [36] авторы использовали ResNet-50 в качестве кодера и новый блок повышающей дискретизации в качестве декодера для оценки глубины по одному изображению RGB. В [32] авторы использовали ViT вместо сверточных сетей в качестве основы для задачи оценки глубины. Эксперименты показали, что Transformer способен предоставлять более точные и глобально согласованные прогнозы, чем традиционные сверточные сети. Для данных о событиях в [33] авторы предложили новую модель глубокого обучения под названием E2Depth, которая способна с высокой точностью оценивать глубину по камерам событий. В этой работе используется полностью сверточная нейронная сеть, основанная на архитектуре U-Net. В [38] многомасштабный кодер используется для извлечения признаков из стеков событий смешанной плотности, а декодер с масштабированием используется для прогнозирования глубины. Структура Transformer также используется в монокулярной оценке глубины на основе событий. В [39] предлагается EReFormer, который основан на Transformer и способен оценивать глубину по камерам событий с более высокой точностью.
Традиционное глубокое обучение основано на контролируемом обучении, которое обычно требует больших объемов обучающих данных. Спрос на данные огромен, особенно для архитектуры Transformer, которая может изучать зависимости на больших расстояниях [21]. Для монокулярной оценки глубины использование больших объемов обучающих данных может улучшить производительность модели [32]. Необходимость больших объемов данных для обучения существенно ограничивает масштабируемость и удобство использования модели. Более того, поскольку поток пакетных данных очень плотный, практически невозможно обучать модели глубокого обучения контролируемым образом, поскольку невозможно получить парные метки глубины.
Чтобы справиться с этими проблемами, самоконтролируемое обучение, неконтролируемое обучение и дистилляция знаний стали новыми горячими точками в обучении моделей глубокого обучения на основе импульсных данных. Автоматическое/неконтролируемое обучение — это метод машинного обучения, при котором модель обучается на немаркированных данных, а дистилляция знаний — это метод переноса знаний из большой обученной модели в новую модель. Разумно ожидать, что эти методы перспективны для монокулярной оценки глубины на основе событий. Авторы статьи в [39] улучшают производительность предложенной модели, внося в нее знания большой обученной модели. [40] предложили метод неконтролируемой оценки глубины импульса посредством передачи знаний из модели оценки глубины на основе изображений.
2.2 Spiking Neural Networks (SNNs)
В отличие от традиционных моделей глубокого обучения, которые используют непрерывные десятичные значения для передачи информации, импульсные нейронные сети (SNN) используют дискретные последовательности импульсов для передачи информации и вычислений. Спайковые нейроны получают непрерывные значения и преобразуют их в последовательность спайков. Было предложено множество различных моделей импульсных нейронов. Модель Ходжкина-Хаксли была одной из первых моделей, описывающих поведение биологических нейронов [41]. Это базовая модель для объяснения потока импульсов в нейронах, но она слишком сложна для реализации в кремнии. Модель Лжикевича [42] упрощает модель Ходжкина-Хаксли, которая представляет собой двумерную модель, описывающую динамику мембранного потенциала нейронов. Нейрон с интегралом утечки (LIF) — еще одна простая модель нейрона, широко используемая в нейробиологии и искусственных нейронных сетях. Она проще модели Лжикевича, но отражает основные особенности работы нейронов. Его можно использовать для создания SNN и реализовать в сверхбольших интегральных схемах (СБИС) [5]. Мембранный потенциал LIF-нейронов контролируется следующим уравнением:
где v — мембранный потенциал, t — время, tau — постоянная времени, а I — ток. Ток I может быть возбуждающим или тормозящим. Возбуждающие токи делают мембранный потенциал более положительным, а тормозные токи — более отрицательным. Когда мембранный потенциал достигает порога, нейрон запускает потенциал действия. В данном исследовании LIF используется для построения предлагаемой модели.
В структурном проектировании SNN, аналогичном ANN, по мере увеличения глубины шиповых нейронных сетей (SNN) их производительность значительно улучшается [16, 43, 17]. В настоящее время большинство SNN основаны на структуре ANN и могут быть разделены на две основные категории: SNN на основе CNN и SNN на основе трансформатора.
Как наиболее успешная модель CNN, ResNet широко изучалась с целью расширения глубины SNN [16, 17]. SEW ResNet [16] решает проблему исчезновения/взрыва градиента в SNN с помощью метода, называемого пластичностью, зависящей от времени (STDP). Он доказал свою эффективность в различных задачах, включая классификацию изображений и обнаружение объектов. Однако сверточные сети обладают трансляционной инвариантностью и локальными зависимостями, но их вычисления имеют фиксированные рецептивные поля, что ограничивает их способность улавливать глобальные зависимости. Напротив, ViT основан на механизме самообслуживания, который может фиксировать долгосрочные зависимости. Они основаны на архитектуре Transformer, изначально разработанной для задач обработки естественного языка.
SNN на основе трансформатора представляет собой новый тип SNN, который сочетает в себе архитектуру Transformer с SNN и потенциально способен преодолеть узкое место в производительности SNN.
Яо и др. [44] и Чжоу и др. [27] предложили две разные модели импульсивного внимания к себе. Они избегают умножения, используя только операции маски и сложения, которые эффективны и имеют низкое энергопотребление. Чжоу и др. [28] предложили Spikingformer, который изменяет остаточное соединение, делая его исключительно управляемым событиями, что повышает производительность и при этом обеспечивает энергоэффективность.
В настоящее время ViTs продемонстрировали самые современные результаты в различных задачах зрения, включая классификацию изображений, обнаружение объектов, сегментацию и оценку глубины. Однако SNN на основе трансформатора все еще находится в зачаточном состоянии с точки зрения оценки глубины [26]. Существует две основные проблемы: 1) сложность обучения моделей SNN, основанных исключительно на Трансформаторе; 2) ограниченная доступность данных двойной глубины в данных о событиях для поддержки обучения модели Трансформатора; Фильтрация знаний дает возможность обучать новые или небольшие модели, используя хорошо предварительно обученные модели. В этом исследовании авторы предлагают метод дистилляции знаний, который переносит знания модели ИНС в SNN.
Knowledge distillation for SNN
Дистилляция знаний – этоСжатие моделитехнология,Он передает знания от большой Модели учителя к Маленькой Модели ученика. Ему отдали предпочтение из-за его способности обучать глубокие модели с ограниченными ресурсами [45]. в то же время,Обработка знаний также доказала свою эффективность в повышении производительности SNN. В [46],Авторы предлагают метод дистилляции знаний, который переносит знания от больших обученных SNN к маленьким SNN в задачах классификации изображений. Результаты показывают,Использование знаний предварительно обученных больших моделей может значительно повысить производительность маленьких моделей.,Тем самым увеличивается возможность развертывания высокой производительности Модели на платформах с ограниченными ресурсами. В исследованиях [29],Предлагается метод дистилляции знаний SNN для классификации изображений. Этот метод представляет собой дистилляцию знаний.,Это повышает точность студенческой SNN на 2,7–9,8%. Автор [47] нашел,Парадигма дистилляции знаний может эффективно сократить разрыв между ИНС и СНС. Производительность модели улучшается с использованием аналогичных структур ANN и SNN. В [42],Впервые дистилляция знаний используется для оценки глубины SNN. Автор предлагает кросс-модальный метод передачи знаний предметной области.,Для неконтролируемой оценки глубины пульса с использованием данных RGB из открытого источника.
Однако существующие методы дистилляции знаний для SNN требуют предварительного обучения модели учителя. В настоящее время крупномасштабные базовые модели стали новой горячей точкой глубокого обучения [48]. Большие базовые модели обучаются на крупномасштабных данных (обычно посредством самостоятельного или полуконтролируемого обучения), так что изученные функции можно напрямую использовать в различных последующих задачах или при дистилляции знаний. Например, преобразователи плотного прогнозирования (DPT) [32] — это ViT, предназначенный для задач прогнозирования глубины, который использует 1,4 миллиона изображений для обучения монокулярной оценке глубины. DINOv2 [30] использует ViT-Giant, более крупную версию ViT с 10 миллиардами параметров. Он более мощный, чем предыдущие модели ViT, превосходя предыдущие методы самостоятельного обучения в различных задачах компьютерного зрения, особенно в оценке глубины. В этой работе авторы делают первую попытку перенести знания из большой базовой модели (DINOv2) [30] в SNN для оценки глубины.
3 The Proposed Method
Авторы предлагают новую чисто импульсную вычислительную сеть Transformer для оценки глубины посредством кросс-модальной дистилляции знаний. Сетевая архитектура использует структуру кодер-декодер, в которой трансформатор служит основным вычислительным блоком кодера. Декодер Fusion специально разработан для объединения функций с разных этапов кодирования для создания комплексной карты глубины. Блок-схема метода показана на рисунке 1 и состоит из трех основных компонентов: 1) импульсного преобразователя, 2) дистилляции знаний и 3) объединенной головки оценки глубины.
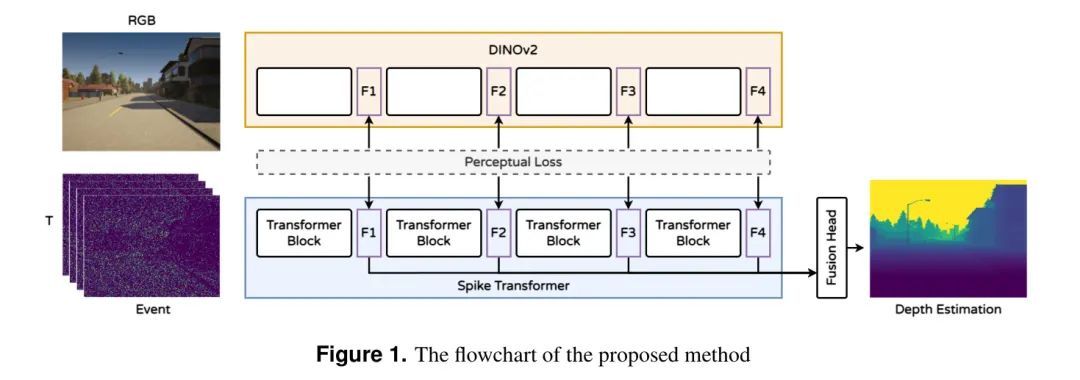
В основе предложенного авторами метода лежит следующее:
- Transformer Он известен своей способностью улавливать долгосрочные зависимости посредством самообслуживания и умножения матриц, но часто требует выполнения ресурсоемких операций, которые не подходят для парадигм, управляемых пиками. В этом контексте авторы представляют чисто импульсный Transformer сеть,Сеть управляется остаточным обучением и вниманием к себе. Этот дизайн позволяет избежать традиционного умножения с плавающей запятой и целочисленного числа с плавающей запятой.,Строго соблюдайте принцип пульса.,Это приводит к значительной экономии энергии при сохранении мощности.
- SNN — модель энергосбережения,Они используют двоичный пульс вместо непрерывных значений.,Но для достижения высокой точности также требуется глубокая архитектура.,Это может привести к большим вычислительным затратам и высокому энергопотреблению. При дистилляции знаний можно использовать знания предварительно обученной ИНС (учителя) для руководства обучением меньшей ИНС (студента).,Это позволяет ему достичь аналогичной производительности с меньшими ресурсами. в этой работе,Автор предлагает кросс-модальный метод дистилляции знаний между данными RGB-событий. Предлагаемый метод обучается путем сопоставления данных событий RGBи.,И рассуждения выполняются только по данным события. Предварительно обученная крупномасштабная визуальная база DINOv2 используется в качестве преподавателя для дистилляции знаний. Модель,Не участвует в обучении,Извлекайте только функции из RGBданных.
- В отличие от традиционных полностью сверточных сетей, использующих понижающую дискретизацию, Transformer Сеть поддерживает согласованное пространственное представление, что имеет решающее значение для глобальных восприимчивых полей для таких задач, как сегментация или прогнозирование глубины. Поэтому автор предлагает объединенную головку для оценки глубины, которая может использовать каждый Transformer Функции этапа для оптимизации эффективности оценки глубины.
Pure spike-driven transformer network for depth estimation
В этой работе авторы предлагают вычислительную сеть с чистым импульсным преобразованием для оценки глубины посредством кросс-модальной дистилляции знаний. Конструкция предлагаемого метода соответствует шаблону, который логически разделяет сеть на кодеры и декодеры. Блок преобразования импульса выбирается в качестве кодера для извлечения пространственно-временных характеристик из импульсных данных. Головка объединенной оценки глубины спроектирована как декодер для генерации результатов глубины на уровне пикселей на основе представлений объектов.
3.1.1 Spike-transformer
Предлагаемый Spike Transformer (спайк-трансформер) соответствует базовой структуре исходного Vision Transformer (Vision Transformer, ViT), включая Spiking Patch Embedding (Вложение шипового патча) и Spiking Transformer Block (Блок шипового трансформатора). Учитывая последовательность событий
Встраивание блоков шипов используется для преобразования входных данных в последовательность токенов, которые могут быть обработаны архитектурой Transformer, где входные данные событий проецируются в блоки в виде шипов.
,
. Затем эти импульсные блоки
Передайте несколько импульсов в блок Трансформатора (L). Учитывая, что авторы использовали дистилляцию знаний из больших моделей, в этом подходе использовалось только минимальное количество блоков, т. е. L = 4. Вдохновленный [27, 28], чтобы избежать вычислений без скачков в традиционной архитектуре глубокого обучения, автор использует Spiking Self Attention (SSA) и Spiking MLP в блоке Spiking Transformer.
Встраивание блоков импульсов реализовано в оригинальном ViT [20], который представляет изображение как серию маркеров посредством встраивания блоков. Это делается путем разделения изображения на сетку блоков и преобразования каждого блока в вектор. В этой работе авторы реализуют эту операцию посредством комбинации сверточной пакетной нормализации (ConvBN), максимального пула (MP) и многошагового LIF (MLIF). Структура показана на рисунке 2. Этот процесс можно выразить как:
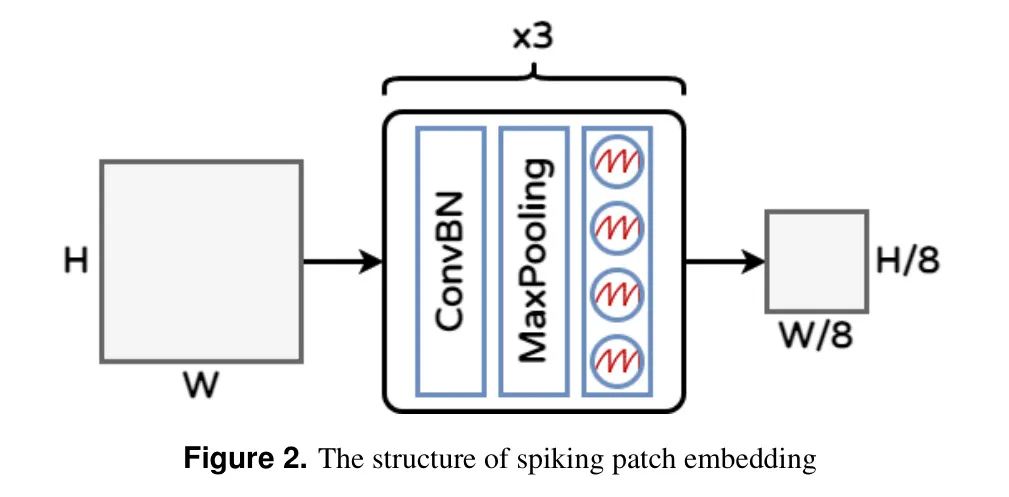
в ConvBN Содержит 2D-сверточные слои (шаг 1, 3).
размер ядра 3) и максимальный пул. Количество операций может быть больше 1. При использовании нескольких блоков количество выходных каналов постепенно увеличивается, а размер объекта уменьшается вдвое, что в конечном итоге соответствует размерам встраивания блока в ViT.
Блок Impulse Transformer Структура блока Impulse Transformer включает в себя механизм Impulse Self-Attention (SSA) и блок Impulse MLP, как показано на рисунке 3. Основываясь на результатах исследования [28], авторы поместили многошаговый LIF перед ConvBN в остаточном механизме, чтобы исключить умножение с плавающей запятой и вычисления смешанной точности во время работы ConvBN. Эта настройка также позволяет ConvBN легко заменить традиционные линейные слои и пакетную нормализацию. Операции SSA математически можно описать как:
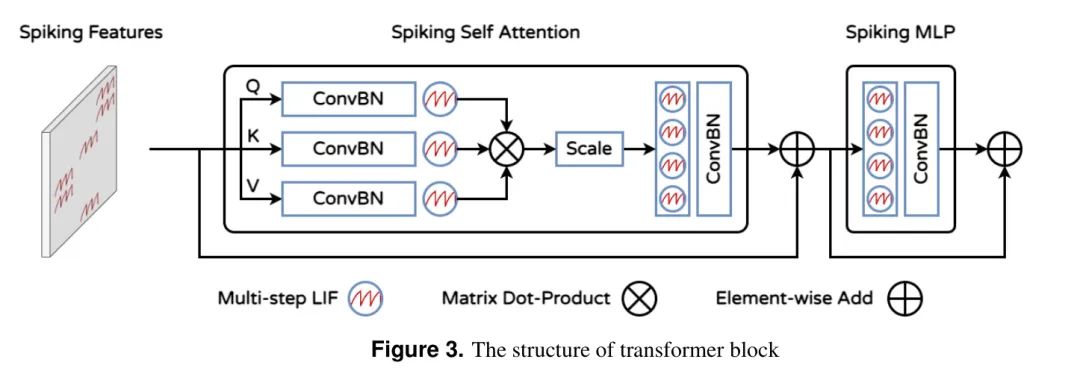
переменная
Представляет чистые импульсные данные (содержащие только 0 и 1). коэффициент масштабирования
Используется для настройки максимального значения результатов матричного умножения. Это не влияет на природу ССА. Импульсный блок MLP состоит из остаточных связей и комбинации MLIF и ConvBN.
3.1.2 Fusion Depth estimation Head
Целью головки оценки глубины является предсказание глубины каждого пикселя, что аналогично задаче сегментации. В настоящее время наиболее распространенной структурой сегментации является многомасштабная структура на основе U-Net. Декодер U-Net использует пропускаемые соединения из разных масштабных слоев кодера, чтобы помочь сохранить пространственную информацию входного изображения. Это помогает гарантировать, что декодер имеет доступ к низким Level Ватака Level Характеристики, низкие Level Функции важны для захвата деталей, и высокая Level Особенности важны для понимания общей структуры изображения. В отличие от традиционной структуры CNN, Transformer Размер скрытых функций в структуре постоянен, и напрямую использовать структуру U-Net непросто. Существует множество моделей, использующих Transformer как разделенный Backbone и редизайн Transformer структура, такая как многомасштабное видение Transformer [49], Видение пирамиды Transformer [50], Многолучевое зрение Transformer [51] и т. д. В этой работе дистилляция знаний выбрана для преобразования обученных крупномасштабных Transformer Знания извлекаются в предлагаемую SNN. Изменение структуры существенно снизит эффективность перегонки. Поэтому для прогнозирования глубины предлагается объединенная головка оценки глубины.
Структура сварочной головки для оценки глубины показана на рисунке 4. Первым шагом работы Fusion Head является сборка внутренних элементов блока Transformer в представление объектов, подобное изображению. Эти представления функций затем объединяются в окончательный плотный прогноз посредством пропуска соединений. Общая структура повышения дискретизации используется для восстановления представления объекта до исходного размера данных. Учитывая функцию ввода
,i=1,2,3,4。
Knowledge distillation from DINOv2
в этой работе,Описание кросс-модального подхода к дистилляции знаний,Виспользовать разработал крупномасштабную модель фундамента видения, в частности DINOv2, для руководства авторским обучением SNN. DINOv2Модель обучалась на разнообразном наборе данных, содержащем 142 миллиона изображений [30].,Есть несколько преимуществ:
- Архитектура DINOv2 основана на видении Transformer (ViT),Похоже на авторскую Модель,Благодаря конструкции и совместимости по размерам,Это способствует эффективной дистилляции знаний.
- Функции, извлеченные из предварительно обученной модели DINOv2, были использованы в NYUиSUN. Достигните высочайшей производительности при использовании набора данных для эталонной оценки глубины RGB-D. На рисунке 5 показаны результаты визуализации самообслуживания и оценки глубины функций DIVO_V2 для линейного обнаружения в авторском наборе данных по замороженным функциям DINOv2. Как показано на рисунке, ДИВНО Представление объекта v2 (средний столбец на рисунке 5) и результаты оценки глубины, близкие к истинной глубине изображения, поддерживают DINO. Гипотеза о том, что V2Model может обеспечить эффективное руководство в процессе обучения по дистилляции знаний.

На рисунке 1 показан процесс дистилляции знаний. Автор замораживает DINOv2 как модель учителя. Выходные функции DINOv2 рассматриваются как цель в обучении автора. Чтобы получить тот же размер объекта, авторы повысили дискретизацию изображения RGB в 1,75 раза. Окончательный размер модели учителя:
。
На рисунке 6 показан алгоритм дистилляции знаний. В авторском методе автор использует функцию слияния потерь. Потери L1 измеряют разницу в функциях между сетью ученика и сетью учителя. Также была принята потеря восприятия [52], которая обычно используется в машинном обучении для количественной оценки разницы между двумя изображениями. Функция потерь L2, масштабно-инвариантная метрика [53], выбрана для оценки результатов оценки глубины. Это масштабно-инвариантное свойство гарантирует, что потери не нанесут ущерб модели из-за масштабных различий во входных данных, демонстрируя ее эффективность для монокулярной оценки глубины. Масштабно-инвариантные потери определяются следующим уравнением:
в
— это разница между прогнозируемой глубиной и истинной глубиной пикселя i, а n — это
общее количество пикселей.
4 Experiments
В этой работе авторы провели два эксперимента, чтобы продемонстрировать эффективность предложенной SNN. Сначала авторы представляют детали набора данных, использованного в этом эксперименте. Затем мы оцениваем эффективность нашего метода, включая точность и энергопотребление. Мы оцениваем наш метод на данных о реальных событиях и синтетических данных о событиях, чтобы продемонстрировать надежность модели и возможности обобщения. Наконец, было проведено комплексное исследование абляции для изучения влияния каждого компонента.
Datasets
Для оценки модели авторы использовали два набора данных, включая реальные и синтетические данные.
Первый набор данных представляет собой синтетический набор данных из [26], который создан на основе набора данных DENSE [33] и содержит 30 наборов данных для различных погодных условий и условий освещения. Четкие карты глубины и рамки интенсивности для шутеров от первого лица. Чтобы получить поток импульсов с высоким временным разрешением, авторы интерполируют видео, чтобы создать соседние 30 FPSрамка之间из中间RGBрамка。использоватьRGBрамка之间из绝对强度信息,Каждый пиксель датчика может киспользовать механизм генерации импульсов, непрерывно накапливая интенсивность света.,Создает высокое временное разрешение (128
30 FPS) пульсового потока, что в 128 раз превышает частоту кадров видео. Версия набора данных DENSE «пульс» (т. е. DENSE) содержит восемь последовательностей пульсов: пять для тренировки и три для оценки. Каждая последовательность состоит из 999 сэмплов, каждый сэмпл представляет собой кортеж RGB-изображения, карты глубины и потока пульсов. Каждый поток пульса моделируется между двумя последовательными изображениями, генерируя двоичную последовательность из 128 кадров пульса (каждый кадр имеет размер 346 кадров).
260) для изображения непрерывного процесса динамичных сцен.
Второй набор данных DSEC представляет собой набор данных о реальных событиях, который обеспечивает набор стереоскопических данных в сценах вождения. Он содержит данные с двух монохромных камер событий и двух цветных камер с глобальным затвором как в хороших, так и в сложных условиях освещения. Для прогнозирования глубины также предоставляются синхронизированные с оборудованием лидарные данные. Этот набор данных содержит 41 последовательность, собранную во время вождения в различных условиях освещения, и обеспечивает несоответствие GT для оценки глубины. В этой работе 29 последовательностей (70%) использовались для обучения модели и 12 для оценки. Каждая последовательность состоит из 200-900 семплов, каждый семпл представляет собой RGB-изображение, карту глубины (плотное несоответствие) и 480 кадров импульсов, содержащих 16
Кортеж потоков импульсов размером 640. На рисунке 7 показаны два образца данных, использованных в этой работе.

Experiment design
Начинается опытно-конструкторская часть.
4.2.1 Experiment 1. Qualitative and Quantitative Comparisons
В этом разделе мы оцениваем производительность оценки глубины и энергопотребление нашей SNN на синтетическом наборе данных (DENSE) и реальном наборе данных (DSEC) и сравниваем его с тремя конкурирующими сетями плотного прогнозирования, а именно U-Net [37], E2Depth [ 33] и «Спайк-Т» [26]. U-Net использует 2D-сверточные слои в качестве кодера и фокусируется на извлечении пространственных признаков, в то время как E2Depth применяет слой ConvLSTM, который объединяет CNN и LSTM для захвата пространственных и временных характеристик. Spike-T использует блоки на основе трансформаторов для одновременного изучения пространственно-временных функций. Таким образом, эти модели становятся прямыми и непосредственными конкурентами автора.
4.2.2 Experiment 2 Ablation study: the contribution of the proposed modules
В этом подразделе подробно проводится исследование абляции, чтобы изучить вклад двух новых компонентов в модель авторов. Это объединенная головка оценки глубины и технология дистилляции знаний соответственно. В этой статье будет проанализировано и обсуждено их влияние на производительность модели.
Metrics
Для оценки эффективности предложенного метода было выбрано несколько показателей, в том числе абсолютная относительная ошибка (Abs Rel.), квадратичная относительная ошибка (Sq Rel.), средняя абсолютная ошибка глубины (MAE), среднеквадратическая логарифмическая ошибка (RMSE log) и индекс точности (Согл.
). Формула выглядит следующим образом:
Абсолютная относительная погрешность (Abs Rel.) Рассчитаем среднюю ошибку каждого пикселя на нормализованной карте глубины по формуле:
Он нормализует значения глубины до диапазона [0,1].
Квадратная относительная погрешность (Sq Rel.) Формула:
Поскольку его числитель представляет собой квадрат, он фокусируется на больших ошибках глубины.
Средняя абсолютная ошибка (MAE) Его можно сформулировать как:
Среднеквадратическая ошибка (RMSE) — это классический индикатор ошибки прогнозирования на уровне пикселей, и его логарифмическая версия может быть выражена как:
Точность (Акк) к
Представляет все пиксели, которые соответствуют приведенным ниже условиям.
Процент:
Acc=\left(\frac{\widehat{\mathcal{D}}_{p}}{\mathcal{D}_{p}},\frac{\mathcal{D} _{p}}{\widehat{\mathcal{D}}_{p}}\right)<thr \tag{10}
в
,
,
。
Experiment Result
Начинается раздел результатов экспериментов.
4.4.1 Qualitative and Quantitative Comparisons
Экспериментальные исследования авторов включают количественный анализ производительности и энергопотребления с использованием синтетических (DENSE) и реальных (DESC) наборов данных. Для комплексной оценки результатов было использовано в общей сложности девять показателей.
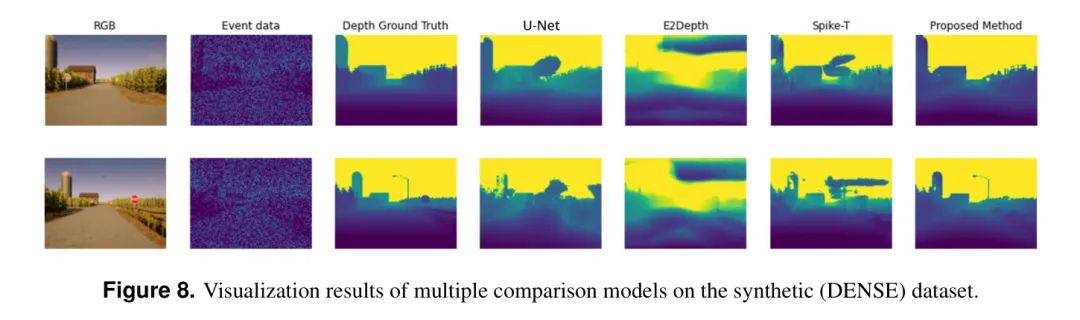
В таблице 1 представлено количественное сравнение производительности с использованием синтетических наборов данных (в частности, набора данных DENSE). Результаты показывают,Предложенный авторами метод превосходит другие методы практически по всем оцениваемым показателям. в частности,В Абсолютная относительная погрешность (Abs.Rel) и Квадратная относительная погрешность (Sq.Rel) Это особенно важные показатели в задачах оценки глубины.,Были замечены значительные улучшения. Абс.Отн по авторскому методу составляет 0,80.,Значительно превзошел U-Net (2,89), E2Depth (9,91) и Spike-T (1,57),Представляет собой улучшение на 72%, 91,9% и 49% соответственно. такой же,Sq.Rel авторского метода составляет 8,32.,Гораздо ниже, чем U-Net (72,25), E2Depth (96,01) и Spike-T (39,77).,Они представляют собой улучшение на 88,5%, 91,3% и 79% соответственно. также,Метод авторов хорошо работает с показателями точности (
,
,
) также демонстрируют незначительные улучшения, достигая 0,53, 0,68 и 0,76 соответственно, что немного лучше, чем у конкурирующих методов.
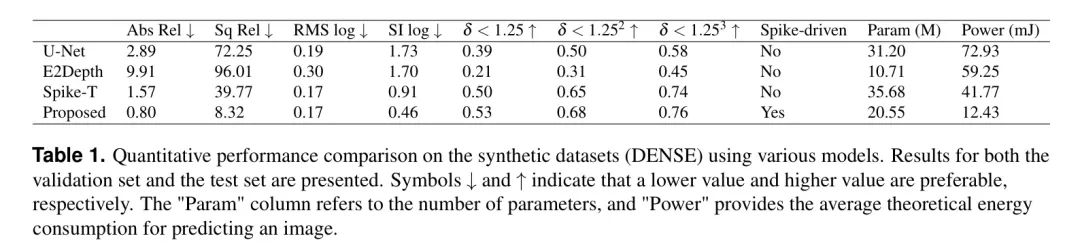
По энергопотреблению,Предложенный метод расчета чистого пульса демонстрирует явные преимущества перед конкурентами. также,Использование дистилляции знаний позволяет авторскому методу использовать всего четыре блока Трансформера.,По сравнению с методом Spike-T с использованием восьми блоков Transformer.,Количество параметров значительно уменьшено.
Эти экспериментальные результаты показывают,Предложенный автором метод позволяет более эффективно улавливать пространственные и временные характеристики нерегулярного непрерывного течения.,Обеспечить удовлетворительную точность. Это дополнительно проиллюстрировано на рисунке 8.,На рисунке показаны результаты визуализации множественных сравнений Модель на наборе проверки синтетических данных. Визуализированная демонстрация,В отличие от методов U-Net и Spike-T (которые предсказывают детали, но неправильно оценивают глубину) или метода E2Depth, который дает размытые результаты и теряет детализацию данных,Авторский подход эффективно улавливает более сложные детали.,Включая крошечные структуры, острые края и контуры.
также,Чтобы проверить обобщающую способность Модели,Автор оценивает предложение Модель на наборе данных о реальных событиях DESC.,И сравнил с тремя конкурирующими Моделью (E2Depth, Spike-TиU-Net). Стоит отметить, что,Набор данных композиции DENSE содержит 128 кадров пульса.,Но реальный набор DESCданные содержит всего 16 кадров. Авторскую Модель SpikeU-Net необходимо переобучить на этом сокращенном наборе данных. Однако,на Метод на основе SNN (E2DepthиSpike-T) не подлежит переобучению из-за недостаточных параметров обучения, поэтому необходимо скопировать DESCданные на 128 кадров для адаптации к их настройкам. Поэтому производительность E2DepthиSpike-T ожидается ниже. Результаты таблицы 2 показывают, что предложенная Модель лучше модели E2Depth и Spike-TiU-Net по всем показателям. Особенно в Абсе Rel、Sq Rel、RMS журнал и СИ журнал и другие показатели к и показатели точности (
,
,
), более высокие оценки указывают на лучшую производительность, и эти результаты подчеркивают эффективность предлагаемой модели при обработке данных о реальных событиях с импульсных камер.
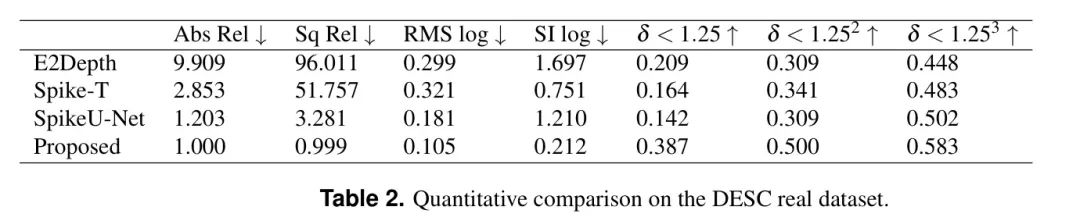
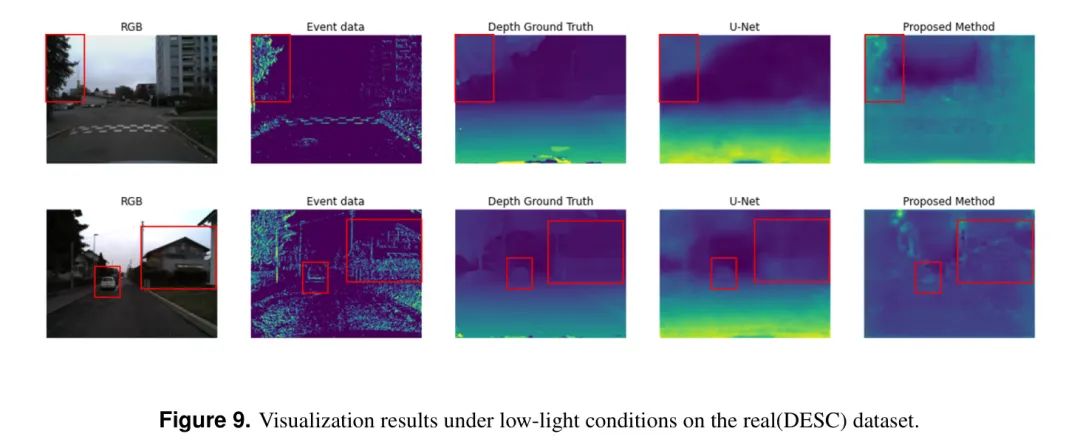
На рисунке 9 показаны результаты визуализации в условиях низкой освещенности. Авторский метод эффективно идентифицирует придорожные деревья, дома и объекты транспортных средств, расположенные в центре дороги.
4.4.2 Ablation study
В этом подразделе представлено исследование абляции для оценки эффективности предлагаемой объединенной головки оценки глубины и модуля дистилляции знаний (KD).
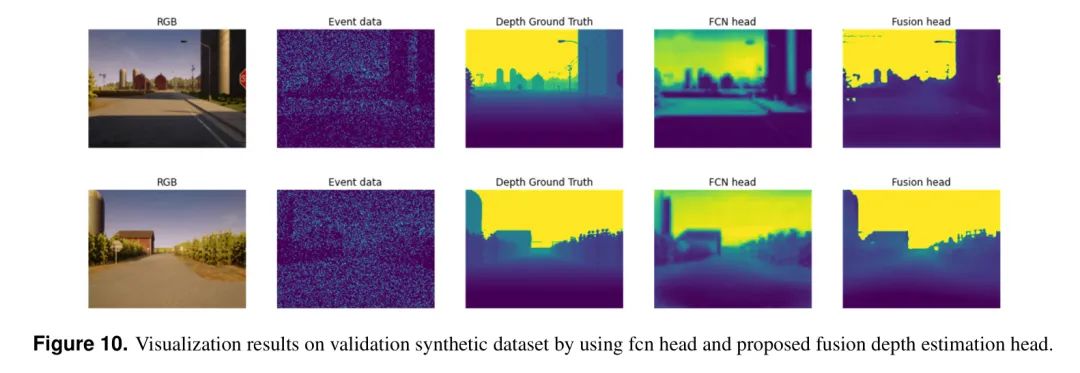
В Таблице 3 представлено сравнение количественных показателей синтетического набора данных (DENSE) в исследовании абляции. Как показывают результаты, все показатели точности страдают при использовании линейной полностью сверточной сети (FCN) для оценки глубины. В частности, абсолютная относительная ошибка (Abs Rel) увеличилась с 0,80 до 2,85, а квадратичная относительная ошибка (Sq Rel) увеличилась с 8,32 до 51,76. На рисунке 10 показаны результаты визуализации с использованием двух разных головок. Если полагаться исключительно на конечные функции, созданные Трансформером, использование линейной головки FCN приводит к тому, что изображение становится заметно размытым и теряет детали. Напротив, сварочная головка авторов объединяет многомасштабные функции и, следовательно, имеет преимущества в восстановлении деталей по сравнению с линейной головкой FCN.

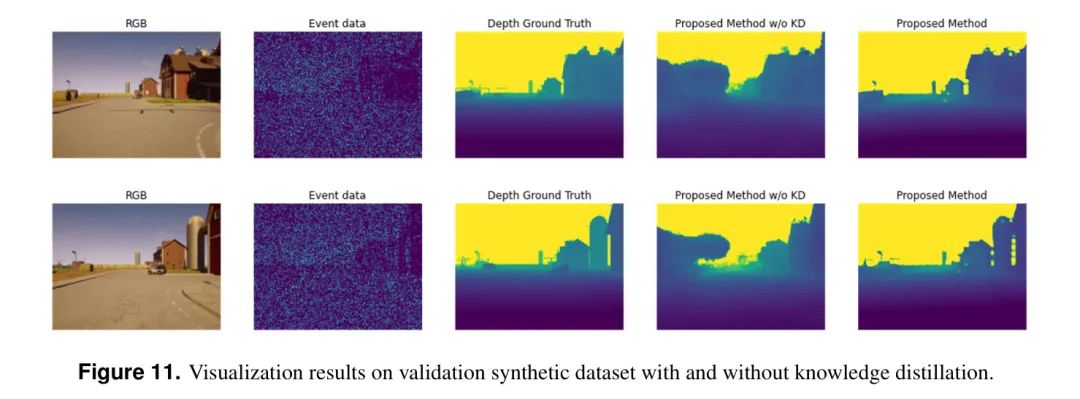
На рисунке 11 показана визуализация результатов с дистилляцией знаний и без нее. Результаты без дистилляции знаний аналогичны базовой модели в эксперименте 1. Шум в данных о пиках приводит к менее точным оценкам глубины для некоторых частей облака точек. Однако использование дистилляции знаний позволяет модели более точно предсказывать глубину отдаленных облаков, что объясняется расширенными возможностями обобщения, полученными на основе большого количества базовых моделей.
5 Conclusion
Рисунок 11: Визуализация результатов проверки на синтетических наборах данных с дистилляцией знаний и без нее.
Рисунок 10: Результаты визуализации набора синтетических данных проверки с использованием головки fcn и предлагаемой головки объединенной оценки глубины.
В этой статье предлагается новый всплеск Transformer Сеть для получения данных о расчетной глубине со спайк-камер. Объединив остаточное обучение, управляемое спайками, и механизм самовнимания, основанный на спайках, авторы разработали полностью управляемый спайками механизм. Transformer архитектура. Эта конструкция значительно повышает вычислительную эффективность пиковых нейронных сетей (SNN). Кроме того, авторская одноэтапная система передачи знаний опирается на такие инструменты, как DINO. Крупномасштабные базовые модели искусственных нейронных сетей, такие как V2, могут улучшить производительность SNN даже при ограниченных данных. Экспериментальные оценки авторов на синтетических и реальных наборах данных показывают значительные улучшения по нескольким показателям, особенно по Abs. Отн. и кв. Rel (на 49% и 39,77% выше современного Spike-TМодель соответственно). Помимо точности, предлагаемая Модель также демонстрирует низкое энергопотребление, что имеет решающее значение для практического применения. Будущие исследования будут сосредоточены —Дальнейшая проверка и развертывание на реальных наборах данных, а также применение на выделенных процессорах SNN, потенциально расширяя пики Transformer Область применения в реальных сценариях.
ссылка
[1].A Novel Spike Transformer Network for DepthEstimation from Event Cameras via Cross-modalityKnowledge Distillation.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
