Решение для анализа родословной Spark App
Автор: Санью
Подразделение: Дата-центр
1. Предыстория
С ростом объема данных в хранилищах данных происхождение данных (Data Lineage или Data Provence) становится все более важным для анализа данных. Благодаря происхождению данных можно проследить восходящие и нисходящие отношения таблицы-таблицы, таблицы-задачи и задачи-задачи. поддержка Отслеживаемость проблемных данных и необходимость перевода офлайн-данных в автономный режим.
В настоящее время анализ происхождения задач SQL поддерживается на основе анализа синтаксиса ANTLR, тогда как анализ происхождения задач приложения Spark по-прежнему выполняется посредством ручной настройки. Мы надеемся дополнить анализ задач Spark App и улучшить логику кровного родства.
В настоящее время задачи онлайн-приложения Spark поддерживают две версии Spark 2.3 и Spark 3.1, а также типы python2/3, java и scala. Рабочие платформы поддерживают пряжу и k8s соответственно. Необходимо учитывать возможность адаптации ко всем механизмам сбора крови. вышеперечисленные задачи.
два. идеи дизайна
Идеи анализа задач приложения Spark обычно делятся на следующие три категории:
- На основе разбора кода: путём разбора Spark App излогика для достижения анализа родословнойизглазиз, Похожие продукты из включают в себя SPROV[1]。
- На основе динамического мониторинга: проведение изменяет код для сбора связей крови во время выполнения. Titian [2] и Pebble [3] или метод подключаемого модуля собирает происхождение во время выполнения Spline [4] и Apache Atlas [5]。
- На основе анализа журналов: путем анализа, например. Spark App из event log Информация, а затем разобрать задачу по родословной.
Поскольку приложение Spark написано по-разному, при анализе на основе кода необходимо учитывать Java, Python и Scala, что слишком сложно. Сначала мы рассмотрели анализ на основе журналов. Анализируя исторические журналы событий задач spark3 и spark2, обнаруживается, что журнал событий spark2 не содержит полной метаинформации, связанной с таблицей кустов, в то время как spark3 распечатывает элементы таблицы кустов на основе различных операторов чтения, таких как FileSourceScanExec. и HiveTableScan, поэтому метод журнала событий не может полностью поддерживать spark2.
На основании этого мы наконец приняли метод, основанный на динамическом мониторинге, исследовали сплайн и провели анализ юзабилити. Ниже представлены принципы использования и проектирования сплайна.
3. Решение для анализа кровного родства на основе сплайнов.
3.1 принцип сплайна
spline (Spark Lineage) — бесплатная система сбора родословных Spark с открытым исходным кодом, основанная на протоколе Apache 2.0. Система в основном разделена на три части: сплайн-агент, сплайн-сервер и сплайновый интерфейс.
Здесь мы в основном вводим принцип сплайн-агента, поскольку именно эта часть отвечает за анализ кровного родства. Что касается сплайн-сервера и пользовательского интерфейса, то они отвечают за сбор и отображение кровных связей и могут быть заменены внутренними системами.
Общая схема архитектуры показана ниже:
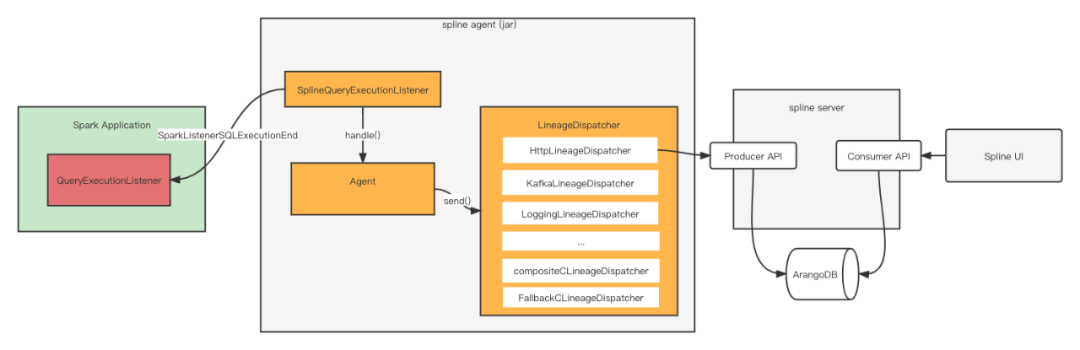
3.1.1 Инициализация
сплайн поддерживает два метода инициализации, без кода и программный. По сути, они регистрируют QueryExecutionListener, который отвечает за прослушивание. SparkListenerSQLExecutionEnd информация.
бескодовая инициализация
codeless init Он внедряется в пользователей посредством конфигурации. Spark APP программа, Нет необходимости модифицировать код. Зарегистрировавшись QueryExecutionListener Слушатель, который может принимать и обрабатывать Spark изинформация.запускать Конфигурация Например:
spark-submit --jars /path/to/lineage/spark-3.1-spline-agent-bundle_2.12-1.0.0-SNAPSHOT.jar --files /path/to/lineage/spline.properties --num-executors 2 --executor-memory 1G --driver-memory 1G --name test_lineage --deploy-mode cluster --conf spark.spline.mode=BEST_EFFORT --conf spark.spline.lineageDispatcher.http.producer.url=http://172.18.221.156:8080/producer --conf "spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener" test.py Используйте --jars для выполнения адреса jar-пакета сплайн-агента, или его можно поместить в каталог jars развертывания Spark по умолчанию.
Укажите файл свойств сплайна через --files или напрямую укажите элемент конфигурации через --conf. Элемент конфигурации должен иметь дополнительный префикс spark.
Прослушиватели можно зарегистрировать через --conf "spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener".
программная инициализация
Программная инициализация должна включать анализ родословной явно в коде, например
- scala demo
// given a Spark session ...
val sparkSession: SparkSession = ???
// ... enable data lineage tracking with Spline
import za.co.absa.spline.harvester.SparkLineageInitializer._
sparkSession.enableLineageTracking() - java demo
import za.co.absa.spline.harvester.SparkLineageInitializer;
// ...
SparkLineageInitializer.enableLineageTracking(session); - python demo
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
spark = SparkSession.builder \
.appName("spline_app")\
.config("spark.jars", "dbfs:/path_where_the_jar_is_uploaded")\
.getOrCreate()
sc = spark.sparkContext
sc.setSystemProperty("spline.mode", "REQUIRED")
jvm = sc._jvm
sc._jvm.za.co.absa.spline.harvester.SparkLineageInitializer.enableLineageTracking(spark._jsparkSession)
3.1.2 Анализ родословной
Логика анализа кровного родства находится в методе SplineAgent.handle(). При вызове LineageHarvester.harvest() получается окончательное кровное родство, которое передается LineageDispatcher для вывода результата.
Сообщение QueryExecution можно получить с помощью сообщения SparkListenerSQLExecutionEnd. Разрешение кровного родства основано на QueryExecution. analyzed logical plan и executedPlan Логика LineageHarvester.harvest() следующая:
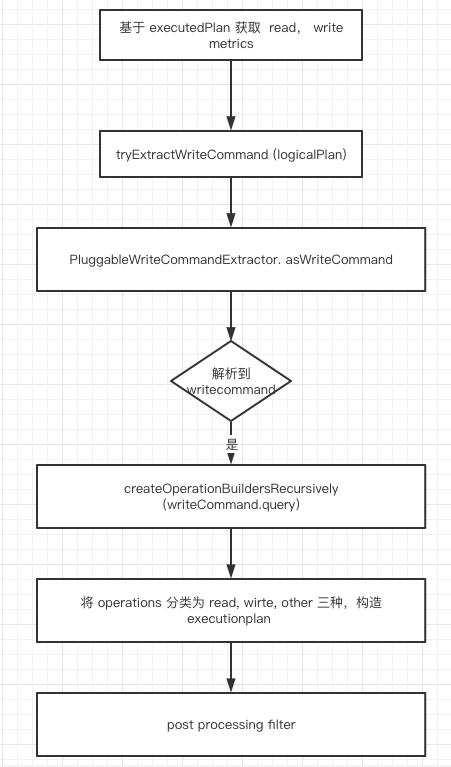
tryExtractWriteCommand (logicalPlan)Ответственный за разбор logicalPlan серединаиз операции записи, операция записи анализа опирается на метод подключаемого модуля.- получив
PluginRegistryсерединаWriteNodeProcessingВведите плагин,получать logicalPlan серединаизоперация записи,проходитьконкретномуиз Command из синтаксического анализа можно получить например hive поверхностьиз Информация об имени таблицы. Окончательная информация будет инкапсулирована какWriteCommandструктура данных.НапримерDataSourceV2Plugin.writeNodeProcessor()Будет нести ответственностьV2WriteCommand、CreateTableAsSelect、ReplaceTableAsSelectЭти командыизанализировать。 Плагин синтаксического анализа можно расширять и обогащать самостоятельно. spline Анализ источника данных, Плагины должны наследоватьza.co.absa.spline.harvester.plugin.Plugin, spline agent Он будет загружен автоматически при запуске classpath серединаиз Все плагины. - разобрать на writeCommand В будущем оно будет основано на writeCommand серединаиз query Разбор полей, операции чтения. Операции чтения основаны на query эта часть logicalPlan Выполните рекурсивный анализ.
- После завершения окончательного анализа мы можем получить plan и event два json информация, план Из-за кровного родства, event Дополнительную вспомогательную информацию.
Например:
[
"plan",
{
"id": "acd5157c-ddc5-5ef0-b1bc-06bb8dcda841",
"name": "team evaluation ranks",
"operations": {
"write": {
"outputSource": "hdfs:///user/hive/warehouse/dm_ai.db/dws_kdt_comment_ranks_info",
"append": false,
"id": "op-0",
"name": "CreateDataSourceTableAsSelectCommand",
"childIds": [
"op-1"
],
"params": {
"table": {
"identifier": {
"table": "dws_kdt_comment_ranks_info",
"database": "dm_ai"
},
"storage": "Storage()"
}
},
"extra": {
"destinationType": "orc"
}
},
"reads": [
{
"inputSources": [
"hdfs://yz-cluster-qa/user/hive/warehouse/dm_ai.db/dws_kdt_comment_rank_base"
],
"id": "op-6",
"name": "LogicalRelation",
"output": [
"attr-0",
"attr-12"
],
"params": {
"table": {
"identifier": {
"table": "dws_kdt_comment_rank_base",
"database": "dm_ai"
},
"storage": "Storage(Location: hdfs://yz-cluster-qa/user/hive/warehouse/dm_ai.db/dws_kdt_comment_rank_base, Serde Library: org.apache.hadoop.hive.ql.io.orc.OrcSerde, InputFormat: org.apache.hadoop.hive.ql.io.orc.OrcInputFormat, OutputFormat: org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat, Storage Properties: [serialization.format=1])"
}
},
"extra": {
"sourceType": "hive"
}
}
],
"other": [
{
"id": "op-5",
"name": "SubqueryAlias",
"childIds": [
"op-6"
],
"output": [
"attr-0",
"attr-12"
],
"params": {
"identifier": "spark_catalog.dm_ai.dws_kdt_comment_rank_base"
}
},
{
"id": "op-4",
"name": "Filter",
"childIds": [
"op-5"
],
"output": [
"attr-0",
"attr-12"
],
"params": {
"condition": {
"__exprId": "expr-0"
}
}
},
{
"id": "op-3",
"name": "Project",
"childIds": [
"op-4"
],
"output": [
"attr-0",
"attr-12"
],
"params": {
"projectList": [
{
"__attrId": "attr-0"
},
{
"__attrId": "attr-12"
}
]
}
},
...
]
},
"attributes": [
{
"id": "attr-0",
"dataType": "e63adadc-648a-56a0-9424-3289858cf0bb",
"name": "id"
},
{
"id": "attr-1",
"dataType": "75fe27b9-9a00-5c7d-966f-33ba32333133",
"name": "content"
},
...
{
"id": "attr-13",
"dataType": "75fe27b9-9a00-5c7d-966f-33ba32333133",
"childRefs": [
{
"__exprId": "expr-7"
}
],
"name": "comment_info"
}
],
"expressions": {
"functions": [
{
"id": "expr-2",
"dataType": "ab4da308-91fb-550a-a5e4-beddecff2a2b",
"childRefs": [
{
"__attrId": "attr-12"
}
],
"extra": {
"simpleClassName": "Cast",
"_typeHint": "expr.Generic"
},
"name": "cast",
"params": {
"timeZoneId": "Asia/Shanghai"
}
},
{
"id": "expr-1",
"dataType": "a155e715-56ab-59c4-a94b-ed1851a6984a",
"childRefs": [
{
"__exprId": "expr-2"
},
{
"__exprId": "expr-3"
}
],
"extra": {
"simpleClassName": "EqualTo",
"_typeHint": "expr.Binary",
"symbol": "="
},
"name": "equalto"
},
{
"id": "expr-5",
"dataType": "ba7ef708-332f-54fd-a671-c91d13ae6f8e",
"childRefs": [
{
"__exprId": "expr-6"
}
],
"extra": {
"simpleClassName": "Cast",
"_typeHint": "expr.Generic"
},
"name": "cast",
"params": {
"timeZoneId": "Asia/Shanghai"
}
},
{
"id": "expr-4",
"dataType": "a155e715-56ab-59c4-a94b-ed1851a6984a",
"childRefs": [
{
"__attrId": "attr-11"
},
{
"__exprId": "expr-5"
}
],
"extra": {
"simpleClassName": "GreaterThanOrEqual",
"_typeHint": "expr.Binary",
"symbol": ">="
},
"name": "greaterthanorequal"
},
{
"id": "expr-0",
"dataType": "a155e715-56ab-59c4-a94b-ed1851a6984a",
"childRefs": [
{
"__exprId": "expr-1"
},
{
"__exprId": "expr-4"
}
],
"extra": {
"simpleClassName": "And",
"_typeHint": "expr.Binary",
"symbol": "&&"
},
"name": "and"
},
{
"id": "expr-8",
"dataType": "75fe27b9-9a00-5c7d-966f-33ba32333133",
"childRefs": [
{
"__attrId": "attr-3"
},
{
"__attrId": "attr-0"
},
{
"__attrId": "attr-8"
}
],
"extra": {
"simpleClassName": "PythonUDF",
"_typeHint": "expr.Generic"
},
"name": "pythonudf",
"params": {
"name": "fun_one",
"evalType": 100,
"func": "PythonFunction(WrappedArray(...),{PYTHONPATH={{PWD}}/pyspark.zip<CPS>{{PWD}}/py4j-0.10.9-src.zip, PYTHONHASHSEED=0},[],/data/venv/hdp-envpy3/bin/python,3.6,[],PythonAccumulatorV2(id: 0, name: None, value: []))",
"udfDeterministic": true
}
},
{
"id": "expr-7",
"dataType": "75fe27b9-9a00-5c7d-966f-33ba32333133",
"childRefs": [
{
"__exprId": "expr-8"
}
],
"extra": {
"simpleClassName": "Alias",
"_typeHint": "expr.Alias"
},
"name": "comment_info",
"params": {
"name": "comment_info",
"nonInheritableMetadataKeys": [
"__dataset_id",
"__col_position"
],
"explicitMetadata": "{}"
}
}
],
"constants": [
{
"id": "expr-3",
"dataType": "455d9d5b-7620-529e-840b-897cee45e560",
"extra": {
"simpleClassName": "Literal",
"_typeHint": "expr.Literal"
},
"value": 20220830
},
{
"id": "expr-6",
"dataType": "455d9d5b-7620-529e-840b-897cee45e560",
"extra": {
"simpleClassName": "Literal",
"_typeHint": "expr.Literal"
},
"value": 80
}
]
},
"systemInfo": {
"name": "spark",
"version": "3.1.2-yz-1.4"
},
"agentInfo": {
"name": "spline",
"version": "1.0.0-SNAPSHOT+874577a"
},
"extraInfo": {
"appName": "team evaluation ranks",
"dataTypes": [
{
"_typeHint": "dt.Simple",
"id": "e63adadc-648a-56a0-9424-3289858cf0bb",
"name": "bigint",
"nullable": true
},
{
"_typeHint": "dt.Simple",
"id": "75fe27b9-9a00-5c7d-966f-33ba32333133",
"name": "string",
"nullable": true
},
{
"_typeHint": "dt.Simple",
"id": "a155e715-56ab-59c4-a94b-ed1851a6984a",
"name": "boolean",
"nullable": true
},
{
"_typeHint": "dt.Simple",
"id": "ab4da308-91fb-550a-a5e4-beddecff2a2b",
"name": "int",
"nullable": true
},
{
"_typeHint": "dt.Simple",
"id": "455d9d5b-7620-529e-840b-897cee45e560",
"name": "int",
"nullable": false
},
{
"_typeHint": "dt.Simple",
"id": "ba7ef708-332f-54fd-a671-c91d13ae6f8e",
"name": "bigint",
"nullable": false
}
]
}
}
]
[
"event",
{
"planId": "acd5157c-ddc5-5ef0-b1bc-06bb8dcda841",
"timestamp": 1661960765255,
"durationNs": 4353094937,
"extra": {
"appId": "application_1656468332243_128755",
"user": "app",
"readMetrics": {
"numFiles": 1,
"scanTime": 995,
"pruningTime": 0,
"metadataTime": 161,
"filesSize": 87538,
"numOutputRows": 7269,
"numPartitions": 1
},
"writeMetrics": {
"numFiles": 1,
"numOutputBytes": 48430,
"numOutputRows": 6785,
"numParts": 0
}
}
}
]3.1.3 Распределение крови
LineageDispatcher Решите, как отправить родословную, И встроенный Dispatcher Реализация также понятна с первого взгляда. Например:HttpLineageDispatcher Это отправить кровь в HTTP интерфейс, KafkaLineageDispatcher отправляется в Kafka topic, LoggingLineageDispatcher Просто напечатайте кровное родство в Spark APP из stderr В журнале Удобен для отладки и подтверждения.
Если вы хотите настроить диспетчер, Вы можете унаследовать его самостоятельно LineageDispatcher, И укажите входной параметр какorg.apache.commons.configuration.Configurationиз Конструктор,специфический Конфигурациянравиться Вниз:
spline.lineageDispatcher=my-dispatcher
spline.lineageDispatcher.my-dispatcher.className=org.example.spline.MyDispatcherImpl
spline.lineageDispatcher.my-dispatcher.prop1=value1
spline.lineageDispatcher.my-dispatcher.prop2=value2 3.1.4 Постобработка
post processing filter После завершения анализа кровного родства перед передачей его диспетчеру можно выполнить некоторую постобработку, например десенсибилизацию. . реализовать filter Необходимо реализовать za.co.absa.spline.harvester.postprocessing.PostProcessingFilter, конструктор принимает тип org.apache.commons.configuration.Configuration из Вход。Конфигурациянравиться Вниз:
spline.postProcessingFilter=my-filter
spline.postProcessingFilter.my-filter.className=my.awesome.CustomFilter
spline.postProcessingFilter.my-filter.prop1=value1
spline.postProcessingFilter.my-filter.prop2=value2 3.2 Связь версий

Если pyspark 2.3 хочет поддерживать инициализацию без кода, вам необходимо исправить SPARK-23228. По связанным проблемам обратитесь к этой ПРОБЛЕМЕ (https://github.com/AbsaOSS/spline-spark-agent/issues/490).
3.3 сплайн-интеграция
3.3.1 Интегрирование сплайна
компилировать переписываться spark и scala Версия из spline-agent пакет баночка.
Такие как спарка 3.1
mvn scala-cross-build:change-version -Pscala-2.12
mvn clean install -Pscala-2.12,spark-3.1 -DskipTests=True Разверните пакет jar агента искры в каталоге /path/to/spark/jars.
Настройте spark-defaults.conf
spark.sql.queryExecutionListeners=za.co.absa.spline.harvester.listener.SplineQueryExecutionListener
spark.spline.mode=BEST_EFFORT
spark.spline.lineageDispatcher=composite
spark.spline.lineageDispatcher.composite.dispatchers=logging,http
spark.spline.lineageDispatcher.http.producer.url=http://[ip:port]/producer 3.3.2 Система сбора родословной
Существующая интегрированная система требует соответствующей модификации кода, в конце концов event Добавьте это в сообщение Spark APP переписатьсяиз рабочего процесса или имени задачи, ВоляBloodlineинформация о задаче отправляется на заказ HTTP server, Анализ отчетов о предках kafka, Единая обработка потребления.
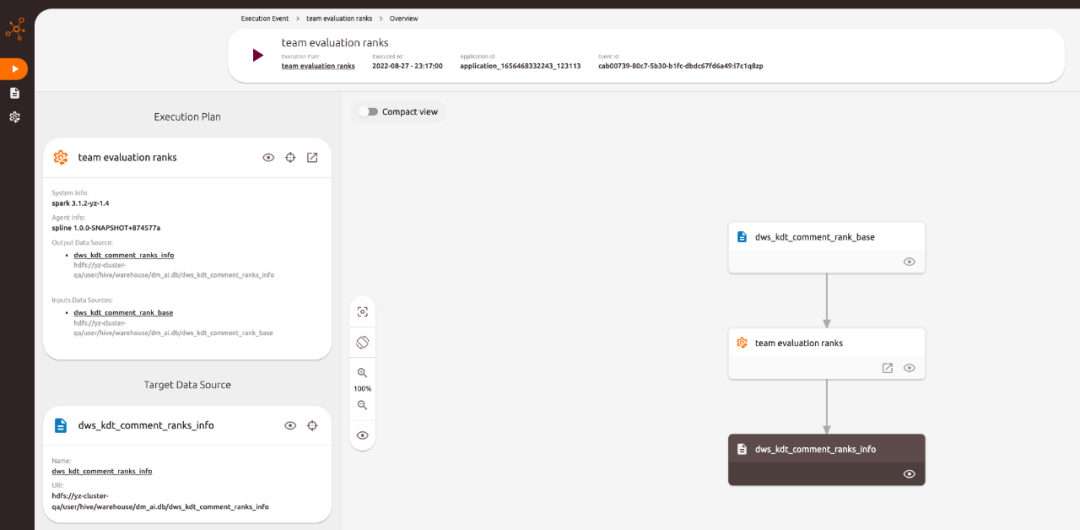
3.4 демонстрация сплайна
через docker-compose Можно запустить одним щелчком мыши spline server конец. доступ spline ui можно увидетьанализироватьпублично заявитьиз Родословная。
1. wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/docker-compose.yml
2. wget https://raw.githubusercontent.com/AbsaOSS/spline-getting-started/main/docker/.env
3. export DOCKER_HOST_EXTERNAL=yourhostip // spline Адрес сервера доступа к пользовательскому интерфейсу по умолчанию — 127.0.0.1, Невозможно получить доступ извне без изменений
4. docker-compose up
4. Резюме
В настоящий момент сплайн-агент неспособен обрабатывать сценарии родословной, как показано ниже:
- Не могущийразобрать на RDD серединаизисходная логика, если dataframe Преобразовать в RDD После этой операции кровное родство проследить невозможно. Это похоже на spline анализироватьизкогдапроходить logicalPlan серединаиз child отношения рекурсивно связаны, встретиться LogicalRDD Рекурсия заканчивается. Возможно решение - встретиться LogicalRDD Оператор из времени проводит анализ RDDиз dependency Отношения находят информацию о происхождении.
2. Анализ родословной основан на триггерных записях, поэтому, если задача только запрашивает, кровное родство не может быть разрешено.
Хотя некоторые недостатки все же имеются, spline agent Возможность работать онлайн без какого-либо осознания Spark APP Анализ увеличения программы Способность родословной — очень хорошая идея. Дальнейшие исследования и оптимизацию можно провести в этом направлении в будущем. Spark APP из точности родословной.
5. Справочные материалы
- SPROV 2.0
- TiTian: http://web.cs.ucla.edu/~todd/research/vldb16.pdf
- Pebble
- Spline
- Atlas
- spline-spark-agent github
- Collecting and visualizing data lineage of Spark jobs



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
