Redis против локального кэширования: зачем вам оба?

введение
в интервью,Интервьюер спросил меня о моем опыте использования локального кэша.,Первое, что пришло мне в голову, былоRedis,Однако после некоторых раздумий,Это не совсем правильно. после колебания,Мне пришлось ответить, что у меня нет соответствующего опыта. После возвращения домой,Я сразу проверил соответствующую информацию,Только тогда я обнаружил,Оказывается, это поле есть в локальном кэше.,Здесь так много скрытых тайн.
1. Введение в Redis
The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker.
Простой перевод: программное обеспечение для хранения данных в памяти с открытым исходным кодом, используемое миллионами разработчиков в качестве базы данных, кэша, механизма потоковой передачи и брокера сообщений.
1.1 Что такое Редис
Судя по официальному представлению, помимо функции кэширования, он также имеет множество привлекательных функций. Однако сегодня мы сосредоточимся исключительно на функциональности кэширования. Когда я впервые узнал об этом, я сравнил его с MySQL, которая привлекла большое внимание как база данных NoSQL в памяти. Учитывая узкое место базы данных с точки зрения ввода-вывода и тот факт, что большинство операций связаны только с чтением данных, мы рассмотрели возможность введения промежуточного уровня для кэширования части данных и предоставления их клиенту.
В истории вычислений всегда существовало мнение, что любую проблему в области вычислений можно решить, добавив промежуточный слой.
Как правило, разница между уникальной скоростью записи диска и памяти составляет более 10 раз.
Redis родился по похожему сценарию. На заре существования веб-сайта из-за небольшого количества посещений было возможно использовать JavaScript для подсчета и мониторинга различных данных. Однако по мере роста объема данных рабочая нагрузка по обслуживанию продолжает увеличиваться, и диск становится узким местом. Поэтому автор Redis написал эту базу данных в памяти на языке C.
Причина, по которой Redis называется Redis, заключается в том, что весь его процесс представляет собой службу REmote DIctionary Service, которая интерпретируется как служба удаленного словаря. (Это также соответствует местному).

Функции
- Храните неструктурированные данные Поскольку это словарная служба, по сути, это служба, хранящая неструктурированные типы данных (ключ:значение).
- Большой объем памяти и высокая скорость одновременной записи На уровне хранилища Redis предоставляет множество специальных структур данных для различных предприятий. Кроме того, Redis, являясь базой данных в памяти, обеспечивает высокую производительность чтения и записи.
- распределенный Распределенная реализация Redis в основном опирается на две основные концепции Redis Sentinel и Redis Cluster.
1.2 Основные функции Redis
Согласно официальному описанию, его основные функции разделены на четыре части: база данных, кеш, механизм потоковой передачи и брокер сообщений.
ⅠВ качестве базы данных
Поскольку это база данных, хранящаяся в памяти, потеря данных может легко произойти после отключения питания или сбоя. Затем он также разрабатывает стратегию. Это персистентность, разделенная на RDB и AOF.
- RDB записывает данные на жесткий диск в течение определенного практического интервала.
- AOF записывает каждую полученную команду на жесткий диск.
Так какой из них лучше? Ответ: я хочу их всех. Хорошо это или нет, во многом зависит от вашего сценария использования. Что подходит, то и лучше.

Ⅱ Кэш
Обычно это основная функция, которую мы используем Redis. Пока у нее нет конкурентов в базах данных NoSQL.
Ⅲ Стриминговый движок
Тогда мне интересно, что такое потоковой двигатель?
Механизмы потоковой передачи — это способ обработки постоянных потоков данных, управляемых событиями. В потоке данных каждое событие соответствует элементу данных, и каждый элемент добавляется, изменяется или удаляется в течение определенного интервала времени. Механизмы потоковой передачи обычно используются в сценариях обработки данных в реальном времени, таких как очереди сообщений, архитектура, управляемая событиями, анализ данных в реальном времени и т. д.
Похоже, что он действительно похож на Message Queuing (MQ), и его удобнее использовать с операцией персистентности Redis. В практических сценариях применения его можно использовать в качестве промежуточного потока сообщений для обмена мгновенными сообщениями, анализа веб-данных, системных журналов и т. д.
Ⅳ Брокер сообщений
Эта функция в основном используется, чтобы позволить Redis выполнять асинхронную связь и приложения, управляемые событиями, в реальном времени между несколькими узлами.
Поскольку Redis поддерживает модель публикации/подписки, это очень важное средство.
Конечно, это также может служить промежуточным прокси-сервером для микросервисов.
1.3 Сценарии применения Redis
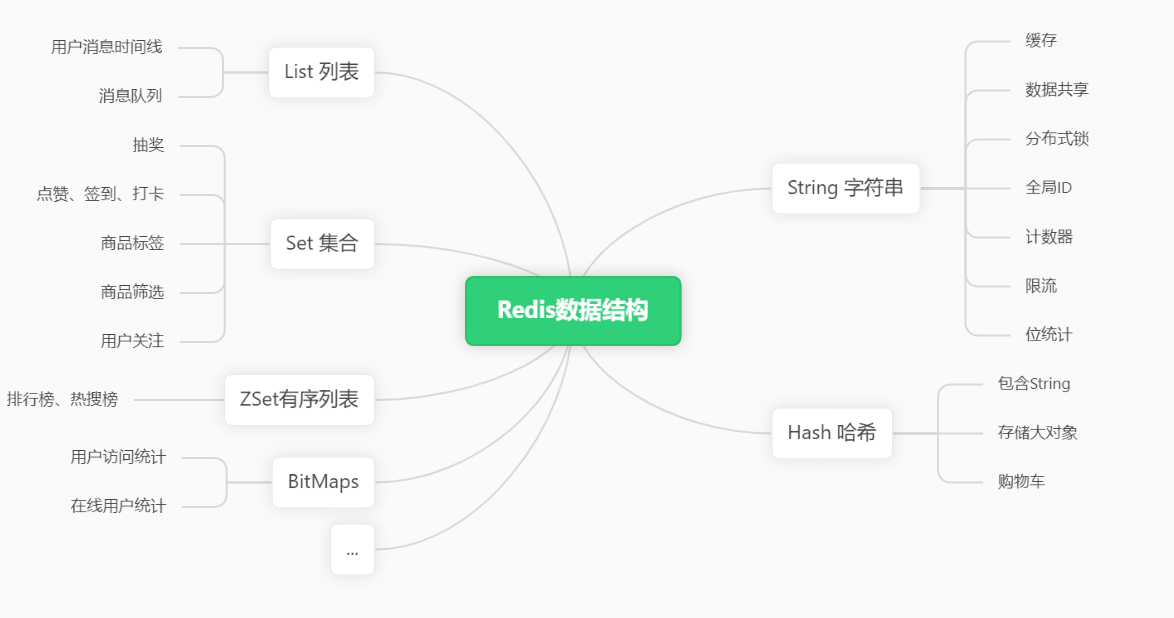
Если вы просто задумаетесь о том, какие ресурсы может сэкономить кэширование, вы, возможно, какое-то время не сможете ответить на этот вопрос. Но начиная со структуры данных Redis, будет много вдохновения.
- ① Строка Распределенная блокировка, глобальный идентификатор
- ② Хэш Храните объекты и информацию о корзине.
- ③ Список списка Очередь сообщений, временная шкала сообщений пользователя
- ④ набор набор Лотерея, типа, войдите, вбейте, Тег продукта пользовательсосредоточиться на: взаимныйсосредоточиться на?пересечение ясосредоточиться налюди такжесосредоточиться на него? пересечение Кто-то, кого вы можете знать? набор различий
Здесь есть еще много случаев, и все они основаны на богатых структурах данных.
2. Знакомство с локальным кешем
Прежде чем обращаться к удаленному кешу, многие кеши фактически используются неявно в процессе, например, кеш ORM и строковый кеш JDK (постоянный пул).
Понимание этого в Java на самом деле представляет собой большую карту.
2.1 Локальный кеш
Если мы хотим реализовать кэш самостоятельно, что нам нужно учитывать?
- Область вызова. Если вы полагаетесь на Spring Boot, вы можете зарегистрировать его в классе запуска и использовать глобально (немного опасно).
- Срок годности Если память занята в течение длительного времени, это неизбежно приведет к сбою программы, поэтому подумайте об истечении срока действия и удалении.
- последовательность Это очень распространенная проблема в кэшировании. Ключ заключается в том, должен ли бизнес полностью доверять ей и применять разные стратегии.
- Параллелизм и блокировки JDK предоставляет пакет JUC, и коллекции в нем очень полезны.
- Масштабируемость Можно ли повторно расширить приложение плагина?
Принимая все во внимание, это на самом деле большая проблема. К счастью, экосистема Java достаточно сильна.
2.2 Зрелая структура
Guava Cache
Guava Cache — это локальная библиотека инструментов кэширования с открытым исходным кодом, разработанная Google. Ее дизайн вдохновлен ConcurrentHashMap. Она использует мелкозернистые блокировки в нескольких сегментах для обеспечения безопасности потоков, одновременно поддерживая требования к сценариям с высоким уровнем параллелизма и поддерживая несколько типов стратегий очистки кэша. Очистка на основе емкости, очистка на основе времени, очистка на основе ссылок и т. д.
Важным контейнером пакета JUC является ConcurrentHashMap, созданный на его основе и имеющий более мелкую детализацию блокировок. В сочетании с полной реализацией в мышлении и родилась такая основа. Судя по Google, существует определенная гарантия прочности. Вначале он стал встроенным кешем Spring.
Caffeine
Caffeine — это библиотека кэширования Java с открытым исходным кодом, которая обеспечивает высокую частоту попаданий и отличные возможности параллелизма. Caffeine поддерживает параллелизм и доступ к данным временной сложности O(1), аналогично структуре данных ConcurrentMap, но предоставляет стратегию автоматического удаления «редко используемых» данных для поддержания разумного использования памяти. В Caffeine данные можно кэшировать из локальной памяти приложения Java, чтобы повысить производительность и скорость реагирования приложения. Caffeine предоставляет четыре стратегии добавления кэша, включая ручную загрузку, автоматическую загрузку, ручную асинхронную загрузку и автоматическую асинхронную загрузку.
Усовершенствованный Guava и ставший первым выбором платформы кэширования в Spring 5, это Caffeine, и его название очень похоже на Java.
Ява, остров Ява, богат кофе. Итак, иконка Java — это форма кофе. Кофеин: кофеин

2.2 Основные сценарии локального кэша
Помимо вышеперечисленных фреймворков, локальное кэширование действительно прошло длительный период развития. Так что же с ними сделали разработчики?
- Кэш базы данных Это похоже на идею удаленного кэширования. В рамках ORM такая возможность кэширования доступна. Например, кэш третьего уровня MyBatis. Конечно, если кеш этого не понимает, данные очень легко прочитать или изменить, что приведет к путанице.
- Кэширование сетевых запросов Кэширование сетевых запросов также является важной частью одного из нескольких сценариев ввода-вывода.
3. Почему вам нужно иметь и то, и другое
После сравнения преимуществ и недостатков этих двух вариантов, я думаю, у вас уже есть ответ. Но здесь я кратко изложу свою точку зрения.
- Адаптируйтесь к потребностям различных сценариев Даже в распределенной системе фреймворк реализовал для нас необходимость локального кэша, нам все равно нужно сосредоточиться и оптимизировать его. Локальный кеш: больше ориентирован на одну службу/приложение, что позволяет сократить количество операций ввода-вывода и повысить производительность. Распределенный кеш: подходит для комплексных приложений в более крупных сценариях, глобальный кеш.
- Компромисс затрат и выгод Хотя внедрение новых технологий может принести высокую прибыль, оно также сопряжено с высокими рисками. Поэтому предприятиям следует сосредоточиться на экономии затрат на технологии, а также затрат на эксплуатацию и техническое обслуживание в процессе разработки, даже если новая технология действительно очень полезна.
в заключение
Независимо от технологии, лучшим выбором будет та технология, которая лучше всего соответствует потребностям вашего бизнеса.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
