Развертывание реализации YOLO | Обзор последних достижений в области обрезки и количественной оценки YOLOv5 в одной статье [обязательно прочитать]
Эта статья была впервые опубликована на [Jizhi Shutong]. Для учетных записей, внесенных в белый список, пожалуйста, сознательно вставляйте визитную карточку этой официальной учетной записи и указывайте источник при перепечатке. Для учетных записей, не внесенных в белый список, сначала подайте заявку на получение разрешения.

В последние несколько лет большое количество исследований было посвящено совершенствованию детектора объектов YOLO. С момента запуска было представлено 8 основных версий YOLO с целью повышения его точности и эффективности. Хотя очевидные преимущества YOLO сделали его широко используемым во многих областях, все еще существуют проблемы с его развертыванием на устройствах с ограниченными ресурсами. Для решения этой проблемы были разработаны различные методы сжатия нейронных сетей, которые разделены на 3 основные категории:
- сетьобрезка
- Количественная оценка
- дистилляция знаний
Плодотворные результаты использования методов сжатия моделей, таких как сокращение использования памяти и времени вывода, делают их популярным и даже необходимым выбором для развертывания больших нейронных сетей на периферийных устройствах с аппаратными ограничениями. В этом обзоре мы сосредоточимся на методах обрезки и количественной оценки, поскольку они относительно независимы. Авторы классифицируют их и анализируют практические результаты применения этих методов к YOLOv5. Таким образом, авторы выявляют пробелы в адаптации методов обрезки и квантования для сжатия YOLOv5 и определяют будущие направления для дальнейших исследований в этой области. Среди множества версий YOLO авторы особенно выбрали YOLOv5, поскольку она обеспечивает превосходный баланс между актуальностью и популярностью в литературе. Это первый обзорный документ, в котором конкретно рассматриваются методы обрезки и квантования YOLOv5 с точки зрения реализации. Исследование авторов также применимо к более новым версиям YOLO, поскольку их развертывание на устройствах с ограниченными ресурсами по-прежнему сопряжено с теми же проблемами. Эта статья предназначена для тех, кто заинтересован в практическом развертывании методов сжатия моделей в YOLOv5 и изучении различных методов сжатия, которые могут использоваться в последующих версиях YOLO.
1. Введение
Обнаружение объектов является фундаментальной проблемой и уже много лет является активной областью исследований. Основная цель обнаружения объектов — идентифицировать и найти объекты разных категорий на заданном изображении. Обнаружение объектов является основой для многих других сложных задач компьютерного зрения, включая семантическую сегментацию, отслеживание объектов, распознавание активности и многое другое.
В последние годы методы, основанные на глубоком обучении, такие как сверточные нейронные сети (CNN), достигли самых современных показателей в задачах обнаружения объектов. Благодаря достижениям в области вычислительной мощности и передовым алгоритмам обнаружение объектов стало более точным, что открывает возможности для множества реальных приложений. По сравнению с традиционными методами обнаружения целей, использование CNN может облегчить проблемы выделения, классификации и локализации признаков при обнаружении целей.
Обычно обнаружение объектов может выполняться двумя методами, а именно одноэтапным и двухэтапным обнаружением. В первом случае алгоритм напрямую прогнозирует ограничивающую рамку и вероятность класса объекта, а во втором алгоритм сначала генерирует набор предложений региона, а затем классифицирует эти предложения как объекты или фоны. В отличие от двухэтапных методов обнаружения объектов, таких как Faster R-CNN и R-FCN, одноэтапные методы, такие как YOLO, SSD, EfficientDet и RetinaNet, обычно используют полностью сверточную нейронную сеть (FCN) для определения категории и пространственного местоположения. объекта, при этом никаких промежуточных действий не требуется.
Среди различных одноэтапных методов обнаружения объектов YOLO привлек внимание с момента своего выпуска в 2016 году. Основная идея YOLO — разделить входное изображение на сетку ячеек и предсказать ограничивающие рамки и вероятности классов для каждой ячейки. YOLO рассматривает обнаружение объектов как проблему регрессии. Поскольку для обнаружения и классификации объектов используется одна нейронная сеть, ее можно оптимизировать для обеих задач одновременно, тем самым улучшая общую производительность обнаружения.
YOLOv1 использует простую структуру, включающую 24 сверточных слоя и два полностью связанных слоя для вывода вероятностей и координат. С момента запуска YOLO претерпел несколько улучшений и вариантов.
В 2017 году был выпущен YOLOv2 (также известный как YOLO9000), улучшающий производительность за счет использования многомасштабного обучения, Anchor-Box, пакетной нормализации, архитектуры Darknet-19 и модифицированных функций потерь.
Впоследствии Редмон и Фархади представили YOLOv3, который принял сеть пирамидных объектов, сверточные слои с Anchor-Box, блок пространственного пирамидного пула (SPP), архитектуру Darknet-53 и улучшенную функцию потерь.
В отличие от предыдущих версий, YOLOv4 был представлен другим автором. А. Бочковский и др., используя архитектуру CSPDarknet53, Bag-of-Freebies, Bag-of-Specials, функцию активации миша, взвешенное остаточное соединение (WRC), объединение пространственных пирамид (SPP) и сеть агрегации путей (PAN). выступление YOLO.
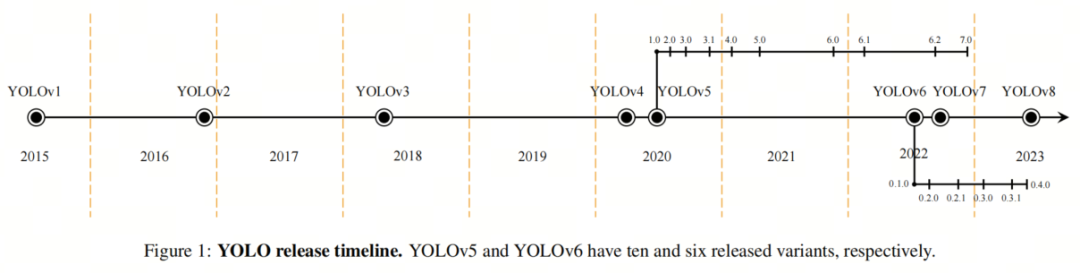
В 2020 году Ultralytics выпустила YOLOv5 пяти разных размеров: от нано до очень большого. YOLO претерпел значительные улучшения: от новой архитектуры Backbone до автоматической оптимизации гиперпараметров. В магистральной части YOLOv5 использует новую структуру CSPDarknet53, основанную на Darknet53, и добавляет стратегию Cross-Stage Partial (CSP). В конструкции шеи YOLOv5 используются CSP-PAN и более быстрые блоки SPP (SPPF). Вывод генерируется с использованием структуры Head YOLOv3.
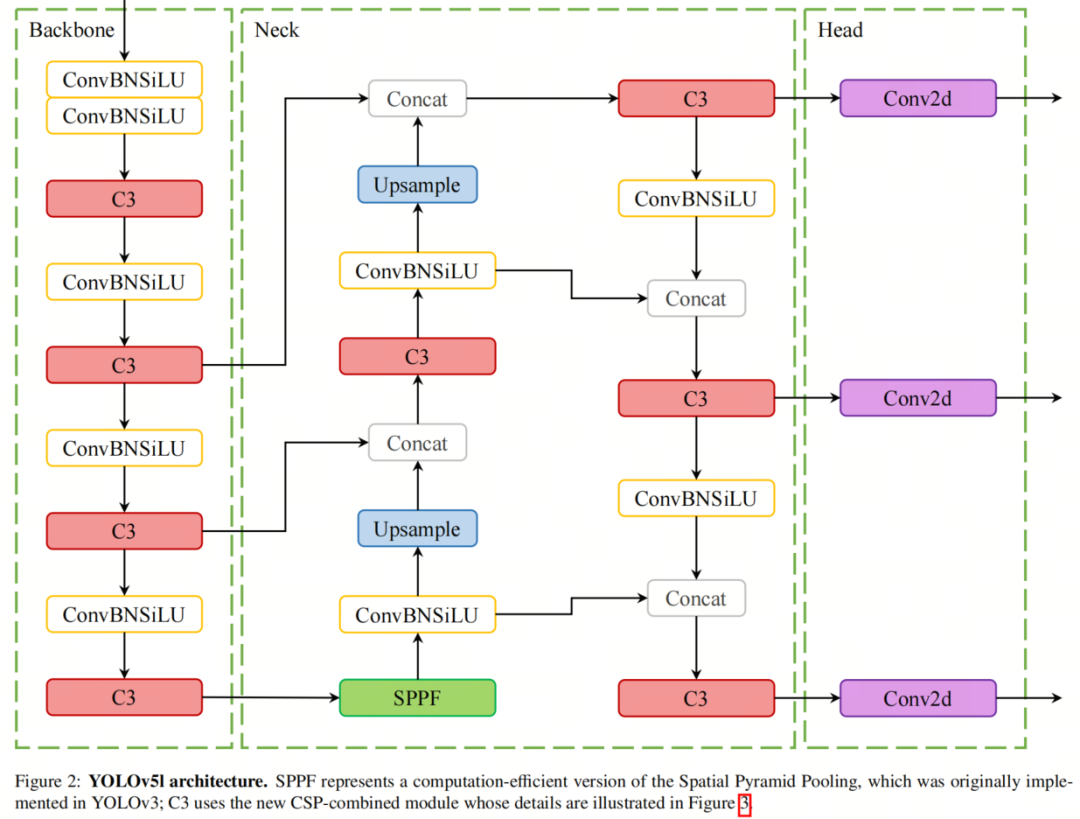
Структура YOLOv5l показана на рисунке 2, где CSPDarknet53 содержит блок C3, который является модулем слияния CSP. Стратегия CSP разделяет карту объектов базового слоя на две части, а затем объединяет их через межэтапную иерархию. Таким образом, модуль C3 может эффективно обрабатывать избыточные градиенты, одновременно повышая эффективность передачи информации между остатками и плотными блоками. C3 — это упрощенная версия BottleNeckCSP, которая в настоящее время используется в последнем варианте YOLOv5.
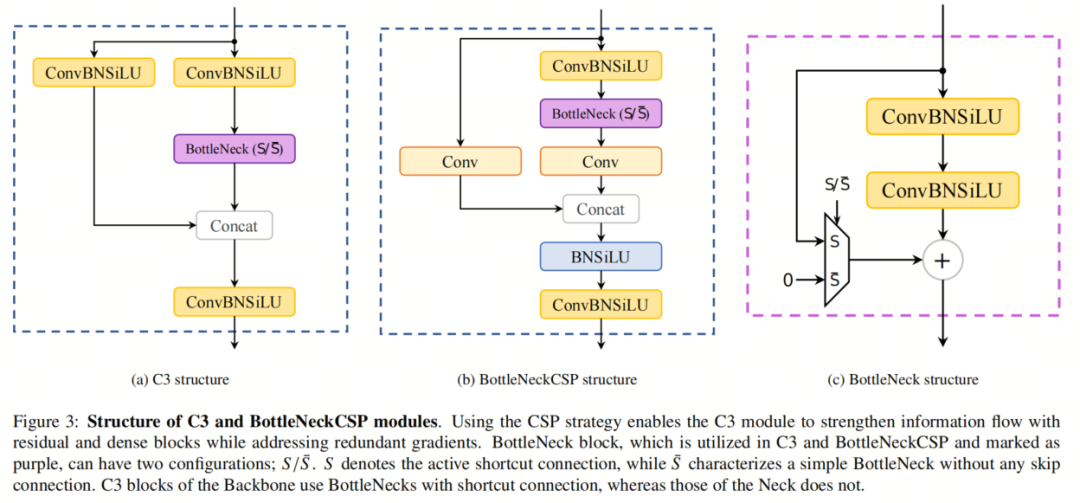
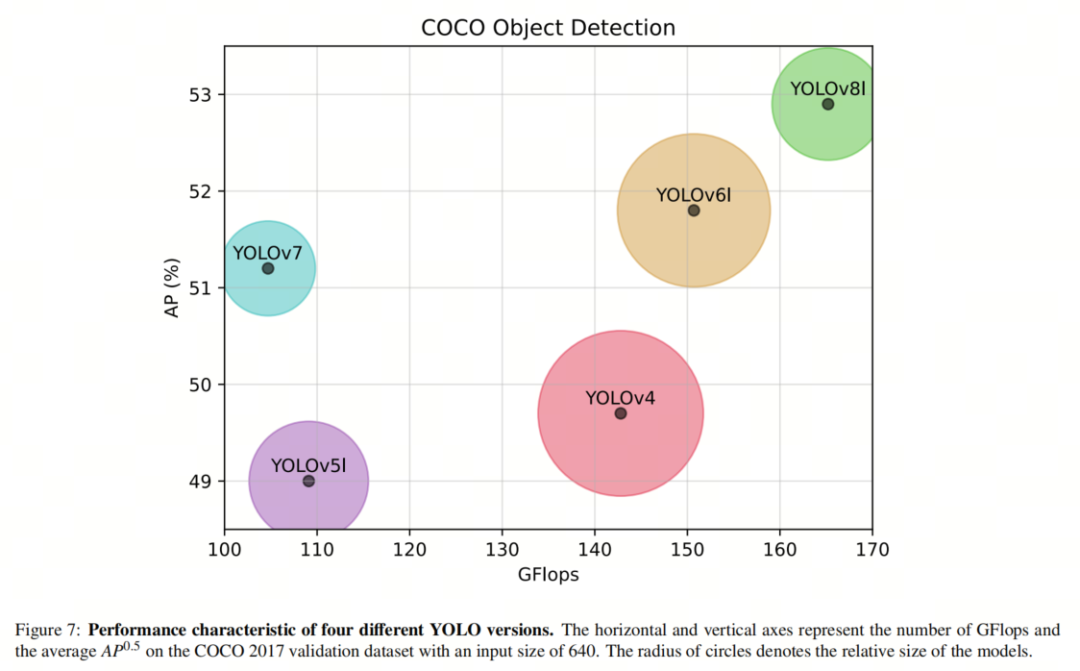
Для сравнения конструкции блоков C3 и BottleNeckCSP показаны на рисунке 3. В целом, эти модификации позволяют YOLOv5 достичь высочайшей производительности в нескольких тестах обнаружения объектов, включая набор данных COCO. Кроме того, различные размеры моделей предоставляют пользователям возможность выбора в соответствии со своими потребностями.
В 2022 году Meituan выпустила YOLOv6, который включает улучшенные модули двунаправленного соединения (BiC), стратегии тренировки с использованием якорной коробки (AAT) и новые конструкции позвоночника и шеи.
YOLOv7 вскоре был запущен первоначальным автором, что стало большим прорывом. Ван и др. предложили «Мешок халявы», метод масштабирования составной модели и расширенную архитектуру ELAN для расширения, перетасовки и объединения мощностей. «Мешок халявы» включает в себя запланированные перепараметризованные свертки (вдохновленные ResConv), дополнительные вспомогательные головки в средних слоях сети (для глубокого контроля) и средства назначения мягких меток для управления вспомогательными головками и основной головкой.
Наконец, Ultralytics запустила YOLOv8 в 2023 году, внеся несколько изменений в Backbone, Neck и Head, используя модуль C2f вместо C3, предоставляя в качестве выходных данных разделенную голову; Хотя YOLOv6/7/8 являются более популярными моделями, работа автора сосредоточена на YOLOv5, поскольку по нему было проведено больше исследований. Однако это исследование можно распространить на более новые версии YOLO, в частности на YOLOv8.
Текущая тенденция заключается в использовании и расширении чрезмерно параметризованных моделей для получения более высокой точности, однако количество операций с плавающей запятой (FLOP) и требуемых параметров резко возрастает; Эта проблема препятствует развертыванию сложных моделей на периферийных устройствах из-за ограничений памяти, мощности и вычислительных возможностей. Для решения этой проблемы можно использовать облачные вычисления (CC). Однако запуск сложных моделей в облачных сервисах может оказаться нецелесообразным, поскольку:
- Стоимость сети: передача данных изображения в облако требует относительно большого объема пропускной способности сети;
- Задержка для задач, критичных по времени. Задержка при доступе к облачным сервисам не гарантируется;
- Доступность. Облачные сервисы полагаются на доступ устройств к беспроводной связи, которая может подвергаться помехам во многих ситуациях окружающей среды.
В результате периферийные вычисления во многих случаях становятся более плодотворным решением. Поэтому были введены различные методы сжатия нейронных сетей, чтобы можно было развертывать большие модели на периферийных устройствах. Методы сжатия модели можно разделить на 3 категории: сокращение, квантование и дистилляция знаний. При сокращении неважные избыточные параметры модели удаляются, чтобы получить разреженную/компактную структуру модели. Квантование предполагает использование типов данных низкой точности для представления активаций и весов модели. Наконец, дистилляция знаний подразумевает использование большой точной модели в качестве учителя для обучения маленькой модели с использованием мягких меток, предоставляемых моделью учителя.
В этом обзорном документе авторы фокусируются на методах обрезки и квантования, поскольку они широко используются в качестве методов модульного сжатия, в то время как использование дистилляции знаний требует наличия двух моделей или изменения структуры целевой сети. Авторы рассматривают методы применения обрезки и квантования на YOLOv5 за последние годы и сравнивают результаты при сжатии терминов. Авторы решили сосредоточиться на YOLOv5, потому что это самая последняя версия YOLO и по ней проведено достаточно исследований, связанных с обрезкой и квантованием.
Хотя новые версии YOLO превзошли YOLOv5 во многих областях, применяемые в них методы сжатия по-прежнему недостаточны для рассмотрения. Обзоров методов нейросетевого сжатия было много, но здесь авторы рассматривают практические реализации этих методов на YOLOv5. Авторы представляют все работы, связанные с обрезкой и квантованием YOLOv5, и их результаты в разных аспектах. Обычно результаты сжатия могут быть выражены через изменения объема памяти, энергопотребления, количества операций ввода-вывода, времени вывода, частоты кадров, точности и времени обучения.
2. Обрезка
Обрезка нейронных сетей первоначально была предложена в книгах «Оптимальное повреждение мозга» и «Оптимальный мозговой хирург». Все они полагаются на разложение Тейлора второго порядка для оценки важности параметра сокращения. То есть в этих методах матрица Гессе должна рассчитываться частично или полностью. Однако для определения важности параметра, также известного как значимость, можно использовать и другие критерии.
Теоретически оптимальный критерий обеспечил бы точную оценку влияния каждого параметра в сети, но такая оценка была бы непомерно дорогой в вычислительном отношении. Таким образом, другие методы оценки включают в себя
Для анализа значимости можно использовать нормы, среднее или стандартное отклонение активаций карты признаков, масштабные коэффициенты пакетной нормализации, первые производные и взаимную информацию. В следующих разделах авторы обсуждают эти методы оценки значимости. Авторы не будут здесь количественно оценивать эффективность каждой схемы, поскольку различные усилия трудно сравнивать, а на результаты могут повлиять различные факторы, от гиперпараметров до графиков скорости обучения и архитектуры реализации. Вместо этого авторы представят идеи, лежащие в основе каждого критерия, и представят результаты их применения к сжатому YOLOv5.
2.1. Критерии значимости обрезки.
Критерий значимости — это мера или индикатор, который определяет важность или релевантность отдельного веса, нейрона, фильтра или группы весов в нейронной сети на основе некоторой характеристики или атрибута сети.
2.1.1.
норма
на основе
Сокращение модели по нормам является наиболее широко используемым методом в рамках данного обзора. Поскольку значения весов обычно образуют нормальное распределение с нулевым средним,Это интуитивный подход,Используется для выбора менее важных отдельных весов и весовых структур. Проблема с использованием этого критерия заключается в определении порога сокращения. Такие пороговые значения могут быть установлены статически для каждого слоя. также,Думайте об этом как о динамическом параметре,И определите планировщик для этого порога. Например,[A unified framework for soft threshold обрезка] предложил метод, который рассматривает пороговое планирование как неявную задачу оптимизации и использует итеративный алгоритм порогового сжатия (ISTA) для создания порогового планировщика.
норма часто используется в сочетании с разреженным обучением сети.,чтобы передать параметры с одинаковым эффектом, чтобы они имели схожие значения (см. раздел 2.1.3). с этой целью,Обычно добавляется к функции стоимости
или
Регуляризируйте и сокращайте после тренировки (на каждом этапе) с более низкими
параметры нормы.
2.1.2. Активация карты объектов.
При использовании функции активации в конце слоя,Его выходные данные можно интерпретировать как важность прогнозируемых параметров. Например,В случае функции ReLU,Результаты, близкие к нулю, можно считать менее значимыми.,и выбран в качестве кандидата на обрезку. также,С более широкой точки зрения,Среднее и стандартное отклонение тензора активации могут указывать на значимость.
2.1.3. Пакетный нормализованный масштабный коэффициент (BNSF).
Хотя его можно отнести к категории
нормаи Активация карты объекты стандартного слияния, но коэффициент масштабирования BN в основном используется для сокращения YOLOv5 и, в более общем плане, для CNN. [, Learning efficient convolutional networks through network похудение] вводит коэффициент масштабирования для каждого канала.
и наказать ее в процессе обучения, чтобы получить разреженную сеть, которую можно сократить. Авторы предложили коэффициент масштабирования BN, необходимый для сжатия сети.
. В своем подходе они используют
норма на канал
Наказывайте, а затем сокращайте каналы с коэффициентом масштабирования, близким к нулю.
2.1.4. Первая производная.
В отличие от предыдущих критериев, первая производная метрика использует информацию, полученную во время обратного распространения ошибки через градиенты. Такие критерии могут объединять информацию от активаций до градиентов.
2.1.5. Взаимная информация.
между двумя параметрами слоя или между параметрами слоя и предсказаниями взаимозависимая информация (MI) может указывать на известность. существовать[ Compressing neural networks using the variational information узкое место], авторы пытаются минимизировать MI между двумя скрытыми слоями, одновременно максимизируя MI между последним скрытым слоем и прогнозом.
2.2. Детализация обрезки.
длина детализации определяет, какие параметры Модели будут сокращены. Вообще говоря, обрезка может выполняться структурированным или неструктурированным способом.
2.2.1. Неструктурированная обрезка.
Неструктурированное или мелкозернистое сокращение означает, что целевым параметром сокращения является вес модели.,независимо от их положения в связанном тензорном слое. При весовой обрезке,Определение ненужных весов посредством оценки значимости,И потом заблокируйте или удалите их. Поскольку удаление весов может повредить структуру Модели.,Поэтому во время этого процесса веса обычно маскируют, а не удаляют.
Хотя маскирование весов вместо их удаления во время обучения увеличивает использование памяти, информацию о маскированных весах можно использовать на каждом этапе для сравнения сокращенной модели с исходной моделью. Мелкозернистая обрезка не всегда полезна, поскольку для использования этой нерегулярной разреженной операции требуется специальное оборудование. Хотя более высокие коэффициенты сжатия могут быть достигнуты с помощью неструктурированного сокращения, индексы, хранящие веса сокращения, могут привести к более высокому использованию хранилища.
2.2.2. Структурированная обрезка.
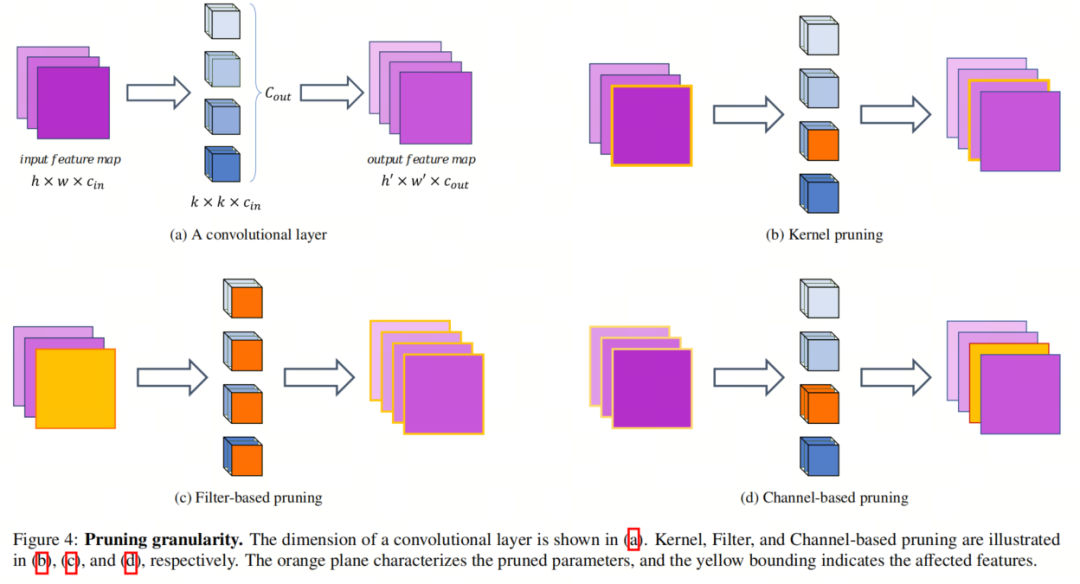
В отличие от предыдущей категории, Структурированная обрезку можно обрезать на основе структуры тензора веса. Структурированная обрезка Наблюдайте закономерности в тензорах весов при оценке важности весов.,чтобы их можно было описать с минимальными накладными расходами на индексацию.,Например, шаг или блок. в сверточном слое,Нет.
канал проходит через
Он получается путем свертки фильтра с входной картой объектов. Поэтому можно выбрать Структурированную выборка групп параметров, таких как фильтры, каналы или ядра. На рисунке 4 изображены эти Структурированные Выбора Различия между примерами.
Обрезка на основе каналов
Его цель — удалить первый объект, который приводит к выходной карте объектов в каждом слое.
весовой фильтр для каждого канала. Многие существующие методы обрезки каналов используют
норма как критерий определения наименее важного весового тензора. Однако существуют разногласия по поводу влияния этого процесса на общую структуру Модели. существуют [Очистка каналов для ускорения работы очень глубоких нейронных сетей], автор отметил, что процесс обрезки каналов наносит меньший ущерб представленные модели.
Напротив, в [,Отсечение каналов посредством автоматического поиска структуры] наблюдается, что сокращение каналов приводит к радикальным изменениям в структуре сети. Однако структурный ущерб можно смягчить путем маскировки параметров, а не их полного удаления. Однако такой подход может не принести никакой экономии при обучении, поскольку всю модель необходимо хранить в памяти.
Отсечение на основе фильтров
Отсечение на основе фильтров Устраняет Нет.
Вес канала. То есть обрезать определенный фильтр, то есть i-й фильтр, в сверточном слое. Этот метод сокращения наносит меньший ущерб структуре модели и может обрабатываться аналогично исходной модели, поскольку количество выходных каналов остается прежним.
Стоит упомянуть:
1) в
Слой Обрезка на основе раствора эквивалентен в
слой Отсечение на основе фильтров;
2) Обрезка фильтра и отсечение на основе фильтры не те. При сокращении фильтра будет удален фильтр с несколькими слоями, который с точки зрения детализации можно классифицировать как «обрезка». на основе каналов。
Обрезка на основе ядра
В этой категории отсекаются все параметры фильтра в l-м слое, соединяющем i-й канал входной карты объектов и j-й канал выходной карты объектов. Такая обрезка детализации не вредит структуре модели.
Независимо от критериев детализации и значимости обрезки,Процесс сокращения может выполняться в однократном или итеративном режиме. при однократной обрезке,Неважные параметры удаляются/маскируются до и после обучения.
При сокращении после обучения производительность сети может постоянно ухудшаться, в то время как итеративное сокращение учитывает снижение производительности и переобучает сеть. Хотя итеративное сокращение требует больше вычислений и времени по сравнению с однократным сокращением, в некоторых случаях оно может предотвратить ухудшение точности или даже повысить точность.
Кроме того, некоторые методы изменяют функцию стоимости сети, например, добавляют условия регуляризации, чтобы сделать модель более подходящей для сокращения. Поэтому их нельзя использовать в качестве обрезки после тренировки.
2.3. Недавние исследования применения обрезанного YOLOv5.
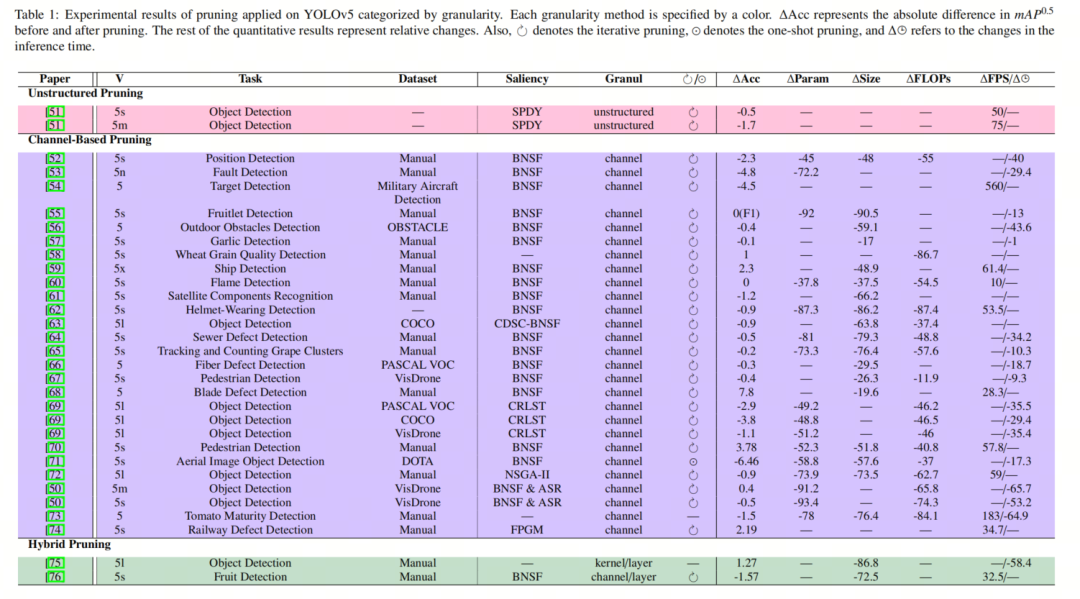
В таблице 1 показаны результаты недавнего экспериментального сокращения YOLOv5, классифицированные по степени детализации обрезки.
[Spdy: Точная обрезка с гарантиями ускорения] фокусируется на достижении желаемого времени вывода, а не на определенной степени сжатия. Он предлагает метод сокращения для изучения эффективных разреженных профилей с помощью динамического программного поиска (SPDY), который можно использовать как в однократных, так и в итеративных схемах.
[Faster and accurate green pepper detection using nsga-ii-based pruned yolov5l in the field environment] Исследователи в на основе алгоритма генетического алгоритма недоминируемой сортировки (NSGA-II),Этот алгоритм рассматривает обрезку как задачу оптимизации. То есть,Как обрезать каналы, чтобы минимизировать GFLOP и максимизировать mAP0.5.
[Структурированная обрезка для глубоких сверточных нейронных сетей посредством адаптивной регуляризации разреженности] предлагает адаптивную регуляризацию разреженности (ASR),Он генерирует ограничения разреженности на основе весов фильтра. То есть,Назначьте штраф фильтрам с более слабыми выходными сигналами канала в регуляризованной функции потерь.,Вместо прямого использования L1норма масштабного коэффициента нормализации партии для нормализации потерь. После тренировки,для всех слоев,Удалите пакеты фильтров, нормализованный коэффициент масштабирования которых меньше глобального порога.,И внесите точные настройки, чтобы восстановить точность.
Работа [Легкий алгоритм на основе yolov5 для определения относительного положения гидравлической крепи на угольных забоях] изменяет структуру YOLOv5 за счет использования функции активации PReLU и использования Ghost Bottleneck вместо BottleNeckCSP. Затем, в соответствии с методом BNSF (см. раздел 2.1.3), он отсекает каналы, кроме «узкого места-призрака».
[Улучшенный облегченный yolov5 с использованием механизма внимания для распознавания спутниковых компонентов] предлагает слой объединения функций и сеть выборочного ядра для улучшения внимания канала и ядра модели. Он подключает модуль кодировщика Transformer к выходу шеи PAN, исследует потенциал прогнозов модели посредством процесса самоконтроля и сжимает модель с использованием метода BNSF перед развертыванием в NVIDIA Jetson Xavier NX.
Кроме того, [Метод сокращения фильтра целевой емкости для оптимизации времени вывода на основе yolov5 во встроенных системах] направлен на получение желаемого количества параметров и FLOP и использует вычислительное регуляризованное разреженное обучение (CRLST). После разреженного обучения каналы итеративно отсекаются в соответствии с нормализованным пакетным коэффициентом масштабирования.
Все сжатые модели YOLOv5 в [Улучшенный облегченный yolov5 с использованием механизма внимания для распознавания спутниковых компонентов] развернуты на NVIDIA Xavier NX.
[Обнаружение дефектов крепежных элементов гусениц на основе обрезанной модели yolo v5] Рассматривайте фильтр как точку в пространстве и используйте метод геометрической медианы сокращения фильтра (FPGM), чтобы обрезать фильтр слоя свертки, который аналогичен
Стандарт -norm отличается тем, что явно использует взаимосвязь между фильтрами. Он вычисляет геометрическую медиану весов всего слоя и удаляет фильтры, считающиеся избыточными, если их геометрическая медиана близка к геометрической медиане слоя.
[Pruned-yolo: Обучение эффективному детектору объектов с использованием обрезки модели] Отказ от слоев повышающей дискретизации, соединения и обнаружения и сокращение фильтра в соответствии с методом BNSF, а затем использование стратегии мягкой маски для внедрения разреженных коэффициентов с косинусным затуханием (CDSC-BNFS) .
[Research on pedestrian detection model and compression technology for uav изображения и Сод-йоло: A small target defect detection algorithm for wind turbine blades based on improved yolov5, Advanced Theory and Simulations ] От BNSFОбрезка на основе каналовделать Модельлегче Количественная оценка,и добавил еще один модуль повышения частоты дискретизации BottleNeckCSP в шейную сеть.,для извлечения большего количества смысловой информации из небольших объектов. Последний также добавляет модуль внимания сверточного блока (CBAM) на выходе каждого модуля BottleNeckCSP в шейной сети перед подачей его в головку.
[Apple stem/calyx real-time recognition using yolo-v5 algorithm for fruit automatic loading system] Среднее значение каждого слоя Conv учитывается перед каждым соединением ярлыка в BottleNeckCSP, и сеть Backbone сжимается. Также выполняется Обрезка методом BNSF. на основе что. Ниже приведен список нескольких недавних реализаций обрезки YOLOv5:
- [ Compressed yolov5 for oriented object detection with integrated network slimming and knowledge distillation] Сеть чернослива методом BNSF, но доработать дистилляцией. знания в совокупности позволяют сэкономить время обучения, сохраняя при этом
точность.
- [Улучшенный метод обнаружения целей в режиме реального времени yolov5] Авторы заменили CSPDarknet на MobileNetV3 и использовали TensorRT после обрезки фильтров.
- Работа [Подход глубокого обучения на основе Channel Pruned yolo v5s для быстрого и точного обнаружения плодов яблок перед их прореживанием] фокусируется на использовании стратегии BNSF для обрезки фильтра и выполнения точной настройки.
- [Быстрое и точное определение качества зерна пшеницы на основе улучшенного йолова5] обрезка Backboneсеть,и поскольку желаемые размеры объектов относительно одинаковы,Удалена карта максимальных возможностей модуля PAN. также,в шее,Предлагается гибридный модуль внимания для извлечения наиболее полных характеристик канала.
- [Быстрое обнаружение судов на основе облегченной сети yolov5] использует алгоритм встраивания случайных окрестностей с t-распределением, чтобы уменьшить размерность прогнозирования опорного кадра и объединить его с взвешенной кластеризацией для прогнозирования размера кадра для достижения более точного прогнозирования целевых кадров. Впоследствии фильтр отсекается методом BNSF.
- [Mcca-yolov5-light: более быстрый, сильный и легкий алгоритм обнаружения ношения шлема] В Backboneset используется механизм многоспектрального внимания к каналам для генерации более информативных функций.,И улучшена точность обнаружения мелких объектов.,Обрежьте фильтры модели с помощью процесса BNSF.
- [Отслеживание и подсчет гроздей винограда на поле в режиме реального времени на основе обрезки каналов с помощью yolov5s] через стандартный фильтр обрезки BNSF.,и ввести мягкое немаксимальное подавление,Позволяет модели обнаруживать перекрывающиеся гроздья винограда, а не отбрасывать их.
- [Исследование по обнаружению дефектов в автоматизированных процессах размещения волокон на основе многомасштабного детектора] Использование расширенных сверток пространственной пирамиды (SPDC) для объединения карт характеристик различных рецептивных полей,для интеграции информации о дефектах в нескольких масштабах. это в шее Встроенный механизм внимания канала,Сосредоточьте больше внимания на эффективных каналах функций после каждой операции конкатенации. впоследствии,От BNSFОбрезка на основе часы с тонкой настройкой для сжатия Модель.
- [ Yolov5-ac: облегченный yolov5 на основе механизма внимания для обнаружения пешеходов] В структуру YOLOv5 было внесено множество изменений.,Напримерв шее Добавлен механизм внимания,И добавлено извлечение контекста Модель в Backboneсеть. Что касается обрезки,В нем используются стандартные удаляющие фильтры BNSF.
- [Метод обнаружения объектов для захвата робота на основе улучшенного yolov5] Сжатие шеи и магистральной сети YOLOv5 посредством обрезки слоев и ядра.
- [ Lightweight tomato real-time detection method based on improved yolo and mobile deployment] Замените Backbone-сеть YOLOv5 на MobileNetV3 и передайте Обрезку. на основе сеть каналов.
В исследованиях по обрезке YOLOv5 почти 85% использовали Обрезку. на основе каналовметод,Остальное связано с другими структурированными и неструктурированными деталями. Критерием значимости, в основном используемым для сокращения, является метод разреженного обучения BNSF.,Около 60% опрошенных статей приняли этот подход в рамках авторского подхода.,а остальные приняли
норма、
нормаили предложили новый критерий различимости.
3. Количественная оценка
Квантование нейронной сети направлено на представление весов и активаций глубокой нейронной сети с меньшим количеством битов, чем их исходная точность (обычно 32-битные числа с плавающей запятой одинарной точности FP32). Этот процесс выполняется при попытке сохранить производительность/точность модели. Квантование может уменьшить размер модели и сократить время вывода, используя преимущества более быстрых аппаратных целочисленных инструкций.
В [А survey of quantization methods for efficient neural network вывод], Голами и др. Исследуются различные аспекты оценки, включая теоретические детали предмета. Здесь автор кратко представит и обсудит ключевые моменты. Не умаляя общности, автор поясняет Количественную Концепция оценки использует фактическую конечную переменную, которая может представлять вес или активацию в нейронной сети.
гипотеза
— конечная переменная, ограниченная диапазоном S, и автор желает сопоставить ее значение с q, которое представляет собой набор
дискретные числа в . Перед отображением автор может захотеть ограничить диапазон входных данных r меньшим набором.
。
3.1. Интервал квантования: равномерный и неравномерный.
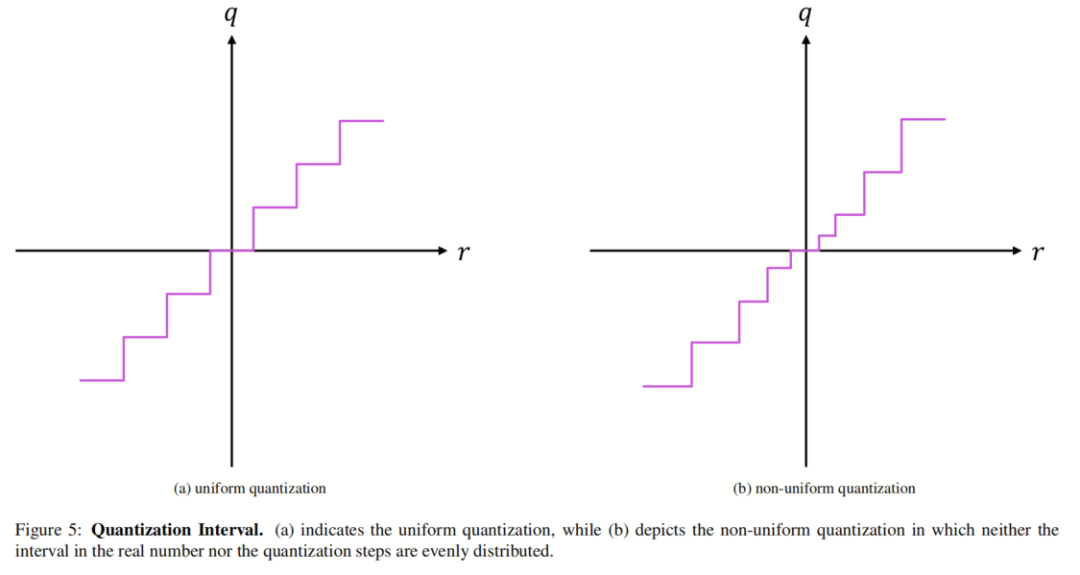
Равномерное квантование отображает r в набор равномерно расположенных дискретных значений, тогда как при неравномерном квантовании расстояния между дискретными значениями не обязательно равны. При неравномерном квантовании можно лучше уловить важную информацию о распределениях весов и активации, поскольку более плотные области можно назначить более близким шагам. Следовательно, хотя использование неравномерного квантования требует большего проектирования, чем унифицированные методы, оно может привести к меньшему ухудшению точности.
Более того, поскольку распределения весов и активаций обычно имеют колоколообразную форму с длинными хвостами, неравномерное квантование может привести к лучшим результатам. Рисунок 5 иллюстрирует различия между приведенными выше схемами количественного определения.
3.2. Статическое квантование и динамическое квантование.
Для набора входных данных обрежьте диапазон
,в
, может определяться динамически или статически. Динамическая Количественная Оценка динамически вычисляет диапазон ограничения для каждого входа, а статическая Количественная Crowth использует заранее вычисленный диапазон для обрезки всех входных данных. Динамическая Количественная рейтинг может быть достигнут лучше, чем статический Количественная Оценка Более высокая точность, но значительные вычислительные затраты.
3.3. Количественные схемы: QAT и PTQ.
Выполните Количественную на обученной Модели. Оценка может оказать негативное влияние на точность Модели из-за накопления числовых ошибок. Поэтому Количественная Оценку можно выполнить двумя способами: Количественная Оценка Перцептивное обучение (QAT), то есть сеть переобучения, или посттренинговая Количественная повышение квалификации (PTQ), без учета переподготовки. В QAT, Количественная Прямое и обратное распространение значения Модель выполняется с использованием чисел с плавающей запятой, а параметры сети выполняются после каждого обновления градиента. оценка。
PTQ же выполняет Количественную сеть без переподготовки. Настройка и настройка параметров. Этот метод обычно приводит к снижению точности Модели по сравнению с QAT, но требует меньших вычислительных затрат. Обычно PTQ использует небольшой объем калибровочных данных для оптимизации Количественной параметр оценки, затем Количественная модель оценка. Поскольку PTQ опирается на минимальную информацию, обычно невозможно достичь точности менее 4 и 8 бит при сохранении точности.
3.4 Количественный план развертывания.
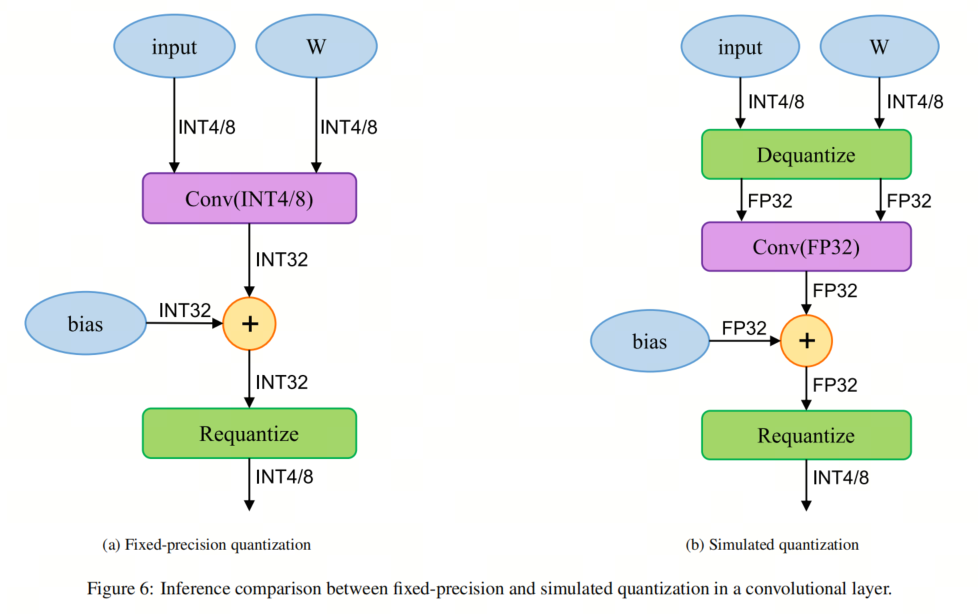
один раз Модельодеяло Количественная уважение, оно может использовать лицемерие Количественная оценка (также известная как аналог Количественной оценка)илитолько целые числа Количественная оценка(Также называется фиксированной точкой Количественная распаковать) провести развертывание. В первом случае веса и активации хранятся с низкой точностью, но все операции от сложения до умножения матриц выполняются с точностью с плавающей запятой. Хотя этот метод требует постоянного решения до и после операций с плавающей запятой. оценкаи Количественная точность, но это в пользу точности Модели.
Однако в последнем операции, а также сохранение веса/активации выполняются с использованием целочисленной арифметики низкой точности. Таким образом, модель может использовать преимущества быстрой целочисленной арифметики, предоставляемой большинством аппаратных средств. Рисунок 6 иллюстрирует разницу между развертыванием PTQ и QAT на одном сверточном уровне.
3.5. Прикладное исследование количественного YOLOv5.
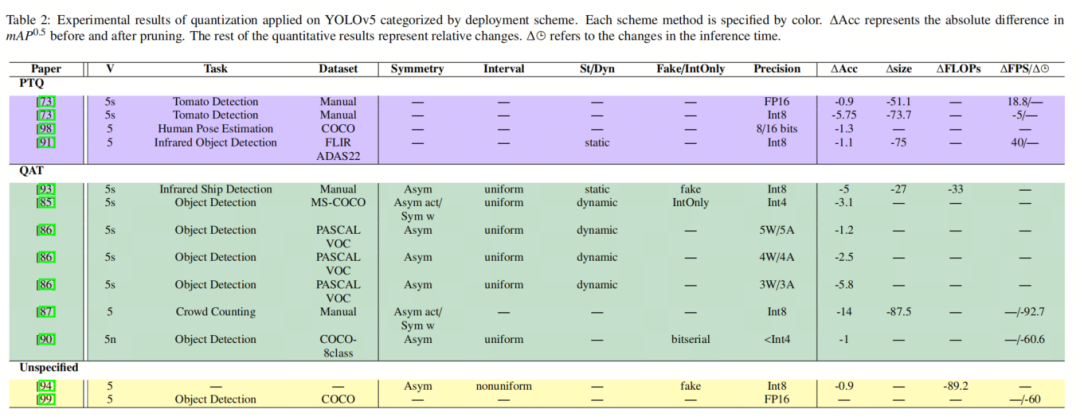
В таблице 2 перечислены результаты недавних исследований количественного анализа, проведенных на YOLOv5, классифицированных по схемам квантования. В [Drgs: Низкоточное полное квантование глубокой нейронной сети с динамическим округлением и градиентным масштабированием для обнаружения объектов] автор предложил метод QAT, который динамически выбирает режим округления веса в соответствии с направлением обновления веса во время обучения. процесс и соответствующим образом отрегулируйте градиент. Они квантовают модель слой за слоем, используя симметричные/асимметричные диапазоны отсечения для весов и активаций сети.
Псевдоквантование с введением шума (NIPQ) в качестве метода QAT сначала использует шум псевдоквантования для предварительного обучения сети, а затем квантует модель после обучения. Этот метод автоматически регулирует разрядность и интервал квантования, одновременно регулируя суммирование следов матрицы Гессе нейронной сети. Авторы оценили свой метод на YOLOv5 и достигли точности менее трех цифр практически без заметного снижения точности.
Кроме того, [встроенная система обнаружения пожара и подсчета толпы с искусственным интеллектом со сверхнизким энергопотреблением для внутренних помещений] использует ShuffleNetV2 для модификации магистральной сети и уменьшения количества слоев в PAN и головных сетях, чтобы сделать модель более подходящей для мобильных устройств. Они использовали TensorFlow Lite Micro для квантования весов и активаций с 8-битной точностью и в конечном итоге применили модель на микроконтроллерах со сверхмалым энергопотреблением STM32.
[Ускорение вывода модели глубокого обучения на процессоре руки с помощью сверхмалого битового квантования и времени выполнения] представляет Deeplite Neutrino, который может автоматически выполнять суб4-битное квантование на моделях CNN, а также предоставляет механизм вывода Deeplite Runtime, позволяющий работать на Процессор ARM Становится возможным развертывание квантованных моделей со сверхнизкой разрядностью. Их метод QAT может обеспечить точность менее 4 бит для весов и активаций сети благодаря специальным операторам свертки, разработанным с использованием вычислений на уровне битов. То есть вычисление скалярного произведения младших битовых весов и значений активации выполняется посредством popcount и битовых операций. Они оценили свой подход, развернув YOLOv5 на Raspberry Pi 4B.
[Обнаружение объектов транспортного средства и человека по инфракрасному изображению на основе улучшенного yolov5] заменяет магистральную сеть на MobileNetV2 и добавляет механизм координатного внимания. После квантования модели через PyTorch с использованием статической схемы и псевдоквантования с 8-битной точностью модель была развернута на NVIDIA Xavier NX.
Аналогично, в [Оценка производительности и квантование модели алгоритма обнаружения объектов для инфракрасного изображения] модифицированный YOLOv5 псевдоквантуется с использованием PyTorch с 8-битной точностью и статическим диапазоном ограничения.
[Облегченный метод обнаружения томатов в реальном времени, основанный на улучшенном развертывании yolo и мобильных устройств] После обучения модель сжатия квантуется с использованием структуры сверточной нейронной сети Nihui (NCNN) и развертывается на реальных мобильных устройствах, оснащенных процессорами MediaTek Dimensity. [94] предложили метод логарифмического квантования, который масштабирует распределение активаций, чтобы сделать его пригодным для логарифмического квантования. Этот подход может минимизировать ухудшение точности YOLOv5, вызванное логарифмическим квантованием.
В целом, более половины исследовательских работ используют схемы QAT, результаты которых позволяют достичь квантования с низкой точностью ниже 3 цифр. Однако ни одна схема PTQ еще не достигла точности менее 8 бит. Несмотря на то, что существует больше количественных исследований YOLOv5, в центре внимания этого обзора в основном находятся те статьи, в которых используются новые количественные методы. Поэтому авторы исключают те результаты, которые в своей реализации используют только TensorRT, квантование PyTorch и квантование ONNX.
4. Резюме
4.1. Проблемы обрезки и будущие направления.
В отличие от обычных CNN, обрезка YOLOv5 сталкивается с некоторыми проблемами из-за сложной и высокооптимизированной архитектуры глубокой нейронной сети. YOLOv5 использует архитектуру нейронной сети CSP-Darknet53 в качестве магистральной сети и PANet в качестве шеи, обе из которых состоят из множества сверточных слоев, которые тесно связаны между собой. Кроме того, взаимосвязь между магистральной сетью и шеей увеличивает сложность модели. В целом структурная сложность этих уровней предотвращает удаление ненужных фильтров, не оказывая при этом отрицательного влияния на общую производительность сети. В противном случае пространственное разрешение карт объектов, связанных с соединениями, не будет совпадать. Следовательно, перед обрезкой YOLOv5 необходимо выполнить некоторую компенсацию. Например, [Pruned-yolo: обучение эффективному детектору объектов с использованием сокращения модели] не учитывает сокращение слоя повышающей дискретизации, уровня соединения и заголовка YOLOv5.
также,Он игнорирует ярлыки соединений в модуле BottleNeck.,чтобы разрешить входы с различным количеством каналов. в этом отношении,Дополнительные исследования должны рассмотретьна на основе фильтра и на на основе сокращения ядра Convolution, поскольку эта стратегия сокращения не меняет количество выходных каналов, тем самым упрощая процесс сокращения. Как показано в Таблице 1, текущее направление исследований заключается в использовании BNSF для обучения разреженности и Обрезки. на основе настройки и тонкая настройка. Однако существует пробел в единовременном сокращении с использованием других критериев значимости. Здесь автор представляет некоторые новые методы, которые не применялись к YOLOv5.
EagleEye рассматривает процесс сокращения как проблему оптимизации и отмечает, что использование точности оценки не может быть многообещающим критерием для выбора кандидатов на сокращение. Поэтому он предлагает случайный коэффициент обрезки для каждого слоя, а затем на основе их
норма подрезать фильтр. Он оценивает влияние сокращения кандидатов с помощью адаптивного модуля оценки кандидатов на основе BN, используя подвыборки обучающих данных.
В [Hrank: сокращение фильтров с использованием карты признаков высокого ранга] автор предлагает сокращение фильтров HRank, которое итеративно сокращает фильтры с картами активации низкого ранга. [Ускоренное разреженное обучение нейронов: доказуемый и эффективный метод поиска n: m переносимых масок] предлагает метод оценки разнообразия масок, который связывает структурированное сокращение с ожидаемой точностью. Он также представляет алгоритм сокращения под названием AdaPrune, который сжимает неструктурированные разреженные модели в мелкозернистые разреженные структурированные модели без повторного обучения.
Аналогичным образом, [Вариационная обрезка сверточной нейронной сети] предлагает вариационный алгоритм байесовской обрезки, который учитывает распределение масштабных коэффициентов BN каналов вместо их детерминированного использования, как в разделе 2.1.
4.2. Количественные проблемы и будущие направления.
Хоть и не имеет отношения к YOLO,Количественная оценка от FP32 к INT8 — это не плавный переход.,Если градиентный ландшафт плох,может препятствовать оптимальности результатов. также,делатьиспользоватьPTQдобиться низкого положения(<4Кусочек)Точность практически невозможна,Потому что это, скорее всего, разрушит производительность Модели.
В настоящее время существует тенденция использовать готовые модули квантования, такие как TensorRT, PyTorch Quantization и ONNX Quantization, но они не могут достичь очень низкой точности, поскольку они ограничены 8-битной точностью. Однако такие исследования не были включены в этот обзор, поскольку внимание авторов было сосредоточено на поиске новых методов количественного определения для использования на YOLOv5.
Что касается прикладных исследований квантованного YOLOv5, в большинстве исследований для квантования используется QAT с точностью от 1 до 8 бит. Однако существует пробел в том, чтобы сосредоточиться на ускорении времени обучения и времени вывода, особенно потому, что обучение YOLOv5 на новых наборах данных требует большого количества вычислений и времени. В качестве решения можно было бы более широко использовать квантование целых чисел, поскольку пропускная способность оборудования намного выше, когда арифметика выполняется с использованием целых чисел. Например, при типе данных INT4 вместо FP32 количество операций в секунду TITAN RTX можно увеличить примерно в 23 раза.
Кроме того, метод PTQ по-прежнему имеет проблемы при проведении исследований/потребностей с точностью менее 8 бит, что открывает возможности для будущих исследований. Поэтому автор предлагает некоторые методы, которые можно применить к YOLOv5, чтобы заполнить вышеуказанные пробелы.
существовать[ Up or down? adaptive rounding for post-training квантование] предлагается алгоритм PTQ под названием AdaRound для более эффективного квантования весов. оценка Округление。это Доступно по цене от4Кусочек Получено с точностьюSOTAпроизводительность,Точность почти не снижается(<1%)。
Яо и др. предложили HAWQV3, целое число смешанной точности. метод оценки, который может реализовать унифицированное отображение INT4илиINT4/INT8Количественная оценка. AdaQuant предлагает PTQКоличественную схема оценки для минимизации количественности каждого слоя или блока путем оптимизации параметров каждого слоя или блока в соответствии с калибровочным набором ошибка тарификации. Он может получить Количественную SOTA с точностью INT4. точности, что приводит к почти незначительному снижению точности.
[ Fully integer-based quantization for mobile convolutional neural network вывод] предложил Количественную метод оценки, который специально использует на основе Операций над целыми числами, исключающих избыточные инструкции при выводе.
[Квантование после обучения с учетом потерь] оценивает влияние квантования на лицо потерь и представляет новый метод PTQ, который может достичь 4-битной точности за счет прямой минимизации функции потерь, достигая точности, почти эквивалентной базовому результату полной точности.
5, ссылка
[1].Model Compression Methods for YOLOv5: A Review.
6. Рекомендуемая литература



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
