Разница между Само-вниманием и Многоголовым вниманием – с самым популярным пониманием! !
Предисловие
В связи с быстрой популярностью моделей-трансформеров, Self-Attention (механизм самообслуживания) и Multi-Head Внимание (механизм многоголового внимания) стало ключевым компонентом в области обработки естественного языка (НЛП). Эта статья начнется с Краткая работа, рабочий процесс, сравнение между двумятри аспекта,Проанализируйте эти два типа внимания.
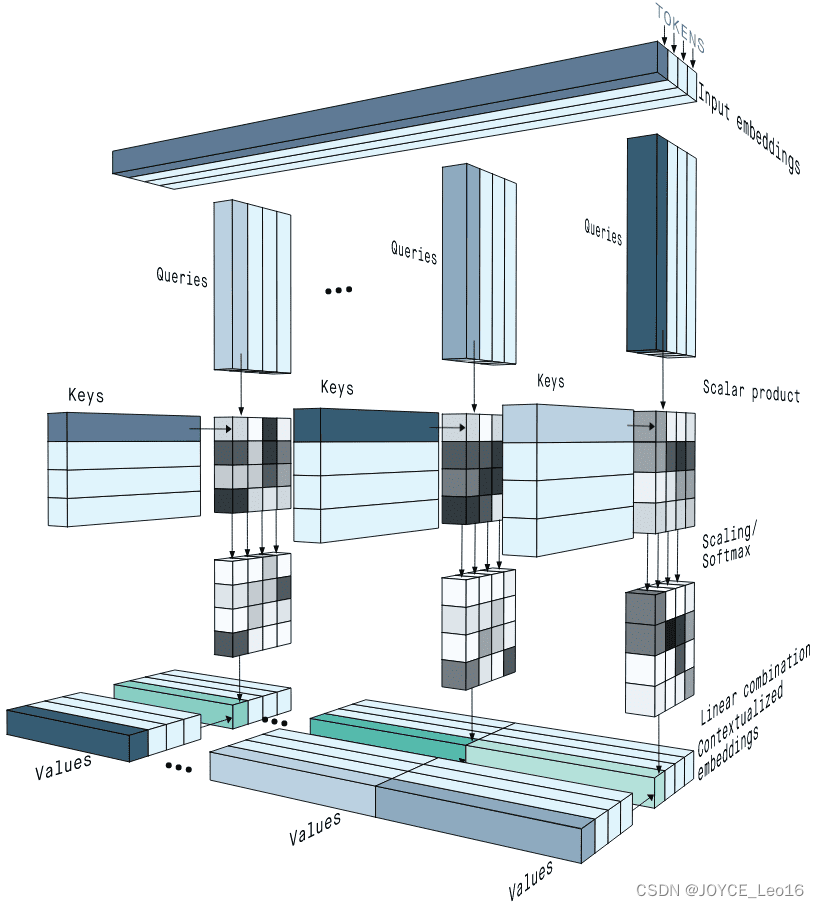
1. Краткое введение
Само-внимание (механизм само-внимания):Позволяет каждому элементу входной последовательностисосредоточиться наи взвесить остальные элементы во всей последовательности,Создать новое выходное представление,Не полагается на внешнюю информацию или исторические состояния.
- Самообслуживание позволяет каждому элементу входной последовательности взаимодействовать с любым другим элементом последовательности.
- Он вычисляет вес внимания каждого элемента ко всем остальным элементам, а затем применяет эти веса к самому соответствующему элементу, тем самым получая выходное представление взвешенной суммы.
- Само внимание не опирается на внешнюю информацию или предыдущие скрытые состояния и полностью основано на самой входной последовательности.
Self-Attention
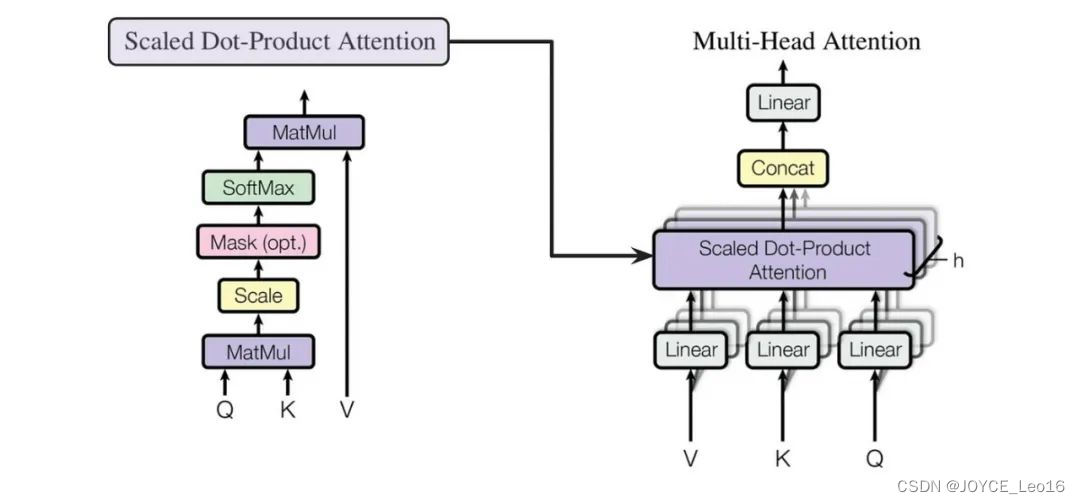
Multi-Head Attention (механизм многоголового внимания):Запуская несколько параллельноSelf-Attentionслои и объединить их результаты,Возможность одновременного захвата информации о входных последовательностях в разных подпространствах.,Тем самым усиливая выразительные возможности Модели.
- Многоголовое внимание на самом деле представляет собой несколько параллельных слоев самообслуживания, и каждая «голова» независимо изучает разные веса внимания.
- Выходные данные этих «голов» затем объединяются (обычно объединяются и пропускаются через линейный уровень) для получения окончательного выходного представления.
- Таким образом, Multi-Head Attentionспособен одновременнососредоточиться —Информация из разных подпространств входной последовательности.
Multi-Head Attention
2. Рабочий процесс
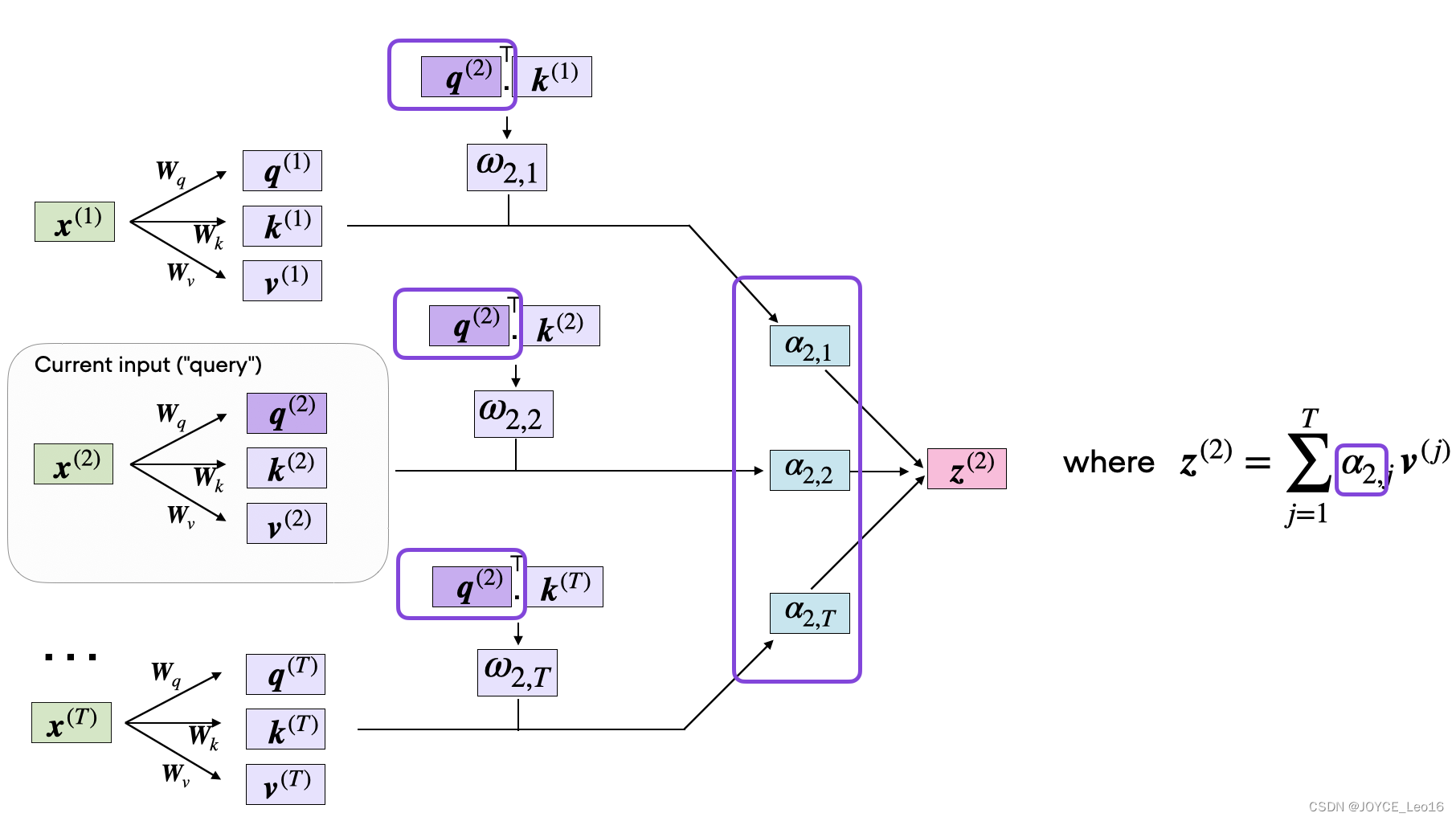
Само-внимание (механизм само-внимания):Создать запрос по、ключивектор значений,Рассчитать и нормализовать показатели внимания,Наконец, вектор значений взвешивается,В результате получается взвешенное представление каждой позиции во входной последовательности.
Рабочий процесс самообслуживания
Шаг первый: запрос, генерация ключей и значений
- входить:Получает входную последовательность, состоящую из векторов внедрения.,Эти векторы внедрения могут представлять собой векторные представления слов и векторные представления позиций.
- иметь дело с:Используйте три отдельных линейных слоя(или плотный слой)Сгенерируйте запрос для каждого входного вектора(Q)、Вектор ключа (K) и значения (V).
вектор запросаИспользуется для обозначения текущего фокуса или информации, которую вы хотите получить.。 ключевой векторопределить ивектор запрос соответствующей информации. Сумка вектора стоимостисодержащий и соответствующийключ Фактическая информация, связанная с векторами。
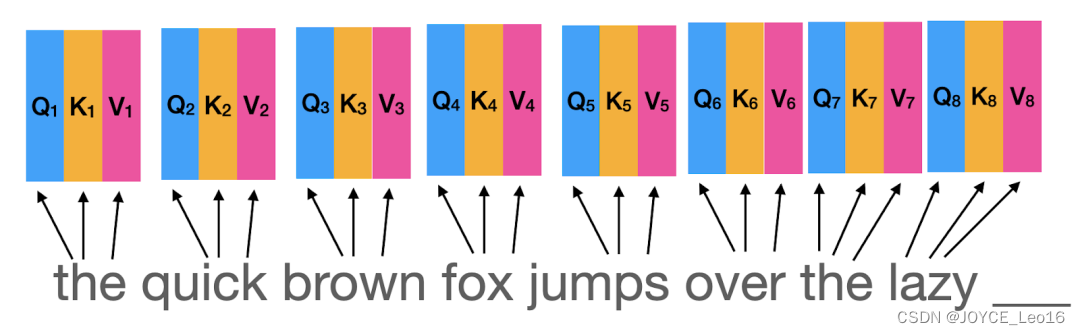
Шаг первый: запрос, генерация ключей и значений
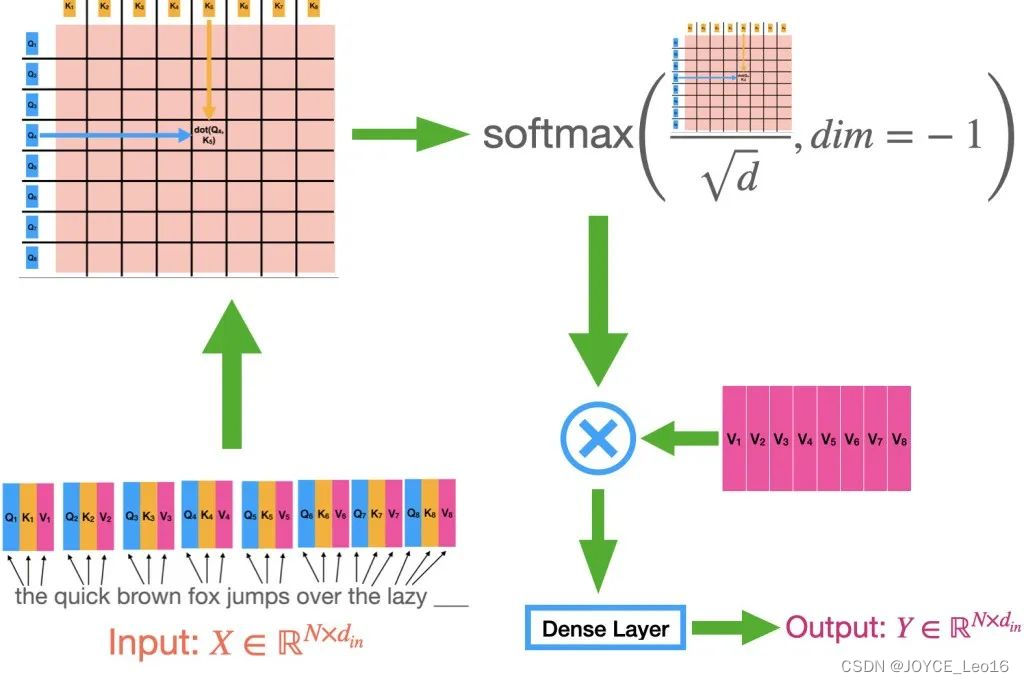
Шаг 2: Расчет матрицы внимания
- Иметь дело с: Вычислить скалярное произведение между всеми ключевыми векторами векторных запросов, чтобы сформировать матрицу оценки внимания.
Каждый элемент этой матрицы представляет показатель корреляции между вектором запроса и соответствующим вектором ключей. Дроби могут быть очень большими или очень маленькими из-за операций скалярного произведения.
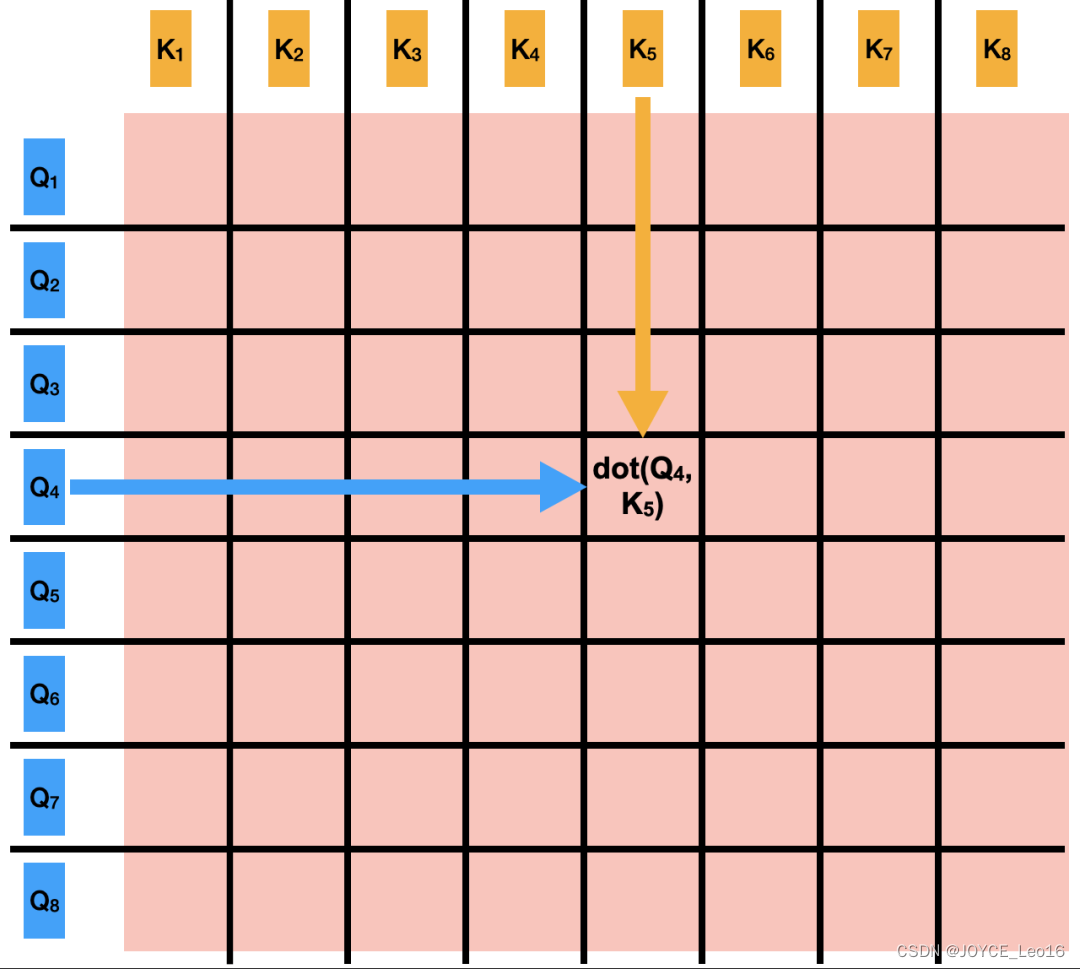
Шаг 2: Расчет матрицы внимания
Шаг 3: Нормализованные оценки внимания
- иметь дело с:приложение Softmaxфункция Нормализовать матрицу оценки внимания。
После нормализации сумма каждой строки равна 1, а каждая оценка представляет собой вес соответствующей информации о позиции. Перед применением softmax градиенты обычно стабилизируются путем деления на коэффициент масштабирования (например, квадратный корень из запроса или размерность ключевого вектора).
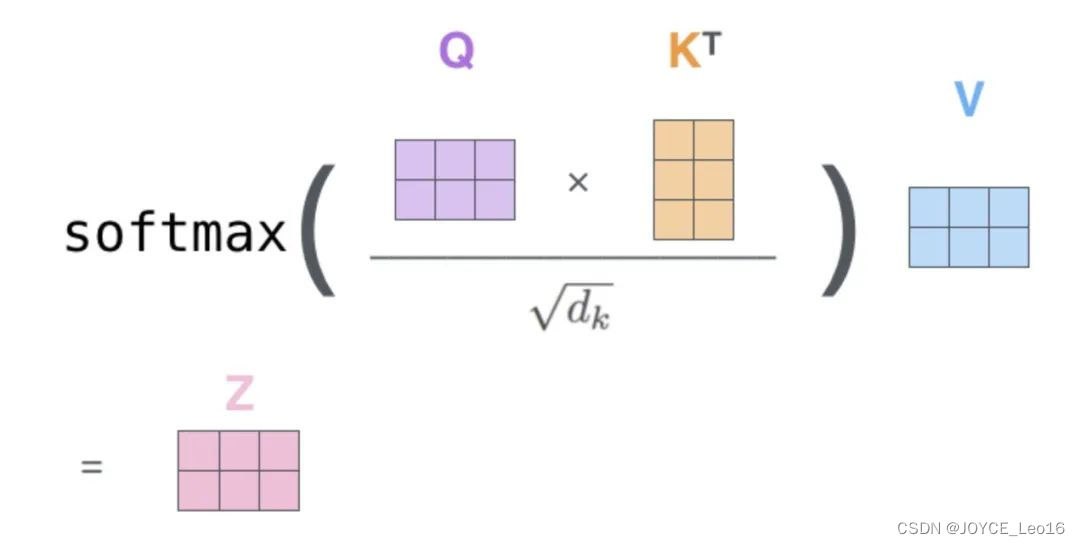
Шаг 3. Нормализуйте показатели внимания
Шаг 4: Вывод взвешенной суммы
- иметь дело с:Используйте нормализованную пару весов внимания.вектор значений Выполните взвешенный поиски
Результатом взвешенного суммирования является выходной сигнал механизма самообслуживания, который содержит взвешенную информацию всех позиций во входной последовательности. Каждый элемент выходного вектора представляет собой взвешенную сумму входных векторов, а веса определяются механизмом внимания.
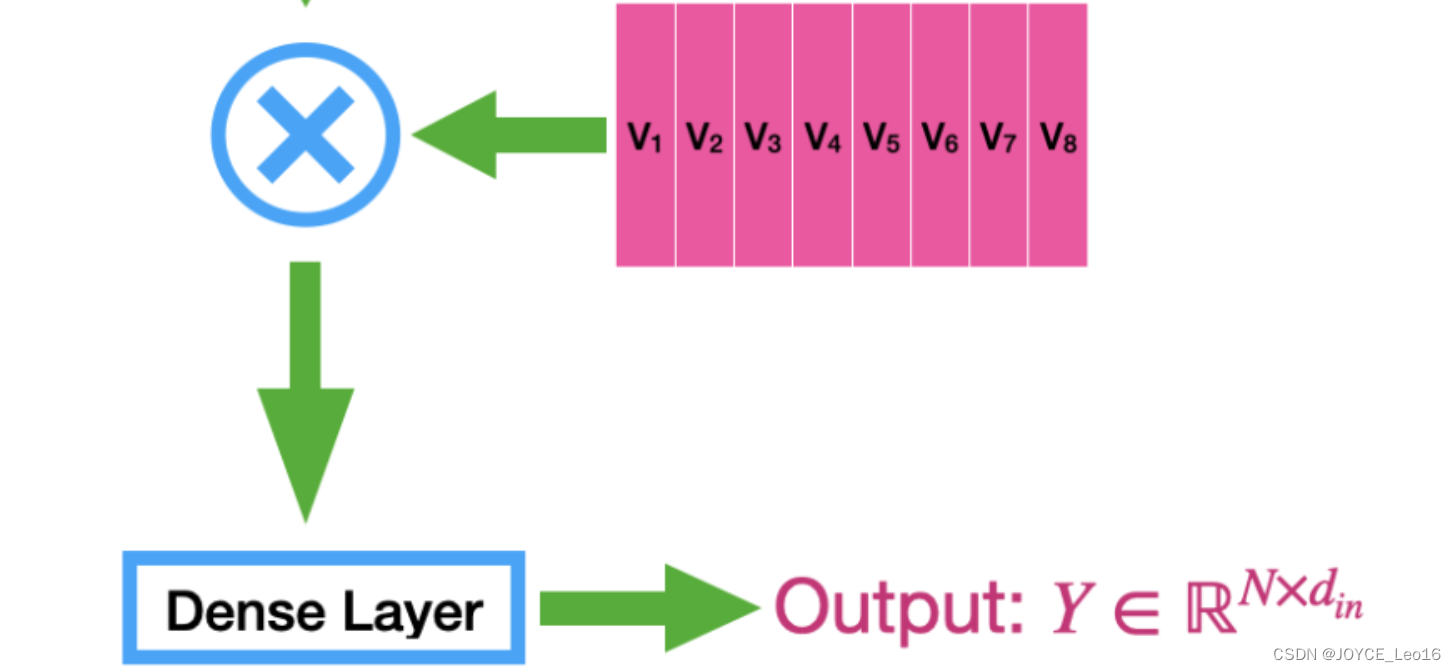
Шаг 4: Вывод взвешенной суммы
Multi-Head Attention (механизм многоголового внимания):Введя запрос、ключи Разделить матрицу значений на несколько голов,и рассчитывать внимание независимо в каждой голове,Затем выходы этих головок сращиваются и линейно преобразуются,Это обеспечивает одновременный захват и интеграцию множества интерактивных данных в разных подпространствах представления.,Улучшите выразительные способности Модели.
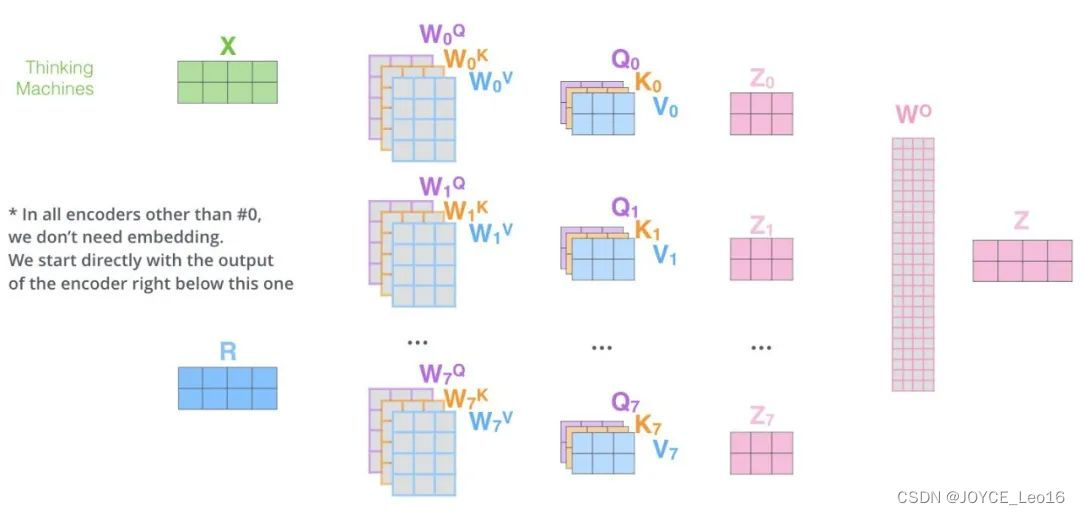
Рабочий процесс внимания нескольких голов
- инициализация:первый,Инициализируйте необходимые параметры,Включая веса запроса, матрицы ключей и значений.,и количество голов в бычьем внимании. Эти веса будут использоваться в последующих линейных преобразованиях.
- Линейное преобразование:Запрос на входе、Матрица ключей и значений преобразуется линейно. Эти линейные преобразования реализуются путем умножения на соответствующую весовую матрицу. Преобразованная матрица будет использоваться для последующих расчетов внимания нескольких голов.
- Сегментация и проекция:Запрос после линейного преобразования、Матрица ключей и значений разбита на несколько голов. Каждый заголовок имеет свой собственный запрос、ключиматрица значений。Затем,Оценки внимания рассчитывались независимо в каждой голове.
- Масштабирование и Softmax:Масштабирование оценки внимания каждой головы,Чтобы избежать проблем с исчезновением или взрывом градиента. Затем,Примените функцию Softmax для нормализации показателей внимания.,Сделайте сумму весов каждой позиции равной 1.
- Взвешенная сумма:Используйте нормализованную пару весов внимания.матрица значений Выполните взвешенный поиски,Получите выходную матрицу для каждой головы.
- Сращивание с Линейным преобразование:Объедините выходные матрицы всех головок вместе,Сформируйте большую выходную матрицу. Затем,Линейное преобразование этой выходной матрицы,Получите окончательный результат.
3. Сравнение двух
Основное отличие: внимание к себесосредоточиться на Важность каждой позиции в последовательности для всех остальных позиций.,иMulti-Head AttentionЗатем, вычислив внимание в нескольких подпространствах параллельно,Позволяет модели одновременно захватывать и интегрировать различные аспекты контекстной информации.,Это расширяет возможности моделирования внутренней структуры сложных данных.
- Само-внимание (механизм само-внимания):Суть механизма самообслуживания заключается в изучении распределения веса для каждой позиции во входной последовательности.,Таким образом, Модель будет знать при обработке текущего местоположения.,Какая информация о местоположении важнее. Самовнимание, в частности, относится к расчету внимания, выполняемому в рамках последовательности,То есть каждая позиция в последовательности должна рассчитывать вес внимания относительно всех остальных позиций.
- Multi-Head Attention (механизм многоголового внимания):чтобы позволить Модельспособен одновременнососредоточиться на Информация из разных мест, Transformer представляет Multi-Head Внимание. Его основная идея состоит в том, чтобы разделить представление входной последовательности на несколько подпространств (голов).,Затем веса внимания рассчитываются независимо внутри каждого подпространства.,Наконец, результаты каждого подпространства объединяются. Преимущество этого заключается в том, что Модель может собирать различную контекстную информацию в разных подпространствах представления.
Сравнение случаев:существовать“Я люблюAI”Пример,Self-Attention вычисляет вес каждого слова, связанный с другими словами.,иMulti-Head Внимание позволяет модели собирать более обширную контекстную информацию путем разделения пространства внедрения и параллельного вычисления этих весов в нескольких подпространствах.
Само-внимание (механизм само-внимания):
1. входить:последовательность“Я люблюAI”После встраивания слоя,Каждое слово (например, «Я») отображается в 512-мерный вектор. 2. Внимание расчет веса: Для слова «Я» механизм Само-Внимания вычисляет вес внимания между ним и всеми остальными словами в последовательности («любовь», «А», «Я»). Это означает, что для 512-мерного вектора внедрения «Я» мы вычисляем оценку внимания между ним и векторами внедрения «Любви», «А» и «Я». 3. Выход:Согласно расчетному весу внимания,Вычислите взвешенные векторы слов во входной последовательности,Получите выходной вектор, обработанный механизмом самообслуживания.
Multi-Head Attention (механизм многоголового внимания):
1. Разделение подпространства: Исходное 512-мерное пространство вложения разделено на несколько подпространств (например, 8 голов, каждое подпространство 64-мерное). Для слова «I» его 512-мерный вектор внедрения соответственно разбивается на восемь 64-мерных подвекторов. 2. независимый Внимание расчет веса: В каждом 64-мерном подпространстве веса внимания между «Я» и «любовью», «А» и «Я» рассчитываются независимо. Это означает, что в каждом подпространстве у нас есть независимый набор оценок внимания для расчета взвешенной суммы. 3. Объединение и преобразование результатов: Выходные данные внимания, рассчитанные для каждого подпространства, объединяются в более крупный вектор (в данном случае 8 64-мерных векторов объединяются в 512-мерный вектор). Через линейный слой этот склеенный вектор преобразуется обратно в исходное 512-мерное пространство для получения Multi-Head. Окончательный результат «Внимания».
4. Популярное понимание
Само-внимание (механизм само-внимания)
Предположим, вы играете с кучей игрушек. Некоторые игрушки дружат, и им нравится с ними играть. Например, игрушки-супергерои любят быть с другими супергероями, а игрушки-животные любят быть с другими животными. Когда вы играете с игрушкой, вы задаетесь вопросом, какие игрушки ее лучшие друзья? Механизм внимания к себе подобен помощи игрушкам найти своих лучших друзей. Таким образом, игрушки смогут лучше играть вместе, делая игру более увлекательной.
В мире компьютеров механизм самообслуживания помогает компьютерам определить, какие слова в предложении являются «хорошими друзьями», а какие слова необходимо понимать вместе. Это похоже на помощь игрушкам найти своих лучших друзей и делает всю историю более интересной.
Multi-Head Attention (механизм многоголового внимания)
Предположим, у вас есть группа разных детей, у каждого из которых есть своя любимая игрушка. Одному ребенку больше всего могут нравиться супергерои, другому — животные, а третьему — автомобили. Когда они играют вместе, каждый сосредотачивается на своей игрушке. Затем они вместе рассказывают истории о своей игре, образуя одну большую историю, в которой каждая игрушка имеет свой характер.
Многоголовый механизм внимания такой же, как у этих детей. Компьютер не просто видит проблему под одним углом, но, как и многие дети, он видит ее под разными углами. Таким образом, компьютер может узнать больше о вещах. Точно так же, как дети делятся своими историями, компьютер может объединить эти разные точки зрения, чтобы лучше понять проблему в целом.
Подвести итог
Таким образом, механизм самовнимания подобен помощи игрушкам в поиске хороших друзей, а механизм многоголового внимания похож на то, как многие дети играют с игрушками под разными углами, что делает историю богаче и интереснее. Компьютер использует эти методы, чтобы лучше понимать то, что мы ему говорим, словно играя в веселую игру!
Ссылка: Architect предлагает вам поиграть с ИИ.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
