Разница между искрообразованием и искрой
Spark Streaming и Spark — два важных компонента экосистемы Apache Spark. Они принципиально различаются по способу и целям обработки данных. Ниже приводится подробное сравнение этих двух компонентов и объяснение того, как их использовать для обработки данных.
(Источник изображения из Интернета, удален в связи с нарушением авторских прав)
1. Основные понятия Spark Streaming и Spark.
Spark Streaming
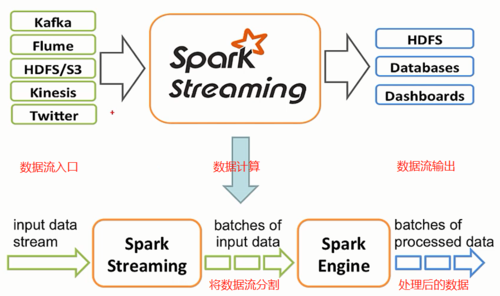
Spark Streaming — это платформа потоковой обработки, которая позволяет пользователям обрабатывать потоки данных в реальном времени с высокой пропускной способностью. Spark Streaming может обрабатывать данные из нескольких источников данных (таких как Kafka, Flume, Kinesis и т. д.) и преобразовывать непрерывные потоки данных. Разделить на ряд дискретных пакетов данных. Эти пакеты называются DStreams (Дискретизированные потоки), и каждый пакет данных может обрабатываться в механизме Spark, аналогично заданию пакетной обработки.
Spark
Spark Это платформа обработки больших данных, предоставляющая мощный интерфейс для выполнения задач пакетной обработки Spark. Spark поддерживает различные операции обработки данных, включая преобразования и действия, и может эффективно обрабатывать крупномасштабные наборы данных в памяти. Основная концепция заключается в RDD(ResiLIent Distributed DaTAset),Это неизменяемая коллекция распределенных объектов.,Возможна параллельная обработка.
Исходная ссылка: https://www.mfdjyx.com/om/34522.html.
2. Разница между Spark Streaming и Spark
Методы обработки данных
Spark Streaming:Обработка Непрерывнаяизпоток данных,Разделите данные на небольшие пакеты,и обрабатывается для каждой партии.
Spark:Работа со статическими наборами данных,Обычно обработка больших объемов данных, хранящихся в файловой системе или базе данных.
в реальном времени
Spark Streaming:Обеспечить возможности обработки практически в реальном времени,Вы можете установить интервал пакетной обработки в соответствии с вашими потребностями (например, обработка данных каждые 1 секунду).
Spark:Не подходит для обработки в реальном времени.,Потому что он предназначен для пакетной обработки.
модель данных
Spark Streaming:использовать DStreams для представления непрерывного потока данных.
Spark:использовать RDDs для представления статических наборов данных.
механизм отказоустойчивости
Spark Streaming:Сохранив данные в Spark из RDD в, наследство Spark измеханизм отказоустойчивости。
Spark:проходитьRDDизродословная карта(lineage)для достижения отказоустойчивости,Нет необходимости пересчитывать недостающие данные.
3. Техническое обучение
Использование потоковой передачи Spark
Для начала Использование потоковой передачи Спарк, тебе нужно настроить Spark Streaming контекст, а затем создайте его из источника данных DStreams, определяют операции преобразования и вывода. Ниже приведен простой пример, показывающий, как использовать потоковой передачи Spark Считайте данные из источника текстового файла и посчитайте каждое слово.
import org.apache.spark._
import org.apache.spark.streaming._
// создавать SparkConf и StreamingContext
val conf = new SparkConf().setAppName("WordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Из источника текстового файла создателя DStream
val lines = ssc.textFileStream("hdfs://...")
// Разделите каждую строку на слова
val words = lines.flatMap(_.split(" "))
// Посчитайте каждое слово
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
// Распечатать результаты
wordCounts.print()
// Начните получать данные и обрабатывать их
ssc.start()
ssc.awaitTermination()
Использование Искры
Использование Искры Выполнение обработки данных обычно включает загрузку набора данных, выполнение серии преобразований, а затем запуск вычислений, таких как Искры Выполните подсчет слов по простому примеру.
import org.apache.spark._
import org.apache.spark.rdd.RDD
// создавать SparkConf и SparkContext
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
// Загрузите текстовый файл в RDD
val textFile = sc.textFile("hdfs://...")
// Разделите каждую строку на слова
val words = textFile.flatMap(_.split(" "))
// Посчитайте каждое слово
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
// Соберите результаты и распечатайте
val result = wordCounts.collect()
result.foreach(println)
// останавливаться SparkContext
sc.stop()
4. Заключение
Spark Streaming и Spark Оба являются мощными инструментами обработки данных, но подходят для разных сценариев. Streaming Подходит для сценариев, требующих быстрой обработки потоков данных в реальном времени, и Spark Больше подходит для пакетной обработки больших объемов статических данных.,При выборе того, какой фреймворк использовать,Решение должно приниматься на основе конкретных потребностей бизнеса и технических требований.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
