Разберитесь, как работает Трансформер, в одной статье! !
Предисловие
Эта статья начнется сПринцип работы с одной головкой Внимание、Как работает многоголовое внимание?、полностью подключенная сеть Работапринциптри аспекта,выполнить Разбираемся в одной статьеКак работает Трансформер。

Как работает Трансформер
1. Принцип работы одноголового внимания
Одноголовое внимание: Одноголовое внимание — это механизм внимания, который привлекает внимание только один раз. В этом процессе внимание обращается на один и тот же запрос (Q), ключ (K) и значение (V) один раз, и получается результат. Этот механизм позволяет модели сосредоточиться на информации в разных местах из разных подпространств представления.
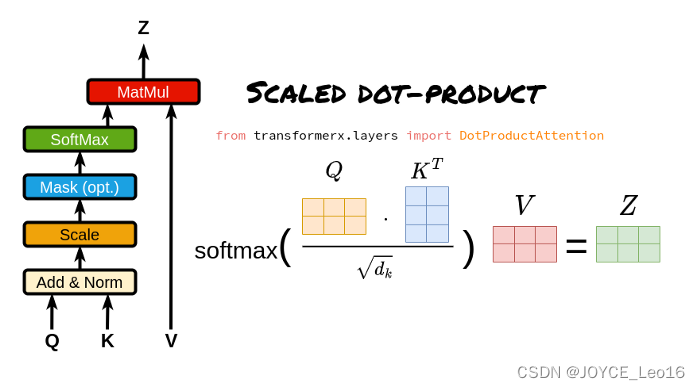
Scaled Dot-Product (операция масштабированного скалярного произведения)
- Матрица запроса, ключа и значения:
Матрица запроса (Q):Указывает текущийсосредоточиться на точку или информационное требование, используемое для сопоставления с Ключевой матрицей.
Ключевая матрица (К):Содержит идентификационную информацию для каждой позиции во входной последовательности.,Используется для сопоставления с запросом матрицы запросов.
Матрица значений (V):хранится сKeyФактическое значение или информационное содержание, соответствующее матрице,Когда запрос соответствует ключу,Соответствующее значение будет использоваться для расчета выходных данных.
- Расчет скалярного произведения:
Путем вычисления скалярного произведения между матрицей запроса и матрицей ключей (то есть соответствующие элементы умножаются, а затем суммируются) измеряется степень сходства или совпадения между запросом и каждым ключом.
- Коэффициент масштабирования:
Поскольку результат операции скалярного произведения может быть очень большим, особенно если входная размерность высока, это может привести к тому, что функция softmax войдет в зону насыщения при вычислении весов внимания. Чтобы избежать этой проблемы, внимание к масштабированному скалярному произведению вводит коэффициент масштабирования, обычно квадратный корень из входного измерения. Разделив результат скалярного произведения на этот коэффициент масштабирования, можно сохранить входные данные функции softmax в разумных пределах.
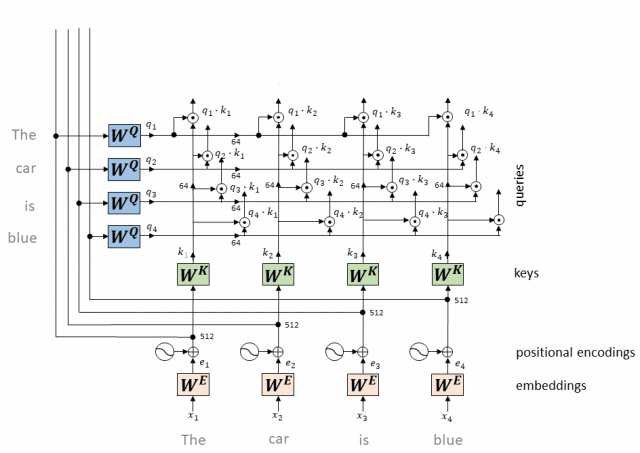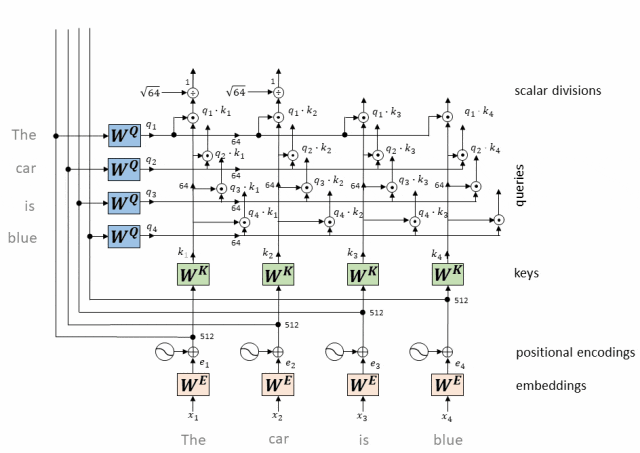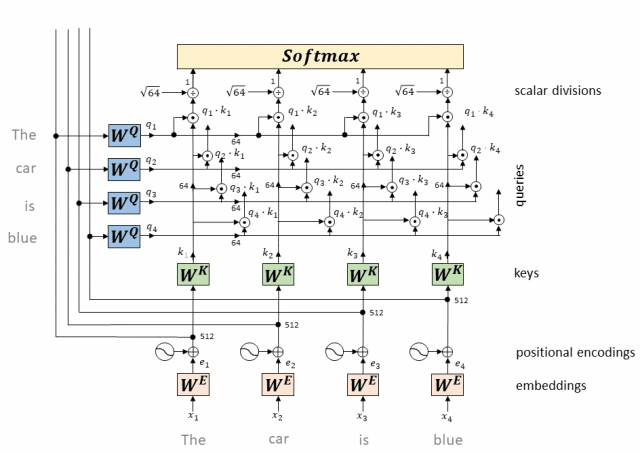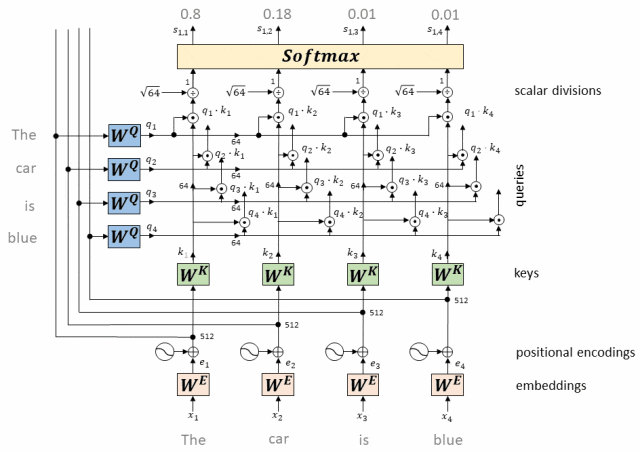
- Функция Софтмакс:
Введите масштабированный результат скалярного произведения в функцию softmax, чтобы вычислить вес внимания каждого ключа относительно запроса. Функция Softmax преобразует исходный балл в такое распределение вероятностей, что сумма весов внимания всех ключей равна 2.
Принцип работы: внимание с одной головкой вычисляет скалярное произведение вектора запроса каждого токена и ключевых векторов всех токенов, получает веса внимания посредством нормализации softmax, а затем применяет эти веса к векторам значений для взвешенного суммирования, тем самым генерируя Выходное представление каждого токена с самообслуживанием.
- Вектор запроса, соответствующий каждому токену, представляет собой скалярное произведение с вектором ключа, соответствующим каждому токену.
Для каждого токена во входной последовательности у нас есть соответствующий вектор запроса (вектор запроса, Q) и вектор ключа (вектор ключа, K).
Мы вычисляем скалярное произведение каждого вектора запроса со всеми ключевыми векторами.
Этот шаг заключается в установлении связи между всеми токенами, указывающей степень «внимания» каждого токена к другим токенам.
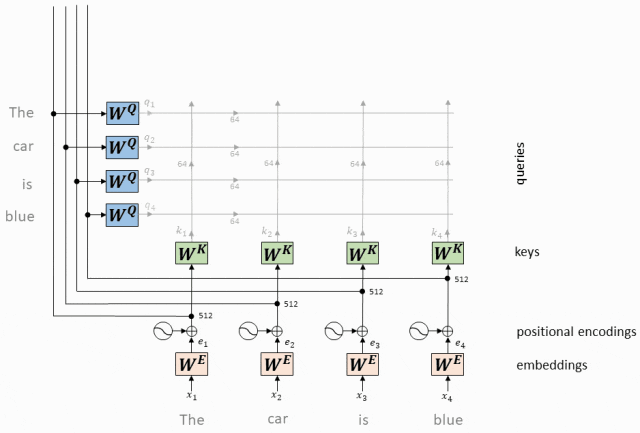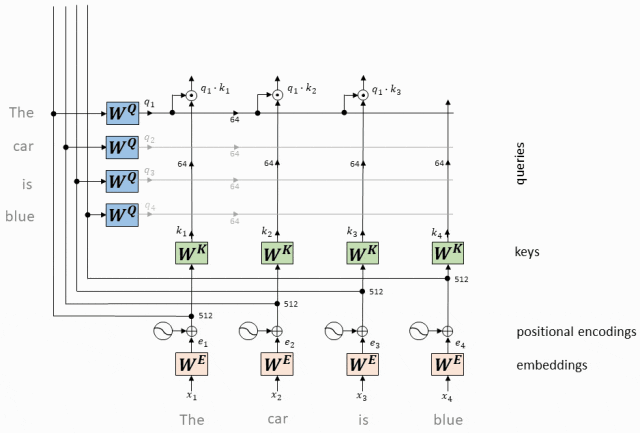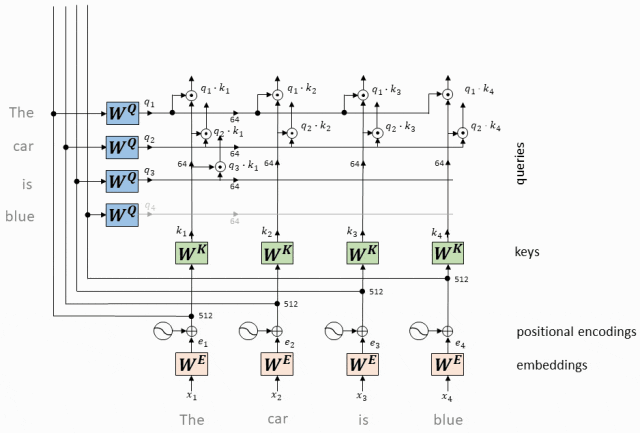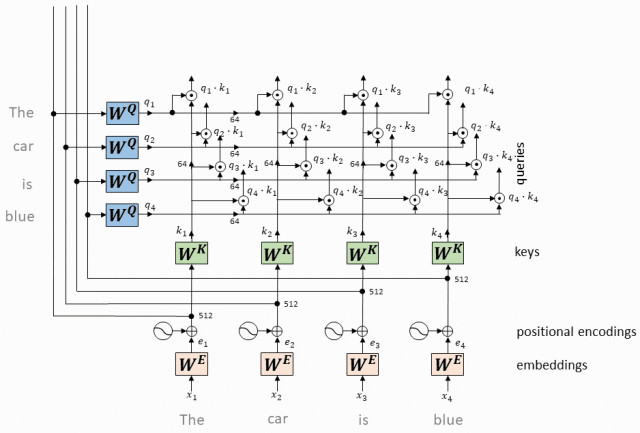
Операция скалярного произведения вектора QK
- Возьмите softmax вышеуказанного скалярного произведения (получено значение от 0 до 1, которое является весом внимания)
Результат скалярного произведения должен пройти через функцию softmax, чтобы гарантировать, что сумма весов внимания всех токенов равна 1. Функция softmax преобразует результаты скалярного произведения в значения от 0 до 1, которые представляют вес внимания каждого токена относительно всех остальных токенов.
Рассчитать вес внимания
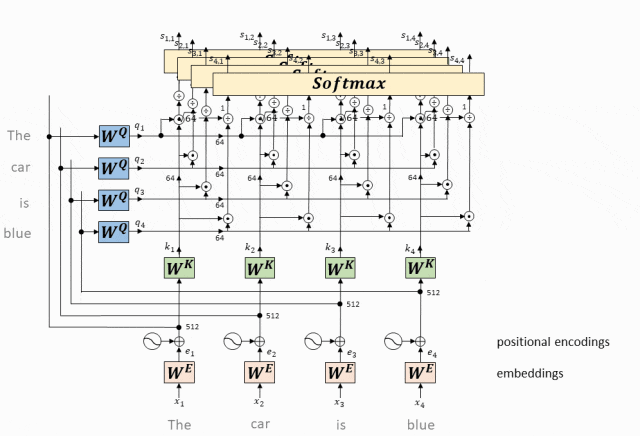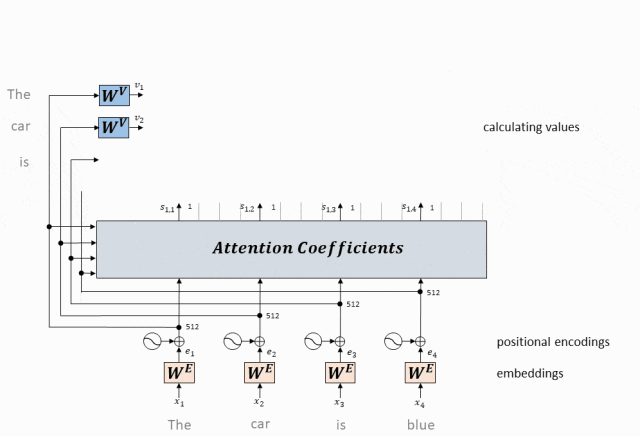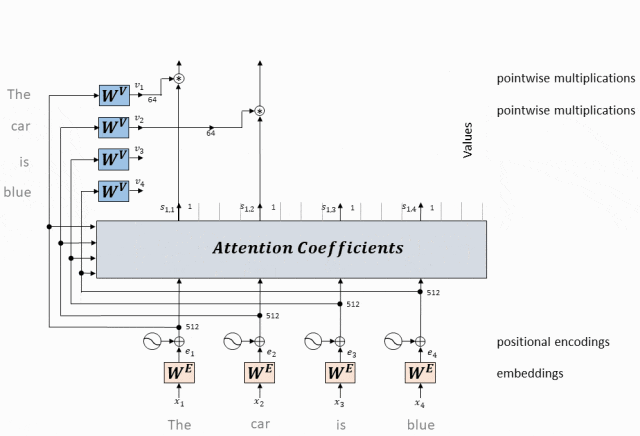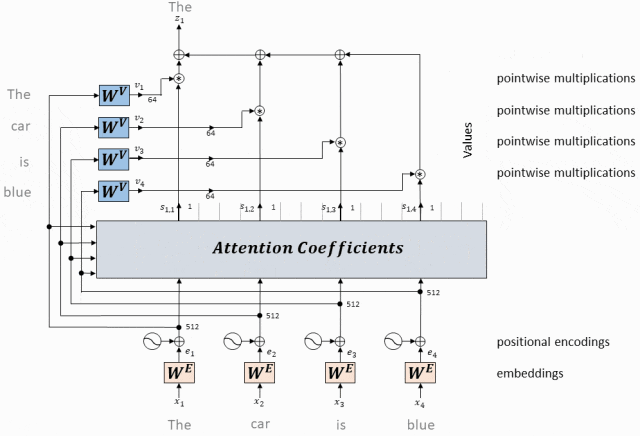
- Рассчитайте вес внимания каждого токена относительно всех остальных токенов (в конечном итоге формируя матрицу внимания).
Веса внимания после обработки softmax формируют матрицу внимания.
Каждая строка этой матрицы соответствует токену, а каждый столбец также соответствует токену. Каждый элемент в матрице представляет вес внимания соответствующего токена строки к токену столбца.

Составьте матрицу внимания
- Вектор значений, соответствующий каждому токену, умножается на вес внимания и суммируется, чтобы получить вектор значения самовнимания текущего токена.
Используйте эту матрицу внимания, чтобы взвесить вектор значений (V) во входной последовательности.
В частности, для каждого токена мы умножаем соответствующий ему вектор значений на все веса строки токена в матрице внимания и складываем результаты.
Результатом этого взвешенного суммирования является выходное представление токена после обработки механизмом самообслуживания.
Вектор значения взвешенной суммы
- Преобразуйте приведенные выше операции в Применяется к каждому токену
Приведенные выше операции будут применены к каждому токену в входной последовательности, чтобы получить выход, выраженный каждым токеном с помощью механизма самообслуживания.
Эти выходные представления обычно отправляются на следующий уровень модели для дальнейшей обработки.
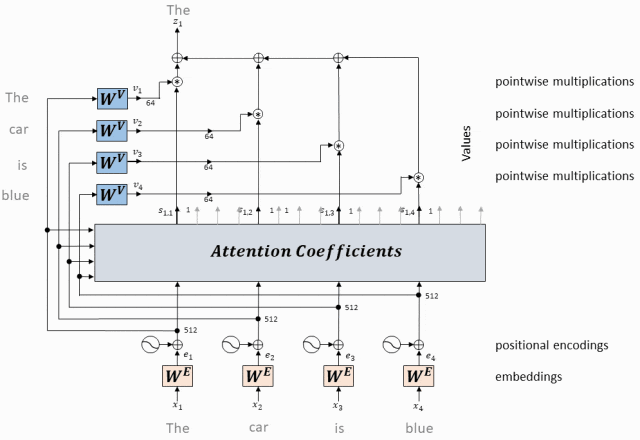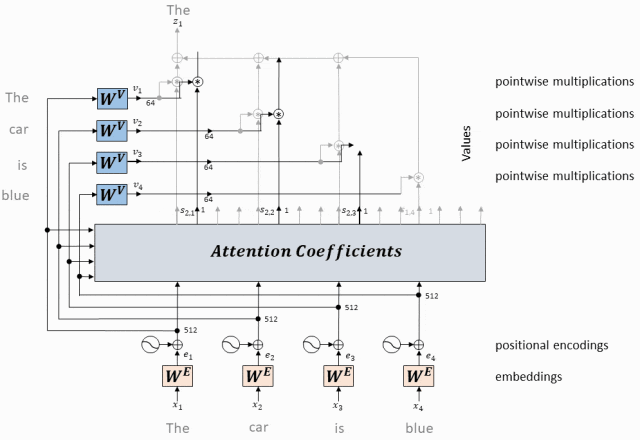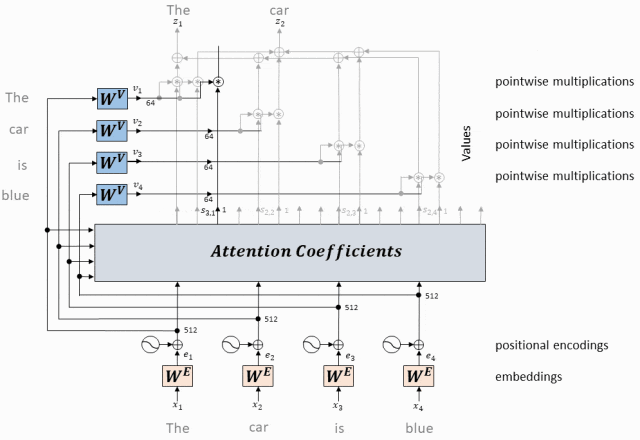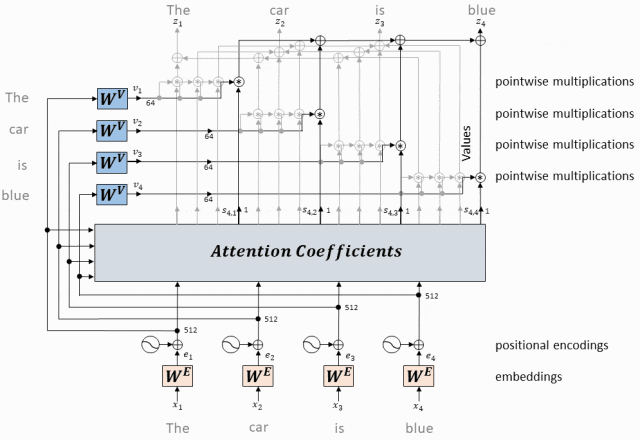
Применяется к каждому токену
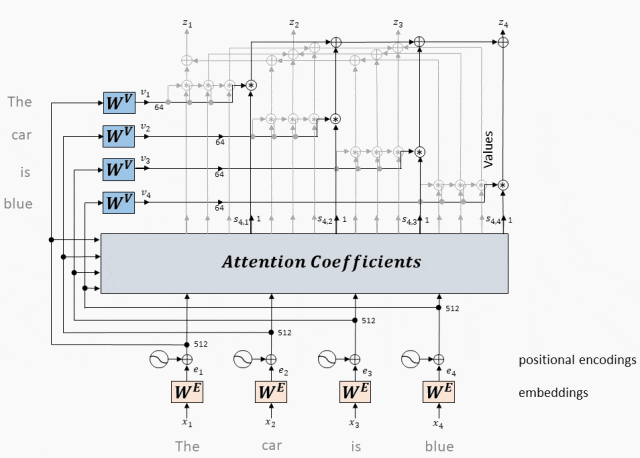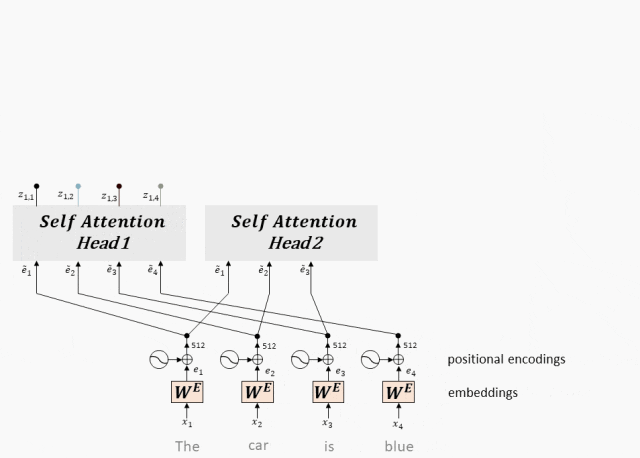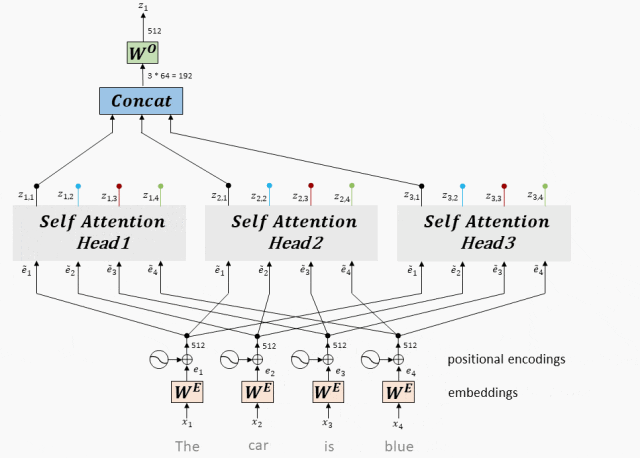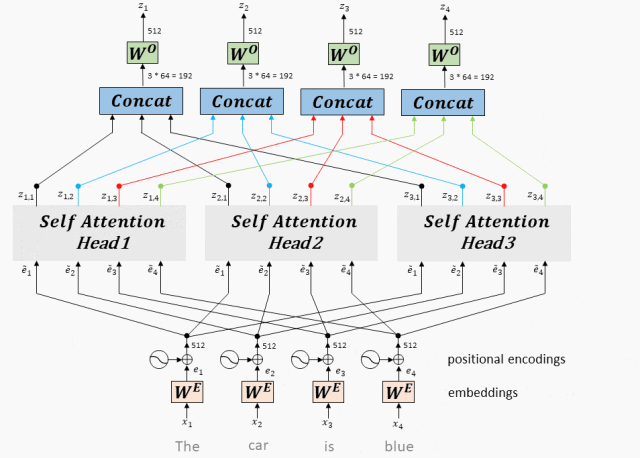
2. Принцип работы мультиголовочного внимания
Многоголовое внимание: механизм многоголового внимания может одновременно захватывать информацию входной последовательности в разных подпространствах, параллельно запуская несколько слоев самообслуживания и синтезируя результаты, тем самым улучшая выразительные способности модели.
- Многоголовое внимание на самом деле представляет собой несколько параллельных слоев самообслуживания, и каждая «голова» независимо изучает разные веса внимания.
- Выходные данные этих «голов» затем объединяются (обычно объединяются и пропускаются через линейный уровень) для получения окончательного выходного представления.
- Таким образом, Multi-Head Attentionспособен одновременнососредоточиться —Информация из разных подпространств входной последовательности.
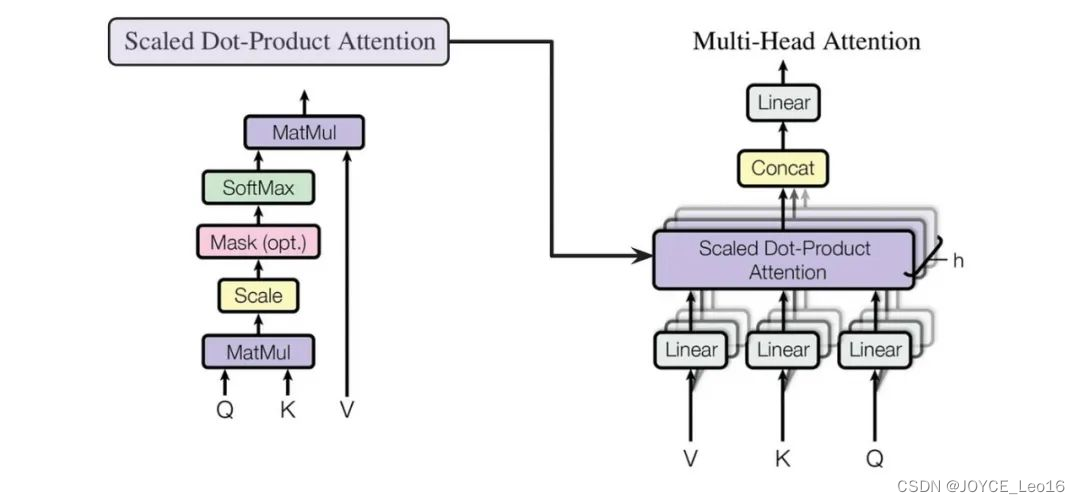
Multi-Head Attention
Принцип работы: Multi-Head Attention объединяет векторы, полученные каждой головой, и, наконец, умножает линейную матрицу для получения выходных данных Multi-Head Attention.
- Введите линейное преобразование:Для вводаQuery(Запрос)、Key(ключ)иValue(ценить)вектор,Во-первых, они отображаются в разные подпространства посредством линейного преобразования. Эти параметры линейного преобразования — это то, что модель должна изучить.
- Разделение длинной позиции:После линейного преобразования,Векторы запроса, ключа и значения разбиваются на несколько заголовков. Каждая голова производит расчеты внимания самостоятельно.
- Масштабирование внимания к скалярному произведению:внутри каждого заголовка,Используйте масштабированное скалярное произведение внимания, чтобы вычислить оценку внимания между запросом и ключом. Эта оценка определяет при создании выходных данных,Модель должнасосредоточиться — Часть вектора значений.
- Внимание: приложение веса:Примените рассчитанные веса внимания кValueвектор,Получите взвешенный промежуточный результат. Этот процесс можно понимать как фильтрацию и фокусировку входной информации на основе весов внимания.
- Сплайсинг и линейное преобразование:Объедините взвешенные выходные данные всех головок.,Затем окончательный вывод внимания Multi-Head получается посредством линейного преобразования.
Сплайсинг и линейное преобразование
3. Принцип работы полностью подключенной сети.
Сеть прямой связи: в модели Transformer сеть прямой связи используется для сопоставления вектора входного слова с вектором выходного слова для извлечения более богатой семантической информации. Сети прямой связи обычно включают в себя несколько линейных преобразований и нелинейных функций активации, а также остаточную связь и операцию нормализации слоев.
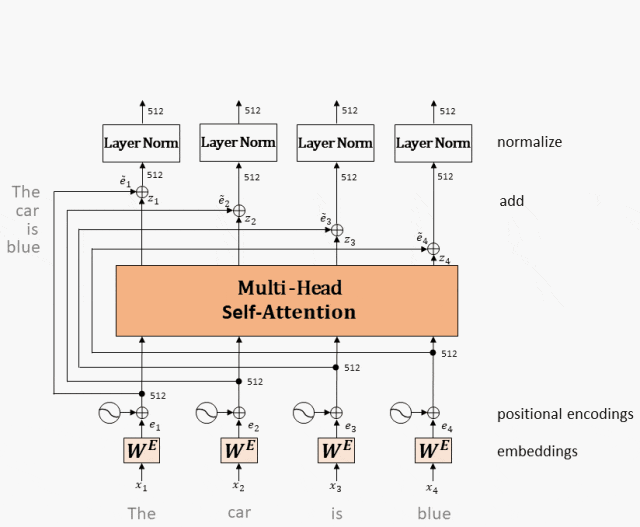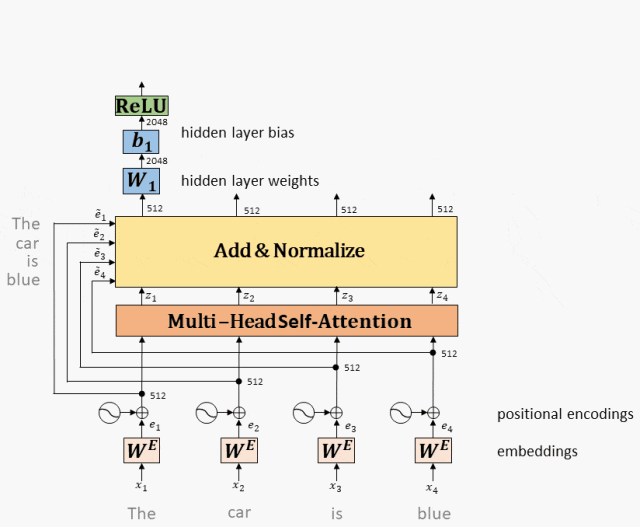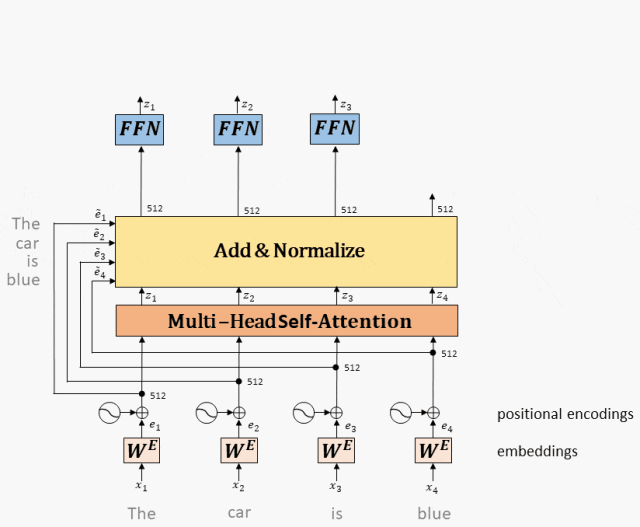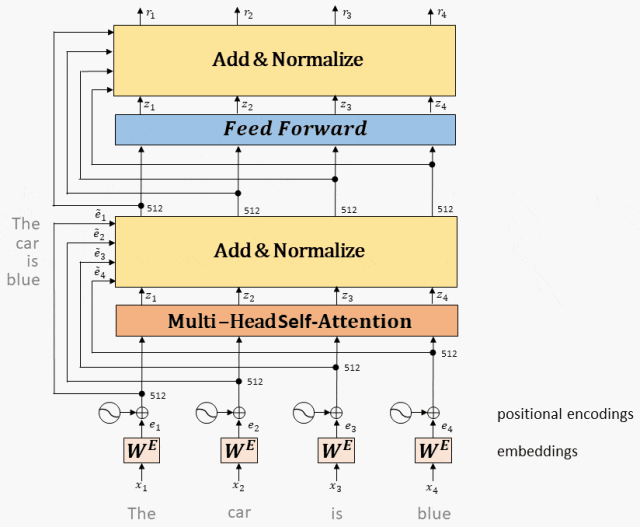
- Кодировщик:
Часть кодера в Transformer состоит из N идентичных слоев кодера.
Каждый уровень кодера имеет два подуровня, а именно уровень многоголового внимания и сеть прямой связи.
За каждым подслоем расположены операции остаточного соединения (пунктирная линия на рисунке) и нормализации слоя (LayerNorm).,Эти двое вместе называютсяAdd&Normдействовать。
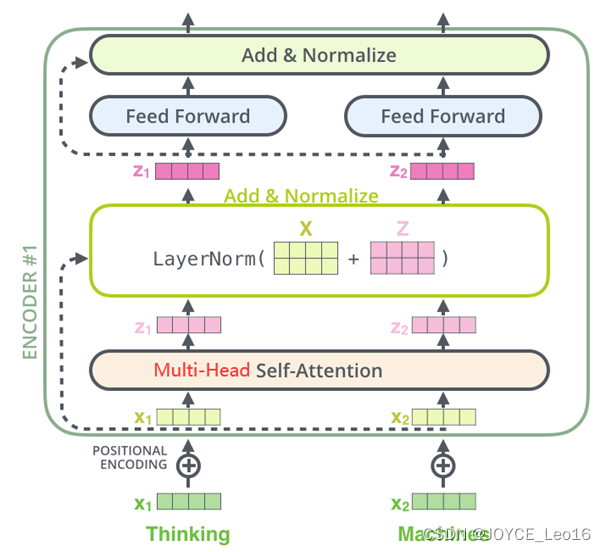
Архитектура кодировщика
- Декодер декодер:
Часть декодера в Transformer также состоит из N идентичных слоев декодера.
Каждый уровень декодера имеет три подуровня: уровень маскированного самообслуживания, уровень внимания кодировщика-декодера и сеть прямой связи.
такой же,За каждым подслоем расположены операции остаточного соединения (пунктирная линия на рисунке) и нормализации слоя (LayerNorm).,Эти двое вместе называютсяAdd&Normдействовать。
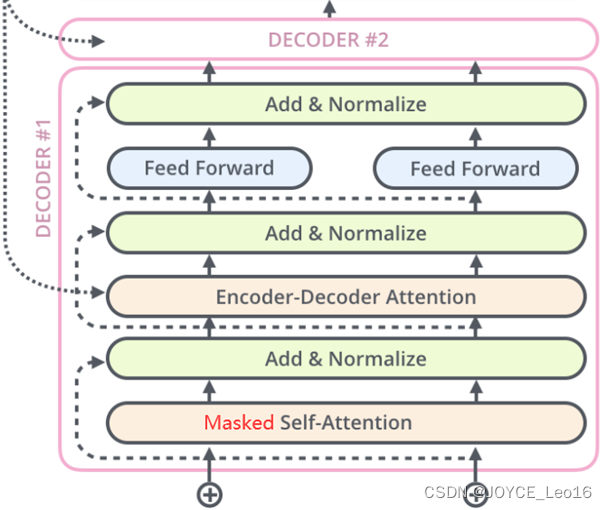
Структура декодера
Принцип работы: Выход Multi-Head Attention входит в двухслойную полностью подключенную сеть после остатка и нормы.
полностью подключенная сеть
Ссылка: Architect предлагает вам поиграть с ИИ.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
